Linux 用户层 和 内核层锁的实现
目录
- 一、系统调用futex介绍
- 1. 核心机制
- 2. 常见操作
- 3. 工作流程示例(互斥锁)
- 4. 优势
- 5. 注意事项
- 6. 典型应用
- 二、Linux中用户态的锁和内核的锁不是同一个实现吗?
- 2.1 本质区别
- 2.2 用户态锁如何工作(以 `pthread_mutex` 为例)
- 2.3 内核锁的实现(以 `mutex_t` 为例)
- 2.4 为什么用户态锁需要内核参与?
- 2.5 性能对比
- 2.6 协作关系图解
- 2.7 关键结论
- 三、arm64位app层的原子操作如何实现?和内核实现的原子操作一样吗?
- 3.1、应用层原子操作的实现原理
- 3.1.1 硬件指令支撑
- 2. 编译器与标准库封装
- 3. 内存序控制
- 3.2 内核层原子操作的实现
- 3.2.1 相同硬件基础
- 3.2.2 关键差异:特权级扩展
- 3.2.3 内核独占原语
- 3.3 本质对比:相同硬件,不同使命
- 3.4 为什么应用层不直接使用内核锁?
- 四、用户态的自旋锁和互斥锁
- 4.1 用户空间互斥锁(Mutex)
- 4.1.1 核心特性:竞争时主动让出CPU
- 4.1.2 关键设计:
- 4.2 用户空间自旋锁(Spinlock)
- 4.2.1 核心特性:竞争时忙等待(Busy-Wait)
- 4.2.2 关键设计:
- 4.3 核心对比:互斥锁 vs 自旋锁
- 4.4 性能临界点:何时选择?
- 4.5 ARM64 特殊优化
- 4.5.1 自旋锁低功耗优化
- 4.5.2 互斥锁适应性改进
- 4.6 错误使用案例
- 场景1:在单核系统用自旋锁
- 场景2:在中断处理中用互斥锁
- 4.7 总结:用户态锁的选择
- 五、内核态的互斥锁和自旋锁
- 5.1 内核自旋锁(Spinlock)
- 5.1.1 设计目标:非睡眠场景的极速同步
- 5.1.2 关键特性:
- 5.2 内核互斥锁(Mutex)
- 5.2.1 设计目标:可睡眠场景的灵活同步
- 5.2.2 关键特性:
- 5.2.3 核心对比:自旋锁 vs 互斥锁
- 5.2.4 实现原理深度解析
- 5.2.4.1 自旋锁底层(ARM64 示例)
- 5.2.4.1 互斥锁状态机(核心状态)
- 5.2.5 错误使用案例
- 案例1:在中断中使用互斥锁
- 案例2:未关闭中断的自旋锁
- 案例3:长临界区用自旋锁
- 5.2.6 性能优化实践
一、系统调用futex介绍
futex(Fast Userspace Mutex)是 Linux 内核提供的一种底层同步原语,用于高效实现用户空间的锁(如互斥锁、信号量等)。它的核心思想是通过减少不必要的内核态切换来优化性能,特别适用于高并发场景。
1. 核心机制
-
混合模式(用户态+内核态协作):
-
用户态原子操作:
线程先尝试在用户空间通过原子指令(如 CAS)获取锁。若成功,则无需进入内核,性能极高。CAS的全称为Compare And Swap,直译就是比较交换。是一条CPU的原子指令,其作用是让CPU先进行比较两个值是否相等,然后原子地更新某个位置的值,其实现方式是基于硬件平台的汇编指令
-
内核态阻塞:
若锁已被占用,线程通过futex系统调用进入内核态阻塞(FUTEX_WAIT),直到锁释放后被唤醒(FUTEX_WAKE)。
-
-
关键系统调用:
#include <linux/futex.h> #include <sys/syscall.h>int syscall(SYS_futex, uint32_t *uaddr, int futex_op, uint32_t val, const struct timespec *timeout, uint32_t *uaddr2, uint32_t val3);uaddr:指向用户空间的一个整数(锁的状态标志)。futex_op:操作类型(如FUTEX_WAIT,FUTEX_WAKE)。val:辅助值(如等待时的预期值)。
2. 常见操作
| 操作 | 行为 |
|---|---|
FUTEX_WAIT | 检查 *uaddr == val,若成立则阻塞线程;否则立即返回 EAGAIN。 |
FUTEX_WAKE | 唤醒最多 val 个在 uaddr 上阻塞的线程。 |
FUTEX_REQUEUE | 将部分线程从 uaddr 的等待队列迁移到 uaddr2 的等待队列(避免惊群)。 |
FUTEX_PRIVATE | 标志位,表示仅限进程内使用(优化性能)。 |
3. 工作流程示例(互斥锁)
- 加锁:
// 用户态尝试原子交换 if (atomic_cas(uaddr, 0, 1) == success) return; // 成功获得锁 // 失败则进入内核等待 syscall(SYS_futex, uaddr, FUTEX_WAIT, 1, NULL, NULL, 0); - 解锁:
atomic_set(uaddr, 0); // 先释放锁 syscall(SYS_futex, uaddr, FUTEX_WAKE, 1); // 唤醒一个等待线程
4. 优势
- 性能:无竞争时完全在用户态运行,避免内核切换开销。
- 灵活性:可构建更高级的同步机制(如读写锁、条件变量)。
- 资源节省:内核仅在线程阻塞时介入,减少调度负担。
5. 注意事项
- 优先级反转:需结合优先级继承(如
FUTEX_LOCK_PI)解决实时性问题。 - 惊群效应:使用
FUTEX_REQUEUE或FUTEX_WAKE_OP分散唤醒压力。 - ABA 问题:
FUTEX_WAIT会验证*uaddr == val,但需确保状态变更逻辑正确。
6. 典型应用
- Glibc 的 pthread 库:互斥锁(
pthread_mutex_t)、条件变量(pthread_cond_t)、信号量(sem_t)、读写锁(pthread_rwlock_t)、屏障(pthread_barrier_t)底层使用futex。 - 高性能服务器:Redis、Nginx 等利用
futex实现自定义锁。
📌 提示:直接使用
futex需谨慎!通常推荐通过高级 API(如 C++11 的std::mutex)间接使用,避免复杂的内核交互细节。
二、Linux中用户态的锁和内核的锁不是同一个实现吗?
Linux 中用户态的锁和内核的锁是完全不同的实现机制和层次,但它们之间通过 futex 等机制实现了协作。以下是关键区别和联系:
2.1 本质区别
| 维度 | 用户态锁 (如 pthread_mutex) | 内核锁 (如 spinlock_t, mutex_t) |
|---|---|---|
| 实现位置 | 用户空间库(如 glibc)实现 | Linux 内核源码实现 |
| 依赖机制 | 基于原子指令 + futex 系统调用 | 基于内核原子操作、中断控制、调度器 |
| 作用范围 | 用户进程内的线程间同步 | 内核线程/中断上下文/多核间的同步 |
| 内存可见性 | 依赖进程的虚拟地址空间 | 依赖物理内存和内核地址空间 |
| 阻塞行为 | 通过 futex 让内核挂起线程 | 直接调用内核调度器切换任务 |
2.2 用户态锁如何工作(以 pthread_mutex 为例)
// 伪代码:用户态锁的加锁流程
void pthread_mutex_lock(pthread_mutex_t *mutex) {// 1. 用户态快速路径(无竞争)if (atomic_cas(&mutex->state, UNLOCKED, LOCKED) == success) return;// 2. 慢速路径:通过 futex 请求内核协助while (true) {if (atomic_cas(&mutex->state, UNLOCKED, LOCKED_WAITERS) == success) return;// 调用 futex 让内核阻塞线程syscall(SYS_futex, &mutex->state, FUTEX_WAIT_PRIVATE, LOCKED_WAITERS, NULL);}
}
- 关键点:
用户态锁在无竞争时完全在用户空间运行(仅需几条原子指令);
仅在竞争时通过futex陷入内核挂起线程。
2.3 内核锁的实现(以 mutex_t 为例)
// 内核源码(kernel/locking/mutex.c)
void __sched mutex_lock(struct mutex *lock)
{might_sleep();if (!__mutex_trylock_fast(lock)) // 1. 快速尝试__mutex_lock_slowpath(lock); // 2. 慢路径:内核调度介入
}
- 关键点:
内核锁全程在内核态执行,可直接调用调度器、中断控制等底层原语;
无需系统调用(因自身就在内核)。
2.4 为什么用户态锁需要内核参与?
用户态程序无法自行挂起线程——这必须由内核调度器完成。 当锁竞争时:
- 用户态通过
futex(FUTEX_WAIT)主动请求内核挂起自己; - 解锁时通过
futex(FUTEX_WAKE)请求内核唤醒等待线程。
2.5 性能对比
| 场景 | 用户态锁 | 内核锁 |
|---|---|---|
| 无竞争 | ≈10 ns(纯用户态原子操作) | ≈20 ns(内核原子操作) |
| 有竞争 | μs 级(需陷入内核) | μs 级(但无模式切换开销) |
| 适用场景 | 高并发用户程序 | 内核代码、驱动开发 |
📌 用户态锁在无竞争时性能接近无锁程序!
2.6 协作关系图解
用户程序│├── 无竞争 → 用户态原子操作(极快)│└── 有竞争 → 调用 futex 陷入内核│▼内核调度器│├── 挂起线程(FUTEX_WAIT)│└── 唤醒线程(FUTEX_WAKE)
2.7 关键结论
- 不是同一实现:用户态锁由库(如 glibc)基于原子指令 +
futex实现;内核锁由内核用更底层的机制实现。 - 协作而非替代:用户态锁依赖内核提供阻塞/唤醒能力(通过
futex),形成跨层协作。 - 性能分离:通过
futex的混合模式,用户态锁在无竞争时完全避开内核,实现高性能。
这种设计是 Linux 高并发性能的关键——既给了用户态灵活的同步能力,又通过最小化内核介入保障了效率!
三、arm64位app层的原子操作如何实现?和内核实现的原子操作一样吗?
在 ARM64 架构的 Linux 系统中,应用层(app 层)的原子操作与内核层的原子操作在硬件基础上相同,但实现层级和功能目标存在本质差异。
原子指令和内存屏障的关系:
- 原子指令 解决操作的原子性问题(怎么做)
- 内存屏障 解决操作的顺序和可见性问题(何时生效)
- 在复杂同步场景(如 mutex 或)中,二者缺一不可。
内存屏障(Memory Barrier)是计算机体系结构中的一种硬件级同步指令,用于解决多核处理器中内存访问的乱序执行和可见性问题。其核心作用是限制指令重排和确保内存一致性,在多线程、锁实现、无锁编程中至关重要。为什么需要内存屏障?
- 乱序执行的根源
- 编译器优化:编译器可能调整指令顺序以提升性能。
- CPU流水线:CPU为提升效率会乱序执行指令(Out-of-Order Execution)。
- 多级缓存:不同CPU核心的缓存(L1/L2)数据可能不一致。
- 典型问题场景
// 线程A
