rknn优化教程(一)
文章目录
- 1. 前述
- 2. 优化思想
- 2.1 实时帧率
- 2.2 多线程处理
- 2.2.1 排序
- 2.2.2 批量处理
- 2.2.3 队列
- 2.3 进一步优化
- 3. 代码
1. 前述
OK,铺垫了很久的rknn优化,终于开始写了。为什么要优化呢?当然是我们的使用遇到了瓶颈,要么使用的时候达不到实时帧率,要么就是根本没有将硬件利用起来,那么这篇博客就是围绕两个核心的问题来进行说明。那么博客的内容主要就是如下的一些部分:
- 如何解决
rknn_model_zoo给的demo中无法达到实时帧率的问题 - 如何能将
rk3588上的硬件资源全部利用起来 - 如何使用一些成熟的库来替代和优化
rknn_model_zoo的demo中给出的部分函数 - 如何使用
xmake构建这个优化工程
2. 优化思想
针对前面提出的4个部分,博客将逐一给出解决方案。
注意,博客将以detect进行说明,至于其他的比如segment和pose等等,都是一通百通了。
2.1 实时帧率
如果正常的使用yolo11或者yolov8的nano模型在rk3588上跑,大致能跑15~20fps就差不多了。但如果是small模型呢?如果标签数量很多呢?可能连15fps都达不到。当然这些都是以rknn_model_zoo中的demo来说的。
这里不得不吐槽一下rknn_model_zoo的代码水平,我是觉得那个
c/c++写的不伦不类,用c的思路写c++不说了,而且各种东西穿插使用,看的特别割裂。而且还有一些c/c++入门的新手写代码的一些非常低级的用法,这个东西不好用,写这个库和demo的人至少背80%的锅。一个很简单的东西,比如我现在有两个
float类型的数组A和B,如果要将A中的元素全部拷贝到B中去,这个里面的写法是:// 这里的count可能是 640*640*3这样的大小 for (int index = 0; index < count; ++index) {B[index] = A[index]; }我就不说优化的思路,或者说经常写
c/c++的人应该怎么写了,大家也可以给出自己的想法。
为了解决实时帧率:既然单线程只能跑15~20fps,那我是不是可以开2个线程?是不是可以开3个?甚至9个?
OK,那我们已经找到了一个很有用的解决方法,就是使用多线程来解决实时帧率的问题,那么我们解决了实时帧率的问题,但是又带来了新的问题:
- 如何在多线程的情况下保证帧的顺序?
2.2 多线程处理
多线程可以帮助我们达到实时帧率的处理,但是我们需要一个优雅的方法来处理帧的顺序问题。
比如我们有一个连续的帧1 2 3,然后放入到三个线程中进行处理:

当然,如果按照顺序输出 1 2 3的结果肯定是好的,但是我们根本无法保证这个输出的顺序,而且输出的顺序 3 2 1这个的概率不低,那我们就还得给输出进行排序,这个就是多线程下必须解决的问题。
那我们有几个思路:
- 对每一个数据帧都绑定一个数值,然后输出的时候进行排序?
- 每次都是执行线程数量的数据帧,每次输入输出,然后再进行下一批数量的输入输出,按照图示,就是每次送3帧数据,然后都处理完了,再送入三帧。
- 队列处理?
那我们就对这三种思路分别分析一下:
2.2.1 排序
纯粹的排序听起来是最简单的方法,非常容易,每次调用一下std::sort似乎就可以了,但是没办法解决几个问题:
- 每次
std::sort非常耗费时间和资源 - 数据连续处理的时候,针对图示的线程数量,可能存在第6帧的结果比第2帧的结果还要先得到,虽然概率极小,但是也是存在的,那怎么排序呢?怎么确认你得到了序号最小的那一个数据?
所以这个排序可以实现,但不稳定、不好用。
2.2.2 批量处理
这个很容易解决,只要我们将三个线程都是用std::future就可以了,每次等待三帧的处理,然后三个结果那也很好处理序号的问题,代码写起来那也是非常easy了,但是有一个非常严重的问题:
- 每次都必须延迟3帧的时间
虽然看起来处理的速度很快,但是要导致3帧的延迟,这对于实时系统来说,可能无法接受,尤其是:
假设你现在传入的是1fps的视频进行处理,就必须延迟3s左右才能获得结果,这就没法玩了……
2.2.3 队列
那就必须要考虑到我们在处理时序问题时候经常使用到的方法:队列
OK,知道要使用队列了,但是我怎么处理队列呢?还是没法避免排序的问题啊?
这里我们首先要想到,我线程的数量肯定不是无止境的,就rk3588这个板子,开10个线程跑detect就不错了,再开多了,搞不好还速度下降了。当然这里就是线程的数量处理问题了,经常进行并发编程的是知道的,线程并不是越多越好。
那我们来看这样一个队列处理:

