【Elasticsearch】映射:Join 类型、Flattened 类型、多表关联设计
映射:Join 类型、Flattened 类型、多表关联设计
- 1.Join 类型
- 1.1 主要应用场景
- 1.1.1 一对多关系建模
- 1.1.2 多层级关系建模
- 1.1.3 需要独立更新子文档的场景
- 1.1.4 文档分离但需要关联查询
- 1.2 使用注意事项
- 1.3 与 Nested 类型的区别
- 2.Flattened 类型
- 2.1 实际运用场景和案例
- 2.1.1 日志数据处理
- 2.1.2 用户自定义属性
- 2.1.3 API 请求/响应存储
- 2.1.4 第三方数据集成
- 2.2 不足之处
- 2.3 与 Nested / Object 类型的对比
- 3.多表关联设计方案
- 3.1 嵌套对象(Nested Objects)
- 3.2 父子文档(Parent-Child Relationship)
1.Join 类型
在 Elasticsearch 中,Join 类型是一种特殊的数据类型,用于在文档之间建立 父子关系 或 嵌套关系。它允许你在索引中创建类似于关系型数据库中的表连接(join)效果。
Join 类型主要通过以下两个字段实现:
join_field:定义关系的字段。relations:指定父子关系的映射。
1.1 主要应用场景
1.1.1 一对多关系建模
当需要表示一个父文档对应多个子文档时,例如:
- 博客文章(父)、评论(子)
- 订单(父)、订单项(子)
PUT my_index
{"mappings": {"properties": {"join_field": {"type": "join","relations": {"post": "comment"}}}}
}
1.1.2 多层级关系建模
需要表示多层级的树形结构,例如:
- 组织架构(公司 → 部门 → 员工)
- 产品分类(大类 → 中类 → 小类)
PUT my_index
{"mappings": {"properties": {"join_field": {"type": "join","relations": {"company": ["department", "employee"],"department": "employee"}}}}
}
1.1.3 需要独立更新子文档的场景
- 场景:当子文档需要频繁独立更新,而父文档相对稳定时。
- 优势:可以单独更新子文档,而不影响父文档。
1.1.4 文档分离但需要关联查询
- 场景:文档逻辑上属于不同实体但需要联合查询。
- 示例:
- 用户基本信息(父)、用户行为日志(子)。
- 产品信息(父)、产品价格历史(子)。
1.2 使用注意事项
- 性能考虑:Join 查询通常比普通查询更耗资源。
- 分片限制:父子文档必须存储在同一个分片上。
- 替代方案:对于简单关系,考虑使用
nested类型或应用层处理。 - 适用版本:Elasticsearch
5.x及以上版本支持。
1.3 与 Nested 类型的区别
| 特性 | Join 类型 | Nested 类型 |
|---|---|---|
| 存储方式 | 独立文档 | 同一文档内嵌 |
| 更新灵活性 | 可单独更新子文档 | 需要更新整个文档 |
| 查询性能 | 相对较慢 | 相对较快 |
| 适用场景 | 大量子文档、频繁更新 | 少量子文档、不常更新 |
Join 类型为 Elasticsearch 提供了处理复杂关系的灵活性,但应根据具体场景权衡使用,因为它在查询性能和资源消耗上会有一定代价。
2.Flattened 类型
Flattened 类型是 Elasticsearch 7.3 版本引入的一种特殊数据类型,主要用于解决以下核心问题:
- 动态字段爆炸问题:当索引包含大量不可预知的动态字段时,会导致映射膨胀,影响集群性能。
