DiMTAIC 2024 数字医学技术及应用创新大赛-甲状腺B超静态及动态影像算法赛-参赛项目

参赛成绩
项目介绍
去年参加完这个比赛之后,整理了项目文件和代码,虽然比赛没有获奖,但是参赛过程中自己也很有收获,自己一个人搭建了完整的pipeline并基于此提交了多次提高成绩,现在把这个项目梳理成博客,便于以后学习借鉴。
本项目涉及对医学图像的分类和分割两种视觉任务,分类任务基于论文:HIFUSE: HIERARCHICAL MULTI-SCALE FEATURE FUSION NETWORK FOR MEDICAL IMAGE CLASSIFICATION 提出的方案
论文源码:https://github.com/huoxiangzuo/HiFuse
分割任务基于论文:SAM2-UNet: Segment Anything 2 Makes Strong Encoder for Natural and Medical Image Segmentation 提出的方案
论文源码:https://github.com/WZH0120/SAM2-UNet
项目结构
/app
├── submit
│ └── label
│ ├── img_0030_0000.png
│ └── ...
├── label.csv
├── run.sh
└── submit.zip/model_weight
├── cls
│ ├── checkpoint
│ └── best_model.pth
└── seg
└── SAM2-UNet-epoch.pth/pretrained_model
└── sam2_hiera_large.pt/sam2
/sam2_configs
/cls_model.py
/cls_test.py
/cls_train.py
/cls_utils.py
/dataset.py
/Dockerfile
/requirements.txt
/SAM2UNet.py
/seg_eval.py
/seg_eval.sh
/seg_test.py
/seg_test.sh
/seg_train.py
/seg_train.sh
/tcdata
重要代码
/app/run.sh
CUDA_VISIBLE_DEVICES="0" \
# seg task train
python /mnt/home/maojianzeng/2024dimtaic/seg_train.py \
--hiera_path "/mnt/home/maojianzeng/2024dimtaic/pretrained_model/sam2_hiera_large.pt" \
--train_image_path "/mnt/home/maojianzeng/2024dimtaic/tcdata/train/img/" \
--train_mask_path "/mnt/home/maojianzeng/2024dimtaic/tcdata/train/label/" \
--save_path "/mnt/home/maojianzeng/2024dimtaic/model_weight/seg" \
--epoch 20 \
--lr 0.001 \
--batch_size 4 \
--weight_decay 5e-4# seg task test
python /mnt/home/maojianzeng/2024dimtaic/seg_test.py \
--checkpoint "/mnt/home/maojianzeng/2024dimtaic/model_weight/seg/SAM2-UNet-20.pth" \
--test_image_path "/mnt/home/maojianzeng/2024dimtaic/tcdata/train/img/" \
--test_gt_path "/mnt/home/maojianzeng/2024dimtaic/tcdata/train/label/" \
--save_path "submit/label"# cls task train
python /mnt/home/maojianzeng/2024dimtaic/cls_train.py \
--num_classes 2 \
--epochs 20 \
--batch-size 4 \
--lr 0.001 \
--wd 5e-4 \
--train_data_path "/mnt/home/maojianzeng/2024dimtaic/tcdata/train/img/" \
--train_label_path "/mnt/home/maojianzeng/2024dimtaic/tcdata/train/label.csv" \
--val_data_path "/mnt/home/maojianzeng/2024dimtaic/tcdata/train/img" \
--val_label_path "/mnt/home/maojianzeng/2024dimtaic/tcdata/train/label.csv" \
--save_dir "/mnt/home/maojianzeng/2024dimtaic/model_weight/cls" \
--save_best_model_path "/mnt/home/maojianzeng/2024dimtaic/model_weight/cls/best_model.pth" \
--checkpoint_path "/mnt/home/maojianzeng/2024dimtaic/model_weight/cls/checkpoint" # cls task test
python /mnt/home/maojianzeng/2024dimtaic/cls_test.py \
--test_data_path "/mnt/home/maojianzeng/2024dimtaic/tcdata/train/img" \
--test_label_path "/mnt/home/maojianzeng/2024dimtaic/tcdata/train/label.csv" \
--model_weight_path "/mnt/home/maojianzeng/2024dimtaic/model_weight/cls/best_model.pth" \
--save_path "submit/label.csv"zip -r submit.zip submit/cls_model.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import numpy as np
from typing import Optionaldef drop_path_f(x, drop_prob: float = 0., training: bool = False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted forchanging the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use'survival rate' as the argument."""if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path_f(x, self.drop_prob, self.training)class main_model(nn.Module):def __init__(self, num_classes, patch_size=4, in_chans=3, embed_dim=96, depths=(2, 2, 2, 2),num_heads=(3, 6, 12, 24), window_size=7, qkv_bias=True, drop_rate=0,attn_drop_rate=0, drop_path_rate=0., norm_layer=nn.LayerNorm, patch_norm=True,use_checkpoint=False, HFF_dp=0.,conv_depths=(2, 2, 2, 2), conv_dims=(96, 192, 384, 768), conv_drop_path_rate=0.,conv_head_init_scale: float = 1., **kwargs):super().__init__()###### Local Branch Setting #######self.downsample_layers = nn.ModuleList() # stem + 3 stage downsamplestem = nn.Sequential(nn.Conv2d(in_chans, conv_dims[0], kernel_size=4, stride=4),LayerNorm(conv_dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)# stage2-4 downsamplefor i in range(3):downsample_layer = nn.Sequential(LayerNorm(conv_dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(conv_dims[i], conv_dims[i+1], kernel_size=2, stride=2))self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple blocksdp_rates = [x.item() for x in torch.linspace(0, conv_drop_path_rate, sum(conv_depths))]cur = 0# Build stacks of blocks in each stagefor i in range(4):stage = nn.Sequential(*[Local_block(dim=conv_dims[i], drop_rate=dp_rates[cur + j])for j in range(conv_depths[i])])self.stages.append((stage))cur += conv_depths[i]self.conv_norm = nn.LayerNorm(conv_dims[-1], eps=1e-6) # final norm layerself.conv_head = nn.Linear(conv_dims[-1], num_classes)self.conv_head.weight.data.mul_(conv_head_init_scale)self.conv_head.bias.data.mul_(conv_head_init_scale)###### Global Branch Setting ######self.num_classes = num_classesself.num_layers = len(depths)self.embed_dim = embed_dimself.patch_norm = patch_norm# The channels of stage4 output feature matrixself.num_features = int(embed_dim * 2 ** (self.num_layers - 1))# split image into non-overlapping patchesself.patch_embed = PatchEmbed(patch_size=patch_size, in_c=in_chans, embed_dim=embed_dim,norm_layer=norm_layer if self.patch_norm else None)self.pos_drop = nn.Dropout(p=drop_rate)# stochastic depthdpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rulei_layer = 0self.layers1 = BasicLayer(dim=int(embed_dim * 2 ** i_layer),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=window_size,qkv_bias=qkv_bias,drop=drop_rate,attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer,downsample=PatchMerging if (i_layer > 0) else None,use_checkpoint=use_checkpoint)i_layer = 1self.layers2 = BasicLayer(dim=int(embed_dim * 2 ** i_layer),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=window_size,qkv_bias=qkv_bias,drop=drop_rate,attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer,downsample=PatchMerging if (i_layer > 0) else None,use_checkpoint=use_checkpoint)i_layer = 2self.layers3 = BasicLayer(dim=int(embed_dim * 2 ** i_layer),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=window_size,qkv_bias=qkv_bias,drop=drop_rate,attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer,downsample=PatchMerging if (i_layer > 0) else None,use_checkpoint=use_checkpoint)i_layer = 3self.layers4 = BasicLayer(dim=int(embed_dim * 2 ** i_layer),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=window_size,qkv_bias=qkv_bias,drop=drop_rate,attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer,downsample=PatchMerging if (i_layer > 0) else None,use_checkpoint=use_checkpoint)self.norm = norm_layer(self.num_features)self.avgpool = nn.AdaptiveAvgPool1d(1)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.apply(self._init_weights)###### Hierachical Feature Fusion Block Setting #######self.fu1 = HFF_block(ch_1=96, ch_2=96, r_2=16, ch_int=96, ch_out=96, drop_rate=HFF_dp)self.fu2 = HFF_block(ch_1=192, ch_2=192, r_2=16, ch_int=192, ch_out=192, drop_rate=HFF_dp)self.fu3 = HFF_block(ch_1=384, ch_2=384, r_2=16, ch_int=384, ch_out=384, drop_rate=HFF_dp)self.fu4 = HFF_block(ch_1=768, ch_2=768, r_2=16, ch_int=768, ch_out=768, drop_rate=HFF_dp)def _init_weights(self, m):if isinstance(m, nn.Linear):nn.init.trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)elif isinstance(m, (nn.Conv2d, nn.Linear)):nn.init.trunc_normal_(m.weight, std=0.2)nn.init.constant_(m.bias, 0)def forward(self, imgs):###### Global Branch ######x_s, H, W = self.patch_embed(imgs)x_s = self.pos_drop(x_s)x_s_1, H, W = self.layers1(x_s, H, W)x_s_2, H, W = self.layers2(x_s_1, H, W)x_s_3, H, W = self.layers3(x_s_2, H, W)x_s_4, H, W = self.layers4(x_s_3, H, W)# [B,L,C] ---> [B,C,H,W]x_s_1 = torch.transpose(x_s_1, 1, 2)x_s_1 = x_s_1.view(x_s_1.shape[0], -1, 56, 56)x_s_2 = torch.transpose(x_s_2, 1, 2)x_s_2 = x_s_2.view(x_s_2.shape[0], -1, 28, 28)x_s_3 = torch.transpose(x_s_3, 1, 2)x_s_3 = x_s_3.view(x_s_3.shape[0], -1, 14, 14)x_s_4 = torch.transpose(x_s_4, 1, 2)x_s_4 = x_s_4.view(x_s_4.shape[0], -1, 7, 7)###### Local Branch ######x_c = self.downsample_layers[0](imgs)x_c_1 = self.stages[0](x_c)x_c = self.downsample_layers[1](x_c_1)x_c_2 = self.stages[1](x_c)x_c = self.downsample_layers[2](x_c_2)x_c_3 = self.stages[2](x_c)x_c = self.downsample_layers[3](x_c_3)x_c_4 = self.stages[3](x_c)###### Hierachical Feature Fusion Path ######x_f_1 = self.fu1(x_c_1, x_s_1, None)x_f_2 = self.fu2(x_c_2, x_s_2, x_f_1)x_f_3 = self.fu3(x_c_3, x_s_3, x_f_2)x_f_4 = self.fu4(x_c_4, x_s_4, x_f_3)x_fu = self.conv_norm(x_f_4.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)x_fu = self.conv_head(x_fu)return x_fu##### Local Feature Block Component #####class LayerNorm(nn.Module):r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.The ordering of the dimensions in the inputs. channels_last corresponds to inputs withshape (batch_size, height, width, channels) while channels_first corresponds to inputswith shape (batch_size, channels, height, width)."""def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()self.weight = nn.Parameter(torch.ones(normalized_shape), requires_grad=True)self.bias = nn.Parameter(torch.zeros(normalized_shape), requires_grad=True)self.eps = epsself.data_format = data_formatif self.data_format not in ["channels_last", "channels_first"]:raise ValueError(f"not support data format '{self.data_format}'")self.normalized_shape = (normalized_shape,)def forward(self, x: torch.Tensor) -> torch.Tensor:if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":# [batch_size, channels, height, width]mean = x.mean(1, keepdim=True)var = (x - mean).pow(2).mean(1, keepdim=True)x = (x - mean) / torch.sqrt(var + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return xclass Local_block(nn.Module):r""" Local Feature Block. There are two equivalent implementations:(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute backWe use (2) as we find it slightly faster in PyTorchArgs:dim (int): Number of input channels.drop_rate (float): Stochastic depth rate. Default: 0.0"""def __init__(self, dim, drop_rate=0.):super().__init__()self.dwconv = nn.Conv2d(dim, dim, kernel_size=3, padding=1, groups=dim) # depthwise convself.norm = LayerNorm(dim, eps=1e-6, data_format="channels_last")self.pwconv = nn.Linear(dim, dim) # pointwise/1x1 convs, implemented with linear layersself.act = nn.GELU()self.drop_path = DropPath(drop_rate) if drop_rate > 0. else nn.Identity()def forward(self, x: torch.Tensor) -> torch.Tensor:shortcut = xx = self.dwconv(x)x = x.permute(0, 2, 3, 1) # [N, C, H, W] -> [N, H, W, C]x = self.norm(x)x = self.pwconv(x)x = self.act(x)x = x.permute(0, 3, 1, 2) # [N, H, W, C] -> [N, C, H, W]x = shortcut + self.drop_path(x)return x# Hierachical Feature Fusion Block
class HFF_block(nn.Module):def __init__(self, ch_1, ch_2, r_2, ch_int, ch_out, drop_rate=0.):super(HFF_block, self).__init__()self.maxpool=nn.AdaptiveMaxPool2d(1)self.avgpool=nn.AdaptiveAvgPool2d(1)self.se=nn.Sequential(nn.Conv2d(ch_2, ch_2 // r_2, 1,bias=False),nn.ReLU(),nn.Conv2d(ch_2 // r_2, ch_2, 1,bias=False))self.sigmoid = nn.Sigmoid()self.spatial = Conv(2, 1, 7, bn=True, relu=False, bias=False)self.W_l = Conv(ch_1, ch_int, 1, bn=True, relu=False)self.W_g = Conv(ch_2, ch_int, 1, bn=True, relu=False)self.Avg = nn.AvgPool2d(2, stride=2)self.Updim = Conv(ch_int//2, ch_int, 1, bn=True, relu=True)self.norm1 = LayerNorm(ch_int * 3, eps=1e-6, data_format="channels_first")self.norm2 = LayerNorm(ch_int * 2, eps=1e-6, data_format="channels_first")self.norm3 = LayerNorm(ch_1 + ch_2 + ch_int, eps=1e-6, data_format="channels_first")self.W3 = Conv(ch_int * 3, ch_int, 1, bn=True, relu=False)self.W = Conv(ch_int * 2, ch_int, 1, bn=True, relu=False)self.gelu = nn.GELU()self.residual = IRMLP(ch_1 + ch_2 + ch_int, ch_out)self.drop_path = DropPath(drop_rate) if drop_rate > 0. else nn.Identity()def forward(self, l, g, f):W_local = self.W_l(l) # local feature from Local Feature BlockW_global = self.W_g(g) # global feature from Global Feature Blockif f is not None:W_f = self.Updim(f)W_f = self.Avg(W_f)shortcut = W_fX_f = torch.cat([W_f, W_local, W_global], 1)X_f = self.norm1(X_f)X_f = self.W3(X_f)X_f = self.gelu(X_f)else:shortcut = 0X_f = torch.cat([W_local, W_global], 1)X_f = self.norm2(X_f)X_f = self.W(X_f)X_f = self.gelu(X_f)# spatial attention for ConvNeXt branchl_jump = lmax_result, _ = torch.max(l, dim=1, keepdim=True)avg_result = torch.mean(l, dim=1, keepdim=True)result = torch.cat([max_result, avg_result], 1)l = self.spatial(result)l = self.sigmoid(l) * l_jump# channel attetion for transformer branchg_jump = gmax_result=self.maxpool(g)avg_result=self.avgpool(g)max_out=self.se(max_result)avg_out=self.se(avg_result)g = self.sigmoid(max_out+avg_out) * g_jumpfuse = torch.cat([g, l, X_f], 1)fuse = self.norm3(fuse)fuse = self.residual(fuse)fuse = shortcut + self.drop_path(fuse)return fuseclass Conv(nn.Module):def __init__(self, inp_dim, out_dim, kernel_size=3, stride=1, bn=False, relu=True, bias=True, group=1):super(Conv, self).__init__()self.inp_dim = inp_dimself.conv = nn.Conv2d(inp_dim, out_dim, kernel_size, stride, padding=(kernel_size-1)//2, bias=bias)self.relu = Noneself.bn = Noneif relu:self.relu = nn.ReLU(inplace=True)if bn:self.bn = nn.BatchNorm2d(out_dim)def forward(self, x):assert x.size()[1] == self.inp_dim, "{} {}".format(x.size()[1], self.inp_dim)x = self.conv(x)if self.bn is not None:x = self.bn(x)if self.relu is not None:x = self.relu(x)return x#### Inverted Residual MLP
