【RAG召回】bge实现向量相似度索引
sentence-transformers 是一个非常强大的 Python 框架,它可以将句子或段落转换成高质量、高信息密度的数字向量(称为“嵌入”或 Embeddings)。它厉害的地方在于,语义上相似的句子,其向量在空间中的距离也更近。
这使得我们能够超越简单的关键词匹配,去实现真正理解“意思”的搜索。例如,用户搜索“手提电脑”,我们能轻松地找出包含“笔记本电脑”的文档。
下面,我们同样通过一系列代码示例,快速上手 sentence-transformers。
sentence-transformers 全功能中文示例
本篇将展示如何使用 sentence-transformers 进行向量生成和相似度搜索。
准备工作
首先,你需要安装 sentence-transformers。它依赖于 PyTorch,通常会自动安装。同时,我们也会用到 scikit-learn 来辅助计算。
# 推荐同时安装 scikit-learn 以便使用其中的工具
pip install sentence-transformers scikit-learn
示例 1:将文本转换为向量
向量搜索的第一步,也是最关键的一步,就是将文本转换为数字向量。
from sentence_transformers import SentenceTransformer# 1. 加载一个预训练好的中文模型
# 'shibing624/text2vec-base-chinese' 是一个常用且效果不错的中文模型
# 第一次运行时会自动下载模型,请耐心等待
model = SentenceTransformer('shibing624/text2vec-base-chinese')# 2. 准备要编码的句子
sentences = ["今天天气真不错","今天天气很糟糕","我爱吃北京烤鸭"
]# 3. 使用 model.encode() 将句子转换为向量
embeddings = model.encode(sentences)print("向量的维度:", embeddings.shape)
print("\n第一个句子的向量 (部分展示):")
print(embeddings[0][:5]) # 向量很长,我们只看前5个维度
运行结果:
向量的维度: (3, 768)第一个句子的向量 (部分展示):
[-0.4398335 -0.43577313 0.0303108 -0.2334005 0.2187311 ]
可以看到,每个句子都被转换成了一个包含768个数字的向量。
示例 2:计算句子间的相似度
拿到向量后,我们就可以通过计算它们之间的“余弦相似度”(Cosine Similarity)来判断其语义的接近程度。分数范围在-1到1之间,越接近1代表越相似。
from sentence_transformers import SentenceTransformer, utilmodel = SentenceTransformer('shibing624/text2vec-base-chinese')# 我们有两个句子列表
sentences1 = ['一个男人在弹吉他', '一只猫在玩毛线球']
sentences2 = ['有个人正在演奏乐器', '那个动物在睡觉', '一个男人在弹奏吉他']# 将它们全部编码为向量
embeddings1 = model.encode(sentences1)
embeddings2 = model.encode(sentences2)# 2. 使用 util.cos_sim 计算相似度矩阵
# 这会计算 sentences1 中每个句子与 sentences2 中每个句子之间的相似度
cosine_scores = util.cos_sim(embeddings1, embeddings2)# 打印结果
for i in range(len(sentences1)):for j in range(len(sentences2)):print(f"'{sentences1[i]}' vs '{sentences2[j]}' 的相似度: {cosine_scores[i][j]:.4f}")print("-" * 30)运行结果:
'一个男人在弹吉他' vs '有个人正在演奏乐器' 的相似度: 0.7410
'一个男人在弹吉他' vs '那个动物在睡觉' 的相似度: 0.0526
'一个男人在弹吉他' vs '一个男人在弹奏吉他' 的相似度: 0.9472
------------------------------
'一只猫在玩毛线球' vs '有个人正在演奏乐器' 的相似度: -0.0163
'一只猫在玩毛线球' vs '那个动物在睡觉' 的相似度: 0.5212
'一只猫在玩毛线球' vs '一个男人在弹奏吉他' 的相似度: 0.0210
------------------------------
可以看到,语义相近的句子对(如“弹吉他”和“弹奏吉他”)获得了非常高的相似度分数。
示例 3:构建一个简单的语义搜索引擎
现在,我们可以整合以上步骤,构建一个和 rank-bm25 功能类似的搜索引擎。
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np# --- 准备阶段 ---
model = SentenceTransformer('shibing624/text2vec-base-chinese')corpus = ["北京是中国的首都,也是一座历史悠久的文化名城。","上海是中国的经济中心,拥有繁忙的港口和现代化的建筑。","深圳是中国科技创新的重要城市,被誉为“中国硅谷”。","广州的美食文化闻名全国,是粤菜的发源地。","学习人工智能技术需要扎实的数学基础和编程能力。","中国的历史源远流长,有许多著名的历史人物和事件。"
