时间序列预测的机器学习方法:从基础到实战
时间序列预测是机器学习中一个重要且实用的领域,广泛应用于金融、气象、销售预测、资源规划等多个行业。本文将全面介绍时间序列预测的基本概念、常用方法,并通过Python代码示例展示如何构建和评估时间序列预测模型。
1. 时间序列预测概述
时间序列是按时间顺序排列的一系列数据点,通常是在连续时间间隔内进行的测量。时间序列预测就是基于历史数据来预测未来的值。
1.1 时间序列的特点
时间序列数据通常具有以下几个特征:
-
趋势(Trend): 数据长期呈现上升或下降的趋势
-
季节性(Seasonality): 数据在固定周期内的重复模式
-
周期性(Cyclicity): 非固定周期的波动
-
随机性(Randomness): 无法预测的噪声
1.2 时间序列预测的应用场景
-
股票价格预测
-
销售额预测
-
电力负荷预测
-
气象预报
-
交通流量预测
-
设备故障预测
2. 传统时间序列预测方法
在介绍机器学习方法之前,我们先简要了解一些传统的时间序列预测方法。
2.1 自回归模型(AR)
自回归模型使用过去值的线性组合来预测未来值:
from statsmodels.tsa.ar_model import AutoReg
import numpy as np# 生成示例数据
np.random.seed(42)
data = np.random.normal(size=100)# 拟合AR模型
model = AutoReg(data, lags=2)
model_fit = model.fit()# 预测
predictions = model_fit.predict(start=len(data), end=len(data)+5)
print(predictions)2.2 移动平均模型(MA)
移动平均模型使用过去误差项的线性组合来预测未来值。
2.3 自回归移动平均模型(ARMA)
ARMA模型结合了AR和MA模型:
from statsmodels.tsa.arima.model import ARIMA# 拟合ARMA模型 (ARIMA(p,d,0)就是ARMA(p,0))
model = ARIMA(data, order=(2,0,1))
model_fit = model.fit()# 预测
predictions = model_fit.predict(start=len(data), end=len(data)+5)
print(predictions)2.4 自回归积分移动平均模型(ARIMA)
ARIMA模型在ARMA基础上增加了差分处理:
# 拟合ARIMA模型
model = ARIMA(data, order=(1,1,1))
model_fit = model.fit()# 预测
predictions = model_fit.predict(start=len(data), end=len(data)+5, typ='levels')
print(predictions)3. 机器学习在时间序列预测中的应用
传统时间序列方法虽然有效,但机器学习方法能够捕捉更复杂的模式,并且可以方便地整合外部特征。
3.1 特征工程
时间序列预测的关键是构建合适的特征。常用的特征包括:
8.1 未来方向
-
滞后特征(Lagged features)
-
滑动窗口统计量(滚动均值、滚动标准差等)
-
时间特征(小时、星期几、月份等)
-
傅里叶变换特征
-
目标变量的历史统计量
import pandas as pddef create_features(df, target, lags=5, window_sizes=[3, 7]):"""为时间序列数据创建特征参数:df -- 包含时间序列的DataFrametarget -- 目标列名lags -- 滞后阶数window_sizes -- 滑动窗口大小列表返回:包含特征的DataFrame"""df = df.copy()# 创建滞后特征for lag in range(1, lags+1):df[f'lag_{lag}'] = df[target].shift(lag)# 创建滑动窗口统计量for window in window_sizes:df[f'rolling_mean_{window}'] = df[target].rolling(window=window).mean()df[f'rolling_std_{window}'] = df[target].rolling(window=window).std()df[f'rolling_min_{window}'] = df[target].rolling(window=window).min()df[f'rolling_max_{window}'] = df[target].rolling(window=window).max()# 创建时间特征if 'date' in df.columns:df['date'] = pd.to_datetime(df['date'])df['day_of_week'] = df['date'].dt.dayofweekdf['day_of_month'] = df['date'].dt.daydf['month'] = df['date'].dt.monthdf['year'] = df['date'].dt.year# 删除包含NaN的行df = df.dropna()return df3.2 常用机器学习模型
3.2.1 线性回归
from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error# 加载数据 (这里使用示例数据) dates = pd.date_range(start='2020-01-01', periods=100) values = np.random.normal(loc=0, scale=1, size=100).cumsum() + 100 df = pd.DataFrame({'date': dates, 'value': values})# 创建特征 df = create_features(df, target='value', lags=5, window_sizes=[3, 7])# 划分特征和目标 X = df.drop(['value', 'date'], axis=1, errors='ignore') y = df['value']# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)# 训练模型 model = LinearRegression() model.fit(X_train, y_train)# 预测 y_pred = model.predict(X_test)# 评估 mse = mean_squared_error(y_test, y_pred) print(f"Mean Squared Error: {mse:.4f}")3.2.2 随机森林
from sklearn.ensemble import RandomForestRegressor# 训练模型 model = RandomForestRegressor(n_estimators=100, random_state=42) model.fit(X_train, y_train)# 预测 y_pred = model.predict(X_test)# 评估 mse = mean_squared_error(y_test, y_pred) print(f"Mean Squared Error: {mse:.4f}")# 特征重要性 importances = model.feature_importances_ features = X.columns feature_importance = pd.DataFrame({'feature': features, 'importance': importances}) feature_importance = feature_importance.sort_values('importance', ascending=False) print(feature_importance)3.2.3 梯度提升树(XGBoost)
import xgboost as xgb# 训练模型 model = xgb.XGBRegressor(objective='reg:squarederror', n_estimators=100, random_state=42) model.fit(X_train, y_train)# 预测 y_pred = model.predict(X_test)# 评估 mse = mean_squared_error(y_test, y_pred) print(f"Mean Squared Error: {mse:.4f}")# 特征重要性 xgb.plot_importance(model)4. 深度学习在时间序列预测中的应用
深度学习模型特别适合处理时间序列数据,因为它们能够自动学习时间依赖关系。
4.1 循环神经网络(RNN)
python
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import SimpleRNN, Dense from sklearn.preprocessing import MinMaxScaler# 数据准备 scaler = MinMaxScaler() scaled_data = scaler.fit_transform(df[['value']])# 创建时间序列数据集 def create_dataset(data, time_steps=1):X, y = [], []for i in range(len(data)-time_steps):X.append(data[i:(i+time_steps), 0])y.append(data[i+time_steps, 0])return np.array(X), np.array(y)time_steps = 5 X, y = create_dataset(scaled_data, time_steps)# 划分训练集和测试集 train_size = int(len(X) * 0.8) X_train, X_test = X[:train_size], X[train_size:] y_train, y_test = y[:train_size], y[train_size:]# 重塑输入为 [样本数, 时间步长, 特征数] X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1) X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)# 构建RNN模型 model = Sequential([SimpleRNN(50, activation='relu', input_shape=(time_steps, 1)),Dense(1) ])model.compile(optimizer='adam', loss='mse')# 训练模型 history = model.fit(X_train, y_train,epochs=50,batch_size=16,validation_split=0.1,verbose=1 )# 预测 y_pred = model.predict(X_test)# 反归一化 y_test_inv = scaler.inverse_transform(y_test.reshape(-1, 1)) y_pred_inv = scaler.inverse_transform(y_pred)# 评估 mse = mean_squared_error(y_test_inv, y_pred_inv) print(f"Mean Squared Error: {mse:.4f}")4.2 长短期记忆网络(LSTM)
