自然语言处理——语言模型
语言模型
- n元文法
- 参数估计
- 数据平滑方法
- 加1法
- 神经网络模型
- 提出原因
- 前馈神经网络(FNN)
- 循环神经网络
n元文法
大规模语料库的出现为自然语言统计处理方法的实现提供了可能,统计方法的成功应用推动了语料库语言学的发展。
语句 𝑠 = 𝑤 1 𝑤 2 … 𝑤 𝑚 𝑠=𝑤_1𝑤_2…𝑤_𝑚 s=w1w2…wm的先验概率
- p ( s ) = p ( w 1 ) × p ( w 2 ∣ w 1 ) p(s)=p(w_1) \times p(w_2|w_1) p(s)=p(w1)×p(w2∣w1)
- p ( s ) = p ( w 1 ) × p ( w 2 ∣ w 1 ) × p ( w 3 ∣ w 1 w 2 ) p(s)=p(w_1) \times p(w_2|w_1) \times p(w_3|w_1w_2) p(s)=p(w1)×p(w2∣w1)×p(w3∣w1w2)
- p ( s ) = p ( w 1 ) × p ( w 2 ∣ w 1 ) × p ( w 3 ∣ w 1 w 2 ) × ⋯ × p ( w m ∣ w 1 … w m − 1 ) p(s)=p\left(w_{1}\right) \times p\left(w_{2} \mid w_{1}\right) \times p\left(w_{3} \mid w_{1} w_{2}\right) \times \cdots \times p\left(w_{m} \mid w_{1} \ldots w_{m-1}\right) p(s)=p(w1)×p(w2∣w1)×p(w3∣w1w2)×⋯×p(wm∣w1…wm−1)
𝑤 𝑖 𝑤_𝑖 wi 可以是字、词、短语或词类等,统称为统计基元。通常以“词”(token)代之; 𝑤 𝑖 𝑤_𝑖 wi 的概率取决于 𝑤 1 𝑤_1 w1,…, 𝑤 𝑖 − 1 𝑤_{𝑖−1} wi−1,条件序列 𝑤 1 𝑤_1 w1,…, 𝑤 𝑖 − 1 𝑤_{𝑖−1} wi−1 称为 𝑤 𝑖 𝑤_𝑖 wi 的历史。
随着历史基元数量的增加,不同的“历史”组合构成的路径数量指数级增长。对于第𝑖(𝑖 > 1)个统计基元,历史基元的个数为𝑖−1,如果共有𝐿个不同的基元,如词汇表,理论上每一个单词都有可能出现在1到𝑖 −1的每一个位置上,那么,𝑖基元就有 𝐿 𝑖 − 1 𝐿^{𝑖−1} Li−1 种不同的历史组合。我们必须考虑在所有𝐿𝑖−1种不同的历史条件下产生第𝑖个基元的概率。那么,对于长度为𝑚的句子,模型中有 𝐿 𝑚 𝐿^𝑚 Lm个自由参数 p ( w m ∣ w 1 … w m − 1 ) p\left(w_{m} \mid w_{1} \ldots w_{m-1}\right) p(wm∣w1…wm−1),如果L=6763,m=3,自由参数的数目为 3.09 × 10 11 3.09\times10^{11} 3.09×1011,这是一个很大的问题。
解决方案:设法减少历史基元的个数,将 𝑤 1 , 𝑤 2 , … , 𝑤 𝑖 − 1 𝑤_1,𝑤_2,…,𝑤_{𝑖−1} w1,w2,…,wi−1映射到等价类S( 𝑤 1 , 𝑤 2 , … , 𝑤 𝑖 − 1 ) 𝑤_1,𝑤_2,…,𝑤_{𝑖−1)} w1,w2,…,wi−1),使等价类的数目远远小于原来不同历史基元的数目。
那么如何划分等价类呢?将两个历史映射到同一个等价类,当且仅当这两个历史中的最近𝑛−1个基元相同,即:

这种计算语言(通常指句子)概率的模型称为语言模型(language model)。由于通常只考虑历史基元与当前词构成𝑛元词序列(即只考虑前𝑛−1个词的历史情况),因此这种模型又称为n
元文法模型(n-gram model)。𝑛为整数,通常𝑛=1~5。
- 当𝑛=1时,出现在第𝑖位置上的基元𝑤𝑖独立于历史,称为一元文法,记作uni-gram或monogram;
- 当𝑛=2时,出现在第𝑖位置上的基元𝑤i只与𝑖−1位置上的基元相关,称为2元文法(2-gram或bi-gram)。2元文法序列又被称为1阶马尔可夫链,2元文法很常见;
- 当𝑛=3时,出现在第𝑖位置上的基元𝑤i与𝑖−2和𝑖−1位置上的基元相关,称为三元文法(3-gram或tri-gram)。三元文法序列又被称为2阶马尔可夫链。
为了保证条件概率在𝑖 = 1时有意义,同时保证句子内所有字符串的概率为1,即 ∑ s p ( s ) = 1 \sum_sp(s)=1 ∑sp(s)=1,可以在句子首尾两端增加两个标志: < B O S > 𝑤 1 𝑤 2 ⋯ 𝑤 𝑚 < E O S > <BOS>𝑤_1𝑤_2⋯𝑤_𝑚<EOS> <BOS>w1w2⋯wm<EOS>。
参数估计
收集、标注大规模样本,我们称其为训练数据/语料,利用最大似然估计(maximum likelihood evaluation, MLE) 方法计算概率。
p ( w i ∣ w i − n + 1 i − 1 ) = f ( w i ∣ w i − n + 1 i − 1 ) = c ( w i − n + 1 i ) ∑ w i c ( w i − n + 1 i ) p\left(w_{i} \mid w_{i-n+1}^{i-1}\right)=f\left(w_{i} \mid w_{i-n+1}^{i-1}\right)=\frac{c\left(w_{i-n+1}^{i}\right)}{\sum_{w_{i}} c\left(w_{i-n+1}^{i}\right)} p(wi∣wi−n+1i−1)=f(wi∣wi−n+1i−1)=∑wic(wi−n+1i)c(wi−n+1i)
举个简单的例子:

数据平滑方法
定义:调整最大似然估计的概率值,使零概率增值,使非零概率下调,“劫富济贫”,消除零概率,改进模型的整体正确率。
目标是为了让测试样本的语言模型困惑度越小越好。
平滑的n-gram概率为 p ( w i ∣ w i − n + 1 i − 1 ) p\left(w_{i} \mid w_{i-n+1}^{i-1}\right) p(wi∣wi−n+1i−1),句子𝑠的概率为: p ( s ) = ∏ i = 1 m + 1 p ( w i ∣ w i − n + 1 i − 1 ) p(s)=\prod_{i=1}^{m+1} p\left(w_{i} \mid w_{i-n+1}^{i-1}\right) p(s)=i=1∏m+1p(wi∣wi−n+1i−1)
假定测试语料𝑇由 𝑙 𝑇 𝑙_𝑇 lT个句子构成:( s 1 , s 2 . . . s l T s_1,s_2...s_{l_T} s1,s2...slT),共含有 w T w_T wT个词,那么整个测试集的概率为: p ( T ) = ∏ i = 1 l T p ( s i ) p(T)=\prod_{i=1}^{l_{T}} p\left(s_{i}\right) p(T)=∏i=1lTp(si)
困惑度可以定义为: P P P ( T ) = 2 − 1 w T log 2 p ( T ) P P_{P}(T)=2^{-\frac{1}{w_{T}} \log _{2} p(T)} PPP(T)=2−wT1log2p(T) ,不难看出,P(T)越接近0,困惑度会特别大。n-gram对于英语文本的困惑度范围一般为10~1000,语言模型设计的任务就是寻找困惑度最小的模型,使其最接近真实的语言。
加1法
基本思想: 每一种情况出现的次数加1。
例如,对于 uni-gram,设 𝑤 1 , 𝑤 2 , 𝑤 3 𝑤_1,𝑤_2,𝑤_3 w1,w2,w3三个词, 𝑤 1 𝑤_1 w1出现1次, 𝑤 2 𝑤_2 w2出现0次, w 3 w_3 w3出现两次,概率分别为:1/3,0,2/3,加1后情况就变为: 2/6,1/6,3/6
对于二元文法有:
p ( w i ∣ w i − 1 ) = 1 + c ( w i − 1 w i ) ∑ w i [ 1 + c ( w i − 1 w i ) ] = 1 + c ( w i − 1 w i ) ∣ V ∣ + ∑ w i c ( w i − 1 w i ) \begin{aligned} p\left(w_{i} \mid w_{i-1}\right) & =\frac{1+c\left(w_{i-1} w_{i}\right)}{\sum_{w_{i}}\left[1+c\left(w_{i-1} w_{i}\right)\right]} \\ & =\frac{1+c\left(w_{i-1} w_{i}\right)}{|V|+\sum_{w_{i}} c\left(w_{i-1} w_{i}\right)}\end{aligned} p(wi∣wi−1)=∑wi[1+c(wi−1wi)]1+c(wi−1wi)=∣V∣+∑wic(wi−1wi)1+c(wi−1wi)
在前面的例题中,原来的概率存在0值:

