第6章:Neo4j数据导入与导出
在实际应用中,数据的导入与导出是使用Neo4j的重要环节。无论是初始数据加载、系统迁移还是数据备份,都需要高效可靠的数据传输机制。本章将详细介绍Neo4j中的各种数据导入与导出方法,帮助读者掌握不同场景下的最佳实践。
6.1 数据导入策略
将数据导入Neo4j是使用图数据库的第一步。根据数据量大小、来源格式和性能要求,可以选择不同的导入策略。
小规模数据的LOAD CSV
对于小到中等规模的数据集(通常是数十万条记录以内),Neo4j的LOAD CSV命令是一个简单而强大的选择。这是一个内置的Cypher命令,可以直接从CSV文件中读取数据并创建节点和关系。
基本用法:
// 从CSV文件加载数据并创建Person节点
LOAD CSV WITH HEADERS FROM 'file:///people.csv' AS row
CREATE (:Person {name: row.name, age: toInteger(row.age), email: row.email})
LOAD CSV的优点包括:使用方式简单,用户可以直接在Cypher查询中执行,无需额外的工具或复杂配置。同时,它支持在导入过程中进行数据转换和验证,灵活处理不同的数据需求。此外,LOAD CSV非常适合用于增量更新和小批量数据的导入场景,能够满足日常开发和维护的需要。
LOAD CSV的局限性主要体现在性能和资源消耗方面。当处理数百万条记录以上的大规模数据时,其导入速度明显受限,难以满足高性能需求。此外,LOAD CSV在处理大文件时会占用较多内存,可能导致系统资源紧张。由于导入过程需要逐行解析和执行Cypher语句,整体执行时间较长,可能对数据库的其他操作产生影响。因此,LOAD CSV更适合中小规模数据的导入,对于超大数据集建议采用专用的批量导入工具。
LOAD CSV非常适合用于初始原型开发、概念验证、小型项目的数据导入,以及定期进行小批量数据更新的场景。它还特别适用于在导入过程中需要进行复杂数据转换的需求。通过灵活的Cypher语句,用户可以在导入时对数据进行清洗、转换和验证,从而满足多样化的业务场景。
大规模数据的批量导入
对于大规模数据集(数百万到数十亿条记录),Neo4j提供了专门的批量导入工具,能够以极高的速度导入数据。
Neo4j Admin Import工具:
这是一个命令行工具,专为初始数据库填充设计,能够绕过事务处理和约束检查,直接写入数据库文件。
neo4j-admin import --nodes=persons.csv --relationships=friendships.csv --delimiter="," --array-delimiter=";"
Neo4j Admin Import工具具有极高的导入速度,通常比LOAD CSV快10到100倍,能够显著缩短大规模数据加载的时间。同时,该工具在内存使用上非常高效,可以处理超大规模的数据集而不会轻易耗尽系统资源。此外,导入过程支持并行处理,能够充分利用多核CPU,实现更高的吞吐量和性能表现。
Neo4j Admin Import工具的局限性主要包括以下几个方面:首先,它只能用于创建新的数据库,无法向现有数据库中追加数据,因此适用于初始数据加载场景。其次,导入所需的CSV文件必须符合特定的格式要求,包括节点和关系的ID、标签、类型等,格式不正确会导致导入失败。此外,导入操作必须在数据库离线状态下进行,导入期间数据库不可用,无法对外提供服务。最后,该工具在导入过程中不会执行唯一性约束或其他数据完整性检查,因此需要在导入完成后手动验证和修复数据一致性问题。
除了官方的批量导入工具外,Neo4j还支持多种其他批量导入方式。例如,APOC(Awesome Procedures On Cypher)库提供了如apoc.periodic.iterate等过程,可以将大型导入任务拆分为小批次执行,提升导入效率并降低内存压力。Neo4j ETL工具则为用户提供了图形化界面,方便地将关系型数据库中的数据迁移到Neo4j。对于有特殊需求的场景,还可以利用Neo4j驱动程序(如Java、Python等)编写自定义导入脚本,实现复杂的数据转换、校验和错误处理。这些方法为不同规模和复杂度的数据导入需求提供了灵活的解决方案。
批量导入通常适用于初始数据库填充、系统迁移、数据仓库建设等场景,尤其是在需要高性能导入大规模数据集时效果最佳。这类方式能够显著提升导入速度,减少系统资源消耗,是处理数百万到数十亿条数据时的首选方案。
在生产环境中,数据通常是动态变化的,需要定期或实时更新图数据库。
定期批量更新:
使用LOAD CSV或自定义脚本定期导入新数据或更新现有数据:
// 使用MERGE确保不创建重复节点
LOAD CSV WITH HEADERS FROM 'file:///new_people.csv' AS row
MERGE (p:Person {id: row.id})
ON CREATE SET p.name = row.name, p.age = toInteger(row.age), p.created = timestamp()
ON MATCH SET p.name = row.name, p.age = toInteger(row.age), p.updated = timestamp()
实时数据同步:
对于需要近实时更新的系统,可以考虑以下方案:
| 方案 | 描述 |
|---|---|
| 变更数据捕获 (CDC) | 监控源系统的数据变更,并将这些变更实时应用到 Neo4j。 |
| 消息队列集成 | 使用 Kafka、RabbitMQ 等消息队列系统,将数据变更事件发送到 Neo4j 处理程序。 |
| Neo4j Streams 插件 | 直接集成 Kafka 和 Neo4j,实现数据流处理。 |
// 使用Java驱动程序处理Kafka消息并更新Neo4j
kafkaConsumer.subscribe(Arrays.asList("data-changes"));
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 解析消息JsonObject change = JsonParser.parseString(record.value()).getAsJsonObject();// 更新Neo4jtry (Session session = driver.session()) {session.writeTransaction(tx -> {tx.run("MERGE (p:Person {id: $id}) SET p.name = $name, p.updated = timestamp()",parameters("id", change.get("id").getAsString(),"name", change.get("name").getAsString()));return null;});}}
}
在进行增量数据导入时,建议遵循以下原则以确保数据一致性和高效性。首先,为每个实体分配唯一标识符,便于后续的数据匹配和更新。其次,记录每条数据的创建和更新时间戳,有助于追踪数据的变更历史。导入时应优先使用MERGE而非CREATE,以避免重复数据的产生。对于大批量数据更新,建议采用分批处理方式,减少单个事务的压力,提高系统稳定性。同时,建立健全的错误处理与重试机制,确保在出现异常时能够及时恢复并保证数据完整。最后,整个导入过程应进行详细的日志记录和监控,便于后续的问题排查和性能优化。
选择合适的数据导入策略需要考虑数据量、更新频率、性能要求和系统架构等因素。对于大多数应用,可能需要结合使用多种导入方法,例如初始数据使用批量导入,后续更新使用增量方式。
6.2 LOAD CSV详解
LOAD CSV是Neo4j中最常用的数据导入工具,适合中小规模数据集和增量更新场景。本节将深入探讨LOAD CSV的各种用法和最佳实践。
文件格式与预处理
LOAD CSV命令设计用于处理CSV(逗号分隔值)文件,但实际上它可以处理任何分隔符分隔的文本文件。
在使用LOAD CSV导入数据时,CSV文件应满足一些基本格式要求。首先,文件应为文本格式,推荐使用UTF-8编码,以确保字符集兼容性。每一行代表一条数据记录,字段之间通过分隔符(通常为逗号)进行分隔。CSV文件可以包含标题行(即字段名),也可以省略标题行,具体取决于导入时的配置。遵循这些基本规范,有助于确保数据能够被Neo4j正确解析和导入。
示例CSV文件:
name,age,email
Alice,30,alice@example.com
