2025-05-01-决策树算法及应用
决策树算法及应用
参考资料
- GitHub - zhaoyichanghong/machine_learing_algo_python: implement the machine learning algorithms by p(机器学习相关的 github 仓库)
- 决策树实现与应用
- 决策树
概述
机器学习算法分类
决策树算法
决策树是一种以树状结构对数据进行划分的分类(Classification)或回归(Regression)模型。其核心思想是:
通过“自上而下”的方式,根据某一特征对样本进行二叉或多叉划分,直至满足停止条件(如纯度高、样本数小于阈值等),构造一棵可解释性高的树形模型。在叶节点输出类别(分类树)或数值(回归树)。
决策树具有以下特点:
- 易于理解与可视化:生成后以树状图呈现,人类可直观理解每个分类/回归决策过程。
- 无需大量数据预处理:对数值型与类别型特征均可处理,无需像线性模型那样对特征做严格的标准化、归一化。
- 自动进行特征选择:在划分过程中会自动选出最能区分正负样本或最能减少误差的特征。
从数据产生决策树的机器学习技术叫做决策树学习,通俗说就是决策树。
一个决策树包含三种类型的节点:
- 决策节点:通常用矩形框来表示
- 机会节点:通常用圆圈来表示
- 终结点:通常用三角形来表示
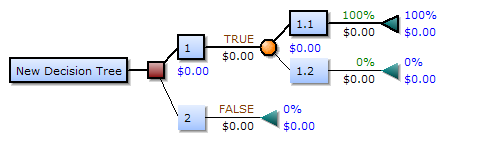
决策树是一种特殊的树形结构,一般由节点和有向边组成。其中,节点表示特征、属性或者一个类,而有向边包含判断条件。决策树从根节点开始延伸,经过不同的判断条件后,到达不同的子节点。而上层子节点又可以作为父节点被进一步划分为下层子节点。一般情况下,我们从根节点输入数据,经过多次判断后,这些数据就会被分为不同的类别。这就构成了一颗简单的分类决策树。
算法原理
其实决策树算法如同上面场景一样,其思想非常容易理解,具体的算法流程为:
- 数据准备 → 通过数据清洗和数据处理,将数据整理为没有缺省值的向量。
- 寻找最佳特征 → 遍历每个特征的每一种划分方式,找到最好的划分特征。
- 生成分支 → 划分成两个或多个节点。
- 生成决策树 → 对分裂后的节点分别继续执行 2-3 步,直到每个节点只有一种类别。
- 决策分类 → 根据训练决策树模型,将预测数据进行分类。
决策树的基本概念
结点类型
- 根节点 (Root Node)
- 树的起始节点,包含了整个训练集。
- 内部节点 (Internal Node)
- 又称决策节点(Decision Node),表示一个根据某个特征进行划分的测试。
- 叶节点 (Leaf / Terminal Node)
- 表示最终的类别(分类树)或数值(回归树)。
- 分支 (Branch / Edge)
- 从父节点到子节点的连线,通常对应该节点特征的某个取值或取值范围。
树结构与术语
- 路径 (Path):从根节点到某个叶节点所经过的结点序列,即一个完整的决策逻辑分支。
- 深度 (Depth):根节点的深度定义为 0,子节点依次递增。树的最大深度称为 高度 (Height)。
- 样本纯度 (Purity):指一个节点中样本类别的一致性。
- 比如在分类问题中,若节点仅包含同一类别样本,则称该节点纯度为 1(纯节点)。
- 叶子样本数 (Leaf Sample Count):用于限制过拟合,可设定:当某节点样本数不足阈值时,停止划分,将其设为叶节点。
- 划分停止条件:
- 所有样本属于同一类别(分类树),或样本方差足够小(回归树)。
- 树达到最大深度。
- 节点中样本数量小于某个阈值。
- 划分后信息增益或基尼系数提升不足阈值。
决策树构建的核心要素
划分指标
决策树的关键在于如何选择最优划分特征与划分点。常见的三种指标为信息增益、信息增益率和基尼不纯度。
信息增益 (Information Gain) ——ID3
设当前节点样本集为 D D D,共有 K K K 个类别 { C 1 , C 2 , … , C K } \{C_1, C_2, \dots, C_K\} {C1,C2,…,CK}。定义:
- 节点 D D D 信息熵:
H ( D ) = − ∑ k = 1 K p k log 2 p k , p k = ∣ D k ∣ ∣ D ∣ H(D) = -\sum_{k=1}^K p_k \log_2 p_k,\quad p_k = \frac{|D_k|}{|D|} H(D)=−k=1∑Kpklog2pk,pk=∣D∣∣Dk∣
其中 ∣ D k ∣ |D_k| ∣Dk∣ 是类别 C k C_k Ck 在 D D D 中的样本数。
- 若使用特征 A A A 进行划分,且 A A A 共有 v v v 个互斥取值 { a 1 , … , a v } \{a_1,\dots,a_v\} {a1,…,av},则在 A = a i A=a_i A=ai 处的子集记为 D i D_i Di。
划分后加权平均的信息熵:
H ( D ∣ A ) = ∑ i = 1 v ∣ D i ∣ ∣ D ∣ H ( D i ) H(D \mid A) = \sum_{i=1}^v \frac{|D_i|}{|D|} H(D_i) H(D∣A)=i=1∑v∣D∣∣Di∣H(Di)
- 信息增益:即划分前后熵的减少量:
Gain ( A ) = H ( D ) − H ( D ∣ A ) \text{Gain}(A) = H(D) - H(D \mid A) Gain(A)=H(D)−H(D∣A)
ID3 算法选择信息增益最大的特征进行划分——即令:
A ∗ = arg max A Gain ( A ) A^* = \arg\max_{A} \text{Gain}(A) A∗=argAmaxGain(A)
缺点:信息增益偏向取值多的特征(类别型变量有大量不同取值时容易过拟合)。
信息增益率 (Gain Ratio) ——C4.5
为克服 ID3 的偏向性,C4.5 引入分裂信息(Split Information)来对信息增益进行归一化:
- 分裂信息(或称固有信息):
SplitInfo ( A ) = − ∑ i = 1 v ∣ D i ∣ ∣ D ∣ log 2 ∣ D i ∣ ∣ D ∣ \text{SplitInfo}(A) = -\sum_{i=1}^v \frac{|D_i|}{|D|} \log_2 \frac{|D_i|}{|D|} SplitInfo(A)=−i=1∑v∣D∣∣Di∣log2∣D∣∣Di∣
