【大模型】【推荐系统】LLM在推荐系统中的应用价值
文章目录
- A 论文出处
- B 背景
- B.1 背景介绍
- B.2 问题提出
- B.3 创新点
- B.4 两大推荐方法
- C 模型结构
- C.1 知识蒸馏(训练过程)
- C.2 轻量推理(部署过程)
- D 实验设计
- E 个人总结
A 论文出处
- 论文题目:SLMRec:Distilling Large Language Models into Small for Sequential Recommendation
- 发表情况:2025-ICLR
- 作者单位:蚂蚁集团、国外大学及研究院
B 背景
B.1 背景介绍
序列推荐任务旨在通过用户过往的交互数据,来预测用户可能与之互动的下一个行为,因此这类模型通过建模分析用户的行动序列,揭示更复杂的行为模式和时间动态。近期研究表明,将大语言模型引入推荐系统逐渐成为研究热门,无论是将序列推荐视为语言模型的语义建模,还是作为用户表征的一种方法,都使大语言模型对序列推荐任务产生了深远影响。但是,由于大模型的庞大,在现实生活中大部分平台上应用大模型显得低效且不切实际,如何平衡好大模型的规模和推荐系统的海量数据,成为了能否用大模型进行序列推荐的关键问题。
B.2 问题提出
(1)尽管大模型在预训练阶段并没有显式地对商品ID的语义进行学习,现阶段大模型的杰出表现来源于预训练知识的迁移能力?还是注意力机制的固有建模优势?
(2)现有大模型的参数量较大,如此巨大的模型是否适配海量数据场景的推荐任务?模型是否有进一步裁剪的可能性?
B.3 创新点
(1)论文重新评估大语言模型(LLM)在序列推荐中的必要性,并在大规模行业数据集上进行了一系列实验,研究了减少训练和推理阶段参数数量对整体性能的影响。通过实证结果,论文发现模型参数的增加并不总是带来一致的改进。
(2)基于论文实证研究的结果,论文提出了一种名为SLMREC的小语言模型,用于序列推荐,并通过采用了标准的知识蒸馏方法来对齐表示知识。此外,论文还设计了多种监督信号,以引导学生模型在其隐藏表示中获取任务感知的知识。
B.4 两大推荐方法
下面简要介绍一下传统的序列推荐方法和基于大模型的推荐方法的主要步骤
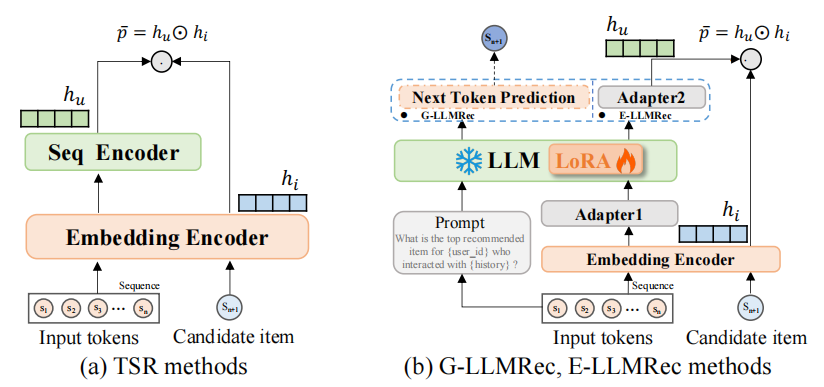
(1)传统序列推荐(TSR)
- 输入:用户历史交互的物品序列(如 [ i t e m 1 , i t e m 2 , . . . , i t e m t ] [item₁, item₂, ..., itemₜ] [item1,item2,...,itemt])。
- 流程:
- 嵌入编码(Embedding Encoder):
将每个物品ID转换为低维向量表示(Embedding)。 - 序列编码(Seq Encoder):
使用RNN/Transformer等模型,将物品序列编码为用户表征向量 h u h_u hu。 - 候选物品编码:
目标物品 i i i 通过独立Embedding层生成物品表征向量 h i h_i hi。 - 预测交互概率:
计算用户与物品的匹配度: p = h u ⊙ h i p = h_u ⊙ h_i p=hu⊙hi( ⊙ ⊙ ⊙ 表示内积或神经网络交互函数)。
- 嵌入编码(Embedding Encoder):
- 目标:直接预测用户对候选物品的偏好概率。
(2)基于大模型的推荐:G-LLMRec(生成式推荐)
- 输入:
自然语言提示(Prompt),例如:
“What is the top recommended item for user_123 who interacted with [itemA, itemB, …]?” - 流程:
- 文本化序列编码:
用户历史序列被转换为文本描述(如物品标题)。 - 大语言模型(LLM)推理:
将提示输入LLM(如GPT),直接生成推荐物品的文本标识(如物品名称或ID)。 - 适配器(Adapter1):
可选模块,用于对齐LLM表征与推荐任务(微调时引入)。
- 文本化序列编码:
- 特点:端到端生成式推荐,依赖LLM的推理能力直接输出结果。
(3)基于大模型的推荐:E-LLMRec(表征增强推荐)
- 输入:用户历史物品序列(ID或文本)。
- 流程:
- 文本嵌入编码:
物品ID/文本通过LLM的Embedding Encoder生成向量(如LLM的词嵌入层)。 - 序列编码(LLM适配):
使用Adapter2调整LLM输出,生成用户表征 h u h_u hu(保留序列结构信息)。 - 候选物品编码:
目标物品通过相同LLM Embedding层生成 h i h_i hi。 - 预测交互概率:
传统交互函数计算匹配度: p = h u ⊙ h i p = h_u ⊙ h_i p=hu⊙hi。
- 文本嵌入编码:
- 特点:利用LLM增强表征,但保留传统推荐器的交互预测层。
C 模型结构
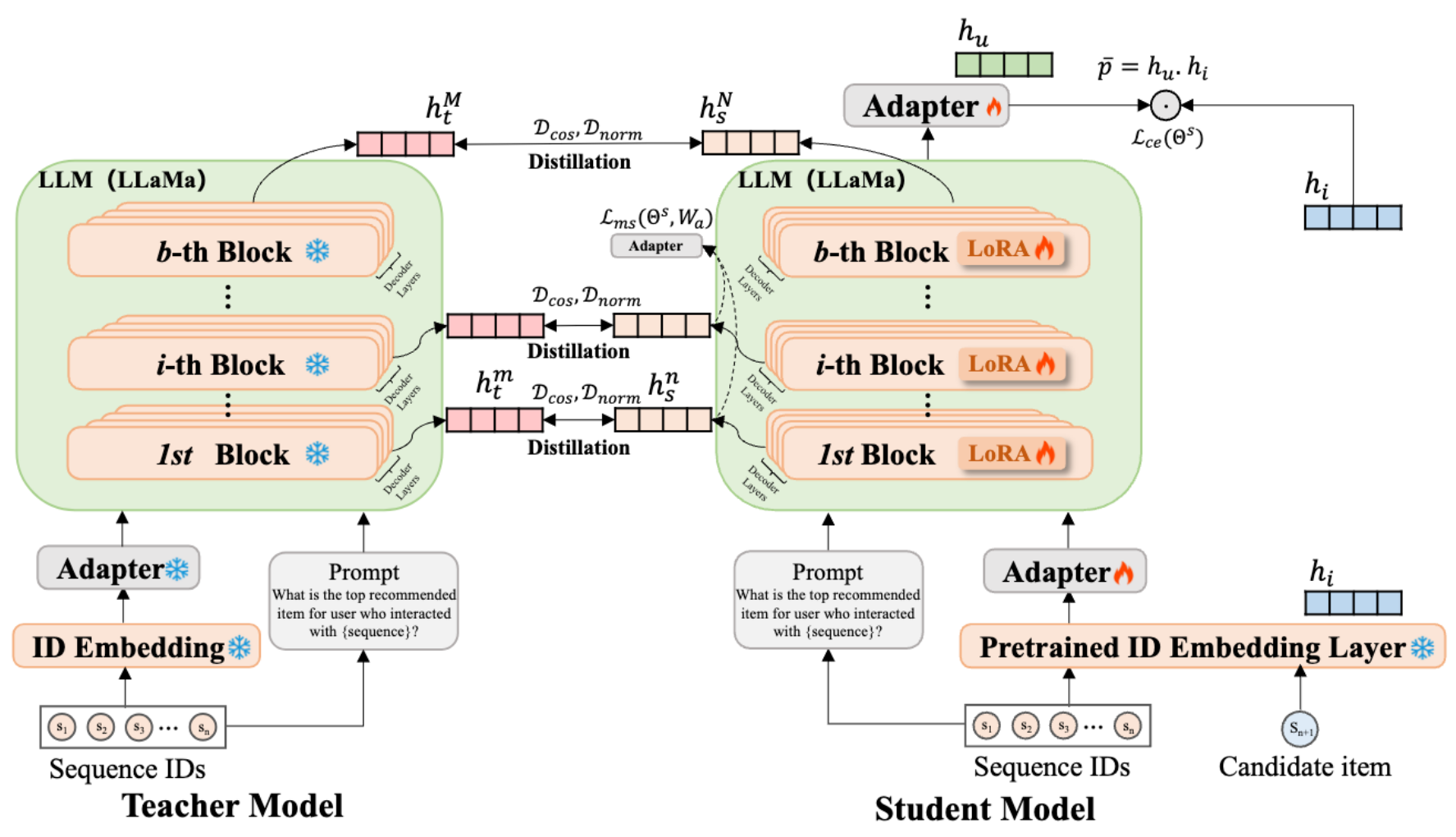
C.1 知识蒸馏(训练过程)
(1)教师模型生成软标签:
- 输入用户历史序列的物品ID,以及自定义的prompt模板。
- LLaMA输出推荐物品的概率分布(软标签),蕴含LLM的语义推理知识。
(2)学生模型学习语义对齐:
- 输入同一用户的物品ID序列,经ID嵌入层和Adapter编码为向量。
- 输出学生预测概率分布。
(3)多层次+多监督信号的知识蒸馏:
- 预测层蒸馏:为了调节教师模型与学生模型之间特征方向的对齐,采用基于余弦相似度的损失项,具体描述公式如下:
D cos ( Θ t , Θ s ) = 1 B ∑ k = 1 B h t ( k m ) ⋅ h s ( k n ) ∥ h t ( k m ) ∥ 2 ⋅ ∥ h s ( k n ) ∥ 2 \mathcal{D}_{\cos}(\Theta_t,\Theta_s)=\frac{1}{B}\sum_{k=1}^B\frac{\mathbf{h}_t^{(km)}\cdot\mathbf{h}_s^{(kn)}}{\|\mathbf{h}_t^{(km)}\|_2\cdot\|\mathbf{h}_s^{(kn)}\|_2} Dcos(Θt,Θs)=B1k=1∑B∥ht(km)∥2⋅∥hs(kn)∥2ht(km)⋅hs(kn)