同样我们还可以求到句子“John read a book”的概率,计算过程如下所示:


神经网络模型
提出原因
首先我们来回顾一下上文提出的n-gram,假设现在有一个句子“这本小说很枯燥,读起来很乏味。”主要会存在以下两个问题:
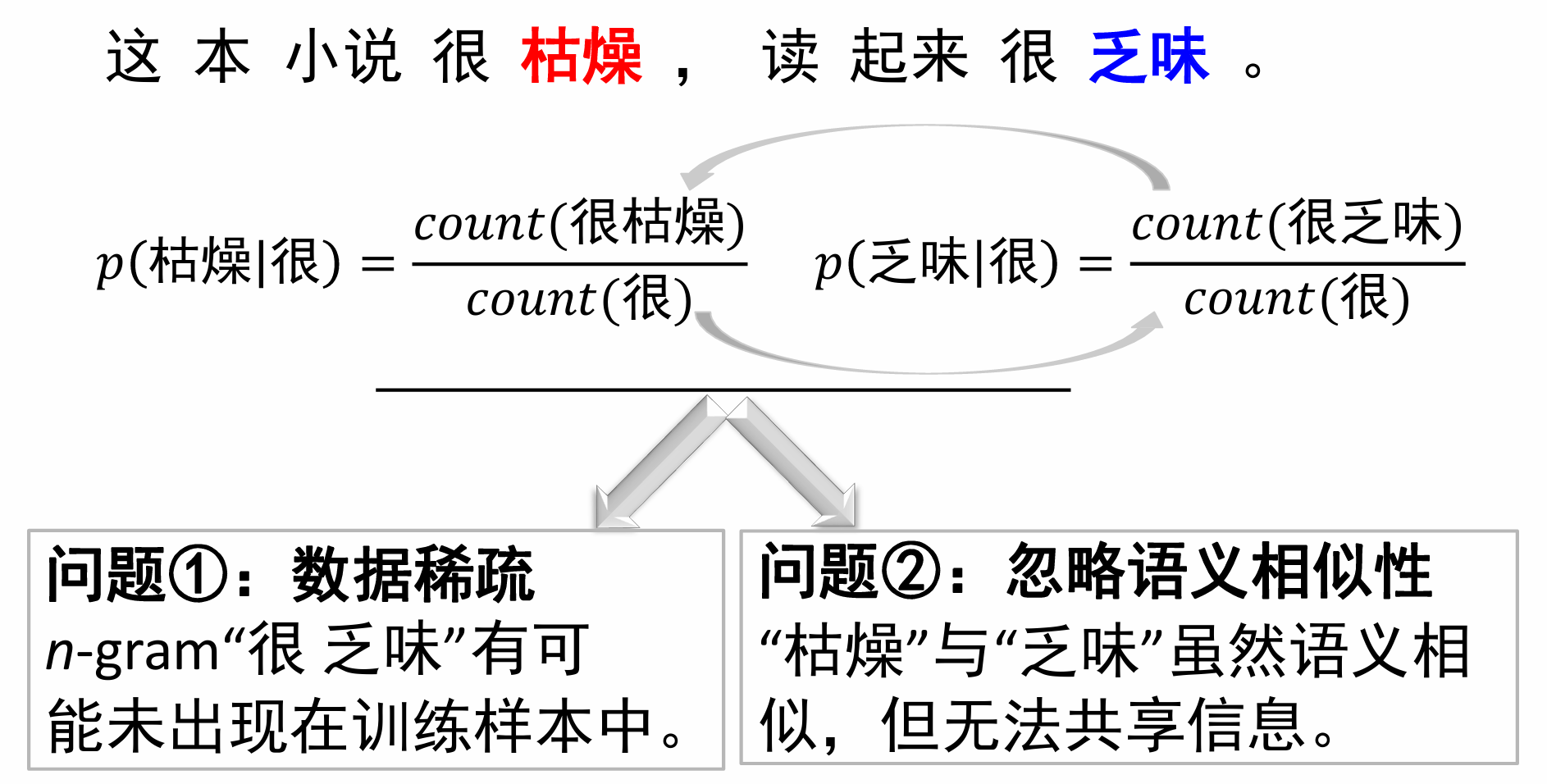
我们来分析一下原因:在n元文法中,“词”以词形本身表示,是离散的符号,这等价于one-hot 向量,这会导致任意两个词之间的相似度都为0。维度太高!
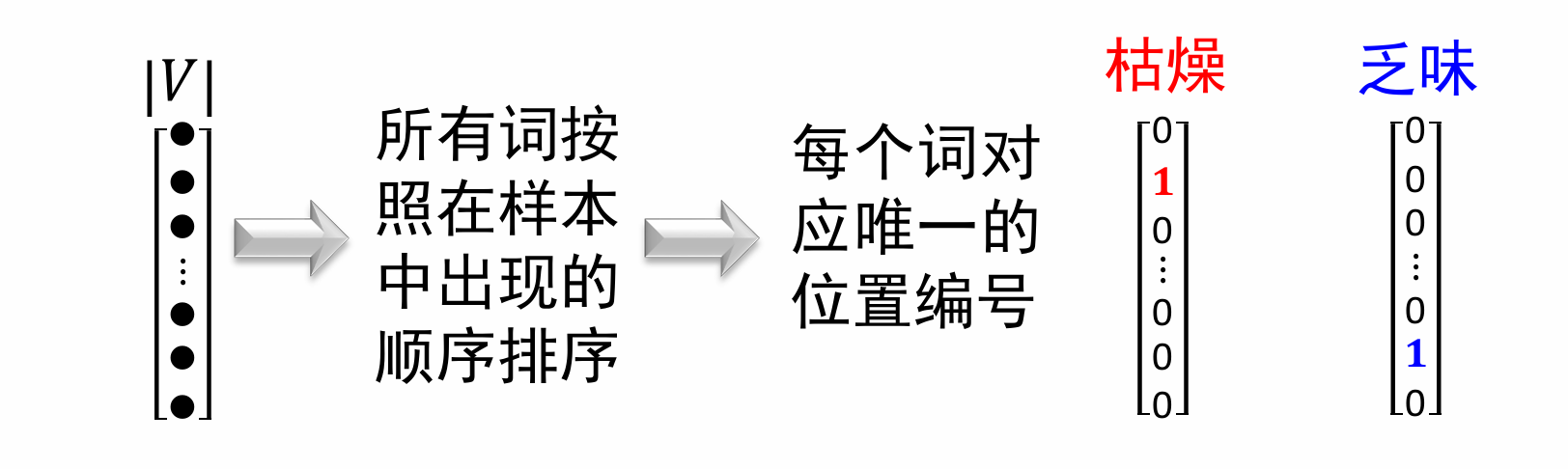
我们需要连续空间的分布式表示赋予词向量!
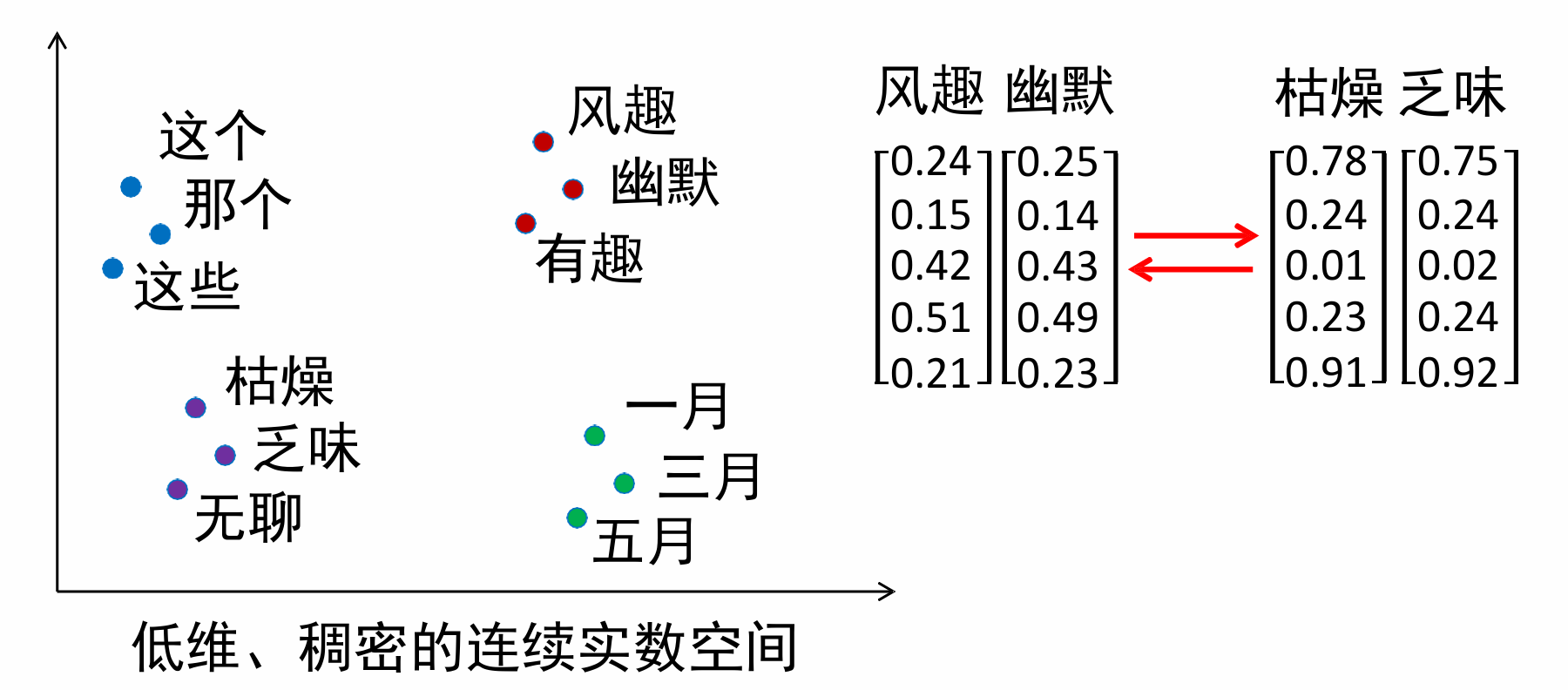
前馈神经网络(FNN)