- 信息增益率:
GainRatio ( A ) = Gain ( A ) SplitInfo ( A ) + ϵ \text{GainRatio}(A) = \frac{\text{Gain}(A)}{\text{SplitInfo}(A) + \epsilon} GainRatio(A)=SplitInfo(A)+ϵGain(A)
通常选择信息增益率最高的特征进行划分。
C4.5 同时支持对连续性(数值型)特征的二元划分:先对候选切分点进行排序,再遍历所有相邻两值中点,选取使增益率最大的切分点。
基尼不纯度 (Gini Impurity) ——CART
CART(Classification And Regression Tree)算法采用基尼不纯度作为划分依据。对于节点 D D D,基尼不纯度定义为:
G i n i ( D ) = 1 − ∑ k = 1 K p k 2 , p k = ∣ D k ∣ ∣ D ∣ \mathrm{Gini}(D) = 1 - \sum_{k=1}^K p_k^2, \quad p_k = \frac{|D_k|}{|D|} Gini(D)=1−k=1∑Kpk2,pk=∣D∣∣Dk∣
- 若使用特征 A A A 将 D D D 划分为两个子集(CART 传统上构建二叉树),设划分后两部分分别为 D left , D right D_\text{left}, D_\text{right} Dleft,Dright,则划分后的基尼系数为加权平均:
G i n i ( D , A , s ) = ∣ D left ∣ ∣ D ∣ G i n i ( D left ) + ∣ D right ∣ ∣ D ∣ G i n i ( D right ) \mathrm{Gini}(D, A, s) = \frac{|D_\text{left}|}{|D|}\mathrm{Gini}(D_\text{left}) + \frac{|D_\text{right}|}{|D|}\mathrm{Gini}(D_\text{right}) Gini(D,A,s)=∣D∣∣Dleft∣Gini(Dleft)+∣D∣∣Dright∣Gini(Dright)
- 基尼增益 (Gini Gain)(或称基尼减少量):
Δ G i n i ( A , s ) = G i n i ( D ) − G i n i ( D , A , s ) \Delta \mathrm{Gini}(A, s) = \mathrm{Gini}(D) - \mathrm{Gini}(D, A, s) ΔGini(A,s)=Gini(D)−Gini(D,A,s)
CART 选择使基尼不纯度下降最多(即 Δ G i n i \Delta \mathrm{Gini} ΔGini 最大)的特征和切分点。
CART 区别:
- 使用基尼而非熵;
- 通常只考虑二元(yes/no)划分,即每个节点形成左右两个子节点。
- 对数值型特征遍历所有可能切分点;对类别型特征可先将类别编码为虚拟变量 (One-Hot) 或按某种顺序处理。
特征选择与最佳划分
- 离散(类别)特征
- ID3/C4.5 直接按每个取值划分;CART 需要将 m m m 个类别先切分为两组(所有可能子集划分),计算基尼并选择最优。
- 连续(数值)特征
- 首先对该特征在当前节点的所有样本的取值排序: x ( 1 ) ≤ x ( 2 ) ≤ ⋯ ≤ x ( n ) x_{(1)} \le x_{(2)} \le \dots \le x_{(n)} x(1)≤x(2)≤⋯≤x(n)。
- 对每个相邻取值对 { x ( i ) , x ( i + 1 ) } \{x_{(i)}, x_{(i+1)}\} {x(i),x(i+1)},将其中点 s = x ( i ) + x ( i + 1 ) 2 s = \tfrac{x_{(i)}+x_{(i+1)}}{2} s=2x(i)+x(i+1) 作为候选切分点。
- 分别计算按 A ≤ s A \le s A≤s 与 A > s A > s A>s 两部分划分后的信息增益(或基尼减少量),选择最优 s ∗ s^* s∗。
- 递归构建
- 从根节点开始,对当前节点所有候选特征(及可能的切分点)分别计算划分指标;
- 选出指标最优的特征/切分点,将样本划分到子节点;
- 对每个子节点递归执行,同样进行“特征选择 → 划分 → 递归”,直到满足停止条件。
常见决策树算法变体
ID3 (Quinlan,1986)
- 核心思想:
- 使用信息增益作为划分标准;
- 仅适用于离散(类别)特征;
- 构建多叉树(一个节点可以有多条分支,对应特征的所有取值)。
- 简易流程:
-
计算当前节点样本集信息熵 H ( D ) H(D) H(D)。
-
对每个候选特征 A A A,计算信息增益 Gain ( A ) \text{Gain}(A) Gain(A)。
-
选取信息增益最大的特征 A ∗ A^* A∗,对该节点进行划分。
-
递归地对每个子节点执行上述步骤。
-
递归终止条件:
- 节点样本全属于同一类别(纯度 1)。
- 特征集为空(多数投票决定叶节点类别)。
- 节点样本数小于阈值。
C4.5(Quinlan,1993)
- 改进点:
- 支持数值型特征的自动二元划分。
- 使用信息增益率(Gain Ratio)来选择特征,克服取值多特征的偏向问题。
- 支持“有缺失值”处理:当样本缺失特征 A A A 时,按已知特征在其他样本中的分布进行加权。
- 剪枝:可基于统计检验进行后剪枝,减少过拟合。
- 流程:
- 对所有特征计算信息增益率 GainRatio ( A ) \text{GainRatio}(A) GainRatio(A),选取最优特征 A ∗ A^* A∗;
- 对于数值型特征,遍历所有候选切分点(相邻排序值中点),计算最佳增益率;
- 按 A ∗ A^* A∗ 将节点划分;
- 递归;
- 在树构建完成后进行后剪枝(可选)。
CART (Breiman 等,1984)
- 核心思想:
- 使用基尼不纯度 (Gini) 作为划分标准;
- 构建二叉树:每个节点仅有 “是/否” 两个分支;
