The Quantization Model of Neural Scaling
文章目录
- 摘要
- 1引言
- 2 理论
- 3 概念验证:一个玩具数据集
- 3.1 “多任务稀疏奇偶校验”数据集
- 3.2 幂律规模和新兴能力
- 4 拆解大型语言模型的规模定律
- 4.1 单token损失的分布
- 4.2 单基因(monogenic)与多基因(polygenic)的规模曲线
- 5.1 语言模型量子的自然分布
- 6 相关工作
- 7 讨论
摘要
我们提出了神经网络规模定律的量化模型,该模型既解释了随着模型和数据规模增加损失按幂律下降的现象,也解释了随着规模扩展新能力突然出现的现象。我们基于所谓的“量化假设”推导出该模型,认为网络的知识和技能被“量化”为离散的单元(量子)。我们展示了当这些量子按照使用频率从高到低依次被学习时,使用频率的幂律分布能够解释观察到的损失幂律缩放现象。我们在简单数据集上验证了该预测,并进一步研究了大型语言模型的规模曲线如何分解。通过利用语言模型的梯度信息,我们自动将模型行为分解为多样化的技能集合(量子)。初步发现,这些量子在训练数据中的使用频率大致遵循幂律分布,与语言模型的经验规模指数相对应,这与我们的理论预测相符。
1引言
总体而言,训练规模更大、数据更多的神经网络往往表现优于规模较小、数据较少的神经网络,并且这种性能提升呈现出可预测的规律。在多项研究中,平均测试损失随着网络参数数量(L ∝ N^(-α_N))和训练样本数量(L ∝ D^(-α_D))的增加,都表现出幂律下降的趋势 [1-7]。虽然整体性能随着规模平滑变化,但当具体能力被考察时,较大模型常常表现出“新兴能力”(emergent abilities),即与较小模型有质的不同表现 [8, 9]。理解并调和规模扩展中两方面的表现——损失的幂律可预测下降和新能力的突然出现——既有理论意义,也具备实际价值 [10]。深入理解规模变化如何影响神经网络的学习内容,与核心问题密切相关:深度神经网络内部到底做了什么?它们是否会随着规模继续提升性能?
近期针对神经网络内部机制的研究发现,梯度下降训练过程中网络学习了多种复杂算法 [11-15]。随着对神经网络所学结构(即机械可解释性的任务)的进一步理解,我们可能会发现在模型中存在越来越多可理解的“电路”[11, 16],即在特定情境下实现预测的内部算法。这样的分析方法是否能推广到最前沿的大型模型?若以下两点成立,我们对大规模模型的机械可解释性将更为乐观:(1)可分解性/模块化/稀疏性[18-21]——大型模型可分解为若干部分,且在任意给定样本上的行为通常受少量部分主导;(2)普遍性[22, 11, 23, 24]——相似的结构会在不同规模模型中反复出现。Olsson 等人 [25] 最近发现了“诱导头”(induction heads)在大型语言模型中的普遍存在,并且这些结构在训练过程中表现出离散转变。
本文提出“量化假设”(Quantization Hypothesis),这是一组非正式的猜想,涉及网络可分解为更小部分、不同规模模型计算的普遍性、模型所学知识的离散性,以及数据分布特性如何产生幂律的神经网络规模定律。具体而言,我们假设对于许多预测问题,存在一组特定且可枚举的不可再分割的知识或技能单元,模型必须学习这些内容,而模型性能由成功掌握多少这些单元决定。我们称这些模型性能的基本构建单元为“量子”(quanta):
量子(复数:quanta):一个不可分割的计算模块,例如负责检索某个事实、实现某个算法,或更广义地对应模型所具备的基本技能。
我们使用该术语类比于马克斯·普朗克在1900年提出的能量被量子化为离散块(quanta)的假设——这里我们设想知识和技能被量子化为离散单元(quanta)。由于“量化”(quantization)在机器学习中通常指低精度算术,这里我们建议使用“知识量化”(knowledge quantization)或“技能量化”(skill quantization)来表述我们的概念。我们将看到,支配这些量子“使用频率”的Zipf分布产生了幂律的神经网络规模定律,其本质是规模扩展使模型学习到更多离散的量子,而平滑的规模定律则是对模型性能中多个小的离散跳跃的平均。
本文结构如下:
第2节我们基于量化假设构建幂律神经网络规模定律的理论模型。
第3节我们设计满足该假设的简单数据集,在这些数据集上平滑幂律表现为多个离散性能跳跃的平均。
第4节我们分析幂律规模定律在真实大型语言模型中的分解。
第5节我们开发了一种方法,通过聚类语言模型的行为,自动发现量子(即基本且连贯的技能),并分析这些聚类的统计特性。
最后,第7节进行总结。
2 理论
考虑对互联网文本分布进行建模的任务。由于世界的极端复杂性和多样性,进而导致人类语言的复杂多样,成功的预测需要大量的知识以及执行多样计算的能力。例如,要预测两个物理学家对话中接下来的单词,必须“知道”大量物理学知识;要续写“2534 + 7261 = ”,必须能够进行算术运算(对于足够大的数字,仅靠记忆效率极低)[26]。现实中生成文本的过程中存在大量不同类型的计算,因此文本预测模型也必须具备这些计算能力。
本文提出量化假设(Quantization Hypothesis):
QH1 许多自然的预测问题可以分解为一组可枚举的计算、知识片段或技能,模型必须学习这些以降低损失。我们称这些为“量子”(quanta),并将其建模为离散的——即要么学会,要么未学会。模型性能由已学会哪些量子决定。
QH2 有些量子在降低损失方面比其他量子更有用,因此存在一个自然的量子顺序。我们称这种有序的量子序列为“Q序列”。经过最优训练的网络应当按此顺序学习量子。规模扩展的效果即学习更多Q序列中的量子,因此规模对性能的影响仅由成功学习的量子数决定。
QH3 量子在预测中被使用的频率服从幂律分布。
这三点假设共同导致了幂律神经网络规模定律。我们将量化假设形式化如下,以下内容称为“量化(或量子)模型”。令 q q q为一个比特串,其第 k k k位 q k = 1 q_k=1 qk=1表示第 k k k个Q序列中的量子已被学习, q k = 0 q_k=0 qk=0表示未被学习。根据QH1,平均损失 L L L是 q q q的函数;根据QH2,当已学量子数为 n ≡ ∑ k q k n \equiv \sum_k q_k n≡∑kqk时,有 q k = 1 q_k=1 qk=1对所有 k ≤ n k \leq n k≤n成立。令 L n L_n Ln表示此时的平均损失。根据QH3,第 k k k个量子在随机选取的样本中被用到的概率为