class IRMLP(nn.Module):def __init__(self, inp_dim, out_dim):super(IRMLP, self).__init__()self.conv1 = Conv(inp_dim, inp_dim, 3, relu=False, bias=False, group=inp_dim)self.conv2 = Conv(inp_dim, inp_dim * 4, 1, relu=False, bias=False)self.conv3 = Conv(inp_dim * 4, out_dim, 1, relu=False, bias=False, bn=True)self.gelu = nn.GELU()self.bn1 = nn.BatchNorm2d(inp_dim)def forward(self, x):residual = xout = self.conv1(x)out = self.gelu(out)out += residualout = self.bn1(out)out = self.conv2(out)out = self.gelu(out)out = self.conv3(out)return out####### Shift Window MSA #############class WindowAttention(nn.Module):r""" Window based multi-head self attention (W-MSA) module with relative position bias.It supports both of shifted and non-shifted window.Args:dim (int): Number of input channels.window_size (tuple[int]): The height and width of the window.num_heads (int): Number of attention heads.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueattn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0proj_drop (float, optional): Dropout ratio of output. Default: 0.0"""def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # [Mh, Mw]self.num_heads = num_headshead_dim = dim // num_headsself.scale = head_dim ** -0.5# define a parameter table of relative position biasself.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # [2*Mh-1 * 2*Mw-1, nH]# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing="ij")) # [2, Mh, Mw]coords_flatten = torch.flatten(coords, 1) # [2, Mh*Mw]# [2, Mh*Mw, 1] - [2, 1, Mh*Mw]relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # [2, Mh*Mw, Mh*Mw]relative_coords = relative_coords.permute(1, 2, 0).contiguous() # [Mh*Mw, Mh*Mw, 2]relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1) # [Mh*Mw, Mh*Mw]self.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)nn.init.trunc_normal_(self.relative_position_bias_table, std=.02)self.softmax = nn.Softmax(dim=-1)def forward(self, x, mask: Optional[torch.Tensor] = None):"""Args:x: input features with shape of (num_windows*B, Mh*Mw, C)mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None"""# [batch_size*num_windows, Mh*Mw, total_embed_dim]B_, N, C = x.shape# qkv(): -> [batch_size*num_windows, Mh*Mw, 3 * total_embed_dim]# reshape: -> [batch_size*num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]# permute: -> [3, batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)# [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)# transpose: -> [batch_size*num_windows, num_heads, embed_dim_per_head, Mh*Mw]# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, Mh*Mw]q = q * self.scaleattn = (q @ k.transpose(-2, -1))# relative_position_bias_table.view: [Mh*Mw*Mh*Mw,nH] -> [Mh*Mw,Mh*Mw,nH]relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # [nH, Mh*Mw, Mh*Mw]attn = attn + relative_position_bias.unsqueeze(0)if mask is not None:# mask: [nW, Mh*Mw, Mh*Mw]nW = mask.shape[0] # num_windows# attn.view: [batch_size, num_windows, num_heads, Mh*Mw, Mh*Mw]# mask.unsqueeze: [1, nW, 1, Mh*Mw, Mh*Mw]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)else:attn = self.softmax(attn)attn = self.attn_drop(attn)# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]# transpose: -> [batch_size*num_windows, Mh*Mw, num_heads, embed_dim_per_head]# reshape: -> [batch_size*num_windows, Mh*Mw, total_embed_dim]x = (attn @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)x = self.proj_drop(x)return x### Global Feature Block
class Global_block(nn.Module):r""" Global Feature Block from modified Swin Transformer Block.Args:dim (int): Number of input channels.num_heads (int): Number of attention heads.window_size (int): Window size.shift_size (int): Shift size for SW-MSA.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Truedrop (float, optional): Dropout rate. Default: 0.0attn_drop (float, optional): Attention dropout rate. Default: 0.0drop_path (float, optional): Stochastic depth rate. Default: 0.0act_layer (nn.Module, optional): Activation layer. Default: nn.GELUnorm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, dim, num_heads, window_size=7, shift_size=0,qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm):super().__init__()self.dim = dimself.num_heads = num_headsself.window_size = window_sizeself.shift_size = shift_sizeassert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"self.norm1 = norm_layer(dim)self.attn = WindowAttention(dim, window_size=(self.window_size, self.window_size), num_heads=num_heads, qkv_bias=qkv_bias,attn_drop=attn_drop, proj_drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)self.fc1 = nn.Linear(dim, dim)self.act = act_layer()def forward(self, x, attn_mask):H, W = self.H, self.WB, L, C = x.shapeassert L == H * W, "input feature has wrong size"shortcut = xx = self.norm1(x)x = x.view(B, H, W, C)pad_l = pad_t = 0pad_r = (self.window_size - W % self.window_size) % self.window_sizepad_b = (self.window_size - H % self.window_size) % self.window_sizex = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))_, Hp, Wp, _ = x.shape# cyclic shiftif self.shift_size > 0:shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))else:shifted_x = xattn_mask = None# partition windowsx_windows = window_partition(shifted_x, self.window_size) # [nW*B, Mh, Mw, C]x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [nW*B, Mh*Mw, C]# W-MSA/SW-MSAattn_windows = self.attn(x_windows, mask=attn_mask) # [nW*B, Mh*Mw, C]# merge windowsattn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [nW*B, Mh, Mw, C]shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H', W', C]# reverse cyclic shiftif self.shift_size > 0:x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))else:x = shifted_xif pad_r > 0 or pad_b > 0:x = x[:, :H, :W, :].contiguous()x = x.view(B, H * W, C)x = self.fc1(x)x = self.act(x)x = shortcut + self.drop_path(x)return xclass BasicLayer(nn.Module):"""Downsampling and Global Feature Block for one stage.Args:dim (int): Number of input channels.depth (int): Number of blocks.num_heads (int): Number of attention heads.window_size (int): Local window size.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Truedrop (float, optional): Dropout rate. Default: 0.0attn_drop (float, optional): Attention dropout rate. Default: 0.0drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormdownsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: Noneuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False."""def __init__(self, dim, depth, num_heads, window_size,mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):super().__init__()self.dim = dimself.depth = depthself.window_size = window_sizeself.use_checkpoint = use_checkpointself.shift_size = window_size // 2# build blocksself.blocks = nn.ModuleList([Global_block(dim=dim,num_heads=num_heads,window_size=window_size,shift_size=0 if (i % 2 == 0) else self.shift_size,qkv_bias=qkv_bias,drop=drop,attn_drop=attn_drop,drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,norm_layer=norm_layer)for i in range(depth)])# patch merging layerif downsample is not None:self.downsample = downsample(dim=dim, norm_layer=norm_layer)else:self.downsample = Nonedef create_mask(self, x, H, W):# calculate attention mask for SW-MSAHp = int(np.ceil(H / self.window_size)) * self.window_sizeWp = int(np.ceil(W / self.window_size)) * self.window_sizeimg_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # [1, Hp, Wp, 1]h_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))w_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cntcnt += 1mask_windows = window_partition(img_mask, self.window_size) # [nW, Mh, Mw, 1]mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # [nW, Mh*Mw]attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # [nW, 1, Mh*Mw] - [nW, Mh*Mw, 1]# [nW, Mh*Mw, Mh*Mw]attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))return attn_maskdef forward(self, x, H, W):if self.downsample is not None:x = self.downsample(x, H, W) #patch merging stage2 in [6,3136,96] out [6,784,192]H, W = (H + 1) // 2, (W + 1) // 2attn_mask = self.create_mask(x, H, W) # [nW, Mh*Mw, Mh*Mw]for blk in self.blocks: # global blockblk.H, blk.W = H, Wif not torch.jit.is_scripting() and self.use_checkpoint:x = checkpoint.checkpoint(blk, x, attn_mask)else:x = blk(x, attn_mask)return x, H, Wdef window_partition(x, window_size: int):"""Args:x: (B, H, W, C)window_size (int): window size(M)Returns:windows: (num_windows*B, window_size, window_size, C)"""B, H, W, C = x.shapex = x.view(B, H // window_size, window_size, W // window_size, window_size, C)# permute: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H//Mh, W//Mh, Mw, Mw, C]# view: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B*num_windows, Mh, Mw, C]windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)return windowsdef window_reverse(windows, window_size: int, H: int, W: int):"""Args:windows: (num_windows*B, window_size, window_size, C)window_size (int): Window size(M)H (int): Height of imageW (int): Width of imageReturns:x: (B, H, W, C)"""B = int(windows.shape[0] / (H * W / window_size / window_size))# view: [B*num_windows, Mh, Mw, C] -> [B, H//Mh, W//Mw, Mh, Mw, C]x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)# permute: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B, H//Mh, Mh, W//Mw, Mw, C]# view: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H, W, C]x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)return xclass PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, patch_size=4, in_c=3, embed_dim=96, norm_layer=None):super().__init__()patch_size = (patch_size, patch_size)self.patch_size = patch_sizeself.in_chans = in_cself.embed_dim = embed_dimself.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):_, _, H, W = x.shape# paddingpad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)if pad_input:# to pad the last 3 dimensions,# (W_left, W_right, H_top,H_bottom, C_front, C_back)x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],0, self.patch_size[0] - H % self.patch_size[0],0, 0))# downsample patch_size timesx = self.proj(x)_, _, H, W = x.shape# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = x.flatten(2).transpose(1, 2)x = self.norm(x)return x, H, Wclass PatchMerging(nn.Module):r""" Patch Merging Layer.Args:dim (int): Number of input channels.norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, dim, norm_layer=nn.LayerNorm):super().__init__()dim = dim//2self.dim = dimself.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)self.norm = norm_layer(4 * dim)def forward(self, x, H, W):"""x: B, H*W, C"""B, L, C = x.shapeassert L == H * W, "input feature has wrong size"x = x.view(B, H, W, C)# paddingpad_input = (H % 2 == 1) or (W % 2 == 1)if pad_input:# to pad the last 3 dimensions, starting from the last dimension and moving forward.# (C_front, C_back, W_left, W_right, H_top, H_bottom)x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C]x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C]x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C]x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C]x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]x = self.norm(x)x = self.reduction(x) # [B, H/2*W/2, 2*C]return xdef HiFuse_Tiny(num_classes: int):model = main_model(depths=(2, 2, 2, 2),conv_depths=(2, 2, 2, 2),num_classes=num_classes)return modeldef HiFuse_Small(num_classes: int):model = main_model(depths=(2, 2, 6, 2),conv_depths=(2, 2, 6, 2),num_classes=num_classes)return modeldef HiFuse_Base(num_classes: int):model = main_model(depths=(2, 2, 18, 2),conv_depths=(2, 2, 18, 2),num_classes=num_classes)return model
/cls_test.py
import os
import json
import argparse
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from cls_model import main_model as create_modeldef main(args):device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print(f"using {device} device.")test_data_path = args.test_data_pathtest_label_path = args.test_label_pathnum_classes = 2img_size = 224data_transform = transforms.Compose([transforms.Resize(int(256)),transforms.CenterCrop(img_size),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])test_img_path = []test_img_label = []with open(test_label_path, 'r', encoding='utf-8') as file:for line in file:if line.strip().split(',')[0] == 'case':continuetest_img_path.append(line.strip().split(',')[0]+'.png')test_img_label.append(line.strip().split(',')[1])# create modelmodel = create_model(num_classes=num_classes).to(device)# load model weightsmodel_weight_path = args.model_weight_pathmodel.load_state_dict(torch.load(model_weight_path, map_location=device, weights_only=True), strict=False)model.eval()infer_data = []# load imagefor i in range(0,len(test_img_path)):img_path = os.path.join(test_data_path, test_img_path[i])label = torch.tensor(int(test_img_label[i]), dtype=torch.long)assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)img = Image.open(img_path).convert('RGB')plt.imshow(img)# [N, C, H, W]img = data_transform(img)# expand batch dimensionimg = torch.unsqueeze(img, dim=0)with torch.no_grad():# predict classoutput = torch.squeeze(model(img.to(device))).cpu()predict = torch.softmax(output, dim=0)predict_cla = torch.argmax(predict).numpy()print_infer = "img: {} predict_class: {} prob: {:.3}".format([test_img_path[i]], [str(predict_cla)], predict[predict_cla].numpy())print(print_infer)infer_data.append((test_img_path[i].split('.')[0], str(predict_cla)))total = sum([param.nelement() for param in model.parameters()])print("Number of parameters: %.2fM" % (total/1e6))if not os.path.exists(args.save_path):with open(args.save_path, 'w', encoding='utf-8') as f:f.write('case,prob\n')else:with open(args.save_path, 'w', encoding='utf-8') as f:f.write('case,prob\n') # 追加数据到文件with open(args.save_path, 'a', encoding='utf-8') as f:for case, prob in infer_data:f.write(f'{case},{prob}\n')print("Successfully saved {} !".format(args.save_path))print('====> cls task test finished !')print('=' * 100)if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--test_data_path', type=str, default="/home/maojianzeng/2024dimtaic/tcdata/train/img")parser.add_argument('--test_label_path', type=str, default="/home/maojianzeng/2024dimtaic/tcdata/train/label.csv")parser.add_argument('--model_weight_path', type=str, default="model_weight/cls/best_model.pth")parser.add_argument('--save_path', type=str, default="submit/label.csv")opt = parser.parse_args()main(opt)
/cls_train.py
import os
import argparse
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from torch.utils.data import DataLoader
from cls_utils import MyDataset
from cls_model import HiFuse_Small as create_model