这里的1st 2nd 3rd都是表示得到结果的顺序,可以快速在输出的队列上进行对应填写结果,那么:
当得到3的结果的时候,先在输出的队列索引3上写入结果,然后发现1和2还是没有得到,不进行输出
当得到2的结果的时候,先在输出的队列索引2上写入结果,然后发现1还是没有得到,不进行输出
当得到1的结果的时候,先在输出的队列索引1上写入结果,进行输出,然后发现2和3的结果也有了,那就一起输出

那么我们如何构造这样一个队列呢?
首先,我们注意到uin8_t这个类型,取值是0~255,并且当其为255的时候,自增会回到0,利用自身的溢出功能,能帮我们构建天然的索引闭环!
那我们直接将输出队列使用大小256的数组进行表示,是不是就可以实现了一个自动闭环的队列索引了?然后控制输入输出的索引处理,连排序都省去了!
256的大小完全远远超出我们的使用极限了,线程就是开了20个,那最差的情况差不多就是19个数据帧等待一个数据帧的处理结束,256完全满足了缓冲的条件了。
这只是我们假想的一个极特殊的情况,等待个线程数量的数据帧已经很极限了,正常的时候等两三帧就已经差不多了
那么用代码怎么实现呢:
// 假设的输入数据用这个结构体存储
struct TaskInput
{cv::Mat m_img;uint8_t m_taskId;... // 其他的额外数据
};// 假设输出的结果用这个一个结构体进行存储
struct TaskResult
{TaskInput m_inputData;bool m_isGet; // 是否得到了结果... // 结果的数据存储
};// 然后我们有一个线程池的类
class TaskPool
{
public:// 添加一个处理的任务void add(cv::Mat&& img);// 线程处理的函数,每一个线程都是调用这个函数进行识别的处理void run(int thread_id);// 这是所有线程处理完了之后都调用这个函数来进行结果的处理void dealResult(TaskInput&& task_data, ...); // 这里的 ... 只是表示一个结果的类型,暂时不写明具体的形参类型
private:bool m_isRun;std::mutex m_mutexInput;std::queue<TaskInput> m_taskInputs;uint8_t m_indexInput = 0; // 初始化为0std::mutex m_mutexOutput;uint8_t m_indexOutput = 0; // 初始化为0std::array<TaskResult, 256> m_taskResults;
}
那我们在add中就需要处理好输入!
void TaskPool::add(cv::Mat&& img)
{// 使用线程锁保护一下lock_guard<mutex> lg(m_mutexInput);// 将输入添加到任务队列中TaskInput input;input.m_img = std::move(img);input.m_taskId = m_indexInput++; // 这里就打上了序号了……// 其他可能的操作...;
}
在run函数中做好数据的提取:
void TaskPool::run(int thread_id)
{while (m_isRun){TaskInput task_data;{unique_lock<mutex> lock(m_mutexInput);m_cvTask.wait(lock, [&]{ return !m_taskInputs.empty() || !m_isRun; });if (!m_isRun){return;}// 减少内存拷贝task_data = std::move(m_taskInputs.front());m_taskDatas.pop();}// 这里就是根据数据进行识别的处理了,包括前处理、推理和后处理等等realWork(thread_id, std::move(task_data));// 注意,结果是通过回调处理的!}
}
