Python 训练营打卡 Day 46
通道注意力
一、什么是注意力
注意力机制是一种让模型学会「选择性关注重要信息」的特征提取器,就像人类视觉会自动忽略背景,聚焦于图片中的主体(如猫、汽车)。 transformer中的叫做自注意力机制,他是一种自己学习自己的机制,他可以自动学习到图片中的主体,并忽略背景。我们现在说的很多模块,比如通道注意力、空间注意力、通道注意力等等,都是基于自注意力机制的。
从数学角度看,注意力机制是对输入特征进行加权求和,输出=∑(输入特征×注意力权重),其中注意力权重是学习到的。所以他和卷积很像,因为卷积也是一种加权求和。但是卷积是 “固定权重” 的特征提取(如 3x3 卷积核)--训练完了就结束了,注意力是 “动态权重” 的特征提取(权重随输入数据变化)---输入数据不同权重不同。
问:为什么需要多种注意力模块? 答:因为不同场景下的关键信息分布不同。例如,识别鸟类和飞机时,需关注 “羽毛纹理”“金属光泽” 等特定通道的特征,通道注意力可强化关键通道;而物体位置不确定时(如猫出现在图像不同位置),空间注意力能聚焦物体所在区域,忽略背景。复杂场景中,可能需要同时关注通道和空间(如混合注意力模块 CBAM),或处理长距离依赖(如全局注意力模块 Non-local)。
问:为什么不设计一个‘万能’注意力模块? 答:主要受效率和灵活性限制。专用模块针对特定需求优化计算,成本更低(如通道注意力仅需处理通道维度,无需全局位置计算);不同任务的核心需求差异大(如医学图像侧重空间定位,自然语言处理侧重语义长距离依赖),通用模块可能冗余或低效。每个模块新增的权重会增加模型参数量,若训练数据不足或优化不当,可能引发过拟合。因此实际应用中需结合轻量化设计(如减少全连接层参数)、正则化(如 Dropout)或结构约束(如共享注意力权重)来平衡性能与复杂度。
通道注意力(Channel Attention)属于注意力机制(Attention Mechanism)的变体,而非自注意力(Self-Attention)的直接变体。可以理解为注意力是一个动物园算法,里面很多个物种,自注意力只是一个分支,因为开创了transformer所以备受瞩目。我们今天的内容用通道注意力举例,常见注意力模块分类如下:
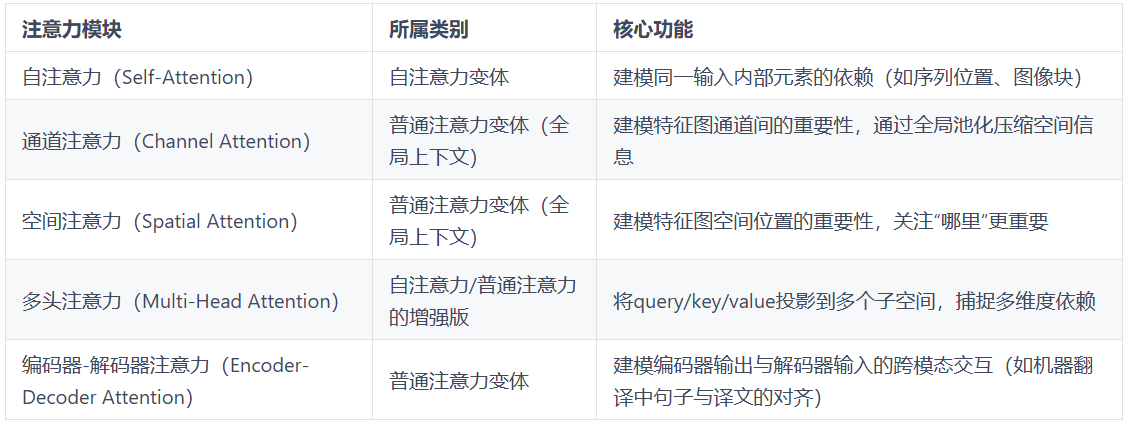
二、特征图的提取
2.1 简单CNN训练
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集:仅进行必要的标准化,保持数据原始特性,标准化不损失数据信息,可还原
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform # 测试集不使用增强
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 50 # 增加训练轮次为了确保收敛
print("开始使用CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_cnn_model.pth')
# print("模型已保存为: cifar10_cnn_model.pth")2.2 特征图的可视化
为了方便观察,我们先尝试提取下特征图。特征图本质就是不同的卷积核的输出,浅层指的是离输入图近的卷积层,浅层卷积层的特征图通常较大,而深层特征图会经过多次下采样,尺寸显著缩小,尺寸差异过大时,小尺寸特征图在视觉上会显得模糊或丢失细节。步骤逻辑如下:
-
初始化设置:
- 将模型设为评估模式,准备类别名称列表(如飞机、汽车等)。
-
数据加载与处理:
- 从测试数据加载器中获取图像和标签。
- 仅处理前
num_images张图像(如2张)。
-
注册钩子捕获特征图:
- 为指定层(如
conv1,conv2,conv3)注册前向钩子。 - 钩子函数将这些层的输出(特征图)保存到字典中。
- 为指定层(如
-
前向传播与特征提取:
- 模型处理图像,触发钩子函数,获取并保存特征图。
- 移除钩子,避免后续干扰。
-
可视化特征图:
- 对每张图像:
- 恢复原始像素值并显示。