p k = 1 ζ ( α + 1 ) k − ( α + 1 ) ∝ k − ( α + 1 ) (1) p_k = \frac{1}{\zeta(\alpha + 1)} k^{-(\alpha + 1)} \propto k^{-(\alpha + 1)} \tag{1} pk=ζ(α+1)1k−(α+1)∝k−(α+1)(1)
其中 α > 0 \alpha > 0 α>0, ζ ( s ) = ∑ k = 1 ∞ k − s \zeta(s) = \sum_{k=1}^\infty k^{-s} ζ(s)=∑k=1∞k−s为黎曼ζ函数,符合Zipf幂律分布。假设学习第 k k k个量子后,模型在用到该量子的样本上的平均损失从未学前的 b k b_k bk降至已学后的 a k a_k ak。若假设 a k = a a_k = a ak=a, b k = b b_k = b bk=b与 k k k无关,则学习前 n n n个量子的模型的期望损失为:
L n = ∑ k = 1 n a p k + ∑ k = n + 1 ∞ b p k = a + ( b − a ) ∑ k = n + 1 ∞ p k = a + ( b − a ) 1 ζ ( α + 1 ) ∑ k = n + 1 ∞ k − ( α + 1 ) ≈ a + ( b − a ) α ζ ( α + 1 ) n − α (2) \begin{aligned} L_n &= \sum_{k=1}^n a p_k + \sum_{k=n+1}^\infty b p_k \\ &= a + (b - a) \sum_{k=n+1}^\infty p_k \\ &= a + (b - a) \frac{1}{\zeta(\alpha + 1)} \sum_{k=n+1}^\infty k^{-(\alpha + 1)} \\ &\approx a + (b - a) \alpha \zeta(\alpha + 1) n^{-\alpha} \end{aligned} \tag{2} Ln=k=1∑napk+k=n+1∑∞bpk=a+(b−a)k=n+1∑∞pk=a+(b−a)ζ(α+1)1k=n+1∑∞k−(α+1)≈a+(b−a)αζ(α+1)n−α(2)
换言之,当 n → ∞ n \to \infty n→∞时, L ∞ = a L_\infty = a L∞=a,且 ( L n − L ∞ ) ∝ n − α (L_n - L_\infty) \propto n^{-\alpha} (Ln−L∞)∝n−α,表现为幂律衰减。
在附录A中,我们推导了对 a k a_k ak和 b k b_k bk的其他假设条件,发现多种假设下也能得到精确或近似的幂律形式,其中后者包括小的对数修正。
以上推导中,我们假设所有样本为“单基因”(monogenic),即预测最多依赖单个量子,类似生物学中某些单基因遗传特征(如囊性纤维化)仅依赖单个基因。通过此假设,期望损失可写成量子的加权和,权重为依赖该量子的样本比例 p k p_k pk。关于单基因与多基因样本的区别,我们将在第4.2节进一步探讨。
至此,我们展示了量化假设如何产生以学习量子数 n n n为变量的幂律规模定律。接下来给出这一机制如何转化为参数、数据等维度的规模定律:
- 参数规模(Parameter scaling):对于有限规模的网络,容量限制(瓶颈)限定了能学习的量子数。若每个量子需同等容量 C C C个参数,网络参数数为 N N N,则大致能学到的量子数为 n ≈ N C n \approx \frac{N}{C} n≈CN。因此损失函数关于 N N N的表现为
L ( N ) − L ∞ ∝ n − α ≈ ( N C ) − α ∝ N − α L(N) - L_\infty \propto n^{-\alpha} \approx \left(\frac{N}{C}\right)^{-\alpha} \propto N^{-\alpha} L(N)−L∞∝n−α≈(CN)−α∝N−α
得到参数规模的幂律缩放指数 α N = α \alpha_N = \alpha αN=α。
- 数据规模(多轮训练,多 epoch):假设学习第 k k k个量子需训练集中包含至少 τ \tau τ个依赖该量子的样本。训练集大小为 D D D时,约有 D p k D p_k Dpk个样本依赖第 k k k个量子。令临界量子编号为 n n n满足 D p n = τ D p_n = \tau Dpn=τ,由于 p k ∝ k − ( α + 1 ) p_k \propto k^{-(\alpha + 1)} pk∝k−(α+1),则
n ∝ ( D τ ) 1 α + 1 n \propto \left(\frac{D}{\tau}\right)^{\frac{1}{\alpha + 1}} n∝(τD)α+11
因此,损失关于数据量的规模关系为
L ( D ) − L ∞ ∝ n − α ∝ ( D τ ) − α α + 1 ∝ D − α α + 1 L(D) - L_\infty \propto n^{-\alpha} \propto \left(\frac{D}{\tau}\right)^{-\frac{\alpha}{\alpha + 1}} \propto D^{-\frac{\alpha}{\alpha + 1}} L(D)−L∞∝n−α∝(τD)−α+1α∝D−α+1α
得到数据规模的幂律指数
α D = α α + 1 \alpha_D = \frac{\alpha}{\alpha + 1} αD=α+1α
结合前述 α N = α \alpha_N = \alpha αN=α,得
α D = α N α N + 1 \alpha_D = \frac{\alpha_N}{\alpha_N + 1} αD=αN+1αN
关于该关系在各种实证研究中参数和数据规模指数的适用性,我们将在附录F中讨论。
- 数据规模(单轮训练,单 epoch):在多轮训练中,训练数据的信息含量限制学习的量子。单轮训练中,更多训练样本意味着训练时间更长。若每个量子带来的损失下降量遵循幂律,且量子的梯度大小也遵循幂律,则学习每个量子的收敛时间也可能呈幂律。若学习第 k k k个量子的步骤数 ∝ 1 / p k \propto 1/p_k ∝1/pk,则若第一个量子需 T T T步, n n n号量子需 T n α + 1 T n^{\alpha + 1} Tnα+1步,故在 S S S步内能学的量子数为
