基于 Transformer robert的情感分类任务实践总结之二——R-Drop
基于 Transformer robert的情感分类任务实践总结之一
核心改进点
1. R-Drop正则化
- 原理:通过在同一个输入上两次前向传播(利用Dropout的随机性),强制模型对相同输入生成相似的输出分布,避免过拟合。
- 实现:
- 对同一文本输入,两次通过RoBERTa模型(Dropout层随机失活不同神经元),得到两组logits。
- 损失函数由**交叉熵损失(CE)和KL散度损失(KL)**组成:
Loss = CE ( l o g i t s 1 , l a b e l s ) + CE ( l o g i t s 2 , l a b e l s ) + α × KL ( l o g i t s 1 , l o g i t s 2 ) \text{Loss} = \text{CE}(logits_1, labels) + \text{CE}(logits_2, labels) + \alpha \times \text{KL}(logits_1, logits_2) Loss=CE(logits1,labels)+CE(logits2,labels)+α×KL(logits1,logits2)
其中,(\alpha)为KL损失权重(本文设为5.0)。
2. 标签平滑(Label Smoothing)
- 作用:缓解模型对标签的过度自信,通过向独热标签中添加均匀噪声(本文系数为0.1),提升泛化能力。
评价指标
- 准确率(Accuracy)、F1分数(F1)、ROC-AUC值,全面评估分类性能。
实验结果与总结
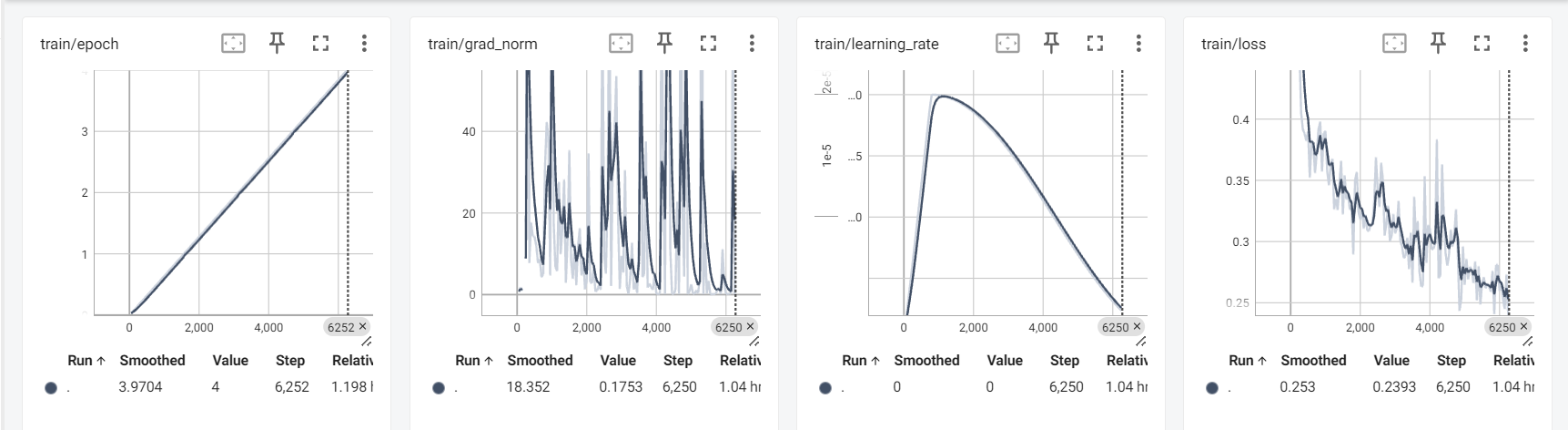
- 性能提升:相比基础RoBERTa,改进后模型在测试集上的F1分数提升约1.2%,AUC提升约0.8%,过拟合现象明显缓解。
- 核心价值:R-Drop通过强制模型输出一致性,有效增强了预测稳定性;标签平滑则降低了模型对硬标签的依赖,两者结合显著提升了泛化能力。
- 适用场景:文本分类、情感分析等任务,尤其适合标注数据有限或需提升模型鲁棒性的场景。
代码
#!/usr/bin/env python
# 改进版 RoBERTa 情感分类器 v2
import os
import random
import numpy as np
import torch
import torch.nn as nn
from transformers import (AutoTokenizer,AutoModelForSequenceClassification,Trainer,TrainingArguments,DataCollatorWithPadding,get_cosine_schedule_with_warmup,set_seed,EarlyStoppingCallback,
)
from datasets import load_dataset
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"# 设置随机种子
set_seed(42)# 配置
MODEL_NAME = "roberta-base"
NUM_LABELS = 2
R_DROP_ALPHA = 5.0 # R-Drop loss 权重
LABEL_SMOOTHING = 0.1 # 标签平滑系数# 加载数据
dataset = load_dataset("imdb")
train_dataset = dataset["train"]
test_dataset = dataset["test"]# Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)def preprocess_function(examples):return tokenizer(examples["text"], truncation=True)train_dataset = train_dataset.map(preprocess_function, batched=True)
test_dataset = test_dataset.map(preprocess_function, batched=True)# 数据整理器
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME, num_labels=NUM_LABELS
)# 改进版 Loss R-Drop + Label Smoothing)
class RDropLoss(nn.Module):def __init__(self, alpha=1.0, label_smoothing=0.0):super(RDropLoss, self).__init__()self.alpha = alphaself.label_smoothing = label_smoothingself.ce = nn.CrossEntropyLoss(label_smoothing=label_smoothing)self.kl = nn.KLDivLoss(reduction="batchmean")def forward(self, logits1, logits2, labels):# CrossEntropy Lossce_loss1 = self.ce(logits1, labels)ce_loss2 = self.ce(logits2, labels)ce_loss = 0.5 * (ce_loss1 + ce_loss2)# KL散度 Lossp = torch.log_softmax(logits1, dim=-1)q = torch.log_softmax(logits2, dim=-1)p_softmax = torch.softmax(logits1, dim=-1)q_softmax = torch.softmax(logits2, dim=-1)kl_loss = 0.5 * (self.kl(p, q_softmax) + self.kl(q, p_softmax))return ce_loss + self.alpha * kl_loss# 评价指标