- 为每个目标层创建子图,展示前
num_channels个通道的特征图(如9个通道)。 - 每个通道的特征图以网格形式排列,显示通道编号。
- 对每张图像:
关键细节
- 特征图布局:原始图像在左侧,各层特征图按顺序排列在右侧。
- 通道选择:默认显示前9个通道(按重要性或索引排序)。
- 显示优化:
- 使用
inset_axes在大图中嵌入小网格,清晰展示每个通道。 - 层标题与通道标题分开,避免重叠。
- 反标准化处理恢复图像原始色彩。
- 使用
def visualize_feature_maps(model, test_loader, device, layer_names, num_images=3, num_channels=9):"""可视化指定层的特征图(修复循环冗余问题)参数:model: 模型test_loader: 测试数据加载器layer_names: 要可视化的层名称(如['conv1', 'conv2', 'conv3'])num_images: 可视化的图像总数num_channels: 每个图像显示的通道数(取前num_channels个通道)"""model.eval() # 设置为评估模式class_names = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']# 从测试集加载器中提取指定数量的图像(避免嵌套循环)images_list, labels_list = [], []for images, labels in test_loader:images_list.append(images)labels_list.append(labels)if len(images_list) * test_loader.batch_size >= num_images:break# 拼接并截取到目标数量images = torch.cat(images_list, dim=0)[:num_images].to(device)labels = torch.cat(labels_list, dim=0)[:num_images].to(device)with torch.no_grad():# 存储各层特征图feature_maps = {}# 保存钩子句柄hooks = []# 定义钩子函数,捕获指定层的输出def hook(module, input, output, name):feature_maps[name] = output.cpu() # 保存特征图到字典# 为每个目标层注册钩子,并保存钩子句柄for name in layer_names:module = getattr(model, name)hook_handle = module.register_forward_hook(lambda m, i, o, n=name: hook(m, i, o, n))hooks.append(hook_handle)# 前向传播触发钩子_ = model(images)# 正确移除钩子for hook_handle in hooks:hook_handle.remove()# 可视化每个图像的各层特征图(仅一层循环)for img_idx in range(num_images):img = images[img_idx].cpu().permute(1, 2, 0).numpy()# 反标准化处理(恢复原始像素值)img = img * np.array([0.2023, 0.1994, 0.2010]).reshape(1, 1, 3) + np.array([0.4914, 0.4822, 0.4465]).reshape(1, 1, 3)img = np.clip(img, 0, 1) # 确保像素值在[0,1]范围内# 创建子图num_layers = len(layer_names)fig, axes = plt.subplots(1, num_layers + 1, figsize=(4 * (num_layers + 1), 4))# 