MySQL 数据库深度剖析:事务、SQL 优化、索引与 Buffer Pool
在当今数据驱动的时代,数据库作为数据存储与管理的核心,其性能与可靠性至关重要。MySQL 作为一款广泛使用的开源数据库,在众多应用场景中发挥着关键作用。在这篇博客中,我将围绕 MySQL 数据库的核心知识展开,涵盖事务及隔离级别、SQL 优化、索引结构以及 Buffer Pool 等关键领域,为你呈现全面且深入的技术干货。
一、事务与事务隔离级别
1.1 事务的特性
事务是数据库操作的一个逻辑单元,由一组相关的数据库操作组成,这些操作要么全部成功执行,要么全部不执行,就像一个不可分割的原子。事务具有四个重要特性,常被简称为 ACID:
- 原子性(Atomicity):事务中的所有操作要么全部完成,要么全部不完成,不存在部分成功的情况。例如,在一个银行转账事务中,从账户 A 扣除金额和向账户 B 添加金额这两个操作必须作为一个整体执行,要么都成功,要么都失败,以确保数据的一致性。
- 一致性(Consistency):事务执行前后,数据库的完整性约束不会被破坏。比如,在转账事务中,转账前后账户 A 和账户 B 的总金额应该保持不变,这就是一致性的体现。
- 隔离性(Isolation):一个事务的执行不能被其他事务干扰。不同事务并发执行时,每个事务都感觉不到其他事务的存在,就好像它们是在串行执行一样。
- 持久性(Durability):一旦事务提交成功,其所做的修改将永久保存在数据库中,即使系统发生故障也不会丢失。
1.2 事务的隔离级别
在多事务并发执行的环境中,为了平衡性能与数据一致性,SQL 标准定义了四种事务隔离级别,不同的隔离级别对并发事务的可见性和数据一致性有不同的保证程度:
- 读未提交(Read Uncommitted):这是最低的隔离级别。在该级别下,一个事务可以读取到另一个未提交事务修改的数据。这种隔离级别可能导致脏读(Dirty Read),即读取到了其他事务尚未提交的 “脏数据”,一旦该事务回滚,读取到的数据就变得无效了。由于其隔离性较差,在实际应用中很少使用。
- 读已提交(Read Committed):大多数主流数据库的默认隔离级别。在这个级别下,一个事务只能读取到其他已经提交事务修改的数据,避免了脏读问题。但在同一事务中多次读取同一数据时,如果其他事务在这期间对该数据进行了修改并提交,可能会导致不可重复读(Non - Repeatable Read),即多次读取结果不一致。
- 可重复读(Repeatable Read):在该隔离级别下,一个事务在整个执行过程中,对同一数据的多次读取结果始终保持一致,即使其他事务在这期间对该数据进行了修改并提交。这解决了不可重复读问题。MySQL 的默认隔离级别就是可重复读,并且通过多版本并发控制(MVCC)机制,在一定程度上也避免了幻读(Phantom Read)问题。幻读是指在一个事务中多次执行相同的查询条件,却发现每次返回的结果集不一样,好像出现了 “幻影” 数据,这是因为其他事务在该事务执行期间插入或删除了符合查询条件的数据。
- 串行化(Serializable):最高的隔离级别。在串行化隔离级别下,事务串行执行,避免了所有并发问题,包括脏读、不可重复读和幻读。但由于所有事务依次执行,并发性能最低,系统开销最大,通常只在对数据一致性要求极高且并发量较低的场景中使用。
选择合适的事务隔离级别需要综合考虑应用场景的并发需求和数据一致性要求。如果应用对并发性能要求较高,而对数据一致性的一些小瑕疵可以容忍,那么可以选择较低的隔离级别;反之,如果数据一致性至关重要,则需要选择较高的隔离级别。
二、SQL 性能优化:让查询飞起来
在数据库开发中,经常会遇到 SQL 语句执行效率低下的问题。当组长交给你一个运行缓慢的 SQL 语句,要求进行优化时,该从哪些方面入手呢?下面介绍一些常用的 SQL 优化方法:
2.1 使用 EXPLAIN 工具分析查询计划
EXPLAIN 是 MySQL 提供的一个强大工具,用于分析 SQL 查询语句的执行计划。通过它,我们可以了解 MySQL 是如何执行查询的,包括表的连接顺序、使用的索引、扫描的行数等信息。这些信息对于发现查询性能瓶颈至关重要。例如,执行以下 SQL 语句:
EXPLAIN SELECT * FROM users WHERE age > 30 AND city = 'Beijing';EXPLAIN 的输出结果会包含多个字段,其中一些重要字段的含义如下:
- id:查询中执行的顺序标识符,相同的 id 表示在同一层次的查询中按顺序执行。
- select_type:表示查询的类型,常见的有 SIMPLE(简单查询,不包含子查询或 UNION)、PRIMARY(主查询,包含子查询的最外层查询)等。
- table:显示这一步操作涉及的表。
- type:表示表的连接类型,如 ALL(全表扫描)、index(索引扫描)、range(范围扫描)等,其中 ALL 是性能最差的连接类型,应尽量避免。
- possible_keys:显示可能用于该查询的索引。
- key:实际使用的索引,如果为 NULL,表示没有使用索引。
- key_len:使用的索引长度。
- rows:MySQL 估算的为了找到所需的行而要扫描的行数,该值越小越好。
- Extra:额外信息,如 Using where 表示使用了 WHERE 条件过滤数据,Using temporary 表示创建了临时表来处理查询等。
