Steam爬取相关游戏评测
## 因为是第一次爬取Steam。所以作为一次记录发出;有所错误欢迎指出。
无时间指定爬取
import requests
import time
import csv
import osappid = "553850"
# 这里你也可以改成
#appid = int(input()) max_reviews = 10000 # 想爬多少条
# max_reviews = int(input("请输入你想读取的个数(要为10的倍数)"))
batch_size = 100 # 每页请求条数cursor_file = "cursor.txt" # 游标保存文件
data_file = "helldivers_reviews.csv" # 数据保存文件
// 数据保存文件可以改成你要想要的名字,我这个是csv# 读取上次保存的游标,没有则用起始游标 *
def load_cursor():if os.path.exists(cursor_file):with open(cursor_file, "r", encoding="utf-8") as f:cursor = f.read().strip()if cursor:return cursorreturn "*"# 保存游标到文件
def save_cursor(cursor):with open(cursor_file, "w", encoding="utf-8") as f:f.write(cursor)# 保存数据到CSV,追加模式
def save_reviews(reviews):file_exists = os.path.exists(data_file)with open(data_file, "a", encoding="utf-8-sig", newline="") as f:writer = csv.writer(f)if not file_exists:writer.writerow(["username", "recommend", "hours", "comment", "votes_up", "votes_funny"])for r in reviews:writer.writerow([r.get("author", {}).get("steamid", ""),r.get("voted_up"),r.get("author", {}).get("playtime_forever", 0)/60, # 游戏时长(小时)r.get("review"),r.get("votes_up"),r.get("votes_funny")])# 请求一页评论
def fetch_reviews(appid, cursor):url = f"https://store.steampowered.com/appreviews/{appid}"params = {"json": "1","filter": "recent","language": "all","day_range": "30","review_type": "all","purchase_type": "all","cursor": cursor,"num_per_page": batch_size,}headers = {"User-Agent": "Mozilla/5.0"}proxies = {"http": "http://127.0.0.1:7890","https": "http://127.0.0.1:7890"}try:resp = requests.get(url, params=params, headers=headers,proxies=proxies, timeout=10)resp.raise_for_status()data = resp.json()return dataexcept Exception as e:print("请求失败:", e)return Nonedef main():cursor = load_cursor()total_reviews = 0print(f"开始爬取,起始游标: {cursor}")while total_reviews < max_reviews:data = fetch_reviews(appid, cursor)if not data:print("请求失败,等待后重试...")time.sleep(5)continuereviews = data.get("reviews", [])if not reviews:print("没有更多评论了,爬取结束。")breaksave_reviews(reviews)total_reviews += len(reviews)print(f"已爬取 {total_reviews} 条评论")cursor = data.get("cursor")if not cursor:print("无游标,爬取结束。")breaksave_cursor(cursor) # 保存游标,断点续爬关键time.sleep(1) # 防止请求过快print(f"爬取完成,总共爬取 {total_reviews} 条评论")if __name__ == "__main__":main()
这里有一些提示。
第一点: 对于appid 这个
你要爬的游戏ID 在SteamDB查看 或者是https://store.steampowered.com/app/553850/HELLDIVERS_2/ 那个数字就是appid
第二点,我这个是使用的记录上一次的保存游标不断联读取。 什么意思呢,对于Steam爬取,你可能爬取到一半,对方服务器就给你断连了;那么你就需要重新连接读取,而每次的读取都其实是从上次断开连接的地方开始,而不是从头再来。
第三点,因为是爬取Steam,这种国外平台,你没有外部代理的话是访问不了的,所以得要点魔法。地址呢就是填入代理的地址
proxies = {"http": "http://127.0.0.1:7890","https": "http://127.0.0.1:7890"}例如我这样,7890是我的代理的端口号,实测了一下,Steam++也是可以使用它这个空闲端口的,本来Steam++是448默认端口,但是这个也可以照样使用。
记得是加入request.(xxxx,xxxx,proxies=proxies),不然你是连接不上的。
最后,这个代码是从今天往以前的代码进行爬取,也就是说你如果没有时间要求的话,就不用管太多,如果有的话,就参考我下面的代码。
指定时间段爬取
import requests
import time
import csv
import os
from datetime import datetimeappid = "553850" #游戏appid
batch_size = 100 #每页请求条数
max_reviews_per_lang = 20000 #最大爬取个数cursor_files = {"english": "cursor_english.txt","schinese": "cursor_schinese.txt",
}data_files = {"english": "reviews_english.csv","schinese": "reviews_schinese.csv",
}// 这里我增加了分语言爬取# 时间范围(转为时间戳)
start_date = datetime.strptime("2025-05-20", "%Y-%m-%d")
end_date = datetime.strptime("2025-06-05", "%Y-%m-%d")
start_ts = int(start_date.timestamp())