def compute_metrics(eval_pred):logits, labels = eval_predprobs = torch.softmax(torch.tensor(logits), dim=-1).numpy()predictions = np.argmax(logits, axis=-1)acc = accuracy_score(labels, predictions)f1 = f1_score(labels, predictions)try:auc = roc_auc_score(labels, probs[:, 1])except:auc = 0.0return {"accuracy": acc, "f1": f1, "auc": auc}# 自定义 Trainer,支持 R-Drop
class RDropTrainer(Trainer):def __init__(self, *args, alpha=1.0, label_smoothing=0.0, **kwargs):super().__init__(*args, **kwargs)self.rdrop_loss_fn = RDropLoss(alpha=alpha, label_smoothing=label_smoothing)def compute_loss(self, model, inputs, return_outputs=False, **kwargs):labels = inputs.pop("labels")# forward twice (Dropout 不同)# model.train()#没有必要。重复了。outputs1 = model(**inputs)outputs2 = model(**inputs)logits1 = outputs1.logitslogits2 = outputs2.logitsloss = self.rdrop_loss_fn(logits1, logits2, labels)return (loss, outputs1) if return_outputs else loss# Trainer 参数
training_args = TrainingArguments(output_dir="./results_rdrop",eval_strategy="epoch",save_strategy="epoch",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=16,num_train_epochs=5,weight_decay=0.01,warmup_ratio=0.1,lr_scheduler_type="cosine", # CosineAnnealinglogging_dir="./logs_rdrop",#tensorboard --logdir ./logs_rdroplogging_steps=50,load_best_model_at_end=True,metric_for_best_model="f1",fp16=True,save_total_limit=2,
)
early_stopping_callback = EarlyStoppingCallback(early_stopping_patience=3, early_stopping_threshold=0.01)# 初始化 Trainer
trainer = RDropTrainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=test_dataset,processing_class=tokenizer, data_collator=data_collator,compute_metrics=compute_metrics,callbacks=[early_stopping_callback], alpha=R_DROP_ALPHA,label_smoothing=LABEL_SMOOTHING,
)# 训练
trainer.train()# 评估
trainer.evaluate()tensorboard
参考资料:
- R-Drop论文:《R-Drop: Regularized Dropout for Neural Networks》
相关文章:
基于 Transformer robert的情感分类任务实践总结之二——R-Drop
基于 Transformer robert的情感分类任务实践总结之一 核心改进点 1. R-Drop正则化 原理:通过在同一个输入上两次前向传播(利用Dropout的随机性),强制模型对相同输入生成相似的输出分布,避免过拟合。实现:…...
个人电脑部署本地大模型+UI
在这个AI飞速进步的时代,越来越多的大模型出现在市面上 本地大模型也越来越火爆! 它完全免费,随时可以访问,数据仅存在本地,还可以自己微调,训练! 今天我来教大家,如何在一台普通…...