显示原始图像axes[0].imshow(img)axes[0].set_title(f'原始图像\n类别: {class_names[labels[img_idx]]}')axes[0].axis('off')# 显示各层特征图for layer_idx, layer_name in enumerate(layer_names):fm = feature_maps[layer_name][img_idx] # 取第img_idx张图像的特征图fm = fm[:num_channels] # 仅取前num_channels个通道num_rows = int(np.sqrt(num_channels))num_cols = num_channels // num_rows if num_rows != 0 else 1# 创建子图网格layer_ax = axes[layer_idx + 1]layer_ax.set_title(f'{layer_name}特征图 \n')# 加个换行让文字分离上去layer_ax.axis('off') # 关闭大子图的坐标轴# 在大子图内创建小网格for ch_idx, channel in enumerate(fm):ax = layer_ax.inset_axes([ch_idx % num_cols / num_cols, (num_rows - 1 - ch_idx // num_cols) / num_rows, 1/num_cols, 1/num_rows])ax.imshow(channel.numpy(), cmap='viridis')ax.set_title(f'通道 {ch_idx + 1}')ax.axis('off')plt.tight_layout()plt.show()# 调用示例(按需修改参数)
layer_names = ['conv1', 'conv2', 'conv3']
visualize_feature_maps(model=model,test_loader=test_loader,device=device,layer_names=layer_names,num_images=5, # 可视化5张测试图像 → 输出5张大图num_channels=9 # 每张图像显示前9个通道的特征图
)
上面的图为提取CNN不同卷积层输出的特征图,我们以青蛙的图片进行解读。
由于经过了不断的下采样,特征变得越来越抽象,人类已经无法理解。
核心作用 通过可视化特征图,可直观观察:
- 浅层卷积层(如
conv1)如何捕获边缘、纹理等低级特征。 - 深层卷积层(如
conv3)如何组合低级特征形成语义概念(如物体部件)。 - 模型对不同类别的关注区域差异(如鸟类的羽毛纹理 vs. 飞机的金属光泽)。
conv1 特征图(浅层卷积)
- 特点:
- 保留较多原始图像的细节纹理(如青蛙身体的边缘轮廓)。
- 通道间差异相对小,每个通道都能看到类似原始图像的基础结构(如通道 1 - 9 都能识别边缘、纹理)。
- 意义:
- 提取低级特征(边缘、颜色块、简单纹理),是后续高层特征的“原材料”。
- 类似人眼初步识别图像的轮廓和基础结构。
conv2 特征图(中层卷积)
- 特点:
- 空间尺寸(高、宽)比 conv1 更小(因卷积/池化下采样),但语义信息更抽象。
- 通道间差异更明显:部分通道开始聚焦局部关键特征(如通道 5、8 中黄色高亮区域,可能对应青蛙身体或植物的关键纹理)。
- 意义:
- 对 conv1 的低级特征进行组合与筛选,提取中级特征(如局部形状、纹理组合)。
- 类似人眼从“边缘轮廓”过渡到“识别局部结构”(如青蛙的身体块、植物的叶片簇)。
conv3 特征图(深层卷积)
- 特点:
- 空间尺寸进一步缩小,抽象程度最高,肉眼难直接对应原始图像细节。
- 通道间差异极大,部分通道聚焦全局语义特征(如通道 4、7 中黄色区域,可能对应模型判断“青蛙”类别的关键特征)。
- 意义:
- 对 conv2 的中级特征进行全局整合,提取高级语义特征(如物体类别相关的抽象模式)。
- 类似人眼最终“识别出这是青蛙”的关键依据,模型通过这些特征判断类别。