data = 42; // 写数据
flag = 1; // 写标志位// 线程B
while (flag != 1); // 等待标志位
print(data); // 读取数据
若没有内存屏障:
- CPU/编译器可能交换
data=42和flag=1的顺序 → 线程B看到flag=1但data仍是旧值。 - 线程B的CPU缓存未更新
data值 → 读到data=0。
内存屏障根据限制程度分为四类(以ARM64为例):
| 屏障类型 | 作用 | ARM64指令 | 使用场景 |
|---|---|---|---|
| LoadLoad | 确保后续读操作不会重排到当前读之前 | ldar (Load-Acquire) | 读后需依赖之前读的结果 |
| StoreStore | 确保当前写操作不会重排到后续写之后 | stlr (Store-Release) | 写后需立即被其他线程看到 |
| LoadStore | 确保后续写操作不会重排到当前读之前 | 包含在dmb ishld | 读后需立即写 |
| StoreLoad | 确保后续读操作不会重排到当前写之前(最强屏障) | dmb ish | 写后需立即读最新值 |
💡 StoreLoad屏障最重:因为它需要刷新整个写缓冲区(Write Buffer),通常对应
dmb ish(ARM64)或mfence(x86)。写操作后放 Release,读操作前放 Acquire —— 这对屏障组合可解决 90% 的线程同步问题。
3.1、应用层原子操作的实现原理
3.1.1 硬件指令支撑
ARM64 提供两类关键指令:
-
独占访问指令(ARMv8.0)
ldxr x0, [x1] ; 独占加载:标记地址 x1 为当前 CPU 独占 stxr w2, x3, [x1] ; 独占存储:若标记未失效则写入 x3 → [x1],结果状态存入 w2通过循环重试实现原子操作(如 CAS):
// 原子比较交换(用户态伪代码) //stxr仅在标记未被破坏时执行写入,否则失败并重试。这种“尝试-检测-重试”机制确保了“读-改-写”操作的原子性 bool atomic_cas(uint64_t *ptr, uint64_t old, uint64_t new) {uint64_t tmp;int status;do {asm volatile("ldxr %0, [%2]\n" // 独占加载"cmp %0, %3\n" // 比较旧值"b.ne 1f\n" // 不相等则跳转"stxr %w1, %4, [%2]\n" // 尝试存储新值"1:": "=&r"(tmp), "=&r"(status): "r"(ptr), "r"(old), "r"(new));} while (status != 0); // 失败则重试return (tmp == old); } -
LSE 指令(ARMv8.1+,大系统扩展)
单条指令完成原子操作,避免循环开销:ldaddal x0, x1, [x2] ; 原子操作:[x2] = [x2] + x0, x1 = 原值
2. 编译器与标准库封装
- GCC/Clang 内置函数直接映射到硬件指令:
// 原子加法(用户态) __atomic_add_fetch(&counter, 1, __ATOMIC_SEQ_CST); - C++11 原子类型:
std::atomic<int> counter; counter.fetch_add(1, std::memory_order_relaxed);
3. 内存序控制
通过屏障指令保证可见性:
dmb ish ; 数据内存屏障(Inner Shareable Domain)
3.2 内核层原子操作的实现
3.2.1 相同硬件基础
内核使用相同的 ARM64 原子指令(ldxr/stxr 或 LSE),例如:
// 内核原子加法(源码片段:arch/arm64/include/asm/atomic_ll_sc.h)
static inline void atomic_add(int i, atomic_t *v) {unsigned long tmp;asm volatile("// atomic_add\n""1: ldxr %w0, %2\n" // 独占加载"add %w0, %w0, %w3\n" // 执行加法"stxr %w1, %w0, %2\n" // 条件存储"cbnz %w1, 1b" // 失败则重试: "=&r" (tmp), "=&r" (tmp2): "Q" (v->counter), "Ir" (i));
}
3.2.2 关键差异:特权级扩展
内核原子操作需处理用户态无法触及的场景:
| 能力 | 内核实现 | 用户态限制 |
|---|---|---|
| 内存屏障 | 直接调用 dmb ish 或 dsb sy | 只能使用普通屏障指令 |
| 中断控制 | 可关闭中断(local_irq_save())避免并发 | 无权操作中断 |
| SMP 核间同步 | 使用 smp_mb() 等跨核屏障 | 仅限当前 CPU 缓存一致性 |
| 调度器协作 | 自旋锁(spin_lock())在争用时结合调度器 | 无调度干预权限 |
3.2.3 内核独占原语
用户态无法实现的原子操作:
- RCU(Read-Copy-Update):依赖内核线程和调度机制。
- 中断上下文原子操作:内核可在中断处理中安全使用原子变量。
3.3 本质对比:相同硬件,不同使命
| 维度 | 应用层原子操作 | 内核层原子操作 |
|---|---|---|
| 硬件基础 | 相同 ARM64 指令(LSE/LDXR/STXR) | 相同指令 + 扩展屏障/中断控制 |
| 执行位置 | 纯用户态(无特权指令) | 内核态(可调用特权指令) |
| 内存序控制 | 通过标准内存序参数(如 __ATOMIC_ACQ_REL) | 直接使用硬件屏障指令 |
| 阻塞行为 | 非阻塞(自旋重试) | 可结合调度器(如自旋锁升级为睡眠) |
| 适用场景 | 细粒度数据操作(计数器、标志位) | 内核数据结构、驱动寄存器访问 |
3.4 为什么应用层不直接使用内核锁?
-
性能鸿沟
- 用户态原子操作:≈10–50 ns(纯硬件指令)
- 内核锁(如
futex):≥1000 ns(系统调用 + 上下文切换)
实测数据(Cortex-A78 @2.8GHz):
Atomic Add (user): 28 ns Futex Lock (uncontended): 1200 ns -
功能冗余性
内核锁(如互斥锁)的底层仍依赖原子操作,用户态直接使用原子操作可避免陷入内核的开销。 -
安全边界
用户程序直接调用内核锁会突破进程隔离,需通过系统调用代理(如futex),而原子操作无需跨特权边界。
四、用户态的自旋锁和互斥锁
4.1 用户空间互斥锁(Mutex)
4.1.1 核心特性:竞争时主动让出CPU
// 伪代码:用户态互斥锁实现(基于 futex)
void mutex_lock(mutex_t *m) {// 1. 用户态快速路径(无竞争)if (atomic_cas(&m->lock, 0, 1) == success) return;// 2. 慢速路径:标记有等待者,并陷入内核阻塞atomic_set(&m->lock, 2); // 设置等待标志syscall(SYS_futex, &m->lock, FUTEX_WAIT_PRIVATE, 2, NULL);
}void mutex_unlock(mutex_t *m) {// 1. 释放锁并检查是否有等待者if (atomic_swap(&m->lock, 0) == 2) { // 原值为2表示有等待者// 2. 唤醒一个等待线程syscall(SYS_futex, &m->lock, FUTEX_WAKE_PRIVATE, 1);}
}
4.1.2 关键设计:
-
混合模式优化
- 无竞争时:仅需 1次原子CAS操作(≈20ns)
- 有竞争时:通过
futex陷入内核挂起线程,避免CPU空转
-
内核协作机制
依赖futex系统调用实现线程阻塞(FUTEX_WAIT)和唤醒(FUTEX_WAKE) -
典型行为
- 锁被占用时:线程进入睡眠状态,触发内核调度
- 解锁时:唤醒等待队列中的线程
4.2 用户空间自旋锁(Spinlock)
4.2.1 核心特性:竞争时忙等待(Busy-Wait)
// 伪代码:用户态自旋锁(纯原子操作)
void spin_lock(spinlock_t *lock) {while (true) {// 尝试获取锁:0表示空闲,1表示占用if (atomic_exchange(&lock->flag, 1) == 0) return;// ARM64优化:降低CPU功耗asm volatile("wfe" ::: "memory"); // Wait For Event}
}void spin_unlock(spinlock_t *lock) {atomic_store(&lock->flag, 0);asm volatile("sev" ::: "memory"); // Send Event
}
4.2.2 关键设计:
-
纯用户态执行
- 全程无系统调用,依赖原子指令(如
ldxr/stxr或 LSE) - 解锁时通过
sev指令唤醒其他核心的wfe等待
- 全程无系统调用,依赖原子指令(如
-
忙等待优化
- 基础版:循环执行原子检查(高CPU占用)
- 优化版:插入
wfe指令让CPU进入低功耗状态,直到sev事件唤醒
-
典型行为
- 锁被占用时:线程在用户态循环检测(可能结合
wfe) - 解锁时:直接修改锁状态,无内核交互
- 锁被占用时:线程在用户态循环检测(可能结合
4.3 核心对比:互斥锁 vs 自旋锁
| 特性 | 互斥锁 (Mutex) | 自旋锁 (Spinlock) |
|---|---|---|
| 竞争策略 | 阻塞线程(睡眠) | 忙等待(循环检测) |
| 内核介入 | 依赖 futex 系统调用 | 无系统调用 |
| 无竞争开销 | ≈20 ns(原子CAS) | ≈10 ns(原子交换) |
| 高竞争开销 | 微秒级(上下文切换) | 浪费CPU周期(纳秒级/循环) |
| 线程状态 | 睡眠(TASK_INTERRUPTIBLE) | 运行中(RUNNING) |
| 适用场景 | 长临界区(>1μs)或可能阻塞的操作 | 短临界区(<1μs)且多核环境 |
| ARM64优化 | FUTEX_WAIT + FUTEX_WAKE | wfe + sev 低功耗等待 |
| 饥饿风险 | 公平锁需额外设计(如队列) | 可能饥饿(无排队机制) |
4.4 性能临界点:何时选择?
通过 临界区执行时间(C) 和 上下文切换开销(S) 决策:
if C < S : 选自旋锁(避免切换开销)
if C > S : 选互斥锁(避免CPU浪费)
- 典型值(Linux on ARM64):
- 上下文切换开销
S ≈ 1-3 μs - 自旋锁单次循环
≈5-20 ns
- 上下文切换开销
📌 经验法则:
- 临界区 < 1μs(如计数器增减):自旋锁
- 临界区 > 2μs(如链表操作):互斥锁
- 涉及I/O或睡眠操作:必须用互斥锁
4.5 ARM64 特殊优化
4.5.1 自旋锁低功耗优化
// 锁等待时进入低功耗状态