同时也引入了一个简单的正则化项,旨在最小化教师模型与学生模型的隐藏表示之间的L2距离,该正则化项在数学上表述如下:
D norm ( Θ t , Θ s ) = 1 B ∑ k = 1 B ∥ h t ( k m ) − h s ( k n ) ∥ 2 2 \mathcal{D}_{\text{norm}}(\Theta_t,\Theta_s)=\frac{1}{B}\sum_{k=1}^B\|\mathbf{h}_t^{(km)}-\mathbf{h}_s^{(kn)}\|_2^2 Dnorm(Θt,Θs)=B1k=1∑B∥ht(km)−hs(kn)∥22
- 中间层蒸馏:采用了多种监督策略来引导学生模型吸收推荐相关知识的特定方面,具体描述公式如下:
L m s ( Θ s , W a ) = 1 B − 1 ∑ k = 1 B − 1 L c e ( y , p ^ t ( k m ) ) \mathcal{L}_{ms}(\Theta_{s}, W_{a}) = \frac{1}{B-1} \sum_{k=1}^{B-1} \mathcal{L}_{ce}(y, \hat{p}^{(km)}_{t}) Lms(Θs,Wa)=B−11k=1∑B−1Lce(y,p^t(km)) - 联合训练:综合上述蒸馏损失,用于训练学生模型的复合目标函数可表示为:
L t o t a l = L c e ( Θ s ) + λ 1 D cos ( Θ t , Θ s ) + λ 2 D n o r m ( Θ t , Θ s ) + λ 3 L m s ( Θ s , W a ) \mathcal{L}_{total} = \mathcal{L}_{ce}(\Theta_s) + \lambda_1 \mathcal{D}_{\cos}(\Theta_t, \Theta_s) + \lambda_2 \mathcal{D}_{norm}(\Theta_t, \Theta_s) + \lambda_3 \mathcal{L}_{ms}(\Theta_s, W_a) Ltotal=Lce(Θs)+λ1Dcos(Θt,Θs)+λ2Dnorm(Θt,Θs)+λ3Lms(Θs,Wa)
C.2 轻量推理(部署过程)
(1)学生模型独立接收物品ID序列,经Adapter增强的编码器生成用户表征。
(2)计算用户表征与候选物品向量的内积( p = h u ⊙ h i p = h_u ⊙ h_i p=hu⊙hi),输出推荐得分。
(3)部署优势:学生模型仅保留轻量Adapter和ID嵌入层,参数量显著低于LLM。
D 实验设计
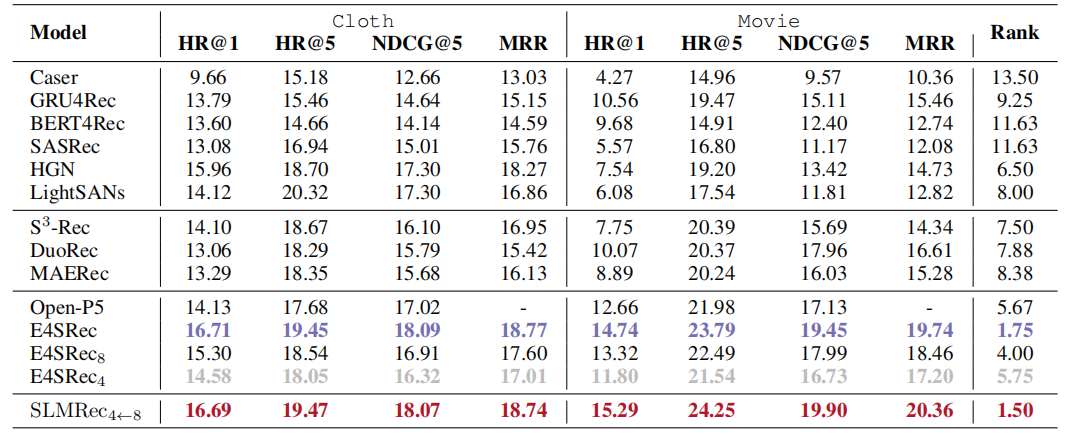
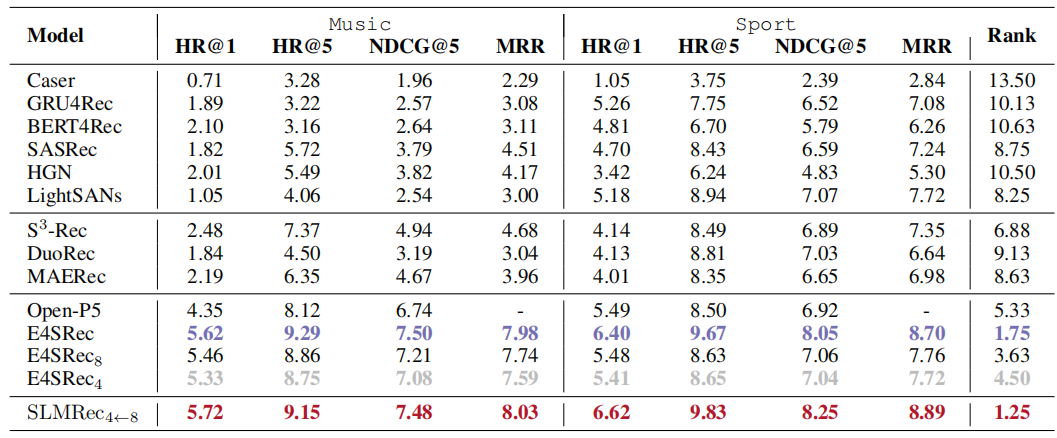
论文提出的SLMRec框架在多个基准数据集上实现突破:在训练效率上,相比原始LLMRec,训练速度提升6.6倍(NVIDIA A100);在推理性能上,服务响应速度提升8.0倍;在模型压缩上,参数量减少87%的同时,在Amazon数据集上略有提升。具体实验结果如下所示:

E 个人总结
(1)本文证明了大模型在推荐系统中的应用价值,同时通过知识蒸馏的方式找到了用大模型进行推荐的新角度,这种对大模型进行多监督信号的蒸馏学习值得学习。
(2)学生模型目前无法通过少量样本学习来适应新场景,当面对新的数据集或平台上的新流量日志时,模型需要从整个数据集中重新训练。未来可以将增量学习技术整合到基于LLM的推荐系统中,以增强模型的迁移能力。
相关文章:
【大模型】【推荐系统】LLM在推荐系统中的应用价值
文章目录 A 论文出处B 背景B.1 背景介绍B.2 问题提出B.3 创新点B.4 两大推荐方法 C 模型结构C.1 知识蒸馏(训练过程)C.2 轻量推理(部署过程) D 实验设计E 个人总结 A 论文出处 论文题目:SLMRec:Distilling…...

uni-app学习笔记二十九--数据缓存
uni.setStorageSync(KEY,DATA) 将 data 存储在本地缓存中指定的 key 中,如果有多个key相同,下面的会覆盖掉原上面的该 key 对应的内容,这是一个同步接口。数据可以是字符串,可以是数组。 <script setup>uni.setStorageSyn…...

csharp基础....
int[][] jaggedArray new int[3][]; jaggedArray[0] new int[] { 1, 2 }; jaggedArray[1] new int[] { 3, 4, 5 }; jaggedArray[2] new int[] { 6, 7, 8, 9 }; 嵌套 反转和排序 List<int> list new List<int> { 1, 2, 3, 4, 5 }; list.Reverse(); Cons…...

【C/C++】EBO空基类优化介绍
空对象优化(Empty Base Optimization,简称 EBO)是 C 编译器的一种 优化技术,用于消除空类作为基类时占用的内存空间,从而避免浪费空间、提升结构体或类的存储效率。 1 什么是“空对象”? 一个**空类&#…...

工作邮箱收到钓鱼邮件,点了链接进去无法访问,会有什么问题吗?
没事的,很可能是被安全网关拦截了。最近做勒索实验,有感而发,不要乱点击邮箱中的附件。 最初我们采用钓鱼邮件投递恶意载荷,发现邮件网关把我们的 exe/bat 程序直接拦截了,换成压缩包也一样拦截了,载荷始终…...
基于安卓的线上考试APP源码数据库文档
摘 要 21世纪的今天,随着社会的不断发展与进步,人们对于信息科学化的认识,已由低层次向高层次发展,由原来的感性认识向理性认识提高,管理工作的重要性已逐渐被人们所认识,科学化的管理,使信息存…...