三、通道注意力
3.1 通道注意力的定义
现在我们引入通道注意力,来观察精度是否有变化,并且进一步可视化。
想要把通道注意力插入到模型中,关键步骤如下:
- 定义注意力模块
- 重写之前的模型定义部分,确定好模块插入的位置
# ===================== 新增:通道注意力模块(SE模块) =====================
class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_ratio=16):"""参数:in_channels: 输入特征图的通道数reduction_ratio: 降维比例,用于减少参数量"""super(ChannelAttention, self).__init__()# 全局平均池化 - 将空间维度压缩为1x1,保留通道信息self.avg_pool = nn.AdaptiveAvgPool2d(1)# 全连接层 + 激活函数,用于学习通道间的依赖关系self.fc = nn.Sequential(# 降维:压缩通道数,减少计算量nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),nn.ReLU(inplace=True),# 升维:恢复原始通道数nn.Linear(in_channels // reduction_ratio, in_channels, bias=False),# Sigmoid将输出值归一化到[0,1],表示通道重要性权重nn.Sigmoid())def forward(self, x):"""参数:x: 输入特征图,形状为 [batch_size, channels, height, width]返回:加权后的特征图,形状不变"""batch_size, channels, height, width = x.size()# 1. 全局平均池化:[batch_size, channels, height, width] → [batch_size, channels, 1, 1]avg_pool_output = self.avg_pool(x)# 2. 展平为一维向量:[batch_size, channels, 1, 1] → [batch_size, channels]avg_pool_output = avg_pool_output.view(batch_size, channels)# 3. 通过全连接层学习通道权重:[batch_size, channels] → [batch_size, channels]channel_weights = self.fc(avg_pool_output)# 4. 重塑为二维张量:[batch_size, channels] → [batch_size, channels, 1, 1]channel_weights = channel_weights.view(batch_size, channels, 1, 1)# 5. 将权重应用到原始特征图上(逐通道相乘)return x * channel_weights # 输出形状:[batch_size, channels, height, width]通道注意力模块的核心原理
Squeeze(压缩):
- 通过全局平均池化将每个通道的二维特征图(H×W)压缩为一个标量,保留通道的全局信息。
- 物理意义:计算每个通道在整个图像中的 “平均响应强度”,例如,“边缘检测通道” 在有物体边缘的图像中响应值会更高。
Excitation(激发):
- 通过全连接层 + Sigmoid 激活,学习通道间的依赖关系,输出 0-1 之间的权重值。
- 物理意义:让模型自动判断哪些通道更重要(权重接近 1),哪些通道可忽略(权重接近 0)。
Reweight(重加权):
- 将学习到的通道权重与原始特征图逐通道相乘,增强重要通道,抑制不重要通道。
- 物理意义:类似人类视觉系统聚焦于关键特征(如猫的轮廓),忽略无关特征(如背景颜色)
通道注意力插入后,参数量略微提高,增加了特征提取能力
3.2 模型的重新定义
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # ---------------------- 第一个卷积块 ----------------------self.conv1 = nn.Conv2d(3, 32, 3, padding=1)self.bn1 = nn.BatchNorm2d(32)self.relu1 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca1 = ChannelAttention(in_channels=32, reduction_ratio=16) self.pool1 = nn.MaxPool2d(2, 2) # ---------------------- 第二个卷积块 ----------------------self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca2 = ChannelAttention(in_channels=64, reduction_ratio=16) self.pool2 = nn.MaxPool2d(2) # ---------------------- 第三个卷积块 ----------------------self.conv3 = nn.Conv2d(64, 128, 3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca3 = ChannelAttention(in_channels=128, reduction_ratio=16) self.pool3 = nn.MaxPool2d(2) # ---------------------- 全连接层(分类器) ----------------------self.fc1 = nn.Linear(128 * 4 * 4, 512)self.dropout = nn.Dropout(p=0.5)self.fc2 = nn.Linear(512, 10)def forward(self, x):# ---------- 卷积块1处理 ----------x = self.conv1(x) x = self.bn1(x) x = self.relu1(x) x = self.ca1(x) # 应用通道注意力x = self.pool1(x) # ---------- 卷积块2处理 ----------x = self.conv2(x) x = self.bn2(x) x = self.relu2(x) x = self.ca2(x) # 应用通道注意力x = self.pool2(x) # ---------- 卷积块3处理 ----------x = self.conv3(x) x = self.bn3(x) x = self.relu3(x) x = self.ca3(x) # 应用通道注意力x = self.pool3(x) # ---------- 展平与全连接层 ----------x = x.view(-1, 128 * 4 * 4) x = self.fc1(x) x = self.relu3(x) x = self.dropout(x) x = self.fc2(x) return x # 重新初始化模型,包含通道注意力模块
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)# 训练模型(复用原有的train函数)
print("开始训练带通道注意力的CNN模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs=50)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")相关文章:
Python 训练营打卡 Day 46
通道注意力 一、什么是注意力 注意力机制是一种让模型学会「选择性关注重要信息」的特征提取器,就像人类视觉会自动忽略背景,聚焦于图片中的主体(如猫、汽车)。 transformer中的叫做自注意力机制,他是一种自己学习自…...
什么是复合索引?)
MySQL(56)什么是复合索引?
复合索引(Composite Index),也称为多列索引,是在数据库表的多列上创建的索引。它可以提高涉及多个列的查询性能,通过组合多个列的值来索引数据。复合索引特别适用于需要同时过滤多列的查询。 复合索引的优点 提高多列…...