from cls_utils import create_lr_scheduler, get_params_groups, train_one_epoch, evaluatedef main(args):device = torch.device(args.device if torch.cuda.is_available() else "cpu")print(f"using {device} device.")print(args)print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')tb_writer = SummaryWriter()train_dataset = MyDataset(args.train_label_path,"train", args.train_data_path)val_dataset = MyDataset(args.val_label_path,"val", args.val_data_path)batch_size = args.batch_sizenw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)model = create_model(num_classes=args.num_classes).to(device)if args.RESUME == False:if args.weights != "":assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)weights_dict = torch.load(args.weights, map_location=device)['state_dict']# Delete the weight of the relevant categoryfor k in list(weights_dict.keys()):if "head" in k:del weights_dict[k]model.load_state_dict(weights_dict, strict=False)if args.freeze_layers:for name, para in model.named_parameters():# All weights except head are frozenif "head" not in name:para.requires_grad_(False)else:print("training {}".format(name))# pg = [p for p in model.parameters() if p.requires_grad]pg = get_params_groups(model, weight_decay=args.wd)optimizer = optim.AdamW(pg, lr=args.lr, weight_decay=args.wd)lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs,warmup=True, warmup_epochs=2)best_acc = 0.start_epoch = 0# if args.RESUME:# path_checkpoint = "./model_weight/checkpoint/ckpt_best_100.pth"# print("model continue train")# checkpoint = torch.load(path_checkpoint)# model.load_state_dict(checkpoint['net'])# optimizer.load_state_dict(checkpoint['optimizer'])# start_epoch = checkpoint['epoch']# lr_scheduler.load_state_dict(checkpoint['lr_schedule'])for epoch in range(start_epoch + 1, args.epochs + 1):# traintrain_loss, train_acc = train_one_epoch(model=model,optimizer=optimizer,data_loader=train_loader,device=device,epoch=epoch,lr_scheduler=lr_scheduler)# validateval_loss, val_acc = evaluate(model=model,data_loader=val_loader,device=device,epoch=epoch)tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]tb_writer.add_scalar(tags[0], train_loss, epoch)tb_writer.add_scalar(tags[1], train_acc, epoch)tb_writer.add_scalar(tags[2], val_loss, epoch)tb_writer.add_scalar(tags[3], val_acc, epoch)tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)if best_acc < val_acc:if not os.path.isdir(args.save_dir):os.mkdir(args.save_dir)torch.save(model.state_dict(), args.save_best_model_path)print("Saved epoch{} as new best model".format(epoch))best_acc = val_accif epoch % 10 == 0:print('epoch:', epoch)print('learning rate:', optimizer.state_dict()['param_groups'][0]['lr'])checkpoint = {"net": model.state_dict(),'optimizer': optimizer.state_dict(),"epoch": epoch,'lr_schedule': lr_scheduler.state_dict()}if not os.path.isdir(args.checkpoint_path):os.mkdir(args.checkpoint_path)torch.save(checkpoint, args.checkpoint_path +'/ckpt_best_%s.pth' % (str(epoch)))#add loss, acc and lr into tensorboardprint("[epoch {}] accuracy: {}".format(epoch, round(val_acc, 3)))total = sum([param.nelement() for param in model.parameters()])print("Number of parameters: %.2fM" % (total/1e6))print('====> cls task train finished !')print('=' * 100)if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--num_classes', type=int, default=2)parser.add_argument('--epochs', type=int, default=20)parser.add_argument('--batch-size', type=int, default=4)parser.add_argument('--lr', type=float, default=1e-4)parser.add_argument('--wd', type=float, default=1e-2)parser.add_argument('--RESUME', type=bool, default=True)parser.add_argument('--train_data_path', type=str, default="/home/maojianzeng/2024dimtaic/tcdata/train/img")parser.add_argument('--val_data_path', type=str, default="/home/maojianzeng/2024dimtaic/tcdata/train/img")parser.add_argument('--train_label_path', type=str, default="/home/maojianzeng/2024dimtaic/tcdata/train/label.csv")parser.add_argument('--val_label_path', type=str, default="/home/maojianzeng/2024dimtaic/tcdata/train/label.csv")parser.add_argument('--save_dir', type=str, default="/mnt/home/maojianzeng/2024dimtaic/SAM2-UNet/model_weight/cls")parser.add_argument('--save_best_model_path', type=str, default="/mnt/home/maojianzeng/2024dimtaic/SAM2-UNet/model_weight/cls/best_model.pth")parser.add_argument('--checkpoint_path', type=str, default="/mnt/home/maojianzeng/2024dimtaic/SAM2-UNet/model_weight/cls/checkpoint")parser.add_argument('--weights', type=str, default='',help='initial weights path')parser.add_argument('--freeze-layers', type=bool, default=False)parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')opt = parser.parse_args()main(opt)
/Dockerfile
## 获取基础镜像
FROM registry.cn-shanghai.aliyuncs.com/tcc-public/pytorch:2.0.0-py3.9.12-cuda11.8.0-u22.04
## 把当前文件夹里的文件构建到镜像的根目录下,并设置为默认工作目录
ADD . /
WORKDIR /
## 复制文件,确保可以找到requirements.txt
COPY requirements.txt /requirements.txt
## 安装python环境的依赖包
RUN pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
## 添加可执行权限
RUN chmod +x app/run.sh
## 执行命令
CMD [ "sh", "app/run.sh" ]/cls_utils.py
import os
import sys
import json
import pickle
import random
import math
from PIL import Image
import torch
from tqdm import tqdm
import matplotlib.pyplot as plt
from torch.utils.data import Dataset
from torch.utils.data import Dataset
import torchvision.transforms as transformsdef plot_data_loader_image(data_loader):batch_size = data_loader.batch_sizeplot_num = min(batch_size, 4)json_path = './class_indices.json'assert os.path.exists(json_path), json_path + " does not exist."json_file = open(json_path, 'r')class_indices = json.load(json_file)for data in data_loader:images, labels = datafor i in range(plot_num):# [C, H, W] -> [H, W, C]img = images[i].numpy().transpose(1, 2, 0)img = (img * [0.5, 0.5, 0.5] + [0.5, 0.5, 0.5]) * 255label = labels[i].item()plt.subplot(1, plot_num, i+1)plt.xlabel(class_indices[str(label)])plt.xticks([])plt.yticks([])plt.imshow(img.astype('uint8'))plt.show()def write_pickle(list_info: list, file_name: str):with open(file_name, 'wb') as f:pickle.dump(list_info, f)def read_pickle(file_name: str) -> list:with open(file_name, 'rb') as f:info_list = pickle.load(f)return info_listdef train_one_epoch(model, optimizer, data_loader, device, epoch, lr_scheduler):model.train()loss_function = torch.nn.CrossEntropyLoss()accu_loss = torch.zeros(1).to(device)accu_num = torch.zeros(1).to(device)optimizer.zero_grad()sample_num = 0data_loader = tqdm(data_loader, file=sys.stdout)for step, data in enumerate(data_loader):images, labels = datasample_num += images.shape[0]pred = model(images.to(device))pred_classes = torch.max(pred, dim=1)[1]accu_num += torch.eq(pred_classes, labels.to(device)).sum()loss = loss_function(pred, labels.to(device))loss.backward()accu_loss += loss.detach()data_loader.desc = "[train epoch {}] loss: {:.3f}, acc: {:.3f}, lr: {:.5f}".format(epoch,accu_loss.item() / (step + 1),accu_num.item() / sample_num,optimizer.param_groups[0]["lr"])if not torch.isfinite(loss):print('WARNING: non-finite loss, ending training ', loss)sys.exit(1)optimizer.step()optimizer.zero_grad()# update lrlr_scheduler.step()return accu_loss.item() / (step + 1), accu_num.item() / sample_numclass MyDataset(Dataset):def __init__(self, label_path, mode, data_path):self.img_path = []self.label = []self.mode = data_pathwith open(label_path, 'r', encoding='utf-8') as file:for line in file:if line.strip().split(',')[0] == 'case':continueself.img_path.append(line.strip().split(',')[0]+'.png')self.label.append(line.strip().split(',')[1])img_size = 224if mode == "train":self.transform = transforms.Compose([transforms.Resize((img_size, img_size)),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])else:self.transform = transforms.Compose([transforms.Resize((img_size, img_size)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])# 测试
# print(len(self.img_path))self.img_path = self.img_path[:]self.label = self.label[:]def __len__(self):return len(self.label)def __getitem__(self, i):image_path = os.path.join(self.mode, self.img_path[i])image = Image.open(image_path).convert('RGB')image = self.transform(image)label = torch.tensor(int(self.label[i]), dtype=torch.long)# for some augmentation code, waiting...return image, label@torch.no_grad()
def evaluate(model, data_loader, device, epoch):loss_function = torch.nn.CrossEntropyLoss()model.eval()accu_num = torch.zeros(1).to(device)accu_loss = torch.zeros(1).to(device)sample_num = 0data_loader = tqdm(data_loader, file=sys.stdout)for step, data in enumerate(data_loader):images, labels = datasample_num += images.shape[0]pred = model(images.to(device))pred_classes = torch.max(pred, dim=1)[1]accu_num += torch.eq(pred_classes, labels.to(device)).sum()loss = loss_function(pred, labels.to(device))accu_loss += lossdata_loader.desc = "[valid epoch {}] loss: {:.3f}, acc: {:.3f}".format(epoch,accu_loss.item() / (step + 1),accu_num.item() / sample_num)return accu_loss.item() / (step + 1), accu_num.item() / sample_numdef create_lr_scheduler(optimizer,num_step: int,epochs: int,warmup=True,warmup_epochs=1,warmup_factor=1e-3,end_factor=1e-2):assert num_step > 0 and epochs > 0if warmup is False:warmup_epochs = 0def f(x):if warmup is True and x <= (warmup_epochs * num_step):alpha = float(x) / (warmup_epochs * num_step)return warmup_factor * (1 - alpha) + alphaelse:current_step = (x - warmup_epochs * num_step)cosine_steps = (epochs - warmup_epochs) * num_stepreturn ((1 + math.cos(current_step * math.pi / cosine_steps)) / 2) * (1 - end_factor) + end_factorreturn torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)def get_params_groups(model: torch.nn.Module, weight_decay: float = 1e-5):parameter_group_vars = {"decay": {"params": [], "weight_decay": weight_decay},"no_decay": {"params": [], "weight_decay": 0.}}parameter_group_names = {"decay": {"params": [], "weight_decay": weight_decay},"no_decay": {"params": [], "weight_decay": 0.}}for name, param in model.named_parameters():if not param.requires_grad:continue # frozen weightsif len(param.shape) == 1 or name.endswith(".bias"):group_name = "no_decay"else:group_name = "decay"parameter_group_vars[group_name]["params"].append(param)parameter_group_names[group_name]["params"].append(name)# print("Param groups = %s" % json.dumps(parameter_group_names, indent=2))return list(parameter_group_vars.values())
/dataset.py
import torchvision.transforms.functional as F
import numpy as np
import random
import os
from PIL import Image
from torchvision.transforms import InterpolationMode
from torch.utils.data import Dataset
from torchvision import transforms
from PIL import Imageclass ToTensor(object):def __call__(self, data):image, label = data['image'], data['label']return {'image': F.to_tensor(image), 'label': F.to_tensor(label)}class Resize(object):def __init__(self, size):self.size = sizedef __call__(self, data):image, label = data['image'], data['label']return {'image': F.resize(image, self.size), 'label': F.resize(label, self.size, interpolation=InterpolationMode.BICUBIC)}class RandomHorizontalFlip(object):def __init__(self, p=0.5):self.p = pdef __call__(self, data):image, label = data['image'], data['label']if random.random() < self.p:return {'image': F.hflip(image), 'label': F.hflip(label)}return {'image': image, 'label': label}class RandomVerticalFlip(object):def __init__(self, p=0.5):self.p = pdef __call__(self, data):image, label = data['image'], data['label']if random.random() < self.p:return {'image': F.vflip(image), 'label': F.vflip(label)}return {'image': image, 'label': label}class Normalize(object):def __init__(self, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):self.mean = meanself.std = stddef __call__(self, sample):image, label = sample['image'], sample['label']image = F.normalize(image, self.mean, self.std)return {'image': image, 'label': label}class FullDataset(Dataset):def __init__(self, image_root, gt_root, size, mode):self.images = [image_root + f for f in os.listdir(image_root) if f.endswith('.jpg') or f.endswith('.png')]self.gts = [gt_root + f for f in os.listdir(gt_root) if f.endswith('.png')]self.images = sorted(self.images)self.gts = sorted(self.gts)if mode == 'train':self.transform = transforms.Compose([Resize((size, size)),RandomHorizontalFlip(p=0.5),RandomVerticalFlip(p=0.5),ToTensor(),Normalize()])else:self.transform = transforms.Compose([Resize((size, size)),ToTensor(),Normalize()])def __getitem__(self, idx):image = self.rgb_loader(self.images[idx])label = self.binary_loader(self.gts[idx])data = {'image': image, 'label': label}data = self.transform(data)return datadef __len__(self):return len(self.images)def rgb_loader(self, path):with open(path, 'rb') as f:img = Image.open(f)return img.convert('RGB')def binary_loader(self, path):with open(path, 'rb') as f:img = Image.open(f)return img.convert('L')class TestDataset:def __init__(self, image_root, gt_root, size):self.images = [image_root + f for f in os.listdir(image_root) if f.endswith('.jpg') or f.endswith('.png')]self.gts = [gt_root + f for f in os.listdir(gt_root) if f.endswith('.png')]self.images = sorted(self.images)self.gts = sorted(self.gts)self.transform = transforms.Compose([transforms.Resize((size, size)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])self.gt_transform = transforms.ToTensor()self.size = len(self.images)self.index = 0def load_data(self):image = self.rgb_loader(self.images[self.index])image = self.transform(image).unsqueeze(0)gt = self.binary_loader(self.gts[self.index])gt = np.array(gt)name = self.images[self.index].split('/')[-1]self.index += 1return image, gt, namedef rgb_loader(self, path):with open(path, 'rb') as f:img = Image.open(f)return img.convert('RGB')def binary_loader(self, path):with open(path, 'rb') as f:img = Image.open(f)return img.convert('L')/requirements.txt
torch==2.4.0
torchaudio
torchvision
-f https://download.pytorch.org/whl/cu118
hydra-core==1.3.2
tqdm==4.65.2
urllib==3.12
imageio
pysodmetrics
matplotlib
numpy