]# 1. 对语料库进行向量化 (这一步可以预先计算并存储,避免每次查询都重新计算)
print("正在对语料库进行向量化...")
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
print("向量化完成!")# --- 查询阶段 ---
def search(query, top_k=3):# 2. 将查询语句向量化query_embedding = model.encode(query, convert_to_tensor=True)# 3. 计算查询向量与所有语料库向量的余弦相似度# `util.cos_sim` 是 sentence-transformers 的内置函数,更高效cos_scores = util.cos_sim(query_embedding, corpus_embeddings)[0]# 4. 寻找得分最高的 top_k 个结果# np.argpartition 比 np.argsort 更快,因为它只保证第k个位置的元素正确top_results_indices = np.argpartition(-cos_scores, range(top_k))[:top_k]print(f"\n查询: '{query}'")print(f"--- 最相关的 {top_k} 个结果 ---")# 按照分数从高到低排序并输出sorted_indices = top_results_indices[np.argsort(-cos_scores[top_results_indices])]for idx in sorted_indices:print(f"分数: {cos_scores[idx]:.4f} | 文档: {corpus[idx]}")# 执行搜索
search("中国的经济发展怎么样?")
search("历史古都")
运行结果:
正在对语料库进行向量化...
向量化完成!查询: '中国的经济发展怎么样?'
--- 最相关的 3 个结果 ---
分数: 0.6908 | 文档: 上海是中国的经济中心,拥有繁忙的港口和现代化的建筑。
分数: 0.6186 | 文档: 深圳是中国科技创新的重要城市,被誉为“中国硅谷”。
分数: 0.4485 | 文档: 学习人工智能技术需要扎实的数学基础和编程能力。查询: '历史古都'
--- 最相关的 3 个结果 ---
分数: 0.7711 | 文档: 北京是中国的首都,也是一座历史悠久的文化名城。
分数: 0.6695 | 文档: 中国的历史源远流长,有许多著名的历史人物和事件。
分数: 0.4418 | 文档: 广州的美食文化闻名全国,是粤菜的发源地。
即使查询中没有“北京”或“历史”这样的关键词,模型也能理解“历史古都”的含义并找到最相关的句子。
示例 4:在海量数据中挖掘相似句子对
如果你有一个庞大的文本列表,想从中找出所有语义相似的句子对(例如,寻找重复问题、相似评论),util.paraphrase_mining 函数会非常有用。
from sentence_transformers import SentenceTransformer, utilmodel = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2') # 使用一个多语言模型# 假设这是一个论坛的评论列表
comments = ['如何安装这个软件?','我的电脑蓝屏了,求助!','请问这个App怎么安装?','系统崩溃了,怎么办?','这个东西的价格是多少?','售价多少钱?','启动时遇到错误。'
]# 使用 paraphrase_mining 寻找相似度高于 0.8 的句子对
similar_pairs = util.paraphrase_mining(model, comments, show_progress_bar=True, score_threshold=0.8)print("\n--- 找到的相似句子对 (阈值 > 0.8) ---")
for score, i, j in similar_pairs:print(f"分数: {score:.4f}")print(f" - {comments[i]}")print(f" - {comments[j]}")print("-" * 20)运行结果:
Batches: 100%|██████████| 1/1 [00:00<00:00, 8.85it/s]--- 找到的相似句子对 (阈值 > 0.8) ---
分数: 0.9413- 这个东西的价格是多少?- 售价多少钱?
--------------------
分数: 0.9126- 如何安装这个软件?- 请问这个App怎么安装?
--------------------
分数: 0.8037- 我的电脑蓝屏了,求助!- 系统崩溃了,怎么办?
--------------------
这个功能对于数据清洗、文本聚类等任务非常实用。
总结与展望
sentence-transformers 将复杂的深度学习模型封装得极其易用,是实现现代语义搜索的首选工具。
-
优点:
- 理解语义: 能处理同义词、近义词,搜索结果更智能。
- 模型丰富: 拥有大量覆盖多语言、多领域的预训练模型。
- 功能全面: 不仅能搜索,还能用于聚类、信息挖掘等多种NLP任务。
-
下一步进阶:
当你的语料库达到数百万甚至上亿级别时,逐一计算余弦相似度会变得非常缓慢。这时,就需要专门的向量检索引擎了,例如 Faiss (来自Facebook) 或 Annoy (来自Spotify)。这些工具可以创建向量索引,实现**近似最近邻(ANN)**搜索,以微小的精度损失换来成千上万倍的搜索速度提升。
sentence-transformers生成的向量可以无缝对接到这些检索引擎中。
相关文章:

【RAG召回】bge实现向量相似度索引
sentence-transformers 是一个非常强大的 Python 框架,它可以将句子或段落转换成高质量、高信息密度的数字向量(称为“嵌入”或 Embeddings)。它厉害的地方在于,语义上相似的句子,其向量在空间中的距离也更近。 这使得…...
算法-数论
C-小红的数组查询(二)_牛客周赛 Round 95 思路:不难看出a数组是有循环的 d3,p4时,a数组:1、0、3、2、1、0、3、2....... 最小循环节为4,即最多4种不同的数 d4,p6时,a数组:1、5、3、…...
详解)
原型对象(Prototype)详解
原型对象(Prototype)详解 一、核心概念 本质:每个 JavaScript 对象(除 null 外)都有的内置属性作用:实现对象间的属性/方法继承(原型继承)存储位置:[[Prototype]] 内部属性(通过 __proto__ 或 Object.getPrototypeOf() 访问)二、关键特性图示 对象实例 (obj)│├─…...

MongoDB账号密码笔记
先连接数据库,新增用户密码 admin用户密码 use admin db.createUser({ user: "admin", pwd: "yourStrongPassword", roles: [ { role: "root", db: "admin" } ] })用户数据库用户密码 use myappdb db.createUser({ user: &…...

SQL导出Excel支持正则脱敏
SQL to Excel Exporter 源码功能特性核心功能性能优化安全特性 快速开始环境要求安装运行 API 使用说明1. 执行SQL并导出Excel2. 下载导出文件3. 获取统计信息4. 清理过期文件 数据脱敏配置支持的脱敏类型脱敏规则配置示例 配置说明应用配置数据库配置 测试运行单元测试运行集成…...

05.查询表
查询表 字段显示可以使用别名: col1 AS alias1, col2 AS alias2, … WHERE子句:指明过滤条件以实现“选择"的功能: 过滤条件: 布尔型表达式算术操作符:,-,*,/,%比较操作符:,<>(相等或都为空),<>,!(非标准SQL),>,>,<,<范围查询: BETWEEN min_num …...

基于深度强化学习的智能机器人导航系统
前言 随着人工智能技术的飞速发展,机器人在日常生活和工业生产中的应用越来越广泛。其中,机器人导航技术是实现机器人自主移动的关键。传统的导航方法依赖于预设的地图和路径规划算法,但在复杂的动态环境中,这些方法往往难以适应。…...