Rust学习(1)
声明:学习来源于 《Rust 圣经》 变量的绑定和解构 变量绑定 let a "hello world":这个过程称之为变量绑定。绑定就是把这个对象绑定给一个变量,让这个变量成为它的主人。 变量可变性 Rust 变量默认情况下不可变,可以通过 mut …...
鸿蒙仓颉语言开发实战教程:商城应用个人中心页面
又到了高考的日子,幽蓝君在这里祝各位考生朋友冷静答题,超常发挥。 今天要分享的内容是仓颉语言商城应用的个人中心页面,先看效果图: 下面介绍下这个页面的实现过程。 我们可以先分析下整个页面的布局结构。可以看出它是纵向的布…...

vue3 eslint ts 关闭多单词命名检查
无效做法 import { globalIgnores } from eslint/config import {defineConfigWithVueTs,vueTsConfigs, } from vue/eslint-config-typescript import pluginVue from eslint-plugin-vue import skipFormatting from vue/eslint-config-prettier/skip-formatting// To allow m…...

横向对比npm和yarn
🔧 基本概况 维度npmYarn所属Node.js 官方工具(npm, Inc.)Meta(Facebook)主导开发初始发布时间2010 年2016 年(为了解决 npm 的一些痛点而诞生)默认安装Node.js 安装后自带需要手动安装最新版本…...
智能生成完整 Java 后端架构,告别手动编写 ControllerServiceDao
在 Java 后端开发的漫长征途上,开发者们常常深陷繁琐的基础代码编写泥潭。尤其是 Controller、Service、Dao 这三层代码的手动编写,堪称开发效率的 “拦路虎”。从搭建项目骨架到填充业务逻辑,每一个环节都需要开发者投入大量精力,…...
Python----目标检测(yolov5-7.0安装及训练细胞)
一、下载项目代码 yolov5代码源 GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite yolov5-7.0代码源 Release v7.0 - YOLOv5 SOTA Realtime Instance Segmentation ultralytics/yolov5 GitHub 二、创建虚拟环境 创建一个3.8…...