tensorboard/SAM2UNet.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from sam2.build_sam import build_sam2class DoubleConv(nn.Module):"""(convolution => [BN] => ReLU) * 2"""def __init__(self, in_channels, out_channels, mid_channels=None):super().__init__()if not mid_channels:mid_channels = out_channelsself.double_conv = nn.Sequential(nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(mid_channels),nn.ReLU(inplace=True),nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))def forward(self, x):return self.double_conv(x)class Up(nn.Module):"""Upscaling then double conv"""def __init__(self, in_channels, out_channels):super().__init__()self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)def forward(self, x1, x2):x1 = self.up(x1)# input is CHWdiffY = x2.size()[2] - x1.size()[2]diffX = x2.size()[3] - x1.size()[3]x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,diffY // 2, diffY - diffY // 2])# if you have padding issues, see# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bdx = torch.cat([x2, x1], dim=1)return self.conv(x)class Adapter(nn.Module):def __init__(self, blk) -> None:super(Adapter, self).__init__()self.block = blkdim = blk.attn.qkv.in_featuresself.prompt_learn = nn.Sequential(nn.Linear(dim, 32),nn.GELU(),nn.Linear(32, dim),nn.GELU())def forward(self, x):prompt = self.prompt_learn(x)promped = x + promptnet = self.block(promped)return netclass BasicConv2d(nn.Module):def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_planes, out_planes,kernel_size=kernel_size, stride=stride,padding=padding, dilation=dilation, bias=False)self.bn = nn.BatchNorm2d(out_planes)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv(x)x = self.bn(x)return xclass RFB_modified(nn.Module):def __init__(self, in_channel, out_channel):super(RFB_modified, self).__init__()self.relu = nn.ReLU(True)self.branch0 = nn.Sequential(BasicConv2d(in_channel, out_channel, 1),)self.branch1 = nn.Sequential(BasicConv2d(in_channel, out_channel, 1),BasicConv2d(out_channel, out_channel, kernel_size=(1, 3), padding=(0, 1)),BasicConv2d(out_channel, out_channel, kernel_size=(3, 1), padding=(1, 0)),BasicConv2d(out_channel, out_channel, 3, padding=3, dilation=3))self.branch2 = nn.Sequential(BasicConv2d(in_channel, out_channel, 1),BasicConv2d(out_channel, out_channel, kernel_size=(1, 5), padding=(0, 2)),BasicConv2d(out_channel, out_channel, kernel_size=(5, 1), padding=(2, 0)),BasicConv2d(out_channel, out_channel, 3, padding=5, dilation=5))self.branch3 = nn.Sequential(BasicConv2d(in_channel, out_channel, 1),BasicConv2d(out_channel, out_channel, kernel_size=(1, 7), padding=(0, 3)),BasicConv2d(out_channel, out_channel, kernel_size=(7, 1), padding=(3, 0)),BasicConv2d(out_channel, out_channel, 3, padding=7, dilation=7))self.conv_cat = BasicConv2d(4*out_channel, out_channel, 3, padding=1)self.conv_res = BasicConv2d(in_channel, out_channel, 1)def forward(self, x):x0 = self.branch0(x)x1 = self.branch1(x)x2 = self.branch2(x)x3 = self.branch3(x)x_cat = self.conv_cat(torch.cat((x0, x1, x2, x3), 1))x = self.relu(x_cat + self.conv_res(x))return xclass SAM2UNet(nn.Module):def __init__(self, checkpoint_path=None) -> None:super(SAM2UNet, self).__init__() model_cfg = "sam2_hiera_l.yaml"if checkpoint_path:print('Useing pretrained sam2 model {}'.format(checkpoint_path))model = build_sam2(model_cfg, checkpoint_path)else:model = build_sam2(model_cfg)del model.sam_mask_decoderdel model.sam_prompt_encoderdel model.memory_encoderdel model.memory_attentiondel model.mask_downsampledel model.obj_ptr_tpos_projdel model.obj_ptr_projdel model.image_encoder.neckself.encoder = model.image_encoder.trunkfor param in self.encoder.parameters():param.requires_grad = Falseblocks = []for block in self.encoder.blocks:blocks.append(Adapter(block))self.encoder.blocks = nn.Sequential(*blocks)self.rfb1 = RFB_modified(144, 64)self.rfb2 = RFB_modified(288, 64)self.rfb3 = RFB_modified(576, 64)self.rfb4 = RFB_modified(1152, 64)self.up1 = (Up(128, 64))self.up2 = (Up(128, 64))self.up3 = (Up(128, 64))self.up4 = (Up(128, 64))self.side1 = nn.Conv2d(64, 1, kernel_size=1)self.side2 = nn.Conv2d(64, 1, kernel_size=1)self.head = nn.Conv2d(64, 1, kernel_size=1)def forward(self, x):x1, x2, x3, x4 = self.encoder(x)x1, x2, x3, x4 = self.rfb1(x1), self.rfb2(x2), self.rfb3(x3), self.rfb4(x4)x = self.up1(x4, x3)out1 = F.interpolate(self.side1(x), scale_factor=16, mode='bilinear')x = self.up2(x, x2)out2 = F.interpolate(self.side2(x), scale_factor=8, mode='bilinear')x = self.up3(x, x1)out = F.interpolate(self.head(x), scale_factor=4, mode='bilinear')return out, out1, out2if __name__ == "__main__":with torch.no_grad():model = SAM2UNet().cuda()x = torch.randn(1, 3, 352, 352).cuda()out, out1, out2 = model(x)print(out.shape, out1.shape, out2.shape)/seg_eval.py
import os
import cv2
import py_sod_metrics
import argparseFM = py_sod_metrics.Fmeasure()
WFM = py_sod_metrics.WeightedFmeasure()
SM = py_sod_metrics.Smeasure()
EM = py_sod_metrics.Emeasure()
MAE = py_sod_metrics.MAE()
MSIOU = py_sod_metrics.MSIoU()parser = argparse.ArgumentParser()
parser.add_argument("--dataset_name", type=str, required=True, help="path to the prediction results")
parser.add_argument("--pred_path", type=str, required=True, help="path to the prediction results")
parser.add_argument("--gt_path", type=str, required=True,help="path to the ground truth masks")
args = parser.parse_args()sample_gray = dict(with_adaptive=True, with_dynamic=True)
sample_bin = dict(with_adaptive=False, with_dynamic=False, with_binary=True, sample_based=True)
overall_bin = dict(with_adaptive=False, with_dynamic=False, with_binary=True, sample_based=False)
FMv2 = py_sod_metrics.FmeasureV2(metric_handlers={"fm": py_sod_metrics.FmeasureHandler(**sample_gray, beta=0.3),"f1": py_sod_metrics.FmeasureHandler(**sample_gray, beta=1),"pre": py_sod_metrics.PrecisionHandler(**sample_gray),"rec": py_sod_metrics.RecallHandler(**sample_gray),"fpr": py_sod_metrics.FPRHandler(**sample_gray),"iou": py_sod_metrics.IOUHandler(**sample_gray),"dice": py_sod_metrics.DICEHandler(**sample_gray),"spec": py_sod_metrics.SpecificityHandler(**sample_gray),"ber": py_sod_metrics.BERHandler(**sample_gray),"oa": py_sod_metrics.OverallAccuracyHandler(**sample_gray),"kappa": py_sod_metrics.KappaHandler(**sample_gray),"sample_bifm": py_sod_metrics.FmeasureHandler(**sample_bin, beta=0.3),"sample_bif1": py_sod_metrics.FmeasureHandler(**sample_bin, beta=1),"sample_bipre": py_sod_metrics.PrecisionHandler(**sample_bin),"sample_birec": py_sod_metrics.RecallHandler(**sample_bin),"sample_bifpr": py_sod_metrics.FPRHandler(**sample_bin),"sample_biiou": py_sod_metrics.IOUHandler(**sample_bin),"sample_bidice": py_sod_metrics.DICEHandler(**sample_bin),"sample_bispec": py_sod_metrics.SpecificityHandler(**sample_bin),"sample_biber": py_sod_metrics.BERHandler(**sample_bin),"sample_bioa": py_sod_metrics.OverallAccuracyHandler(**sample_bin),"sample_bikappa": py_sod_metrics.KappaHandler(**sample_bin),"overall_bifm": py_sod_metrics.FmeasureHandler(**overall_bin, beta=0.3),"overall_bif1": py_sod_metrics.FmeasureHandler(**overall_bin, beta=1),"overall_bipre": py_sod_metrics.PrecisionHandler(**overall_bin),"overall_birec": py_sod_metrics.RecallHandler(**overall_bin),"overall_bifpr": py_sod_metrics.FPRHandler(**overall_bin),"overall_biiou": py_sod_metrics.IOUHandler(**overall_bin),"overall_bidice": py_sod_metrics.DICEHandler(**overall_bin),"overall_bispec": py_sod_metrics.SpecificityHandler(**overall_bin),"overall_biber": py_sod_metrics.BERHandler(**overall_bin),"overall_bioa": py_sod_metrics.OverallAccuracyHandler(**overall_bin),"overall_bikappa": py_sod_metrics.KappaHandler(**overall_bin),}
)pred_root = args.pred_path
mask_root = args.gt_path
mask_name_list = sorted(os.listdir(mask_root))
for i, mask_name in enumerate(mask_name_list):print(f"[{i}] Processing {mask_name}...")mask_path = os.path.join(mask_root, mask_name)pred_path = os.path.join(pred_root, mask_name[:-4] + '.png')mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)pred = cv2.imread(pred_path, cv2.IMREAD_GRAYSCALE)FM.step(pred=pred, gt=mask)WFM.step(pred=pred, gt=mask)SM.step(pred=pred, gt=mask)EM.step(pred=pred, gt=mask)MAE.step(pred=pred, gt=mask)FMv2.step(pred=pred, gt=mask)fm = FM.get_results()["fm"]
wfm = WFM.get_results()["wfm"]
sm = SM.get_results()["sm"]
em = EM.get_results()["em"]
mae = MAE.get_results()["mae"]
fmv2 = FMv2.get_results()curr_results = {"meandice": fmv2["dice"]["dynamic"].mean(),"meaniou": fmv2["iou"]["dynamic"].mean(),'Smeasure': sm,"wFmeasure": wfm, # For Marine Animal Segmentation"adpFm": fm["adp"], # For Camouflaged Object Detection"meanEm": em["curve"].mean(),"MAE": mae,
}print(args.dataset_name)
print("mDice: ", format(curr_results['meandice'], '.3f'))
print("mIoU: ", format(curr_results['meaniou'], '.3f'))
print("S_{alpha}: ", format(curr_results['Smeasure'], '.3f'))
print("F^{w}_{beta}:", format(curr_results['wFmeasure'], '.3f'))
print("F_{beta}: ", format(curr_results['adpFm'], '.3f'))
print("E_{phi}: ", format(curr_results['meanEm'], '.3f'))
print("MAE: ", format(curr_results['MAE'], '.3f'))/seg_test.py
import argparse
import os
import torch
import imageio
import numpy as np
import torch.nn.functional as F
from SAM2UNet import SAM2UNet
from dataset import TestDatasetparser = argparse.ArgumentParser()
parser.add_argument("--checkpoint", type=str, required=True,help="path to the checkpoint of sam2-unet")
parser.add_argument("--test_image_path", type=str, required=True, help="path to the image files for testing")
parser.add_argument("--test_gt_path", type=str, required=True,help="path to the mask files for testing")
parser.add_argument("--save_path", type=str, required=True,help="path to save the predicted masks")
args = parser.parse_args()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
test_loader = TestDataset(args.test_image_path, args.test_gt_path, 352)
model = SAM2UNet().to(device)
model.load_state_dict(torch.load(args.checkpoint), strict=True)
model.eval()
model.cuda()
os.makedirs(args.save_path, exist_ok=True)
for i in range(test_loader.size):with torch.no_grad():image, gt, name = test_loader.load_data()gt = np.asarray(gt, np.float32)image = image.to(device)res, _, _ = model(image)res = torch.sigmoid(res)res = F.upsample(res, size=gt.shape, mode='bilinear', align_corners=False)res = res.sigmoid().data.cpu()res = res.numpy().squeeze()res = (res - res.min()) / (res.max() - res.min() + 1e-8)res = (res * 255).astype(np.uint8)print("Saving " + name)imageio.imsave(os.path.join(args.save_path, name[:-4] + ".png"), res)
print('====> seg task test finished !')
print('=' * 100)/seg_train.py
import os
import argparse
import random
import numpy as np
import torch
import torch.optim as opt
import torch.nn.functional as F
import urllib.request
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import CosineAnnealingLR
from dataset import FullDataset
from SAM2UNet import SAM2UNetparser = argparse.ArgumentParser("SAM2-UNet")
parser.add_argument("--hiera_path", type=str, required=True, help="path to the sam2 pretrained hiera")
parser.add_argument("--train_image_path", type=str, required=True, help="path to the image that used to train the model")
parser.add_argument("--train_mask_path", type=str, required=True,help="path to the mask file for training")
parser.add_argument('--save_path', type=str, required=True,help="path to store the checkpoint")
parser.add_argument("--epoch", type=int, default=20, help="training epochs")
parser.add_argument("--lr", type=float, default=0.001, help="learning rate")
parser.add_argument("--batch_size", default=12, type=int)
parser.add_argument("--weight_decay", default=5e-4, type=float)
args = parser.parse_args()def structure_loss(pred, mask):weit = 1 + 5*torch.abs(F.avg_pool2d(mask, kernel_size=31, stride=1, padding=15) - mask)wbce = F.binary_cross_entropy_with_logits(pred, mask, reduce='none')wbce = (weit*wbce).sum(dim=(2, 3)) / weit.sum(dim=(2, 3))pred = torch.sigmoid(pred)inter = ((pred * mask)*weit).sum(dim=(2, 3))union = ((pred + mask)*weit).sum(dim=(2, 3))wiou = 1 - (inter + 1)/(union - inter+1)return (wbce + wiou).mean()def main(args): if not os.path.exists(args.hiera_path):urllib.request.urlretrieve('https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_large.pt', args.hiera_path)dataset = FullDataset(args.train_image_path, args.train_mask_path, 352, mode='train')dataloader = DataLoader(dataset, batch_size=args.batch_size, shuffle=True, num_workers=8)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = SAM2UNet(args.hiera_path)model.to(device)optim = opt.AdamW([{"params":model.parameters(), "initia_lr": args.lr}], lr=args.lr, weight_decay=args.weight_decay)scheduler = CosineAnnealingLR(optim, args.epoch, eta_min=1.0e-7)os.makedirs(args.save_path, exist_ok=True)for epoch in range(args.epoch):for i, batch in enumerate(dataloader):x = batch['image']target = batch['label']x = x.to(device)target = target.to(device)optim.zero_grad()pred0, pred1, pred2 = model(x)loss0 = structure_loss(pred0, target)loss1 = structure_loss(pred1, target)loss2 = structure_loss(pred2, target)loss = loss0 + loss1 + loss2loss.backward()optim.step()if i % 50 == 0:print("epoch:{}-{}: loss:{}".format(epoch + 1, i + 1, loss.item()))scheduler.step()if (epoch+1) % 10 == 0 or (epoch+1) == args.epoch:torch.save(model.state_dict(), os.path.join(args.save_path, 'SAM2-UNet-%d.pth' % (epoch + 1)))print('[Saving Snapshot:]', os.path.join(args.save_path, 'SAM2-UNet-%d.pth'% (epoch + 1)))print('====> seg task train finished!')print('=' * 100)if __name__ == "__main__":main(args)使用说明
/Dockerfile 用于构建镜像
构建镜像:docker build -t crpi-r9nj0o3w4rzf4gao.cn-shanghai.personal.cr.aliyuncs.com/2024-dimtaic-mjz/2024-dimtaic/test:0.1 .
上传镜像仓库:docker push crpi-r9nj0o3w4rzf4gao.cn-shanghai.personal.cr.aliyuncs.com/2024-dimtaic-mjz/2024-dimtaic/test:0.1
/app 目录为使用入口,运行run.sh可以一键完成分类、分隔模型的训练和测试,生成结果文件,submit.zip为提交结果
/model_weight 用于存放训练过程的checkpoints和训练好的模型文件
/pretrained_model 用于存放训练使用到的预训练模型参数
/sam2,/sam2_configs 两个目录为SAM2项目的默认文件,保持原样
/tcdata 为数据集存放路径
相关文章:
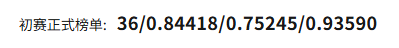
DiMTAIC 2024 数字医学技术及应用创新大赛-甲状腺B超静态及动态影像算法赛-参赛项目
参赛成绩 项目介绍 去年参加完这个比赛之后,整理了项目文件和代码,虽然比赛没有获奖,但是参赛过程中自己也很有收获,自己一个人搭建了完整的pipeline并基于此提交了多次提高成绩,现在把这个项目梳理成博客,…...
window安装docker\docker-compose
安装前配置 打开控制面板,参照下图打开“启动或关闭windows功能”,Hyper-V 和容器需要启用 程序和功能 启动或关闭windows功能 勾选Hyper-V 安装路径配置 Docker在Windows上的默认安装路径为C:\Program Files\Docker。 以管理员身份运行CMD在D盘,dev文件夹下创建Docker文…...
Jenkins的学习与使用(CI/CD)
文章目录 前言背景CI/CDJenkins简介Jenkins特性 安装Jenkins工作流程(仅供参考)安装maven和其他插件新建任务任务源码管理配置maven配置git(非必需) 尝试手动构建jar包可能遇到的错误 发布到远程服务器前置清理工作构建触发器git钩…...
)
vue-14(使用 ‘router.push‘ 和 ‘router.replace‘ 进行编程导航)
使用 ‘router.push’ 和 ‘router.replace’ 进行编程导航 编程导航是使用 Vue Router 构建动态和交互式 Web 应用程序的一个重要方面。它允许您根据应用程序逻辑、用户作或特定条件控制用户的导航流。您可以使用 router.push 和 router.replace 方法以编程方式导航到不同的路…...