LSTM是RNN的一种改进,能够更好地捕捉长期依赖关系。
from tensorflow.keras.layers import LSTM# 构建LSTM模型 model = Sequential([LSTM(50, activation='relu', input_shape=(time_steps, 1)),Dense(1) ])model.compile(optimizer='adam', loss='mse')# 训练模型 history = model.fit(X_train, y_train,epochs=50,batch_size=16,validation_split=0.1,verbose=1 )# 预测 y_pred = model.predict(X_test)# 反归一化 y_pred_inv = scaler.inverse_transform(y_pred)# 评估 mse = mean_squared_error(y_test_inv, y_pred_inv) print(f"Mean Squared Error: {mse:.4f}")4.3 编码器-解码器架构
对于多步预测任务,编码器-解码器架构特别有效。
from tensorflow.keras.layers import RepeatVector, TimeDistributed# 多步预测数据准备 def create_multi_step_dataset(data, input_steps, output_steps):X, y = [], []for i in range(len(data)-input_steps-output_steps+1):X.append(data[i:(i+input_steps), 0])y.append(data[(i+input_steps):(i+input_steps+output_steps), 0])return np.array(X), np.array(y)input_steps = 10 output_steps = 3 X, y = create_multi_step_dataset(scaled_data, input_steps, output_steps)# 划分训练集和测试集 train_size = int(len(X) * 0.8) X_train, X_test = X[:train_size], X[train_size:] y_train, y_test = y[:train_size], y[train_size:]# 重塑输入 X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1) X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1) y_train = y_train.reshape(y_train.shape[0], y_train.shape[1], 1) y_test = y_test.reshape(y_test.shape[0], y_test.shape[1], 1)# 构建编码器-解码器模型 model = Sequential([LSTM(100, activation='relu', input_shape=(input_steps, 1)),RepeatVector(output_steps),LSTM(100, activation='relu', return_sequences=True),TimeDistributed(Dense(1)) ])model.compile(optimizer='adam', loss='mse')# 训练模型 history = model.fit(X_train, y_train,epochs=100,batch_size=32,validation_split=0.1,verbose=1 )# 预测 y_pred = model.predict(X_test)# 反归一化 y_test_inv = scaler.inverse_transform(y_test.reshape(-1, output_steps)) y_pred_inv = scaler.inverse_transform(y_pred.reshape(-1, output_steps))# 评估第一个预测步的MSE mse = mean_squared_error(y_test_inv[:, 0], y_pred_inv[:, 0]) print(f"Mean Squared Error (first step): {mse:.4f}")5. 时间序列预测的评估方法
评估时间序列预测模型需要考虑时间依赖性,不能简单地使用随机划分的交叉验证。
5.1 时间序列交叉验证
from sklearn.model_selection import TimeSeriesSplittscv = TimeSeriesSplit(n_splits=5)model = xgb.XGBRegressor(objective='reg:squarederror', n_estimators=100)for train_index, test_index in tscv.split(X):X_train, X_test = X.iloc[train_index], X.iloc[test_index]y_train, y_test = y.iloc[train_index], y.iloc[test_index]model.fit(X_train, y_train)y_pred = model.predict(X_test)mse = mean_squared_error(y_test, y_pred)print(f"Fold MSE: {mse:.4f}")5.2 常用评估指标
-
均方误差(MSE)
-
均方根误差(RMSE)
-
平均绝对误差(MAE)
-
平均绝对百分比误差(MAPE)
-
对称平均绝对百分比误差(sMAPE)
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_errordef smape(y_true, y_pred):return 100/len(y_true) * np.sum(2 * np.abs(y_pred - y_true) / (np.abs(y_true) + np.abs(y_pred)))def evaluate_forecast(y_true, y_pred):mse = mean_squared_error(y_true, y_pred)rmse = np.sqrt(mse)mae = mean_absolute_error(y_true, y_pred)mape = mean_absolute_percentage_error(y_true, y_pred)smape_val = smape(y_true, y_pred)print(f"MSE: {mse:.4f}")print(f"RMSE: {rmse:.4f}")print(f"MAE: {mae:.4f}")print(f"MAPE: {mape:.4%}")print(f"sMAPE: {smape_val:.4%}")evaluate_forecast(y_test, y_pred)6. 实战案例:电力负荷预测
让我们用一个真实案例来综合应用所学知识。我们将使用UCI的电力负荷数据集。
6.1 数据准备
# 下载数据集 url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00374/energydata_complete.csv" df = pd.read_csv(url)# 解析日期 df['date'] = pd.to_datetime(df['date']) df = df.set_index('date').sort_index()# 选择目标变量 - 应用电器能耗 target = 'Appliances' y = df[target]# 可视化 y.plot(figsize=(12, 6), title='Appliances Energy Use') plt.ylabel('Energy (Wh)') plt.show()6.2 特征工程
# 创建时间特征 df['hour'] = df.index.hour df['day_of_week'] = df.index.dayofweek df['month'] = df.index.month# 创建滞后特征 for lag in [1, 2, 3, 24, 48]:df[f'lag_{lag}'] = y.shift(lag)# 创建滑动窗口特征 for window in [3, 6, 12, 24]:df[f'rolling_mean_{window}'] = y.rolling(window=window).mean()df[f'rolling_std_{window}'] = y.rolling(window=window).std()# 删除包含NaN的行 df = df.dropna()# 分离特征和目标 X = df.drop(target, axis=1) y = df[target]# 划分训练集和测试集 split_date = '2016-05-20' X_train = X[X.index <= split_date] X_test = X[X.index > split_date] y_train = y[y.index <= split_date] y_test = y[y.index > split_date]# 标准化 scaler_X = MinMaxScaler() X_train_scaled = scaler_X.fit_transform(X_train) X_test_scaled = scaler_X.transform(X_test)scaler_y = MinMaxScaler() y_train_scaled = scaler_y.fit_transform(y_train.values.reshape(-1, 1)) y_test_scaled = scaler_y.transform(y_test.values.reshape(-1, 1))6.3 构建LSTM模型
# 重塑数据为LSTM需要的格式 [样本数, 时间步长, 特征数] # 这里我们使用1个时间步长,但可以尝试更多 X_train_reshaped = X_train_scaled.reshape(X_train_scaled.shape[0], 