MySQL EXPLAIN 命令详解
文章目录 MySQL EXPLAIN 命令详解EXPLAIN 输出的基本结构id2. select_type3. table4. partitions5. type6. possible_keys7. key8. key_len9. ref10. rows11. filtered12. Extra 使用 EXPLAIN 的注意事项示例 MySQL EXPLAIN 命令详解 EXPLAIN 是 MySQL 中一个非常有用的命令&a…...

【Linux】文件赋权(指定文件所有者、所属组)、挂载光驱(图文教程)
文章目录 文件赋权创建文件 testChmod查看文件的当前权限使用 chmod 命令修改权限验证权限关键命令总结答案汇总 光驱挂载确认文件是否存在打包压缩压缩验证创建 work 目录将压缩文件复制到 work 目录新建挂载点 /MNT/CDROM 并挂载光驱答案汇总 更多相关内容可查看 此篇用以解决…...
第22讲、Odoo18 QWeb 模板引擎详解
Odoo QWeb 模板引擎详解与实战 Odoo 的 QWeb 是其自研的模板引擎,广泛应用于 HTML、XML、PDF 等内容的生成,支撑了前端页面渲染、报表输出、门户页面、邮件模板等多种场景。本文将系统介绍 QWeb 的核心用法、工作原理,并通过实战案例演示如何…...

OpenJudge | 大整数乘法
总时间限制: 1000ms 内存限制: 65536kB 描述 求两个不超过200位的非负整数的积。 输入 有两行,每行是一个不超过200位的非负整数,没有多余的前导0。 输出 一行,即相乘后的结果。结果里不能有多余的前导0,即如果结果是342&am…...

【原理解析】为什么显示器Fliker dB值越大,闪烁程度越轻?
显示器Fliker 1 显示器闪烁现象说明2 Fliker量测方法2.1 FMA法2.2 JEITA法问题答疑:为什么显示器Fliker dB值越大,闪烁程度越轻? 3 参考文献 1 显示器闪烁现象说明 当一个光源闪烁超过每秒10次以上就可在人眼中产生视觉残留,此时…...

Bootstrap Table开源的企业级数据表格集成
Bootstrap Table 是什么 Bootstrap Table 是一个基于 Bootstrap 框架的开源插件,专为快速构建功能丰富、响应式的数据表格而设计。 它支持排序、分页、搜索、导出等核心功能,并兼容多种 CSS 框架(如 Semantic UI、Material Design 等&am…...

JDK8新特性之Steam流
这里写目录标题 一、Stream流概述1.1、传统写法1.2、Stream写法1.3、Stream流操作分类 二、Stream流获取方式2.1、根据Collection获取2.2、通过Stream的of方法 三、Stream常用方法介绍3.1、forEach3.2、count3.3、filter3.4、limit3.5、skip3.6、map3.7、sorted3.8、distinct3.…...
vue3表格使用Switch 开关
本示例基于vue3 element-plus 注:表格数据返回状态值为0、1。开关使用 v-model"scope.row.state 0" 会报错 故需要对写法做些修改,效果图如下 <el-table-column prop"state" label"入学状态" width"180" …...

【11408学习记录】考研写作双核引擎:感谢信+建议信复合结构高分模板(附16年真题精讲)
感谢信建议信 英语写作2016年考研英语(二)真题小作文题目分析写作思路第一段第二段锦囊妙句9:锦囊妙句12:锦囊妙句13:锦囊妙句18: 第三段 妙句成文 每日一句词汇第一步:找谓语第二步:…...

一套个人知识储备库构建方案
写文章的初心是做知识沉淀。 好记性不如烂笔头,将阶段性的经验总结成文章,下次遇到相同的问题时,查起来比再次去搜集资料快得多。 然而,当文章越来越多时,有一个问题逐渐开始变得“严峻”起来。 比如,我…...

行李箱检测数据集VOC+YOLO格式2083张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2083 标注数量(xml文件个数):2083 标注数量(txt文件个数):2083 …...