spin_wait:wfe // Wait For Event(暂停CPU流水线)b check_lock // 被唤醒后重新检查锁状态// 解锁时触发事件
spin_unlock:str wzr, [x0] // 释放锁sev // Send Event(唤醒其他核心的wfe)
4.5.2 互斥锁适应性改进
现代 pthread_mutex 在ARM64的实现:
- 第一阶段:用户态自旋(约100-200次循环)
- 第二阶段:调用
futex睡眠
平衡短等待的性能和长等待的CPU效率
4.6 错误使用案例
场景1:在单核系统用自旋锁
// 错误!单核忙等待导致死锁
spin_lock(&lock);
// 若锁已被占用,当前线程永不释放CPU,持有锁的线程无法运行
场景2:在中断处理中用互斥锁
// 内核场景(用户态无此问题)
void irq_handler() {mutex_lock(&lock); // 可能睡眠 → 崩溃!
}
4.7 总结:用户态锁的选择
| 场景 | 推荐锁类型 | 原因 |
|---|---|---|
| 短临界区 + 多核CPU | 自旋锁(带 wfe) | 避免上下文切换开销 |
| 长临界区/I/O操作 | 互斥锁 | 防止CPU空转 |
| 需要公平性(如数据库连接池) | 队列互斥锁 | 解决线程饥饿问题 |
| 超高频计数器 | 原子操作(非锁) | 完全无锁,性能极限 |
💡 终极建议:
- 优先使用标准库(如
pthread_mutex_t或std::mutex),其内部已做自适应优化- 仅在极端性能需求时考虑手写自旋锁,并插入
wfe指令- 用
perf工具检测锁竞争率:perf stat -e L1-dcache-loads,mem_inst_retired.lock_loads
五、内核态的互斥锁和自旋锁
在 Linux 内核中,互斥锁(Mutex) 和 自旋锁(Spinlock) 是两种最核心的同步原语,其设计与用户态实现有本质区别。以下是深度解析(基于 Linux 5.x 内核源码):
5.1 内核自旋锁(Spinlock)
5.1.1 设计目标:非睡眠场景的极速同步
// 典型用法(中断安全版)
DEFINE_SPINLOCK(my_lock);
unsigned long flags;spin_lock_irqsave(&my_lock, flags); // 关中断 + 拿锁
/* 临界区操作 */
spin_unlock_irqrestore(&my_lock, flags); // 放锁 + 开中断
5.1.2 关键特性:
-
忙等待机制
- 通过原子指令(如 ARM64
ldaxr/stlxr)循环检测锁状态 - 等待时执行
wfe(ARM64)或pause(x86)降低 CPU 功耗
- 通过原子指令(如 ARM64
-
中断安全性
变体 行为 spin_lock()基础版本,不保证中断安全 spin_lock_irq()关本地中断 spin_lock_irqsave()关中断并保存中断状态 spin_lock_bh()关软中断(Bottom Half) -
适用场景
- 中断上下文(不可睡眠)
- 短临界区(< 10 μs)
- 多核竞争激烈场景(如网络收发包)
5.2 内核互斥锁(Mutex)
5.2.1 设计目标:可睡眠场景的灵活同步
// 典型用法
DEFINE_MUTEX(my_mutex);mutex_lock(&my_mutex); // 可能睡眠
/* 临界区(可包含阻塞操作) */
mutex_unlock(&my_mutex);
5.2.2 关键特性:
-
自适应优化
内核互斥锁融合自旋与睡眠机制:// 加锁流程伪代码(kernel/locking/mutex.c) void mutex_lock(struct mutex *lock) {// 1. 快速路径:用户态式原子获取if (atomic_cas(lock->count, 1, 0)) return;// 2. 中速路径:短暂自旋(约100循环)for (int i = 0; i < 100; i++) {if (atomic_cas(lock->count, 1, 0)) return;cpu_relax(); // 降低CPU压力(ARM64: wfe)}// 3. 慢速路径:真正睡眠__mutex_lock_slowpath(lock); } -
高级特性
特性 描述 优先级继承 解决优先级反转( CONFIG_MUTEX_PI)乐观自旋 持有者运行时,等待者在用户态自旋避免切换( CONFIG_MUTEX_SPIN_ON_OWNER)死锁检测 CONFIG_DEBUG_MUTEXES可追踪锁依赖 -
适用场景
- 进程上下文长临界区(> 10 μs)
- 可能阻塞的操作(如 I/O 等待)
- 需要避免优先级反转的实时任务
5.2.3 核心对比:自旋锁 vs 互斥锁
| 维度 | 自旋锁 (Spinlock) | 互斥锁 (Mutex) |
|---|---|---|
| 等待机制 | 忙等待(Busy-Wait) | 可睡眠(Sleep-Wait) |
| 上下文兼容性 | 中断/进程上下文 | 仅进程上下文(不可在中断使用) |
| 临界区时长 | 短(微秒级) | 长(毫秒级) |
| 阻塞行为 | 永不阻塞 | 可能阻塞并触发调度 |
| 内存开销 | 4-8 字节(简单状态) | 24-40 字节(含等待队列/PI数据) |
| ARM64 优化 | wfe + sevl 低功耗等待 | 乐观自旋(Owner-CPU 检测) |
| 典型使用场景 | 中断处理、调度器、RCU | 文件系统、驱动长操作、用户空间同步 |
| 死锁风险 | 高(需严格关中断) | 中(依赖正确解锁) |
5.2.4 实现原理深度解析
5.2.4.1 自旋锁底层(ARM64 示例)
// arch/arm/include/asm/spinlock.h
static inline void arch_spin_lock(arch_spinlock_t *lock)
{unsigned long tmp; // 用于存储 STREX 指令的返回结果(0表示成功,非0表示失败)u32 newval; // 计算后的新锁值(当前锁值 + 一个 ticket)arch_spinlock_t lockval; // 存储 LDREX 加载的当前锁状态// 预取锁的内存到缓存,优化后续访问速度prefetchw(&lock->slock);// 通过 LDREX/STREX 原子操作尝试获取 ticket(ARM 架构原子操作的核心)__asm__ __volatile__("1: ldrex %0, [%3]\n" // 加载当前锁值到 %0(lockval.slock)" add %1, %0, %4\n" // 计算新锁值:当前锁值 + (1 << TICKET_SHIFT)(分配新 ticket)" strex %2, %1, [%3]\n" // 尝试将新锁值写回内存,结果存入 %2(tmp)" teq %2, #0\n" // 检查 STREX 是否成功(结果为0表示成功)" bne 1b" // 失败则跳转到1标号重试: "=&r" (lockval), "=&r" (newval), "=&r" (tmp) // 输出操作数(按顺序对应 %0/%1/%2): "r" (&lock->slock), "I" (1 << TICKET_SHIFT) // 输入操作数(锁地址和 ticket 偏移量): "cc"); // 破坏的寄存器:条件码寄存器// 等待当前线程的 ticket 被轮到(ticket 机制核心逻辑)// 当 lockval.tickets.next(当前线程的 ticket)等于 lockval.tickets.owner(当前持有锁的 ticket)时,获取锁成功while (lockval.tickets.next != lockval.tickets.owner) {wfe(); // 进入低功耗等待状态(Wait For Event),直到收到 SEV 事件唤醒// 重新读取最新的 owner 值(避免缓存脏数据,确保获取最新锁状态)lockval.tickets.owner = READ_ONCE(lock->tickets.owner);}// 内存屏障:确保加锁后的操作不会被重排序到加锁之前,保证内存可见性smp_mb();
}
5.2.4.1 互斥锁状态机(核心状态)
// include/linux/mutex.h
/** 互斥锁核心结构体,提供严格的互斥访问机制:* 成员说明:* owner - 原子长整型,记录当前持有锁的任务指针(低bit可能包含状态标志)* wait_lock - 自旋锁,用于保护等待队列的并发访问* osq - 乐观自旋队列(MCS锁),用于实现自旋优化(仅在CONFIG_MUTEX_SPIN_ON_OWNER启用时存在)* wait_list - 等待该锁的任务链表头,使用内核标准链表结构* magic - 调试标识指针,用于验证结构体有效性(仅在CONFIG_DEBUG_MUTEXES启用时存在)* dep_map - 锁依赖跟踪映射表,用于死锁检测(仅在CONFIG_DEBUG_LOCK_ALLOC启用时存在)* ANDROID... - Android OEM厂商自定义数据扩展区*/
struct mutex {atomic_long_t owner;spinlock_t wait_lock;
#ifdef CONFIG_MUTEX_SPIN_ON_OWNERstruct optimistic_spin_queue osq; /* Spinner MCS lock */
#endifstruct list_head wait_list;
#ifdef CONFIG_DEBUG_MUTEXESvoid *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOCstruct lockdep_map dep_map;
#endifANDROID_OEM_DATA_ARRAY(1, 2);
};
- 状态位:
MUTEX_FLAG_WAITERS(有等待者)
MUTEX_FLAG_HANDOFF(优先级继承传递)
5.2.5 错误使用案例
案例1:在中断中使用互斥锁
// 错误!导致内核崩溃
void irq_handler() {mutex_lock(&lock); // 可能触发调度 → 内核oops!
}
案例2:未关闭中断的自旋锁
// 死锁风险!
spin_lock(&lock);
// 若中断到来并尝试获取同一锁 → 死锁
案例3:长临界区用自旋锁
// CPU资源浪费
spin_lock(&lock);
msleep(10); // 睡眠10ms → 其他核空转10ms
spin_unlock(&lock);
5.2.6 性能优化实践
- 自旋锁
- 减少临界区到最小(仅保护必要数据)
- 用
READ_ONCE()/WRITE_ONCE()避免编译器优化冲突
- 互斥锁
- 启用
CONFIG_MUTEX_SPIN_ON_OWNER(默认开启) - 避免嵌套锁(否则破坏乐观自旋)
- 启用
- 替代方案
- 读多写少 → 读写锁(
rwlock_t或seqlock_t) - 无锁编程 → 原子操作或 RCU
- 读多写少 → 读写锁(
相关文章:

Linux 用户层 和 内核层锁的实现
目录 一、系统调用futex介绍1. 核心机制2. 常见操作3. 工作流程示例(互斥锁)4. 优势5. 注意事项6. 典型应用 二、Linux中用户态的锁和内核的锁不是同一个实现吗?2.1 本质区别2.2 用户态锁如何工作(以 pthread_mutex 为例ÿ…...
)
Android第十五次面试总结(第三方组件和adb命令)
Android 第三方组件转为系统组件核心流程 这通常是在进行 Android 系统定制(如 ROM 开发、固件制作)时完成,目的是让第三方应用拥有更高的权限和系统身份。主要过程如下: 核心准备:签名!赋予系统身份 …...
Agent短期记忆的几种持久化存储方式
今天给大家讲一下关于Agent长期对话的几种持久化存储方式,之前的文章给大家说过短期记忆和长期记忆,短期记忆基于InMemorySaver做checkpointer(检查点),短期记忆 (线程级持久性) 使代理能够跟踪…...
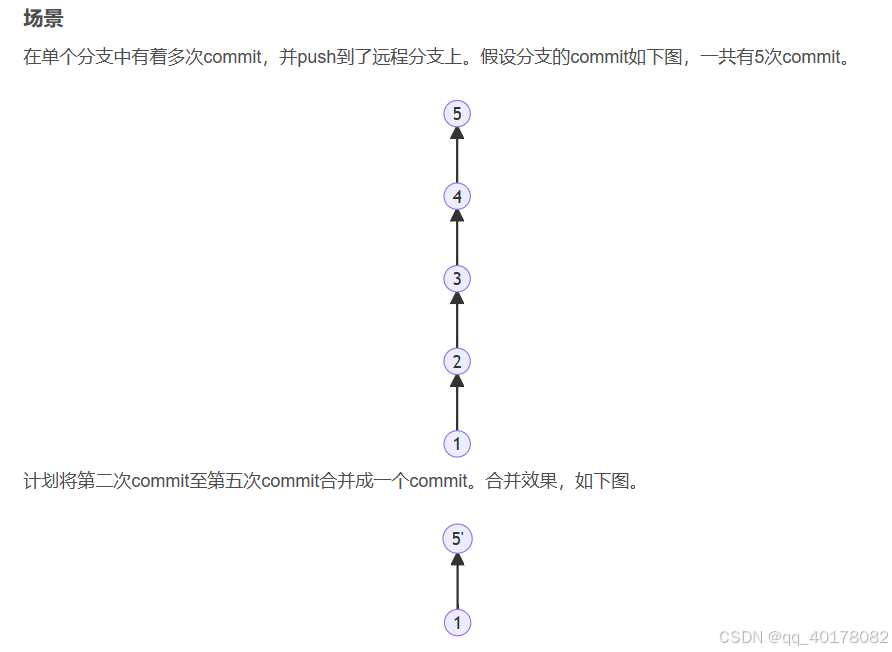
Git 常见操作
目录 1.git stash 2.合并多个commit 3. git commit -amend (后悔药) 4.版本回退 5.merge和rebase 6.cherry pick 7.分支 8.alias 1.git stash git-stash操作_git stash 怎么增加更改内容-CSDN博客 2.合并多个commit 通过git bash工具交互式操作。 1.查询commit的c…...
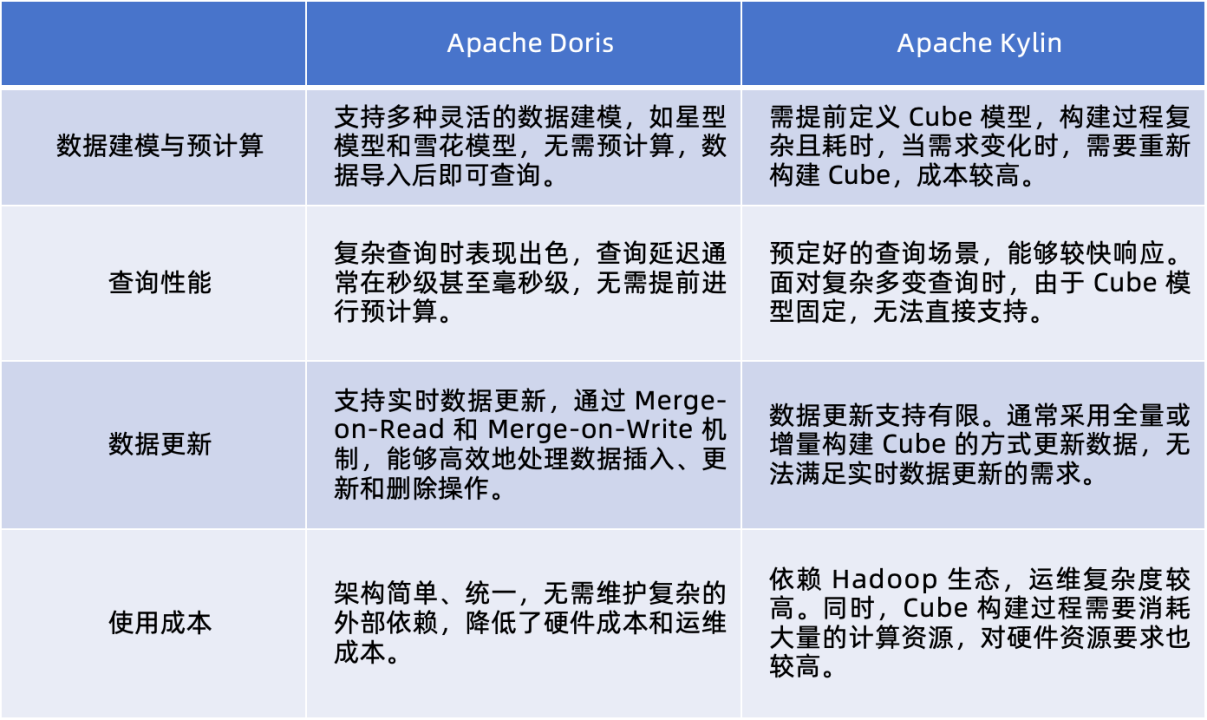
从 ClickHouse、Druid、Kylin 到 Doris:网易云音乐 PB 级实时分析平台降本增效
网易云音乐基于 Apache Doris 替换了早期架构中 Kylin、Druid、Clickhouse、Elasticsearch、HBase 等引擎,统一了实时分析架构,并广泛应用于广告实时数仓、日志平台和会员报表分析等典型场景中,带来导入性能提升 3~30 倍ÿ…...