Bob,35,bob@example.com
Charlie,28,charlie@example.com
文件位置:
LOAD CSV可以从以下位置读取文件:
-
本地文件系统:使用
file:///前缀LOAD CSV FROM 'file:///data/people.csv' AS row -
远程URL:使用
http://或https://前缀LOAD CSV FROM 'https://example.com/data/people.csv' AS row
Tip:出于安全考虑,Neo4j默认只允许从特定目录(通常是
import目录)读取本地文件。可以通过配置dbms.directories.import参数修改此目录。
文件预处理:
在导入大型或复杂的CSV文件之前,通常需要对数据进行预处理。首先,应进行数据清洗,修复格式问题、处理缺失值,并标准化数据格式,以保证数据的一致性和可用性。其次,对于包含嵌套结构或复杂类型的数据,需要将其转换为CSV能够表示的扁平结构,例如将嵌套的JSON字段拆分为多个列。此外,为了便于分批处理和提升导入效率,可以将过大的文件拆分为多个较小的文件。最后,确保所有文件采用UTF-8或其他Neo4j支持的编码格式,以避免字符集兼容性问题。这些预处理步骤有助于提升数据导入的成功率和效率。
可以使用Python、R、awk等工具进行这些预处理:
import pandas as pd# 读取原始数据
df = pd.read_csv('raw_data.csv')# 数据清洗和转换
df['age'] = df['age'].fillna(0).astype(int) # 处理缺失值并转换类型
df['name'] = df['name'].str.strip() # 去除空白
df['email'] = df['email'].str.lower() # 标准化邮箱# 保存处理后的数据
df.to_csv('processed_data.csv', index=False, encoding='utf-8')
导入配置与参数
LOAD CSV命令提供了多种配置选项,可以根据需要调整导入行为。
基本语法:
LOAD CSV [WITH HEADERS] FROM 'url' AS row
[FIELDTERMINATOR 'delimiter']
主要参数:
-
WITH HEADERS:指定CSV文件包含标题行,这样可以通过列名引用字段
// 使用列名引用 LOAD CSV WITH HEADERS FROM 'file:///people.csv' AS row RETURN row.name, row.age// 不使用标题行 LOAD CSV FROM 'file:///people.csv' AS row RETURN row[0], row[1] // 通过索引引用 -
FIELDTERMINATOR:指定字段分隔符,默认为逗号
// 使用制表符作为分隔符 LOAD CSV FROM 'file:///people.tsv' AS row FIELDTERMINATOR '\t' RETURN row -
PERIODIC COMMIT:处理大文件时定期提交事务,减少内存使用
// 每1000行提交一次事务 USING PERIODIC COMMIT 1000 LOAD CSV FROM 'file:///large_file.csv' AS row CREATE (:Person {name: row[0]})
Tip:从Neo4j 4.0开始,
PERIODIC COMMIT已被弃用,推荐使用APOC库的apoc.periodic.iterate过程。
数据类型转换:
CSV文件中的所有数据都被读取为字符串,通常需要进行类型转换:
LOAD CSV WITH HEADERS FROM 'file:///people.csv' AS row
CREATE (:Person {name: row.name,age: toInteger(row.age), // 转换为整数height: toFloat(row.height), // 转换为浮点数isActive: row.active = 'true', // 转换为布尔值birthDate: date(row.birthDate), // 转换为日期lastLogin: datetime(row.lastLogin) // 转换为日期时间
})
处理数组和复杂数据:
CSV不直接支持数组和嵌套结构,但可以通过特殊格式和转换函数处理:
// 假设CSV中的skills列包含分号分隔的技能列表: "Java;Python;SQL"
LOAD CSV WITH HEADERS FROM 'file:///people.csv' AS row
CREATE (:Person {name: row.name,skills: split(row.skills, ';') // 转换为字符串数组
})
错误处理与日志
在处理大量数据时,错误处理和日志记录至关重要,可以帮助识别和解决导入问题。
错误处理策略:
-
预验证数据:在导入前验证数据格式和完整性
// 先检查数据,不执行写操作 LOAD CSV WITH HEADERS FROM 'file:///people.csv' AS row WHERE row.age IS NULL OR NOT row.age =~ '^[0-9]+$' RETURN row.name, row.age, 'Invalid age format' AS error -
使用MERGE而非CREATE:避免因唯一性约束导致的错误
LOAD CSV WITH HEADERS FROM 'file:///people.csv' AS row MERGE (:Person {id: row.id}) ON CREATE SET p.name = row.name, p.age = toInteger(row.age) -
分批处理:使用APOC库分批处理大文件
CALL apoc.periodic.iterate("LOAD CSV WITH HEADERS FROM 'file:///large_file.csv' AS row RETURN row","CREATE (:Person {name: row.name, age: toInteger(row.age)})",{batchSize: 1000, parallel: false} ) -
记录错误:将错误记录到日志或专门的错误表
LOAD CSV WITH HEADERS FROM 'file:///people.csv' AS row CALL {WITH rowMERGE (:Person {id: row.id})ON CREATE SET p.name = row.name, p.age = toInteger(row.age) } IN TRANSACTIONS OF 100 ROWS ON ERROR {CALL apoc.log.error('Error processing row %s: %s', [row.id, apoc.convert.toJson(row)])CONTINUE }
日志记录:
使用Neo4j的日志系统或APOC库记录导入过程:
// 使用APOC记录导入进度
CALL apoc.periodic.iterate("LOAD CSV WITH HEADERS FROM 'file:///large_file.csv' AS row RETURN row","CREATE (:Person {name: row.name}) RETURN count(*)",{batchSize: 1000, iterateList: true, parallel: false}
)
YIELD batches, total, errorMessages
CALL apoc.log.info('Import completed: %d batches, %d total, %d errors', [batches, total, size(errorMessages)])
RETURN batches, total, errorMessages
监控导入进度:
对于大型导入任务,监控进度非常重要:
-
使用APOC的进度报告:
CALL apoc.periodic.iterate("LOAD CSV WITH HEADERS FROM 'file:///large_file.csv' AS row RETURN row","CREATE (:Person {name: row.name})",{batchSize: 1000, parallel: false, iterateList: true} ) YIELD batches, total, errorMessages, operations, timeTaken RETURN batches, total, operations, timeTaken, errorMessages -
使用自定义计数器:
// 创建计数器节点 CREATE (:ImportStatus {name: 'people_import', processed: 0, errors: 0})// 在导入过程中更新计数器 LOAD CSV WITH HEADERS FROM 'file:///people.csv' AS row MATCH (status:ImportStatus {name: 'people_import'}) CREATE (:Person {name: row.name}) WITH status SET status.processed = status.processed + 1
通过深入理解LOAD CSV的功能和最佳实践,可以有效地处理各种数据导入场景,确保数据的准确性和完整性。
6.3 Neo4j Admin导入工具
对于大规模数据集(数百万到数十亿条记录),Neo4j Admin Import工具是最高效的选择。这是一个命令行工具,专为初始数据库填充设计,能够以极高的速度导入数据。
离线批量导入
Neo4j Admin Import工具(以前称为neo4j-import)是一个离线批量导入工具,它绕过了Neo4j的事务系统,直接写入数据库文件,因此速度极快。
基本用法:
neo4j-admin import \--nodes=persons.csv \--relationships=friendships.csv \--delimiter="," \--array-delimiter=";" \--id-type=STRING
Neo4j Admin Import工具具有多项重要特性。首先,它是一种离线操作工具,导入过程中数据库必须停止运行,无法对外提供服务。其次,该工具只能用于创建新的数据库,不能向现有数据库追加数据,因此非常适合初始数据加载场景。与LOAD CSV相比,Neo4j Admin Import工具拥有极高的性能,导入速度通常快10到100倍,能够显著缩短大规模数据加载的时间。此外,它采用高效的内存管理机制,可以处理超大规模的数据集而不会轻易耗尽系统资源。最后,该工具支持并行处理,能够自动利用多核CPU加速导入过程,进一步提升整体性能。
性能优化与配置
为了获得最佳性能,可以调整Neo4j Admin Import工具的各种配置参数。
内存配置:
neo4j-admin import \--nodes=persons.csv \--relationships=friendships.csv \--high-io=true \--skip-duplicate-nodes=true \--skip-bad-relationships=true \--max-memory=4G
常用的性能优化参数包括:--high-io(启用高IO配置,适用于SSD和高性能存储)、--max-memory(设置最大内存使用量)、--processors(指定使用的处理器核心数)、--skip-duplicate-nodes(跳过重复节点而不是报错)、--skip-bad-relationships(跳过无效关系而不是报错)以及--bad-tolerance(设置可容忍的错误记录数量)。合理配置这些参数可以有效提升导入速度和稳定性,减少因数据异常导致的中断。
文件格式要求:
Neo4j Admin Import工具对输入文件有特定的格式要求:
-
节点文件:必须包含ID列,用于唯一标识节点
id:ID,name,age:int,:LABEL person1,Alice,30,Person person2,Bob,35,Person;Employee -
关系文件:必须包含起始节点ID、目标节点ID和关系类型
:START_ID,:END_ID,:TYPE,since:int person1,person2,KNOWS,2010 person2,person1,KNOWS,2010 -
ID空间:可以使用ID空间来区分不同类型的ID
id:ID(Person),name 1,Alice 2,Bobid:ID(Movie),title 101,The Matrix 102,Inception:START_ID(Person),:END_ID(Movie),:TYPE 1,101,WATCHED 2,102,WATCHED
常见问题与解决方案
使用Neo4j Admin Import工具时可能遇到的常见问题及其解决方案:
1. 内存不足错误:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
解决方案:可以通过增加最大内存设置(如使用--max-memory=8G)、减小批处理大小(如设置--batch-size=10000),或者将大文件分割成多个小文件来缓解内存不足的问题。
2. 重复节点错误:
Duplicate node with id 'person1'
解决方案包括:可以通过添加--skip-duplicate-nodes=true参数跳过重复节点,避免因ID重复导致导入中断;也可以在导入前对数据进行预处理,确保所有节点ID的唯一性;此外,建议使用ID空间来区分不同类型的ID,从而减少ID冲突的可能性。
3. 关系引用不存在的节点:
Relationship refers to missing node with id 'person3'
解决方案包括:可以通过添加--skip-bad-relationships=true参数跳过无效关系,避免因关系引用不存在的节点而导致导入中断。此外,建议在导入前对数据进行预处理,确保所有关系所引用的节点都已存在于节点文件中。还应检查ID空间的设置是否正确,确保关系文件中的节点ID与节点文件中的ID及其ID空间一致,从而避免因ID空间不匹配导致的节点缺失问题。
4. 文件格式错误:
Input error: Header mismatch for field 'name'
解决方案:首先,确保所有导入文件的格式保持一致,包括字段顺序和数据类型。其次,检查导入命令中的分隔符设置是否与实际文件一致,避免因分隔符不匹配导致解析错误。此外,要仔细验证CSV文件的标题行格式,确保字段名称与导入工具的要求完全对应,从而避免因标题不符而引发的问题。
5. 导入速度慢:
解决方案包括:可以启用高IO模式(--high-io=true),增加处理器数量(如--processors=8),并优先使用SSD等高性能存储设备以提升读写速度。同时,建议优化导入文件格式,去除不必要的字段,减少数据体积。对于超大文件,可以将其拆分为多个较小的文件,并采用并行导入的方式进一步提升整体导入效率。
最佳实践:
在使用Neo4j Admin Import工具进行大规模数据导入时,应遵循以下最佳实践。首先,务必对原始数据进行预处理,确保数据的质量和格式符合导入要求。其次,建议先用小规模数据集进行测试,验证导入流程和文件格式的正确性,及时发现潜在问题。导入时应分阶段进行,通常先导入所有节点,再导入关系,以避免因节点缺失导致关系导入失败。在整个导入过程中,要密切监控系统的内存、CPU和磁盘资源使用情况,及时调整参数以防止资源耗尽。此外,务必备份原始数据文件,以便在出现问题时能够重新导入。最后,导入完成后要对数据进行全面验证,确保节点和关系数量、属性等信息与预期一致,保证数据的完整性和准确性。
Neo4j Admin Import工具是处理大规模初始数据导入的最佳选择,通过正确配置和遵循最佳实践,可以实现极高的导入性能。
6.4 数据导出与备份
除了导入数据,从Neo4j导出数据和创建备份也是数据管理的重要部分。本节将介绍各种数据导出方法和备份策略。
查询结果的导出
Neo4j提供了多种方式将查询结果导出为各种格式。
使用Neo4j Browser导出:
Neo4j Browser允许将查询结果导出为CSV、JSON或图像格式:
- 执行查询
- 在结果面板中,点击下载按钮
- 选择导出格式(CSV、JSON或PNG)
使用Cypher导出到CSV:
// 导出所有Person节点到CSV
MATCH (p:Person)
WITH p.name AS Name, p.age AS Age, p.email AS Email