QT进阶之路:带命名空间的自定义控件在Qt设计器与qss中的使用技巧
文章目录 0.前言1.带命名空间Qt自定义类在QT设计器中的使用技巧1.1 定义一个带命令空间QLabel自定义类1.2 在QT设计器中引入自定义控件类 2.带命名空间Qt自定义类在qss中的使用技巧2.1 命名空间在 QSS 中的特殊语法2.1 在QSS中定义带命名空间的样式 3.在项目中使用带命名空间的…...

矩阵详解:从基础概念到实际应用
矩阵详解:从基础概念到实际应用 目录 矩阵的基本概念矩阵的类型矩阵运算特殊矩阵矩阵的逆与伴随矩阵的秩与等价分块矩阵矩阵的应用 矩阵知识体系思维导图 mindmaproot((矩阵))基本概念定义mn数表元素aij矩阵记号基本术语行数和列数方阵与非方阵矩阵相等矩阵类型…...

Prompt工程学习之自我一致性
自我一致性 (Self-consistency) 概念:该技术通过对同一问题采样不同的推理路径,并通过多数投票选择最一致的答案,来解决大语言模型(LLM)输出的可变性问题。通过使用不同的温度(temp…...

实践提炼,EtherNet/IP转PROFINET网关实现乳企数字化工厂增效
乳企数字化工厂的核心技术应用 1. 智能质检:机器视觉协议网关的协同 液态奶包装线(利乐罐装)的漏码检测生产线,其高速产线(20,000包/小时)需实时识别微小缺陷,但视觉系统(康耐视Ca…...

从以物换物到DeFi:交易的演变与Arbitrum的DeFi生态
交易的本质:从以物换物到现代金融 交易是人类社会经济活动的核心,是通过交换资源(如货物、服务或货币)满足各方需求的行为。其本质是价值交换,旨在实现资源的优化配置。交易的历史可以追溯到人类文明的起源࿰…...

一文掌握 Tombola 抽象基类的自动化子类测试策略
深入解析 Python 抽象基类的自动化测试框架设计 在 Python 开发中,抽象基类(ABC)是定义接口规范的强大工具。本文将以 Tombola 抽象基类为例,详细解析其子类的自动化测试框架设计,展示如何通过 Python 的内省机制实现…...

vue.js not detected解决方法
如果你在开发环境中遇到“Vue.js not detected”的错误,这通常意味着你的项目没有正确设置或者配置以识别Vue.js。下面是一些解决这个问题的步骤: 1. 确认Vue.js已正确安装 首先,确保你的项目中已经正确安装了Vue.js。你可以通过以下命令来…...

Redis 知识点一
参考 Redis - 常见缓存问题 - 知乎 Redis的缓存更新策略 - Sherlock先生 - 博客园 三种缓存策略:Cache Aside 策略、Read/Write Through 策略、Write Back 策略-CSDN博客 1.缓存问题 1.1.缓存穿透 大量请求未命中缓存,直接访问数据库。 解决办法&…...

分类场景数据集大全「包含数据标注+训练脚本」 (持续原地更新)
一、作者介绍:六年算法开发经验、AI 算法经理、阿里云专家博主。擅长:检测、分割、理解、大模型 等算法训练与推理部署任务。 二、数据集介绍: 质量高:高质量图片、高质量标注数据,吐血标注、整理,可以作为…...
)
数据结构与算法——二叉树高频题目(1)
前言: 简单记录一下自己学习算法的历程,主要根据左老师自己的视频课进行,由于大部分课程涉及题目较多,所以分文章进行记录。 本文将简单记录一下二叉树的层序遍历和 Z 形层次遍历。 参考视频: 算法讲解036【必备】…...

Web后端开发(SpringBootWeb、HTTP、Tomcat快速入门)
目录 SpringBootWeb入门 Spring 需求: 步骤: HTTP协议: 概述: 请求协议: 响应协议: 协议解析: Web服务器-Tomcat: 简介: 基本使用: SpringBootWeb…...