Python 隐藏法宝:双下划线 _ _Dunder_ _
你可能不知道,Python里那些用双下划线包裹的"魔法方法"(Dunder方法),其实是提升代码质量的绝佳工具。但有趣的是,很多经验丰富的开发者对这些方法也只是一知半解。
先说句公道话: 这其实情有可原。因为在多数情况下,Dunder方法的作用是"锦上添花"——它们能让代码更简洁规范,但不用它们也能完成任务。有时候我们甚至不知不觉就在使用这些特殊方法了。
如果你符合以下任一情况:
-
经常用Python但不太了解这个特性
-
像我一样痴迷编程语言的精妙设计
-
想让代码既专业又优雅
那么,这篇文章就是为你准备的!我们将探索如何巧妙运用这些"魔法方法"来:
-
大幅简化代码逻辑
-
提升代码可读性
-
写出更Pythonic的优雅代码
表象会骗人......即使在 Python 中也是如此!
如果说我在生活中学到了什么,那就是并非所有东西都像第一眼看上去那样,Python 也不例外。
看一个看似简单的例子:
class EmptyClass:pass
这是我们可以在 Python 中定义的最 “空” 的自定义类,因为我们没有定义属性或方法。它是如此的空,你会认为你什么也做不了。
然而,事实并非如此。例如,如果您尝试创建该类的实例,甚至比较两个实例是否相等,Python 都不会抱怨:
empty_instance = EmptyClass()
another_empty_instance = EmptyClass()
empty_instance == another_empty_instance
False
当然,这并不是魔法。简单地说,利用标准的 object 接口,Python 中的任何对象都继承了一些默认属性和方法,这些属性和方法可以让用户与之进行最少的交互。
虽然这些方法看起来是隐藏的,但它们并不是不可见的。要访问可用的方法,包括 Python 自己分配的方法,只需使用 dir() 内置函数。对于我们的空类,我们得到
>>> dir(EmptyClass)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__',
'__str__', '__subclasshook__', '__weakref__']
正是这些方法可以解释我们之前观察到的行为。例如,由于该类实际上有一个__init__方法,我们就不应该对我们可以实例化一个该类的对象感到惊讶。
Dunder方法
最后输出中显示的所有方法都属于一个特殊的群体--猜猜看--dunder 方法。dunder 是双下划线(double underscore)的缩写,指的是这些方法名称开头和结尾的双下划线。
它们之所以特殊,有以下几个原因:
-
它们内置于每个对象中:每个 Python 对象都配备了由其类型决定的一组特定的 dunder 方法。
-
它们是隐式调用的:许多 dunder 方法是通过与 Python 本机运算符或内置函数的交互自动触发的。例如,用
==比较两个对象相当于调用它们的__eq__方法。 -
它们是可定制的:您可以覆盖现有的 dunder 方法,或者为您的类定义新的方法,以便在保留隐式调用的同时赋予它们自定义的行为。
对于大多数 Python 开发者来说,他们遇到的第一个 dunder 是 __init__,构造函数方法。当您创建一个类的实例时,这个方法会被自动调用,使用熟悉的语法 MyClass(*args, **kwargs)作为显式调用 MyClass.__init__(*args, **kwargs) 的快捷方式。
尽管是最常用的方法,__init__ 也是最专业的 dunder 方法之一。它没有充分展示 dunder 方法的灵活性和强大功能,而这些方法可以让您重新定义对象与原生 Python 特性的交互方式。
使对象漂亮
定义一个类来表示商店中出售的物品,并通过指定名称和价格来创建一个实例。
class Item:def __init__(self, name: str, price: float) -> None:self.name = nameself.price = priceitem = Item(name="Milk (1L)", price=0.99)
如果我们尝试显示 item 变量的内容,会发生什么?现在,Python 所能做的就是告诉我们它是什么类型的对象,以及它在内存中的分配位置:
item
<__main__.Item at 0x00000226C614E870>
试着得到一个信息量更大、更漂亮的输出!
要做到这一点,我们可以覆盖 __repr__ dunder,当在交互式 Python 控制台中键入一个类实例时,它的输出将完全是打印出来的,而且--只要没有覆盖另一个 dunder 方法 __str__ --当试图调用 print() 时也是如此。
注意:通常的做法是让 __repr__ 提供重新创建打印实例所需的语法。因此,在后一种情况下,我们希望输出Item(name="Milk(1L)", price=0.99)。
class Item:def __init__(self, name: str, price: float) -> None:self.name = nameself.price = pricedef __repr__(self) -> str:return f"{self.__class__.__name__}('{self.name}', {self.price})"item = Item(name="Milk (1L)", price=0.99)item # In this example it is equivalent also to the command: print(item)
Item('Milk (1L)', 0.99)
没什么特别的吧?你说得没错:我们本可以实现同样的方法,并将其命名为 *my_custom_repr*,而不需要使用indo dunder 方法。然而,虽然任何人都能立即理解 print(item) 或 item 的意思,但 item.my_custom_repr() 这样的方法也能理解吗?