那么获得了结果了,那么这里就需要在dealResult进行处理:
void TaskPool::dealResult(TaskInput&& task_data, ...)
{// 这里只是表示通过task_data来构建resultTaskResult result(std::move(task_data), ...);result.m_isGet = true;lock_guard<mutex> lg(m_mutexOutput);m_taskResults[result.m_inputData.m_taskId] = std::move(result);while (true){if (m_taskResults[m_outputIndex].m_isGet){auto &res_data = m_taskResults[m_outputIndex];// 这里就可以去处理结果了callback(std::move(res_data));// 处理完成了,这个又要变成没有得到结果的状态了!res_data.m_isGet = false;++m_outputIndex;}else{break; // 如果最前方的数据还没有得到结果,那就直接退出……}}
}
这样的处理是不是很优雅了……
2.3 进一步优化
上述的处理其实已经能提高不少了,只需要将rknn_model_zoo中的代码变换成多线程处理就可以了。
当然优化嘛,是需要精益求精的,将rknn_model_zoo中的那些低水平的代码更换为我们高水平的代码,优化他们的前处理,后处理,使用opencv和eigen等库来进行优化函数处理,并且使用我们更好的程序设计,避免一些代码的冗余等等……
3. 代码
这些优化和设计有一个可用的代码库,先整理一下,后续的博客再进行分享了。
相关文章:
rknn优化教程(一)
文章目录 1. 前述2. 优化思想2.1 实时帧率2.2 多线程处理2.2.1 排序2.2.2 批量处理2.2.3 队列 2.3 进一步优化 3. 代码 1. 前述 OK,铺垫了很久的rknn优化,终于开始写了。为什么要优化呢?当然是我们的使用遇到了瓶颈,要么使用的时…...
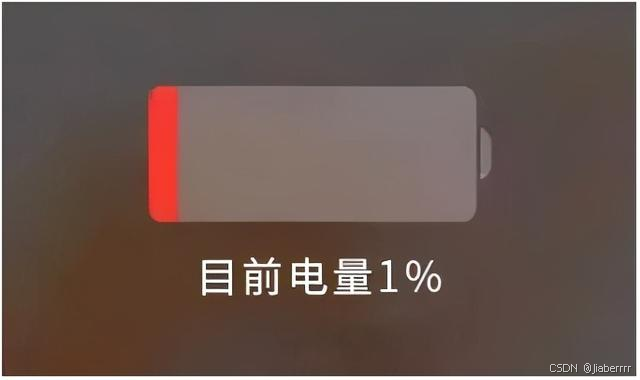
uniapp Vue2 获取电量的独家方法:绕过官方插件限制
在使用 uniapp 进行跨平台应用开发时,获取设备电量信息是一个常见的需求。然而,uniapp 官方提供的uni.getBatteryInfo方法存在一定的局限性,它不仅需要下载插件,而且目前仅支持 Vue3,这让使用 Vue2 进行开发的开发者陷…...
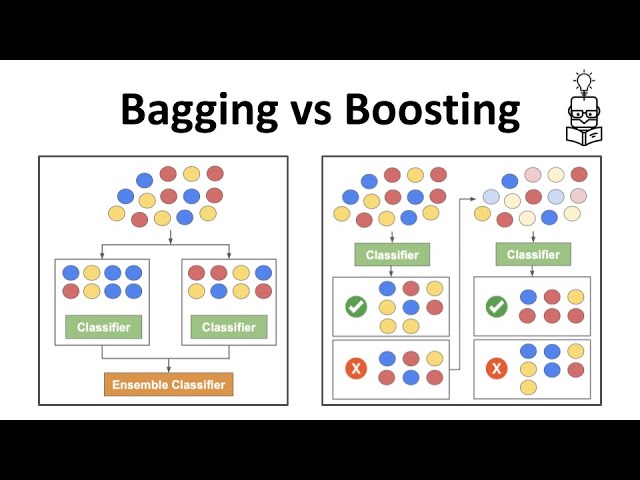
【统计方法】树模型,ensemble,bagging, boosting
决策树基础 回归树 理论上,决策区域可以有任何形状。• 然而,我们选择将预测空间划分为高维矩形或框,这是为了简单和易于解释结果预测模型 目标:将预测空间划分为矩形区域,最小化残差平方和(RSS&#x…...
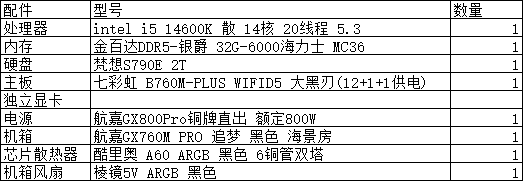
【选配电脑】CPU核显工作机控制预算5000
【选配电脑】CPU核显工作机控制预算5000 1.背景2.配置及估价3.选配的说明 1.背景 不需要独立显卡,内存,硬盘尽量大; 预算控制到5000, 主板型号,电源功率支持后续添加独立显卡。 时间节点:2025.06.07 2.配…...
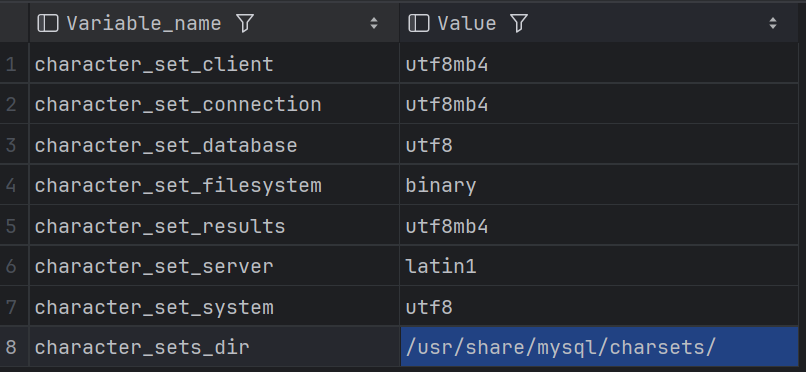
Mysql 插入中文乱码
session范围 查看数据库编码: show variables like %char%; # MySQL 5.7 字符集强制配置 # 修复 character_set_databaselatin1 等问题 [mysqld] character-set-server utf8mb4 collation-server utf8mb4_unicode_ci init_connect SET NAMES utf8mb4[client] d…...