【数据结构】顺序表和链表详解(下)
前言:上期我们从顺序表开始讲到了单链表的概念,分类,和实现,而这期我们来将相较于单链表没那么常用的双向链表。 文章目录 一、双向链表二,双向链表的实现一,增1,头插2,尾插3&#x…...

【系统架构设计师】绪论-系统架构概述
目录 绪论 系统架构概述 单选题 绪论 系统架构概述 单选题 1、软件方法学是以软件开发方法为研究对象的学科。其中,()是先对最高居次中的问题进行定义、设计、编程和测试,而将其中未解决的问题作为一个子任务放到下一层次中去…...

SQL-事务(2025.6.6-2025.6.7学习篇)
1、简介 事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 默认MySQL的事务是自动提交的,也就是说࿰…...

OpenCV 图像通道的分离与合并
一、知识点 1、一张彩色图像可以由R、G、B三个通道的灰度图合并而成。 2、void split(InputArray m, OutputArrayOfArrays mv); (1)、将多通道阵列划分为几个单通道阵列。 (2)、参数说明: m: 要分离的多通道阵列。 mv: 输出的vector容器,每个元素都…...
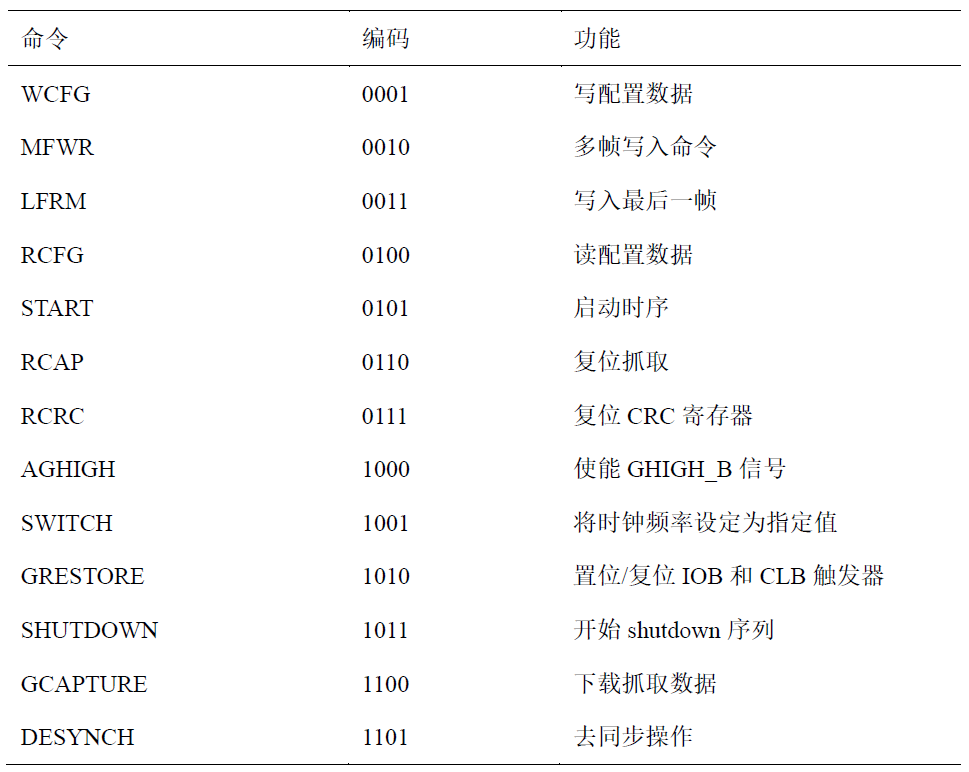
Virtex II 系列FPGA的配置原理
对FPGA 芯片的配置,本质上是将根据设计生成的包含配置命令和配置数据的比特流文件写入到配置存储器中。 1 配置模式 Virtex II 系列FPGA 一共有五种配置模式,配置模式的选择是根据管脚M[2:0]来决定。 (1)串行配置模式 串行配置模…...
蓝桥杯 国赛2024python(b组)题目(1-3)
第一题 试卷答题页 - 蓝桥云课 问题描述 在今年蓝桥杯的决赛中,一共有 1010 道题目,每道题目的分数依次为 55 分,55 分,1010 分,1010 分,1515 分,1515 分,2020 分,2020 分…...

低代码平台前端页面表格字段绑定与后端数据传输交互主要有哪些方式?华为云Astro在这方面有哪些方式?
目录 🔧 一、低代码平台中常见的数据绑定与交互方式 1. 接口绑定(API 调用) 2. 数据源绑定(DataSource) 3. 变量中转(临时变量 / 页面状态) 4. 数据模型绑定(模型驱动) 🌐 二、华为云 Astro 轻应用的实现方式 ✅ 1. 数据源绑定(API服务+API网关) ✅ 2. 变…...

stm32——UART和USART
串口通信协议UART和USART 1. UART与USART协议详解 特性UART (Universal Asynchronous Receiver/Transmitter)USART (Universal Synchronous Asynchronous Receiver/Transmitter)全称通用异步收发器通用同步/异步收发器同步/异步异步:不共享时钟,数据通过…...
算法题(165):汉诺塔问题
审题: 本题需要我们找到最优的汉诺塔搬法然后将移动路径输出 思路: 方法一:递归 我们先分析题目 n为2的情况,我们先将第一个盘子移动到三号柱子上,然后再将二号盘子移动到二号柱子上 n为3的情况,我们先将前…...

