【论文解读】MemGPT: 迈向为操作系统的LLM
1st author: Charles Packer
paper
- MemGPT
- [2310.08560] MemGPT: Towards LLMs as Operating Systems
code: letta-ai/letta: Letta (formerly MemGPT) is the stateful agents framework with memory, reasoning, and context management.
这个项目现在已经转化为 Letta ,一个 16.7K star 的开源项目。Charles Packer 现在是 Letta 的联合创始人兼 CEO, 官网: Letta.
1. 思想
LLM 的核心瓶颈之一是其有限的上下文窗口 (Context Window),这限制了其在长程对话、复杂文档分析等任务中的应用。现有方法如直接扩展上下文长度面临计算成本的平方级增长和“大海捞针” (Lost in the Middle) 的问题;而朴素的 RAG (Retrieval Augmented Generation) 虽能引入外部知识,但缺乏对上下文的动态、智能管理。
MemGPT 借鉴传统操作系统 (OS) 中虚拟内存管理的核心思想,提出一种分层记忆系统 (Hierarchical Memory System)。它不试图无限扩展 LLM 的“物理内存” (即实际的上下文窗口),而是赋予 LLM 一种“虚拟内存”的错觉,使其能够智能地在快速但有限的“主上下文” (Main Context,类比 RAM) 和慢速但海量的“外部上下文” (External Context,类比磁盘) 之间进行信息的换入换出 (Paging)。
核心思想:将 LLM 自身视为一个能够通过函数调用 (Function Calling) 主动管理其认知资源的智能体,而非仅仅是被动的信息处理器。这是一种从“LLM as a model”到“LLM as an agent/OS kernel”的范式转变。
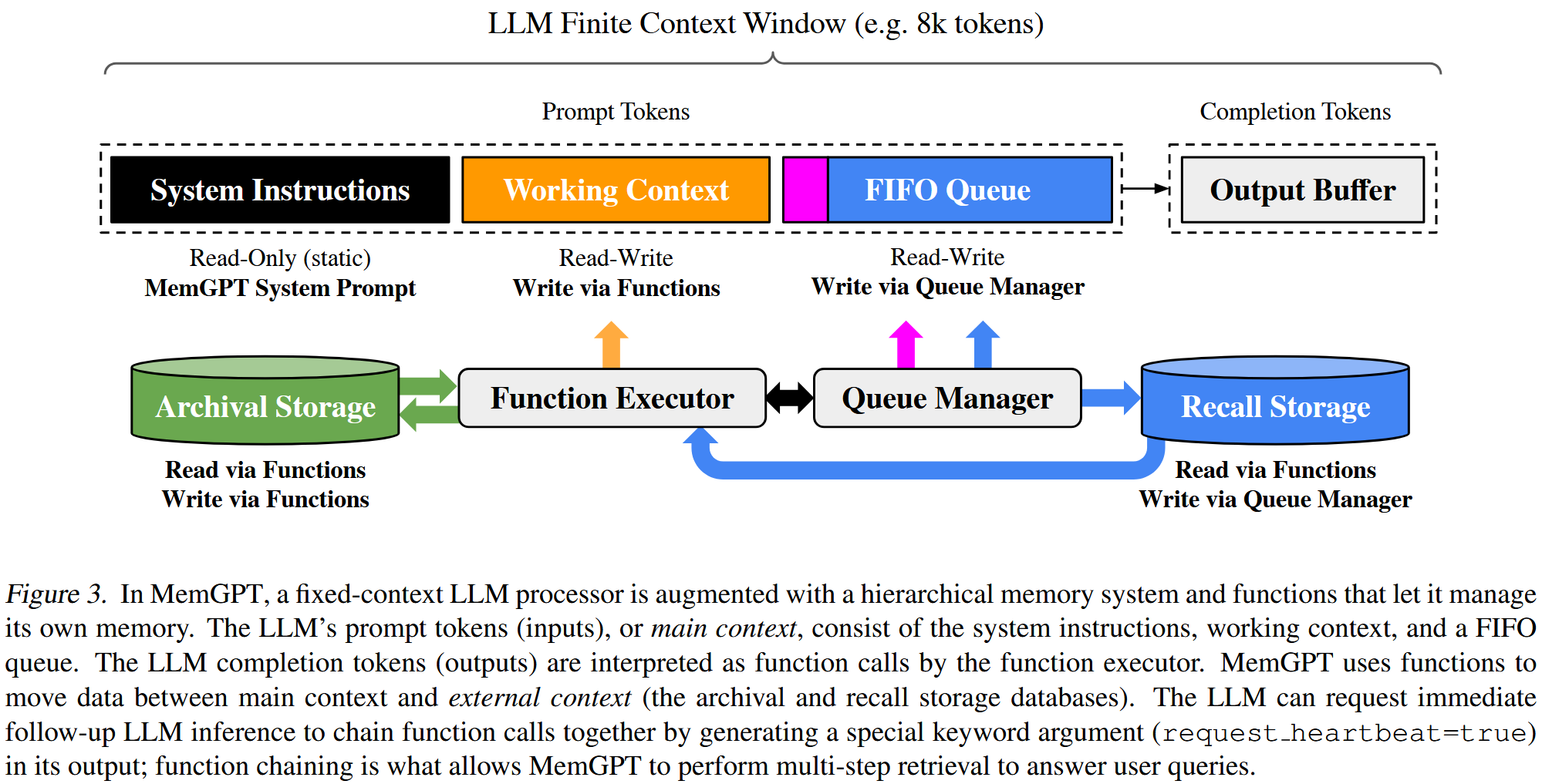
2. 方法
MemGPT的将LLM的上下文窗口视为一种宝贵且有限的资源,并赋予LLM通过“函数调用”(Function Calling)来自主管理这块“内存”的能力。
其架构包含两个主要层级:
-
主上下文 (Main Context / RAM): LLM的实际输入提示(prompt tokens)。它被划分为:
- 系统指令 (System Instructions): 静态的、只读的,定义了MemGPT的控制流、记忆层级用途及函数调用规范(如同OS内核指令)。
- 工作上下文 (Working Context): 固定大小的读写区域,用于存储LLM认为当前任务最关键的事实、状态、中间结论(如同CPU寄存器或高速缓存)。
- FIFO队列 (FIFO Queue): 滚动存储最近的对话历史、系统消息(如内存压力警告)、函数调用及返回结果(如同最近使用的页面缓存)。队首通常是一个对已移除消息的递归摘要。
-
外部上下文 (External Context / Disk): 存储在LLM上下文窗口之外的任何信息。
- 回忆存储 (Recall Storage): 存储完整的对话历史和事件。
- 档案存储 (Archival Storage): 存储更持久、可能更结构化的信息,如大型文档。