Three.js + Vue3 加载GLB模型项目代码详解
本说明结合 src/App.vue 代码,详细解释如何在 Vue3 项目中用 three.js 加载并显示 glb 模型。 1. 依赖与插件导入 import {onMounted, onUnmounted } from vue import * as THREE from three import Stats from stats.js import {OrbitControls } from three/examples/jsm/co…...

MongoDB $type 操作符详解
MongoDB $type 操作符详解 引言 MongoDB 是一款流行的开源文档型数据库,它提供了丰富的查询操作符来满足不同的数据查询需求。在 MongoDB 中,$type 操作符是一个非常有用的查询操作符,它允许用户根据文档中字段的类型来查询文档。本文将详细介绍 MongoDB 的 $type 操作符,…...
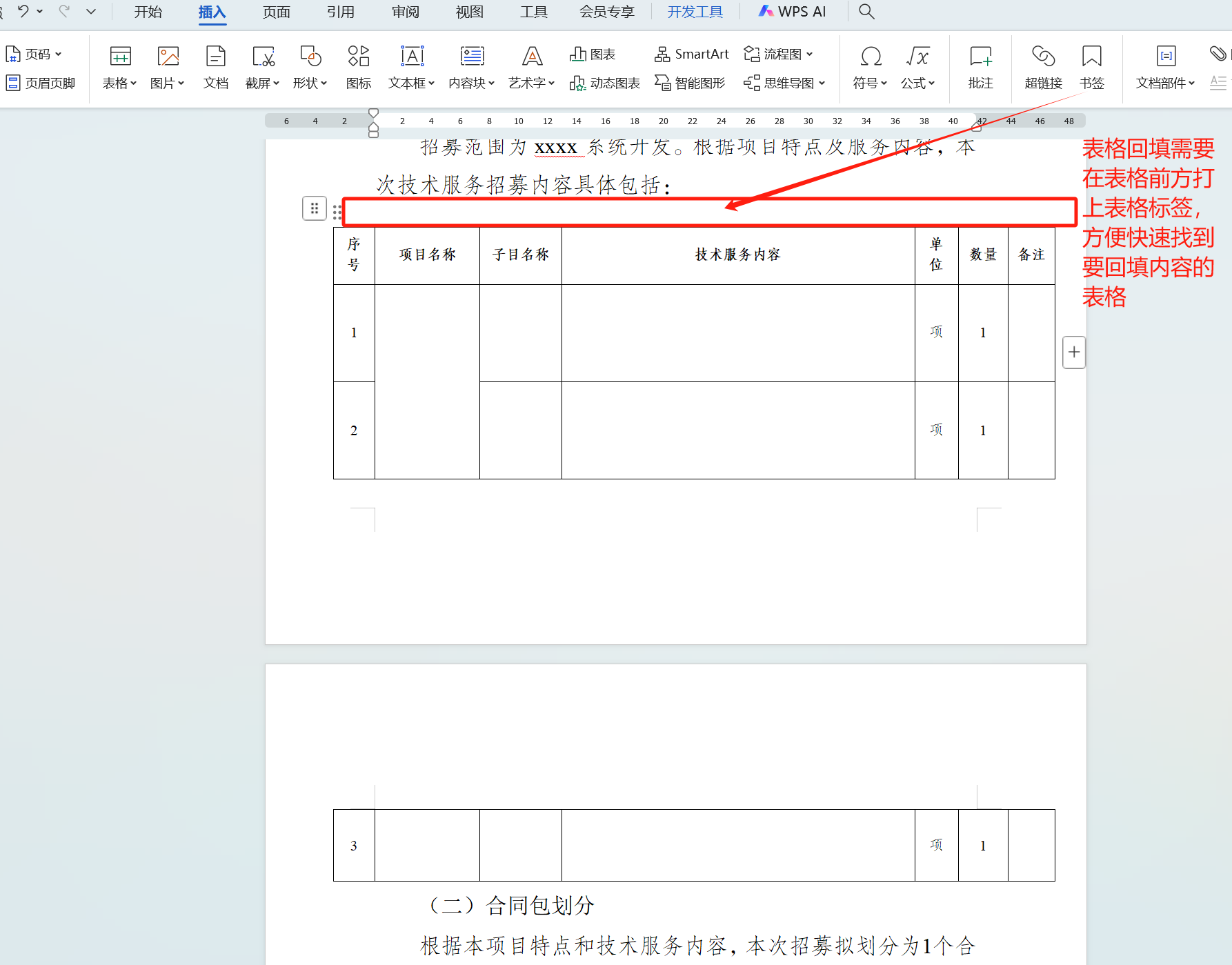
Vue3项目实现WPS文件预览和内容回填功能
技术方案背景:根据项目需要,要实现在线查看、在线编辑文档,并且进行内容的快速回填,根据这一项目背景,最终采用WPS的API来实现,接下来我们一起来实现项目功能。 1.首先需要先准备好测试使用的文档…...
PySide6 GUI 学习笔记——常用类及控件使用方法(多行文本控件QTextEdit)
文章目录 PySide6.QtWidgets.QTextEdit 应用举例概述核心特性常用方法文本内容操作光标和选择操作格式和样式查找功能视图控制状态设置常用信号 代码示例示例说明1. 基本设置2. 文本格式化功能3. 功能按钮4. 信号处理 PySide6.QtWidgets.QTextEdit 应用举例 概述 QTextEdit 是…...