n = ( S T ) 1 α + 1 n = \left(\frac{S}{T}\right)^{\frac{1}{\alpha + 1}} n=(TS)α+11
对应的训练步骤规模定律为
L ( S ) − L ∞ ∝ n − α ≈ ( S T ) − α α + 1 ∝ S − α α + 1 L(S) - L_\infty \propto n^{-\alpha} \approx \left(\frac{S}{T}\right)^{-\frac{\alpha}{\alpha + 1}} \propto S^{-\frac{\alpha}{\alpha + 1}} L(S)−L∞∝n−α≈(TS)−α+1α∝S−α+1α
幂律指数为
α S = α α + 1 \alpha_S = \frac{\alpha}{\alpha + 1} αS=α+1α
故该模型下单轮和多轮训练的数据规模指数相同: α D = α S \alpha_D = \alpha_S αD=αS。
3 概念验证:一个玩具数据集
本节介绍一个玩具数据集,该数据集包含多个子任务,这些子任务在出现频率上服从幂律分布。我们在该任务上观察到了数据规模和参数规模的幂律神经网络规模定律,且神经网络规模扩展机制与第2节提出的理论一致。因此,对于具有合适结构的数据,量化模型能够产生规模定律。我们将在第4节探讨自然数据集(如自然语言建模)是否具有类似结构。
3.1 “多任务稀疏奇偶校验”数据集
我们构造的玩具任务由许多子任务组成——每种输入类型对应一个特定计算(量子)。每个子任务采用稀疏奇偶校验问题的变体,稀疏奇偶校验问题近来在文献中被研究过[28]。稀疏奇偶校验问题描述简明:给定长度为 n n n的比特串,计算其中固定 k k k个比特的奇偶校验(对2求和取模)。我们引入该任务的扩展版本,称为“多任务稀疏奇偶校验”。除了 n n n和 k k k外,该任务增加参数 n t a s k s ntasks ntasks,表示数据集中不同稀疏奇偶校验子任务的数量。
任务构造如下:首先从 { 1 , 2 , … , n } \{1, 2, \ldots, n\} {1,2,…,n}中随机选择 n t a s k s ntasks ntasks个长度为 k k k的索引子集 S i S_i Si,即 S i ⊂ { 1 , … , n } S_i \subset \{1,\ldots,n\} Si⊂{1,…,n}且 ∣ S i ∣ = k |S_i|=k ∣Si∣=k, i = 1 , 2 , … , n t a s k s i=1,2,\ldots, ntasks i=1,2,…,ntasks。输入比特串长度为 n t a s k s + n ntasks + n ntasks+n。前 n t a s k s ntasks ntasks位称为“控制位”,后 n n n位称为“任务位”。若第 i i i个控制位为激活状态,则计算对应任务位子集 S i S_i Si的奇偶校验。控制位采用one-hot编码:每个输入仅有一个控制位为1,其余为0。如下例所示,若控制位2激活,则输出为任务位中索引为 S 2 = { 2 , 7 } S_2 = \{2,7\} S2={2,7}对应位的奇偶校验,本输入中结果为0:
(此处示例略)
任务位按均匀分布采样,控制位按照Zipf分布采样:第 i i i个控制位为激活状态的概率为
1 Z i − ( α + 1 ) , Z = ∑ i = 1 n t a s k s i − ( α + 1 ) , \frac{1}{Z} i^{-(\alpha + 1)}, \quad Z = \sum_{i=1}^{ntasks} i^{-(\alpha + 1)}, Z1i−(α+1),Z=i=1∑ntasksi−(α+1),
这在子任务间施加幂律分布。由于任务答案是奇偶校验,可以将此任务视为对 { 0 , 1 } n t a s k s + n \{0,1\}^{ntasks + n} {0,1}ntasks+n中满足前 n t a s k s ntasks ntasks位仅一位为1的字符串的二分类问题。
3.2 幂律规模和新兴能力
我们使用单隐层ReLU多层感知机(MLP)训练该任务,采用交叉熵损失。输入维度为 n t a s k s + n ntasks + n ntasks+n。采用Adam优化器,学习率为 10 − 3 10^{-3} 10−3。为研究参数规模对性能的影响,我们训练不同宽度的网络,并在线采样训练批次。单次训练中可研究训练步骤 S S S的规模效应。为研究多轮训练中训练集大小 D D D的规模效应,我们使用容量充足的网络(避免容量瓶颈),采样不同大小 D D D的训练集,训练多轮,记录平均测试损失最低时的性能(采用早停)。
多任务稀疏奇偶校验问题的训练动态十分复杂——每个子任务的损失呈现反“S”形曲线,先保持平缓后快速下降,不同子任务的转折点各异,整体损失曲线因此表现平滑,是多个转折的平均。详见附录B中关于训练动态的讨论。
图2展示了该问题的规模曲线。实验参数为: n t a s k s = 500 ntasks=500 ntasks=500, n = 100 n=100 n=100, k = 3 k=3 k=3, α = 0.4 \alpha=0.4 α=0.4,批量大小为20000。训练集大小从 10 4 10^4 104变动到 5 × 10 6 5 \times 10^6 5×106,隐层宽度从10到500神经元,训练步骤为 2 × 10 5 2 \times 10^5 2×105。与第2节理论一致,随着训练数据和参数规模增长,网络依次学习更多量子(减小更多子任务上的损失),大致遵循子任务出现频率的顺序,这驱动了神经网络的规模扩展。我们发现参数规模扩展比数据规模扩展更噪声,可能与模型初始化影响学习哪些量子有关(数据规模扩展实验中固定了随机种子和模型规模)。此外,在单个子任务上的规模扩展表现出明显的阈值效应:低于某阈值网络无法学习该子任务,高于阈值后表现提升。平滑的幂律规模定律因此可视为子任务性能多次离散跳跃的平均,验证了量化模型作为神经网络规模定律机制的可行性。
附录B提供了更多结果和关于规模指数 α N , α S , α D \alpha_N, \alpha_S, \alpha_D αN,αS,αD与子任务分布幂律指数 α + 1 \alpha + 1 α+1之间经验关系的讨论。