通过分析 EXPLAIN 的输出结果,我们可以判断查询是否使用了合适的索引,是否存在全表扫描等性能问题,并针对性地进行优化。
2.2 索引优化:为查询加速
索引是提高数据库查询效率的关键工具。合理创建和使用索引可以显著减少查询所需的时间。在优化 SQL 时,确保查询字段存在索引是非常重要的。例如,对于上面的查询语句,如果 age 和 city 字段上没有索引,MySQL 可能会进行全表扫描,导致查询效率低下。我们可以为这两个字段创建索引:
CREATE INDEX idx_age_city ON users(age, city);在创建索引时,需要注意以下几点:
- 选择合适的列:为经常用于查询条件、排序、分组的列创建索引。例如,如果经常按照用户的年龄和所在城市查询用户信息,那么为 age 和 city 字段创建索引是合适的。
- 避免过多索引:虽然索引可以提高查询性能,但过多的索引会增加数据插入、更新和删除的时间,因为数据库在执行这些操作时,不仅要更新数据,还要更新相关的索引。所以,只在必要的列上创建索引。
- 前缀索引:对于较长的字符串字段,可以使用前缀索引来减少索引占用的空间。例如,对于一个很长的 text 类型字段,如果只需要根据前几个字符进行查询,可以创建前缀索引:
CREATE INDEX idx_text ON table_name(text(10));这表示只对 text 字段的前 10 个字符创建索引。
2.3 查询结构优化
- 避免全表查询:尽量避免使用SELECT *语句,只查询需要的列。例如,将SELECT * FROM users;改为SELECT id, name, age FROM users;,这样可以减少数据传输量和查询时间,并且有可能使用覆盖索引(Covering Index),即索引中已经包含了查询所需的所有数据,无需回表查询。
- 减少子查询依赖:子查询在某些情况下会导致性能问题,尤其是嵌套子查询。可以尝试使用连接(JOIN)或临时表来替代子查询。例如,有以下子查询:
SELECT * FROM orders WHERE customer_id IN (SELECT id FROM customers WHERE country = 'USA');可以改写为连接查询:
SELECT orders.* FROM ordersJOIN customers ON orders.customer_id = customers.idWHERE customers.country = 'USA';通常情况下,连接查询的性能会优于子查询。
2.4 分页查询优化
在处理分页查询时,如果数据量较大,简单的 LIMIT 分页可能会出现性能问题。例如:
SELECT * FROM products LIMIT 10000, 10;随着偏移量(10000)的增大,查询时间会越来越长。这是因为 MySQL 需要跳过前面的 10000 条记录,然后再返回后面的 10 条记录。为了优化分页查询,可以采用以下方法:
- 基于主键的分页:如果表中有主键,可以利用主键的有序性进行分页。例如:
SELECT * FROM productsWHERE id > (SELECT id FROM products LIMIT 10000, 1)LIMIT 10;这种方法通过先查询出第 10001 条记录的主键值,然后再根据主键值进行查询,避免了大量的记录跳过操作。
- 批量数据处理:对于大数据量的分页,可以采用批量处理的方式,每次返回一部分数据,减少单次查询的数据量。例如,将一次返回 1000 条数据改为每次返回 100 条数据,分多次请求,这样可以提高响应速度。
-
三、MySQL 索引及其数据结构 B+Tree
3.1 索引的作用
索引就像是一本书的目录,它可以帮助 MySQL 更快速地定位和检索数据。在没有索引的情况下,MySQL 在执行查询时可能需要扫描整个表,逐行比较数据,这种全表扫描的方式在数据量较大时效率非常低。而有了索引,MySQL 可以根据索引快速定位到符合条件的数据行,大大减少了磁盘 I/O 操作,提高了查询速度。
3.2 B+Tree 数据结构
B+Tree 是 MySQL 中最常用的索引数据结构,它具有以下特点:
- 节点结构:B+Tree 的节点分为叶子节点和非叶子节点。非叶子节点仅存储索引键值,不存储实际数据,叶子节点存储了所有的数据记录,并且叶子节点之间通过双向链表相连。
- 数据存储与查询:在 B+Tree 中,所有数据都存储在叶子节点上,非叶子节点用于引导数据的查找。当进行查询时,从根节点开始,根据索引键值逐层向下查找,直到找到对应的叶子节点。由于叶子节点是有序的,并且通过链表相连,所以范围查询(如WHERE age BETWEEN 20 AND 30)在 B+Tree 上非常高效,只需要遍历相应范围内的叶子节点即可。
- 磁盘 I/O 优化:B+Tree 的设计充分考虑了磁盘 I/O 的效率。每个节点通常对应一个磁盘块,由于非叶子节点不存储实际数据,使得单个节点可以存储更多的索引项,从而减少了树的高度。一般来说,三层的 B+Tree 就可以存储大量的数据,并且查询时通常只需要进行 3 次磁盘 I/O 操作(根节点、中间节点、叶子节点),大大提高了查询性能。
3.3 B+Tree 与其他数据结构的比较
与其他常见的数据结构相比,B+Tree 在数据库索引场景中具有明显的优势:
- 二叉搜索树(Binary Search Tree):在理想情况下,二叉搜索树可以通过比较节点值实现高效的查找,但在最坏的情况下,如果插入顺序导致二叉搜索树退化为链表形态,则查询效率会大大降低,时间复杂度从 O (log n) 变为 O (n)。
- 平衡二叉树(如 AVL 树、红黑树):平衡二叉树通过自我调整保持左右子树高度差不超过 1,确保了查询效率的稳定性,时间复杂度始终为 O (log n)。然而,由于每个节点只能存储少量数据(例如一个元素),对于 MySQL 这样的数据库系统来说,单位磁盘块中包含的有效数据过少,会导致 I/O 操作频繁,查询性能不高。
- B 树:B 树与 B+Tree 类似,但 B 树的非叶子节点也存储数据,这使得 B 树在相同节点大小的情况下,存储的索引项比 B+Tree 少,树的高度相对较高,从而增加了查询时的 I/O 操作次数。
综上所述,B+Tree 由于其高效的磁盘 I/O 利用和对范围查询的良好支持,成为了 MySQL 索引的首选数据结构。
四、MySQL 中的 Buffer Pool
4.1 Buffer Pool 是什么
MySQL 的 Buffer Pool 是 InnoDB 存储引擎的一个重要组件,它是一块内存缓存区,用于暂存数据页和索引页。当 MySQL 需要读取数据时,首先会在 Buffer Pool 中查找,如果找到了所需的数据页(称为命中),则直接从内存中读取,避免了磁盘 I/O 操作,大大提高了查询性能;如果在 Buffer Pool 中没有找到(称为未命中),则从磁盘读取数据页到 Buffer Pool 中,然后再进行读取操作。同样,在数据更新时,也会先在 Buffer Pool 中修改数据页,标记为脏页(Dirty Page),然后在适当的时候将脏页刷新到磁盘上,保证数据的持久性。
4.2 Buffer Pool 的工作原理
- 数据页管理:Buffer Pool 中包含多个数据页,InnoDB 使用 LRU(最近最少使用)算法来管理这些数据页。当数据页被访问时,它会被移动到 LRU 列表的头部,表示它是最近使用过的;而长时间未被访问的数据页会逐渐移动到 LRU 列表的尾部,当 Buffer Pool 空间不足时,位于 LRU 列表尾部的数据页会被淘汰,以腾出空间来加载新的数据页。
- 脏页刷新:为了保证数据的一致性和持久性,Buffer Pool 中的脏页需要定期刷新到磁盘上。InnoDB 会根据一定的策略来决定何时刷新脏页,例如,当脏页数量达到一定比例时,或者在系统空闲时,会触发脏页刷新操作。此外,当数据库关闭时,也会将所有的脏页刷新到磁盘。
- 预读机制:为了进一步提高性能,InnoDB 还支持预读机制。当 InnoDB 发现需要连续读取多个数据页时,它会提前将相邻的数据页也读取到 Buffer Pool 中,这样可以减少后续的磁盘 I/O 操作。
- 自适应哈希索引:Buffer Pool 还支持自适应哈希索引(Adaptive Hash Index)。InnoDB 会根据查询的频繁程度,自动为某些热点数据页创建哈希索引,以加速查询。当查询命中自适应哈希索引时,查询速度可以得到极大提升。
4.3 Buffer Pool 的配置与优化
Buffer Pool 的大小是一个重要的配置参数,它直接影响到数据库的性能。一般来说,建议将 Buffer Pool 设置为服务器物理内存的 50% - 75%,具体比例需要根据服务器的实际负载和应用场景来调整。如果 Buffer Pool 设置过小,可能会导致频繁的磁盘 I/O 操作,影响查询性能;而设置过大,则可能会导致服务器内存不足,影响其他进程的运行。
除了调整 Buffer Pool 的大小,还可以通过其他方式来优化其性能,例如:
- 调整 LRU 列表参数:InnoDB 提供了一些参数来调整 LRU 列表的行为,如innodb_old_blocks_pct用于设置 LRU 列表中旧数据页的比例,innodb_old_blocks_time用于设置新读取的数据页在 LRU 列表中停留多长时间后才会被移动到旧数据页区域。合理调整这些参数可以优化 LRU 算法的性能,提高 Buffer Pool 的命中率。
- 监控与分析:通过监控 Buffer Pool 的命中率、脏页比例等指标,可以了解 Buffer Pool 的运行情况,并针对性地进行优化。MySQL 提供了一些性能视图,如INFORMATION_SCHEMA.INNODB_BUFFER_PAGE和INFORMATION_SCHEMA.INNODB_BUFFER_POOL_STATS,可以用于查看 Buffer Pool 的相关信息。
相关文章:
MySQL 数据库深度剖析:事务、SQL 优化、索引与 Buffer Pool
在当今数据驱动的时代,数据库作为数据存储与管理的核心,其性能与可靠性至关重要。MySQL 作为一款广泛使用的开源数据库,在众多应用场景中发挥着关键作用。在这篇博客中,我将围绕 MySQL 数据库的核心知识展开,涵盖事务及…...
MAZANOKE结合内网穿透技术实现跨地域图像优化服务的远程访问过程
文章目录 前言1. 关于MAZANOKE2. Docker部署3. 简单使用MAZANOKE4. 安装cpolar内网穿透5. 配置公网地址6. 配置固定公网地址总结 前言 在数字世界高速发展的今天,您是否察觉到那些静默增长的视觉数据正在悄然蚕食存储空间?随着影像记录成为日常习惯&…...