1, X_train_scaled.shape[1]) X_test_reshaped = X_test_scaled.reshape(X_test_scaled.shape[0], 1, X_test_scaled.shape[1])# 构建模型 model = Sequential([LSTM(64, activation='relu', input_shape=(1, X_train_reshaped.shape[2])),Dense(1) ])model.compile(optimizer='adam', loss='mse')# 训练模型 history = model.fit(X_train_reshaped, y_train_scaled,epochs=50,batch_size=64,validation_split=0.1,verbose=1 )# 预测 y_pred_scaled = model.predict(X_test_reshaped) y_pred = scaler_y.inverse_transform(y_pred_scaled)# 评估 evaluate_forecast(y_test, y_pred.flatten())# 可视化部分结果 plt.figure(figsize=(12, 6)) plt.plot(y_test.index[:200], y_test.values[:200], label='Actual') plt.plot(y_test.index[:200], y_pred[:200], label='Predicted') plt.legend() plt.title('Appliances Energy Use - Actual vs Predicted') plt.ylabel('Energy (Wh)') plt.show()6.4 模型优化
我们可以尝试以下优化方法:
-
调整网络结构(增加层数、改变单元数)
-
添加Dropout层防止过拟合
-
使用更复杂的架构(如注意力机制)
-
调整学习率和批量大小
-
增加训练轮次
from tensorflow.keras.layers import Dropout from tensorflow.keras.callbacks import EarlyStopping# 构建更复杂的模型 model = Sequential([LSTM(128, activation='relu', return_sequences=True, input_shape=(1, X_train_reshaped.shape[2])),Dropout(0.2),LSTM(64, activation='relu'),Dropout(0.2),Dense(1) ])model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='mse')# 早停法 early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)# 训练模型 history = model.fit(X_train_reshaped, y_train_scaled,epochs=100,batch_size=64,validation_split=0.1,callbacks=[early_stopping],verbose=1 )# 预测和评估 y_pred_scaled = model.predict(X_test_reshaped) y_pred = scaler_y.inverse_transform(y_pred_scaled) evaluate_forecast(y_test, y_pred.flatten())7. 高级主题
7.1 多变量时间序列预测
当有多个相关的时间序列时,可以利用它们之间的关系来改进预测。
# 选择多个相关特征 features = ['Appliances', 'T1', 'RH_1', 'T_out', 'RH_out', 'Windspeed'] df_multi = df[features].copy()# 创建滞后特征 for feature in features:for lag in [1, 2, 3, 24]:df_multi[f'{feature}_lag_{lag}'] = df_multi[feature].shift(lag)df_multi = df_multi.dropna()# 分离特征和目标 X = df_multi.drop('Appliances', axis=1) y = df_multi['Appliances']# 划分训练集和测试集 X_train = X[X.index <= split_date] X_test = X[X.index > split_date] y_train = y[y.index <= split_date] y_test = y[y.index > split_date]# 标准化 scaler_X = MinMaxScaler() X_train_scaled = scaler_X.fit_transform(X_train) X_test_scaled = scaler_X.transform(X_test)scaler_y = MinMaxScaler() y_train_scaled = scaler_y.fit_transform(y_train.values.reshape(-1, 1)) y_test_scaled = scaler_y.transform(y_test.values.reshape(-1, 1))# 重塑数据 X_train_reshaped = X_train_scaled.reshape(X_train_scaled.shape[0], 1, X_train_scaled.shape[1]) X_test_reshaped = X_test_scaled.reshape(X_test_scaled.shape[0], 1, X_test_scaled.shape[1])# 构建模型 model = Sequential([LSTM(128, activation='relu', input_shape=(1, X_train_reshaped.shape[2])),Dense(1) ])model.compile(optimizer='adam', loss='mse')# 训练模型 history = model.fit(X_train_reshaped, y_train_scaled,epochs=50,batch_size=64,validation_split=0.1,verbose=1 )# 预测和评估 y_pred_scaled = model.predict(X_test_reshaped) y_pred = scaler_y.inverse_transform(y_pred_scaled) evaluate_forecast(y_test, y_pred.flatten())7.2 概率预测
有时我们不仅需要点预测,还需要预测的置信区间。
from tensorflow.keras.layers import Input, Dense, Lambda import tensorflow_probability as tfp# 构建概率模型 def negative_loglikelihood(y_true, y_pred_dist):return -y_pred_dist.log_prob(y_true)input_shape = (1, X_train_reshaped.shape[2]) inputs = Input(shape=input_shape) lstm_out = LSTM(64, activation='relu')(inputs)# 输出分布参数 mu = Dense(1)(lstm_out) sigma = Dense(1, activation='softplus')(lstm_out) # sigma必须为正# 创建正态分布 output_dist = tfp.layers.DistributionLambda(lambda t: tfp.distributions.Normal(loc=t[0], scale=t[1]) )([mu, sigma])model = tf.keras.Model(inputs=inputs, outputs=output_dist) model.compile(optimizer='adam', loss=negative_loglikelihood)# 训练模型 history = model.fit(X_train_reshaped, y_train_scaled,epochs=50,batch_size=64,validation_split=0.1,verbose=1 )# 预测 y_pred_dist = model(X_test_reshaped) y_pred_mean = y_pred_dist.mean().numpy().flatten() y_pred_std = y_pred_dist.stddev().numpy().flatten()# 反归一化 y_pred_mean = scaler_y.inverse_transform(y_pred_mean.reshape(-1, 1)).flatten() y_pred_std = scaler_y.scale_ * y_pred_std# 可视化置信区间 plt.figure(figsize=(12, 6)) plt.plot(y_test.index[:100], y_test.values[:100], label='Actual') plt.plot(y_test.index[:100], y_pred_mean[:100], label='Predicted Mean') plt.fill_between(y_test.index[:100],y_pred_mean[:100] - 1.96*y_pred_std[:100],y_pred_mean[:100] + 1.96*y_pred_std[:100],alpha=0.2, label='95% Confidence Interval' ) plt.legend() plt.title('Probabilistic Forecast') plt.ylabel('Energy (Wh)') plt.show()8. 总结与最佳实践
时间序列预测是一个复杂但极具价值的领域。以下是本文的关键要点和最佳实践:
-
理解数据:在建模前充分分析数据的趋势、季节性和其他特征
-
特征工程:创建有意义的特征(滞后、滑动窗口、时间特征等)
-
Transformer模型:在时间序列预测中的应用
-
元学习:学习如何快速适应新的时间序列模式
-
解释性:提高时间序列预测模型的可解释性
-
实时预测:低延迟的在线学习系统
-
模型选择:
-
对于简单问题,传统方法(ARIMA)可能足够
-
对于复杂模式,机器学习方法通常表现更好
-
深度学习适合大规模数据和复杂时间依赖关系
-
-
评估方法:使用时间序列交叉验证,选择合适的评估指标
-
模型优化:调整超参数,防止过拟合,考虑概率预测
-
持续监控:在实际应用中持续监控模型性能
-
相关文章:

时间序列预测的机器学习方法:从基础到实战
时间序列预测是机器学习中一个重要且实用的领域,广泛应用于金融、气象、销售预测、资源规划等多个行业。本文将全面介绍时间序列预测的基本概念、常用方法,并通过Python代码示例展示如何构建和评估时间序列预测模型。 1. 时间序列预测概述 时间序列是按…...
01-VMware16虚拟机详细安装
官网地址:https://www.vmware.com/cn.html 1.1 打开下载好的 .exe 文件, 双击安装。 1.2 点击下一步 1.3 先勾选我接受许可协议中的条款,然后点击下一步 1.4 自定义安装路径,注意这里的文件路径尽量不要包含中文,完成…...
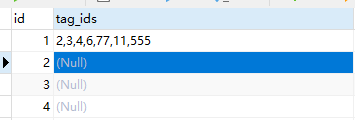
sql列中数据通过逗号分割的集合,按需求剔除部分值
前置 不会REGEXP 方法的需要在这里学习一下下 记sql字段逗号分隔,通过list查询 功能点 现有一个表格中一列存储的是标签的集合,通过逗号分割 入下: 其中tag_ids是逗号分割的标签,现在需要删除标签组中的一些标签,因…...

下一代设备健康管理解决方案:基于多源异构数据融合的智能运维架构
导语: 在工业4.0深度演进的关键节点,传统设备管理面临数据孤岛、误诊率高、运维滞后三大致命瓶颈。本文解析基于边缘智能与数字孪生的新一代解决方案架构,并实测验证中讯烛龙PHM-X系统如何通过多模态感知→智能诊断→自主决策闭环,…...