UserAgent包名识别工具
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 背景具体实现 背景 为了更准确地分析用户下单行为的来源渠道,并实现精细化运营与风险控制,我们希望在用户下单时,能够通过请求中…...

96.如何使用C#实现串口发送? C#例子
Nuget包名称 System.IO.Ports 参考代码 using System; using System.IO.Ports; using System.Threading;namespace test {class Program{static void Main(){SerialPort port new SerialPort("COM1", 9600); // 配置串口port.Open();Timer timer new Timer((_) &…...

【工具使用】STM32CubeMX-FreeRTOS操作系统-信号标志、互斥锁、信号量篇
一、概述 无论是新手还是大佬,基于STM32单片机的开发,使用STM32CubeMX都是可以极大提升开发效率的,并且其界面化的开发,也大大降低了新手对STM32单片机的开发门槛。 本文主要讲述STM32芯片FreeRTOS信号标志、互斥锁和信号…...

[P2P]并发模式
设备可以同时作为 P2P Client 监听其他P2P请求,需要硬件和驱动支持。 //某些高级Wi-Fi芯片(如高通、博通)支持 Concurrent Mode(并发模式 GO 如果GO已经有一个client,大多数支持接受新的P2P Discovery。默认情况下会…...

Cloudflare 免费域名邮箱 支持 Catch-all 无限别名收件
本文首发于只抄博客,欢迎点击原文链接了解更多内容。 前言 与自建 Poste.io 还有 Serv00 邮局不同,Cloudflare 的域名邮箱并不需要 VPS,也没有复杂的配置。只要有一个托管在 Cloudflare 的域名就可以部署,像是常见的免费域名 eu.org 或者 dpdns.org 都是可以使用的。 需要…...
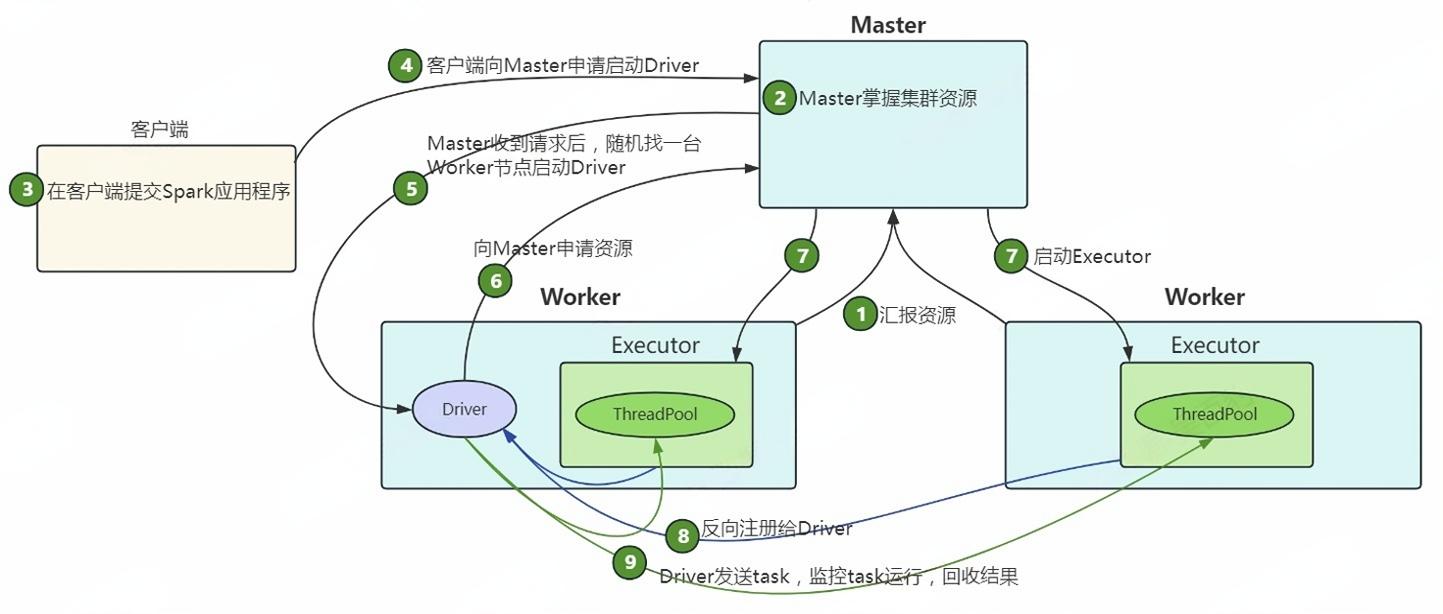
大数据Spark(六十一):Spark基于Standalone提交任务流程
文章目录 Spark基于Standalone提交任务流程 一、Standalone-Client模式 1、提交命令 2、任务执行流程 二、Standalone-Cluster模式 1、提交命令 2、任务执行流程 Spark基于Standalone提交任务流程 在Standalone模式下,Spark的任务提交根据Driver程序运行的位…...