定义对象与 Python 本地运算符之间的交互
假设我们想创建一个新类,即 Grocery,它允许我们建立一个 Item 及其数量的集合。
在这种情况下,我们可以使用 dunder 方法来进行一些标准操作,例如
-
使用 + 运算符将特定数量的 Item 添加到 Grocery 中
-
使用 for 循环直接遍历 Grocery 类
-
使用括号 [] 符号从 Grocery 类中访问特定的 Item
为了实现这一目标,我们将定义(我们已经看到泛型类默认情况下没有这些方法)dunder 方法 __add__, __iter__ 和__getitem__。
from typing import Optional, Iterator
from typing_extensions import Selfclass Grocery:def __init__(self, items: Optional[dict[Item, int]] = None):self.items = items or dict()def __add__(self, new_items: dict[Item, int]) -> Self:new_grocery = Grocery(items=self.items)for new_item, quantity in new_items.items():if new_item in new_grocery.items:new_grocery.items[new_item] += quantityelse:new_grocery.items[new_item] = quantityreturn new_grocerydef __iter__(self) -> Iterator[Item]:return iter(self.items)def __getitem__(self, item: Item) -> int:if self.items.get(item):return self.items.get(item)else:raise KeyError(f"Item {item} not in the grocery")
初始化一个 Grocery 实例,并打印其主要属性 items. 的内容。
item = Item(name="Milk (1L)", price=0.99)
grocery = Grocery(items={item: 3})print(grocery.items)
{Item('Milk (1L)', 0.99): 3}
然后,我们使用 + 运算符添加一个新项目,并验证更改是否已生效。
new_item = Item(name="Soy Sauce (0.375L)", price=1.99)
grocery = grocery + {new_item: 1} + {item: 2}print(grocery.items)
{Item('Milk (1L)', 0.99): 5, Item('Soy Sauce (0.375L)', 1.99): 1}
既友好又明确,对吗?
通过 __iter__ 方法,我们可以按照该方法中实现的逻辑对一个 Grocery 对象进行循环(即,隐式循环将遍历可遍历属性 items 中包含的元素)。
print([item for item in grocery])
[Item('Milk (1L)', 0.99), Item('Soy Sauce (0.375L)', 1.99)]
同样,访问元素也是通过定义 __getitem__ 函数来处理的:
>>> grocery[new_item]
1fake_item = Item("Creamy Cheese (500g)", 2.99)
>>> grocery[fake_item]
KeyError: "Item Item('Creamy Cheese (500g)', 2.99) not in the grocery"
从本质上讲,我们为 Grocery 类分配了一些类似字典的标准行为,同时也允许进行一些该数据类型本机无法进行的操作。
增强功能:使类可调用,以实现简单性和强大功能。
最后,让我们用一个示例来结束对 dunder 方法的深入探讨,展示它们如何成为我们的强大工具。
想象一下,我们实现了一个函数,它可以根据特定输入执行确定性的慢速计算。为了简单起见,我们将以一个内置 time.sleep 为几秒的标识函数为例。
import time def expensive_function(input):time.sleep(5)return input
如果我们对同一输入运行两次函数,会发生什么情况?那么,现在计算将被执行两次,这意味着我们将两次获得相同的输出,在整个执行时间内等待两次(即总共 10 秒)。
start_time = time.time()>>> print(expensive_function(2))
>>> print(expensive_function(2))
>>> print(f"Time for computation: {round(time.time()-start_time, 1)} seconds")
2
2
Time for computation: 10.0 seconds
这合理吗?为什么我们要对相同的输入进行相同的计算(导致相同的输出),尤其是在计算过程很慢的情况下?
