【AIGC】RAGAS评估原理及实践
【AIGC】RAGAS评估原理及实践
- (1)准备评估数据集
- (2)开始评估
- 2.1 加载数据集
- 2.2 评估忠实性
- 2.3 评估答案相关性
- 2.4 上下文精度
- 2.5 上下文召回率
- 2.6 计算上下文实体召回率

RAGas(RAG Assessment)RAG 评估的缩写,是一个专门的解决方案用于评估、监控和提升生产环境中大语言模型(LLM)和检索增强生成(RAG)应用的性能,包括用于生产质量监控的定制模型。它除了评估,还能从数据集中生成测试集,这将极大地降低人力投入,毕竟一个良好的数据集构建是非常消耗时间和人力的。RAGas 从生成和检索两个维度评估 RAG 应用,如下图所示。

生成角度可以从忠实性 faithfulness 和回答相关性 answer relevancy 评估,而检索则从上下文精度(context precision)和上下文召回(context recall)上来测评。当然 ragas 不止这四种评测,还有答案准确性(answer correctness),上下文利用率(context utilization),上下文实体召回率(context entity recall)和噪声敏感度(noise sensitivity)等。后面会专门叙述常见的几种指标的计算。在开始评估之前,我们先安装 ragas。
pip install ragas
安装好之后,我们要如何评估 RAG 呢?拿什么评估?这就必须要说如何准备评估数据集。
(1)准备评估数据集
RAGas 需要的评估数据集格式如下:
data_samples = {'question': ['第一届超级碗是什么时候举行的?', '谁赢得了最多的超级碗冠军?'], 'answer': ['第一届超级碗于1967年1月15日举行', '赢得最多超级碗冠军的是新英格兰爱国者队'], 'contexts': [['第一届 AFL-NFL 世界冠军赛是一场美式橄榄球比赛,于1967年1月15日在洛杉矶纪念体育馆举行'], ['绿湾包装工队...位于威斯康星州绿湾市。', '包装工队参加...全国橄榄球联合会比赛']], 'ground_truth': ['第一届超级碗于1967年1月15日举行', '新英格兰爱国者队赢得了创纪录的六次超级碗冠军']
}
包含 4 个字段,分别是question、answer、contexts和ground_truth。每一项都是一个数组列表,要注意的是,答案、上下文和基本事实和问题列表是一一对应的,即第一个问题的答案也必须是 answer 中的第一个元素,同时也必须是上下文和基本事实的第一个元素。其中上下文的每个元素都是一组字符串数组,这是因为每个问题都可以有多个上下文。
如果你人力资源足够的话,我们可以手动构建这个数据集,假设你有问题列表和基本事实列表(这一个不是必须),回答就由你自己的 RAG 应用根据问题来填充,上下文也由你的 RAG 应用填充。
此外,我们也可以使用 ragas 根据数据集自动构建。因为要读入数据,这里需要先安装 langchain 或者 llamaindex 来支持数据的读入。
pip install langchain-community==0.2.17
pip install unstructured==0.15.13
然后使用如下代码,读入数据。
from langchain_community.document_loaders import DirectoryLoader loader = DirectoryLoader("~/Projects/graphrag/input")
documents = loader.load()
for document in documents: document.metadata['filename'] = document.metadata['source']
既然要生成数据集,当然需要大语言模型的支持了,也需要 embedding 模型支持,这里采用 DeepSeek 和智谱的在线模型 API。
from langchain_openai import ChatOpenAI, OpenAIEmbeddings generator_llm = ChatOpenAI(model="deepseek-chat", openai_api_base="https://api.deepseek.com/v1", openai_api_key="xxxx")
critic_llm = ChatOpenAI(model="deepseek-chat", openai_api_base="https://api.deepseek.com/v1", openai_api_key="xxxx")
embeddings = OpenAIEmbeddings(openai_api_base="https://open.bigmodel.cn/api/paas/v4", openai_api_key="xxxx", embedding_ctx_length=512, chunk_size=512, model="embedding-3")
注意必须配置这些选项,不然它默认就是访问 OpenAI 的模型。
然后就是使用 ragas 框架的 API 来生成测试集了,首先初始化测试集生成器。
generator = TestsetGenerator.from_langchain(generator_llm,critic_llm,embeddings)
然后调用 API generate_with_langchain_docs准备生成,参数为读取的 documents,生成的数据集条数 test_size 以及生成问题的分布,如简单的占比 0.5,推理的 0.25 以及多个上下文的 0.25。
testset: TestDataset = generator.generate_with_langchain_docs(documents,test_size=10,distributions={simple: 0.5, reasoning: 0.25, multi_context: 0.25})
然后我们将生成的数据集保存,以备后用。
ds = testset.to_dataset()
ds.save_to_disk("./activity_testset")
生成的数据大概如下所示。