- 非结构化数据处理:处理 JSON 文档中未知或高度动态的结构时,避免为每个字段创建独立映射。
- 降低存储开销:减少为大量稀疏字段维护倒排索引的开销。
2.1 实际运用场景和案例
2.1.1 日志数据处理
- 场景:处理不同来源、格式各异的日志数据。
- 案例:集中收集不同应用的日志,各应用日志字段结构不同,且可能随时变化。
PUT logs_index
{"mappings": {"properties": {"log_data": {"type": "flattened"}}}
}
2.1.2 用户自定义属性
- 场景:电商平台中商品的扩展属性。
- 案例:不同类别的商品有完全不同的属性集,且卖家可自定义添加属性。
PUT products
{"mappings": {"properties": {"custom_attrs": {"type": "flattened"}}}
}
2.1.3 API 请求/响应存储
- 场景:记录微服务间通信的请求和响应。
- 案例:不同服务的 API 结构差异大,且版本迭代会导致结构变化。
PUT api_monitor
{"mappings": {"properties": {"request": {"type": "flattened"},"response": {"type": "flattened"}}}
}
2.1.4 第三方数据集成
- 场景:集成来自多个第三方来源的数据。
- 案例:从不同社交平台获取用户数据,各平台数据结构迥异。
2.2 不足之处
- 查询功能限制
- 不支持精确的
term查询,只能使用prefix、wildcard等有限查询方式。 - 无法对
flattened字段中的单个子字段进行独立聚合。
- 不支持精确的
- 搜索性能影响
- 相比常规字段,
flattened字段的查询性能较低。 - 不支持相关性评分(
scoring),所有匹配文档得分相同。
- 相比常规字段,
- 存储效率问题
- 虽然减少了映射膨胀,但存储空间可能比精心设计的映射更大。
- 所有子字段值被索引为关键字,不进行文本分析。
- 功能缺失
- 不支持多字段(
multi-fields)特性。 - 不能指定不同的分析器或分词器。
- 不支持多字段(
- 排序限制
- 不能直接对
flattened字段进行排序操作。
- 不能直接对
2.3 与 Nested / Object 类型的对比
| 特性 | Flattened 类型 | Nested 类型 | Object 类型 |
|---|---|---|---|
| 字段映射膨胀 | 完全避免 | 可能发生 | 可能发生 |
| 查询灵活性 | 有限 | 完全支持 | 完全支持 |
| 存储效率 | 中等 | 较低(重复元数据) | 较高 |
| 适合场景 | 未知 / 动态字段 | 固定结构的数组对象 | 固定结构的嵌套对象 |
| 支持子字段独立查询 / 聚合 | 不支持 | 支持 | 支持 |
Flattened 类型是 Elasticsearch 为特定场景提供的折中方案,它在灵活性和功能完整性之间做了平衡。当面对高度动态、不可预测的数据结构时,它提供了可行的解决方案,但需要清楚其局限性。
3.多表关联设计方案
在 Elasticsearch 中,由于它是面向文档的 NoSQL 数据库,不像关系型数据库那样原生支持 JOIN 操作,因此需要采用特殊的设计方案来实现多表关联。以下是常见的两种方案:
3.1 嵌套对象(Nested Objects)
- 场景:适用于一对多关系,子对象数量较少且不经常独立查询的场景。
- 案例:博客文章与评论。
PUT /blog_index
{"mappings": {"properties": {"title": { "type": "text" },"author": { "type": "keyword" },"comments": {"type": "nested", "properties": {"username": { "type": "keyword" },"content": { "type": "text" },"timestamp": { "type": "date" }}}}}