使用WPF的Microsoft.Xaml.Behaviors.Wpf中通用 UI 元素事件
Nuget下载之后记得要先引用下面的 xmlns:i"http://schemas.microsoft.com/xaml/behaviors" <!-- 鼠标事件 --> <i:EventTrigger EventName"MouseEnter"/> <!-- 鼠标进入 --> <i:EventTrigger EventName"MouseLeave"/&g…...
功能介绍)
Elasticsearch中的监控(Monitoring)功能介绍
Elasticsearch 的 监控(Monitoring) 功能用于实时跟踪集群的运行状态、性能指标和资源使用情况,帮助管理员及时发现潜在问题、优化配置并确保集群稳定高效运行。它通过内置工具和集成方案,提供从节点到集群、从硬件到服务层的全方…...
Centos7.6图文安装mysql8.4详细步骤记录
1 前提条件 1.1 关闭数据库服务器的防火墙 # 关闭数据库服务器的防火墙 systemctl stop firewalld systemctl disable firewalld 1.2 关闭SELinux # 编辑 /etc/selinux/configvi /etc/selinux/config#内容更改为disabledSELINUXdisabled 1.3 卸载系统自身带的mysql&#…...
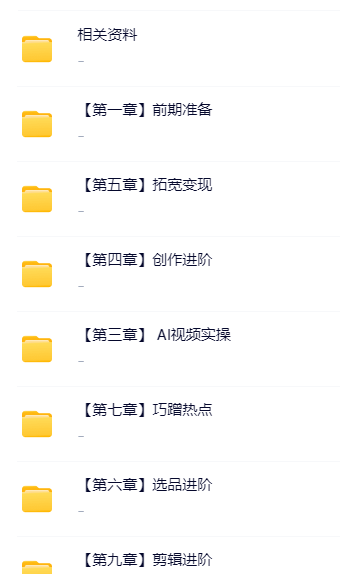
AI短视频创富营
课程内容: 相关资料 【第一章】前期准备 001.【涨粉技巧】新账号如何快速涨粉?_ev(1).mp4 002.【带贷权限】如何开通账号带贷权限?(1).mp4 003.【费用缴纳】如何缴纳账号保证金?_ev(1).mp4 004.【账号检测】如何检测账号是否限流?(1).mp4 005.【风险规避…...
纹理(Texture))
C++.OpenGL (4/64)纹理(Texture)
纹理(Texture) 纹理映射核心流程 #mermaid-svg-XxVbt4fizulzb5H3 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-XxVbt4fizulzb5H3 .error-icon{fill:#552222;}#mermaid-svg-XxVbt4fizulzb5H3 .error-text{fill:…...

