短视频时长预估算法调研
weighted LR
o d d s = T p 1 − p ( 1 − p ) o d d s = T p ( T p + o d d s ∗ p ) = o d d s p = o d d s T + o d d s odds = \frac{Tp}{1-p} \newline (1-p)odds = Tp \newline (Tp + odds * p) = odds \newline p = \frac{odds}{T + odds} \newline odds=1−pTp(1−p)odds=Tp(Tp+odds∗p)=oddsp=T+oddsodds
-
odds表示表示一个事件发生于不发生的比值,事件发生的几率
-
这里先对正样本进行加权,所以称作weighted LR
-
我们假设对 l o g ( o d d s ) log(odds) log(odds)进行参数化建模,其实也就是模型的logits,正常 p p p就是对logits进行sigmoid得到最后的点击率预估值,则有如下公式:
l o g ( o d d s ) = l o g ( T p 1 − p ) = W x + b T p 1 − p = e W x + b T p = e W x + b ( 1 − p ) log(odds) = log(\frac{Tp}{1-p}) = Wx + b \newline \frac{Tp}{1-p} = e^{Wx + b} \newline Tp = e^{Wx + b}(1 - p) log(odds)=log(1−pTp)=Wx+b1−pTp=eWx+bTp=eWx+b(1−p)
- 因为 p p p很小,所以有
E ( p ) ≈ e W x + b E(p) \approx e^{Wx+b} E(p)≈eWx+b
5. 也就是时长预估等于对最后的logits取exp
D2Q
- D2Q根据视频时长将视频划分为不同的组,在组内利用传统的回归模型进行预测,来减轻时长本身的偏差。
- 时长的顺序关系和条件依赖问题没有解决。
树回归
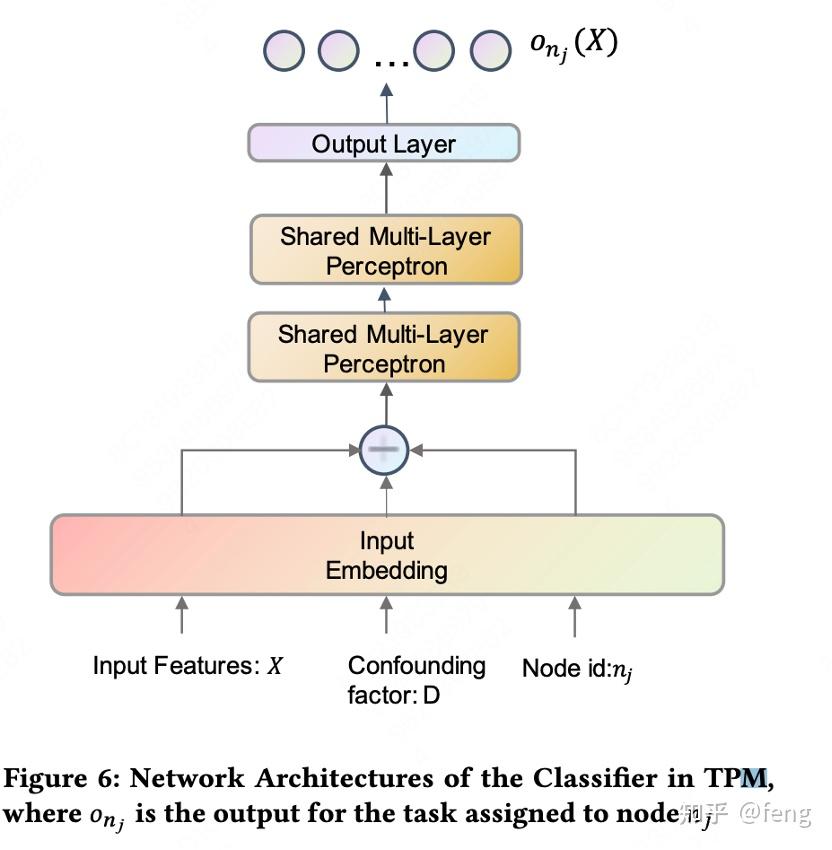