- 同时支持分类树 (Classification Tree) 和回归树 (Regression Tree)。
- 分类树流程:
- 计算当前节点的 G i n i ( D ) \mathrm{Gini}(D) Gini(D)。
- 对每个候选特征及其所有可能二元切分点,计算基尼减少量 Δ G i n i ( A , s ) \Delta \mathrm{Gini}(A, s) ΔGini(A,s)。
- 选择使 Δ G i n i \Delta \mathrm{Gini} ΔGini 最大的特征与切分点 ( A ∗ , s ∗ ) (A^*, s^*) (A∗,s∗)。
- 将节点划分为左右子节点;
- 递归;
- 剪枝:可使用交叉验证来调节树的复杂度,通过最小化验证误差决定是否剪枝。
- 回归树流程:
- 用 MSE(均方误差)或绝对误差作为节点不纯度度量:
M S E ( D ) = 1 ∣ D ∣ ∑ i ∈ D ( y i − y ˉ ) 2 , y ˉ = 1 ∣ D ∣ ∑ i ∈ D y i \mathrm{MSE}(D) = \frac{1}{|D|}\sum_{i\in D} (y_i - \bar y)^2,\quad \bar y = \frac{1}{|D|}\sum_{i\in D} y_i MSE(D)=∣D∣1i∈D∑(yi−yˉ)2,yˉ=∣D∣1i∈D∑yi
M S E ( D ) = 1 ∣ D ∣ ∑ i ∈ D ( y i − y ˉ ) 2 , y ˉ = 1 ∣ D ∣ ∑ i ∈ D y i \mathrm{MSE}(D) = \frac{1}{|D|}\sum_{i\in D} (y_i - \bar y)^2,\quad \bar y = \frac{1}{|D|}\sum_{i\in D} y_i MSE(D)=∣D∣1i∈D∑(yi−yˉ)2,yˉ=∣D∣1i∈D∑yi
- 对数值型特征 A A A 遍历二元切分点,分别计算左右子集的 MSE 加权平均。
- 选取使 MSE 降低最多的切分。
- 剪枝一般使用最小化验证集误差或对叶子节点惩罚复杂度(Cost-Complexity Pruning)。
剪枝 (Pruning)
在决策树中,过深的树容易过拟合训练数据,影响泛化。剪枝是为了提高模型在测试集上的准确性。主要有两种方式:
预剪枝 (Pre-pruning)
在构建树的过程中,提前停止划分,常见策略有:
- 最小样本数:若节点样本数小于某阈值,停止划分;
- 最大深度:树深度达到设定上限,停止;
- 信息增益/基尼减少阈值:若最优划分的增益(或减少量)小于阈值,则不再划分;
- 统计检验:基于卡方检验等统计检验判定划分是否显著。
优点:减少计算和树的复杂度。
缺点:一旦提前停止,可能错过后续有效划分,导致欠拟合。
后剪枝 (Post-pruning)
先让树尽可能长地生长,然后自底向上裁剪。常见流程:
- 构建完完全树(直到所有叶节点纯度为 1 或没有更多可划分特征);
- 对每个非叶子节点评估以下两种情况哪种在验证集上性能更好:
- 保留该子树结构;
- 将其剪为叶节点,并以子树所有样本在该节点的多数类(分类)或平均值(回归)作为输出;
- 如果剪掉子树后验证误差减少或无显著变化,则保留剪枝操作;否则保留子树;
- 重复上述过程,直到没有可剪枝节点或验证集误差不再降低。
CART 的 Cost-Complexity Pruning:定义节点惩罚函数
决策树的优缺点
优点
- 可解释性强
- 生成后的决策树可视化,人类易于理解和解释每个决策路径。
- 无须特征归一化
- 对数值型与类别型特征均可处理,不要求输入特征尺度统一。
- 自动特征选择
- 在划分过程中自动评估并选取对分类/回归最有价值的特征。
- 鲁棒性强
- 对缺失值可采用“分裂时加权”或“按多数类分配”等策略进行处理;对异常值不敏感。
- 易于处理多种类型数据
- 可以同时处理数值、类别以及缺失值。
缺点
- 容易过拟合
- 深度过大时对训练数据拟合过度,泛化能力下降。
- 对噪声敏感
- 训练数据中的噪声决定划分时可能误导特征选择。
- 局部最优
- 由于采用贪心策略(每次只选最优特征),可能无法得到全局最优树。
- 可用性限制
- 对高维稀疏数据(如文本)可能效果不佳;容易生成非常深且稀疏的树。
- 不稳定性
- 微小的数据变化可能导致决策树结构的大幅改变(当某些样本临界时)。
改进思路:
- 集成方法:随机森林 (Random Forest)、梯度提升树 (Gradient Boosting Trees,如 XGBoost、LightGBM) 通过集成多棵弱树克服单棵树的易过拟合与不稳定问题。
- 特征筛选与降维:在高维稀疏场景下,可结合特征工程、特征选择等方法减小特征维度。
决策树在实际中的应用场景
相关代码示例
由于还包含了 c45,cart,id3 为划分指标的决策树代码内容比较多,我整理在了一个 github 仓库中,下面只展示了 decision_stump.py 的代码
https://github.com/tkzzzzzz6/MLandDL
decision_stump.py(主要模块)
import numpy as npclass DecisionStump():def __update_parameter(self, h, feature_index, threshold, direction, err_value):self.**__min_err_value** = err_valueself.**__feature_index** = feature_indexself.**__threshold** = thresholdself.**__direction** = directiondef __select_direction(self, feature_index, threshold, X, y, w):for direction in ['greater', 'less']:h = np.ones_like(y)if direction == 'greater':h[np.flatnonzero(X[:, feature_index] < threshold)] = -1else:h[np.flatnonzero(X[:, feature_index] >= threshold)] = -1err_value = np.sum(w[np.flatnonzero(h != y)])if err_value < self.