隐函数 因变量确定标准
涉及多元隐函数求导法的逻辑本质:当我们对隐函数关系 F ( x , y , z ) 0 F(x, y, z) 0 F(x,y,z)0 使用偏导法求 ∂ z ∂ x \frac{\partial z}{\partial x} ∂x∂z时,为什么「偏导」能确定谁是因变量?为什么只有当对 z z z 的偏导 F z…...
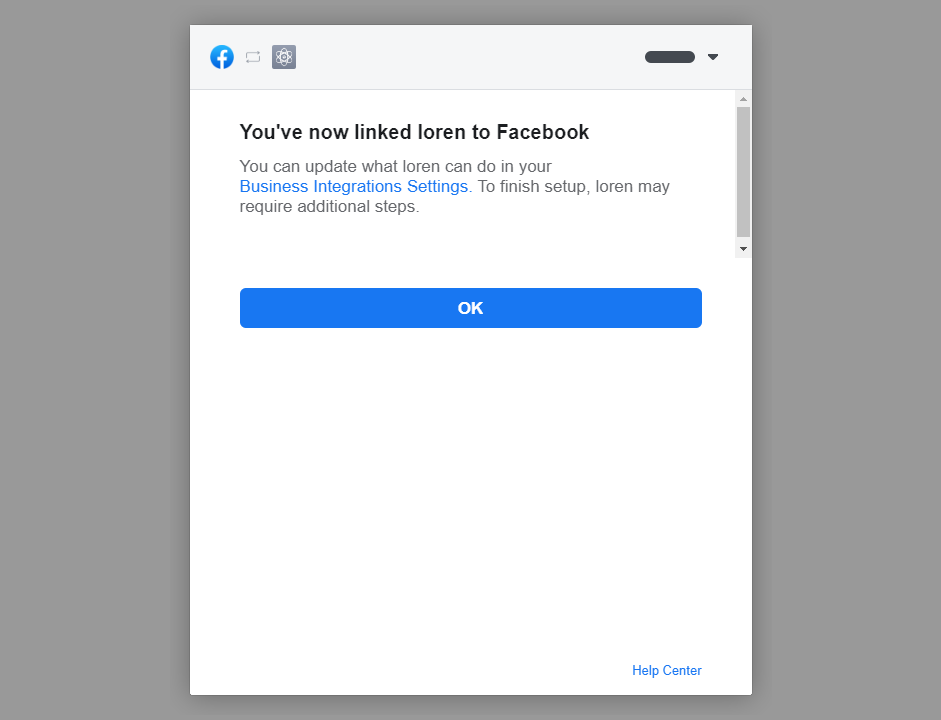
Facebook接入说明
Facebook 原生 Messenger 聊天消息接入到一洽对话中 1、创建 Facebook 主页 进入 https://www.facebook.com/pages/create 页面根据提示创建主页(如果已经有待用主页,可跳过) 2、授权对话权限 1、向您的一洽负责人获取 Facebook 授权链接 2、…...
Grafana 地图本土化方案:使用高德地图API平替GeoMap地图指南
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] 📢 大家好,我是 WeiyiGeek,一名深耕安全运维开发(SecOpsDev)领域的技术从业者,致力于探索DevOps与安全的融合(De…...