spring中的@RabbitListener注解详解
基本用法主要属性1. queues / queueNames2. containerFactory3. id4. concurrency5. ackMode6. priority7. bindings 高级特性1. 消息转换器2. 手动确认3. 条件监听4. 错误处理 配置监听容器工厂注意事项完整示例循环依赖解决1. 使用 Setter 注入2. 使用 Lazy 注解3. 重构代码结…...
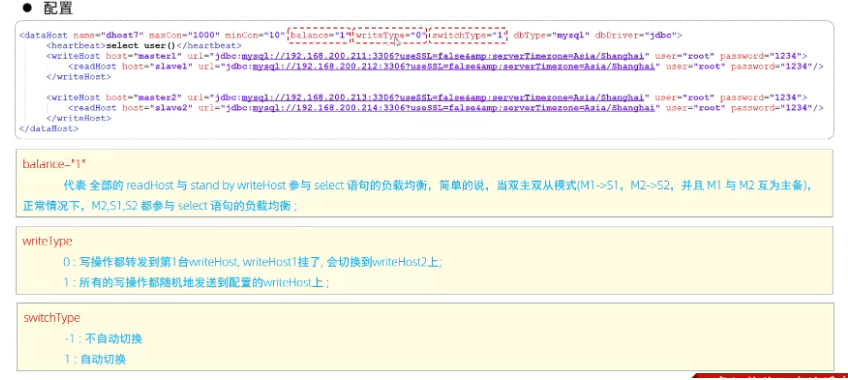
MySQL-运维篇
运维篇 日志 错误日志 错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。 该日志是默认开启的&am…...
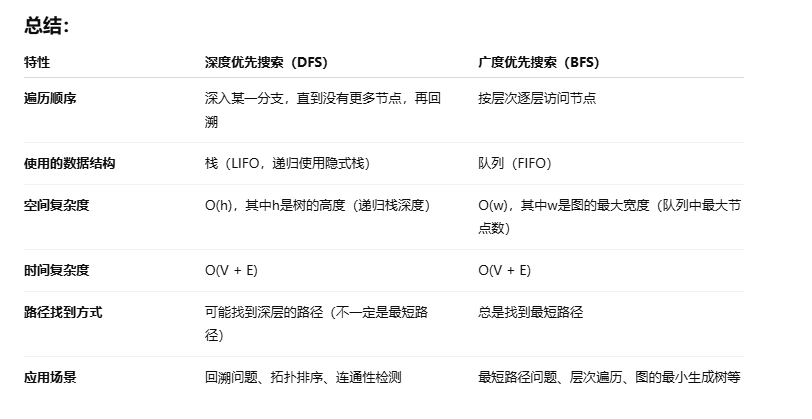
深度优先算法学习
1: 从 1点出发到 15点 #include <stdio.h>#define MAX_NODES 100typedef struct {int node_id;int *nextNodes;int nextNodesSize; } Node;// 假设我们有一个节点数组,全局保存了所有节点 Node nodes[MAX_NODES];void dfs(int node_id) {Node *node &n…...