unipp---HarmonyOS 应用开发实战
HarmonyOS 应用开发实战指南 1. 开篇:为什么选择 HarmonyOS? 最近在开发鸿蒙应用时,发现很多开发者都在问:为什么要选择 HarmonyOS?这里分享一下我的看法: 生态优势 华为手机用户基数大,市场潜…...

Go 语言中switch case条件分支语句
1. 基本语法 package main import "fmt" func main() {var extname ".css"switch extname {case ".html":fmt.Println("text/html")case ".css":fmt.Println("text/css") // text/csscase ".js":fmt.…...

ai流式文字返回前端和php的处理办法
PHP后端 php端主要是用到ob_flush和flush,头改为流式。 基本代码 代码如下: <?php header(Content-Type:text/event-stream); header(Cache-Control:no-cache); header(Connection:keep-alive);function streamPostRequest($url,$data){$chcurl_…...
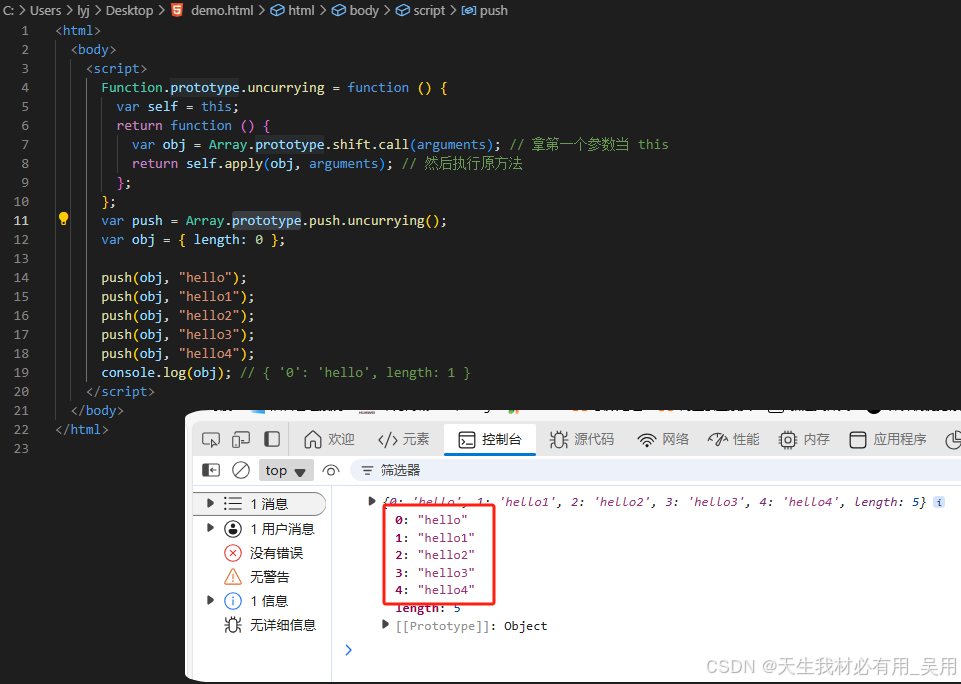
深入理解JavaScript设计模式之闭包与高阶函数
目录 前言小序一场失败面试面试后的觉醒 闭包变量作用域:谁的地盘听谁的变量的生命周期:该走了,不该走的还在闭包的更多作用:不只是谈恋爱,还能干活!1、封装私有变量:你的变量我来守护2、延长变…...
)
【Unity】R3 CSharp 响应式编程 - 使用篇(二)
一、通用的事件监听用法 using System;using R3;using UnityEngine;namespace Aladdin.Standard.Observable.Common{public class CommonObservable : MonoBehaviour{// 默认会调用1次public SerializableReactiveProperty<int> serializableReactiveProperty;…...

springboot启动mapper找不到方法对应的xml
数据源配置 目录结构 idea中mapper.java 可以找到对应的mapper.xml文件 启动却找不到 因为mapper.db1会被识别为文件名 而非目录结构 调整为这种...