Python爬虫实战:研究demiurge框架相关技术
1. 引言 在当今数字化时代,互联网上蕴含着海量的有价值信息。爬虫技术作为获取这些信息的重要手段,被广泛应用于学术研究、商业分析、舆情监测等多个领域。然而,构建一个高效、稳定且可维护的爬虫系统面临诸多挑战,如网页结构复杂多变、反爬机制日益严格、数据处理流程繁琐…...

3 个优质的终端 GitHub 开源工具
1、Oh My Zsh Oh My Zsh 是一个帮助你管理和美化 zsh 终端的开源工具。它让你的终端更炫酷、更高效。安装后,你可以快速使用各种插件和主题,比如常见的 git 命令简化、支持多种编程语言工具等,每次打开终端都会有惊喜。无论你是开发者还是普…...
 = 0 隐函数微分 确定自变量)
F(x, y, z) = 0 隐函数微分 确定自变量
多元隐函数偏导的通用公式: 设一个隐函数由三元函数定义: F ( x , y , z ) 0 F(x, y, z) 0 F(x,y,z)0 且假设 z z ( x , y ) z z(x, y) zz(x,y),即 z z z 是 x , y x, y x,y 的函数,满足这个等式恒成立。则有以下公式&am…...
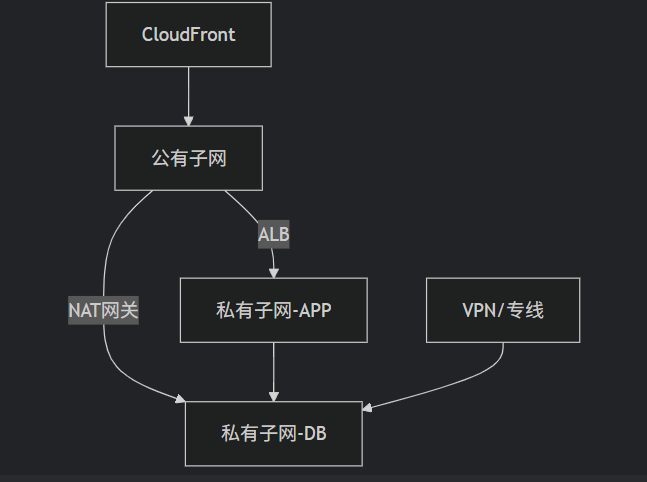
亚马逊AWS云服务器高效使用指南:最大限度降低成本的实战策略
对于初次接触云计算的企业或个人开发者而言,亚马逊云服务器(Amazon EC2)的配置与成本控制往往面临双重挑战:既要理解数百种实例规格的技术参数,又要避免因配置不当导致的资源浪费。本文将深入剖析AWS EC2的核心使用场景…...