【第三十九周】ViLT
ViLT 摘要Abstract文章信息介绍提取视觉特征的方式的演变模态融合的两种方式四种不同的 VLP 模型Q&A 方法模型结构目标函数Whole Word Masking(WWM) 实验结果总结 摘要 本篇博客介绍了ViLT(Vision-and-Language Transformer)…...
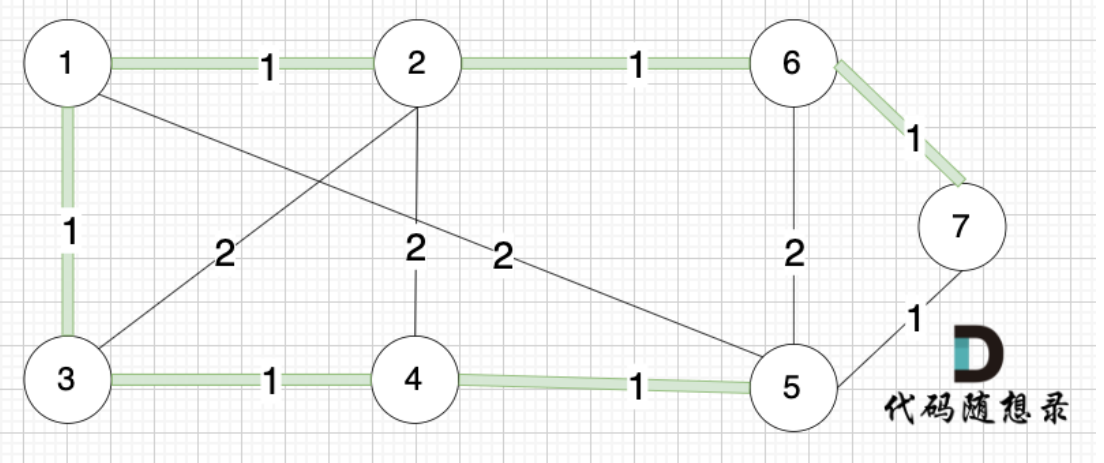
代码随想录算法训练营第60期第六十天打卡
大家好,今天因为有数学建模比赛的校赛,今天的文章可能会简单一点,望大家原谅,我们昨天主要讲的是并查集的题目,我们复习了并查集的功能,我们昨天的题目其实难度不小,尤其是后面的有向图…...

数据结构——D/串
一、串的定义和基本操作  1. 串的定义   1)串的概念   组成结构: 串是由零个或多个字符组成的有限序列,记为 S′a1a2⋯an′Sa_1a_2\cdots a_nS′a1a2⋯an′&#x…...

瀚文机械键盘固件开发详解:HWKeyboard.cpp文件解析与应用
🔥 机械键盘固件开发从入门到精通:HWKeyboard模块全解析 作为一名嵌入式开发老司机,今天带大家拆解一个完整的机械键盘固件代码。即使你是单片机小白,看完这篇教程也能轻松理解机械键盘的工作原理,甚至自己动手复刻一…...

Nginx+Tomcat负载均衡与动静分离架构
目录 简介 一、Tomcat基础部署与配置 1.1 Tomcat应用场景与特性 1.2 环境准备与安装 1.3 Tomcat主配置文件详解 1.4 部署Java Web站点 二、NginxTomcat负载均衡群集搭建 2.1 架构设计与原理 2.2 环境准备 2.3 Tomcat2配置(与Tomcat1对称) 2.4…...
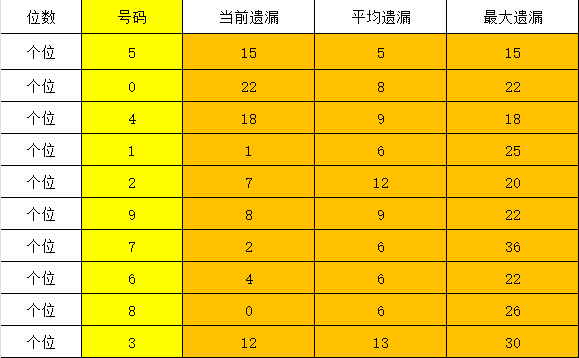
AI+预测3D新模型百十个定位预测+胆码预测+去和尾2025年6月8日第102弹
从今天开始,咱们还是暂时基于旧的模型进行预测,好了,废话不多说,按照老办法,重点8-9码定位,配合三胆下1或下2,杀1-2个和尾,再杀4-5个和值,可以做到100-300注左右。 (1)定…...