MQTT协议:物联网时代的通信基石
MQTT协议:物联网时代的通信基石 在当今快速发展的物联网(IoT)时代,设备之间的通信变得尤为重要。MQTT(Message Queuing Telemetry Transport)协议作为一种轻量级的消息传输协议,正逐渐成为物联…...

vite ts 配置使用@ 允许js
1.vite.config.ts 配置 import { defineConfig } from vite import vue from vitejs/plugin-vue import { fileURLToPath, URL } from node:url import setup_extend from vite-plugin-vue-setup-extend// https://vite.dev/config/ export default defineConfig({plugins: …...
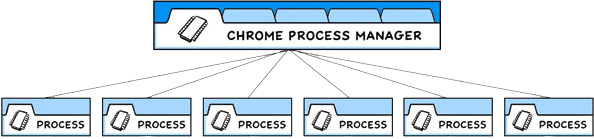
Electron通信流程
前言 今天讲Electron框架的通信流程,首先我们需要知道为什么需要通信。这得益于Electron的多进程模型,它主要模仿chrome的多进程模型如下图: 作为应用开发者,我们将控制两种类型的进程:主进程和渲染器进程 。 …...
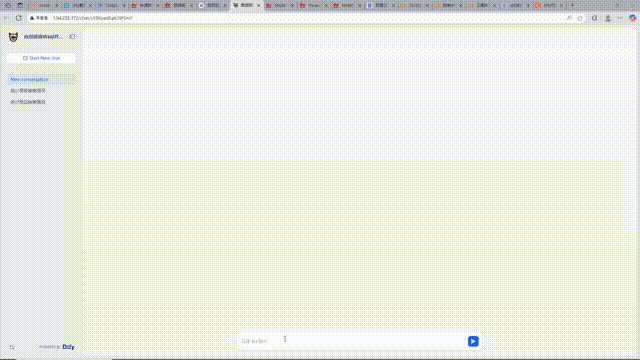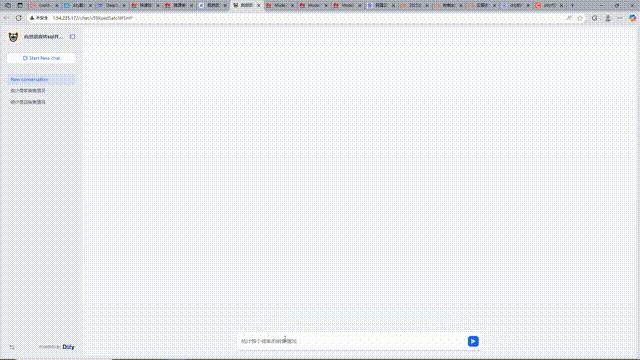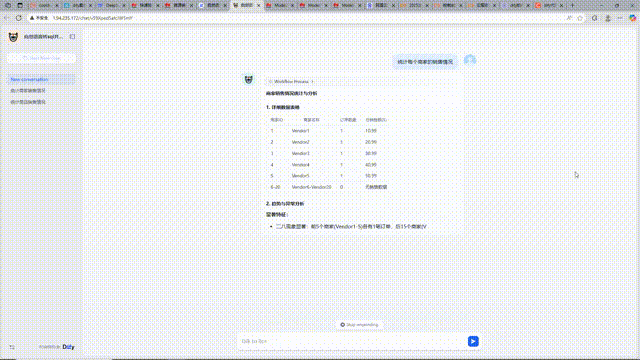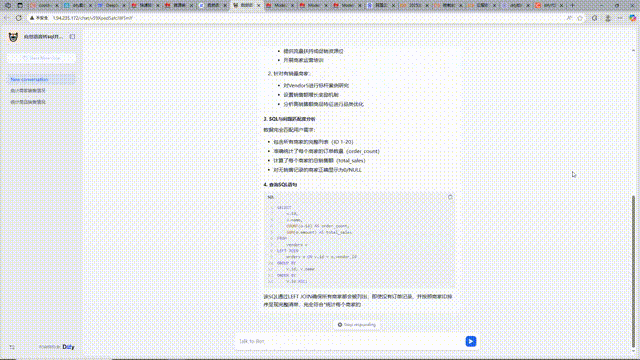
华为云Flexus+DeepSeek征文|华为云Flexus服务器dify平台通过自然语言转sql并执行实现电商数据分析
目录 前言 1 华为云Flexus服务器部署Dify平台 1.1 华为云Flexus服务器一键部署Dify平台 1.2 设置账号登录Dify,进入平台 2 构建自然语言转SQL并执行的应用 2.1 创建应用并启动工作流设计 2.2 应用框架设计 2.3 自然语言转SQL模块详解 2.4 代码执行模块实现…...
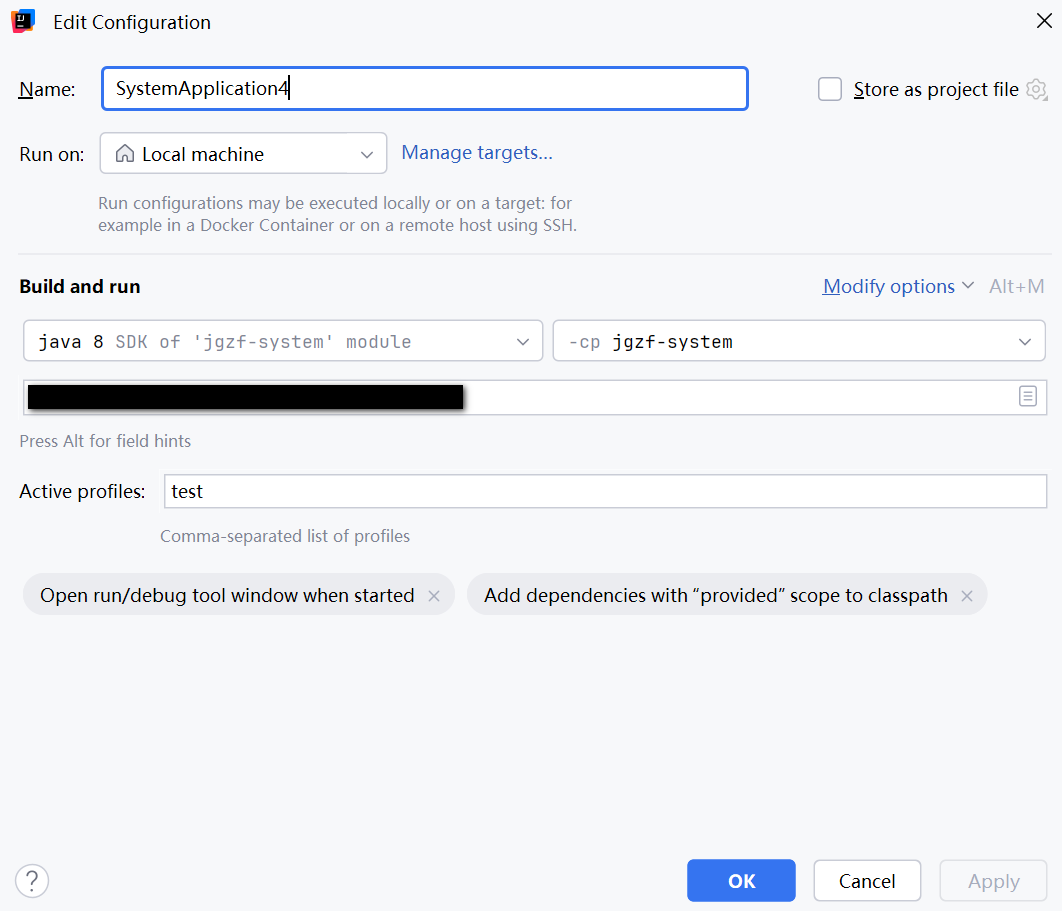
IDEA中微服务指定端口启动
在使用IDEA开发SpringBoot微服务时,经常需要开启多个服务实例以测试负载均衡,以下几种方法开启不同端口。 直接在配置文件中指定 # application.propertiesserver.port8001指定VM参数 点击Modify options,选择Add VM options,值…...
BERT, GPT, Transformer之间的关系
1. Transformer 是什么?简单介绍 1.1 通俗理解 想象你是一个翻译员,要把一句话从中文翻译成英文。你需要同时看句子里的每个词,理解它们之间的关系。Transformer就像一个超级翻译助手,它用“自注意力机制”(Attentio…...
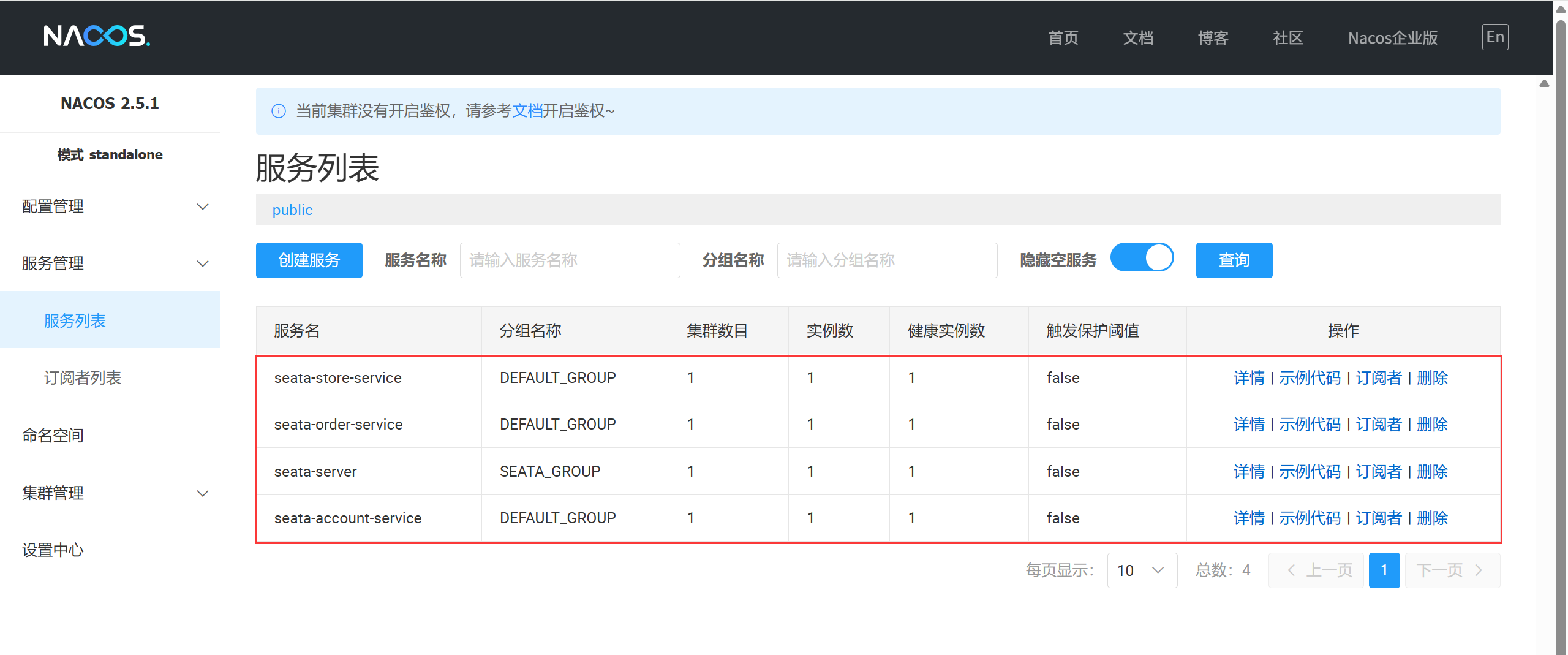
Spring Cloud Alibaba Seata安装+微服务实战
目录 介绍核心功能三层核心架构安装微服务实战创建三个业务数据库编写库存和账户两个Feign接口订单微服务 seata-order-service9701库存微服务 seata-store-service9702账户微服务 seata-account-service9703测试结果 总结 介绍 Spring Cloud Alibaba Seata 是一款开源的分布式…...