迁移科技3D视觉系统:重塑纸箱拆垛场景的智能革命
一、传统拆垛场景的困局与破局之道 在汽车零部件仓库中,每天有超过2万只异形纸箱需要拆垛分拣。传统人工拆垛面临三大挑战: 效率瓶颈:工人每小时仅能处理200-300件,且存在间歇性疲劳安全隐患:20kg以上重箱搬运导致年…...
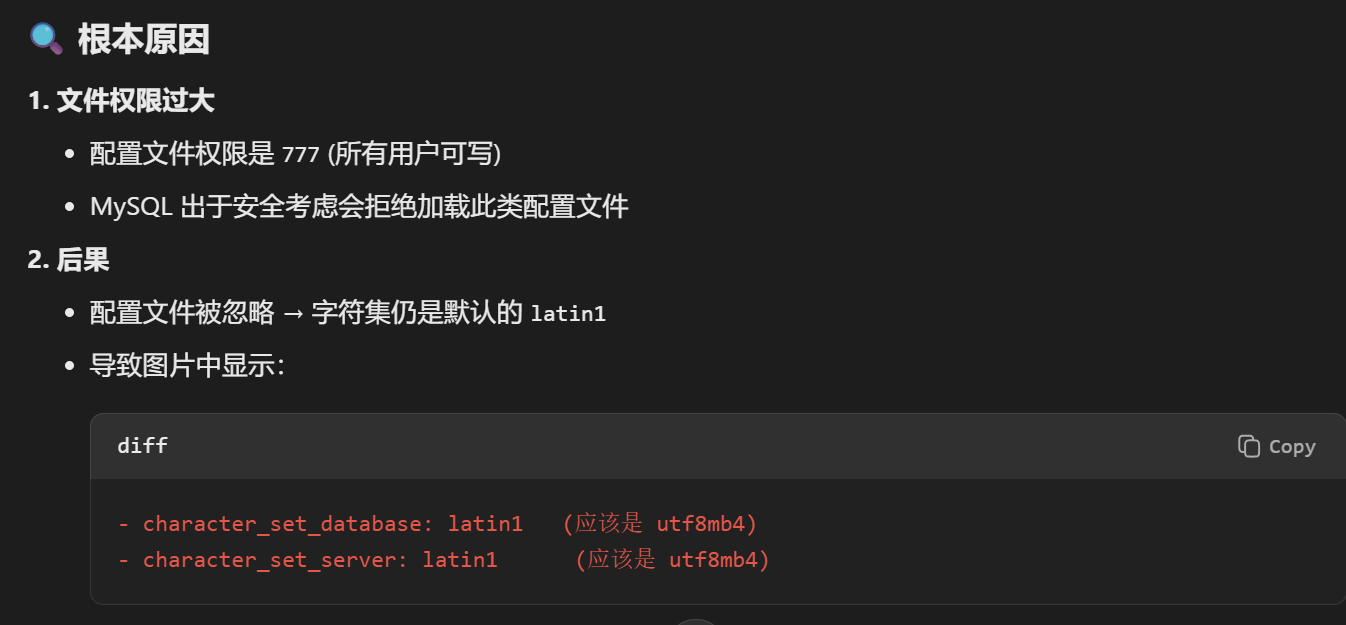
World-writable config file /etc/mysql/mysql.conf.d/my.cnf is ignored
https://stackoverflow.com/questions/53741107/mysql-in-docker-on-ubuntu-warning-world-writable-config-file-is-ignored 修改权限 -> 重启mysql # 检查字符集配置 SHOW VARIABLES WHERE Variable_name IN (character_set_server, character_set_database ); --------…...