ragas 在生成数据集上还可以配置问题的难易分布。理想的评估数据集应涵盖生产中遇到的各种类型的问题,包括不同难度级别的问题。大语言模型(LLMs)通常不擅长生成多样化的样本,因为它们倾向于遵循常见路径。ragas 受 Evol-Instruct[2] 等作品的启发,采用了一种进化生成范式,系统地从提供的文档集创建具有不同特征的问题,如推理、条件、多个上下文等。这种方法确保了对管道中各个组件性能的全面覆盖,从而实现更稳健的评估过程,原理如下图所示。

但我要说的是,ragas 在生成数据集非常不完善,很难生成,全靠运气,经常报 Connection 错误,而 API 明明可以连接。另外一点是所使用的 Prompt 都是英文,有几率生成一些英文问题,即使你的输入文档是中文的。虽然你可以通过 Prompt adapation 进行本地化,但 ragas 里对于 json 的处理非常简单,不会做任何解析增强,所以生成的东西也用不了,除非手工修改。
看了一些 ragas 代码,感觉写的不咋的,但他们的评估指标和思路是挺好的。生成测试集搞了我一周,魔改代码都没能解决一堆报错,搞得我一肚子火。今天发布了最新版本 v0.2.0,已经和上述代码不兼容了。还没空测评,不知道新版本是否有解决,希望给力点吧。
(2)开始评估
上节已经提到生成数据集功能缺陷太多,所以这里为了演示,我们使用官方 Demo 中的数据集。
2.1 加载数据集
from datasets import Dataset, load_dataset def load_amnesty_qa() -> Dataset: # loading the V2 dataset amnesty_qa = load_dataset("explodinggradients/amnesty_qa", "english_v2")print(amnesty_qa['eval'].column_names) # ['question', 'ground_truth', 'answer', 'contexts'] # amnesty_qa['eval']['contexts'] return amnesty_qa["eval"] dataset = load_amnesty_qa()
2.2 评估忠实性
计算 Faithfulness 就是计算忠实性。首先将答案分拆为几个声明(简单理解为句子也行),然后判断每个句子是否可以从上下文 contexts 中推断出来,如果出现过则认为是忠实的。比如将答案拆分为 3 个 claims,然后从 context 中判断有几个可以推断出来,假设为 2,那么忠实性就是 2/3。它需要回答和上下文。
from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall, context_entity_recall
from ragas import evaluate def metric_faithfulness(): score = evaluate(dataset, metrics=[faithfulness], llm=generator_llm, embeddings=embeddings)print(score.to_pandas()) metric_faithfulness()
评估忠实性如下表所示。

2.3 评估答案相关性
计算答案的相关性 Answer relevancy,它基于答案推测出多个问题,然后计算用户问题和推测出的问题的相关性,也就是嵌入的相似度,然后取平均值从而得出相关性。它也需要回答和问题。
def metric_answer_relevancy(): score = evaluate(dataset, metrics=[answer_relevancy], llm=generator_llm, embeddings=embeddings) print(score.to_pandas()) metric_answer_relevancy()
评估结果如下表所示。

2.4 上下文精度
计算上下文精度 Context Precision,即召回的 K 个 Chunk 中,到底多少是和问题、真实答案相关的。然后基于此计算一个精度的分数。它需要问题、基本事实和上下文。
def metric_context_precision(): score = evaluate(dataset, metrics=[context_precision], llm=generator_llm, embeddings=embeddings) print(score.to_pandas()) metric_context_precision()
评估结果如下表所示。

2.5 上下文召回率
计算上下文召回率 Context Recall,衡量检索到的上下文与作为基本事实的一致程度。从基本事实中,提取出 Claims,然后判断每一个 Claims 是否可以从检索出的上下文中推断出来,然后计算推断出的 claims 数量和总 claims 数量。它需要问题、基本事实、上下文。
def metric_context_recall(): score = evaluate(dataset, metrics=[context_recall], llm=generator_llm, embeddings=embeddings) print(score.to_pandas())
评估结果如下表所示。