**__min_err_value**:self.__update_parameter(h, feature_index, threshold, 'greater', err_value)def __select_threshold(self, feature_index, X, y, w):n_samples = X.shape[0]for i in range(n_samples):self.__select_direction(feature_index, X[i, feature_index], X, y, w)def __select_feature(self, X, y, w):n_features = X.shape[1]for i in range(n_features):self.__select_threshold(i, X, y, w)def fit(self, X, y, w):self.**__feature_index** = Noneself.**__threshold** = Noneself.**__direction** = Noneself.**__min_err_value** = np.**inf**self.__select_feature(X, y, w)def predict(self, X):n_samples = X.shape[0]y_pred = np.ones(n_samples)if self.**__direction** == 'greater':y_pred[np.flatnonzero(X[:, self.**__feature_index**] < self.**__threshold**)] = -1else:y_pred[np.flatnonzero(X[:, self.**__feature_index**] >= self.**__threshold**)] = -1return y_pred
运行结果
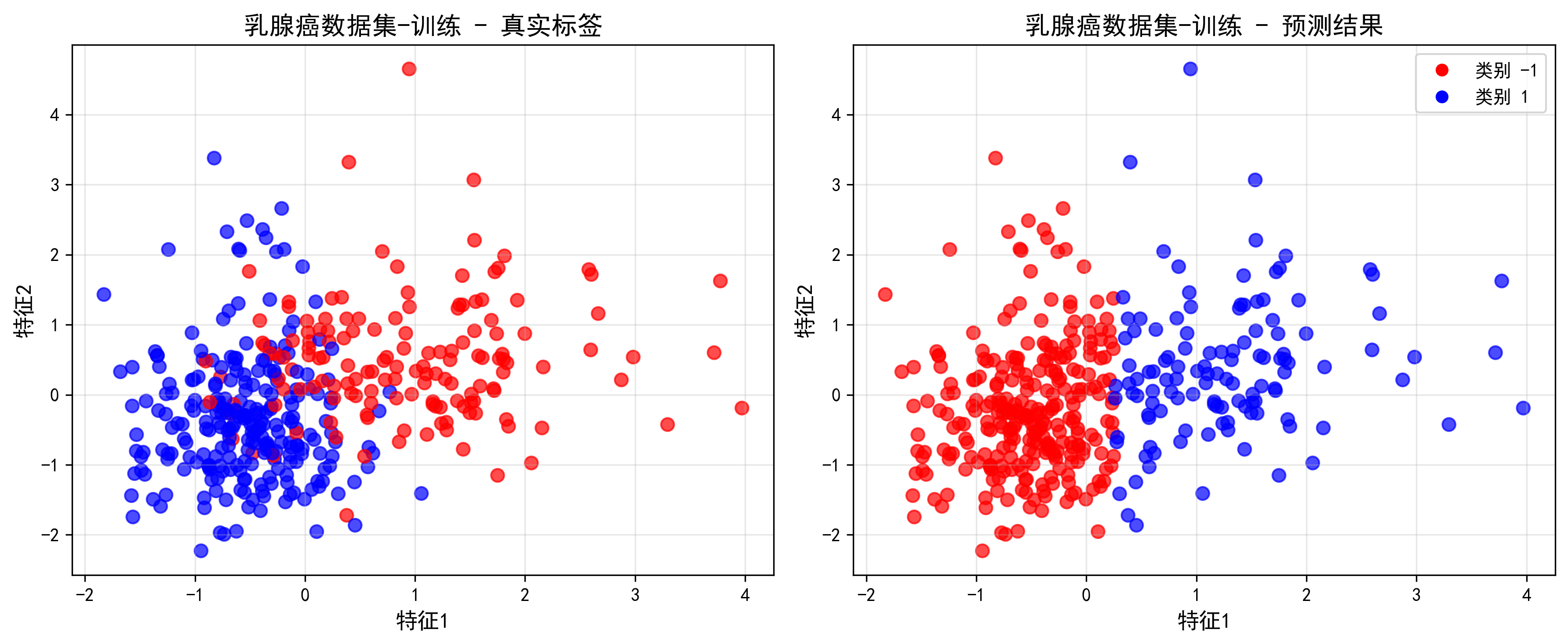
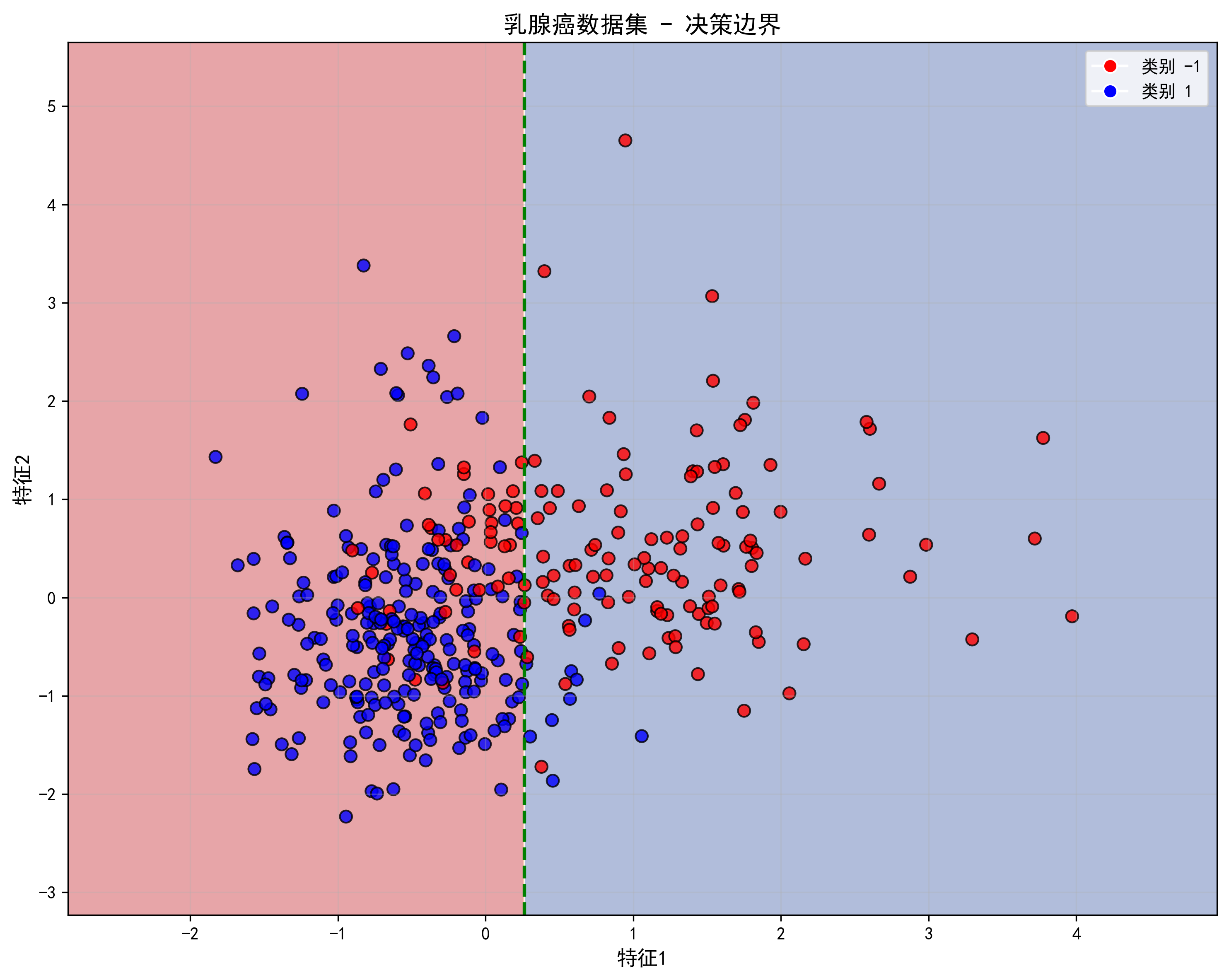
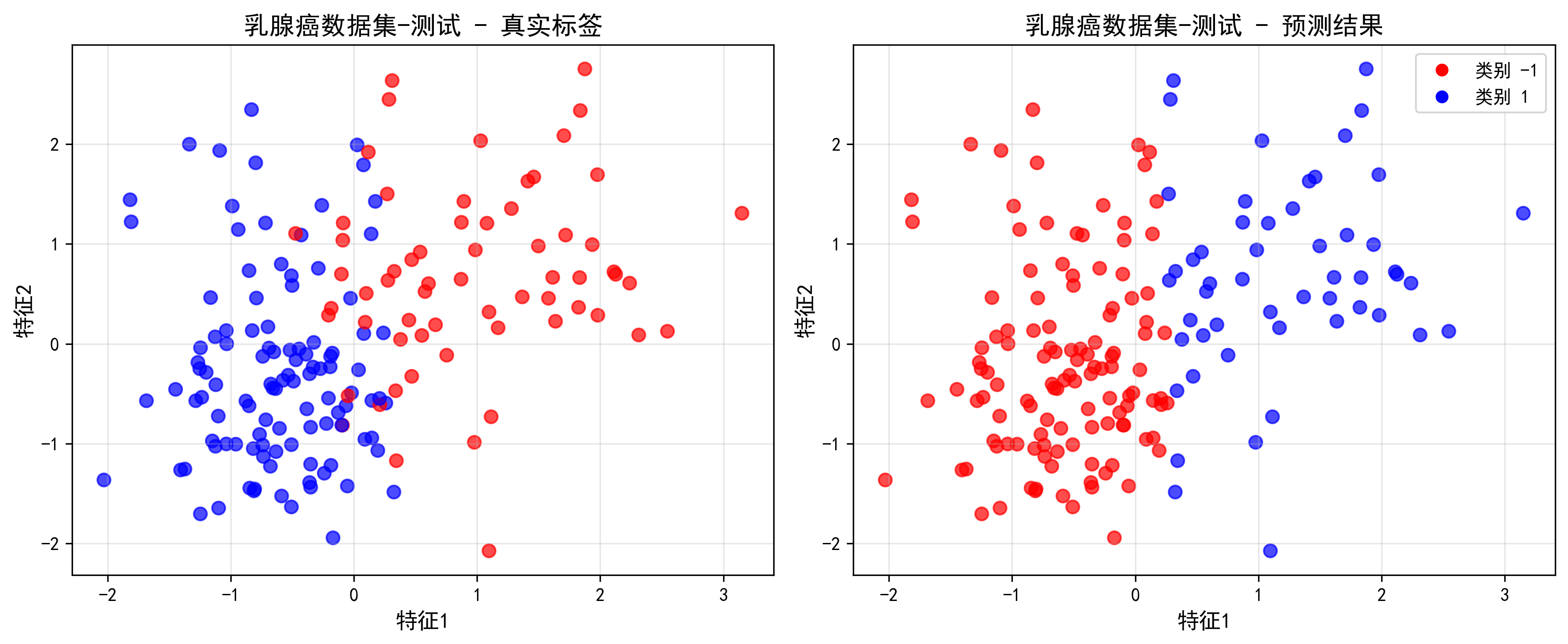
分类任务
- 客户流失预测 (Customer Churn Prediction)
- 业务场景:电信、金融、电商等行业中,通过客户基本属性、历史行为、消费习惯等特征预测是否会流失。
- 决策树优势:易于解释(可解释哪些因素导致客户流失),可处理混合型特征(年龄、性别、套餐类别、使用时长等)。
- 信用评估 (Credit Scoring)
- 业务场景:银行或金融机构根据用户的个人信息(年龄、工作、收入)、信用记录(逾期次数、还款能力)进行信用风险分类(高风险、中风险、低风险)。
- 应用:决策树可直观地给出“如果收入 < X 且逾期次数 > Y,则分类为高风险”,帮助信贷风控。
- 医疗诊断
- 业务场景:根据患者的症状(发热、咳嗽、X 光结果)、检查指标(血常规、心电图)等预测是否患某种疾病。
- 应用:决策树模型可以给出“若咳嗽持续 > 2 周 且 白细胞数 > 某阈值,则可能为肺炎”,同时提供可解释的诊断决策流程。
- 垃圾邮件识别
- 业务场景:根据邮件内容特征(关键字出现次数、发送人是否在白名单)、邮件长度、附件类型等判断是否为垃圾邮件。
- 应用:决策树可快速处理离散/连续特征,常用于构建初期的规则或与其他模型结合(如 Random Forest)。
回归任务
- 房价预测 (House Price Prediction)
- 业务场景:根据房屋面积、楼层、房龄、地理位置、交通等因素预测房价。
- 决策树回归:将房屋特征空间划分为若干区域,每个叶节点输出区域内样本的平均房价。做不到很平滑,但易于理解。
- 销售额预测
- 业务场景:预测节假日、促销活动或天气变化对某商品销售额的影响。
- 决策树回归能够捕获非线性关系,且不需要对特征进行大量预处理。
特征工程与规则提取
- 特征构造
- 通过决策树可以将某些连续特征自动离散化。例如,若决策树对“年龄”做了三次切分,分别在 25 岁、40 岁产生不同的分支,则可得到“年龄段”特征。
- 规则提取
- 从训练好的决策树中可直接提取“如果……则……”的规则,用于可解释性要求高的场景(如审计、医疗)。
集成学习基础
- 随机森林 (Random Forest)
- 由多棵决策树随机组合而成。每棵树训练时只使用特征子集和样本子集,最后多数投票决定分类结果或平均值决定回归值。
- 优势:降低单棵决策树的过拟合风险,提高泛化能力。
- 梯度提升树 (Gradient Boosting Trees)
- 通过逐步拟合残差的方式构建多个弱决策树,每棵新树在前一棵树的基础上拟合残差,最终组合得到强模型,如 XGBoost、LightGBM、CatBoost。
总结
- 决策树 是一种简单、易理解且可处理混合型特征的模型,既可做分类,也可做回归。
- 核心步骤:选择合适的划分指标(信息增益 / 信息增益率 / 基尼不纯度)、确定最佳划分点,递归生成树,并通过剪枝降低过拟合。
- 常见算法:
- ID3(仅支持离散特征,使用信息增益)
- C4.5(支持数值特征 & 离散特征,使用信息增益率,含剪枝)
- CART(构建二叉树,使用基尼不纯度,可用于分类与回归)
- 优缺点:
- 优点:可解释性强、无需特征缩放、自动进行特征选择。
- 缺点:容易过拟合、对噪声敏感、在高维稀疏场景下不够稳定。
- 典型应用:
- 客户流失预测、信用评估、医疗诊断、垃圾邮件识别等分类场景;
- 房价预测、销售额预测等回归场景;
- 特征工程、规则提取、以及集成学习(随机森林、梯度提升树)的基石。
相关文章:
2025-05-01-决策树算法及应用
决策树算法及应用 参考资料 GitHub - zhaoyichanghong/machine_learing_algo_python: implement the machine learning algorithms by p(机器学习相关的 github 仓库)决策树实现与应用决策树 概述 机器学习算法分类 决策树算法 决策树是一种以树状结构对数据进行划分的分类…...