玄机——某次行业攻防应急响应(带镜像)
今天给大家带来一次攻防实战演练复现的过程。 文章目录 简介靶机简介1.根据流量包分析首个进行扫描攻击的IP是2.根据流量包分析第二个扫描攻击的IP和漏扫工具,以flag{x.x.x.x&工具名}3.提交频繁爆破密钥的IP及爆破次数,以flag{ip&次数}提交4. 提…...
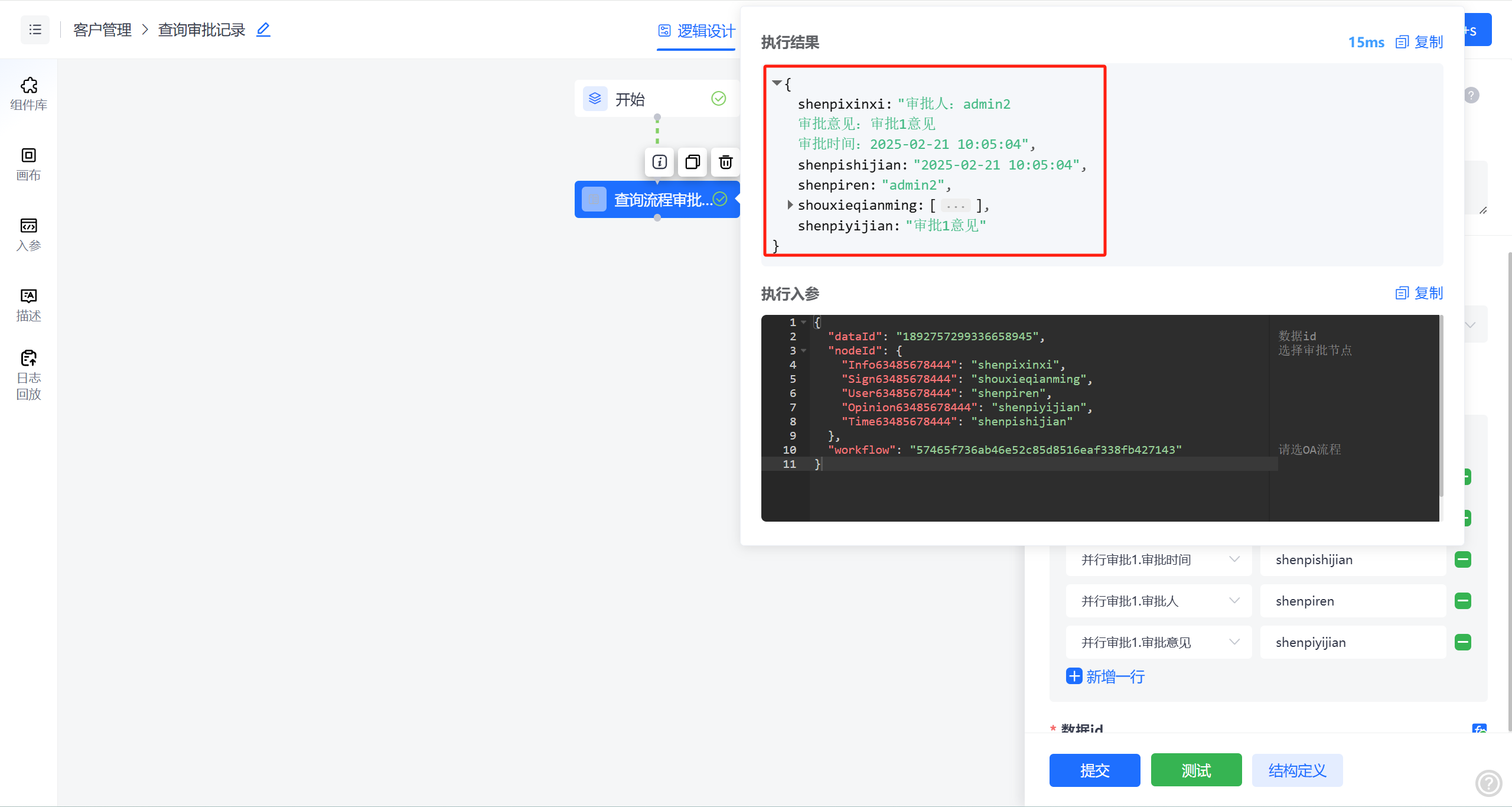
低代码逻辑引擎配置化实战:三步穿透审批记录查询
在堆积如山的报销单中埋头寻找某笔特殊费用的审批轨迹在跨部门协作时被追问"这个合同到底卡在哪个环节" 在快节奏的办公自动化场景中,这些场景是很常见的,传统OA系统中分散的审批记录查询方式往往太繁琐。 为破解这一痛点,在JVS低…...