}
查询嵌套对象:
GET /blog_index/_search
{"query": {"nested": {"path": "comments","query": {"bool": {"must": [{ "match": { "comments.content": "Elasticsearch" }},{ "match": { "comments.username": "john" }}]}}}}
}
3.2 父子文档(Parent-Child Relationship)
- 场景:适用于一对多关系,子对象数量大或需要独立查询的场景。
- 案例:订单与订单项。
PUT /order_index
{"mappings": {"properties": {"order_id": { "type": "keyword" },"order_date": { "type": "date" },"customer_id": { "type": "keyword" },"relation_type": { "type": "join","relations": {"order": "item" }}}}
}
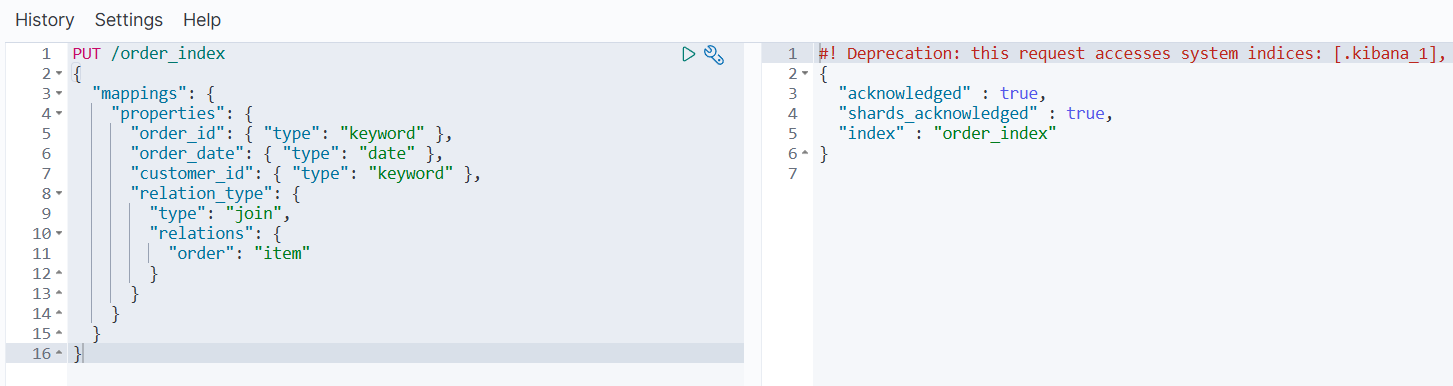
添加父文档(订单):
PUT /order_index/_doc/1
{"order_id": "ORD001","order_date": "2023-01-01","customer_id": "CUST123","relation_type": {"name": "order"}
}
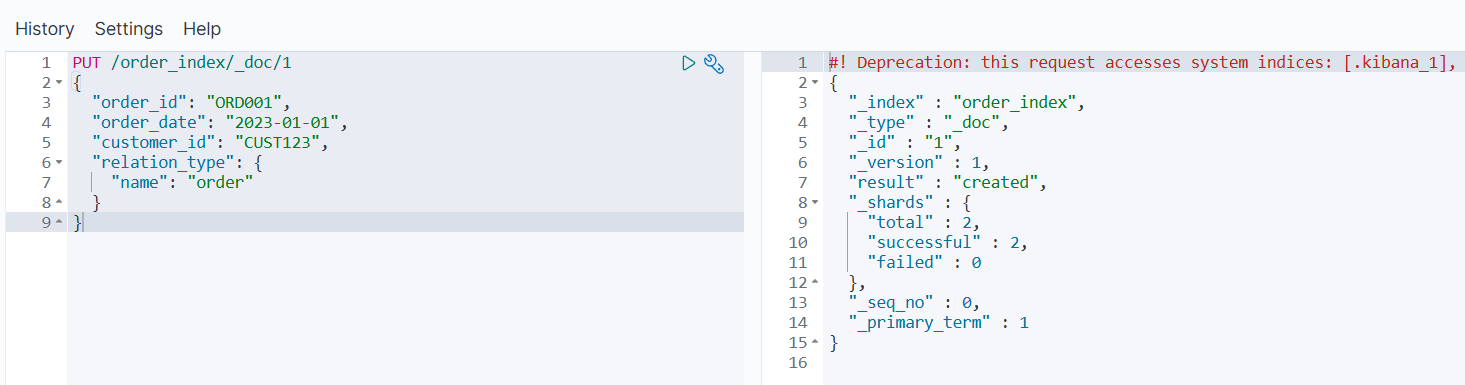
添加子文档(订单项):
PUT /order_index/_doc/2?routing=1
{"product_id": "PROD456","quantity": 2,"price": 19.99,"relation_type": {"name": "item","parent": "1" }
}
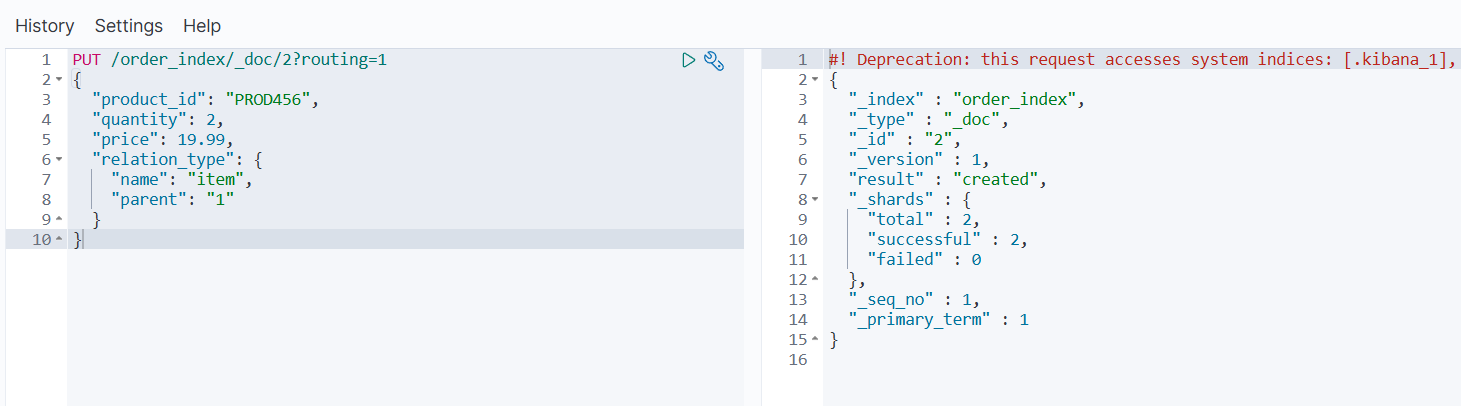
查询子文档:
GET /order_index/_search
{"query": {"has_parent": {"parent_type": "order","query": {"match": { "customer_id": "CUST123" }}}}
}
其他方案还包括:
- 应用层关联:先查询一个索引,再根据结果查询另一个索引。
- 数据冗余:将关联数据冗余存储在主文档中。
- 宽表模式:在索引时预先关联好数据。
选择哪种方案取决于查询模式、数据更新频率和性能要求。
相关文章:
【Elasticsearch】映射:Join 类型、Flattened 类型、多表关联设计
映射:Join 类型、Flattened 类型、多表关联设计 1.Join 类型1.1 主要应用场景1.1.1 一对多关系建模1.1.2 多层级关系建模1.1.3 需要独立更新子文档的场景1.1.4 文档分离但需要关联查询 1.2 使用注意事项1.3 与 Nested 类型的区别 2.Flattened 类型2.1 实际运用场景和…...
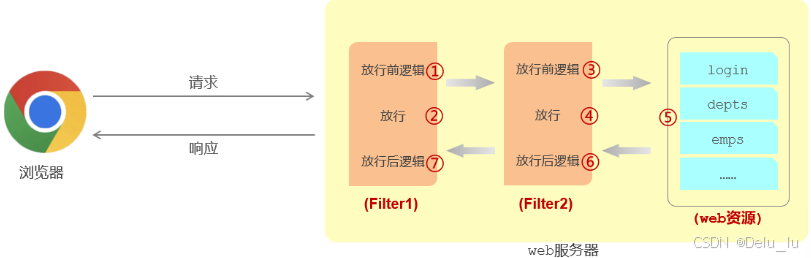
SpringBoot十二、SpringBoot系列web篇之过滤器Filte详解
一、前言 JavaWeb三大组件Servlet、Filter、Listener,其中之一便是过滤器Filter。 其实,Filter我们平常用的不多,一般多为项目初期搭建web架构的时候使用,后面用的就少了,在日常业务开发中不太可能碰到需要手写Filte…...