4 拆解大型语言模型的规模定律
本节研究大型语言模型(LLM)规模曲线的组成。我们实验中采用Eleuther AI提供的Pythia模型套件[29],该套件包含一系列不同规模的decoder-only Transformer模型,训练数据约为3000亿个The Pile数据集的tokens[30]。我们在The Pile测试集约1000万个tokens上评估多种模型(参数规模从1900万至64亿,均不含embedding参数),记录每个token的交叉熵损失,从而分析单个token的损失以及损失分布随模型规模的变化。
4.1 单token损失的分布
图3展示了损失分布随模型规模的变化。首先,对于Pythia序列中的前六个模型,平均损失随着参数规模呈幂律下降,幂指数 α N = 0.083 \alpha_N=0.083 αN=0.083,与文献[3]中测得的参数规模指数0.076大致一致。64亿参数模型偏离了该幂律曲线,因此在计算指数时剔除了该模型的损失。接着,我们绘制了单token损失的概率分布 p ( L ) p(L) p(L),发现接近零的损失最为常见,且随着模型规模扩大,近零损失的比例增加。我们还绘制了损失加权的概率密度 L p ( L ) L p(L) Lp(L),其面积即为平均损失。尽管近零损失的token极为常见,但它们对平均损失的贡献较小。图11展示了损失分布随训练步骤变化的情况,区别于本文这里的模型规模变化。值得注意的是,真实大型语言模型中的神经网络规模扩展比多任务稀疏奇偶校验问题更复杂——特别是损失分布具有更丰富的结构。关于与已有神经网络规模模型的兼容性留待后续工作探讨。
4.2 单基因(monogenic)与多基因(polygenic)的规模曲线
在第2节介绍量化假设时,以及第3节多任务稀疏奇偶校验分析中,我们将模型在单个样本上的性能视作由单个量子决定——所有样本均属于单一子任务,该任务要么被解决,要么未被解决(即二元状态)。在我们的模型和多任务稀疏奇偶校验问题中,单个样本的规模曲线均表现出新兴能力——单样本损失在某个特定参数或数据规模处经历了明显的转折。那么,在大型语言模型中是否也存在类似现象?
我们检视了大量单token(单样本)的规模曲线,观察到多样的规模行为。有些样本的损失确实在某一规模上显著下降,但更常见的是损失在多个规模处逐渐改善。如果量化假设成立,且规模扩展的作用仅是向模型添加新的量子,那么单样本损失在多个规模点改善,意味着该样本的预测性能是多个量子的叠加结果。正如第2节所述,我们借用遗传学术语,将模型性能由单个量子决定的问题称为“单基因”(monogenic),由多个量子共同影响的问题称为“多基因”(polygenic),类似单个基因或多个基因决定某遗传特征的概念。多任务稀疏奇偶校验均属单基因问题;而就自然语言而言,我们发现大多数token的模型性能在多个规模点都有提升,暗示多数token属于多基因类型,但也存在损失在单一规模点出现突变的token。多基因性呈连续谱状:不同样本的损失曲线平滑度差异较大,可能反映部分样本依赖较少量子,另一些依赖大量量子。图4展示了单基因和多基因样本的极端示例。
需要说明的是,我们的单基因/多基因分类假设前提是QH1和QH2成立。但也存在以下可能:学习内容本身并非离散,或者规模扩展实质上改变了网络学到的内容,而非简单添加更多量子。是否真如我们描述,规模扩展仅通过添加量子影响性能,有待未来对神经网络内部机制的深入研究。此外,单token损失曲线上出现的尖锐转变也可能源于噪声——若对每个模型规模进行多次随机种子训练,我们可以更好地检验这些转变是均值的平滑递减还是含有真实的离散跳跃,尤其针对表面上“单基因”样本。
5 语言模型的量子(Quanta)
我们提出猜想,语言模型的内部结构和行为可以分解为一组可枚举的模块和相关技能(称为量子)。那么,LLM的这些基本构件可能是什么?本节中,我们提出一种初步方法来发现这些量子。具体来说,我们尝试根据LLM在预测给定上下文中某个token时所依赖的知识或技能,对语言语料中的token进行聚类。我们的目标是找到一些连贯的语言模型行为簇,每个簇都揭示模型学习到的某种独特技能。需要注意的是,在用token聚类以发现量子时,我们做出了一个可能不现实的假设:每个token的预测仅依赖于单一量子(单基因假设)。此外,这些行为簇不会直接给出量子的机械机制,而只是提供未来可深入研究的LLM技能实例。
我们提出使用梯度信息对下一个token的预测样本进行聚类。一个“样本”由一个token及其所在文档中的上下文构成。给定模型,我们将两个样本聚为一类,条件是它们对应的模型损失相对于模型参数的梯度相似。使用梯度的直觉如下:如果模型在两个样本上使用了相同的内部模块生成预测,则该模块参数的梯度可能非零且相似(而与预测无关模块的参数梯度接近零)。若模型在不同样本上调用不同模块,则梯度重叠较少。因此,我们用梯度相似度作为机械相似性的代理——即判断模型是否用类似的机制/模块进行预测。尽管方法粗糙,我们发现梯度包含足够信息,可自动发现多个连贯的LLM行为簇,具体算法如下:
基于梯度的量子发现(Quanta Discovery from Gradients,QDG):
对梯度进行谱聚类,寻找梯度之间具有非零余弦相似度的样本簇。给定样本集 ( x i , y i ) (x_i, y_i) (xi,yi)及模型 f θ f_\theta fθ,计算每个样本的梯度 g i = ∇ θ L ( f θ ( x i ) , y i ) g_i = \nabla_\theta L(f_\theta(x_i), y_i) gi=∇θL(fθ(xi),yi),并归一化为 g ^ i \hat{g}_i g^i使得 g ^ i ⋅ g ^ i = 1 \hat{g}_i \cdot \hat{g}_i = 1 g^i⋅g^i=1。构造矩阵 A A A,其第 i i i行为 g ^ i \hat{g}_i g^i,尺寸为 ( d , n ) (d, n) (d,n),其中 d d d为样本数, n n n为参数数目。计算亲和矩阵 C = A A T C = A A^T C=AAT,其中 C i j = g ^ i ⋅ g ^ j C_{ij} = \hat{g}_i \cdot \hat{g}_j Cij=g^i⋅g^j为梯度余弦相似度。再通过 C ^ i j = 1 − arccos ( C i j ) / π \hat{C}_{ij} = 1 - \arccos(C_{ij}) / \pi C^ij=1−arccos(Cij)/π将相似度映射到 [ 0 , 1 ] [0,1] [0,1]区间。最后用谱聚类对 C ^ \hat{C} C^进行聚类。