end_ts = int(end_date.timestamp())def load_cursor(lang):f = cursor_files[lang]if os.path.exists(f):with open(f, "r", encoding="utf-8") as file:cur = file.read().strip()if cur:return curreturn "*"def save_cursor(lang, cursor):f = cursor_files[lang]with open(f, "w", encoding="utf-8") as file:file.write(cursor)def save_reviews(lang, reviews):f = data_files[lang]file_exists = os.path.exists(f)with open(f, "a", encoding="utf-8-sig", newline="") as file:writer = csv.writer(file)if not file_exists:writer.writerow(["username", "recommend", "hours", "comment", "votes_up", "votes_funny", "timestamp"])for r in reviews:ts = r.get("timestamp_created", 0)# 时间过滤,只保存目标时间范围内的评论if ts < start_ts or ts > end_ts:continuewriter.writerow([r.get("author", {}).get("steamid", ""),r.get("voted_up"),r.get("author", {}).get("playtime_forever", 0)/60,r.get("review"),r.get("votes_up"),r.get("votes_funny"),datetime.fromtimestamp(ts).strftime("%Y-%m-%d %H:%M:%S")])def fetch_reviews(appid, cursor, lang):url = f"https://store.steampowered.com/appreviews/{appid}"params = {"json": "1","filter": "recent","language": lang,"day_range": "16", # 取最近30天评论,保证覆盖目标时间段"review_type": "all","purchase_type": "all","cursor": cursor,"num_per_page": batch_size,}headers = {"User-Agent": "Mozilla/5.0"}proxies = {"http": "http://127.0.0.1:7890","https": "http://127.0.0.1:7890"}try:resp = requests.get(url, params=params, headers=headers,proxies=proxies, timeout=10)resp.raise_for_status()return resp.json()except Exception as e:print(f"请求失败 ({lang}):", e)return Nonedef crawl_language(lang):print(f"开始爬取语言:{lang}")cursor = load_cursor(lang)total = 0while total < max_reviews_per_lang:data = fetch_reviews(appid, cursor, lang)if not data:print("请求失败,稍后重试...")time.sleep(5)continuereviews = data.get("reviews", [])if not reviews:print("无更多评论,结束爬取", lang)break# 过滤时间后实际保存的评论数count_before = totalsave_reviews(lang, reviews)# 统计有效评论数量(时间范围内)filtered = [r for r in reviews if start_ts <= r.get("timestamp_created", 0) <= end_ts]total += len(filtered)print(f"{lang}: 已保存 {total} 条评论")cursor = data.get("cursor")if not cursor:print(f"{lang}无游标,结束爬取")breaksave_cursor(lang, cursor)time.sleep(1)print(f"{lang}爬取完成,总共保存 {total} 条评论")def main():for lang in ["schinese"]:crawl_language(lang)if __name__ == "__main__":main()
对于这个代码,我增加了几点功能。
1.分语言爬取,第一个代码是没有对玩家评测语言进行分类的,那么就是默认为all,所有的可能语言评论都会被爬取,这个语言---你可以去参考Steam API。应该是开源出来了。
2.分时间段爬取,有一个缺点就是,也是从你指定的时间段开始,但是你的爬取条数会影响到你最终结束的那个评论的时间。比如说,你爬取1000条,从5月30-6月5日,这个时间段的评论数远大于1000的时候,那么你最终的那个结束点,它不会是5月30号的。这个要注意,你可以给很大的值,我实测过,只要它的爬取个数一直没有发生改变的时候,那么你直接终止程序就ok了,不会有什么影响。
获取Steam登录Cookie的脚本
在多分享一个,就是如果你想使用的是Selenium+BeautifulSoup组合,那么你应该是要模拟登录网站的,但是频繁登录就很容易被对方网站给Ban掉,通过加入一个初次登录时的Cookie,不但方便登录而且不那么容易被网站察觉你在爬。
import json
import time
import undetected_chromedriver as uc# 创建 Chrome 浏览器实例
options = uc.ChromeOptions()
options.add_argument("--no-sandbox")
options.add_argument("--disable-gpu")
# 不使用 headless,确保你能手动完成登录
# options.add_argument("--headless") # 不要加这行,手动登录用不到driver = uc.Chrome(options=options)try:# 打开 Steam 登录页面driver.get("https://store.steampowered.com/login/")print("🧭 请手动登录 Steam... 登录完成后不要关闭窗口。")# 等待你手动登录(比如扫码、输入验证码等)input("✅ 登录完成后,按下 Enter 继续...")# 获取 cookiescookies = driver.get_cookies()# 保存 cookies 到本地文件with open("steam_cookies.json", "w", encoding="utf-8") as f:json.dump(cookies, f, indent=2)print("✅ Cookie 已成功保存为 steam_cookies.json")finally:driver.quit()
这个就不做太多解释,应该很容易看懂。
以上的代码都是经过我实际操作过,没有特殊的环境要求配置,你只要把这些库给pip install下来基本上就ok了。
由于是第一次爬虫,所以还有很多地方不太清楚,如果你是想获取动态JavaScript数据的话,那就得去学习逆向了。
相关文章:

Steam爬取相关游戏评测
## 因为是第一次爬取Steam。所以作为一次记录发出;有所错误欢迎指出。 无时间指定爬取 import requests import time import csv import osappid "553850" # 这里你也可以改成 #appid int(input()) max_reviews 10000 # 想爬多少条 # max_reviews…...

《开篇:课程目录》
大家好!我是一名.NET技术开发者,长期以来积累了比较多的项目实战经验,现在把它分享给大家,希望能够帮助到大家,同时为.NET社区提供一份力量,让更多的开发者参与进来。 要讲解的课程如下: 《介绍…...
大陆4D毫米波雷达ARS548调试
本文介绍了大陆ARS548毫米波雷达的调试与测试流程,主要包括以下内容: 设备参数:最大检测距离301m(可调93-1514m),支持gPTP时间同步。 接线调试: Windows需使用USB-RJ45转换器 Linux可直接连接网…...

Qt Quick模块功能及架构
Qt 6.0 中的 Qt Quick 模块是构建现代、动态用户界面的核心框架,基于声明式编程(QML)和 JavaScript,专注于高性能、流畅的动画和跨平台 UI 开发。、 一、主要功能改进 1. Qt Quick 核心架构 QML 引擎升级:Qt 6.0 使用…...

C++信息学竞赛中常用函数的一般用法
在C 信息学竞赛中,有许多常用函数能大幅提升编程效率。下面为你介绍一些常见函数及其一般用法: 一、比较函数 1、max()//求出a,b的较大值 int a10,b5,c;cmax(a,b);//得出的结果就是c等于10. 2、min()//求出a,b的较小值 int a1…...

大语言模型解析
1. Input Embedding embedding:将自然语言翻译成index 每个index对应一个embedding,embedding需要训练,embedding是一个数组...

全面解析网络端口:概念、分类与安全应用
在计算机网络的世界里,数据的传输与交互如同一场繁忙的物流运输,而网络端口就是其中不可或缺的 “货运码头”。无论是日常浏览网页、收发邮件,还是运行各类网络服务,都离不开网络端口的参与。本文将深入介绍网络端口的相关知识&am…...

Python网页自动化测试,DrissonPage库入门说明文档
🛰️ 基本逻辑 操作浏览器的基本逻辑如下: 创建浏览器对象,用于启动或接管浏览器获取一个 Tab 对象使用 Tab 对象访问网址使用 Tab 对象获取标签页内需要的元素对象使用元素对象进行交互 除此以外,还能执行更为复杂的操作&am…...
摄像机(Camera))
C++.OpenGL (9/64)摄像机(Camera)
颜色(Color) 颜色理论在OpenGL中的应用 #mermaid-svg-dKNDfS4EKDUmG4Ts {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-dKNDfS4EKDUmG4Ts .error-icon{fill:#552222;}#mermaid-svg-dKNDfS4EKDUmG4Ts .error-text…...