【RTSP从零实践】1、根据RTSP协议实现一个RTSP服务
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...
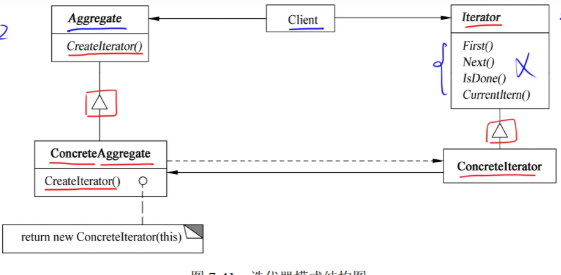
行为设计模式之Iterator(迭代器)
行为设计模式之Iterator(迭代器) 摘要: 迭代器模式(Iterator)是一种行为设计模式,它提供顺序访问聚合对象元素的方法,同时不暴露内部结构。该模式由迭代器接口(Iterator)、具体迭代器(ConcreteIterator)、聚合接口(Ag…...
FPGA点亮ILI9488驱动的SPI+RGB接口LCD显示屏(一)
FPGA点亮ILI9488驱动的SPIRGB接口LCD显示屏 ILI9488 RGB接口初始化 目录 前言 一、ILI9488简介 二、3线SPI接口简介 三、配置寄存器介绍 四、手册和初始化verilog FPGA代码 总结 前言 ILI9488是一款广泛应用于嵌入式系统和电子设备的彩色TFT LCD显示控制器芯片。本文将介…...