2.6 计算上下文实体召回率
计算上下文中实体召回 Context Entities Recall,分别从 Context 和基本事实中提取出实体,然后从中找出实体的交集并和基本事实中的实体数量做比,得出一个实体召回率。它需要上下文和基本事实。
def metric_context_entities_recall(): score = evaluate(dataset, metrics=[context_entity_recall], llm=generator_llm, embeddings=embeddings) print(score.to_pandas())
评估结果如下表所示。

相关文章:
【AIGC】RAGAS评估原理及实践
【AIGC】RAGAS评估原理及实践 (1)准备评估数据集(2)开始评估2.1 加载数据集2.2 评估忠实性2.3 评估答案相关性2.4 上下文精度2.5 上下文召回率2.6 计算上下文实体召回率 RAGas(RAG Assessment)RAG 评估的缩写ÿ…...
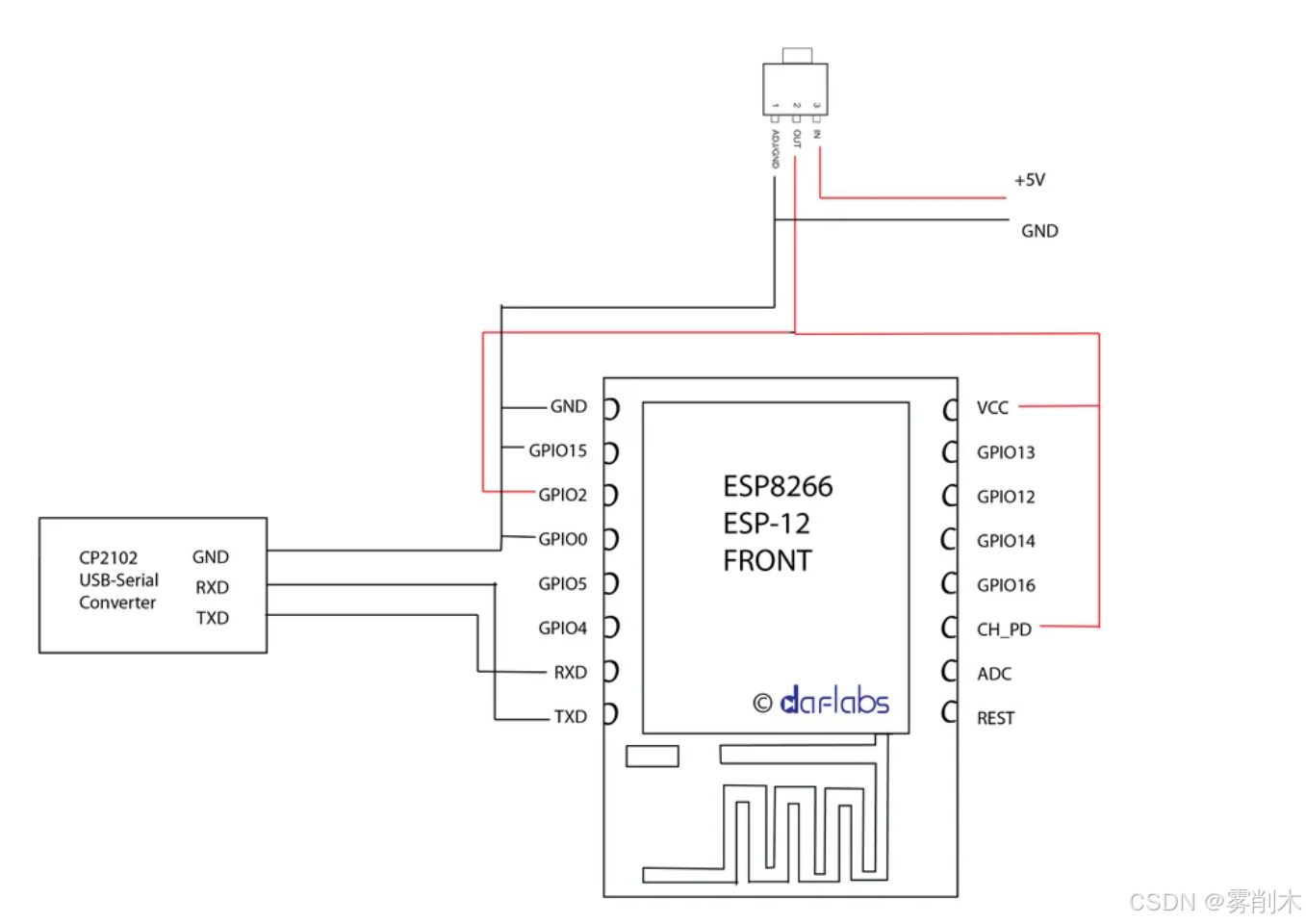
ESP12E/F 参数对比
模式GPIO0GPIO2GPIO15描述正常启动高高低从闪存运行固件闪光模式低高低启用固件刷写 PinNameFunction1RSTReset (Active Low)2ADC (A0)Analog Input (0–1V)3EN (CH_PD)Chip Enable (Pull High for Normal Operation)4GPIO16Wake from Deep Sleep, General Purpose I/O5GPIO14S…...