民锋视角下的资金流效率与账户行为建模
民锋视角下的资金流效率与账户行为建模 在当前复杂多变的金融环境中,资金流效率已成为衡量一家金融服务机构专业能力的重要指标。民锋在账户管理与资金调配的实战经验中,逐步建立起一套以资金流路径为核心的行为建模方法,用以评估客户行为、交…...

python打卡第48天
知识点回顾: 随机张量的生成:torch.randn函数卷积和池化的计算公式(可以不掌握,会自动计算的)pytorch的广播机制:加法和乘法的广播机制 ps:numpy运算也有类似的广播机制,基本一致 **…...

matlab实现DBR激光器计算
DBR激光器计算程序。非常值得参考的程序。DBR激光器程序 DBR计算/1.txt , 2056 DBR计算/4.asv , 22 DBR计算/4.txt , 32 DBR计算/GetDeviceEfficiency.asv , 2012 DBR计算/GetDeviceEfficiency.m , 2014 DBR计算/GetOneLayerArray.asv , 837 DBR计算/GetOneLayerArray.m , 836…...

Java在word中指定位置插入图片。
Java使用(Poi-tl) 在word(docx)中指定位置插入图片 Poi-tl 简介Maven 依赖配置Poi-tl 实现原理与步骤1. 模板标签规范2.完整实现代码3.效果展示 Poi-tl 简介 Poi-tl 是基于 Apache POI 的 Java 开源文档处理库,专注于…...

uni-app学习笔记三十--request网络请求传参
request用于发起网络请求。 OBJECT 参数说明 参数名类型必填默认值说明平台差异说明urlString是开发者服务器接口地址dataObject/String/ArrayBuffer否请求的参数App 3.3.7 以下不支持 ArrayBuffer 类型headerObject否设置请求的 header,header 中不能设置 Refere…...
可视化图解算法48:有效括号序列
牛客网 面试笔试 TOP101 | LeetCode 20. 有效的括号 1. 题目 描述 给出一个仅包含字符(,),{,},[和],的字符串,判断给出的字符串是否是合法的括号序列 括号必须以正确的顺序关闭,"()"和"()[]{}"都是合法的括号序列&…...
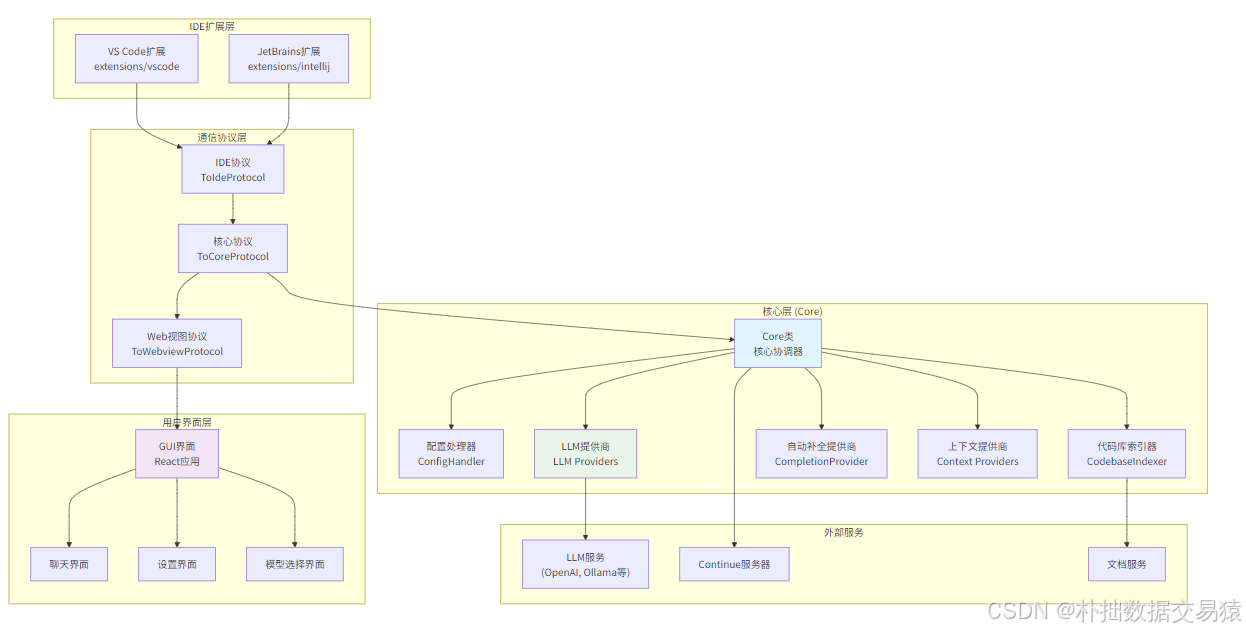
Continue 开源 AI 编程助手框架深度分析
Continue 开源 AI 编程助手框架深度分析 一、项目简介 Continue 是一个模块化、可配置、跨平台的开源 AI 编程助手框架,目标是让开发者能在本地或云端环境中,快速集成和使用自定义的 LLM 编程辅助工具。它通过支持 VS Code 与 JetBrains 等主流 IDE 插件…...