JS的传统写法 vs 简写形式
一、条件判断与逻辑操作 三元运算符简化条件判断 // 传统写法 let result; if (someCondition) {result yes; } else {result no; }// 简写方式 const result someCondition ? yes : no;短路求值 // 传统写法 if (condition) {doSomething(); }// 简写方式 condition &…...

信息收集:从图像元数据(隐藏信息收集)到用户身份的揭秘 --- 7000
目录 🌐 访问Web服务 💻 分析源代码 ⬇️ 下载图片并保留元数据 🔍 提取元数据(重点) 👤 生成用户名列表 🛠️ 技术原理 图片元数据(EXIF 数据) Username-Anarch…...

OCC笔记:TDF_Label中有多个相同类型属性
注:OCCT版本:7.9.1 TDF_Label中有多个相同类型的属性的方案 OCAF imposes the restriction that only one attribute type may be allocated to one label. It is necessary to take into account the design of the application data tree. For exampl…...
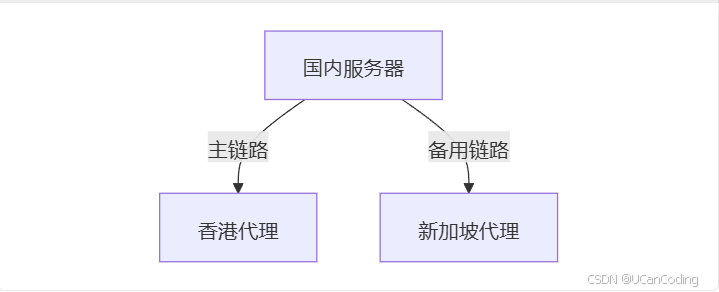
如何优雅地绕过限制调用海外AI-API?反向代理与API中转技术详解
阅读时长 | 8分钟 适用读者 | 需要跨境调用OpenAI等AI服务的开发者/企业 一、问题背景:为什么需要代理? 最近在技术社区看到这样的求助: "公司服务器在国内,但业务需要调用OpenAI接口,直接访…...
【自然语言处理】大模型时代的数据标注(主动学习)
文章目录 A 论文出处B 背景B.1 背景介绍B.2 问题提出B.3 创新点 C 模型结构D 实验设计E 个人总结 A 论文出处 论文题目:FreeAL: Towards Human-Free Active Learning in the Era of Large Language Models发表情况:2023-EMNLP作者单位:浙江大…...