第二十八章 字符串与数字
第二十八章 字符串与数字 计算机程序完全就是和数据打交道。很多编程问题需要使用字符串和数字这种更小的数据来解决。 参数扩展 第七章,已经接触过参数扩展,但未进行详细说明,大多数参数扩展并不用于命令行,而是出现在脚本文件中。 如果没有什么特殊原因,把参数扩展放…...
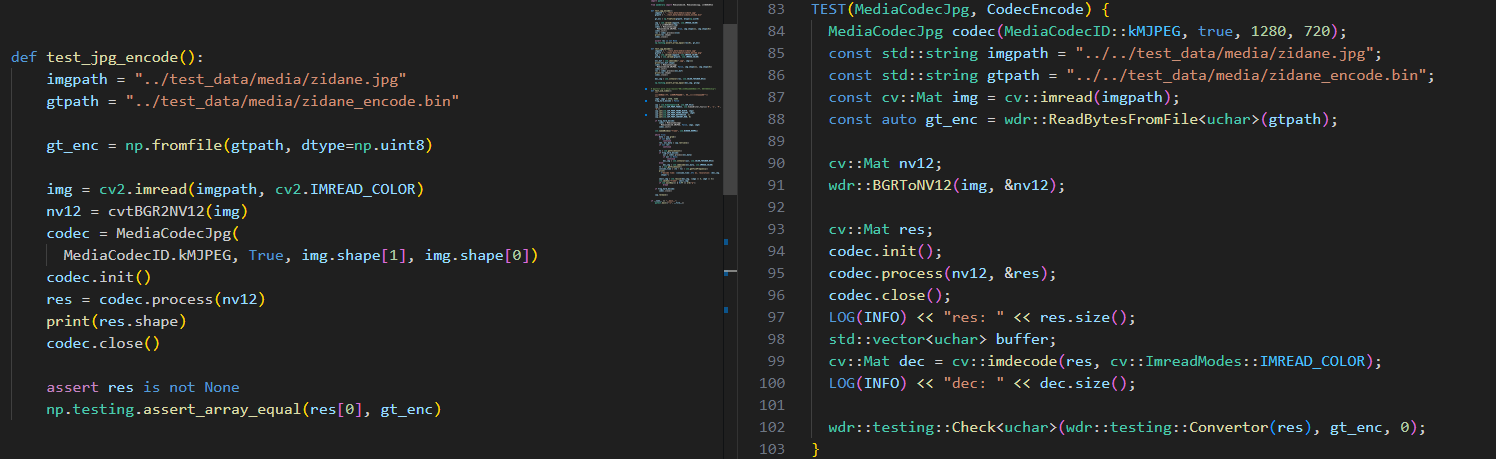
[RDK X5] MJPG编解码开发实战:从官方API到OpenWanderary库的C++/Python实现
业余时间一直在基于RDK X5搞一些小研究,需要基于高分辨率图像检测目标。实际落地时,在图像采集上遇到了个大坑。首先,考虑到可行性,我挑选了一个性价比最高的百元内摄像头,已确定可以在X5上使用,接下来就开…...

java复习 05
我的天啊一天又要过去了,没事的还有时间!!! 不要焦虑不要焦虑,事实证明只要我认真地投入进去一切都还是来得及的,代码多实操多复盘,别叽叽喳喳胡思乱想多多思考,有迷茫前害怕后的功…...

aardio 简单网页自动化
WebView自动化,以前每次重复做网页登录、搜索这些操作时都觉得好麻烦,现在终于能让程序替我干活了,赶紧记录下这个超实用的技能! 一、初次接触WebView WebView自动化就像给程序装了个"网页浏览器",第一步得…...