FMC STM32H7 SDRAM
如何无痛使用片外SDRAM? stm32 已经成功初始化了 STM32H7 上的外部 SDRAM(32MB) 如何在开发中无痛使用SDRAM 使它像普通 RAM 一样“自然地”使用? [todo] 重要 MMT(Memory Management Tool) of STM32CubeMx The Memory Management Tool (MMT) disp…...

部署DNS从服务器
部署DNS从服务器的目的 DNS域名解析服务中,从服务器可以从主服务器上获得指定的区域数据文件,从而起到备份解析记录与负载均衡的作用,因此通过部署从服务器可以减轻主服务器的负载压力,还可以提升用户的查询效率。 注意…...
)
Ubuntu 系统.sh脚本一键部署内网Java服务(组件使用docker镜像,宕机自启动)
#!/bin/bash# 更新系统并安装必要的依赖 sudo apt update sudo apt install -y apt-transport-https ca-certificates curl software-properties-common# 安装 Docker curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo add-apt-repository …...

用 n8n 提取静态网页内容:从 HTTP Request 到 HTML 节点全解析
n8n 的 HTTP Request HTML 节点组合是个实用又高效的工具。这篇文章就带你一步步搞懂如何用它们提取静态网页内容,重点解析 HTML 节点参数和 CSS 选择器,让你轻松上手 。 一、整体流程概览 我们的目标是从静态网页中提取特定内容,流程分两…...

Android Camera Hal中通过Neon指令优化数据拷贝
背景描述: Camera apk普通相机模式录像操作时,一般是同时请求两个流,即预览流和录像流。对于两个流输出图像格式和分辨率相同的情况下,是不是可以通过一个流拷贝得到另一个流的数据,进而节省掉一个Sensor输出处理两次…...
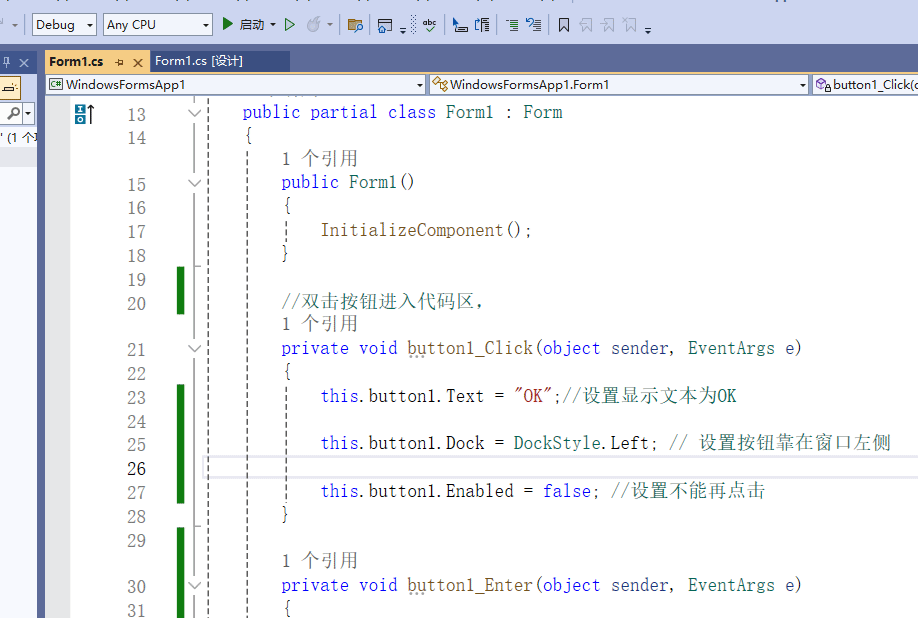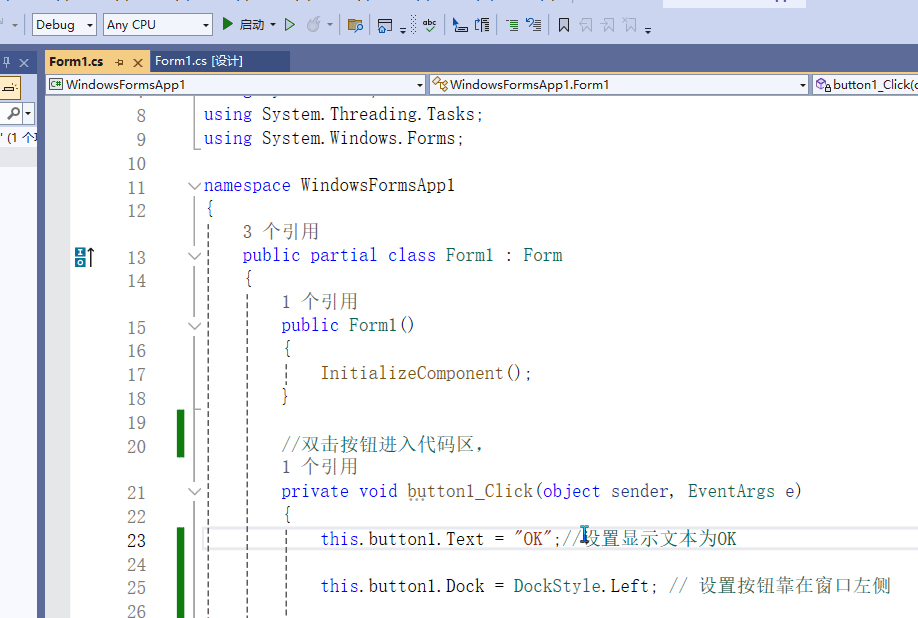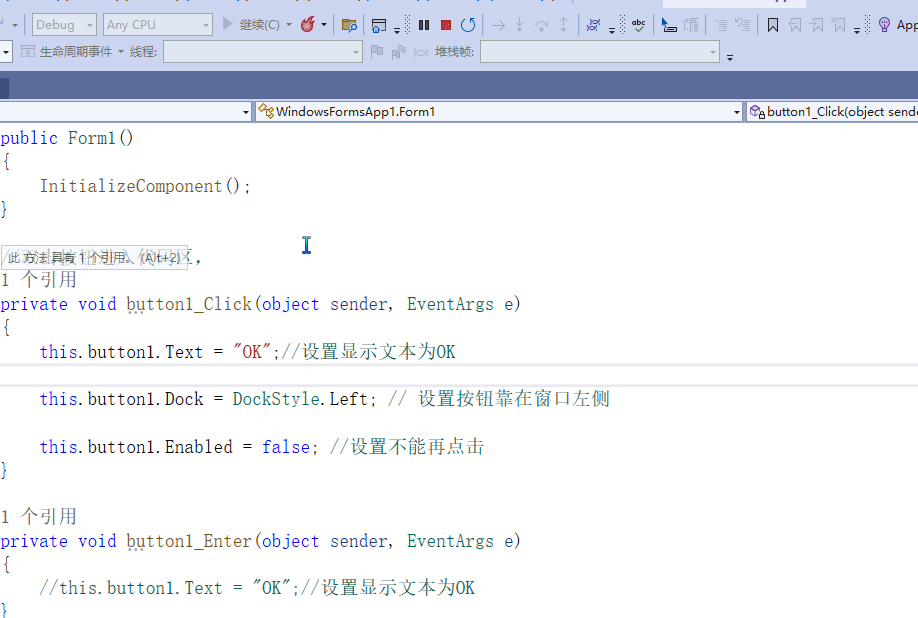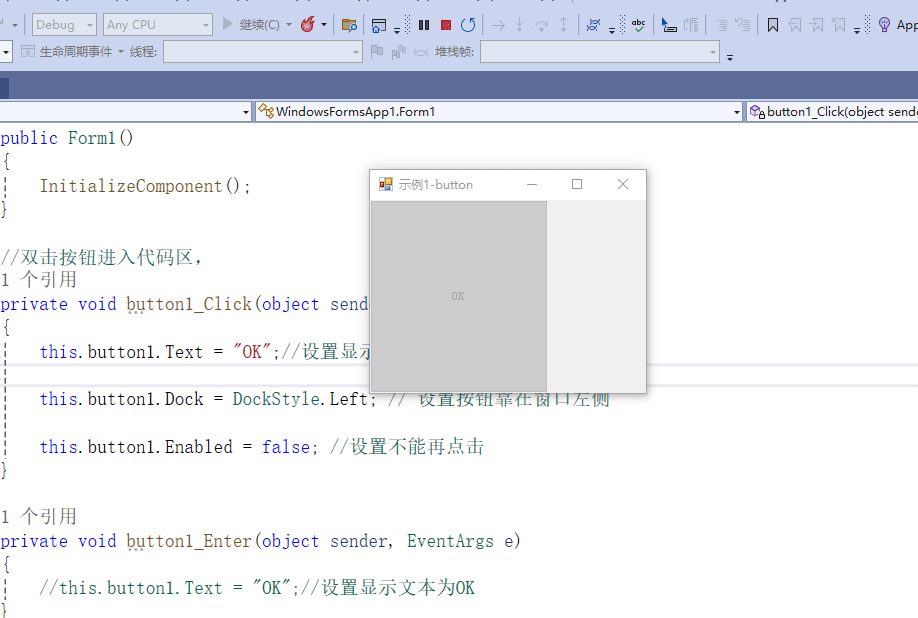
C# winform教程(二)----button
一、button的使用方法 主要使用方法几乎都在属性内,我们操作也在这个界面 二、作用 用户点击时触发事件,事件有很多种,可以根据需要选择。 三、常用属性 虽然属性很多,但是常用的并不多 3.常用属性 名称内容含义AutoSize自动调…...