一种可能的解决方案是将该函数的执行 “封装 ”在类的 __call__ dunder 方法中。
这使得类的实例可以像函数一样被调用--这意味着我们可以使用简单的语法 my_class_instance(\*args,\**kwargs) --同时也允许我们使用属性作为缓存来减少计算时间。
通过这种方法,我们还可以灵活地创建多个进程(即类实例),每个进程都有自己的本地缓存。
class CachedExpensiveFunction:def __init__(self) -> None:self.cache = dict()def __call__(self, input):if input not in self.cache:output = expensive_function(input=input)self.cache[input] = outputreturn outputelse:return self.cache.get(input)start_time = time.time()
cached_exp_func = CachedExpensiveFunction()>>> print(cached_exp_func(2))
>>> print(cached_exp_func(2))
>>> print(f"Time for computation: {round(time.time()-start_time, 1)} seconds")
2
2
Time for computation: 5.0 seconds
不出所料,函数在第一次运行后会被缓存起来,这样就不需要进行第二次计算,从而将总时间缩短了一半。
如上所述,如果需要,我们甚至可以创建该类的独立实例,每个实例都有自己的缓存。
start_time = time.time()
another_cached_exp_func = CachedExpensiveFunction()>>> print(cached_exp_func(3))
>>> print(another_cached_exp_func (3))
>>> print(f"Time for computation: {round(time.time()-start_time, 1)} seconds")
3
3
Time for computation: 10.0 seconds
dunder 方法是一个简单而强大的优化技巧,它不仅可以减少冗余计算,还可以通过本地特定实例缓存提供灵活性。
写在最后
Dunder方法(就是那些用双下划线__包裹的特殊方法)在Python中是个很大的话题,而且还在不断丰富。这篇文章当然没法面面俱到地讲完所有内容。
我写这些主要是想帮你弄明白两件事:
-
Dunder方法到底是什么?
-
怎么用它们解决实际编程中常见的问题?
说实话,不是每个程序员都必须掌握这些方法。但就我个人经验来说,当我真正搞懂它们之后,写代码的效率提高了很多。相信对你也会很有帮助。
使用Dunder方法最大的好处就是:
-
不用重复造轮子
-
让代码更简洁易读
-
更符合Python的编程风格
这些优点,对你一定是有用的。对吧?点个赞吧❤️支持一下
相关文章:

Python 隐藏法宝:双下划线 _ _Dunder_ _
你可能不知道,Python里那些用双下划线包裹的"魔法方法"(Dunder方法),其实是提升代码质量的绝佳工具。但有趣的是,很多经验丰富的开发者对这些方法也只是一知半解。 先说句公道话: 这其实情有可原。因为在多数情况下&am…...

《视觉SLAM十四讲》自用笔记 第三讲:三维空间刚体运动
第三讲 三维空间刚体运动 3.0 目标 1.理解三维空间的刚体运动描述方式:旋转矩阵、变换矩阵、四元数和欧拉角。 2.掌握 Eigen 库的矩阵、几何模块使用方法。 3.1 旋转矩阵 3.1.1 点和向量,坐标系 三维空间中,刚体的运动可以用两个概念来…...

【Zephyr 系列 15】构建企业级 BLE 模块通用框架:驱动 + 事件 + 状态机 + 低功耗全栈设计
🧠关键词:Zephyr、BLE 模块、架构设计、驱动封装、事件机制、状态机、低功耗、可维护框架 📌面向读者:希望将 BLE 项目从“Demo 工程”升级为“企业可复用框架”的研发人员与技术负责人 📊预计字数:5500+ 字 🧭 前言:从 Demo 到产品化,架构该如何升级? 多数 BLE…...
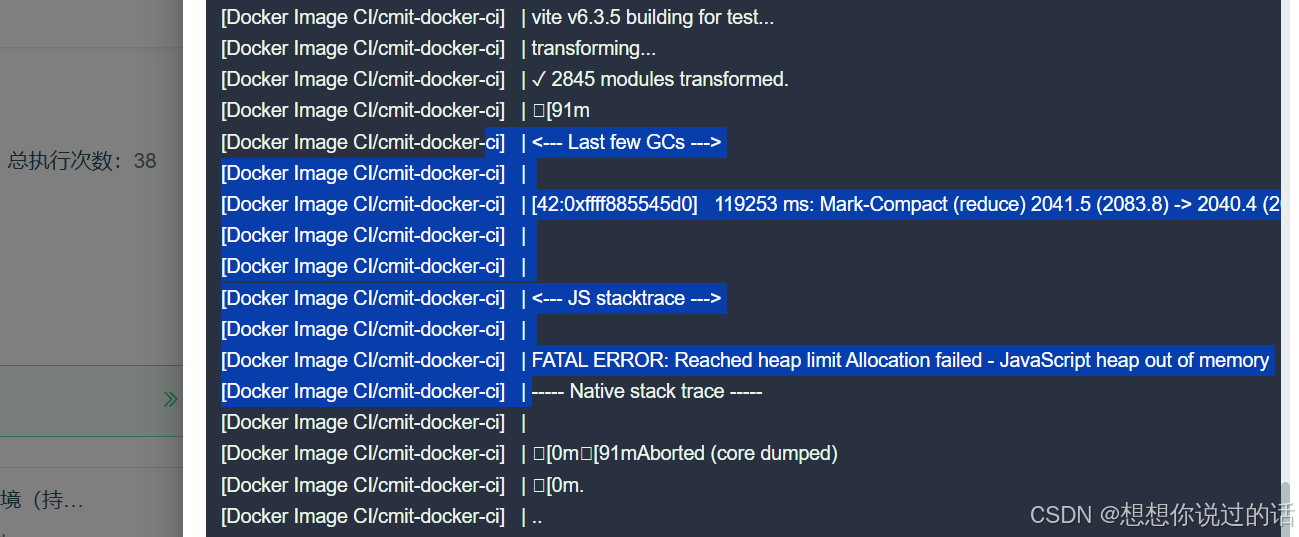
Docker构建Vite项目内存溢出:从Heap Limit报错到完美解决的剖析
问题现象:诡异的"消失的index.html" 最近在CI/CD流水线中遇到诡异现象:使用Docker构建Vite项目时,dist目录中缺少关键的index.html文件,但本地构建完全正常。报错截图显示关键信息: FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out…...