【版本控制】Git 和 GitHub 入门教程
目录 0 引言1 Git与GitHub的诞生1.1 Git:Linus的“两周奇迹”,拯救Linux内核1.2 GitHub:为Git插上协作的翅膀1.3 协同进化:从工具到生态的质变1.4 关键历程时间轴(2005–2008) 2 Git与GitHub入门指南2.1 Gi…...

上位机知识篇---Flask框架实现Web服务
本文将简单介绍Web 服务与前端显示部分,它们基于Flask 框架和HTML/CSS/JavaScript实现,主要负责将实时视频流和检测结果通过网页展示,并提供交互式状态监控。以下是详细技术解析: 一、Flask Web 服务架构 1. 核心路由设计 app.…...

django paramiko 跳转登录
在使用Django框架结合Paramiko进行SSH远程操作时,通常涉及到自动化脚本的执行,比如远程服务器上的命令执行、文件传输等。如果你的需求是“跳转登录”,即在登录远程服务器后,再通过该服务器的SSH连接跳转到另一台服务器࿰…...
)
Prompt工程学习之思维树(TOT)
思维树 定义:思维树(Tree of Thoughts, ToT) 是一种先进的推理框架,它通过同时探索多条推理路径对思维链(Chain of Thought)** 进行了扩展。该技术将问题解决视为一个搜索过程 —— 模型生成不同的中间步骤…...
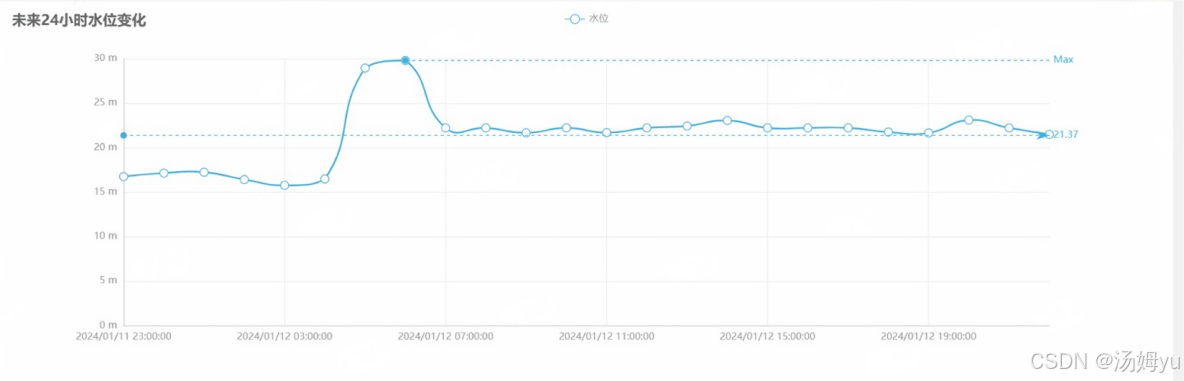
基于python大数据的水文数据分析可视化系统
博主介绍:高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了多年的设计程序开发,开发过上千套设计程序,没有什么华丽的语言,只有实实在…...