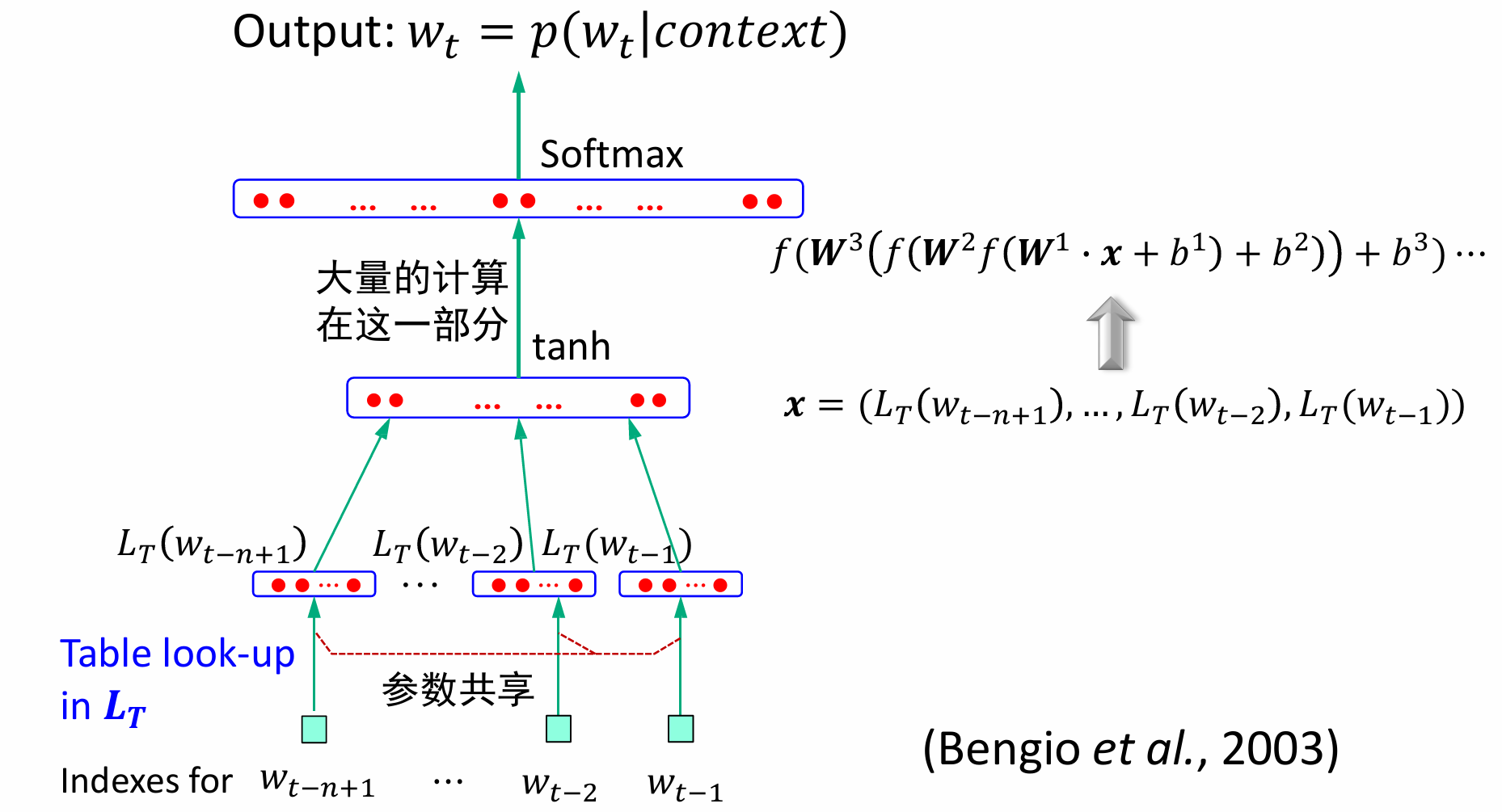
FNN是最早发明的简单人工神经网络,也经常被称为多层感知(Multi-Layer Perceptron, MLP)。前馈网络中各个神经元按接收信息的先后分为不同的组,每一组可以看作一个神经层,每一层中的神经元接收前一层神经元的输出,并输出到下一层神经元,整个网络中的信息是朝一个方向传播,没有反向的信息传播,可以看作是一个有向的无环图。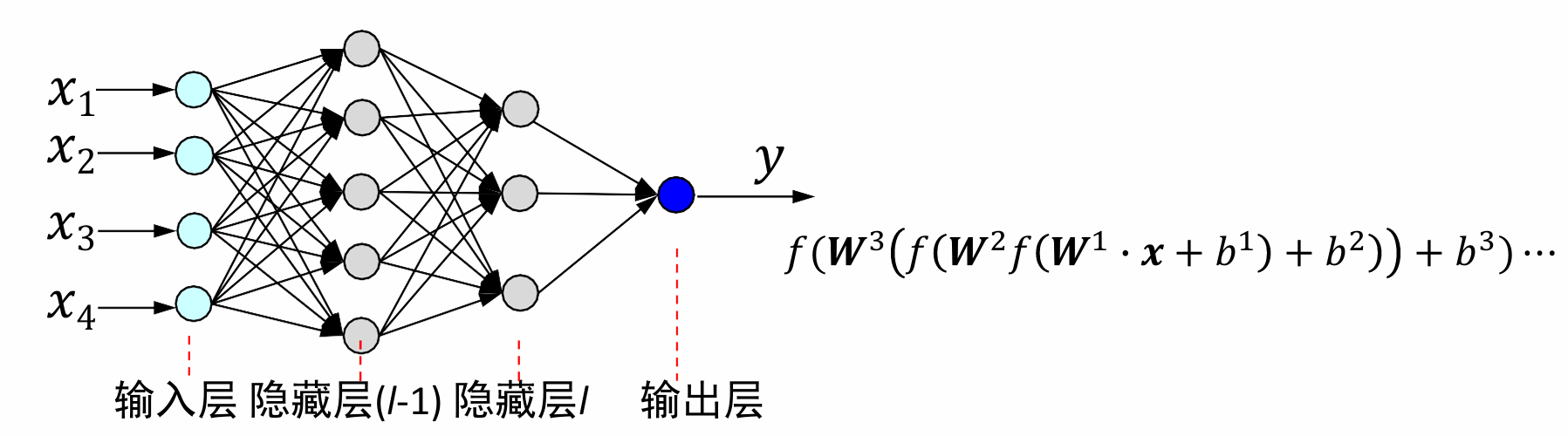
网络表示:𝐿为神经网络的层数;𝑀𝑙为第𝑙层的神经元个数;𝑓𝑙(∙)为第𝑙层神经元的激活函数;
参数学习:确定网络中所有的𝑾和b
基于反向传播(Back Propagation)算法的随机梯度下降参数训练过程:

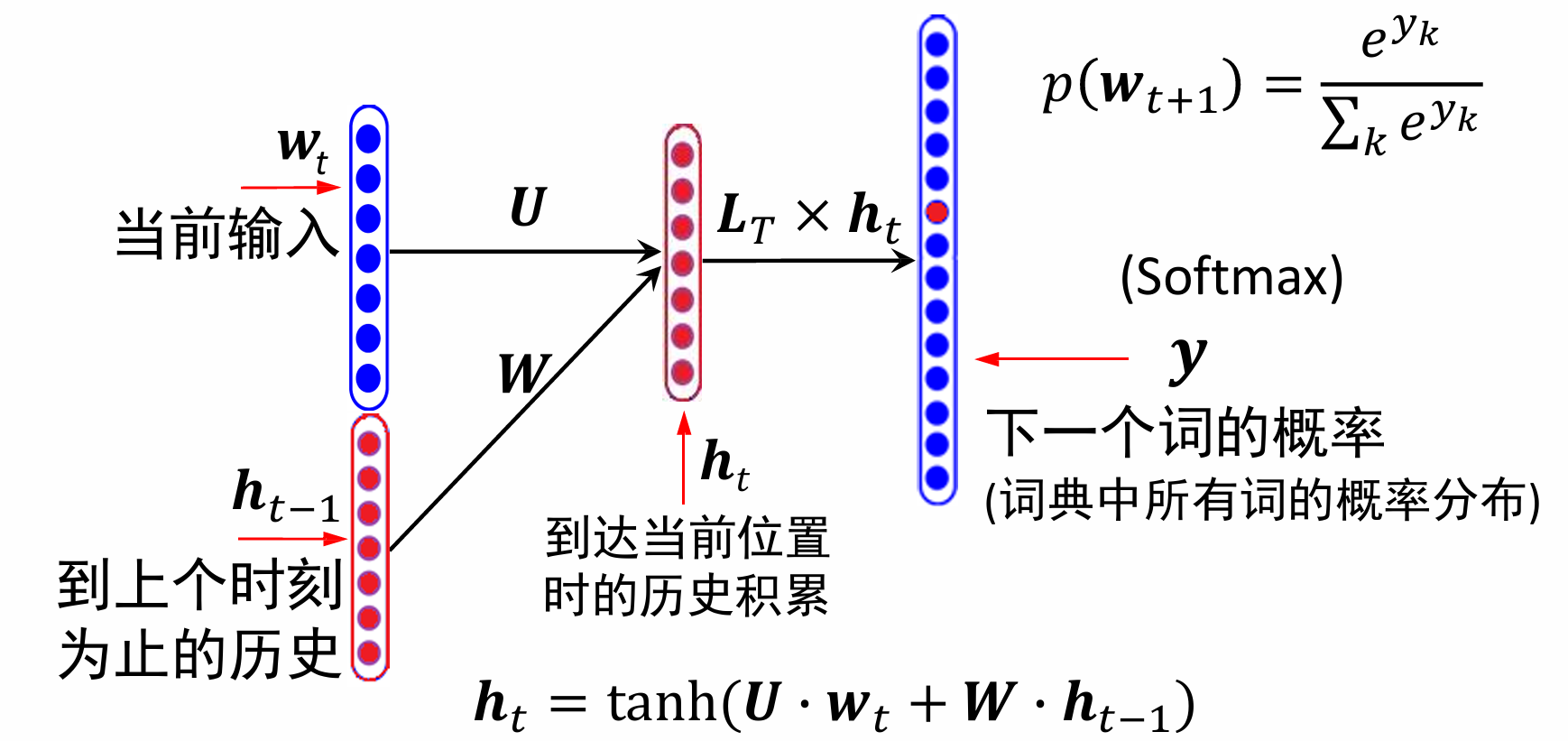
关于词向量的表示,也就是图中的 L T L_T LT,通常先随机初始化,然后通过目标函数优化词的向量表示(如最大化语言模型似然度)。
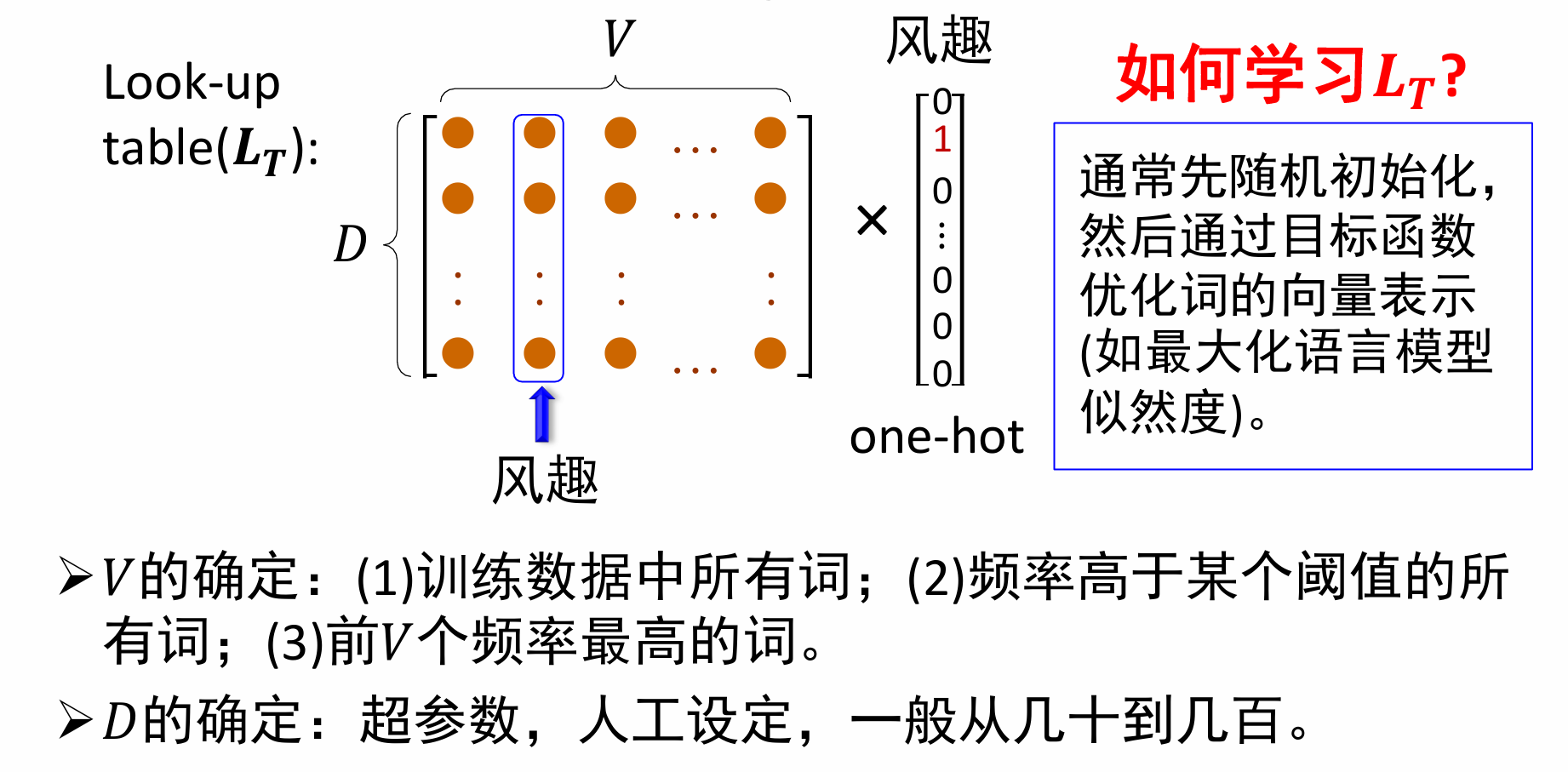
V表示训练集中的词个数,如果训练集很庞大,可以考虑取前V个频率最高的词。
D则表示词向量的维度,一般来说词向量维度越大,模型效果会更好,当然训练难度也会加大。
- Softmax 回归(regression) 也称为多项(Multinomial) 或多类(MultiClass) 的Logistic回归,是Logistic回归在多分类问题上的推广,它也可以看作是一种条件最大熵模型。
- 对于多类问题,类别标签$𝑦∈ 1,2, ⋯,𝐶 $可以有𝐶个取值,给定一个样本𝒙, Softmax回归预测的属于类别𝑐的条件概率为:
p ( y = c ∣ x ) = Softmax ( w c T x ) = exp ( w c T x ) ∑ c ′ = 1 C exp ( w c ′ T x ) \begin{aligned} p(y=c \mid \boldsymbol{x}) & =\operatorname{Softmax}\left(\boldsymbol{w}_{c}^{T} \boldsymbol{x}\right) \\ & =\frac{\exp \left(\boldsymbol{w}_{c}^{T} \boldsymbol{x}\right)}{\sum_{c^{\prime}=1}^{C} \exp \left(\boldsymbol{w}_{c^{\prime}}^{T} \boldsymbol{x}\right)}\end{aligned} p(y=c∣x)=Softmax(wcTx)=∑c′=1Cexp(wc′Tx)exp(wcTx)
其中, 𝒘 𝑐 𝒘_𝑐 wc是第𝑐类的权重向量
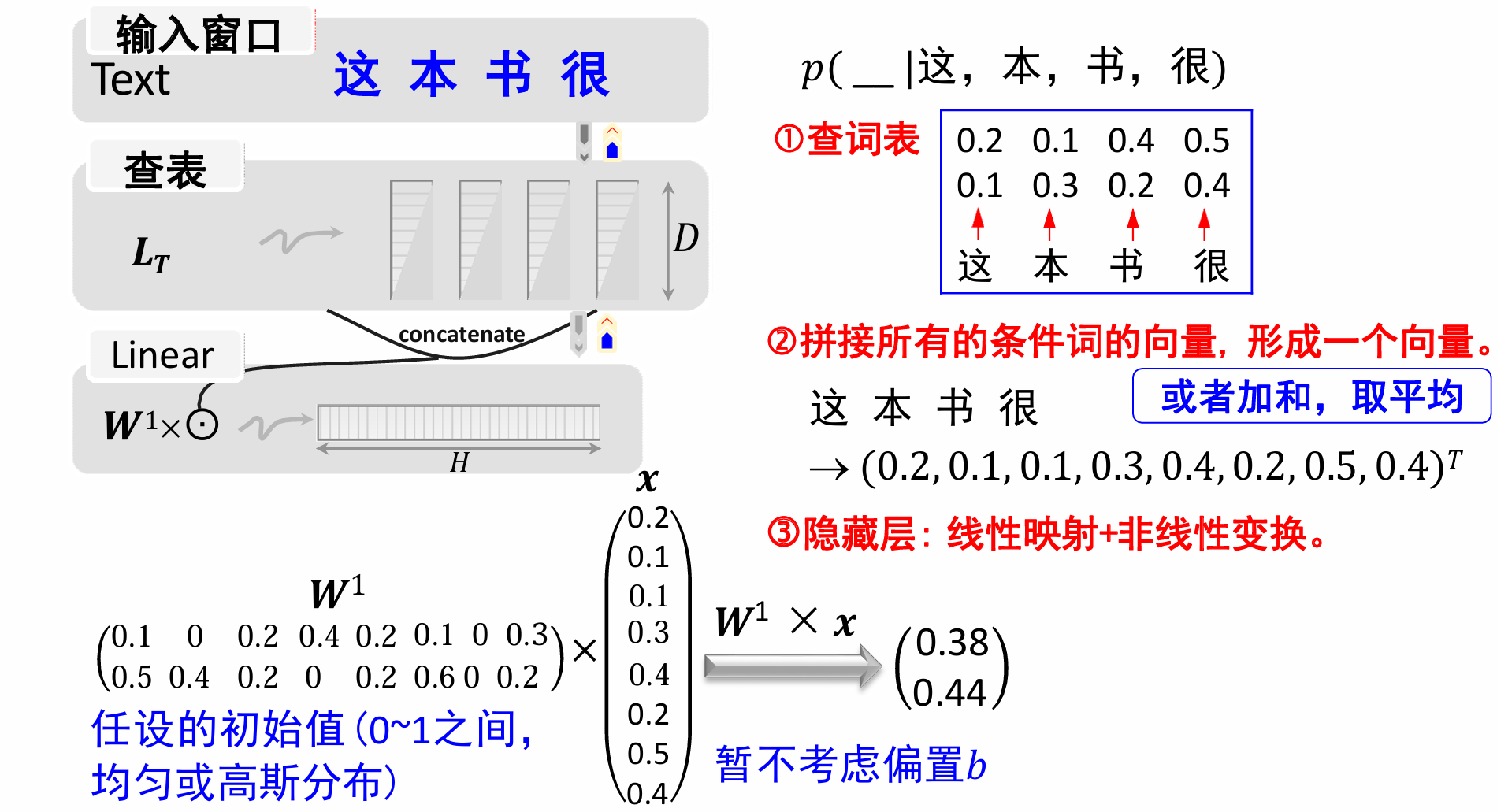
举个例子来看,我们给出 L T L_T LT和输入词串:

暂时不考虑偏置b,分三步进行计算。
再得到最后的结果向量(0.38,0.44 ) T )^T )T后经过tanh激活函数:
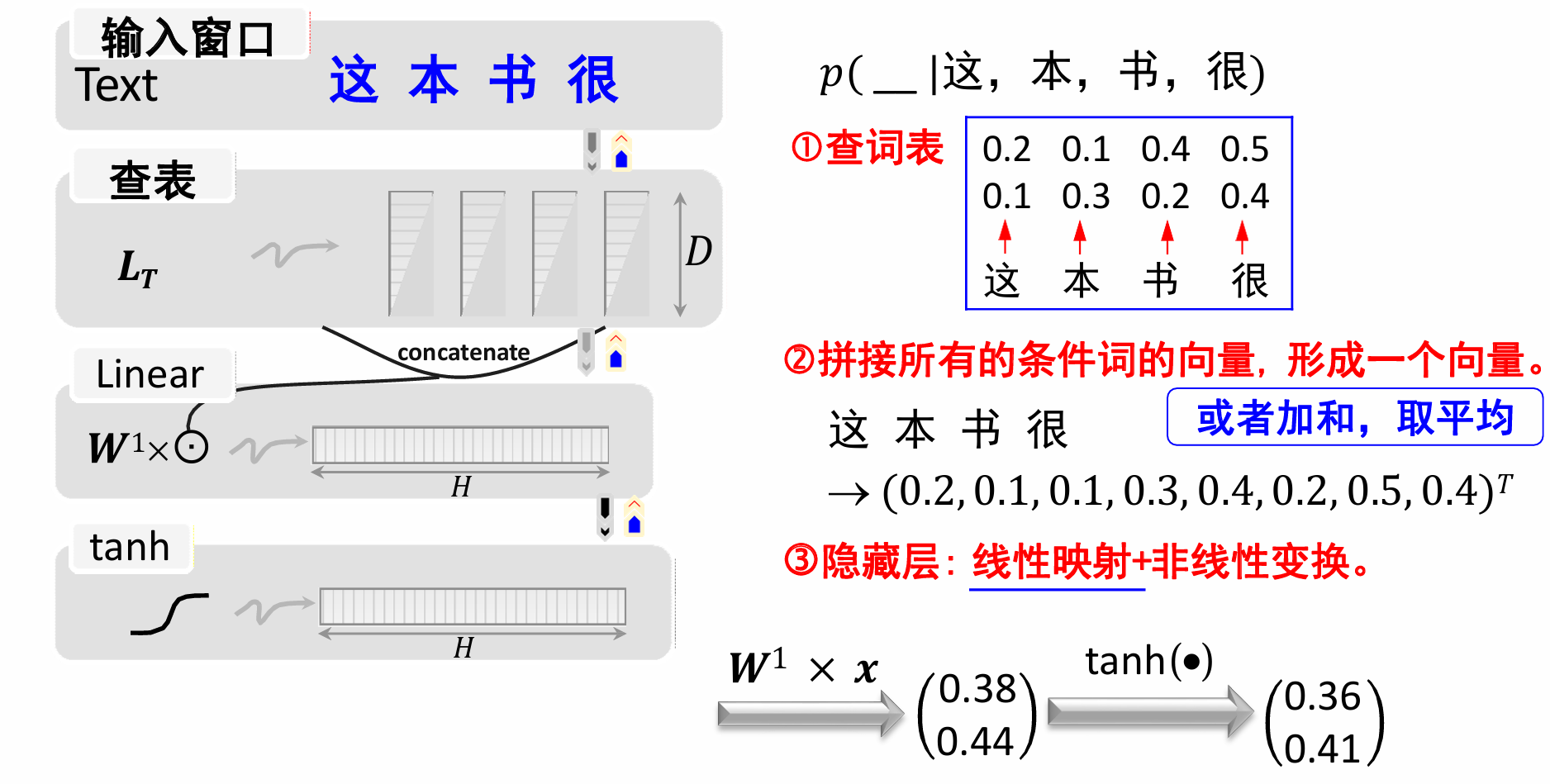
最后我们得到的向量和原来的 L T L_T LT进行处理,再送入softmax找到概率最大的一项,如此就可以找到出现概率最大的词了。
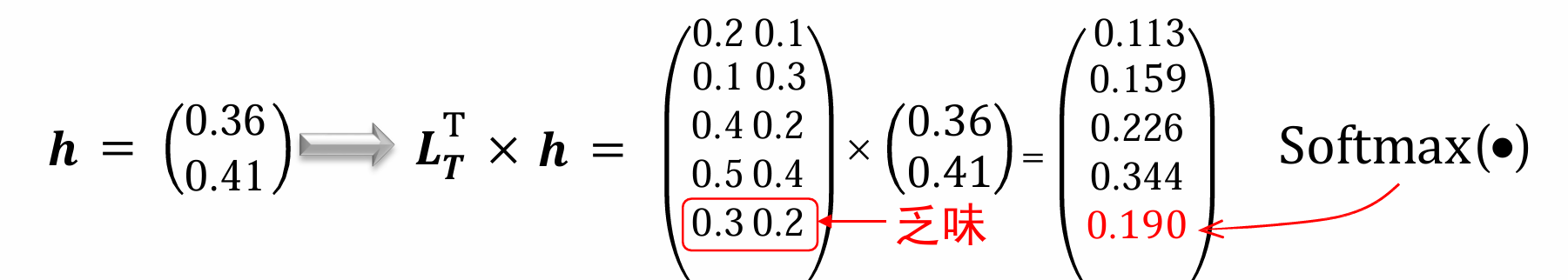
问题:
- 仅对小窗口的历史信息进行建模
- n-gram语言模型仅考虑前面𝑛−1个词的历史信息
我们需要一种对所有的历史信息进行建模的方法!
循环神经网络
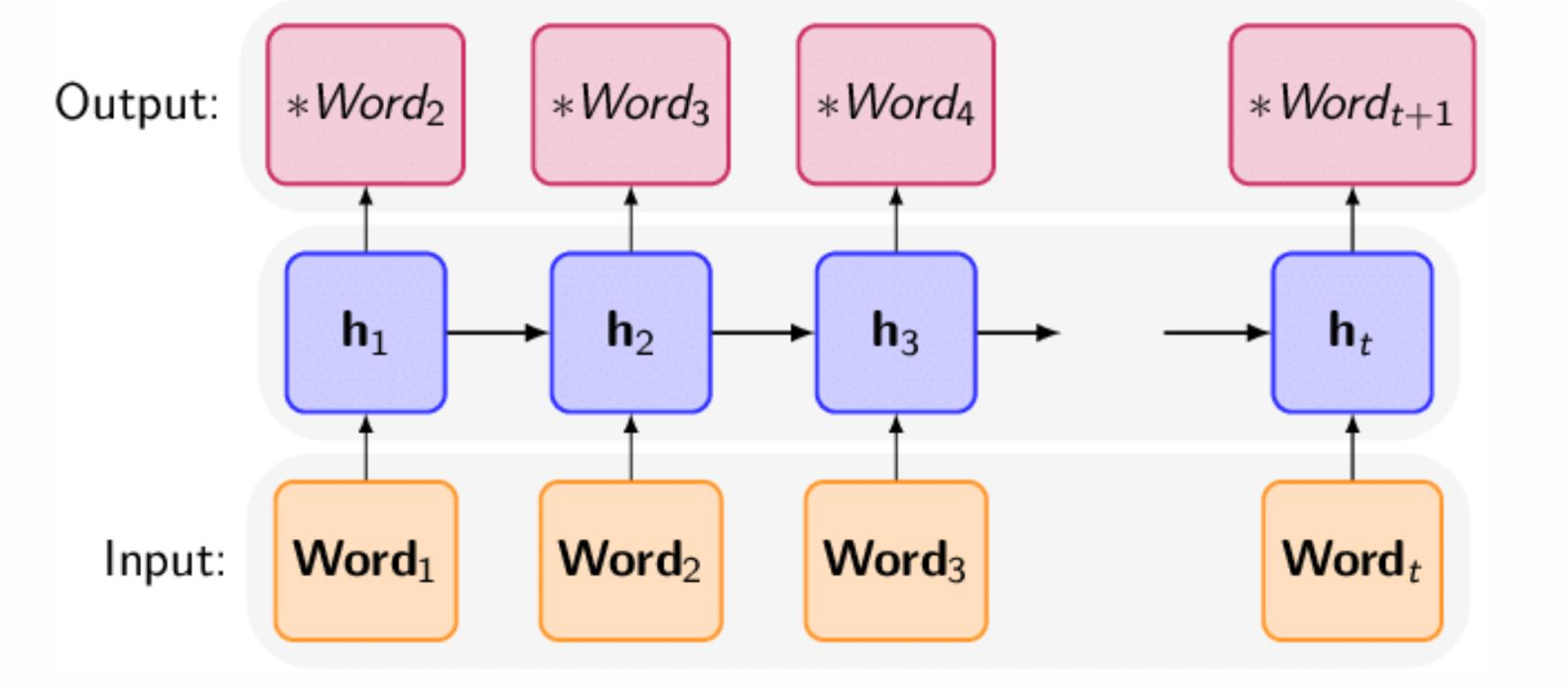
输入:从开始到𝑡−1时刻的历史 𝒉 𝑡 − 1 𝒉_{𝑡−1} ht−1;当前位置𝑡的词向量 𝒘 𝑡 𝒘_𝑡 wt
输出:到𝑡位置时的历史积累 𝒉 𝑡 𝒉_𝑡 ht及其该位置上词的概率
模型训练时需要保证当前词的概率最大