)
Linux运维新人自用笔记(乌班图apt命令和dpkg命令、两系统指令区别,rpm解决路径依赖、免安装配置java环境)
内容全为个人理解和自查资料梳理,欢迎各位大神指点! 每天学习较为零散。 day17 一、Ubuntu apt命令和dpkg命令 二进制命令配置文件数据文件,打包好的单个文件 Windows :.exe macos:.dmg 后缀适用系统安装方式.d…...

vm+ubuntu24.04扩展磁盘
vmubuntu24.04扩展磁盘 $ lsblk $ sudo fdisk -l 1.修复 GPT 表警告 $ sudo parted /dev/sda print当询问是否修复时,输入 Fix2.扩展物理分区 /dev/sda3 $ sudo growpart /dev/sda 33.刷新物理卷 (PV) $ sudo pvresize /dev/sda3检查可用的扩展空间. $ sudo vgd…...

Python爬虫-爬取各省份各年份高考分数线数据,进行数据分析
前言 本文是该专栏的第60篇,后面会持续分享python爬虫干货知识,记得关注。 本文,笔者将基于Python爬虫,爬取各省份历年以来的“各年份高考分数线”进行数据分析。 废话不多说,具体实现思路和详细逻辑,笔者将在正文结合完整代码进行详细介绍。接下来,跟着笔者直接往下看…...
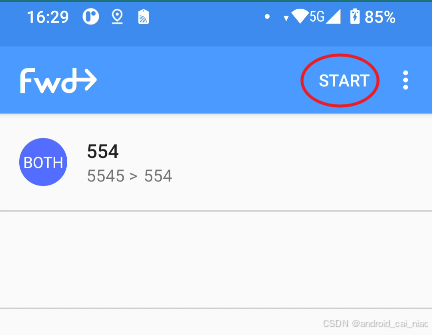
Android端口转发
如上图所示,有一个Android设备,Android设备里面有主板,主板上有网络接口和Wi-Fi,网络接口通过网线连接了一个网络摄像头,这就跟电脑一样,电脑即可以通过网线接入一个网络,也可以同时用Wi-Fi接入…...

C语言 | C代码编写中的易错点总结
C语言易错点 **1. 指针与内存管理****2. 数组与字符串****3. 未初始化变量****4. 类型转换与溢出****5. 运算符优先级****6. 函数与参数传递****7. 宏定义陷阱****8. 结构体与内存对齐****9. 输入/输出函数****10. 其他常见问题****最佳实践**在C语言编程中,由于其底层特性和灵…...

PHP环境极速搭建
一、为什么选择phpStudy VS Code? 作为一名初次接触PHP的开发者,我深知环境配置往往是学习路上的第一道门槛。传统PHP环境搭建需要手动配置Apache/Nginx、PHP解释器、MySQL等多重组件,光是处理版本兼容性和依赖问题就可能耗费半天时间——这…...