运作机制:
- 事件触发: 用户输入、系统警告(如主上下文接近上限,产生“内存压力”)或预设的定时事件会触发LLM进行推理。
- LLM决策与函数调用: LLM根据系统指令和当前上下文,决定是否需要以及如何管理其记忆。例如:
- 当FIFO队列过长,触发“内存压力”警告,LLM可以调用函数将队列中的重要信息存入“工作上下文”或“档案存储”。
- 当需要回忆过去的对话细节或查询文档时,LLM调用函数从“回忆存储”或“档案存储”中检索信息,并将其加载到“主上下文”中。
- 当“工作上下文”中的信息过时或不再相关,LLM可以更新或移除它们。
- 上下文更新与迭代: 函数执行的结果(包括成功信息或错误信息)会反馈给LLM,更新其主上下文,并可能触发后续的函数调用链(例如,分页查询)。这种反馈循环使LLM能从其行为中学习并调整策略。
这种设计使得LLM自身成为记忆管理的“调度员”,而非依赖外部固定逻辑。思想体现在对有限资源的优化分配,尽管本文未明确给出优化目标函数,但其行为模式隐含了最大化任务效用和最小化信息丢失的意图。
3. 优势
MemGPT 的优势在于其赋予 LLM 自主管理上下文的能力,而非依赖固定的上下文窗口或外部的启发式规则。
- 动态上下文管理: LLM 根据当前任务需求和内存状态,主动决定哪些信息保留在昂贵但快速的主上下文,哪些信息分页到廉价但慢速的外部上下文。这比固定长度上下文或简单的 RAG 中的固定数量检索块更为灵活和高效。
- “无限”上下文的错觉: 通过有效的换入换出机制,即使底层 LLM 的物理上下文窗口有限,MemGPT 也能处理远超此限制的信息量,实现类似操作系统提供的虚拟内存效果。
- 自我编辑与反思: LLM 可以通过函数调用修改其工作上下文中的信息,实现对自身知识和状态的更新和纠错,例如在对话中更新用户偏好或修正先前的事实。
- 与工具使用范式的自然融合: 函数调用是 LLM 作为智能体与外部世界交互的核心。MemGPT 将内存管理也纳入函数调用的框架,统一了 LLM 的能力接口。
- 可解释性与可控性: 通过观察 LLM 的函数调用序列,可以部分理解其“思考”过程和记忆管理策略。
4. 实验
在两个对长上下文有强需求的领域进行了评估:
-
长程对话 (Conversational Agents):
- 任务:
深度记忆检索 (Deep Memory Retrieval, DMR): 测试代理是否能回忆起早期对话中的特定细节。对话开启者 (Conversation Opener): 测试代理能否基于长期积累的用户信息生成个性化和引人入胜的开场白。
- 结果: 相比固定上下文的基线模型 (包括 GPT-4),MemGPT 在 DMR 任务上准确率和 ROUGE-L 分数均大幅领先。在对话开启任务上,MemGPT 生成的开场白与人类标注的黄金标准相似度更高。这表明 MemGPT 能有效维护和利用长期记忆。
- 任务:
-
文档分析 (Document Analysis):
- 任务:
多文档问答 (Multi-Document QA): 在多个文档中检索信息回答问题。嵌套键值检索 (Nested Key-Value Retrieval): 需要进行多步查找,一个键的值可能是另一个键,直至找到最终值。
- 结果: 在多文档问答中,随着文档数量增加,基线模型性能因上下文截断而下降,而 MemGPT 通过分页检索能保持稳定性能。在嵌套键值检索任务中,MemGPT (尤其基于 GPT-4) 能
完成多跳查找,显著优于基线模型。这证明了 MemGPT 在需要跨多个信息片段进行推理的任务中的优势。
- 任务:
- 关键发现:
- 性能很大程度上依赖于底层 LLM 的函数调用能力和遵循指令的准确性。GPT-4 作为底层模型时,效果远好于 GPT-3.5。
- 传统的上下文扩展方法 (如简单增加窗口长度) 即使能容纳更多信息,也可能因“大海捞针”问题导致性能下降。MemGPT 通过让 LLM 主动检索和聚焦相关信息,缓解了此问题。
5. 总结
-
核心贡献: 提出了一种由 LLM 自主管理的分层记忆系统,通过模拟操作系统的虚拟内存和分页机制,在固定物理上下文的限制下,赋予 LLM 处理和回忆远超其窗口容量信息的能力。这不仅仅是 RAG 的简单扩展,而是将 LLM 提升为认知资源的主动管理者。
-
数学视角: 其本质是将上下文窗口视为一种有限的、可管理的资源 C m a x C_{max} Cmax。LLM 的任务是在每个时间步 t t t 决定哪些信息片段 I k I_k Ik (来自历史、文档等) 应该被加载到 C t ⊆ C m a x C_t \subseteq C_{max} Ct⊆Cmax 中,以最大化任务效用函数 U ( C t , task ) U(C_t, \text{task}) U(Ct,task)。MemGPT 通过函数调用赋予 LLM 这种决策能力,而非依赖外部启发式算法。
-
与RAG的异同: MemGPT可以视为一种更智能、更主动的检索增强生成(RAG)。传统RAG通常在LLM调用前由外部逻辑完成检索,而MemGPT是LLM 自身 决定何时检索、检索什么、以及如何将检索结果整合进其工作记忆。
-
展望:
- LLM Agent 的基石: 对于需要长期记忆、持续学习和适应环境的自主智能体 (Agent),MemGPT 提供的记忆管理框架是至关重要的。它为构建更持久、更有状态的 LLM 应用奠定了基础。
- 从“模型”到“系统”: MemGPT 代表了从将 LLM 视为单纯的“模型”到将其视为复杂“信息处理系统”核心部件的转变。这预示着未来 LLM 的研究可能更多地借鉴系统工程、操作系统设计等领域的思想。
- 可解释性与控制性的新维度: 通过分析 LLM 的记忆管理决策 (即其函数调用序列),可以间接洞察其“注意力分配”和“知识组织”策略,为理解和控制 LLM 的行为提供了新的途径。
- 潜在的“元学习”: 未来的工作可以探索让 LLM 学习更优的内存管理策略,例如,通过强化学习使其能够根据任务类型和历史经验动态调整其分页、总结和遗忘行为。
-
局限:
- 当前实现依赖于 LLM 强大的函数调用和指令遵循能力,这对模型本身提出了较高要求。
- 内存操作 (尤其是与外部存储的交互) 会引入额外的延迟。
- 如何设计最优的系统指令 (prompt engineering for memory management) 仍是一个挑战。
相关文章:
【论文解读】MemGPT: 迈向为操作系统的LLM
1st author: Charles Packer paper MemGPT[2310.08560] MemGPT: Towards LLMs as Operating Systems code: letta-ai/letta: Letta (formerly MemGPT) is the stateful agents framework with memory, reasoning, and context management. 这个项目现在已经转化为 Letta &a…...