举个例子:以“这本书很好看”为例
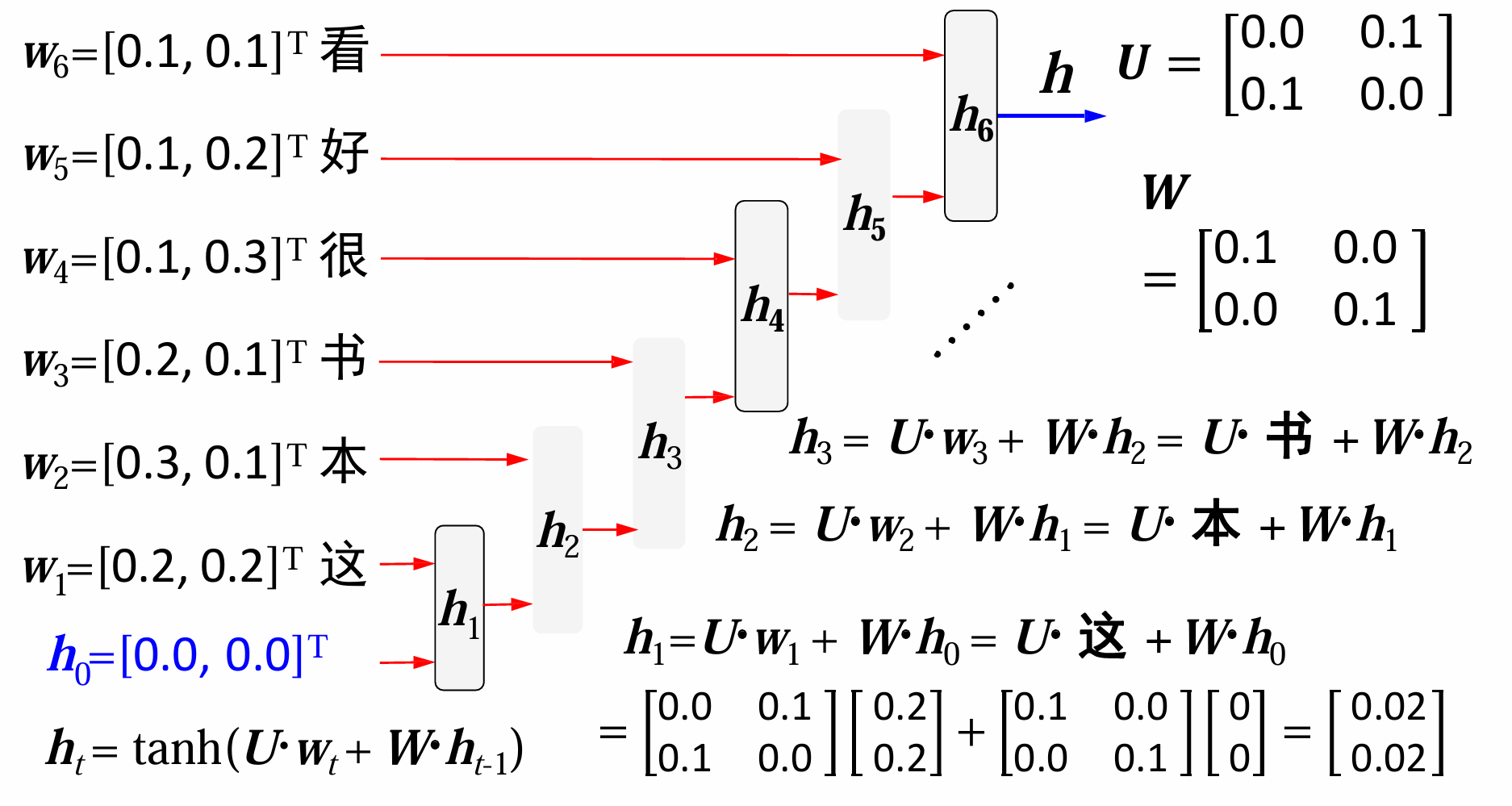
问题:梯度消失或爆炸:参数W经过多次传递后有可能导致梯度消失(小于1)或者爆炸(大于1)。
相关文章:
自然语言处理——语言模型
语言模型 n元文法参数估计数据平滑方法加1法 神经网络模型提出原因前馈神经网络(FNN)循环神经网络 n元文法 大规模语料库的出现为自然语言统计处理方法的实现提供了可能,统计方法的成功应用推动了语料库语言学的发展。 语句 𝑠 …...
数据库管理与高可用-MySQL高可用
目录 #1.1什么是MySQL高可用 1.1.1MySQL主主复制keepalivedhaproxy的高可用 1.1.2优势 #2.1MySQL主主复制keepalivedhaproxy的实验案例 1.1什么是MySQL高可用 MySQL 高可用是指通过技术手段确保 MySQL 数据库在面临硬件故障、软件错误、网络中断、人为误操作等异常情况时&…...