React与原生事件:核心差异与性能对比解析
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...

Go 并发编程基础:select 多路复用
select 是 Go 并发编程中非常强大的语法结构,它允许程序同时等待多个通道操作的完成,从而实现多路复用机制,是协程调度、超时控制、通道竞争等场景的核心工具。 一、什么是 select select 类似于 switch 语句,但它用于监听多个通…...
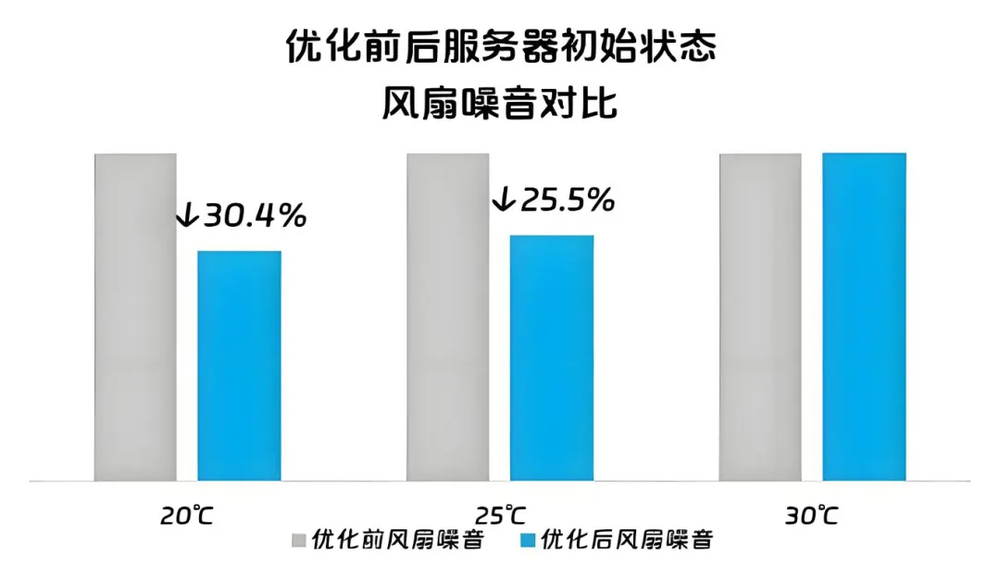
暴雨新专利解决服务器噪音与性能悖论
6月1日,我国首部数据中心绿色化评价方面国家标准《绿色数据中心评价》正式实施,为我国数据中心的绿色低碳建设提供了明确指引。《评价》首次将噪音控制纳入国家级绿色评价体系,要求从设计隔声结构到运维定期监测实现闭环管控,加速…...

Go 语言中的内置运算符
1. 算术运算符 注意: (自增)和--(自减)在 Go 语言中是单独的语句,并不是运算符。 package mainimport "fmt"func main() {fmt.Println("103", 103) // 13fmt.Println("10-3…...