青少年编程与数学 01-011 系统软件简介 08 Windows操作系统
青少年编程与数学 01-011 系统软件简介 08 Windows操作系统 1. Windows操作系统的起源与发展1.1 早期版本(1985-1995)1.2 Windows 9x系列(1995-2000)1.3 Windows NT系列(1993-2001)1.4 Windows XP及以后版…...
前端技能包
ES6 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title> </head> <body><script>// 变量定义var a1;let b5; // 现在使用let 定义变量// 对象解构let person{&quo…...

Vue-github 用户搜索案例
一、前言 在 Vue 开发中,与后端或第三方 API 接口进行交互是非常常见的需求。GitHub 提供了开放的 RESTful API,非常适合用来练习 Vue 的异步请求和数据绑定功能。 本文将带你一步步实现一个完整的 GitHub 用户搜索系统,包括: …...

Mac版Visual Studio Code Copilot 无法使用的解决方法
1 app文件夹删除Visual Studio Code 2 终端里面 输入以下指令,删除各种缓存 rm -fr ~/Library/Preferences/com.microsoft.VSCode.helper.plist rm -fr ~/Library/Preferences/com.microsoft.VSCode.plist rm -fr ~/Library/Caches/com.microsoft.VSCode rm -f…...

【笔记】PyCharm 使用问题反馈与官方进展速览
#工作记录 https://youtrack.jetbrains.com/issue/IJPL-190308 【笔记】记一次PyCharm的问题反馈_the polyglot context is using an implementation th-CSDN博客 【笔记】与PyCharm官方沟通解决开发环境问题-CSDN博客 与 JetBrains 官方沟通记录(PyCharm 相关问题…...
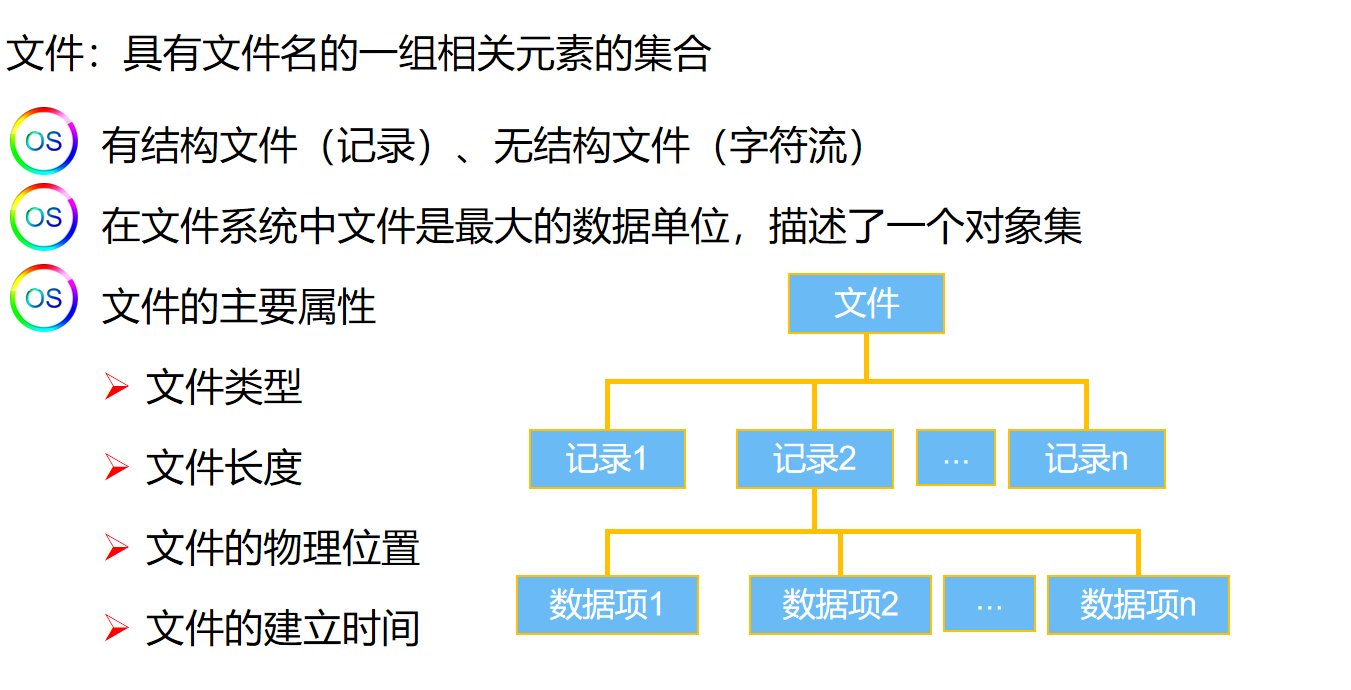
操作系统期末版
文章目录 概论处理机管理进程线程处理机调度生产者消费者问题 死锁简介死锁的四个必要条件解决死锁的方法 存储管理链接的三种方式静态链接装入时动态链接运行时链接 装入内存的三种方式绝对装入可重定位装入动态运行时装入 覆盖交换存储管理方式连续分配**分段存储管理方式***…...

本地主机部署开源企业云盘Seafile并实现外部访问
Seafile是一个开源、专业、可靠的云存储平台;解决文件集中存储、共享和跨平台访问等问题。这款软件功能强大,界面简洁、操作方便。 本文将详细的介绍如何利用本地主机部署 Seafile,并结合nat123,实现外网访问本地部署的 Seafile …...