QuaggaJS用法详解
QuaggaJS简介 QuaggaJS是一个强大的JavaScript库,专门用于在浏览器环境中进行条形码和二维码识别。它支持多种条形码格式,包括Code 128、Code 39、EAN、QR码等,并且可以直接调用设备摄像头进行实时扫描。 QuaggaJS核心功能与用法 1. 基本配…...
 中创建多级目录或文件,可以使用鸿蒙的文件系统 API】)
【鸿蒙在 ETS (Extendable TypeScript) 中创建多级目录或文件,可以使用鸿蒙的文件系统 API】
鸿蒙在 ETS (Extendable TypeScript) 中创建多级目录或文件,可以使用鸿蒙的文件系统 API。 // 导入需要的模块 import fs from ohos.file.fs;const TAG"Index" Entry Component struct Index {State message: string Hello World;build() {Row() {Colum…...

免费工具-微软Bing Video Creator
目录 引言 一、揭秘Bing Video Creator 二、轻松上手:三步玩转Bing Video Creator 2.1 获取与访问: 2.2 创作流程: 2.3 提示词撰写技巧——释放AI的想象力: 三、核心特性详解:灵活满足多样化需求 3.1 双重使用模…...

2025 cs144 Lab Checkpoint 3: TCP Receiver
文章目录 1 关于TCP Sender1.1 关键机制重传超时(RTO)与定时器 2 实现TCP Sender2.1 void push( const TransmitFunction& transmit );const TransmitFunction& transmit 函数型参数?从哪里读取字节࿱…...

【学习笔记】深入理解Java虚拟机学习笔记——第5章 调优案例分析与实战
第5章 调优案例分析与实战 5.1 概述 略 5.2 案例分析 5.2.1 大内存硬件上的程序部署策略 为防止大内存一次Full GC时间过长,可以考虑使用响应速度优先的垃圾回收器,还可以通过将一个10GB堆内存的应用分解为5个2GB堆内存应用,并通过负载均…...

Vue 3 Teleport 实战:优雅实现模态框、通知和全局组件
Vue 3 Teleport:突破 DOM 层级限制的组件渲染利器 在 Vue 应用开发中,组件通常与其模板的 DOM 结构紧密耦合。但当处理模态框(Modal)、通知(Toast)或全局 Loading 指示器时,这种耦合会成为障碍…...

使用高斯朴素贝叶斯算法对鸢尾花数据集进行分类
高斯朴素贝叶斯算法通常用于特征变量是连续变量,符合高素分布的情况。 使用高斯朴素贝叶斯算法对鸢尾花数据集进行分类 """ 使用高斯贝叶斯堆鸢尾花进行分类 """ #导入需要的库 from sklearn.datasets import load_iris from skle…...

vue中ref的详解以及react的ref对比
文章目录 1. ref是什么2. ref的使用3. ref的特性4. 使用场景5. 注意事项6. 与 React 的对比7. 动态 ref8. 函数式组件中的 ref9. 组合式 API 中的 ref10. 总结 1. ref是什么 ref 被用来给元素或子组件注册引用信息。引用信息将会注册在父组件的 $refs 对象上。可以通过实例对象…...
【笔记】解决MSYS2安装后cargo-install-update.exe-System Error
#工作记录 cargo-install-update.exe-System Error The code execution cannot proceed because libgit2-1.9.dll wasnot found. Reinstalling the program may fix this problem. …...

[论文阅读] 人工智能+软件工程 | MemFL:给大模型装上“项目记忆”,让软件故障定位又快又准
【论文解读】MemFL:给大模型装上“项目记忆”,让软件故障定位又快又准 论文信息 arXiv:2506.03585 Improving LLM-Based Fault Localization with External Memory and Project Context Inseok Yeo, Duksan Ryu, Jongmoon Baik Subjects: Software Engi…...
银行卡二三四要素实名接口如何用PHP实现调用?
一、什么是银行卡二三四要素实名接口 输入银行卡卡号、姓名、身份证号码、手机号,验证此二三四要素是否一致。 二、核心价值 1. 提升风控效率 通过实时拦截冒用身份开户,银行卡二三四要素实名接口显著降低了人工审核成本,效率提升50%以上…...

itvbox绿豆影视tvbox手机版影视APP源码分享搭建教程
我们先来看看今天的主题,tvbox手机版,然后再看看如何搭建: 很多爱好者都希望搭建自己的影视平台,那该如何搭建呢? 后端开发环境: 1.易如意后台管理优化版源码; 2.宝塔面板; 3.ph…...

Docker load 后镜像名称为空问题的解决方案
在使用 docker load命令从存档文件中加载Docker镜像时,有时会遇到镜像名称为空的情况。这种情况通常是由于在保存镜像时未正确标记镜像名称和标签,或者在加载镜像时出现了意外情况。本文将介绍如何诊断和解决这一问题。 一、问题描述 当使用 docker lo…...

Redis 集群批量删除key报错 CROSSSLOT Keys in request don‘t hash to the same slot
Redis 集群报错 CROSSSLOT Keys in request dont hash to the same slot 的原因及解决方案 1. 错误原因 在 Redis 集群模式下,数据根据 哈希槽(Slot) 分散存储在不同的节点上(默认 16384 个槽)。当执行涉及多个 key …...

网页抓取混淆与嵌套数据处理流程
当我们在网页抓取中,遇到混淆和多层嵌套的情况是比较常见的挑战。混淆大部分都是为了防止爬虫而设计的,例如使用JavaScript动态加载、数据加密、字符替换、CSS偏移等。多层嵌套则可能是指HTML结构复杂,数据隐藏在多层标签或者多个iframe中。 …...

高性能MYSQL:复制同步的问题和解决方案
一、复制的问题和解决方案 中断MySQL的复制并不是件难事。因为实现简单,配置相当容易,但也意味着有很多方式会导致复制停止,陷入混乱并中断。 (一)数据损坏或丢失的错误 由于各种各样的原因,MySQL 的复制…...