Spring Boot 中实现 HTTPS 加密通信及常见问题排查指南
Spring Boot 中实现 HTTPS 加密通信及常见问题排查指南 在金融行业安全审计中,未启用HTTPS的Web应用被列为高危漏洞。通过正确配置HTTPS,可将中间人攻击风险降低98%——本文将全面解析Spring Boot中HTTPS的实现方案与实战避坑指南。 一、HTTPS 核心原理与…...

项目研究:使用 LangGraph 构建智能客服代理
概述 本教程展示了如何使用 LangGraph 构建一个智能客服代理。LangGraph 是一个强大的工具,可用于构建复杂的语言模型工作流。该代理可以自动分类用户问题、分析情绪,并根据需要生成回应或升级处理。 背景动机 在当今节奏飞快的商业环境中,…...

JS面试常见问题——数据类型篇
这几周在进行系统的复习,这一篇来说一下自己复习的JS数据结构的常见面试题中比较重要的一部分 文章目录 一、JavaScript有哪些数据类型二、数据类型检测的方法1. typeof2. instanceof3. constructor4. Object.prototype.toString.call()5. type null会被判断为Obje…...

创客匠人:如何通过创始人IP打造实现知识变现与IP变现的长效增长?
在流量红利逐渐消退的当下,创始人IP的价值愈发凸显。它不仅能够帮助中小企业及个人创业者突破竞争壁垒,还能成为企业品牌影响力的核心资产。然而,市场上IP孵化机构鱼龙混杂,如何选择一家真正具备长期价值的合作伙伴?创…...
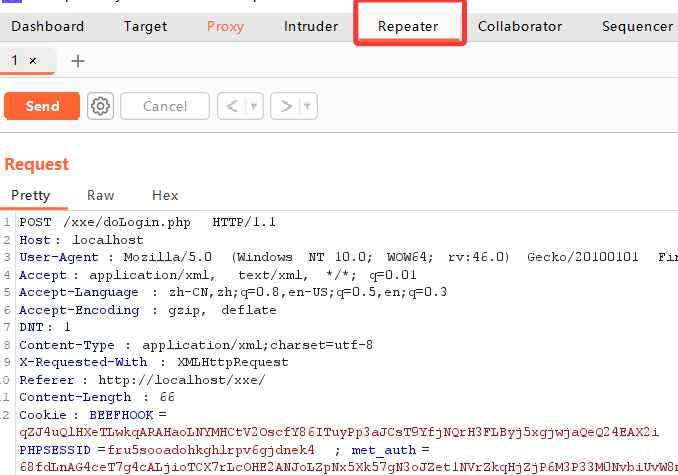
【靶场】XXE-Lab xxe漏洞
前言 学习xxe漏洞,搭了个XXE-Lab的靶场 一、搭建靶场 现在需要登录,不知道用户名密码,先随便试试抓包 二、判断是否存在xxe漏洞 1.首先登录抓包 看到xml数据解析,由此判断和xxe漏洞有关,但还不确定xxe漏洞是否存在。 2.尝试xxe 漏洞 判断是否存在xxe漏洞 A.send to …...
开源项目实战学习之YOLO11:12.6 ultralytics-models-tiny_encoder.py
👉 欢迎关注,了解更多精彩内容 👉 欢迎关注,了解更多精彩内容 👉 欢迎关注,了解更多精彩内容 ultralytics-models-sam 1.sam-modules-tiny_encoder.py2.数据处理流程3.代码架构图(类层次与依赖)blocks.py: 定义模型中的各种模块结构 ,如卷积块、残差块等基础构建…...
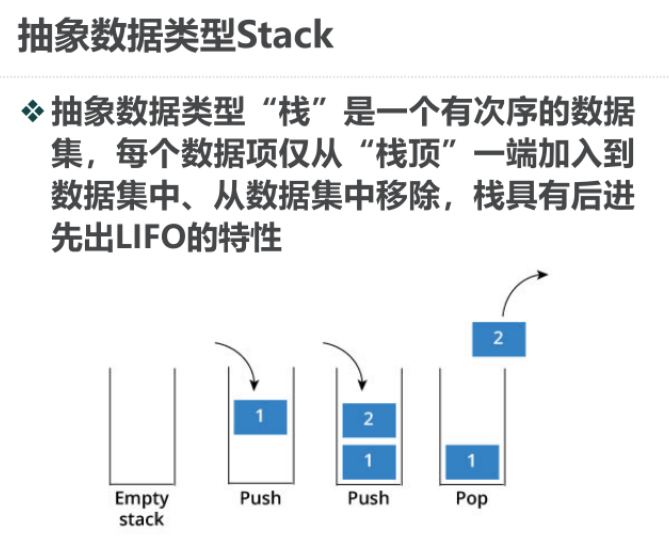
Python[数据结构及算法 --- 栈]
一.栈的概念 在 Python 中,栈(Stack)是一种 “ 后进先出(LIFO)”的数据结构,仅允许在栈顶进行插入(push)和删除(pop)操作。 二.栈的抽象数据类型 1.抽象数…...