打卡第39天:Dataset 和 Dataloader类
知识点回顾: 1.Dataset类的__getitem__和__len__方法(本质是python的特殊方法) 2.Dataloader类 3.minist手写数据集的了解 作业:了解下cifar数据集,尝试获取其中一张图片 import torch import torch.nn as nn import…...

【评测】Qwen3-Embedding模型初体验
每一篇文章前后都增加返回目录 回到目录 【评测】Qwen3-Embedding模型初体验 模型的介绍页面 本机配置:八代i5-8265U,16G内存,无GPU核显运行,win10操作系统 ollama可以通过下面命令拉取模型: ollama pull modelscope…...

BeanFactory 和 FactoryBean 有何区别与联系?
导语: Spring 是后端面试中的“常青树”,而 BeanFactory 与 FactoryBean 的关系更是高频卡人点。很多候选人混淆两者概念,答非所问,轻则失分,重则直接被“pass”。本文将从面试官视角,深入剖析这一经典问题…...

如何做好一份优秀的技术文档:专业指南与最佳实践
如何做好一份优秀的技术文档:专业指南与最佳实践 技术文档是产品开发、用户支持和团队协作的核心工具。高质量的技术文档能够提升开发效率、降低维护成本并改善用户体验。本文将从实践出发,详细讲解如何编写专业、清晰且实用的技术文档。 🌟…...

C语言内存管理和编译优化实战
参考: C语言内存管理“玄学”:从崩溃到精通的避坑指南C语言编译优化实战:从入门到进阶的高效代码优化技巧...

TCP相关问题 第一篇
TCP相关问题1 1.TCP主动断开连接方为什么需要等待2MSL 如上图所示:在被动链接方调用close,发送FIN时进入LAST_ACK状态,但未收到主动连接方的ack确认,需要被动连接方重新发送一个FIN,而为什么是2MSL,一般认为丢失ack在…...
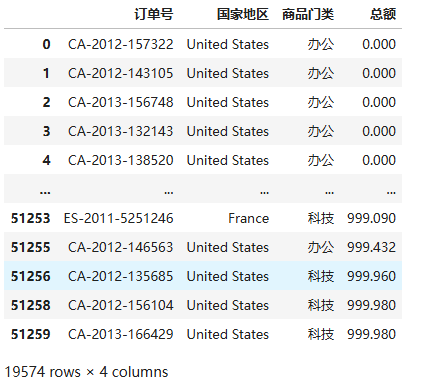
6.Pandas 数据可视化图-1
第三章 数据可视化 文章目录 目录 第三章 数据可视化 文章目录 前言 一、数据可视化 二、使用步骤 1.pyplot 1.1引入库 1.2 设置汉字字体 1.3 数据准备 1.4 设置索引列 编辑 1.5 调用绘图函数 2.使用seaborn绘图 2.1 安装导入seaborn 2.2 设置背景风格 2.3 调用绘图方法 2.…...

软件功能测试报告都包含哪些内容?
软件功能测试报告是软件开发生命周期中的重要文档,主要涵盖以下关键内容: 1.测试概况:概述测试目标、范围和方法,确保读者对测试背景有清晰了解。 2.测试环境:详细描述测试所用的硬件、软件环境,确保…...