CALL apoc.export.csv.query("RETURN $Name AS Name, $Age AS Age, $Email AS Email","persons.csv",{params: {Name: Name, Age: Age, Email: Email}}
)
YIELD file, source, format, nodes, relationships, properties, time, rows
RETURN file, rows
使用APOC库导出:
APOC库提供了强大的导出功能,支持多种格式:
-
导出为CSV:
// 导出特定查询结果 CALL apoc.export.csv.query("MATCH (p:Person) RETURN p.name, p.age, p.email","persons.csv",{} )// 导出整个数据库 CALL apoc.export.csv.all("full_export.csv", {}) -
导出为JSON:
// 导出特定查询结果 CALL apoc.export.json.query("MATCH (p:Person) RETURN p.name, p.age, p.email","persons.json",{} )// 导出整个数据库 CALL apoc.export.json.all("full_export.json", {}) -
导出为GraphML(可用于其他图工具):
// 导出整个数据库为GraphML格式 CALL apoc.export.graphml.all("export.graphml", {}) -
导出为Cypher脚本(可用于重建数据库):
// 导出为Cypher创建语句 CALL apoc.export.cypher.all("export.cypher", {format: "plain"})
使用自定义程序导出:
对于复杂的导出需求,可以使用Neo4j驱动程序编写自定义导出逻辑:
// Java示例:导出查询结果到CSV
try (Session session = driver.session()) {Result result = session.run("MATCH (p:Person) RETURN p.name, p.age, p.email");try (CSVWriter writer = new CSVWriter(new FileWriter("persons.csv"))) {// 写入标题行writer.writeNext(new String[]{"name", "age", "email"});// 写入数据行while (result.hasNext()) {Record record = result.next();writer.writeNext(new String[]{record.get("p.name").asString(),String.valueOf(record.get("p.age").asInt()),record.get("p.email").asString()});}}
}
数据库备份与恢复
定期备份Neo4j数据库是防止数据丢失的关键措施。Neo4j提供了多种备份选项。
在线备份(企业版):
Neo4j企业版提供在线备份功能,可以在数据库运行时创建一致性备份:
# 创建完整备份
neo4j-admin backup --backup-dir=/backups/neo4j --database=neo4j# 创建增量备份(基于上一次备份)
neo4j-admin backup --backup-dir=/backups/neo4j --database=neo4j
离线备份(社区版和企业版):
对于Neo4j社区版,可以通过复制数据文件创建离线备份:
-
停止Neo4j服务
neo4j stop -
复制数据目录
cp -r $NEO4J_HOME/data/databases/neo4j /backups/neo4j_$(date +%Y%m%d) -
重启Neo4j服务
neo4j start
使用APOC库进行备份:
APOC库提供了一些备份功能,特别适用于社区版:
// 导出整个数据库为Cypher脚本
CALL apoc.export.cypher.all("backup.cypher", {format: "plain"})
恢复备份:
-
恢复在线备份(企业版):
# 停止Neo4j neo4j stop# 恢复备份 neo4j-admin restore --from=/backups/neo4j --database=neo4j# 启动Neo4j neo4j start -
恢复离线备份:
# 停止Neo4j neo4j stop# 删除或重命名现有数据库 mv $NEO4J_HOME/data/databases/neo4j $NEO4J_HOME/data/databases/neo4j_old# 复制备份文件 cp -r /backups/neo4j $NEO4J_HOME/data/databases/# 启动Neo4j neo4j start -
从Cypher脚本恢复:
# 创建新数据库或清空现有数据库# 执行Cypher脚本 cat backup.cypher | cypher-shell -u neo4j -p password
数据迁移策略
在系统升级、架构变更或平台迁移时,需要制定合适的数据迁移策略。
版本升级迁移:
当升级Neo4j版本时,通常需要迁移数据:
-
就地升级(适用于小版本升级):
# 停止旧版本 neo4j stop# 安装新版本 # ...# 启动新版本(自动升级数据格式) neo4j start -
导出-导入迁移(适用于大版本升级):
# 从旧版本导出 CALL apoc.export.cypher.all("export.cypher", {format: "plain"})# 在新版本中导入 cat export.cypher | cypher-shell -u neo4j -p password
跨平台迁移:
当需要将Neo4j数据库从一个平台迁移到另一个平台时:
-
使用备份-恢复(如果平台兼容):
- 在源平台创建备份
- 将备份文件传输到目标平台
- 在目标平台恢复备份
-
使用导出-导入(适用于任何平台):
- 在源平台导出为GraphML或Cypher脚本
- 将导出文件传输到目标平台
- 在目标平台导入数据
数据模型迁移:
当需要更改数据模型时,可以使用以下策略:
-
增量迁移:
// 示例:将Person节点分为Customer和Employee两类 MATCH (p:Person) WHERE p.type = 'customer' SET p:Customer REMOVE p:PersonMATCH (p:Person) WHERE p.type = 'employee' SET p:Employee REMOVE p:Person -
批量重建:
// 创建新结构 MATCH (p:OldModel) CREATE (n:NewModel {id: p.id,name: p.name,// 转换属性newAttribute: CASE WHEN p.oldAttribute = 'value1' THEN 'newValue1' ELSE 'newValue2' END })
迁移最佳实践:
在进行数据迁移时,应遵循一系列最佳实践以确保过程顺利、安全。首先,制定详细的迁移计划,明确每一步的操作流程、时间安排以及遇到问题时的回滚策略。迁移前务必创建完整的数据备份,确保在出现意外时能够恢复原始数据。建议先在测试环境中完成迁移操作,充分验证数据的完整性和应用的兼容性,避免在生产环境中出现不可预期的问题。对于大型系统,可以采用分阶段迁移的方式,逐步推进以降低整体风险。在迁移过程中要持续监控系统状态,迁移完成后应全面核查数据,确保所有信息准确无误。同时,始终保留清晰的回滚路径,以便在迁移过程中或迁移后发现问题时能够及时恢复到原始状态。这些措施有助于保障数据迁移的安全性和可靠性。
通过掌握这些数据导出、备份和迁移技术,可以确保Neo4j数据的安全性和可移植性,为系统维护和升级提供保障。
6.5 小结
本章详细介绍了Neo4j中的数据导入与导出方法,包括小规模数据的LOAD CSV、大规模数据的批量导入、Neo4j Admin Import工具的使用,以及数据导出和备份策略。通过掌握这些技术,用户可以高效地管理图数据库中的数据,确保数据的完整性和一致性。
相关文章:

第6章:Neo4j数据导入与导出
在实际应用中,数据的导入与导出是使用Neo4j的重要环节。无论是初始数据加载、系统迁移还是数据备份,都需要高效可靠的数据传输机制。本章将详细介绍Neo4j中的各种数据导入与导出方法,帮助读者掌握不同场景下的最佳实践。 6.1 数据导入策略 …...

uni-app学习笔记二十三--交互反馈showToast用法
showToast部分文档位于uniapp官网-->API-->界面:uni.showToast(OBJECT) | uni-app官网 uni.showToast(OBJECT) 用于显示消息提示框 OBJECT参数说明 参数类型必填说明平台差异说明titleString是提示的内容,长度与 icon 取值有关。iconString否图…...

Go爬虫开发学习记录
Go爬虫开发学习记录 基础篇:使用net/http库 Go的标准库net/http提供了完善的HTTP客户端功能,是构建爬虫的基石: package mainimport ("fmt""io""net/http" )func fetchPage(url string) string {// 创建自定…...

前端异步编程全场景解读
前端异步编程是现代Web开发的核心,它解决了浏览器单线程执行带来的UI阻塞问题。以下从多个维度进行深度解析: 一、异步编程的核心概念 JavaScript的执行环境是单线程的,这意味着在同一时间只能执行一个任务。为了不阻塞主线程,J…...