学习记录:DAY32
Electron 开发之旅:从入门到实践 前言 接续上一篇 blog,这篇的内容主要和 Electron 有关。 课设不是特别想做下去了,实际核心代码大概只有 3,4 百行左右,比较水…… 或许会把 Docker 的部署也做一做(权当是…...

next,react封装axios,http请求
import axios from axios;//声明一个基础接口变量1 let base_url; //配置开发环境 if (process.env.NODE_ENV development) {base_url "http://127.0.0.1/"; } // 配置生产环境 if (process.env.NODE_ENV production) {base_url "http://127.0.0.1/"; …...

元图CAD:一键解锁PDF转CAD,OCR技术赋能高效转换
在建筑、工程与制造领域,图纸的精准性与高效协作是项目成功的关键。然而,传统PDF文件中的文字和图形往往难以直接编辑,手动输入不仅耗时易错,还可能因格式问题导致信息丢失。元图CAD凭借创新的OCR文字识别技术,重新定义…...
Android 平台RTSP/RTMP播放器SDK接入说明
一、技术背景 自2015年起,大牛直播SDK持续深耕音视频直播领域,自主研发并迭代推出跨平台 RTSP/RTMP 播放模块,具备如下核心优势: 全平台兼容:支持 Android/iOS/Windows/Linux 等主流系统; 超低延迟&#…...

Nodejs工程化实践:构建高性能前后端交互系统
一、工程架构设计 1.1 现代化项目初始化 采用多包管理架构: mkdir content-platform && cd content-platform npm init -y npx lerna init mkdir -p {packages/client,packages/server,packages/shared} 关键模块划分: client/: 基于Next.js…...
STM32什么是寄存器
提示:文章 文章目录 前言一、背景二、2.12.2 三、3.1 总结 前言 前期疑问: 1、什么是寄存器? 答:在4GB的地址空间中,512MB的block2上,每4个字节组成32位,这个32位为一个单元,控制&a…...

Linux 的 find 命令使用指南
精通 Linux 的 find 命令:终极使用指南 在 Linux 系统中,find 命令是文件搜索的瑞士军刀,它能基于多种条件在目录树中精准定位文件。无论你是系统管理员还是开发者,掌握 find 都能极大提升工作效率。本文将深入解析 find 的核心用法,并附赠实用示例! 一、基础语法结构 …...
第六个微信小程序:教师工具集
源于工作需要,下面开始。 安装及使用 | Taro 文档 vscode 代码管理 git 辅助 开发技术如上: 1.开始创建模板 taro4.1.1 $ taro init teachers-tools 2.用vsocde开始吧。 选择 第二个文件夹找一。 (base) PS D:\react\teachers-tools> pnpm…...
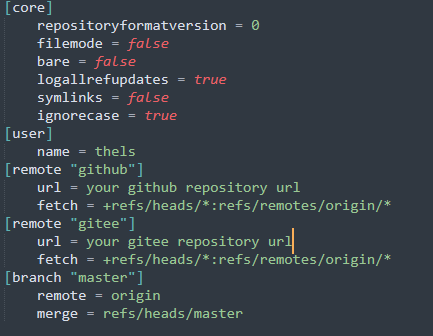
记录一个用了很久的git提交到github和gitee比较方便的方法
在当前git init后,在隐藏的git文件夹中找到config文件 [user]name thels [remote "github"]url your github repository urlfetch refs/heads/*:refs/remotes/origin/* [remote "gitee"]url your gitee repository urlfetch refs/heads/*:…...
Qt Qml模块功能及功能解析
QtQml 是 Qt 6.0 中用于声明式 UI 开发和应用程序逻辑的核心模块,它提供了 QML 语言的支持和运行时环境。 一、主要功能 1. QML 语言支持 QML 语法解析:支持 QML (Qt Meta-Object Language 或 Qt Modeling Language) 的完整语法 JavaScript 集成&…...