MySQL技术内幕1:内容介绍+MySQL编译使用介绍
文章目录 1.整体内容介绍2.下载编译流程2.1 安装编译工具和依赖库2.2 下载编译 3.配置MySQL3.1 数据库初始化3.2 编辑配置文件3.3 启动停止MySQL3.4 登录并修改密码 1.整体内容介绍 MySQL技术系列文章将从MySQL下载编译,使用到MySQL各组件使用原理源码分析…...
)
RMQ 算法详解(区间最值问题)
RMQ 算法详解(区间最值问题) 问题介绍解决方法暴力法ST表法基本思想算法步骤C实现 问题介绍 RMQ问题是OI中经常遇到的问题,主要是一下形式: 给你一堆数,不断的对里面的数进行操作,例如:让某个…...

SpringCloud——Nacos
1、核心功能: 服务注册与发现: 服务实例可动态注入到Nacos中,消费者通过服务名发现可用实例。 // 启用EnableDiscoveryClient注解启用Nacos SpringBootApplication EnableDiscoveryClient public class UserServiceApplication {public st…...

ubuntu自定义服务自动启动
自定义服务 在路径 /etc/systemd/system/ 下 定义example.service [Unit] DescriptionMy Custom Script[Service] ExecStart/root/exe_start.sh Typeoneshot RemainAfterExityes[Install] WantedBymulti-user.target在/root/ 路径下执行 vi exe_start.shcd /root/mes_server/…...
网络安全问题及对策研究
摘 要 网络安全问题一直是近年来社会乃至全世界十分关注的重要性问题,网络关乎着我们的生活,政治,经济等多个方面,致力解决网络安全问题以及给出行之有效的安全策略是网络安全领域的一大目标。 本论文简述了课题的开发背景&…...