LeetCode--25.k个一组翻转链表
解题思路: 1.获取信息: (1)给定一个链表,每k个结点一组进行翻转 (2)余下不足k个结点,则不进行交换 2.分析题目: 其实就是24题的变题,24题是两两一组进行交换&…...

css | class中 ‘.‘ 和 ‘:‘ 的使用 | 如,何时用 .is-selected{ ... } 何时用 :hover{...}?
省流总结:交互时的短暂视觉反馈 → 用 :hover,状态需要记录或切换 → 用类名如 .is-selected。 🧠 本质区别: 写法触发方式用途&.is-selected依赖 class 切换需要 JavaScript 控制状态,如选中、激活&:hover鼠…...
【第九篇】 SpringBoot测试补充篇
简介 本文介绍了SpringBoot测试中的五项关键技术:测试类专用属性加载、 测试类专用Bean配置、 表现层测试方法、测试类事务回滚控制、配置文件随机数据设置)。这些技术可以有效隔离测试环境,确保测试数据不影响生产环境,同时提供了…...
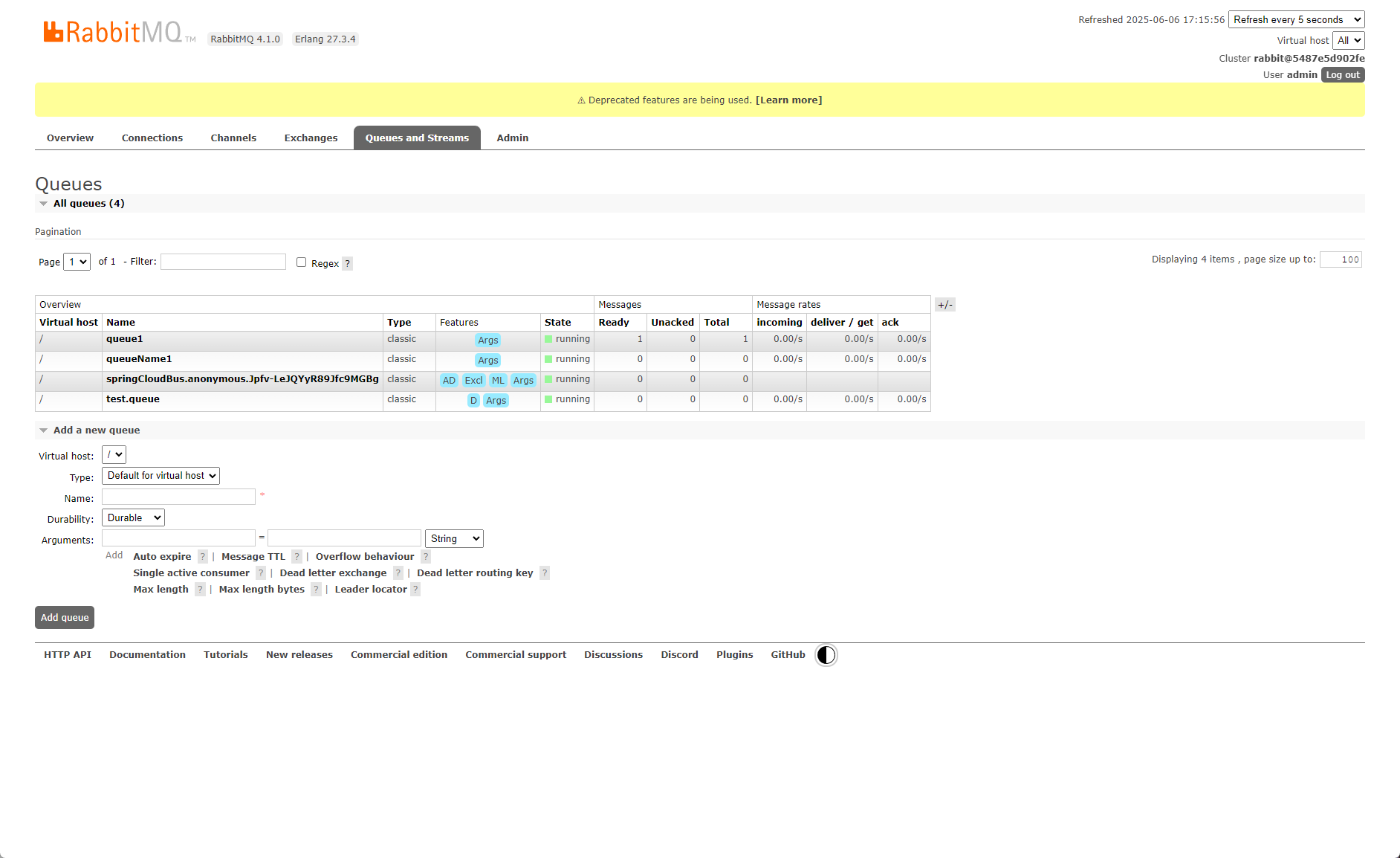
springcloud SpringAmqp消息队列 简单使用
这期只是针对springBoot/Cloud 在使用SpringAmqp消息队列的时候遇到的坑。 前提 如果没有安装RabbitMQ是无法连接成功的!所以前提是你要安装好RabbitMQ。 docker 安装命令 # 拉取docker镜像 docker pull rabbitmq:management# 创建容器 docker run -id --namera…...
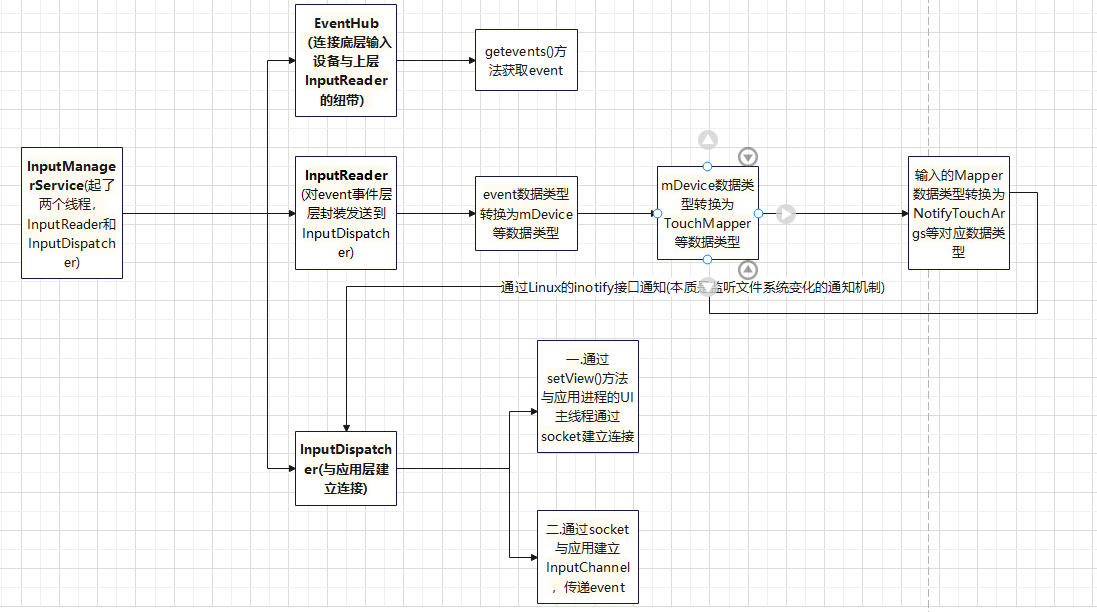
Framework开发之IMS逻辑浅析1--关键线程及作用
关键线程:EventHub,InputReader,InputDispatcher EventHub: 由于Android继承Linux,Linux的思想是一切皆文件,而输入的类型不止一种(触碰,写字笔,键盘等),每种类型都对应一种驱动设备,而每个硬件驱动设备又对应Linux的一个目录文件…...