6板块公共数据典型应用场景【政务服务|公共安全|公共卫生|环境保护|金融风控|教育科研]
1. 政务服务 1.1 城市规划与管理 公共数据在城市规划与管理中可发挥关键作用。通过汇聚自然资源、建筑物、人口分布等基础数据,构建数字孪生城市模型,辅助城市总体规划编制、决策仿真模拟。在城市基础设施建设、安全运营、应急管理等方面,公共数据也是不可或缺的基础支撑。例…...

如何实现本地mqtt服务器和云端服务器同步?
有时候,一个物联网项目,A客户想要本地使用,B客户想要线上使用,C客户想要本地部署,当有网环境时能线上使用。这个时候就需要本地MQTT服务和线上MQTT服务能相互自动转发。 后来经我一翻研究,其实Activemq支持…...
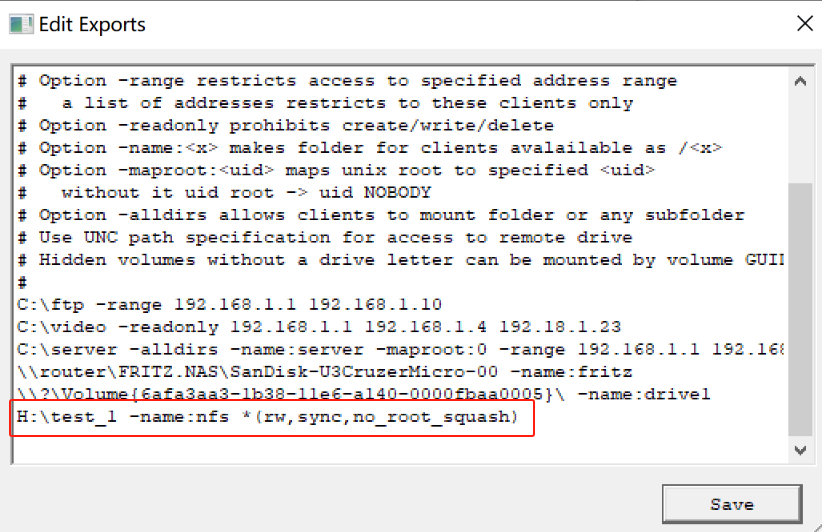
windows10下搭建nfs服务器
windows10下搭建nfs服务器 有参考这篇博客 Windows10搭建NFS服务 - fuzidage - 博客园 下载 NFS Server这个app 通过网盘分享的文件:nfs1268 (1).exe 链接: https://pan.baidu.com/s/1rE4h710Uh-13kWGXvjkZzw 提取码: mwa4 --来自百度网盘超级会员v5的分享 下载后…...
)
CSS中justify-content: space-between首尾贴边中间等距(两端元素紧贴左右边缘,中间元素等距均匀分布)
justify-content: space-between; 是 CSS Flexbox 布局中的一个属性值,主要作用是在弹性容器的主轴方向上均匀分布子元素,具有以下核心特性: 作用效果: 首尾贴边 第一个子元素紧贴容器起始端 最后一个子元素紧贴容器结束端 中…...