微前端 - Native Federation使用完整示例
这是一个极简化的 Angular 使用angular-architects/native-federation 插件的微前端示例,只包含一个主应用和一个远程应用。 完整示例展示 项目结构 federation-simple/ ├── host-app/ # 主应用 └── remote-app/ # 远程应用 创建远程应用 (remote…...
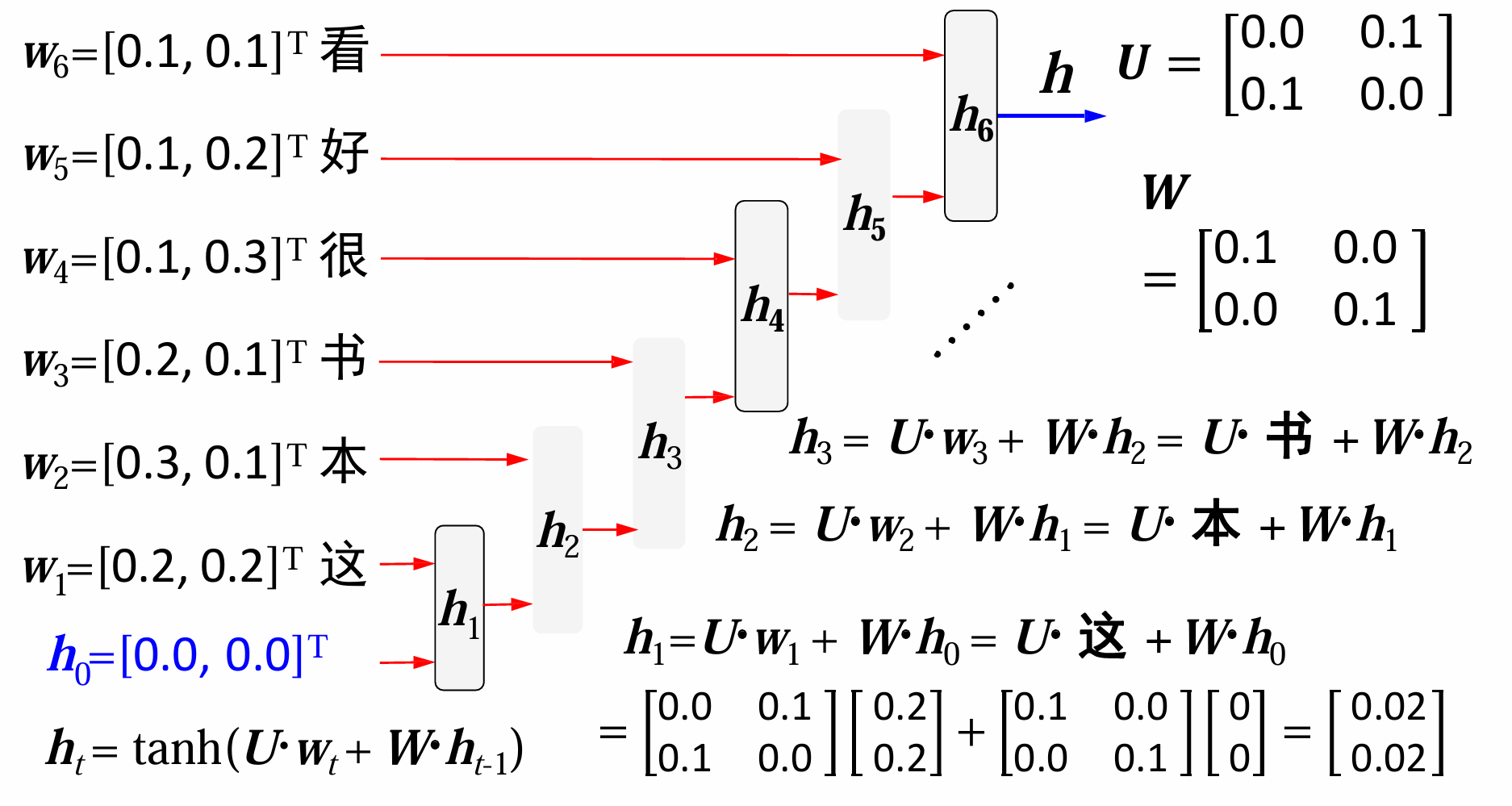
自然语言处理——语言模型
语言模型 n元文法参数估计数据平滑方法加1法 神经网络模型提出原因前馈神经网络(FNN)循环神经网络 n元文法 大规模语料库的出现为自然语言统计处理方法的实现提供了可能,统计方法的成功应用推动了语料库语言学的发展。 语句 𝑠 …...
数据库管理与高可用-MySQL高可用
目录 #1.1什么是MySQL高可用 1.1.1MySQL主主复制keepalivedhaproxy的高可用 1.1.2优势 #2.1MySQL主主复制keepalivedhaproxy的实验案例 1.1什么是MySQL高可用 MySQL 高可用是指通过技术手段确保 MySQL 数据库在面临硬件故障、软件错误、网络中断、人为误操作等异常情况时&…...

QuaggaJS用法详解
QuaggaJS简介 QuaggaJS是一个强大的JavaScript库,专门用于在浏览器环境中进行条形码和二维码识别。它支持多种条形码格式,包括Code 128、Code 39、EAN、QR码等,并且可以直接调用设备摄像头进行实时扫描。 QuaggaJS核心功能与用法 1. 基本配…...
 中创建多级目录或文件,可以使用鸿蒙的文件系统 API】)
【鸿蒙在 ETS (Extendable TypeScript) 中创建多级目录或文件,可以使用鸿蒙的文件系统 API】
鸿蒙在 ETS (Extendable TypeScript) 中创建多级目录或文件,可以使用鸿蒙的文件系统 API。 // 导入需要的模块 import fs from ohos.file.fs;const TAG"Index" Entry Component struct Index {State message: string Hello World;build() {Row() {Colum…...

免费工具-微软Bing Video Creator
目录 引言 一、揭秘Bing Video Creator 二、轻松上手:三步玩转Bing Video Creator 2.1 获取与访问: 2.2 创作流程: 2.3 提示词撰写技巧——释放AI的想象力: 三、核心特性详解:灵活满足多样化需求 3.1 双重使用模…...

2025 cs144 Lab Checkpoint 3: TCP Receiver
文章目录 1 关于TCP Sender1.1 关键机制重传超时(RTO)与定时器 2 实现TCP Sender2.1 void push( const TransmitFunction& transmit );const TransmitFunction& transmit 函数型参数?从哪里读取字节࿱…...

【学习笔记】深入理解Java虚拟机学习笔记——第5章 调优案例分析与实战
第5章 调优案例分析与实战 5.1 概述 略 5.2 案例分析 5.2.1 大内存硬件上的程序部署策略 为防止大内存一次Full GC时间过长,可以考虑使用响应速度优先的垃圾回收器,还可以通过将一个10GB堆内存的应用分解为5个2GB堆内存应用,并通过负载均…...

Vue 3 Teleport 实战:优雅实现模态框、通知和全局组件
Vue 3 Teleport:突破 DOM 层级限制的组件渲染利器 在 Vue 应用开发中,组件通常与其模板的 DOM 结构紧密耦合。但当处理模态框(Modal)、通知(Toast)或全局 Loading 指示器时,这种耦合会成为障碍…...

使用高斯朴素贝叶斯算法对鸢尾花数据集进行分类
高斯朴素贝叶斯算法通常用于特征变量是连续变量,符合高素分布的情况。 使用高斯朴素贝叶斯算法对鸢尾花数据集进行分类 """ 使用高斯贝叶斯堆鸢尾花进行分类 """ #导入需要的库 from sklearn.datasets import load_iris from skle…...

vue中ref的详解以及react的ref对比
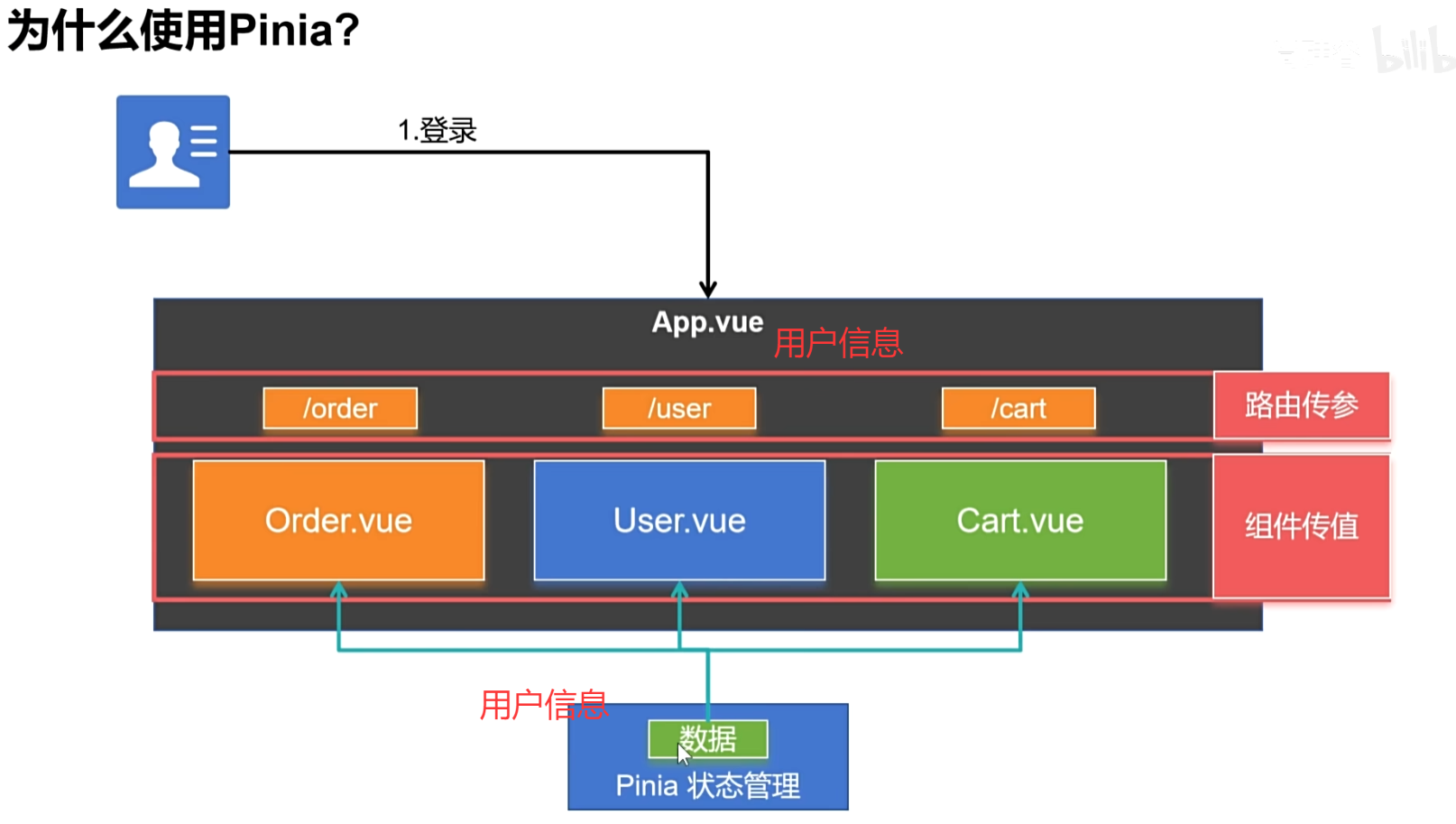
文章目录 1. ref是什么2. ref的使用3. ref的特性4. 使用场景5. 注意事项6. 与 React 的对比7. 动态 ref8. 函数式组件中的 ref9. 组合式 API 中的 ref10. 总结 1. ref是什么 ref 被用来给元素或子组件注册引用信息。引用信息将会注册在父组件的 $refs 对象上。可以通过实例对象…...