vb监测Excel两个单元格变化,达到阈值响铃
需求 在Excel中实现监控两个单元格之间的变化范围,当达到某个设定的值的范围内时,实现自动响铃提示。 实现: 首先设置Excel,开启宏、打开开发者工具,点击visual Basic按钮,然后在左侧双击需要监测的shee…...

跨域请求解决方案全解析
跨域请求可以通过多种技术方案实现,核心是绕过浏览器的同源策略限制。以下是主流解决方案及具体实现方式: 一、CORS(跨域资源共享) 最常用的标准化方案,通过服务器设置HTTP响应头实现: Access-Control-Al…...

【前端】vue3性能优化方案
以下是Vue 3性能优化的系统性方案,结合核心优化策略与实用技巧,覆盖渲染、响应式、加载、代码等多个维度: ⚙️ 一、渲染优化 精准控制渲染范围 v-if vs v-show: v-if:条件为假时销毁DOM,适合低频切换场景&…...
node 进程管理工具 pm2 的详细说明 —— 一步一步配置 Ubuntu Server 的 NodeJS 服务器详细实录 7
前言 我以 Ubuntu Server 打造的 NodeJS 服务器为主题的系列文章,经过五篇博客,我们顺利的 安装了 ubuntu server 服务器,并且配置好了 ssh 免密登录服务器,安装好了 服务器常用软件安装, 配置好了 zsh 和 vim 以及 通过 NVM 安装…...
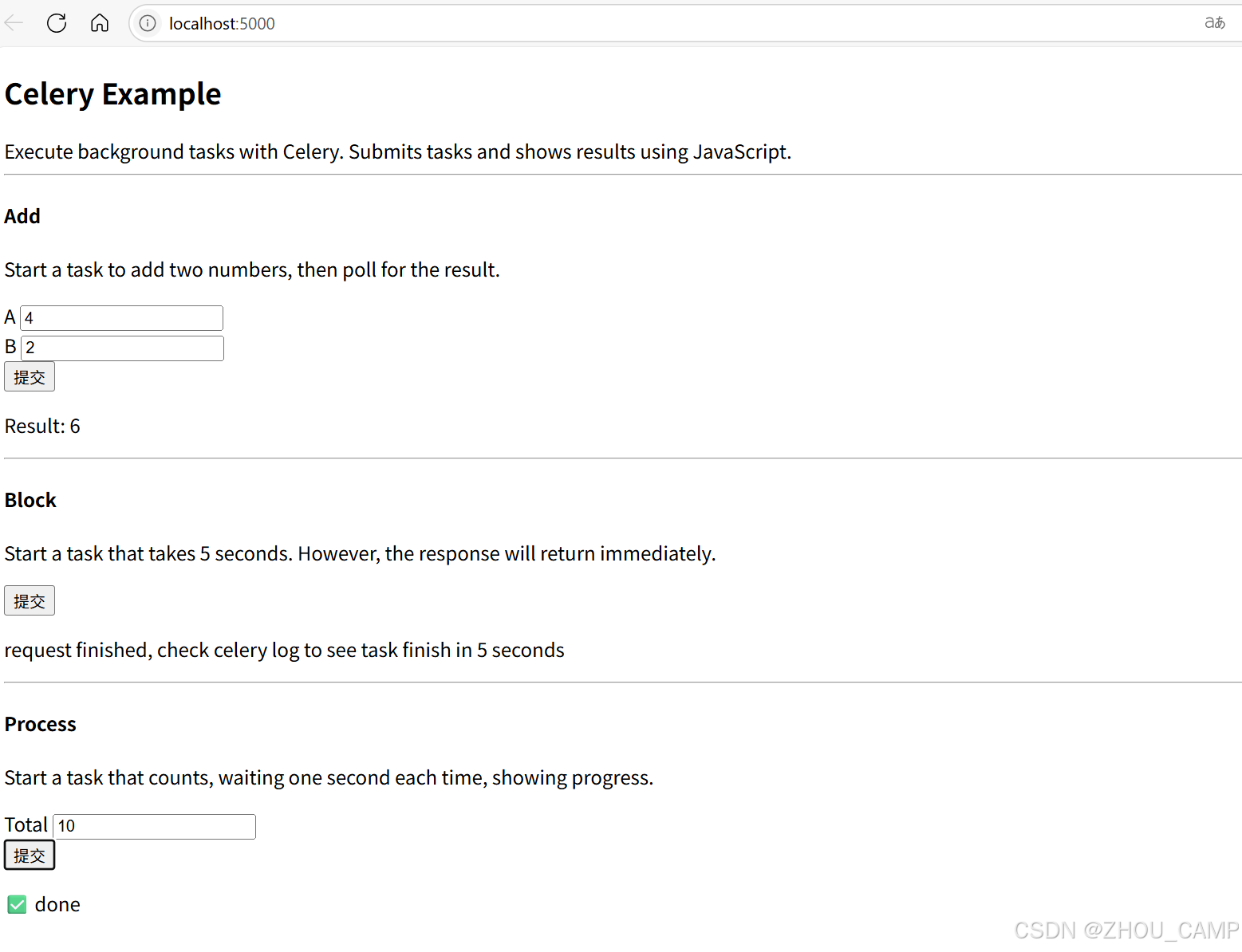
Flask与Celery 项目应用(shared_task使用)
目录 1. 项目概述主要功能技术栈 2. 项目结构3. 环境设置创建虚拟环境并安装依赖主要依赖 4. 应用配置Flask应用初始化 (__init__.py)Celery应用初始化 (make_celery.py) 5. 定义Celery任务 (tasks.py)任务说明 6. 创建API端点 (views.py)API端点说明 7. 前端界面 (index.html)…...