AcWing 3417:砝码称重——位集合
【题目来源】 3417. 砝码称重 - AcWing题库 【题目描述】 你有一架天平和 N 个砝码,这 N 个砝码重量依次是 W1,W2,⋅⋅⋅,WN。 请你计算一共可以称出多少种不同的正整数重量? 注意砝码可以放在天平两边。 【输入格式】 输入的第一行包含一个整数 N。 …...

我认为STM32输入只分为模拟输入 与 数字输入
核心概念解析 模拟输入 (Analog Input) 设计目的:直接连接模拟信号(如ADC采集电压、温度传感器输出) 硬件行为: ✅ 断开内部数字电路(施密特触发器禁用) ✅ 信号直通模拟外设(如ADC、运放&…...

Python编码格式化之PEP8编码规范
文章目录 概要PEP8编码风格py文本组织规范命名规范编码风格 PEP8编码检查工具pylintflake8PyCharm中配置检查工具 PEP8编码格式化工具blackautopep8PyCharm配置格式化工具本地git配置hook 总结 概要 在Python项目开发过程中,代码的可读性和一致性对于项目的长期维护…...
【Zephyr 系列 14】使用 MCUboot 实现 BLE OTA 升级机制:构建安全可靠的固件分发系统
🧠关键词:Zephyr、MCUboot、OTA 升级、BLE DFU、双分区、Bootloader、安全固件管理 📌面向读者:希望基于 Zephyr 为 BLE 设备加入安全 OTA 升级功能的开发者 📊预计字数:5200+ 字 🧭 前言:为什么你需要 OTA? 随着设备部署数量增多与产品生命周期延长,远程升级(…...

K8S认证|CKS题库+答案| 8. 沙箱运行容器 gVisor
目录 8. 沙箱运行容器 gVisor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、官网找模板 3)、创建 RuntimeClass 4)、 将命名空间为 server 下的 Pod 引用 RuntimeClass 5)…...

【Redis】数据库与缓存一致性
目录 1、背景2、核心问题3、常见解决方案【1】缓存更新策略[1]旁路缓存模式(Cache-Aside)[2]写穿透模式(Write-Through)[3]写回模式 【2】删除与更新策略[1]先更新数据库再删除缓存[2]先删除缓存再更新数据库 【3】一致性保障机制…...
Selenium4+Python的web自动化测试框架
一、什么是Selenium? Selenium是一个基于浏览器的自动化测试工具,它提供了一种跨平台、跨浏览器的端到端的web自动化解决方案。Selenium主要包括三部分:Selenium IDE、Selenium WebDriver 和Selenium Grid。 Selenium IDE:Firefo…...