QDG计算量大,故仅应用于Pythia套件中最小的模型——拥有1900万非embedding参数。我们对该模型预测准确且置信度高(交叉熵损失低于0.1 nats)的10000个token进行聚类,详见附录C.1。
结果显示,许多(但非全部)QDG聚类揭示了某种连贯的模型行为。图1和图13展示了部分聚类示例。这些聚类使用谱聚类超参数 n clusters = 400 n_\text{clusters}=400 nclusters=400得到。虽然大多数聚类涉及同一token的预测,但人工检查表明,聚类通常基于同一合理原因预测该token,而非仅因输出相同。我们还发现更抽象的预测规则聚类。例如,图1左栏展示的量子是“数字序列递增”的技能,示例包含多种数字token的预测。
5.1 语言模型量子的自然分布
在我们的模型中,某些量子的使用频率高于其他。如果这些频率符合量化假设的幂律分布,则QDG聚类大小应受幂律支配。图3中测得的规模指数 α N = 0.083 \alpha_N = 0.083 αN=0.083暗示量子使用频率的幂律指数约为 − 1.083 -1.083 −1.083。聚类大小是否符合这一规律?
图5展示了不同 n clusters n_\text{clusters} nclusters参数下使用QDG得到的聚类的秩频曲线。秩频曲线将聚类按大小排序,并在图中绘制聚类大小与秩序(排名)关系。由于事先不确定最佳 n clusters n_\text{clusters} nclusters,我们绘制了多条曲线,并从其包络线测量斜率(详见附录E)。聚类算法偏差和梯度噪声导致聚类结果不完美,幂律指数测量误差较大。根据附录E的分析,通过秩频曲线测斜率估测量子使用频率的幂律指数至少有约0.2的误差。部分秩频曲线并非完美幂律。附录E图16中,类似曲线可由高维且有噪声的玩具模型聚类过程产生。我们在秩100至1000区间测得斜率约为 − 1.24 -1.24 −1.24,与预期的 − 1.08 -1.08 −1.08相差约0.16,处于误差范围内。我们对此结果感到鼓舞,发现聚类大小衰减速率大致与神经网络规模定律的幂律指数兼容,符合理论预期。但更精细的聚类方法、更多样本和更大聚类数,或能提升测量精度。
6 相关工作
神经网络规模定律模型:
已有多种神经网络规模定律模型提出。Sharma和Kaplan[31]基于逼近理论论证参数规模上的幂律,指数与数据流形维度 d d d相关。Michaud等[32]指出有效维度 d d d可推广为稀疏组合问题中目标函数计算图的最大元数(arity)。Bahri等[33]推广Sharma和Kaplan模型至数据规模,关联规模指数与某些核函数的幂律谱。Maloney等[34]建立了可精确求解的随机特征模型,导出参数-数据联合规模定律。Bordelon等[35]提出核方法的数据规模定律,将泛化误差分解为特征模态和,而本文则分解为量子。与本文最接近的工作是Hutter[36],其数据规模模型假设需学习离散“特征”集合,特征只要在训练集出现一次即被学习。若特征遵循Zipf分布,期望上产生幂律规模但方差大。我们模型中引入数据阈值 τ ≫ 1 \tau \gg 1 τ≫1降低了规模定律的方差,且考虑了参数规模,应用于实际网络。
理解新兴能力:
Wei等[8]和Srivastava等[37]文档了大语言模型中新兴能力的实例,但Schaeffer等[38]指出这些可能是评估指标的伪像。Arora和Goyal[39]提出“技能”涌现的框架,预测文本时需结合多种语言技能。
杂项:
机器学习中的相变话题并不新颖[40],但本文受Olsson等[25]观察归纳头形成的相变和Nanda等[13]关于相变普遍性的猜想启发。Simon等[41]展示了学习过程分阶段的任务。Chen等[42]构建了LLM技能分层理解和高效数据选择的框架。Chan等[43]研究了Zipf数据分布对上下文学习的影响。
7 讨论
总结:
量化假设提出,对于某些预测问题,模型必须学习一组离散(量化的)模块/知识/技能(量子)。当数据中这些量子的“使用频率”服从幂律分布时,随着模型学习越来越多量子,神经网络规模定律的幂律特性自然产生,平滑的规模曲线实为众多小规模新兴能力的平均。我们展示了一个具备这些性质的玩具数据集;分析了语言模型规模曲线的分解,不仅限于平均损失的变化;并开发了从训练模型内部结构发现量子的方法,成功枚举了小型语言模型的多种技能。我们发现发现的量子在自然文本中的使用频率大致符合理论预测的幂律分布,尽管测量精度有限。
局限性:
量化假设在玩具数据集上成立,但在自然任务(如语言建模)中的适用性仍有待研究。我们最冒险的假设是模型学习内容存在潜在的离散性。实际中,LLM表现出平滑的逐步改进[38],可能更合理的建模是神经网络规模定律反映了一个平滑过程,而非高度多基因的离散量子积累。此外,我们对参数规模 N N N的建模仅考虑网络容量增加,而实际上大模型学习效率更高[7],且参数和数据之间存在权衡,而在我们模型中,参数和数据各自独立限制能学习的量子数量。我们还假设量子相互独立,学习顺序由其使用频率决定,但更合理的假设是量子存在层级依赖关系。最后,QDG方法既不够理论严密,也不可扩展,未来需要发展更优方法来发现量子并研究其统计性质,适用于更大模型和更多样本。
对新兴能力和能力预测的启示:
Srivastava等[37]指出某些任务神经规模扩展表现“线性”,即性能随规模逐渐提升;另一些任务表现“突破性”,即在某规模发生性能跃升。我们的模型解释为:若任务相关量子沿Q序列分布宽广,则表现线性;若任务为单基因或量子聚集,则表现突破性。我们的模型还暗示,若能估计训练语料中某技能对预测的使用频率,则可预测未来能力的出现。
对机械解释性的启示:
若量化假设成立,理解网络可简化为枚举其量子。枚举完成后,量子或可被转化为更可解释的形式(如代码),以供研究和执行,而非仅通过网络运算实现。
展望:
我们将网络分解为量子的观点类似Minsky的“心智社会”理论[44],即心智可拆分为单独无意识的“代理”。若此分解可实现,量子(代理)成为网络内部研究的自然对象。这种中尺度的网络理解,有望成为深度学习的统计物理学,连接微观训练动力学和宏观模型性能。
相关文章:

The Quantization Model of Neural Scaling
文章目录 摘要1引言2 理论3 概念验证:一个玩具数据集3.1 “多任务稀疏奇偶校验”数据集3.2 幂律规模和新兴能力 4 拆解大型语言模型的规模定律4.1 单token损失的分布4.2 单基因(monogenic)与多基因(polygenic)的规模曲…...

数据源指的是哪里的数据,磁盘中还是内存中
在 MyDB 项目中,特别是这段缓存框架代码: T obj getForCache(key);以及它的上下文: AbstractCache 是一个抽象类,内部有两个抽象方法,留给实现类去实现具体的操作: protected abstract T getForCache(lon…...

系统思考:跳出症状看全局
明天将为华为全球采购认证管理部的伙伴们带来一场关于系统思考的深度课程!通过经典的啤酒游戏经营决策沙盘,一起沉浸式体验如何从全局视角看待问题,发现单点最优并不等于全局最优。 这不仅是一次简单的课程,更是一次洞察系统背后…...

DeepSeek R1 V2 深度探索:开源AI编码新利器,效能与创意并进
最近,AI界迎来了一位神秘的“突袭者”——DeepSeek团队悄无声息地发布了其推理模型DeepSeek R1的重磅升级版V2(具体型号R1-0528)。这款基于MIT许可的开源模型,在原版R1的基础上进行了多项令人瞩目的改进,正以其强大的潜…...
surfer15安装
安装文件 安装包和破解文件 安装 破解及汉化 打开软件...