Fetch API 使用详解:Bearer Token 与 localStorage 实践
Fetch API:现代浏览器内置的用于发送 HTTP 请求的 API,Bearer Token:一种基于令牌的身份验证方案,常用于 JWT 认证,localStorage:浏览器提供的持久化存储方案,用于在客户端存储数据。 token是我…...

vue3 vite.config.js 引入bem.scss文件报错
[sass] Can’t find stylesheet to import. ╷ 1 │ use “/bem.scss” as *; │ ^^^^^^^^^^^^^^^^^^^^^^ ╵ src\App.vue 1:1 root stylesheet 分析 我们遇到了一个在Vue3项目中使用Vite时,在vite.config.js中引入bem.scss文件报错的问题。错误信息指出在App.vue…...
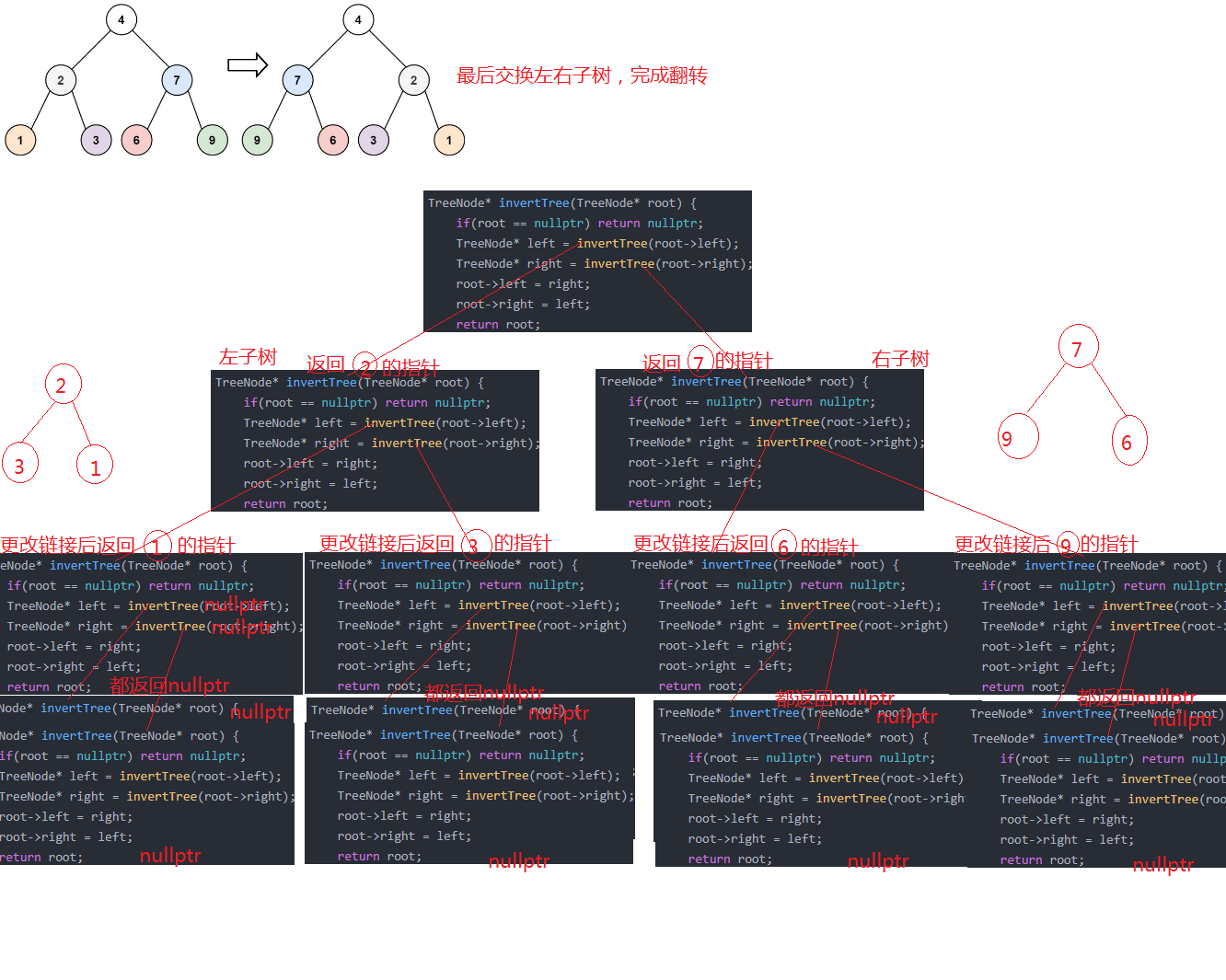