Redis知识体系
1. 概述 本文总结了Redis基本的核心知识体系,在学习Redis的过程中,可以将其作为学习框架,以此更好的从整体的角度去理解和学习Redis的内容和设计思想。同时知识框架带来的好处是可以帮助我们更好的进行记忆,在大脑中形成相应的知识…...
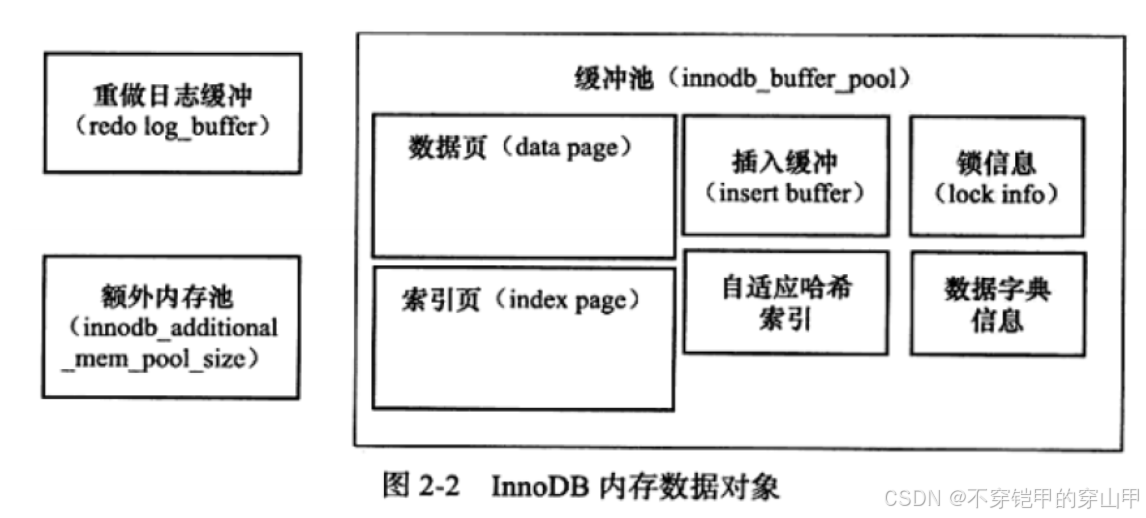
mysql-MySQL体系结构和存储引擎
1. MySQL体系结构和存储引擎 MySQL被设计成一个单进程多线程架构的数据库,MySQL数据库实例在系统上的表现就是一个进 程当启动实例时,读取配置文件,根据配置文件的参数来启动数据库实例;若没有,按编译时的默认 参数设…...