分布式光纤声振传感技术原理与瑞利散射机制解析
分布式光纤传感技术(Distributed Fiber Optic Sensing,简称DFOS)作为近年来迅速发展的新型感知手段,已广泛应用于边界安防、油气管道监测、结构健康诊断、地震探测等领域。其子类技术——分布式光纤声振传感(Distribut…...
RocketMQ 客户端负载均衡机制详解及最佳实践
延伸阅读:🔍「RocketMQ 中文社区」 持续更新源码解析/最佳实践,提供 RocketMQ 专家 AI 答疑服务 前言 本文介绍 RocketMQ 负载均衡机制,主要涉及负载均衡发生的时机、客户端负载均衡对消费的影响(消息堆积/消费毛刺等…...

Q1起重机指挥理论备考要点分析
Q1起重机指挥理论备考要点分析 一、考试重点内容概述 Q1起重机指挥理论考试主要包含三大核心模块:安全技术知识(占40%)、指挥信号规范(占30%)和法规标准(占30%)。考试采用百分制,8…...

c++算法学习3——深度优先搜索
一、深度优先搜索的核心概念 DFS算法是一种通过递归或栈实现的"一条路走到底"的搜索策略,其核心思想是: 深度优先:从起点出发,选择一个方向探索到底,直到无路可走 回溯机制:遇到死路时返回最近…...

如何让非 TCP/IP 协议驱动屏蔽 IPv4/IPv6 和 ARP 报文?
——从硬件过滤到协议栈隔离的完整指南 引言 在现代网络开发中,许多场景需要定制化网络协议(如工业控制、高性能计算),此时需确保驱动仅处理特定协议,避免被标准协议(如 IPv4/IPv6/ARP)干扰。本文基于 Linux 内核驱动的实现,探讨如何通过硬件过滤、驱动层拦截和协议栈…...

组合模式:构建树形结构的艺术
引言:处理复杂对象结构的挑战 在软件开发中,我们常遇到需要处理部分-整体层次结构的场景: 文件系统中的文件与文件夹GUI中的容器与组件组织结构中的部门与员工菜单系统中的子菜单与菜单项组合模式正是为解决这类问题而生的设计模式。它允许我们将对象组合成树形结构来表示&…...

【SSM】SpringMVC学习笔记7:前后端数据传输协议和异常处理
这篇学习笔记是Spring系列笔记的第7篇,该笔记是笔者在学习黑马程序员SSM框架教程课程期间的笔记,供自己和他人参考。 Spring学习笔记目录 笔记1:【SSM】Spring基础: IoC配置学习笔记-CSDN博客 对应黑马课程P1~P20的内容。 笔记2…...

Spring Boot SQL数据库功能详解
Spring Boot自动配置与数据源管理 数据源自动配置机制 当在Spring Boot项目中添加数据库驱动依赖(如org.postgresql:postgresql)后,应用启动时自动配置系统会尝试创建DataSource实现。开发者只需提供基础连接信息: 数据库URL格…...