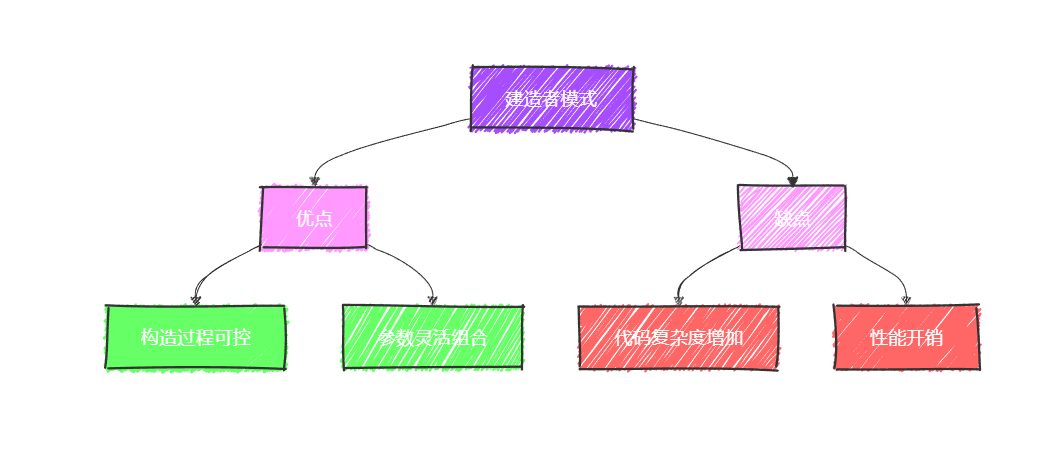
建造者模式深度解析与实战应用
作者简介 我是摘星,一名全栈开发者,专注 Java后端开发、AI工程化 与 云计算架构 领域,擅长Python技术栈。热衷于探索前沿技术,包括大模型应用、云原生解决方案及自动化工具开发。日常深耕技术实践,乐于分享实战经验与…...
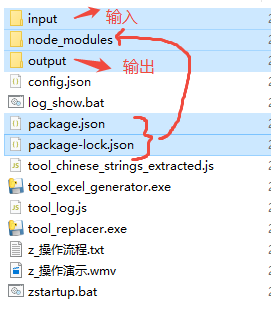
代码中文抽取工具并替换工具(以ts为例)
文章目录 基本思路目录结构配置文件AST解析替换代码中文生成Excel启动脚本 基本思路 通过对应语言的AST解析出中文相关信息(文件、所在行列等)存到临时文件通过相关信息,逐个文件位置替换掉中文基于临时文件,通过py脚本生成Excel…...
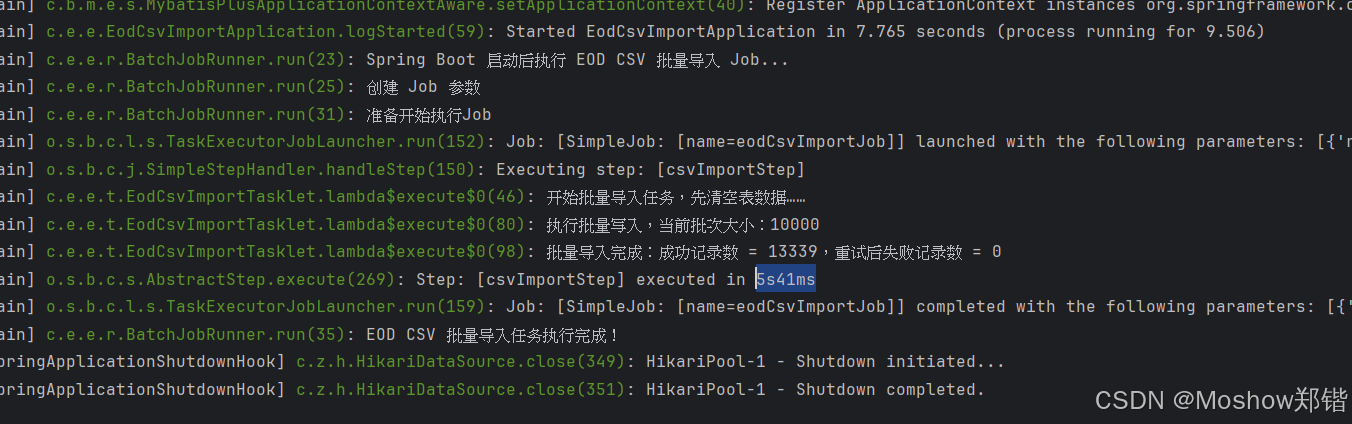
pgsql batch insert optimization (reWriteBatchedInserts )
reWriteBatchedInserts 是 PostgreSQL JDBC 驱动 提供的一个优化选项,它可以 重写批量插入语句,从而提高插入性能。 作用 当 reWriteBatchedInsertstrue 时,PostgreSQL JDBC 驱动会将 多个单独的 INSERT 语句 转换为 一个多行 INSERT 语句&a…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(上)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...
华为云Flexus+DeepSeek征文 | 基于DeepSeek-V3构建企业知识库问答机器人实战
作者简介 我是摘星,一名专注于云计算和AI技术的开发者。本次通过华为云MaaS平台体验DeepSeek系列模型,将实际使用经验分享给大家,希望能帮助开发者快速掌握华为云AI服务的核心能力。 目录 作者简介 1. 引言 2. 技术选型与架构设计 2.1 技…...