在Vue或React项目中使用Tailwind CSS实现暗黑模式切换:从系统适配到手动控制
在现代Web开发中,暗黑模式(Dark Mode)已成为提升用户体验的重要功能。本文将带你使用Tailwind CSS在React项目(Vue项目类似)中实现两种暗黑模式控制方式: 系统自动适配 - 根据用户设备偏好自动切换手动切换 - 通过按钮让用户自由选择 一、项目准备 使…...
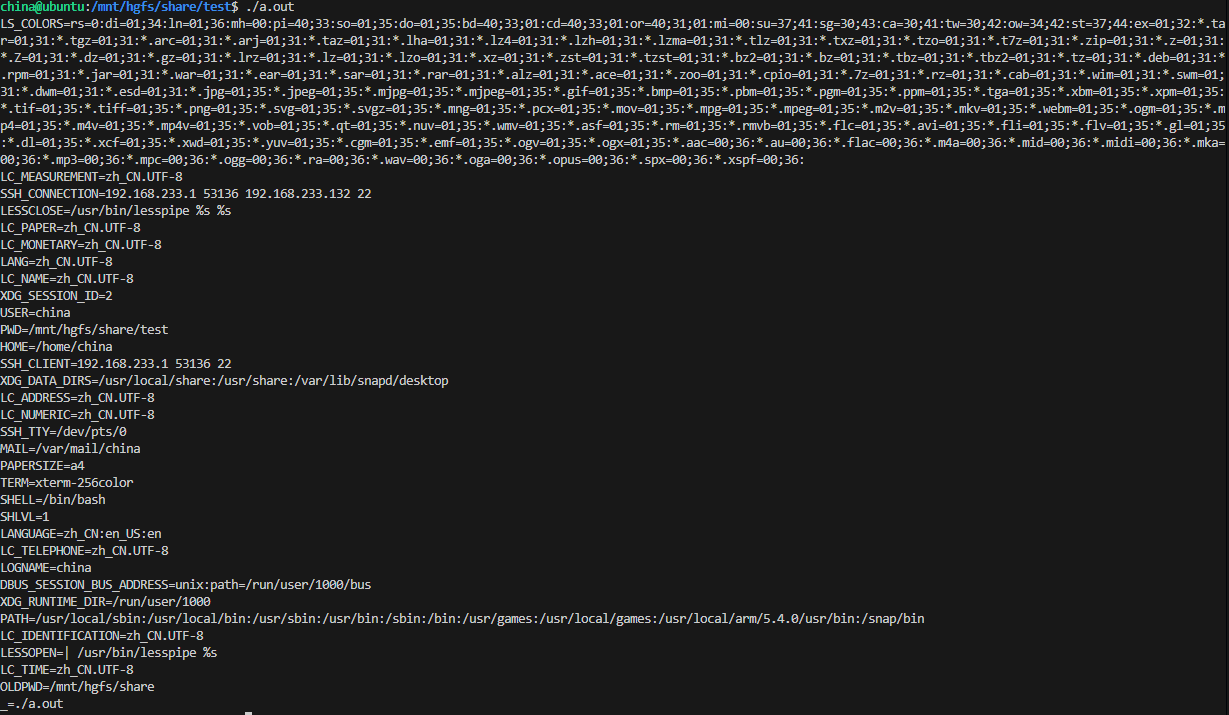
Linux--命令行参数和环境变量
1.命令行参数 Linux 命令行参数基础 1.1参数格式 位置参数:无符号,按顺序传递(如 ls /home/user 中 /home/user 是位置参数) 选项参数: 短选项:以 - 开头,单个字母(如 -l 表示长格…...

Android 集成 Firebase 指南
Firebase 是 Google 提供的一套移动开发平台,包含分析、认证、数据库、消息推送等多种服务。以下是在 Android 应用中集成 Firebase 的详细步骤: 1. 准备工作 安装 Android Studio - 确保使用最新版本 创建或打开 Android 项目 - 项目需要配置正确的包…...

springboot线上教学平台
摘要:在社会快速发展的影响下,使线上教学平台的管理和运营比过去十年更加理性化。依照这一现实为基础,设计一个快捷而又方便的网上线上教学平台系统是一项十分重要并且有价值的事情。对于传统的线上教学平台控制模型来说,网上线上…...

阿里云 Linux 搭建邮件系统全流程及常见问题解决
阿里云 Linux 搭建 [conkl.com]邮件系统全流程及常见问题解决 目录 阿里云 Linux 搭建 [conkl.com]邮件系统全流程及常见问题解决一、前期准备(关键配置需重点检查)1.1 服务器与域名准备1.2 系统初始化(必做操作) 二、核心组件安装…...

【Elasticsearch】映射:fielddata 详解
映射:fielddata 详解 1.fielddata 是什么2.fielddata 的工作原理3.主要用法3.1 启用 fielddata(通常在 text 字段上)3.2 监控 fielddata 使用情况3.3 清除 fielddata 缓存 4.使用场景示例示例 1:对 text 字段进行聚合示例 2&#…...

用Python训练自动驾驶神经网络:从零开始驾驭未来之路
用Python训练自动驾驶神经网络:从零开始驾驭未来之路 哈喽,朋友们!我是Echo_Wish,今天咱们聊点超酷的话题——自动驾驶中的神经网络训练,用Python怎么玩转起来? 说实话,自动驾驶一直是科技圈的香饽饽,为什么?因为它承载了未来交通的无限可能:减少事故、提升效率、节…...