二叉树-226.翻转链表-力扣(LeetCode)
一、题目解析 翻转可以理解为树的左右子树交换,从根到叶子节点,但是这里交换的是链接的指针,而不是单纯的交换值,当出现nullptr时,也是可以交换链接的,交换值的话就不行了。 二、算法原理 依旧的递归&…...
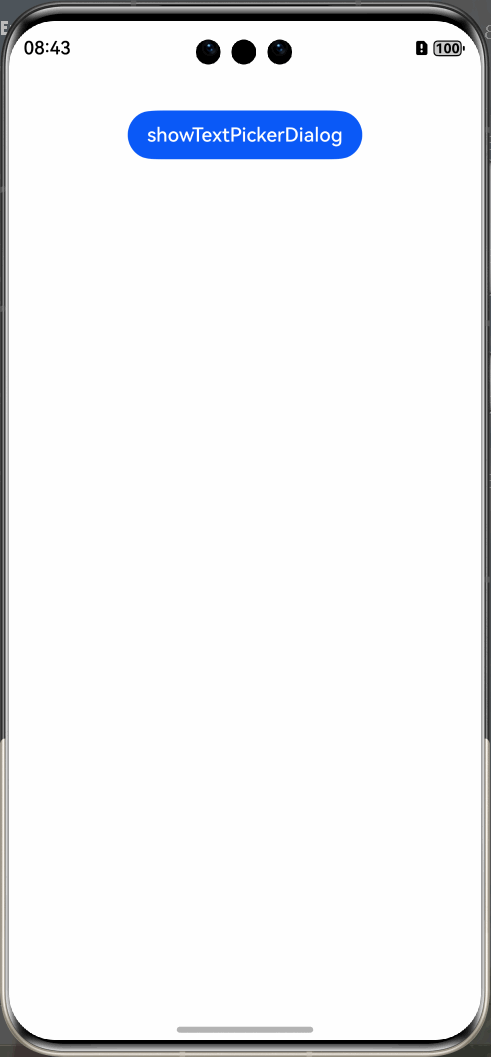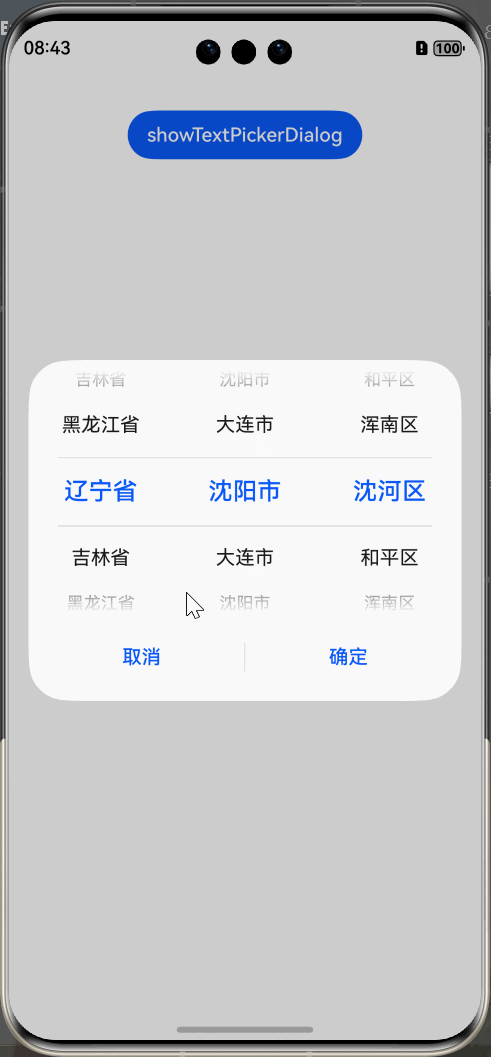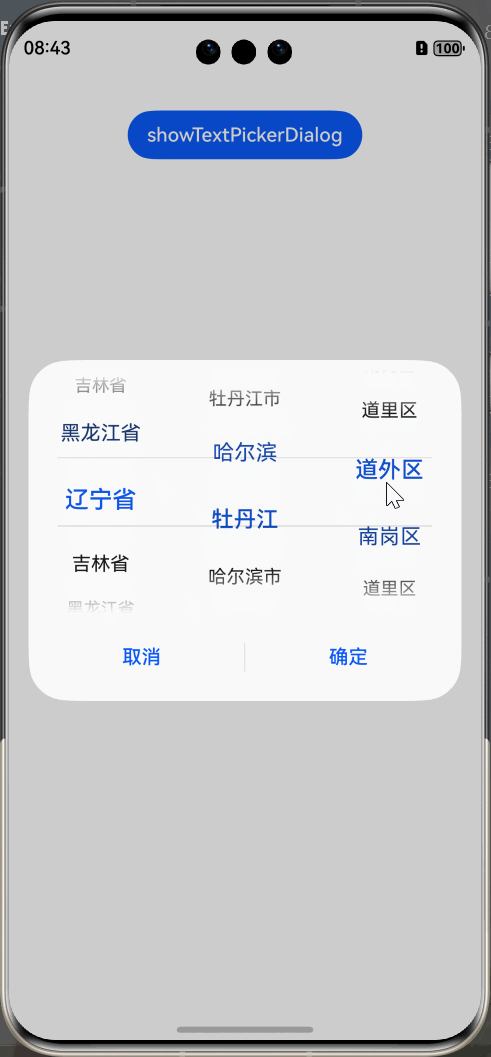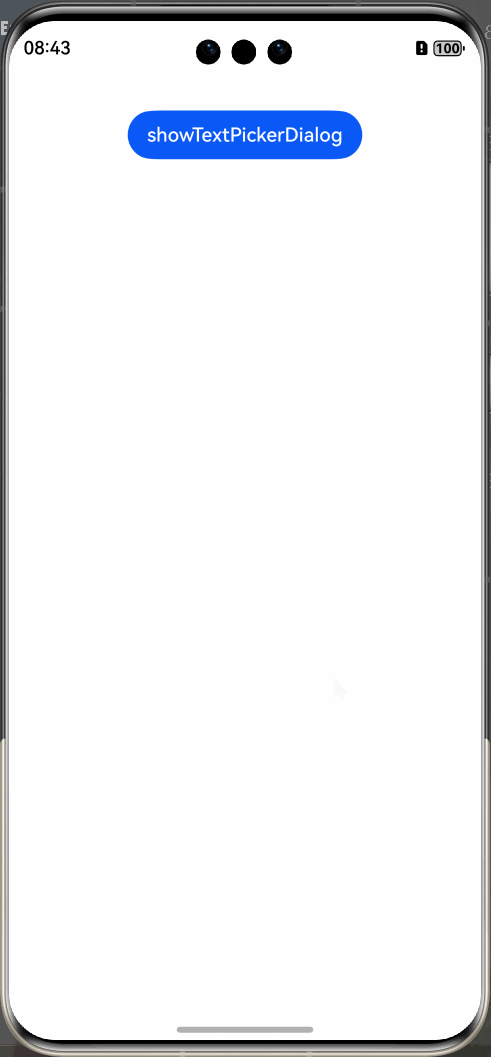
HarmonyOS Next 弹窗系列教程(3)
HarmonyOS Next 弹窗系列教程(3) 选择器弹窗 (PickerDialog) 介绍 选择器弹窗通常用于在用户进行某些操作(如点击按钮)时显示特定的信息或选项。让用户可以进行选择提供的固定的内容。 以下内容都属于选择器弹窗: …...