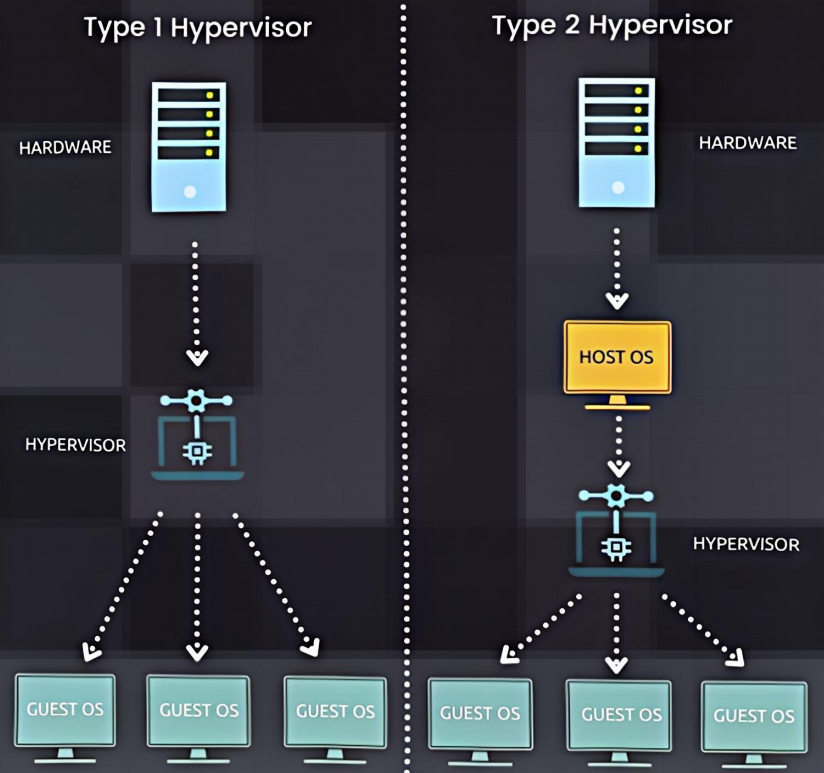
【Docker 01】Docker 简介
🌈 一、虚拟化、容器化 ⭐ 1. 什么是虚拟化、容器化 物理机:真实存在的服务器 / 计算机,对于虚拟机来说,物理机为虚拟机提供了硬件环境。虚拟化:通过虚拟化技术将一台计算机虚拟为 1 ~ n 台逻辑计算机。在一台计算机…...
)
信息最大化(Information Maximization)
信息最大化在目标域无标签的域自适应任务中,它迫使模型在没有真实标签的情况下,对未标记数据产生高置信度且类别均衡的预测。此外,这些预测也可以作为伪标签用于自训练。 例如,在目标域没有标签时,信息最大化损失可以…...

整数的字典序怎么算
在Python中,字典序(lexicographical order)通常指的是按照字符串的字典顺序进行比较或排序。对于整数来说,字典序可以理解为将整数转换为字符串后进行比较的顺序。 计算整数的字典序 要计算整数的字典序,可以按照以下…...

知识拓展卡————————关于Access、Trunk、Hybrid端口
目录 什么是Trunk List、VLAN ID、PVID: VLAN ID(Virtual Local Area Network Identifier): Trunk List(Trunk列表): PVID(Prot VLAN ID): 关于Native VLAN &#x…...
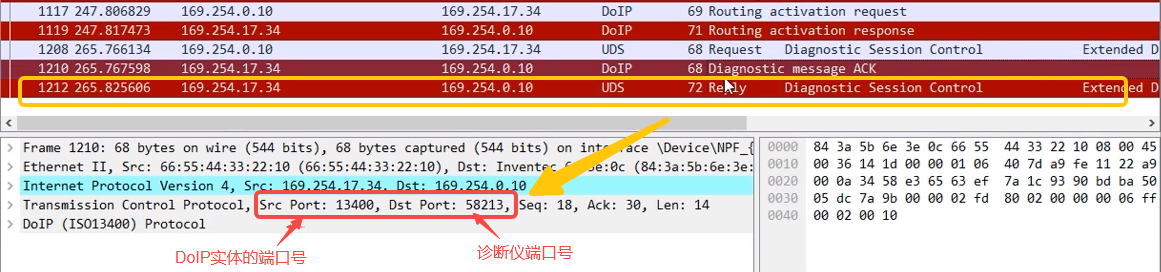
AUTOSAR实战教程--DoIP_02_诊断链路建立流程
第一步:DoIP实体车辆声明/诊断仪车辆识别请求 打开激活线以后,DoIP实体发的三帧车辆声明报文。其中包含了DoIP实体的诊断逻辑地址(可以类比DoCAN的物理请求/响应地址),对应车辆的VIN码(若已配置࿰…...