Pycharm 函数注释
1 Docstring format File -> Settings -> Tools -> Python Integrated Tools -> Docstrings -> Docstring format,选择google File -> Settings -> Editor -> General -> Smart Keys -> Insert type placeholders in the documenta…...

如何使用 Redis 快速实现布隆过滤器?
以下是使用 Redis 实现布隆过滤器的两种方案,结合原理说明和操作步骤: 方案一:手动实现(基于 Redis Bitmap) 原理 利用 Redis 的 SETBIT 和 GETBIT 操作位数组,结合多个哈希函数计算位置。 步骤 确定参数…...
黑马Javaweb Request和Response
一.介绍 在 Web 开发中,HttpServletRequest 和 HttpServletResponse 是两个非常重要的类,它们分别用于处理客户端的请求和服务器的响应。以下是它们的详细说明和使用方法: 1. HttpServletRequest HttpServletRequest 是一个接口࿰…...

山东大学深度学习2025年期末考试
一、名词解释(24) 1.反向传播 2.激活函数 3.梯度裁剪 4.数据增强 5.迁移学习 6.过拟合 7.word2Vec 8.注意力机制 二、简答题(48) 1.池化的概念(作用)以及常见的两种池化操作 2.LSTM为什么能解决…...

添加按钮跳转页面并且根据网站的用户状态判断是否显示按钮
现在我们需要的是为页面添加一个按钮,这个按钮是动态的,需要根据网站用户登录过后是否是vip来判断是否显示,然后按钮的效果是跳转到某个页面。 首先我们需要在页面中找到我们需要添加按钮的位置,找到对应的文件,然后比…...