人工智能学习09-变量作用域
人工智能学习概述—快手视频 人工智能学习09-变量作用域—快手视频...

DJango知识-模型类
一.项目创建 在想要将项目创键的目录下,输入cmd (进入命令提示符)在cmd中输入:Django-admin startproject 项目名称 (创建项目)cd 项目名称 (进入项目)Django-admin startapp 程序名称 (创建程序)python manage.py runserver 8080 (运行程序)将弹出的网址复制到浏览器中…...

结构性-代理模式
动态代理主要是为了处理重复创建模板代码的场景。 使用示例 public interface MyInterface {String doSomething(); }public class MyInterfaceImpl implements MyInterface{Overridepublic String doSomething() {return "接口方法dosomething";} }public class M…...
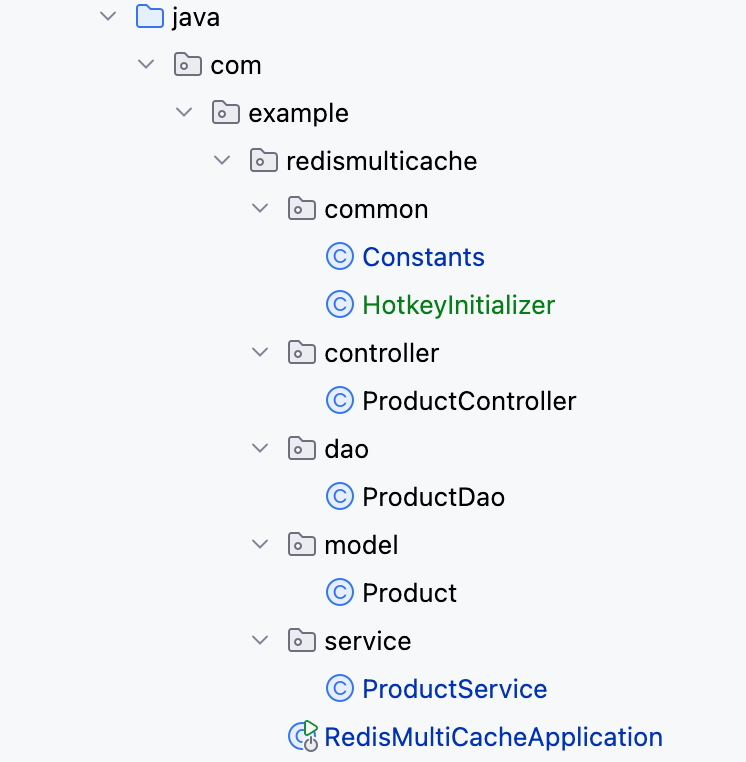
【Redis】笔记|第10节|京东HotKey实现多级缓存架构
缓存架构 京东HotKey架构 代码结构 代码详情 功能点:(如代码有错误,欢迎讨论纠正) 多级缓存,先查HotKey缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新…...
)
Java中Git基础操作详解(clone、commit、push、branch)
Git是Java开发者必备的版本控制工具,以下是核心操作的详细说明及示例: 一、Git基础概念 仓库(Repository):存储代码的目录,包含所有版本历史。提交(Commit)…...