The Quantization Model of Neural Scaling
文章目录 摘要1引言2 理论3 概念验证:一个玩具数据集3.1 “多任务稀疏奇偶校验”数据集3.2 幂律规模和新兴能力 4 拆解大型语言模型的规模定律4.1 单token损失的分布4.2 单基因(monogenic)与多基因(polygenic)的规模曲…...

数据源指的是哪里的数据,磁盘中还是内存中
在 MyDB 项目中,特别是这段缓存框架代码: T obj getForCache(key);以及它的上下文: AbstractCache 是一个抽象类,内部有两个抽象方法,留给实现类去实现具体的操作: protected abstract T getForCache(lon…...

系统思考:跳出症状看全局
明天将为华为全球采购认证管理部的伙伴们带来一场关于系统思考的深度课程!通过经典的啤酒游戏经营决策沙盘,一起沉浸式体验如何从全局视角看待问题,发现单点最优并不等于全局最优。 这不仅是一次简单的课程,更是一次洞察系统背后…...

DeepSeek R1 V2 深度探索:开源AI编码新利器,效能与创意并进
最近,AI界迎来了一位神秘的“突袭者”——DeepSeek团队悄无声息地发布了其推理模型DeepSeek R1的重磅升级版V2(具体型号R1-0528)。这款基于MIT许可的开源模型,在原版R1的基础上进行了多项令人瞩目的改进,正以其强大的潜…...
surfer15安装
安装文件 安装包和破解文件 安装 破解及汉化 打开软件...

MySQL从入门到DBA深度学习指南
目录 引言 MySQL基础入门 数据库基础概念 MySQL安装与配置 SQL语言进阶 数据库设计与规范化 数据库设计原则 表结构设计 MySQL核心管理 用户权限管理 备份与恢复 性能优化基础 高级管理与高可用 高可用与集群 故障诊断与监控 安全与审计 DBA实战与运维 性能调…...

Python训练营---DAY48
DAY 48 随机函数与广播机制 知识点回顾: 随机张量的生成:torch.randn函数卷积和池化的计算公式(可以不掌握,会自动计算的)pytorch的广播机制:加法和乘法的广播机制 ps:numpy运算也有类似的广播机…...

debian12拒绝海外ip连接
确保 nftables 已安装: Debian 12 默认使用 nftables 作为防火墙框架。检查是否安装: sudo apt update sudo apt install nftables启用并启动 nftables 服务 sudo systemctl enable nftables sudo systemctl start nftables下载maxmind数据库 将文件解…...
70年使用权的IntelliJ IDEA Ultimate安装教程
安装Java环境 下载Java Development Kit (JDK) 从Oracle官网或OpenJDK。推荐选择JDK 11或更高版本。 运行下载的安装程序,按照提示完成安装。注意记录JDK的安装路径(如C:\Program Files\Java\jdk-11.0.15)。 配置环境变量: 右键…...

MySQL的日志
就相当于人的日记本,记录每天发生的事,可以对数据进行追踪 一、错误日志 也就是存放错误信息的 二、二进制日志-binlog 在低版本的MySQL中,二进制日志是不会默认开启的 存放除了查询语句的其他语句 三、查询日志 查询日志会记录客户端的所…...

低功耗高安全:蓝牙模块在安防系统中的应用方案
随着物联网(IoT)和智能家居的快速发展,安防行业正迎来前所未有的技术革新。蓝牙模块作为一种低功耗、高稳定性的无线通信技术,凭借其低成本、易部署和智能化管理等优势,在安防领域发挥着越来越重要的作用。本文将探讨蓝牙模块在安防系统中的应…...
基本操作)
数据库(sqlite)基本操作
数据库(sqlite) 一:简介: 为什么需要单独的数据库来进行管理数据? 数据的各种查询功能数据的备份和恢复花大量时间在文件数据的结构设计和维护上要考虑多线程对数据的操作会涉及到同步问题,会增加很多额…...