【知识扫盲】分布式系统架构或分布式服务中的管理面,数据面和业务面
🧩 一、三大“面”的定义与职责(以大模型推理平台为例) 层级英文名职责关键组件举例数据面Data Plane处理用户请求、模型推理、输入输出数据转换等核心任务模型服务引擎、Tokenizer/Detokenizer、推理加速器(TensorRT、ONNX Runt…...
华为云Flexus+DeepSeek征文|Dify - LLM 云服务单机部署大语言模型攻略指南
前言:在当今人工智能快速发展的时代,华为云推出的 Dify - LLM 对话式 AI 开发平台为企业和开发者提供了便捷的大语言模型应用开发解决方案。 通过在华为云 Flexus 云服务器上单机部署 Dify,并成功集成 DeepSeek 模型,我们能够快速…...
)
Python爬虫:trafilatura 的详细使用(快速提取正文和评论以及结构,转换为 TXT、CSV 和 XML)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、trafilatura 概述1.1 trafilatura介绍1.2 亮点特色1.3 安装二、基本使用2.1 从URL直接提取内容2.2 输出格式控制2.3 从HTML字符串提取2.4 使用命令行工具三、高级功能3.1 全局设置3.2 提取参数定制3.3 多线程批量处…...

Cursor 工具项目构建指南: Uniapp Miniprogram 环境下的 Prompt Rules 约束
简简单单 Online zuozuo: 简简单单 Online zuozuo 简简单单 Online zuozuo 简简单单 Online zuozuo 简简单单 Online zuozuo :本心、输入输出、结果 简简单单 Online zuozuo : 文章目录 Cursor 工具项目构建指南: Uniapp Miniprogram 环境下的 Prompt Rules 约束前言项目简…...
JAVA反序列化应用 : URLDNS案例
反序列化的基本原理 基础普及 : 对象初始化数据方法 :1、使用构造方法 2、使用封装中的 set,get方法 这边我们就使用 1 注意 我们之后还需要进行 接入 序列化的接口 : 先进行序列化 : 反序列化: 反序列化导致的安…...

Vue-Leaflet地图组件开发(三)地图控件与高级样式设计
第三篇:Vue-Leaflet地图控件与高级样式设计 1. 专业级比例尺组件实现 1.1 比例尺控件集成 import { LControl } from "vue-leaflet/vue-leaflet";// 在模板中添加比例尺控件 <l-control-scaleposition"bottomleft":imperial"false&qu…...
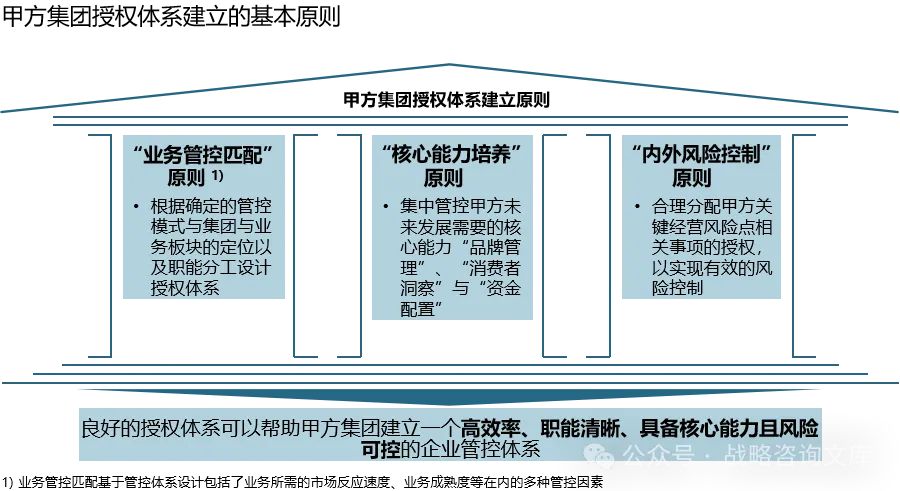
174页PPT家居制造业集团战略规划和运营管控规划方案
甲方集团需要制定一个清晰的集团价值定位,从“指引多元”、“塑造 能力”以及“强化协同”等方面引领甲方做大做强 集团需要通过管控模式、组织架构及职能、授权界面、关键流程、战略 实施和组织演进路径,平衡风险控制和迅速发展,保证战略落地…...

wsl开启即闪退
[ 问题 ]: 在一次电脑卡住,强制关机重启后,遇到打开WSL就闪退的问题在CMD中打开WSL,出现如上图的描述: C:\Users\admin>wsl wsl: 检测到 localhost 代理配置,但未镜像到 WSL。NAT 模式下的 WSL 不支持…...

Spark 写文件
Repartition Spark 输出文件数量 假设每个 Task 的输出数据都包含了全部 8 个分区值,那么最终的文件生成情况如下: 总文件数 = Task 数量 分区组合数 假设: Task 数量:200 分区组合数:8 个 (from_cluster 和 ds 的组合) 则: 总文件数:200 8 = 1600 …...

PostgreSQL 的扩展pg_prewarm
PostgreSQL 的扩展pg_prewarm pg_prewarm 是 PostgreSQL 提供的一个实用扩展,用于将数据预先加载到共享缓冲区或操作系统缓存中,从而提升查询性能。 一、扩展概述 核心功能 手动预热:将指定的表或索引数据加载到内存自动预热:…...