深入理解React Hooks的原理与实践
深入理解React Hooks的原理与实践 引言 React Hooks 自 2018 年 React 16.8 发布以来,彻底改变了前端开发者的编码方式。它通过函数式组件提供了状态管理和生命周期等功能,取代了传统的类组件,使得代码更加简洁、复用性更强。然而ÿ…...

WEB3技术重要吗,还是可有可无?
我从几个角度给你一个全面、理性、技术导向的回答: ✅ 一、Web3 技术的重要性:“有意义,但不是万能” Web3 技术并不是可有可无的噱头,而是一种在特定场景下提供独特价值的技术体系。 它重要的原因包括: 1. 重构数字…...

Python 隐藏法宝:双下划线 _ _Dunder_ _
你可能不知道,Python里那些用双下划线包裹的"魔法方法"(Dunder方法),其实是提升代码质量的绝佳工具。但有趣的是,很多经验丰富的开发者对这些方法也只是一知半解。 先说句公道话: 这其实情有可原。因为在多数情况下&am…...

《视觉SLAM十四讲》自用笔记 第三讲:三维空间刚体运动
第三讲 三维空间刚体运动 3.0 目标 1.理解三维空间的刚体运动描述方式:旋转矩阵、变换矩阵、四元数和欧拉角。 2.掌握 Eigen 库的矩阵、几何模块使用方法。 3.1 旋转矩阵 3.1.1 点和向量,坐标系 三维空间中,刚体的运动可以用两个概念来…...

【Zephyr 系列 15】构建企业级 BLE 模块通用框架:驱动 + 事件 + 状态机 + 低功耗全栈设计
🧠关键词:Zephyr、BLE 模块、架构设计、驱动封装、事件机制、状态机、低功耗、可维护框架 📌面向读者:希望将 BLE 项目从“Demo 工程”升级为“企业可复用框架”的研发人员与技术负责人 📊预计字数:5500+ 字 🧭 前言:从 Demo 到产品化,架构该如何升级? 多数 BLE…...
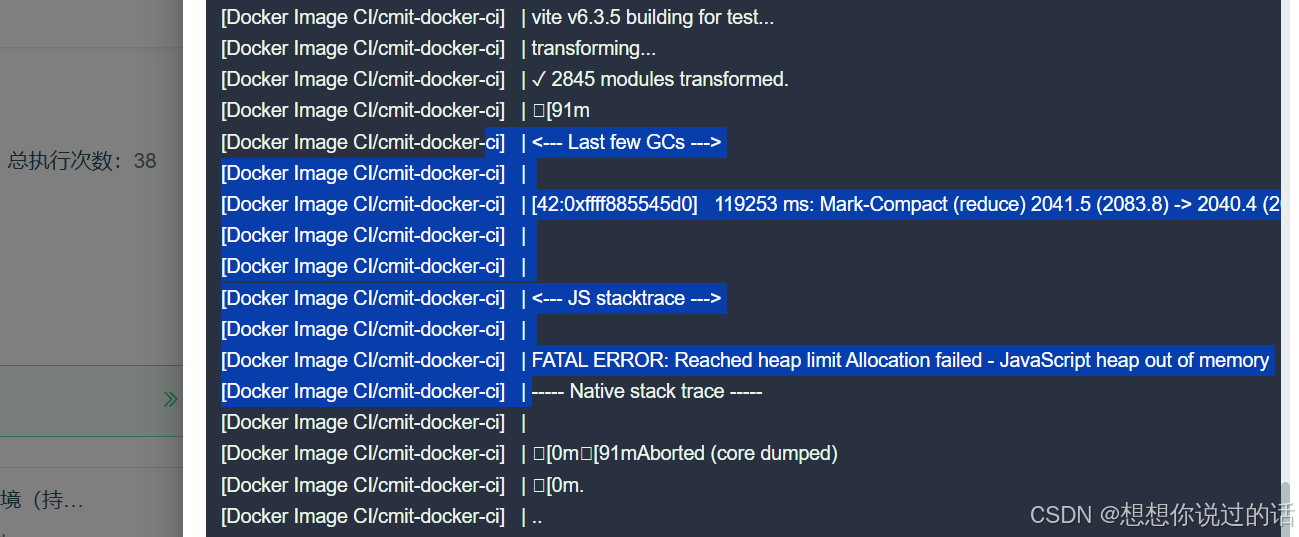
Docker构建Vite项目内存溢出:从Heap Limit报错到完美解决的剖析
问题现象:诡异的"消失的index.html" 最近在CI/CD流水线中遇到诡异现象:使用Docker构建Vite项目时,dist目录中缺少关键的index.html文件,但本地构建完全正常。报错截图显示关键信息: FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out…...
)
Linux运维新人自用笔记(乌班图apt命令和dpkg命令、两系统指令区别,rpm解决路径依赖、免安装配置java环境)
内容全为个人理解和自查资料梳理,欢迎各位大神指点! 每天学习较为零散。 day17 一、Ubuntu apt命令和dpkg命令 二进制命令配置文件数据文件,打包好的单个文件 Windows :.exe macos:.dmg 后缀适用系统安装方式.d…...