编程笔记---问题小计
编程笔记 qml ProgressBar 为什么valuemodel.progress / 100 在QML中,ProgressBar的value属性用于表示进度条的当前进度值,其范围通常为0到1(或0%到100%)。当使用model.progress / 100来设置value时,这样做的原因是为…...

【docker】Windows安装docker
环境及工具(点击下载) Docker Desktop Installer.exe (windows 环境下运行docker的一款产品) wsl_update_x64 (Linux 内核包) 前期准备 系统要求2: Windows 11:64 位系统&am…...
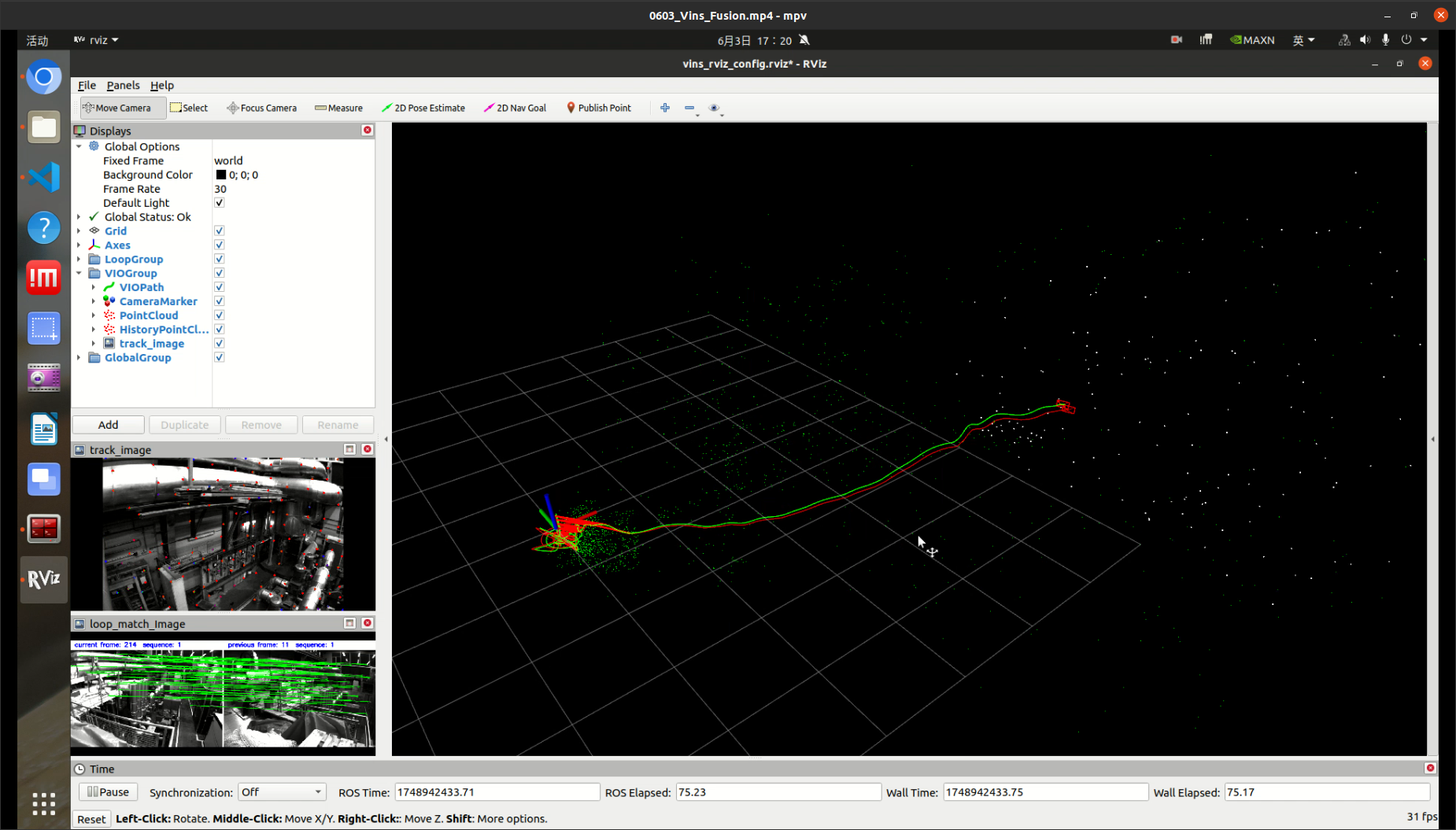
无人机避障——感知部分(Ubuntu 20.04 复现Vins Fusion跑数据集)胎教级教程
硬件环境:NVIDIA Jeston Orin nx 系统:Ubuntu 20.04 任务:跑通 EuRoC MAV Dataset 数据集 展示结果: 编译Vins Fusion 创建工作空间vins_ws # 创建目录结构 mkdir -p ~/vins_ws/srccd ~/vins_ws/src# 初始化工作空间…...

人工智能--大型语言模型的存储
好的,我现在需要回答用户关于GGUF文件和safetensors文件后缀的差别的问题。首先,我得先确认这两个文件格式的具体应用场景和它们各自的优缺点。用户可能是在处理大模型时遇到了这两种文件格式,想了解它们的区别以便正确使用。 首先ÿ…...

OD 算法题 B卷【删除字符串中出现次数最少的字符】
文章目录 删除字符串中出现次数最少的字符 删除字符串中出现次数最少的字符 实现删除字符串中出现次数最少的字符,若(最少的)有多个字符出现次数一样,则都删除。输出删除后的字符串,其他字符保持原有顺序;…...
如何安装并使用RustDesk
参考: 搭建 RustDesk Server:打造属于自己的远程控制系统,替代 TeamViewer 和 ToDesk! 向日葵、ToDesk再见!自己动手,自建RustDesk远程服务器真香! 通俗易懂:RustDesk Server的搭…...