Android设备推送traceroute命令进行网络诊断
文章目录 工作原理下载traceroute for android推送到安卓设备执行traceroutetraceroute www.baidu.com Traceroute(追踪路由) 是一个用于网络诊断的工具,主要用于追踪数据包从源主机到目标主机所经过的路由路径,以及每一跳&#x…...
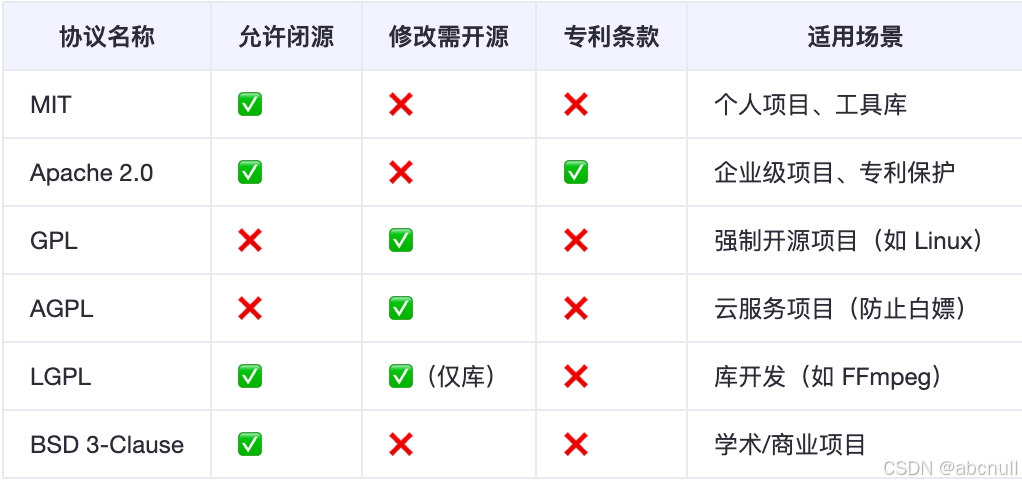
github开源协议选择
文章目录 怎么选协议宽松型协议 Permissive Licenses传染型协议 怎么选协议 希望代码被广泛使用,允许闭源 MIT、Apache 2.0、BSD需要专利保护 Apache 2.0强制开源衍生作品 GPL、AGPL开发库,允许闭源调用 LGPL云服务项目,防止白嫖 AGPL企业级…...
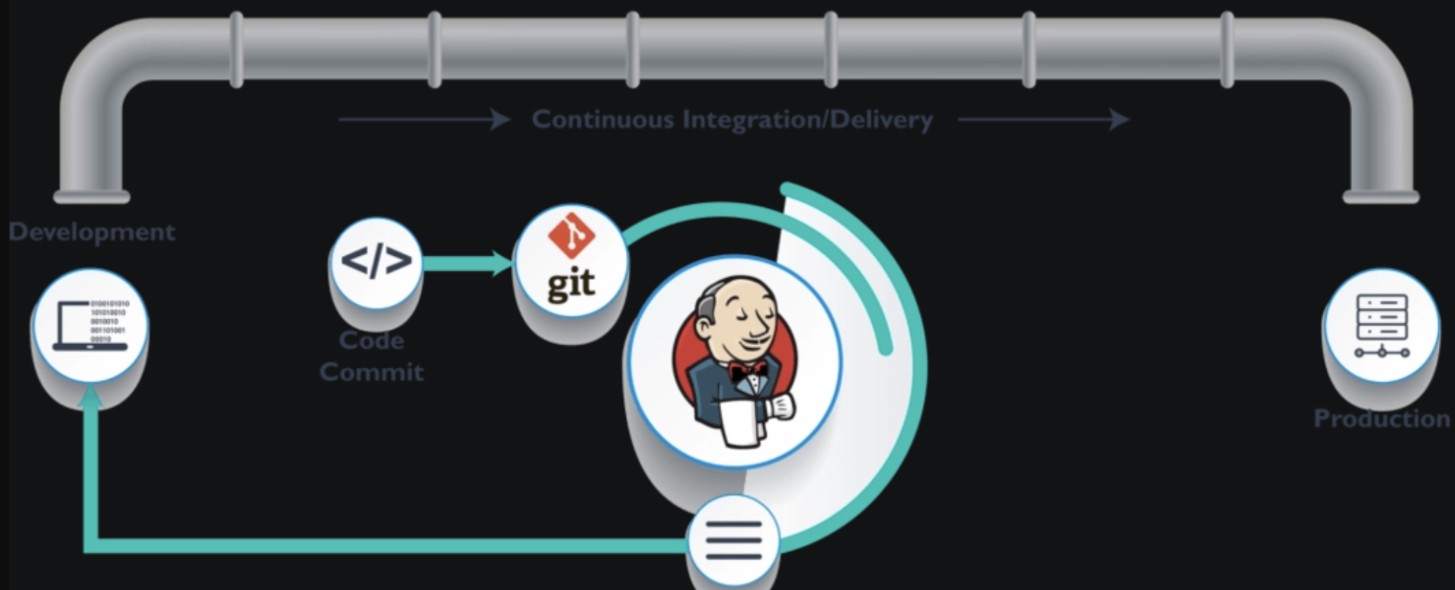
详解Jenkins Pipeline 中git 命令的使用方法
在 Jenkins Pipeline 中,git 命令是用于从版本控制系统(如 Git)拉取代码的核心步骤。其用法灵活,支持多种配置参数,但需要遵循 Jenkins 流水线语法规范。 一、基础语法 1. 声明式流水线(Declarative Pipe…...