vm+ubuntu24.04扩展磁盘
vmubuntu24.04扩展磁盘 $ lsblk $ sudo fdisk -l 1.修复 GPT 表警告 $ sudo parted /dev/sda print当询问是否修复时,输入 Fix2.扩展物理分区 /dev/sda3 $ sudo growpart /dev/sda 33.刷新物理卷 (PV) $ sudo pvresize /dev/sda3检查可用的扩展空间. $ sudo vgd…...

Python爬虫-爬取各省份各年份高考分数线数据,进行数据分析
前言 本文是该专栏的第60篇,后面会持续分享python爬虫干货知识,记得关注。 本文,笔者将基于Python爬虫,爬取各省份历年以来的“各年份高考分数线”进行数据分析。 废话不多说,具体实现思路和详细逻辑,笔者将在正文结合完整代码进行详细介绍。接下来,跟着笔者直接往下看…...
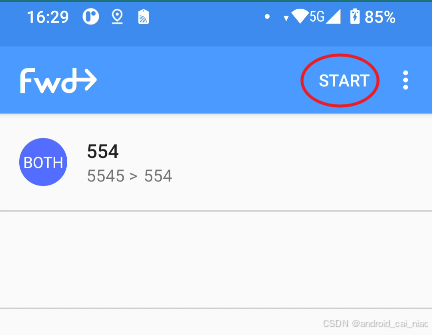
Android端口转发
如上图所示,有一个Android设备,Android设备里面有主板,主板上有网络接口和Wi-Fi,网络接口通过网线连接了一个网络摄像头,这就跟电脑一样,电脑即可以通过网线接入一个网络,也可以同时用Wi-Fi接入…...

C语言 | C代码编写中的易错点总结
C语言易错点 **1. 指针与内存管理****2. 数组与字符串****3. 未初始化变量****4. 类型转换与溢出****5. 运算符优先级****6. 函数与参数传递****7. 宏定义陷阱****8. 结构体与内存对齐****9. 输入/输出函数****10. 其他常见问题****最佳实践**在C语言编程中,由于其底层特性和灵…...

PHP环境极速搭建
一、为什么选择phpStudy VS Code? 作为一名初次接触PHP的开发者,我深知环境配置往往是学习路上的第一道门槛。传统PHP环境搭建需要手动配置Apache/Nginx、PHP解释器、MySQL等多重组件,光是处理版本兼容性和依赖问题就可能耗费半天时间——这…...
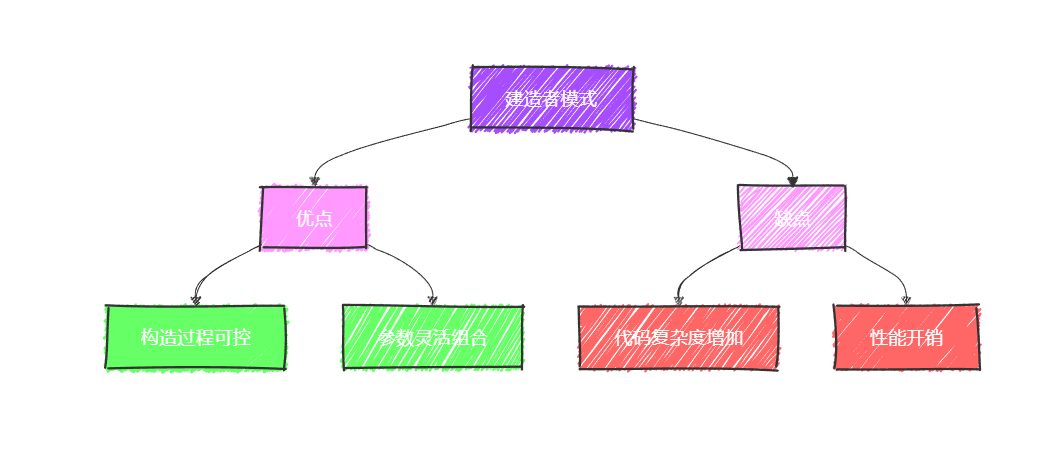
建造者模式深度解析与实战应用
作者简介 我是摘星,一名全栈开发者,专注 Java后端开发、AI工程化 与 云计算架构 领域,擅长Python技术栈。热衷于探索前沿技术,包括大模型应用、云原生解决方案及自动化工具开发。日常深耕技术实践,乐于分享实战经验与…...