机器学习——随机森林算法
随机森林算法是一种强大的树集成算法,比使用单个决策树效果要好得多。 以下是生成树集成的方法:假设有一个大小为m的训练集,然后对于b1到B,所以执行B次,可以使用有放回抽样来创建一个大小为m的训练集。所以如果有10个…...

【从零学习JVM|第二篇】字节码文件
前言: 通过了解字节码文件可以帮助我们更容易的理解JVM的工作原理,所以接下来,我们来介绍一下字节码文件。 目录 前言: 正确的打开字节码文件 字节码文件组成 1. 魔数(Magic Number) 2. 版本号&…...

Fractal Generative Models论文阅读笔记与代码分析
何恺明分型模型这篇文章在二月底上传到arXiv预出版网站到现在已经过了三个月,当时我也听说这篇文章时感觉是大有可为,但是几个月不知道忙啥了,可能错过很多机会,但是亡羊补牢嘛,而且截至目前,该文章应该也还…...

软件测试—学习Day11
今天学习下兼容性 1.App兼容性常见问题 以下是关于 App 兼容性问题的常见举例,涵盖界面展示、操作逻辑、性能差异三大维度,涉及不同系统、设备及网络环境的兼容性场景: 一、界面展示问题 界面展示兼容性问题主要由操作系统版本差异、屏幕…...
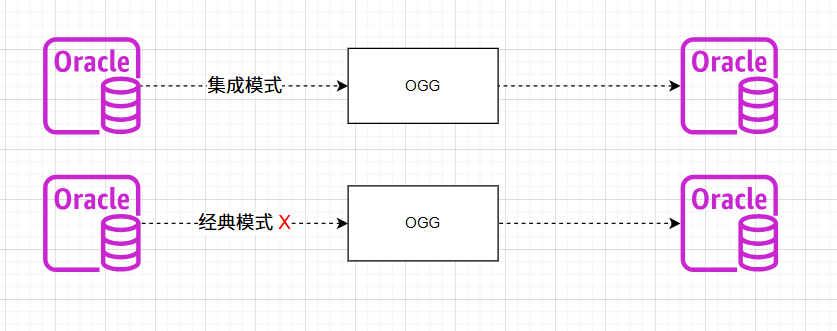
OGG-01635 OGG-15149 centos服务器远程抽取AIX oracle11.2.0.4版本
背景描述 有一套ogg远程抽取的环境,源端是AIX7.1环境的oracle 11.2.0.4版本的数据库,中间是OGG抽取服务器,目标端是centos 7.9环境的oracle 19c。 采用集成模式远程抽取源端数据正常,但是经典模式远程抽取源数据的时候抽取进程启…...
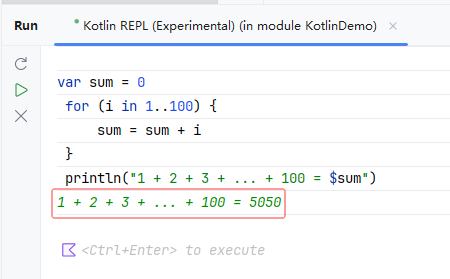
Kotlin REPL初探
文章目录 1. Kotlin REPL 简介2. 在命令行中玩Kotlin REPL2.1 下载Kotlin编译器压缩包2.2 安装配置Kotlin编译器2.3 启动Kotlin交互式环境2.4 在命令行玩Kotlin REPL 3. 在IDEA里玩Kotlin REPL3.1 打开Kotlin REPL窗口3.2 在Kotlin REPL窗口玩代码 4. Kotlin REPL 的优势 1. Ko…...
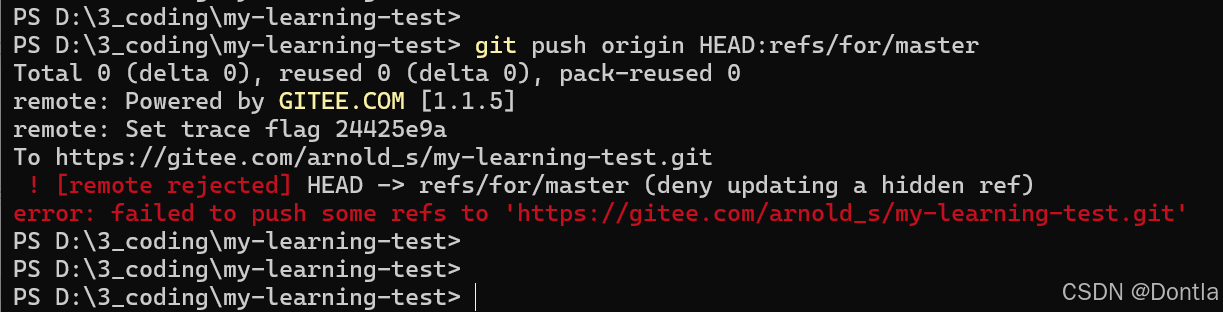
git引用概念(git reference,git ref)(简化对复杂SHA-1哈希值的管理)(分支引用、标签引用、HEAD引用、远程引用、特殊引用)
文章目录 **引用的本质**1. **引用是文件**2. **引用的简化作用** **引用的类型**1. **分支引用(Branch References)**2. **标签引用(Tag References)**3. **HEAD 引用**4. **远程引用(Remote References)*…...
Github 2025-06-07 Rust开源项目日报Top10
根据Github Trendings的统计,今日(2025-06-07统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Rust项目10Dart项目1TypeScript项目1RustDesk: 用Rust编写的开源远程桌面软件 创建周期:1218 天开发语言:Rust, Dart协议类型:GNU Affero Ge…...