【Mini-F5265-OB开发板试用测评】显示RTC日历时钟
一、前言 本章节承接上期的【Mini-F5265-OB开发板试用测评】硬件SPI方式驱动LCD屏帖子上。灵动微官方提供的“LibSamples_MM32F5260_V0.10.2”SDK中包含一个RTC日历的参考例程,因此将该功能移植到上期工程中,即可达成在LCD屏上显示RTC日历时钟。 官方提…...

【生活】程序员防猝si指南
note 一、定期体检二、均衡饮食,多食用对心脏有保护作用的食物三、每周运动四、减压五、保证睡眠六、戒烟限酒7、控制血压8、警惕流感攻击心脏9、关注牙齿健康10、不要抵触吃药 文章目录 note一、定期体检二、均衡饮食,多食用对心脏有保护作用的食物三、…...

CommandLineRunner详细教程
文章目录 1. CommandLineRunner基础概念和背景1.1 什么是CommandLineRunner?1.1.1 核心概念1.1.2 接口定义 1.2 为什么需要CommandLineRunner?1.3 CommandLineRunner的特点1.3.1 执行时机1.3.2 与ApplicationRunner的区别 2. 环境搭建和项目结构2.1 Mave…...

Github 2025-06-05 Go开源项目日报 Top10
根据Github Trendings的统计,今日(2025-06-05统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Go项目10TypeScript项目1Go编程语言:构建简单、可靠和高效的软件 创建周期:3474 天开发语言:Go协议类型:BSD 3-Clause “New” or “Revise…...

C++进阶--C++11--智能指针(重点)
文章目录 C进阶--智能指针(重点)智能指针使用的场景RAII和智能指针的设计思路C标准库智能指针的使用定制删除器智能指针的原理shared_ptr和weak_ptr循环引用(容易考)weak_ptr 其他知识扩展(类型转换)总结个人学习心得结语 很高兴和…...

CSP-38th
目录 1.正态分布 2.走马 3.信息传输 4.字符串可能性个数 5.最多访问节点个数 1.正态分布 本来是很简单的一道模拟题,根据 (n-u) /a 的整数位、十分位确定是在第几行,根据百分位确定是在第几列,但是我直接将 (n-u)/a 乘以100后进行 // 和…...

企业私有化部署DeepSeek实战指南:从硬件选型到安全运维——基于国产大模型的安全可控落地实践
一、部署前的战略评估与规划 私有化部署不仅是技术工程,更是企业数据战略的核心环节。需重点评估三方面: 1、业务场景适配性 适用场景:金融风控(需实时数据处理)、医疗诊断(敏感病历保护)、政…...

【西门子杯工业嵌入式-5-串口实现数据收发】
西门子杯工业嵌入式-5-串口实现数据收发 一、通信基础1.1 什么是通信1.2 嵌入式系统中的通信 二、串行通信原理2.1 串行通信简介2.2 通信参数约定 三、GD32F470 串口资源与性能3.1 串口硬件资源 四、串口通信的实现4.1 串口初始化流程4.2 串口发送函数编写4.3 使用 printf 实现…...
= 0 隐函数 微分法)
F(x,y)= 0 隐函数 微分法
🟦 一、隐函数微分法简介 ▶ 什么是隐函数? 显函数:形如 y f ( x ) y f(x) yf(x),变量之间是显式关系。 隐函数:形如 F ( x , y ) 0 F(x, y) 0 F(x,y)0,变量间不是直接表达的,需要通过…...
深度学习登上Nature子刊!特征选择创新思路
2025深度学习发论文&模型涨点之——特征选择 特征选择作为机器学习与数据挖掘领域的核心预处理步骤,其重要性在当今高维数据时代日益凸显。 通过识别最具判别性的特征子集,特征选择算法能够有效缓解"维度灾难"、提升模型泛化能力&#x…...

面壁智能推出 MiniCPM 4.0 端侧大模型,引领端侧智能新变革
在 2025 智源大会期间,面壁智能重磅发布了开源模型 MiniCPM 4.0 的两个新版本(0.5B、8B),代号「前进四」。此次发布在人工智能领域引发了广泛关注,标志着端侧大模型技术取得了重大突破。 卓越性能,树立行业…...
: 模型压缩与优化)
NLP学习路线图(三十二): 模型压缩与优化
一、 核心压缩与优化技术详解 1. 知识蒸馏:智慧的传承(Knowledge Distillation, KD) 核心思想:“师授徒业”。训练一个庞大、高性能但笨重的“教师模型”(Teacher Model),让其指导训练一个轻量级的“学生模型”(Student Model)。学生模型学习模仿教师模型的输出行为(…...
javaSE复习(7)
1.KMP算法 使用KMP算法在主串 "abaabaabcabaabc" 中搜索模式串 "abaabc",到匹配成功时为止,请问在匹配过程中进行的单个字符间的比较次数是()。 10次 用于互斥时 初值为1 在一个并发编程环境中,…...

算法训练第十一天
150. 逆波兰表达式求值 代码: class Solution(object):def evalRPN(self, tokens):""":type tokens: List[str]:rtype: int"""stack []for i in tokens:if i:b int(stack.pop())a int(stack.pop())stack.append(ab)elif i-:b i…...

【联网玩具】EN 18031欧盟网络安全认证
在当今数字化时代,带联网功能的玩具越来越受到孩子们的喜爱,它们为儿童带来了前所未有的互动体验和学习机会。然而,随着这类玩具的普及,网络安全问题也日益凸显。为了保障儿童使用这类玩具时的安全与隐私,欧盟出台了 E…...