MySQL从入门到DBA深度学习指南
目录 引言 MySQL基础入门 数据库基础概念 MySQL安装与配置 SQL语言进阶 数据库设计与规范化 数据库设计原则 表结构设计 MySQL核心管理 用户权限管理 备份与恢复 性能优化基础 高级管理与高可用 高可用与集群 故障诊断与监控 安全与审计 DBA实战与运维 性能调…...

Python训练营---DAY48
DAY 48 随机函数与广播机制 知识点回顾: 随机张量的生成:torch.randn函数卷积和池化的计算公式(可以不掌握,会自动计算的)pytorch的广播机制:加法和乘法的广播机制 ps:numpy运算也有类似的广播机…...

debian12拒绝海外ip连接
确保 nftables 已安装: Debian 12 默认使用 nftables 作为防火墙框架。检查是否安装: sudo apt update sudo apt install nftables启用并启动 nftables 服务 sudo systemctl enable nftables sudo systemctl start nftables下载maxmind数据库 将文件解…...
70年使用权的IntelliJ IDEA Ultimate安装教程
安装Java环境 下载Java Development Kit (JDK) 从Oracle官网或OpenJDK。推荐选择JDK 11或更高版本。 运行下载的安装程序,按照提示完成安装。注意记录JDK的安装路径(如C:\Program Files\Java\jdk-11.0.15)。 配置环境变量: 右键…...

MySQL的日志
就相当于人的日记本,记录每天发生的事,可以对数据进行追踪 一、错误日志 也就是存放错误信息的 二、二进制日志-binlog 在低版本的MySQL中,二进制日志是不会默认开启的 存放除了查询语句的其他语句 三、查询日志 查询日志会记录客户端的所…...

低功耗高安全:蓝牙模块在安防系统中的应用方案
随着物联网(IoT)和智能家居的快速发展,安防行业正迎来前所未有的技术革新。蓝牙模块作为一种低功耗、高稳定性的无线通信技术,凭借其低成本、易部署和智能化管理等优势,在安防领域发挥着越来越重要的作用。本文将探讨蓝牙模块在安防系统中的应…...
基本操作)
数据库(sqlite)基本操作
数据库(sqlite) 一:简介: 为什么需要单独的数据库来进行管理数据? 数据的各种查询功能数据的备份和恢复花大量时间在文件数据的结构设计和维护上要考虑多线程对数据的操作会涉及到同步问题,会增加很多额…...

【HarmonyOS 5】游戏开发教程
一、开发环境搭建 工具配置 安装DevEco Studio 5.1,启用CodeGenie AI助手(Settings → Tools → AI Assistant)配置游戏模板:选择"Game"类型项目,勾选手机/平板/折叠屏多设备支持 二、游戏引擎核心架构…...

神经元激活函数在神经网络里起着关键作用
神经元激活函数在神经网络里起着关键作用,它能为网络赋予非线性能力,让网络可以学习复杂的函数映射关系。下面从多个方面详细剖析激活函数的作用和意义: 1. 核心作用:引入非线性因素 线性模型的局限性: 假设一个简单…...

[蓝桥杯 2024 国 B] 蚂蚁开会
问题描述 二维平面上有 n 只蚂蚁,每只蚂蚁有一条线段作为活动范围,第 i 只蚂蚁的活动范围的两个端点为 (uix,uiy),(vix,viy)。现在蚂蚁们考虑在这些线段的交点处设置会议中心。为了尽可能节省经费,它们决定只在所有交点为整点的地方设置会议…...
)
GIT(AI回答)
在Git中,git push 命令主要用于将本地分支的提交推送到远程仓库(如GitHub、GitLab等)。如果你希望将本地分支的改动同步到另一个本地分支,这不是 git push 的设计目的。以下是正确的替代方法: 方法1࿱…...

JAVA学习-练习试用Java实现“TF-IDF算法 :用于文本特征提取。”
问题: java语言编辑,实现TF-IDF算法 :用于文本特征提取。 解答思路: TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征提取方法,用于评估一个词语对于一个文件集或一个语料库中的其中一份文件的…...