gorm 配置数据库
介绍 GORM 是 Go 语言中最流行的 ORM(对象关系映射)库之一,基于数据库操作的封装,提供类似 Django ORM / SQLAlchemy 的开发体验。 特性描述支持多种数据库MySQL、PostgreSQL、SQLite、SQL Server、ClickHouse 等自动迁移自动根…...
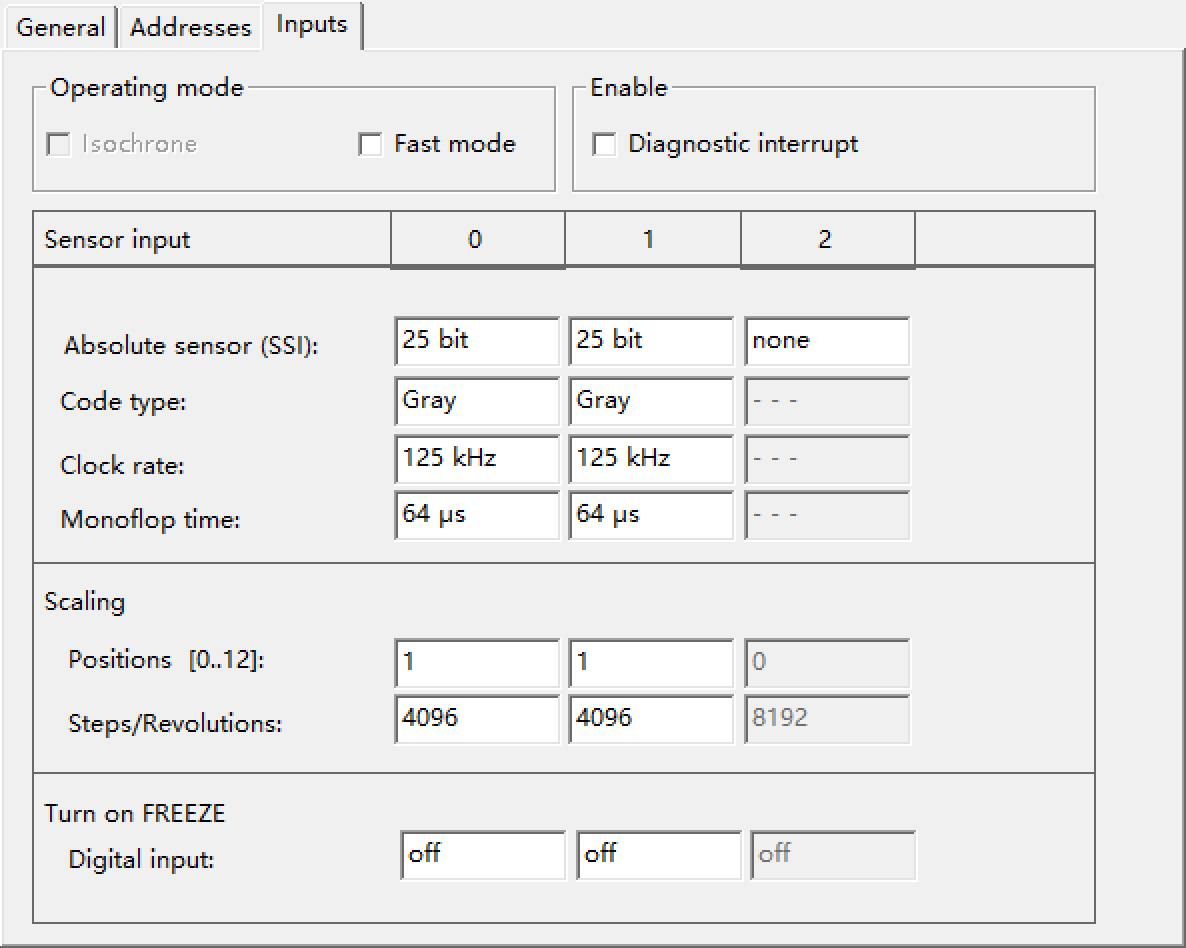
自动化立体仓库堆垛机控制系统STEP7 OB1功能块
1、堆垛机控制系统STEP7硬件组态如下图 CPU CPU 314C-2 PN/DP 6ES7 314-6EH04-0AB0 SM 338 POS-INPUT AO2x12Bit 6ES7 332-5HB01-0AB0 2、堆垛机控制系统STEP7内部变量 前进HMI M 0.0 BOOL 后退HMI M 0.1 BOOL 上升HMI M 0.2 B…...

MATLAB生成大规模无线通信网络拓扑(任意节点数量)
功能: 生成任意节点数量的网络拓扑,符合现实世界节点空间分布和连接规律 效果: 30节点: 100节点: 500节点: 程序: %创建时间:2025年6月8日 %zhouzhichao %自然生长出n节点的网络% …...
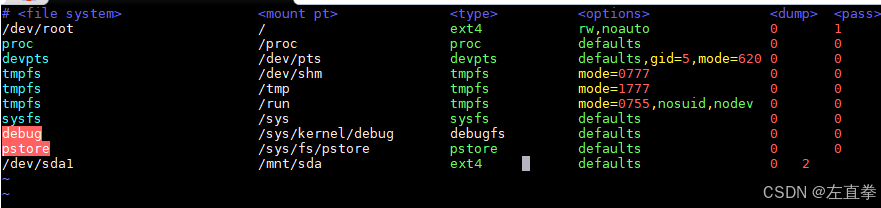
ubuntu 20.04挂载固态硬盘
我们有个工控机,其操作系统是ubuntu 20.04。可以接入一个固态硬盘。将固态硬盘插好后,就要进行挂载。在AI的指导下,过程并不顺利。记录如下: 1、检查硬盘是否被识别 安装好硬盘后,运行以下命令来检查Linux系统是否…...

【AI教我写网站-ECG datacenter】
阶段性总结:后端用户管理基础 在项目管理和协作中,清晰地阐述“为什么做”比“怎么做”更能凝聚共识和提供方向。我们不仅要理解技术实现,更要明白其背后的动机和意义。 让我们重新回顾并总结我们到目前为止的工作,这次会更侧重…...

2. Web网络基础 - 协议端口
深入解析协议端口与netstat命令:网络工程师的实战指南 在网络通信中,协议端口是服务访问的门户。本文将全面解析端口概念,并通过netstat命令实战演示如何监控网络连接状态。 一、协议端口核心知识解析 1. 端口号的本质与分类 端口范围类型说…...