【电路】阻抗匹配
📝 阻抗匹配 一、什么是阻抗匹配? 阻抗匹配(Impedance Matching)是指在电子系统中,为了实现最大功率传输或最小信号反射,使信号源、传输线与负载之间的阻抗达到一种“匹配”状态的技术。 研究对象&#x…...
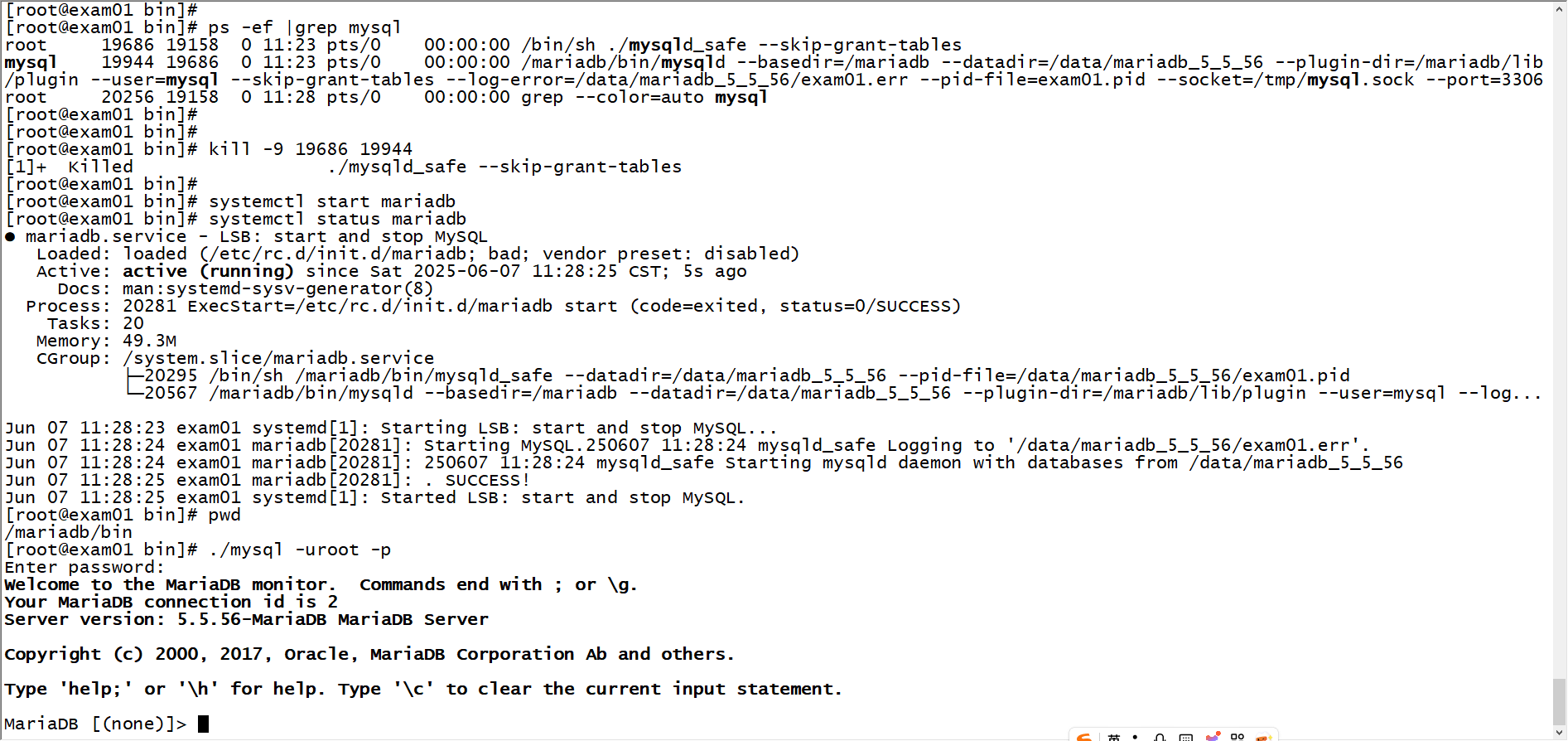
mariadb5.5.56在centos7.6环境安装
mariadb5.5.56在centos7.6环境安装 1 下载安装包 https://mariadb.org/mariadb/all-releases/#5-5 2 上传安装包的服务器 mariadb-5.5.56-linux-systemd-x86_64.tar.gz 3 解压安装包 tar -zxvf mariadb-5.5.56-linux-systemd-x86_64.tar.gz mv mariadb-5.5.56-linux-syst…...