TI德州仪器TPS3103K33DBVR低功耗电压监控器IC电源管理芯片详细解析
1. 基本介绍 TPS3103K33DBVR 是 德州仪器(Texas Instruments, TI) 推出的一款 低功耗电压监控器(Supervisor IC),属于 电源管理芯片(PMIC) 类别,主要用于 系统复位和电压监测。 2. …...
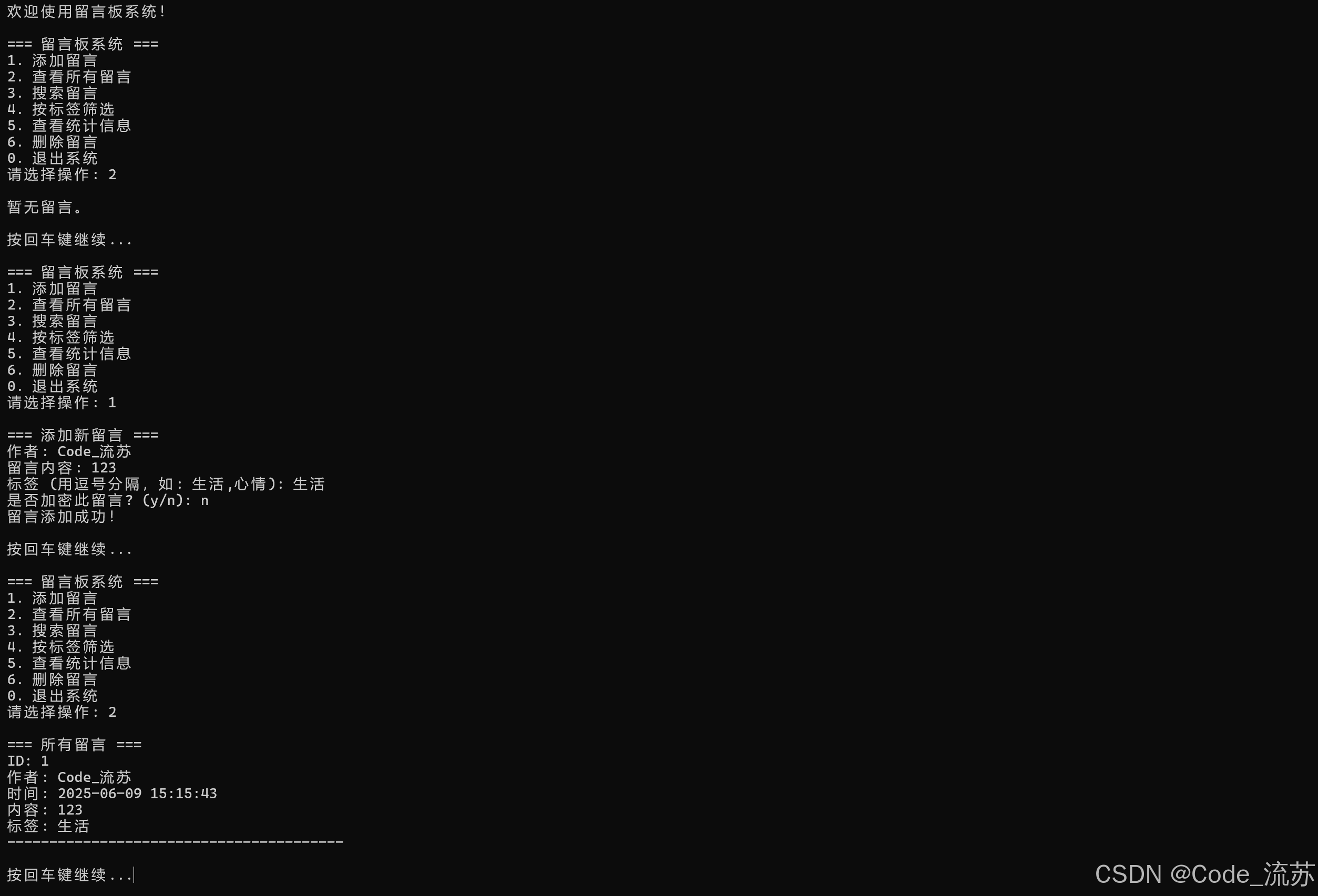
C++课设:实现本地留言板系统(支持留言、搜索、标签、加密等)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、项目功能概览与亮点分析1. 核心功能…...
【见合八方平面波导外腔激光器专题系列】用于干涉光纤传感的低噪声平面波导外腔激光器2
----翻译自Mazin Alalus等人的文章 摘要 1550 nm DWDM 平面波导外腔激光器具有低相位/频率噪声、窄线宽和低 RIN 等特点。该腔体包括一个半导体增益芯片和一个带布拉格光栅的平面光波电路波导,采用 14 引脚蝶形封装。这种平面波导外腔激光器设计用于在振动和恶劣的…...
Xcode 16.2 版本 pod init 报错
Xcode 版本升级到 16.2 后,项目执行 pod init 报错; ### Error RuntimeError - PBXGroup attempted to initialize an object with unknown ISA PBXFileSystemSynchronizedRootGroup from attributes: {"isa">"PBXFileSystemSynchron…...
timestamp时间戳转换工具
作为一名程序员,一款高效的 在线转换工具 (在线时间戳转换 计算器 字节单位转换 json格式化)必不可少!https://jsons.top 排查问题时非常痛的点: 经常在秒级、毫秒级、字符串格式的时间单位来回转换,于是决定手撸一个…...