基于规则的自然语言处理
基于规则的自然语言处理 规则方法形态还原(针对英语、德语、法语等)中文分词切分歧义分词方法歧义字段消歧方法分词带来的问题 词性标注命名实体分类机器翻译规则方法的问题 规则方法 以规则形式表示语言知识,强调人对语言知识的理性整理&am…...
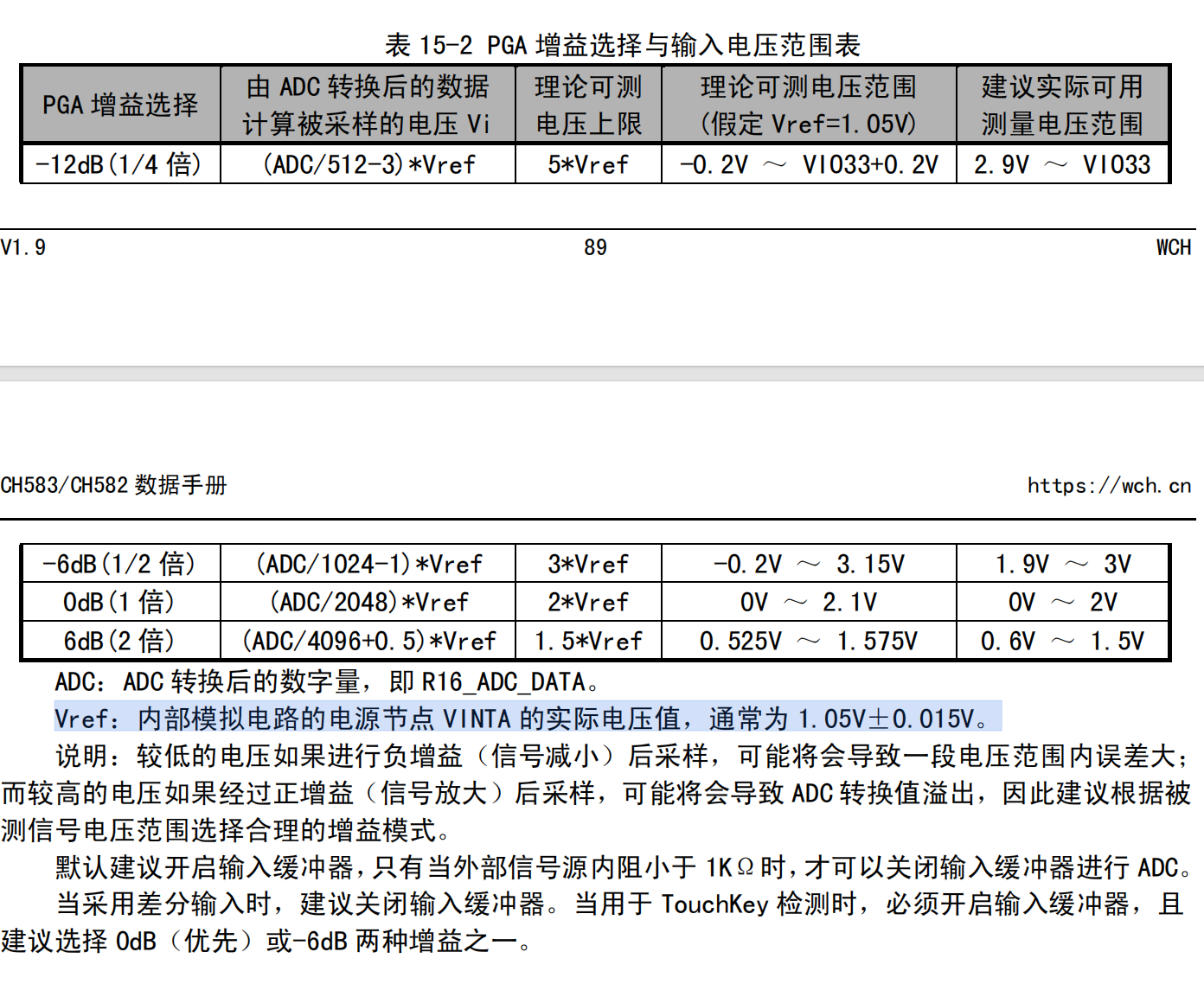
使用MounRiver Studio Ⅱ软件写一个CH592F芯片的ADC采集程序,碰到的问题
MounRiver Studio Ⅱ 默认是不开启浮点计算的,所以有些浮点功能不能用,碰到问题是 while (1) {DelayMs (100);tmp Read_Temperature (0);sprintf (tempBuffer, "temp:%.2f\r\n", tmp); // 格式化温度值到字符串。使用%f要开启相应的…...