Gerrit+repo管理git仓库,如果本地有新分支不能执行repo sync来同步远程所有修改,会报错
问题:创建一个本地分支TEST 来关联远程已有分支origin/TEST,直接执行repo sync可能会出现问题:比如,本地分支TES会错乱关联到origin/master,或者拉不下最新代码等问题。 // git checkout -b 新分支名 远程分支名字 git…...
豆瓣图书评论数据分析与可视化
【题目描述】豆瓣图书评论数据爬取。以《平凡的世界》、《都挺好》等为分析对象,编写程序爬取豆瓣读书上针对该图书的短评信息,要求: (1)对前3页短评信息进行跨页连续爬取; (2)爬取…...

Vue ④-组件通信 || 进阶语法
组件三大部分 template:只有能一个根元素 style:全局样式(默认):影响所有组件。局部样式:scoped 下样式,只作用于当前组件 script:el 根实例独有,data 是一个函数,其他配置项一致…...

0x-2-Oracle Linux 9上安装JDK配置环境变量
一、JDK选择和使用 安装完Oracle Linux9.6,同时使用rpm包安装Oracle 23 ai free后, 将面临sqlcl程序无法使用和java无法使用,需要相应进行变量配置问题。 1、java 环境运行不存在,Oracle 23ai free安装后默认安装JDK 11 /opt/…...

深入理解卷积神经网络:从原理到应用
在人工智能领域,卷积神经网络(Convolutional Neural Network, CNN)无疑是计算机视觉领域的璀璨明珠。从 1998 年 Yann LeCun 提出 LeNet-5 实现手写数字识别,到 2012 年 AlexNet 在 ImageNet 大赛上创造历史性突破,CNN…...

从入门到实战:AI学习路线全解析——避坑指南
分享一下阿里的人工智能学习路线,为感兴趣系统学习的小伙伴们探路。 一、谁适合学这门AI课程?五类人群的精准定位 无论你是零基础小白还是职场转型者,这套系统化课程都能为你量身定制成长路径: 零基础爱好者(无编程/数学背景) 课程提供Python和数学前置学习建议,先补基…...

Spring Boot + Thymeleaf 防重复提交
在 Spring Boot 与 Thymeleaf 结合的 Web 应用中,防止重复提交可以采用token 机制 客户端禁用按钮的方式实现,在高并发场景下,考虑使用 Redis 存储 token 而非 Session。 第一步:后端实现 Controller public class FormControl…...

uniapp实现的简约美观的星级评分组件
采用 uniapp 实现的一款简约美观的星级评分模板,提供丝滑动画效果,用户可根据自身需求进行自定义修改、扩展,纯CSS、HTML实现,支持web、H5、微信小程序(其他小程序请自行测试) 可到插件市场下载尝试&#x…...

AWS Elastic Beanstalk + CodePipeline(Python Flask Web的国区CI/CD)
目标 需要使用AWS Elastic Beanstalk 部署一个Python的Flask Web应用,并且使用CodePipeline作为CI/CD工作流。 eb部署图 前提 假设你已经有一个能够正常运行的Python的Flask Web应用项目代码,而且需要对已有Flask工程做一些调整。由于AWS Elastic Bea…...