MySQL 索引失效:六大场景与原理剖析
我们都熟知索引是优化 MySQL 查询性能的利器。但你是否遇到过这样的困境:明明在表上建立了索引,查询却依然缓慢,EXPLAIN 分析后发现索引并未被使用?这就是所谓的“索引失效”。 索引失效并非一个 Bug,而是 MySQL 查询…...

打造你的 Android 图像编辑器:深入解析 PhotoEditor 开源库
📸 什么是 PhotoEditor? PhotoEditor 是一个专为 Android 平台设计的开源图像编辑库,旨在为开发者提供简单易用的图像编辑功能。它支持绘图、添加文本、应用滤镜、插入表情符号和贴纸等功能,类似于 Instagram 的编辑体验。该库采…...

DeepSeek 终章:破局之路,未来已来
目录 一、DeepSeek 技术发展现状回顾二、未来发展趋势2.1 多模态融合的拓展2.2 模型可解释性的强化2.3 垂直领域的深化应用 三、面临的技术挑战3.1 数据隐私与安全难题3.2 算法偏见与公平性困境3.3 网络攻击与恶意利用威胁 四、挑战应对策略探讨4.1 技术层面的解决方案4.2 算法…...

八:操作系统设备管理之缓冲、缓存与假脱机
弥合鸿沟:操作系统中的缓冲、缓存与假脱机技术深度解析 在计算机系统的世界里,存在着一个根本性的速度差异:中央处理器(CPU)的执行速度飞快,而输入/输出(I/O)设备(如硬盘…...
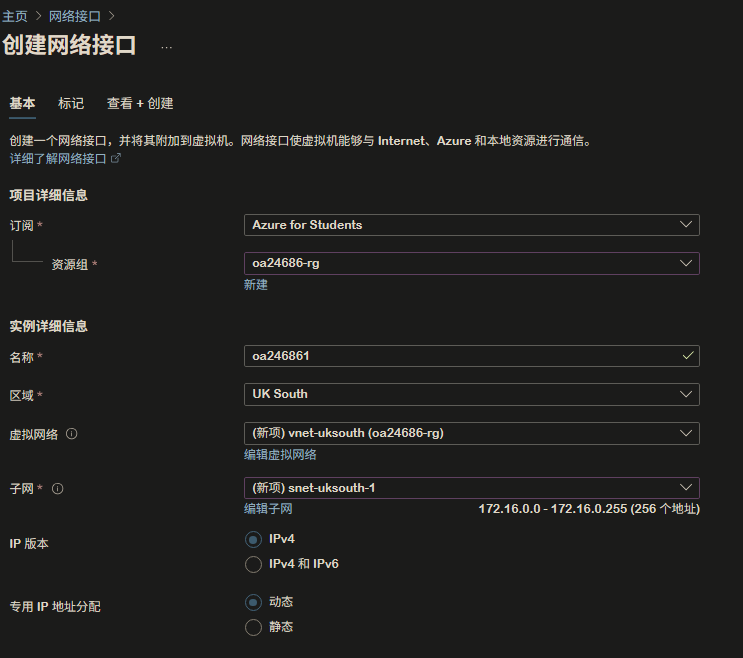
Azure 虚拟机端口资源:专用 IP 和公共 IP Azure Machine Learning 计算实例BUG
## 报错无解 找不到Azure ML 计算实例关联的 NSG .env 文件和 ufw status: .env 文件中 EXPOSE_NGINX_PORT8080 是正确的,它告诉 docker-compose.yaml 将 Nginx 暴露在宿主机的 8080 端口。 sudo ufw status 显示 Status: inactive,意味着宿…...

Java核心技术-卷I-读书笔记(第十二版)
第一章 Java程序设计概述 09年sun被oracle收购->11年java7(简单改进)->14年java8(函数式编程)->2017年java9->2018年java11->2021年java17 第二章 Java编程环境 Java9后新增JShell,提供类似脚本试执…...

从C到C++语法过度1
从C到C语法过度1 文章目录 从C到C语法过度11. 字符串string2. 引用3. 类型转换3.1 新式转换 const_cast3.2 新式转换 static_cast 4. 关键字auto 1. 字符串string C语言从本质上来说,是没有字符串这种类型的,在C语言中如果要表达字符串,只能…...