如何通过外网访问内网服务器?怎么让互联网上连接本地局域网的网址
服务器作为一个数据终端,是很多企事业单位不可获缺的重要设备,多数公司本地都会有部署服务器供测试或部署一些网络项目使用。有人说服务器就是计算机,其实这种说法不是很准确。准确的说服务器算是计算机的一种,它的作用是管理计算…...
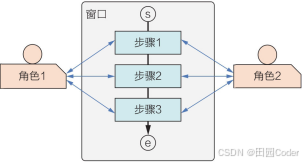
大话软工笔记—架构模型
1. 架构模型1—拓扑图 (1)拓扑图概念 拓扑图,将多个软件系统用网络图连接起来的表达方式。 (2)拓扑图分类 总线型结构 比较普遍采用的方式,将所有的系统接到一条总线上。 星状结构 各个系统通过点到…...
javaweb -html -CSS
HTML是一种超文本标记语言 超文本:超过了文本的限制,比普通文本更强大,除了文字信息,还可以定义图片、音频、视频等内容。 标记语言:由标签"<标签名>"构成的语言。 CSS:层叠样式表,用于…...

spring task定时任务快速入门
spring task它基于注解和配置,可以轻松实现任务的周期性调度、延迟执行或固定频率触发。按照我们约定的时间自动执行某段代码。例如闹钟 使用场景 每月还款提醒,未支付的订单自动过期,收到快递后自动收货,系统自动祝你生日快乐等…...
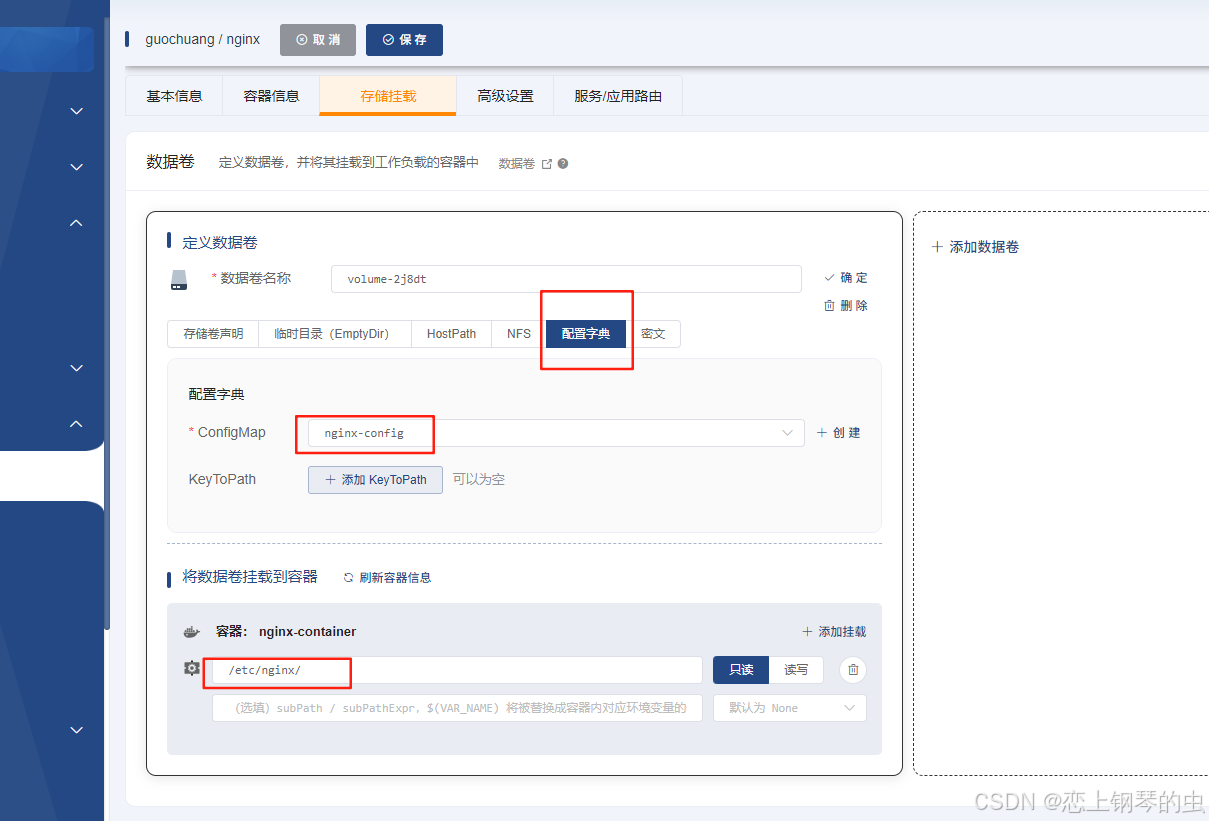
搭建nginx的负载均衡
1、编写一个configMap的配置文件 events {worker_connections 1024; # 定义每个worker进程的最大连接数 }http {# 定义通用代理参数(替代proxy_params文件)proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-F…...
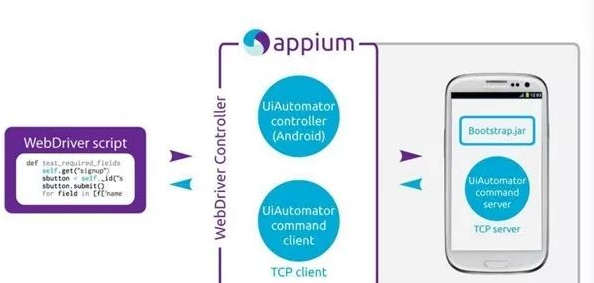
Appium+python自动化(八)- 认识Appium- 下章
1、界面认识 在之前安装appium的时候说过我们有两种方法安装,也就有两种结果,一种是有界面的(客户端安装),一种是没有界面的(终端安装),首先我们先讲一下有界面的,以及界…...
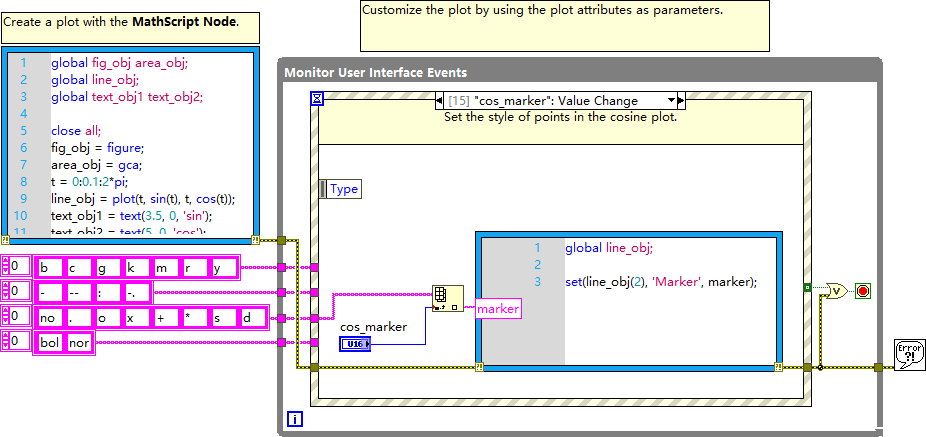
LabVIEW的MathScript Node 绘图功能
该VI 借助 LabVIEW 的 MathScript Node,结合事件监听机制,实现基于 MathScript 的绘图功能,并支持通过交互控件自定义绘图属性。利用 MathScript 编写脚本完成图形初始化,再通过LabVIEW 事件结构响应用户操作,动态修改…...

互斥锁与消息队列的架构哲学
更多精彩内容请访问:通义灵码2.5——基于编程智能体开发Wiki多功能搜索引擎更多精彩内容请访问:更多精彩内容请访问:通义灵码2.5——基于编程智能体开发Wiki多功能搜索引擎 一、资源争用的现实镜像 当多个ATM机共用一个现金库时,…...

每日Prompt:治愈动漫插画
提示词 现代都市治愈动漫插画风格,现代女子,漂亮,长直发,20岁,豆沙唇,白皙,气质,清纯现代都市背景下,夕阳西下,一位穿着白色露脐短袖,粉色工装裤…...

stress-ng 服务器压力测试的工具学习
一、stress-ng (下一代压力测试) 介绍 项目地址:https://github.com/ColinIanKing/stress-ng stress-ng 将以多种可选方式对计算机系统进行压力测试。它旨在锻炼计算机的各种物理子系统以及各种操作系统内核接口。stress-ng 的特点: 360 压力测试100 …...

6.8 note
paxos算法_初步感知 Paxos算法保证一致性主要通过以下几个关键步骤和机制: 准备阶段 - 提议者向所有接受者发送准备请求,请求中包含一个唯一的编号。 - 接受者收到请求后,会检查编号,如果编号比它之前见过的都大,就会承…...

面试心得 --- 车载诊断测试常见的一些面试问题
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...