多线程语音识别工具
软件介绍 本文介绍一款支持大厂接口的语音转文字工具,具备免配置、免费使用的特点。 软件特性 该工具是一款完全免费的桌面端应用程序,部署于开源社区平台,其核心优势在于整合了多家技术供应商的接口资源。 操作方式 用户只需将音频…...

前端对WebSocket进行封装,并建立心跳监测
WebSocket的介绍: WebSocket 是一种在客户端和服务器之间进行全双工、双向通信的协议。它是基于 HTTP 协议,但通过升级(HTTP 升级请求)将连接转换为 WebSocket 协议,从而提供更高效的实时数据交换。 WebSocket 的特点…...
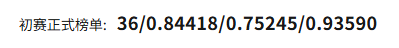
DiMTAIC 2024 数字医学技术及应用创新大赛-甲状腺B超静态及动态影像算法赛-参赛项目
参赛成绩 项目介绍 去年参加完这个比赛之后,整理了项目文件和代码,虽然比赛没有获奖,但是参赛过程中自己也很有收获,自己一个人搭建了完整的pipeline并基于此提交了多次提高成绩,现在把这个项目梳理成博客,…...
window安装docker\docker-compose
安装前配置 打开控制面板,参照下图打开“启动或关闭windows功能”,Hyper-V 和容器需要启用 程序和功能 启动或关闭windows功能 勾选Hyper-V 安装路径配置 Docker在Windows上的默认安装路径为C:\Program Files\Docker。 以管理员身份运行CMD在D盘,dev文件夹下创建Docker文…...
Jenkins的学习与使用(CI/CD)
文章目录 前言背景CI/CDJenkins简介Jenkins特性 安装Jenkins工作流程(仅供参考)安装maven和其他插件新建任务任务源码管理配置maven配置git(非必需) 尝试手动构建jar包可能遇到的错误 发布到远程服务器前置清理工作构建触发器git钩…...
)
vue-14(使用 ‘router.push‘ 和 ‘router.replace‘ 进行编程导航)
使用 ‘router.push’ 和 ‘router.replace’ 进行编程导航 编程导航是使用 Vue Router 构建动态和交互式 Web 应用程序的一个重要方面。它允许您根据应用程序逻辑、用户作或特定条件控制用户的导航流。您可以使用 router.push 和 router.replace 方法以编程方式导航到不同的路…...

使用WPF的Microsoft.Xaml.Behaviors.Wpf中通用 UI 元素事件
Nuget下载之后记得要先引用下面的 xmlns:i"http://schemas.microsoft.com/xaml/behaviors" <!-- 鼠标事件 --> <i:EventTrigger EventName"MouseEnter"/> <!-- 鼠标进入 --> <i:EventTrigger EventName"MouseLeave"/&g…...
功能介绍)
Elasticsearch中的监控(Monitoring)功能介绍
Elasticsearch 的 监控(Monitoring) 功能用于实时跟踪集群的运行状态、性能指标和资源使用情况,帮助管理员及时发现潜在问题、优化配置并确保集群稳定高效运行。它通过内置工具和集成方案,提供从节点到集群、从硬件到服务层的全方…...
Centos7.6图文安装mysql8.4详细步骤记录
1 前提条件 1.1 关闭数据库服务器的防火墙 # 关闭数据库服务器的防火墙 systemctl stop firewalld systemctl disable firewalld 1.2 关闭SELinux # 编辑 /etc/selinux/configvi /etc/selinux/config#内容更改为disabledSELINUXdisabled 1.3 卸载系统自身带的mysql&#…...
AI短视频创富营
课程内容: 相关资料 【第一章】前期准备 001.【涨粉技巧】新账号如何快速涨粉?_ev(1).mp4 002.【带贷权限】如何开通账号带贷权限?(1).mp4 003.【费用缴纳】如何缴纳账号保证金?_ev(1).mp4 004.【账号检测】如何检测账号是否限流?(1).mp4 005.【风险规避…...
纹理(Texture))
C++.OpenGL (4/64)纹理(Texture)
纹理(Texture) 纹理映射核心流程 #mermaid-svg-XxVbt4fizulzb5H3 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-XxVbt4fizulzb5H3 .error-icon{fill:#552222;}#mermaid-svg-XxVbt4fizulzb5H3 .error-text{fill:…...

spring中的@RabbitListener注解详解
基本用法主要属性1. queues / queueNames2. containerFactory3. id4. concurrency5. ackMode6. priority7. bindings 高级特性1. 消息转换器2. 手动确认3. 条件监听4. 错误处理 配置监听容器工厂注意事项完整示例循环依赖解决1. 使用 Setter 注入2. 使用 Lazy 注解3. 重构代码结…...
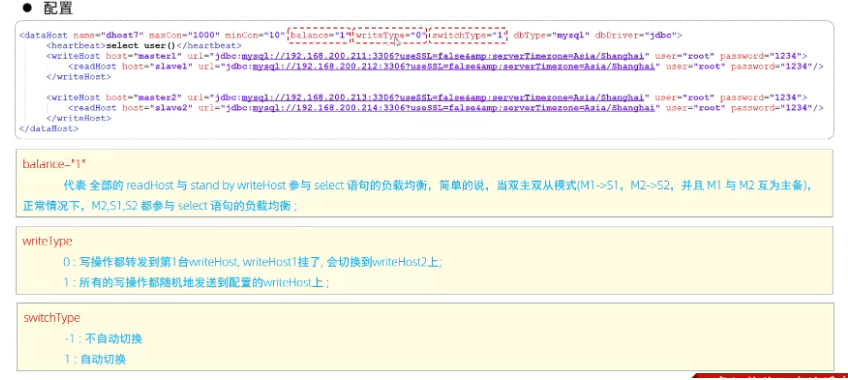
MySQL-运维篇
运维篇 日志 错误日志 错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。 该日志是默认开启的&am…...