F5 – TCP 连接管理:会话、池级和节点级操作
在 F5 BIG-IP 中,您可以在池成员级别或节点级别管理流向服务器的流量。节点级别状态会影响与该节点关联的所有池,而池成员状态则仅限于单个池。了解每种方法以及何时使用它们对于顺利进行维护窗口和流量管理至关重要。 池级状态:启用、禁用、强制离线、移除 在 BIG-IP 配置…...

金融预测模型开发:数据预处理、机器学习预测与交易策略优化
金融预测模型开发:数据预处理、机器学习预测与交易策略优化 概述 本文将详细介绍一个完整的金融预测模型开发流程,包含数据预处理、机器学习预测和交易策略优化三个核心模块。我们使用Python实现一个端到端的解决方案,适用于股票价格预测和量化交易策略开发。 # 导入必要…...

【P2P】直播网络拓扑及编码模式
以下从 P2P 直播的常见拓扑模式出发,分析各种方案的特点与适用场景,并给出推荐。 一、P2P 直播的核心挑战 实时性要求高 直播场景下,延迟必须控制在可接受范围(通常 <2 秒),同时要保证画面连贯、不卡顿。带宽分布不均 每个节点(观众)上传带宽与下载带宽差异较大,且…...

Python数据可视化科技图表绘制系列教程(二)
目录 表格风格图 使用Seaborn函数绘图 设置图表风格 设置颜色主题 图表分面 绘图过程 使用绘图函数绘图 定义主题 分面1 分面2 【声明】:未经版权人书面许可,任何单位或个人不得以任何形式复制、发行、出租、改编、汇编、传播、展示或利用本博…...

低空城市场景下的多无人机任务规划与动态协调!CoordField:无人机任务分配的智能协调场
作者:Tengchao Zhang 1 ^{1} 1 , Yonglin Tian 2 ^{2} 2 , Fei Lin 1 ^{1} 1, Jun Huang 1 ^{1} 1, Patrik P. Sli 3 ^{3} 3, Rui Qin 2 , 4 ^{2,4} 2,4, and Fei-Yue Wang 5 , 1 ^{5,1} 5,1单位: 1 ^{1} 1澳门科技大学创新工程学院工程科学系࿰…...

算法-构造题
#include<iostream> #include<bits/stdc.h> using namespace std; typedef long long ll; const ll N 5e5 10; int main() {ll n, k;cin >> n >> k; ll a[N] {0}; // 初始化一个大小为N的数组a,用于存储排列// 构造满足条件的排列for (l…...

Go 并发编程深度指南
Go 并发编程深度指南 Go 语言以其内置的并发原语而闻名,通过 goroutine 和 channel 提供了一种高效、安全的并发编程模型。本文将全面解析 Go 的并发机制及其实际应用。 核心概念:Goroutines 和 Channels 1. Goroutines (协程) Go 的轻量级线程实现&…...

PostgreSQL 的扩展pg_freespacemap
PostgreSQL 的扩展pg_freespacemap pg_freespacemap 是 PostgreSQL 提供的一个内置扩展,用于查看表的空闲空间映射(Free Space Map, FSM)信息。这个扩展对于数据库性能调优和空间管理非常有用。 一 扩展概述 功能:提供对表的空…...

【Linux】进程的基本概念
目录 概念描述进程-PCB如何查看进程通过系统目录进行查看通过ps指令进行查看 通过系统调用获取进程的PID和PPID(进程标⽰符)通过系统调用创建子进程通过一段代码来介绍fork为什么要有子进程?fork为什么给子进程返回0,给父进程返回子进程的PIDfork函数到底…...

设备驱动与文件系统:05 文件使用磁盘的实现
从文件使用磁盘的实现逻辑分享 我们现在讲第30讲,内容是文件使用磁盘的具体实现,也就是相关代码是如何编写的。上一节我们探讨了如何从字符流位置算出盘块号,这是文件操作磁盘的核心。而这节课,我们将深入研究实现这一核心功能的…...
AI数据分析在体育中的应用:技术与实践
在现代体育竞技领域,"数据驱动"已不再是一个遥远的概念。尤其随着人工智能(AI)和大数据分析的不断成熟,从职业俱乐部到赛事直播平台,从运动员训练到球迷观赛体验,AI正以前所未有的方式渗透并改变…...