分布式计算框架学习笔记
一、🌐 为什么需要分布式计算框架? 资源受限:单台机器 CPU/GPU 内存有限。 任务复杂:模型训练、数据处理、仿真并发等任务耗时严重。 并行优化:通过任务拆分和并行执行提升效率。 可扩展部署:适配从本地…...
数据库管理与高可用-MySQL故障排查与生产环境优化
目录 #1.1MySQL单案例故障排查 1.1.1MySQL常见的故障排查 1.1.2MySQL主从故障排查 #2.1MySQL优化 2.1.1硬件方面的优化 2.1.2进程方面的优化 #3.1MySQL存储引擎 3.1.1 MyISAM存储引擎 3.1.2 InnoDB存储引擎 1.1MySQL单案例故障排查 1.1.1MySQL常见的故障排查 (1&…...

rk3506上移植lvgl应用
本文档介绍如何在开发板上运行以及移植LVGL。 1. 移植准备 硬件环境:开发板及其配套屏幕 开发板镜像 主机环境:Ubuntu 22.04.5 2. LVGL启动 出厂系统默认配置了 LVGL,并且上电之后默认会启动 一个LVGL应用 。 LVGL 的启动脚本为/etc/init.d/pre_init/S00-lv_demo,…...

Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术点解析
Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术点解析 第一轮:基础概念问题 请解释Spring框架的核心容器是什么?它的作用是什么? 程序员JY回答:Spring框架的核心容器是IoC容器(控制反转…...

Flask和Django,你怎么选?
Flask 和 Django 是 Python 两大最流行的 Web 框架,但它们的设计哲学、目标和适用场景有显著区别。以下是详细的对比: 核心区别:哲学与定位 Django: 定位: "全栈式" Web 框架。奉行"开箱即用"的理念。 哲学: "包含…...
LangChain + LangSmith + DeepSeek 入门实战:构建代码生成助手
本文基于 Jupyter Notebook 实践代码,结合 LangChain、LangSmith 和 DeepSeek 大模型,手把手演示如何构建一个代码生成助手,并实现全流程追踪与优化。 一、环境准备与配置 1. 安装依赖 pip install langchain langchain_openai2. 设置环境变…...

湖北理元理律师事务所:债务清偿方案中的法律技术革新
文/金融法律研究组 当前债务服务市场存在结构性矛盾:债权人追求快速回款,债务人需要喘息空间。湖北理元理律师事务所通过创新法律技术,在《企业破产法》《民法典》框架下构建梯度清偿模型,实现多方利益平衡。 一、个人债务优化的…...

大模型的LoRa通讯详解与实现教程
一、LoRa通讯技术概述 LoRa(Long Range)是一种低功耗广域网(LPWAN)通信技术,由Semtech公司开发,特别适合于物联网设备的长距离、低功耗通信需求。LoRa技术基于扩频调制技术,能够在保持低功耗的同时实现数公里甚至数十公里的通信距离。 LoRa的主要特点 长距离通信:在城…...
【Elasticsearch基础】Elasticsearch批量操作(Bulk API)深度解析与实践指南
目录 1 Bulk API概述 1.1 什么是批量操作 1.2 Bulk API的优势 2 Bulk API的工作原理 2.1 请求处理流程 2.2 底层机制 3 Bulk API的使用方法 3.1 基本请求格式 3.2 操作类型示例 3.3 响应格式 4 Bulk API的最佳实践 4.1 批量大小优化 4.2 错误处理策略 4.3 性能调…...

PCA笔记
✅ 问题本质:为什么让矩阵 TT 的行列式为 1? 这个问题通常出现在我们对数据做**线性变换(旋转/缩放)**的时候,比如在 PCA 中把数据从原始坐标系变换到主成分方向时。 📌 回顾一下背景 在 PCA 中ÿ…...
MySQL 数据库深度剖析:事务、SQL 优化、索引与 Buffer Pool
在当今数据驱动的时代,数据库作为数据存储与管理的核心,其性能与可靠性至关重要。MySQL 作为一款广泛使用的开源数据库,在众多应用场景中发挥着关键作用。在这篇博客中,我将围绕 MySQL 数据库的核心知识展开,涵盖事务及…...
MAZANOKE结合内网穿透技术实现跨地域图像优化服务的远程访问过程
文章目录 前言1. 关于MAZANOKE2. Docker部署3. 简单使用MAZANOKE4. 安装cpolar内网穿透5. 配置公网地址6. 配置固定公网地址总结 前言 在数字世界高速发展的今天,您是否察觉到那些静默增长的视觉数据正在悄然蚕食存储空间?随着影像记录成为日常习惯&…...

迁移科技3D视觉系统:重塑纸箱拆垛场景的智能革命
一、传统拆垛场景的困局与破局之道 在汽车零部件仓库中,每天有超过2万只异形纸箱需要拆垛分拣。传统人工拆垛面临三大挑战: 效率瓶颈:工人每小时仅能处理200-300件,且存在间歇性疲劳安全隐患:20kg以上重箱搬运导致年…...