音频剪辑软件少之又少好用
我们平时见到的图片以及视频编辑工具非常多,但是音频剪辑软件却是少之又少,更不用说有没有好用的,今天,给大家带来一款非常专业的音频剪辑软件,而且是会员喔。 软件简介 一款手机号登录即可以享受会员的超专业音频剪…...
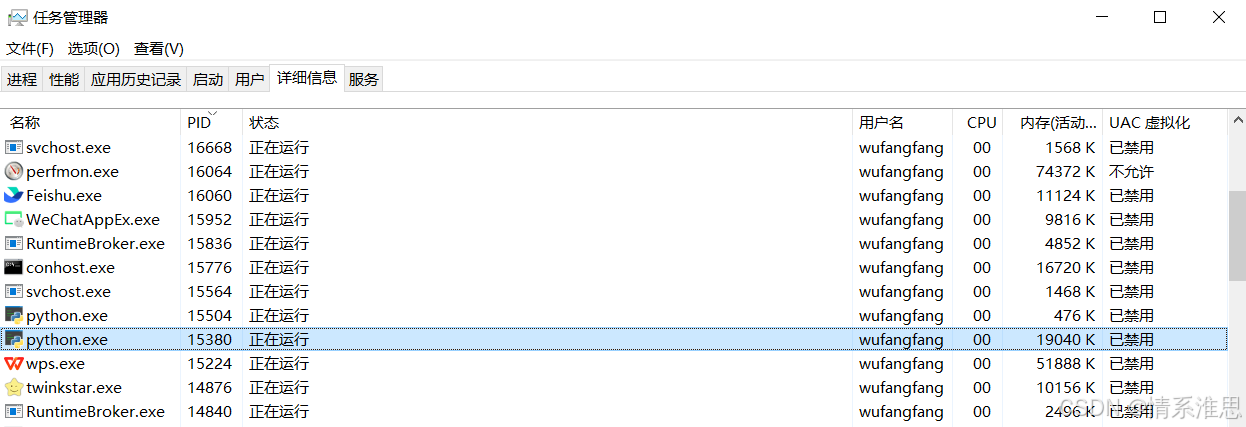
客户端和服务器已成功建立 TCP 连接【输出解析】
文章目录 图片**1. 连接状态解析****第一条记录(服务器监听)****第二条记录(客户端 → 服务器)****第三条记录(服务器 → 客户端)** **2. 关键概念澄清****(1) 0.0.0.0 的含义****(2) 端口号的分配规则** *…...

多标签多分类 用什么函数激活
在多标签多分类任务中,激活函数的选择需要根据任务特性和输出层的设计来决定。以下是常见的激活函数及其适用场景: 一、多标签分类任务的特点 每个样本可以属于多个类别(标签之间非互斥,例如一篇文章可能同时属于 “科技” 和 “…...

day26-计算机网络-4
1. tcp的11种状态 ss -ant -a 表示看所有状态 -n 表示不将ip解析为主机名 -t 表示tcp 1.1. closed状态(客户端、服务端) 客户端发起建立连接前的状态服务端启动服务前的状态 1.2. listen状态(服务端) 服务端软件运行的时候状…...

ngx_stream_geo_module在传输层实现高性能 IP Region 路由
一、模块定位与核心价值 层次:工作在 Stream (TCP/UDP) 层,和 ngx_http_geo_module 的 L7 语义互补。作用:基于客户端 IP 前缀 / 范围生成一个 Nginx 变量,可在后续 proxy_pass、map、limit_conn、access 等指令中使用࿰…...
国防科技大学计算机基础慕课课堂学习笔记
1.信息论 香农作为信息论的这个创始人,给出来了这个信息熵的计算方法,为我们现在的这个生活的很多领域奠定了基础,我第一次听说这个信息熵是在这个数学建模里面的理论学习中有关于这个:决策树的模型,在那个问题里面&a…...
【第七篇】 SpringBoot项目的热部署
简介 本文介绍了热部署(Hot Deployment)的概念、使用场景及在IDEA中的配置方法。热部署可在不重启应用的情况下动态更新代码,提升开发效率,适用于调试、微服务架构和自动化测试等场景。文章详细说明了热部署的实现步骤(…...