Unity VR/MR开发-开发环境准备
视频讲解链接: 【XR马斯维】UnityVR/MR开发环境准备【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...
2025-06-08-深度学习网络介绍(语义分割,实例分割,目标检测)
深度学习网络介绍(语义分割,实例分割,目标检测) 前言 在开始这篇文章之前,我们得首先弄明白,什么是图像分割? 我们知道一个图像只不过是许多像素的集合。图像分割分类是对图像中属于特定类别的像素进行分类的过程,即像素级别的…...

Caliper 配置文件解析:config.yaml 和 fisco-bcos.json 附加在caliper中执行不同的合约方法
Caliper 配置文件解析:config.yaml 和 fisco-bcos.json Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO…...
【Ragflow】26.RagflowPlus(v0.4.0):完善解析逻辑/文档撰写模式全新升级
概述 在历经半个月的间歇性开发后,RagflowPlus再次迎来一轮升级,正式发布v0.4.0。 开源地址:https://github.com/zstar1003/ragflow-plus 更新方法 下载仓库最新代码: git clone https://github.com/zstar1003/ragflow-plus.…...

智能照明系统:具备认知能力的“光神经网络”
智能照明系统是物联网技术与传统照明深度融合的产物,其本质是通过感知环境、解析需求、自主决策的闭环控制,重构光与人、空间、环境的关系。这一系统由智能光源、多维传感器、边缘计算单元及云端管理平台构成,形成具备认知能力的“光神经网络…...

ubuntu系统 | docker+dify+ollama+deepseek搭建本地应用
1、docker 介绍与安装 docker安装:1、Ubuntu系统安装docker_ubuntu docker run-CSDN博客 docker介绍及镜像源配置:2、ubuntu系统docker介绍及镜像源和仓库配置-CSDN博客 docker常用命令:3、ubuntu系统docker常用命令-CSDN博客 docker compose安装:4、docker compose-CS…...

Docker 镜像上传到 AWS ECR:从构建到推送的全流程
一、在 EC2 实例中安装 Docker(适用于 Amazon Linux 2) 步骤 1:连接到 EC2 实例 ssh -i your-key.pem ec2-useryour-ec2-public-ip步骤 2:安装 Docker sudo yum update -y sudo amazon-linux-extras enable docker sudo yum in…...
SpringSecurity+vue通用权限系统
SpringSecurityvue通用权限系统 采用主流的技术栈实现,Mysql数据库,SpringBoot2Mybatis Plus后端,redis缓存,安全框架 SpringSecurity ,Vue3.2Element Plus实现后台管理。基于JWT技术实现前后端分离。项目开发同时采 …...

如何在Spring Boot中使用注解动态切换实现
还在用冗长的if-else或switch语句管理多个服务实现? 相信不少Spring Boot开发者都遇到过这样的场景:需要根据不同条件动态选择不同的服务实现。 如果告诉你可以完全摆脱条件判断,让Spring自动选择合适的实现——只需要一个注解,你是否感兴趣? 本文将详细介绍这种优雅的…...
短视频时长预估算法调研
weighted LR o d d s T p 1 − p ( 1 − p ) o d d s T p ( T p o d d s ∗ p ) o d d s p o d d s T o d d s odds \frac{Tp}{1-p} \newline (1-p)odds Tp \newline (Tp odds * p) odds \newline p \frac{odds}{T odds} \newline odds1−pTp(1−p)oddsTp(Tpodds…...