前端八股之JS的原型链
1.原型的定义 每一个对象从被创建开始就和另一个对象关联,从另一个对象上继承其属性,这个另一个对象就是 原型。 当访问一个对象的属性时,先在对象的本身找,找不到就去对象的原型上找,如果还是找不到,就去…...
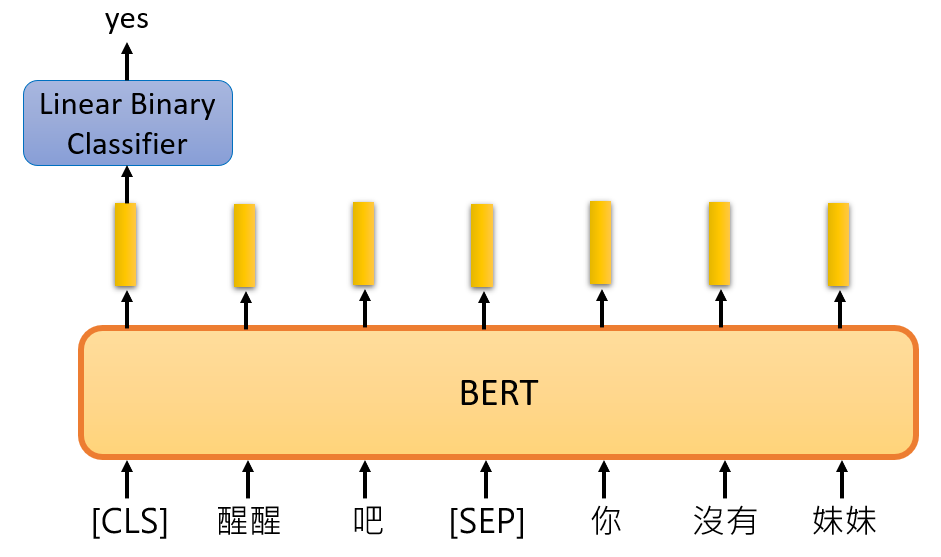
NLP学习路线图(二十九):BERT及其变体
在自然语言处理(NLP)领域,一场静默的革命始于2017年。当谷歌研究者发表《Attention is All You Need》时,很少有人预料到其中提出的Transformer架构会彻底颠覆NLP的发展轨迹,更催生了以GPT系列为代表的语言模型风暴,重新定义了人类与机器的交互方式。 一、传统NLP的瓶颈:…...

机器翻译模型笔记
机器翻译学习笔记(简体中文) 1. 任务概述 目标:将英文句子翻译成简体中文。 示例: 输入:Tom is a student. 输出:汤姆是一个学生。 框架:Seq2Seq(序列到序列)模型。…...

Ref vs. Reactive:Vue 3 响应式变量的最佳选择指南
Ref vs. Reactive:Vue 3 响应式变量的最佳选择指南 在 Vue 3 的 Composition API 中,ref 和 reactive 是创建响应式数据的两种主要方式。许多开发者经常困惑于何时使用哪种方式。本文将深入对比两者的差异,帮助您做出最佳选择。 核心概念解…...
像大语言模型(LLMs)一样“会思考”)
让视觉基础模型(VFMs)像大语言模型(LLMs)一样“会思考”
视觉检测器的演进:从 DETR 到 Grounding-DINO DINO-R1 的基础是 Grounding-DINO,而 Grounding-DINO 本身是一系列视觉检测器演进的结果。理解这个发展过程对掌握 DINO-R1 的核心技术至关重要。 DETR:用 Transformer 革新目标检测 在 DETR&…...