C++定长内存块的实现
内存池 内存池是指程序预先从操作系统 申请一块足够大内存 ,此后,当程序中需要申请内存的时候,不是直接向操作系统申请,而是 直接从内存池中获取 ; 同理,当 **程序释放内存 **的时候,并不真正将…...

【判断自整除数】2022-4-6
缘由是判断自整除数的,这个我的结果是正确的,但是提交就有运行错误是怎么回事啊-编程语言-CSDN问答 void 自整除数字() {//所谓的自整除数字就是该数字可以整除其每一个位上的数字。 //对一个整数n,如果其各个位数的数字相加得到的数m能整除n,则称n为自…...

使用 Ansible 在 Windows 服务器上安装 SSL 证书系列之二
今天带大家实战一下如何通过ansible在windows 服务器上给iis web site安装证书。 前提条件: 准备一张pfx证书,可以通过openssl工具来生成,具体的步骤请参考帮助文档。一台安装了iis 的windows 服务器 准备inventory文件 [windows] solarwinds ansible_host=20.47.126.72 a…...

Unity使用代码分析Roslyn Analyzers
一、创建项目(注意这里不要选netstandard2.1会有报错) 二、NuGet上安装Microsoft.CodeAnalysis.CSharp 三、实现[Partial]特性标注的类,结构体,record必须要partial关键字修饰 需要继承DiagnosticAnalyzer 注意一定要加特性Diagn…...
大数据CSV导入MySQL
CSV Import MySQL 源码主要特性技术栈快速开始1. 环境要求2. 构建项目3. 使用方式交互式模式命令行模式编程方式使用 核心组件1. CsvService2. DatabaseService3. CsvImportService 数据类型映射性能优化1. 连接池优化2. 批量操作优化3. MySQL配置优化 配置说明application.yml…...
)
GitHub 趋势日报 (2025年06月04日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 1757 onlook 870 nautilus_trader 702 ChinaTextbook 582 system-design-primer 4…...
)
基于sqlite的任务锁(支持多进程/多线程)
前言 介绍 任务锁,在多进程服务间控制耗时任务的锁,确保相同id的耗时任务同时只有一个在执行 依赖 SqliteOp,参考这篇文章 https://blog.csdn.net/weixin_43721000/article/details/137019125 实现方式 utils/taskLock.py import timefrom utils.SqliteOp import Sqli…...

MySQL 索引优化(Explain执行计划) 详细讲解
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 MySQL 索引优化(Explain执行计划…...
Cad 反应器 cad c#二次开发
在 AutoCAD C# 二次开发中,DocumentCollectionEventHandler 是一个委托(delegate),用于处理与 AutoCAD 文档集合(DocumentCollection)相关的事件。它属于 AutoCAD .NET API 的事件处理机制,本质…...

GitOps 核心思想 - 当 Git 成为唯一信源
GitOps 核心思想 - 当 Git 成为唯一信源 在我们之前的 CI/CD 系列中,我们构建了一条流水线:GitHub Actions 在代码测试和构建通过后,执行 kubectl apply 命令将变更推送 (Push) 到 Kubernetes 集群。这种模式非常普遍且有效,但当系统规模和团队复杂度增加时,它可能会遇到一…...

【websocket】安装与使用
websocket安装与使用 1. 介绍2. 安装3. websocketpp常用接口4. Websocketpp使用4.1 服务端4.2 客户端 1. 介绍 WebSocket 是从 HTML5 开始支持的一种网页端和服务端保持长连接的 消息推送机制。 传统的 web 程序都是属于 “一问一答” 的形式,即客户端给服务器发送…...
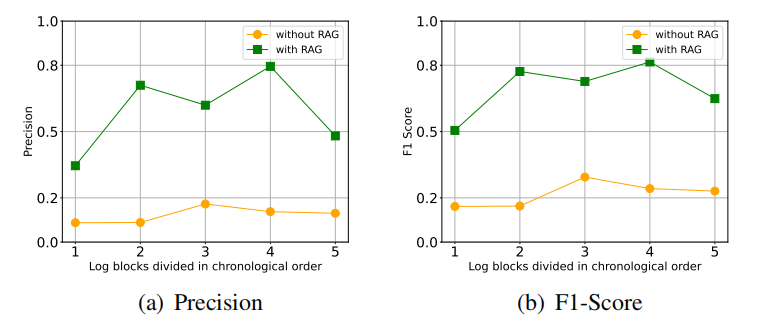
【大模型】LogRAG:基于检索增强生成的半监督日志异常检测
文章目录 A 论文出处B 背景B.1 背景介绍B.2 问题提出B.3 创新点 C 模型结构D 实验设计D.1 数据集/评估指标D.2 SOTAD.3 实验结果 E 个人总结E.1 优点E.2 不足 A 论文出处 论文题目:LogRAG: Semi-Supervised Log-based Anomaly Detection with Retrieval-Augmented …...
基于SpringBoot实现的大创管理系统设计与实现【源码+文档】
基于SpringBootVue实现的大创管理系统采用前后端分离架构方式,系统设计了管理员、学生、指导老师、院系管理员两种角色,系统实现了用户登录与注册、个人中心、学生管理、指导老师管理、院系管理员管理、优秀项目管理、项目类型管理、项目信息管理、项目申…...