简约商务年终工作总结报告PPT模版分享
简约精致扁平化商务通用动画PPT模版,简约大气素雅商务PPT模版,商务PPT模版,商业计划书PPT模版,IOS风商务通用PPT模版,公司介绍企业宣传PPT模版,创业融资PPT模版,创意低多边形PPT模版,…...
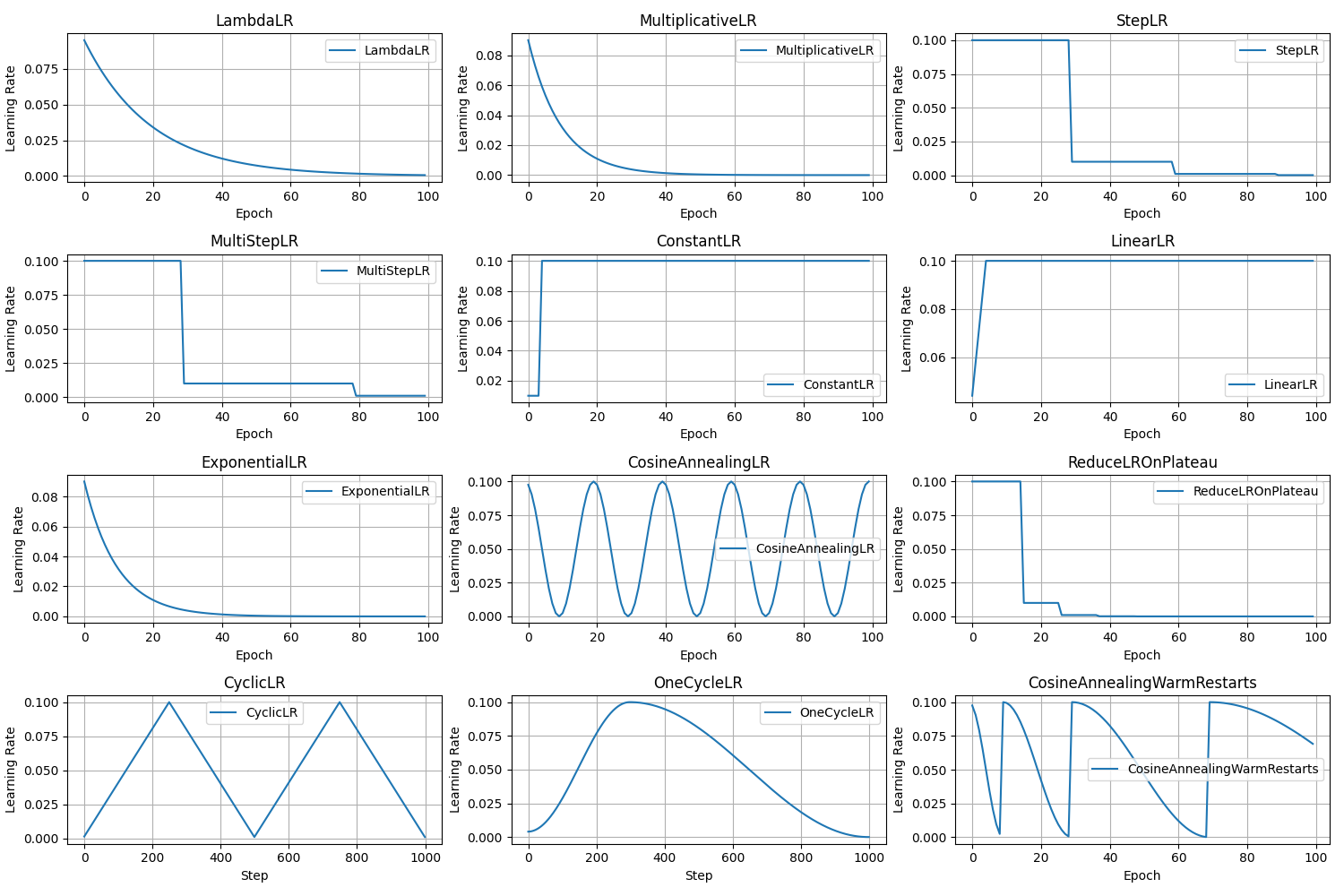
深度学习学习率优化方法——pytorch中各类warm up策略
warm-up具体原理以及为什么这么做在之前的博客有介绍,这里直接介绍如何直接使用pytorch中的warm-up策略,在pytorch中对于warm-up所有支持的方法都有描述,可以直接阅读1。 深度学习中各类学习率优化方法(AdaGrad/RMSprop/Adam/Warm-UP)原理及其…...