现代前端框架的发展与演进
现代前端框架的发展与演进是一个非常值得关注的话题,反映了整个前端生态系统的不断演化与技术深度的提升。以下是这一趋势的详细解析: 📈 现代前端框架的发展与演进 🔹 第一阶段:jQuery 时代(2006-2013&am…...
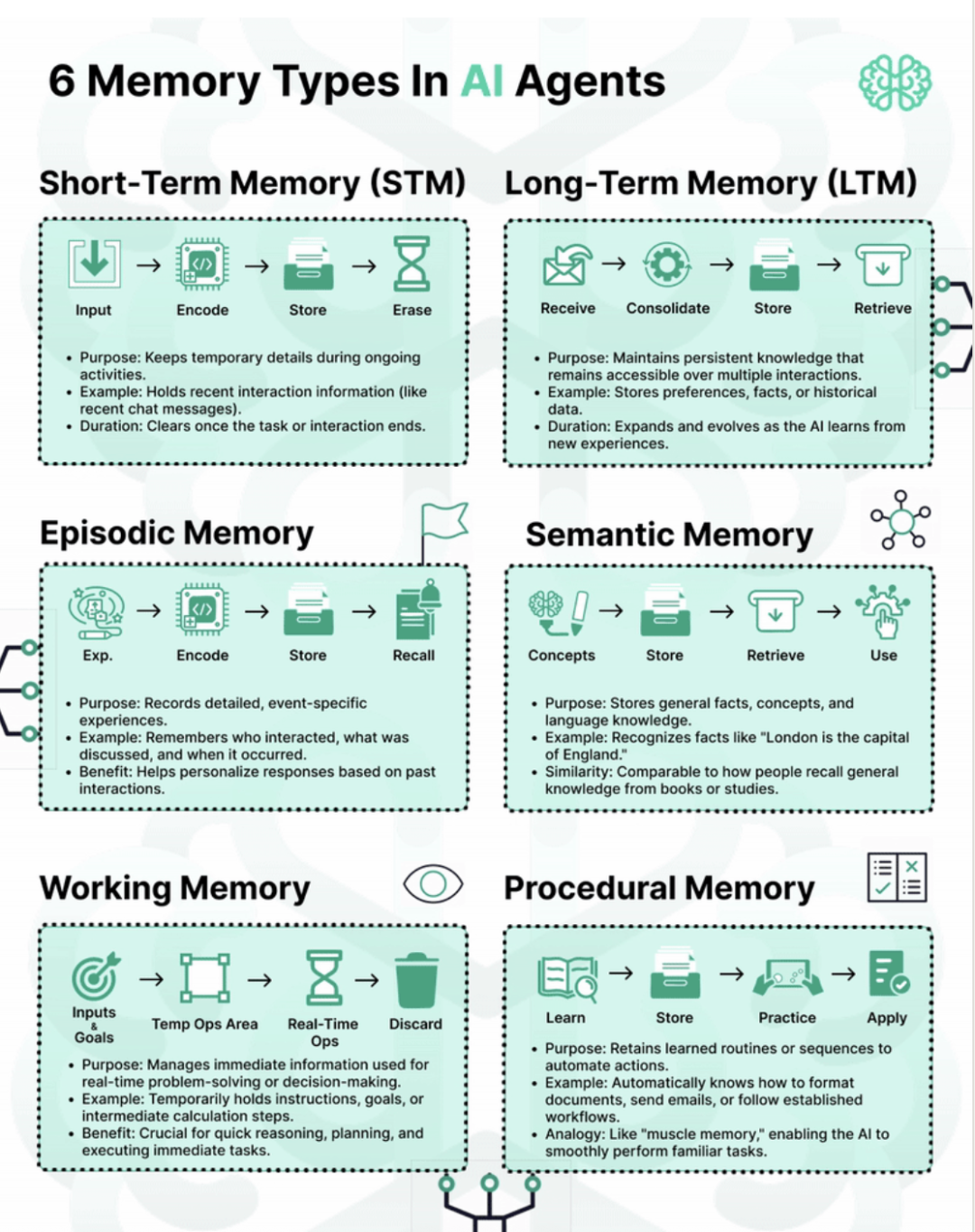
【LLM-Agent】智能体的记忆缓存设计
note 实践:https://modelscope-agent.readthedocs.io/zh-cn/latest/modules/memory.html 文章目录 note一、Agent的记忆实现二、相关综述三、记忆体的构建四、cursor的记忆设计1. 记忆生成提示词2. 记忆评估提示词 五、记忆相关的MCPReference 一、Agent的记忆实现…...