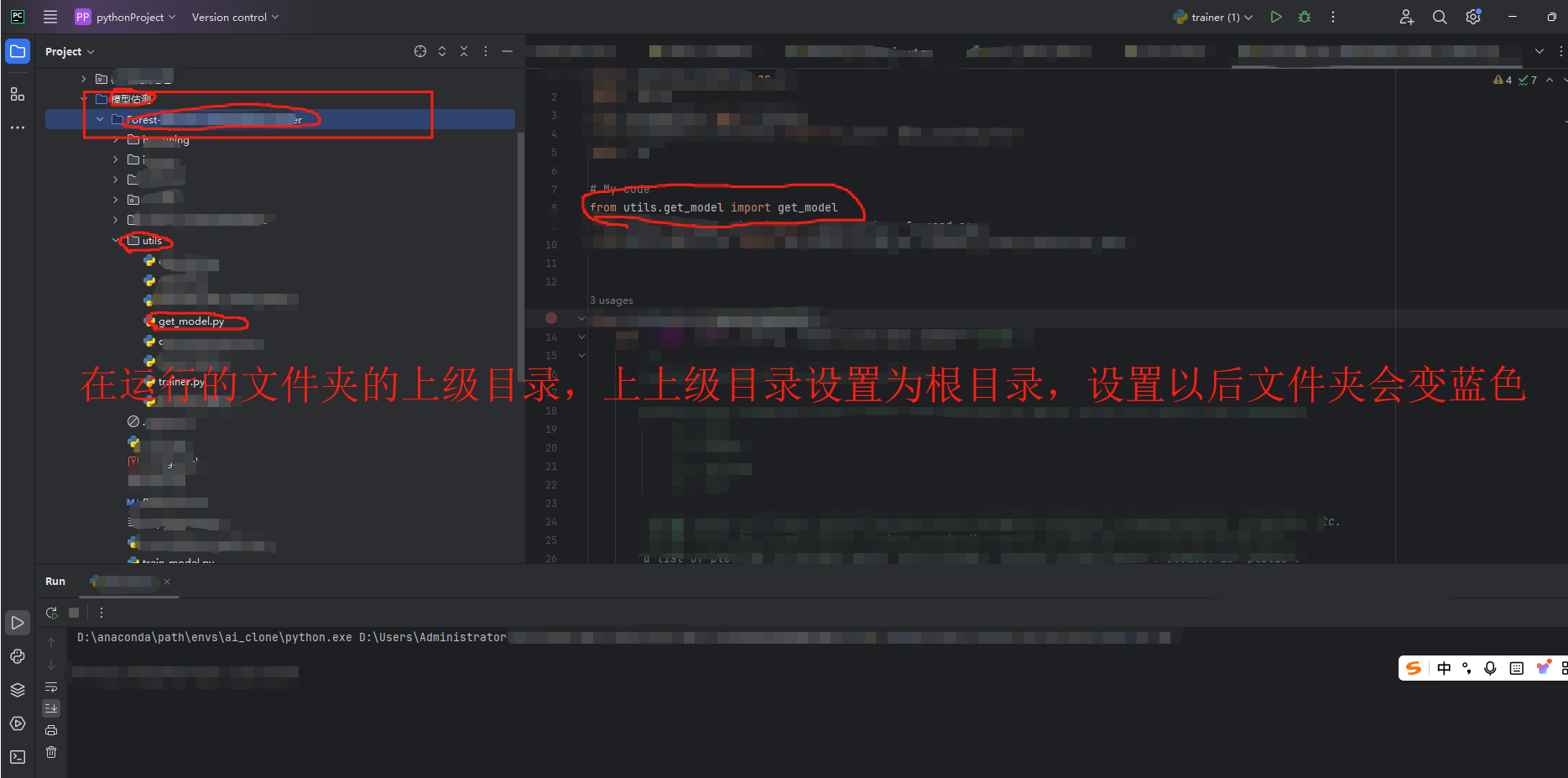
解决pycharm同一个文件夹下from *** import***仍显示No module named
1、,from ***import *,同文件夹中已有.py文件但是仍然报错No module named 原因是因为pycharm没有把文件夹设置为根目录,只需要在文件夹的上一级设置为根目录即可,测试过如果仅仅将当前的文件夹设置仍然报错,如果把最上…...
)
GO 基础语法和数据类型面试题及参考答案(上)
目录 Go 中变量定义方式有哪些?各有什么适用场景? 使用 : 定义变量的限制是什么? 全局变量可以使用 : 声明吗?为什么? Go 中如何声明一个多变量赋值?有哪些注意事项? 常量能否通过表达式赋值…...

使用 Redisson 实现分布式锁—解决方案详解
Redisson 是 Redis 官方推荐的 Java 客户端,提供了一系列分布式服务实现,其中分布式锁是其核心功能之一。本文将深入解析 Redisson 分布式锁的实现原理、高级特性和最佳实践。 一、Redisson 分布式锁的优势 与传统实现的对比 特性手动实现Redisson 实现…...