分类数据集 - 场景分类数据集下载
数据集介绍:自然场景分类数据集,真实场景高质量图片数据;适用实际项目应用:自然场景下场景分类项目,以及作为通用场景分类数据集场景数据的补充;数据集类别:buildings、forest、glacier、mounta…...
leetcode.多数元素
169. 多数元素 - 力扣(LeetCode) import java.util.HashMap;public class LeetCode169 {public int majorityElement(int[] nums) {int count nums.length;int res count/2;Scanner scanner new Scanner(System.in);HashMap<Integer,Integer> …...
Server - 使用 Docker 配置 PyTorch 研发环境
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/148421901 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 建议使…...

2025年渗透测试面试题总结-腾讯[实习]安全研究员(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]安全研究员 1. 自我介绍 2. SQL二次注入原理 3. 二次注入修复方案 4. SQL注入绕WAFÿ…...

Vue:Form正则校验
目录 1. 只能输入正整数或正小数(保留三位小数) 1. 只能输入正整数或正小数(保留三位小数) cc: [{required: true, message: "钻杆长度不能为空", trigger: "blur" },{pattern: /^\d(\.\d{1,3})?$/, message: 只能输入正整数或正小数(保留三位小数), tri…...

如何处理React中表单的双向数据绑定?
在前端开发中,双向数据绑定(Two-way Data Binding)是指视图(View)与数据模型(Model)之间保持同步:当模型发生变化时,视图会自动更新;当视图(用户输…...

时间序列预测的机器学习方法:从基础到实战
时间序列预测是机器学习中一个重要且实用的领域,广泛应用于金融、气象、销售预测、资源规划等多个行业。本文将全面介绍时间序列预测的基本概念、常用方法,并通过Python代码示例展示如何构建和评估时间序列预测模型。 1. 时间序列预测概述 时间序列是按…...
01-VMware16虚拟机详细安装
官网地址:https://www.vmware.com/cn.html 1.1 打开下载好的 .exe 文件, 双击安装。 1.2 点击下一步 1.3 先勾选我接受许可协议中的条款,然后点击下一步 1.4 自定义安装路径,注意这里的文件路径尽量不要包含中文,完成…...
sql列中数据通过逗号分割的集合,按需求剔除部分值
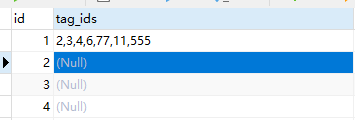
前置 不会REGEXP 方法的需要在这里学习一下下 记sql字段逗号分隔,通过list查询 功能点 现有一个表格中一列存储的是标签的集合,通过逗号分割 入下: 其中tag_ids是逗号分割的标签,现在需要删除标签组中的一些标签,因…...

下一代设备健康管理解决方案:基于多源异构数据融合的智能运维架构
导语: 在工业4.0深度演进的关键节点,传统设备管理面临数据孤岛、误诊率高、运维滞后三大致命瓶颈。本文解析基于边缘智能与数字孪生的新一代解决方案架构,并实测验证中讯烛龙PHM-X系统如何通过多模态感知→智能诊断→自主决策闭环,…...