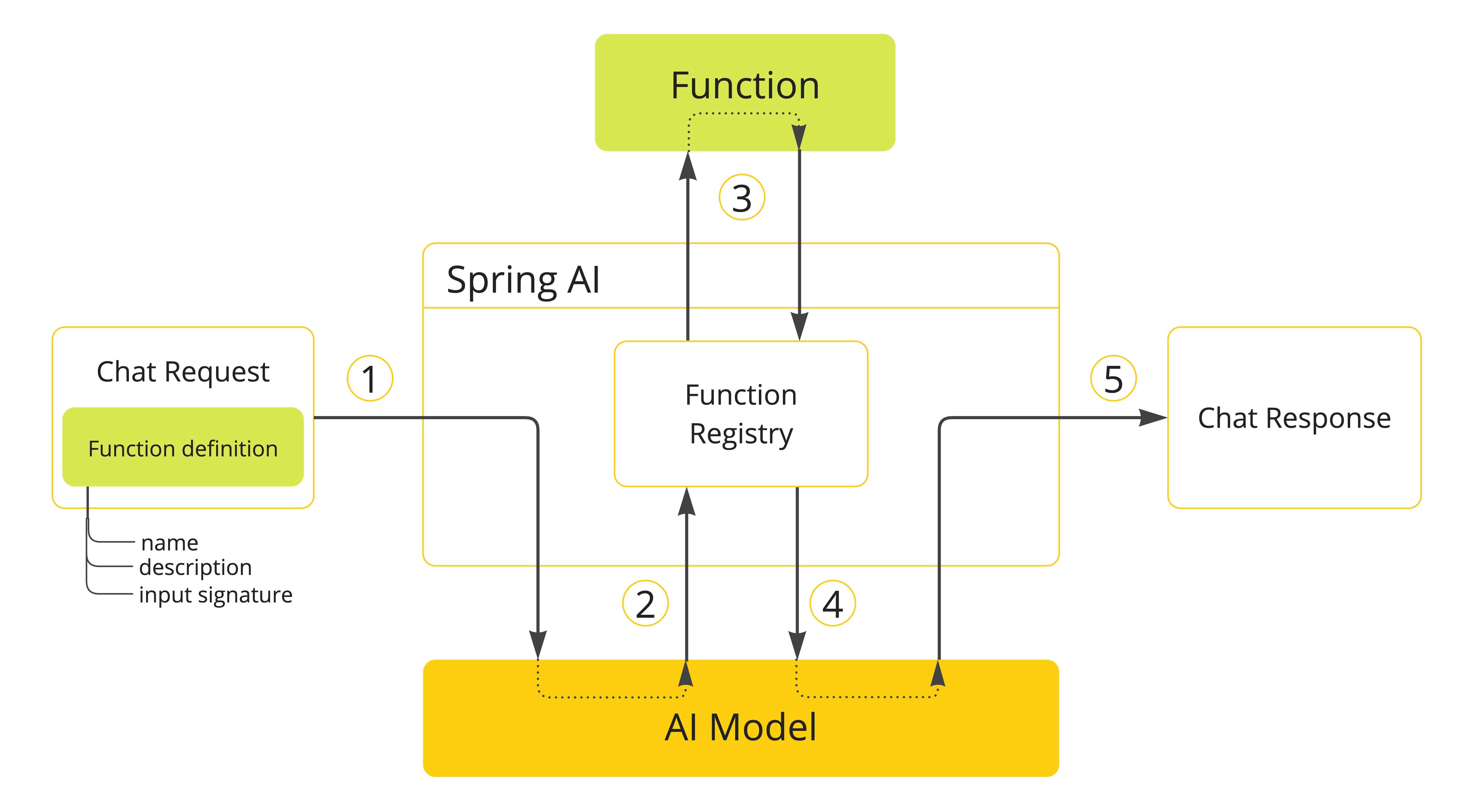
一起学Spring AI:核心概念
人工智能概念 本节描述了 Spring AI 使用的核心概念。我们建议您仔细阅读,以理解 Spring AI 实现背后的思想。 模型(Models) 人工智能模型是设计用来处理和生成信息的算法,通常模仿人类的认知功能。通过从大型数据集中学习模式…...

Oracle业务用户的存储过程个数及行数统计
Oracle业务用户的存储过程个数及行数统计 统计所有业务用户存储过程的个数独立定义的存储过程定义在包里的存储过程统计所有业务用户存储过程的总行数独立定义的存储过程定义在包里的存储过程📖 对存储过程进行统计主要用到以下三个系统视图: dba_objects:记录了所有独立创…...