Ubantu-Docker配置最新镜像源250605
尝试其他镜像加速器 阿里云镜像加速器:登录阿里云,进入容器镜像服务获取专属加速器地址。毫秒镜像:https://docker.1ms.run。DockerHub镜像加速器:https://docker.xuanyuan.me。Docker Hub 镜像加速服务:https://dock…...
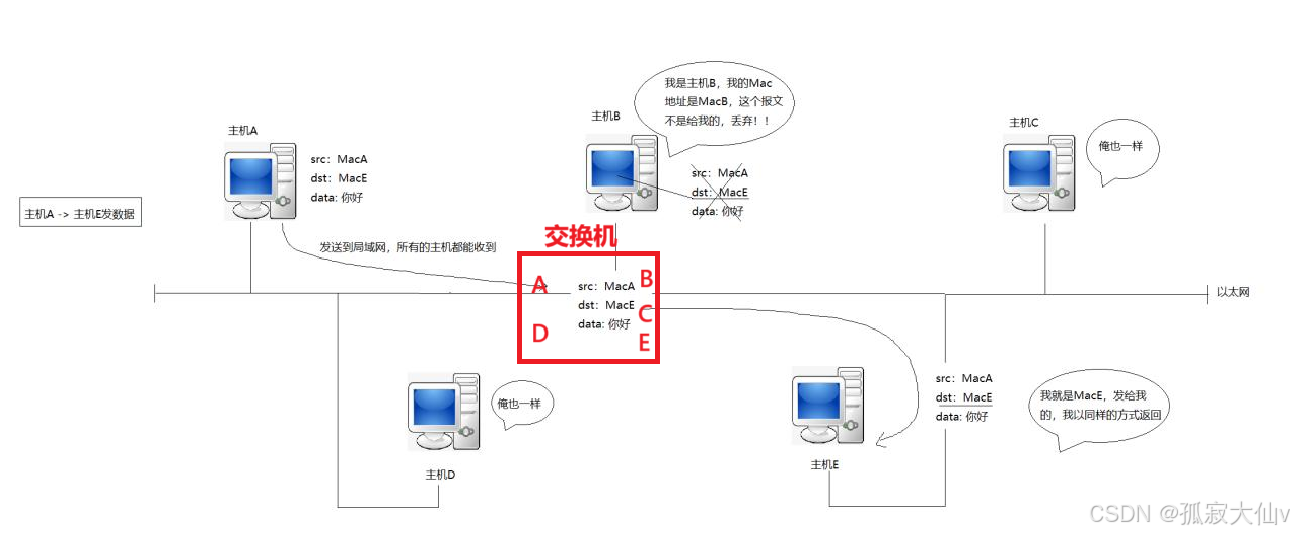
【计算机网络】NAT、代理服务器、内网穿透、内网打洞、局域网中交换机
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:计算机网络 🌹往期回顾🌹:【计算机网络】数据链路层——ARP协议 🔖流水不争,争的是滔滔不息 一、网络地址转…...
)
后端解决跨域问题的三种方案:注解配置 vs 全局配置 vs 过滤器配置(附完整代码详解)
文章目录 一、引言:跨域问题的本质与解决方案分类解决方案分类二、方案一:`WebMvcConfigurer` 全局配置(推荐)1. 核心代码(你提供的 `CorsConfig` 示例)2. 代码详解3. 优点4. 注意事项三、方案二:`CorsFilter` 过滤器配置(传统方式)1. 核心代码(你提供的 `ResourcesC…...
在 Vue 的template中使用 Pug 的完整教程
在 Vue 的template中使用 Pug 的完整教程 引言 什么是 Pug? Pug(原名 Jade)是一种高效的网页模板引擎,通过缩进式语法和简洁的写法减少 HTML 的冗长代码。Pug 省略了尖括号和闭合标签,使用缩进定义结构,…...

【立体匹配】:双目立体匹配SGBM:(1)运行
注:这是一个专题,我会一步步介绍SGBM的实现,按照我的使用和优化过程逐步改善算法,附带实现方法 系列文章【立体匹配】:双目立体匹配SGBM:(1)运行 【立体匹配】:双目立体匹…...
< 自用文 OS有关 新的JD云主机> 国内 京东云主机 2C4G 60G 5Mb 498/36月 Ubuntu22
攒了这么久,废话一些: 前几周很多事儿,打算回北京,开个清真的德克萨斯烤肉店,写了一篇 : < 自用文 Texas style Smoker > 美式德克萨斯烟熏炉 从设计到实现 (第一部分&…...

十、【ESP32开发全栈指南: TCP客户端】
一、TCP协议核心特性回顾 TCP与UDP关键差异 特性TCPUDP连接方式面向连接 (三次握手)无连接可靠性可靠传输 (重传/排序/校验)尽力交付数据顺序保证数据按序到达不保证顺序流控制滑动窗口机制无流控制传输效率协议开销大头部开销小适用场景文件传输、网页浏览实时音视频、广播通…...

基于机器学习的智能故障预测系统:构建与优化
前言 在现代工业生产中,设备故障不仅会导致生产中断,还会带来巨大的经济损失。传统的故障检测方法依赖于人工巡检和定期维护,这种方式效率低下且难以提前预测潜在故障。随着工业物联网(IIoT)和机器学习技术的发展&…...

设计模式-观察着模式
观察者模式 观察者模式 (Observer Pattern) 是一种行为型设计模式,它定义了对象之间一种一对多的依赖关系,当一个对象(称为主题或可观察者)的状态发生改变时,所有依赖于它的对象(称为观察者)都…...