- 构建二叉树对时长进行分段,每个非叶子结点都是一个二分类器。2)文章的loss里面包含了分段预估的方差loss,这个方差其实就是在利用分段的顺序性
CREAD
整体的模型结构是比较基础的,就是一般的序列建模+分类预测。
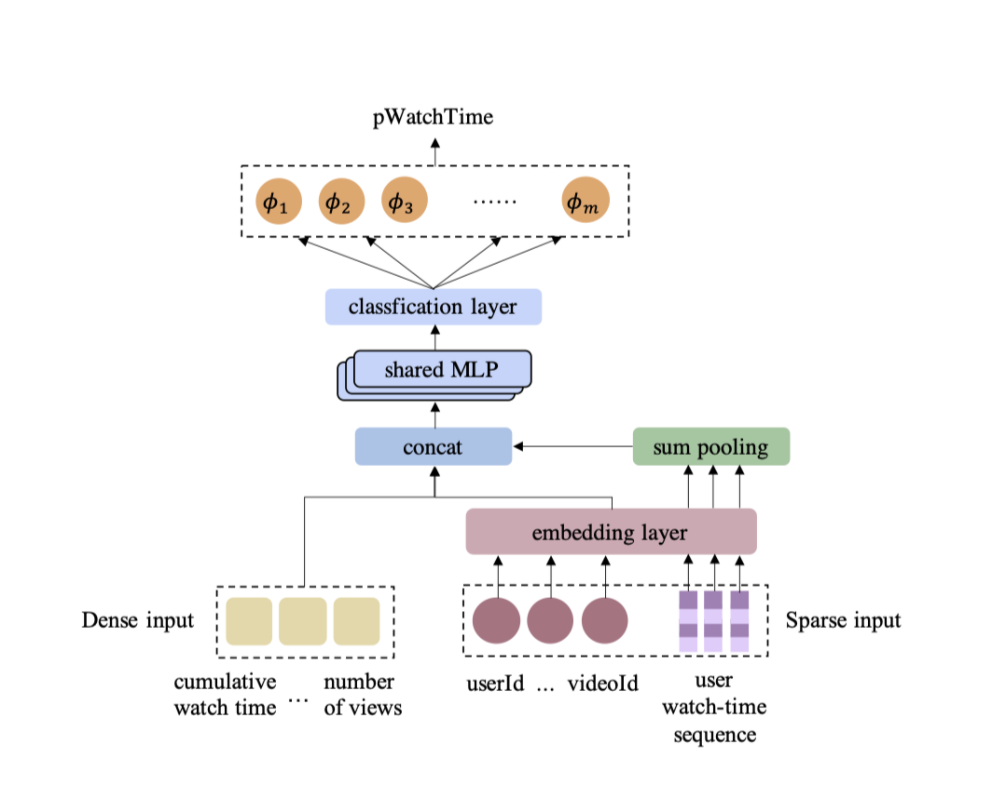
Discretization
离散化:该模块是一个独立于训练和评估过程的预处理模块。它根据数据分布获得阈值集合 { t m } m = 1 M − 1 , 并将目标域 Y 划分为 M 个互不重叠的区间 D ≜ { d m = [ t m − 1 , t m ) } m = 1 M . 这些区间用于将观看时长 y 转换为 m 个离散化的标签。 \text{离散化:}\text{该模块是一个独立于训练和评估过程的预处理模块。它根据数据分布获得阈值集合} \ \{t_{m}\}_{m=1}^{M-1}, \\ \text{并将目标域} \ \mathcal{Y} \ \text{划分为} \ M \ \text{个互不重叠的区间} \ D \triangleq \{d_{m}=[t_{m-1}, t_{m})\}_{m=1}^{M}. \\ \text{这些区间用于将观看时长} \ y \ \text{转换为} \ m \ \text{个离散化的标签。} 离散化:该模块是一个独立于训练和评估过程的预处理模块。它根据数据分布获得阈值集合 {tm}m=1M−1,并将目标域 Y 划分为 M 个互不重叠的区间 D≜{dm=[tm−1,tm)}m=1M.这些区间用于将观看时长 y 转换为 m 个离散化的标签。 y m = 1 ( y > t m ) y_m = \textbf1(y > t_m) ym=1(y>tm)
Classification
分类 : M 个分类器被训练用于预测观看时长 y 是否大于第 m 个阈值 t m , 即公式(1)中的 y m , 并输出一系列概率: 分类: M \ \text{个分类器被训练用于预测观看时长} \ y \ \text{是否大于第} \ m \ \text{个阈值} \ t_{m}, \ \text{即公式(1)中的} \ y_{m}, \ \text{并输出一系列概率:} 分类:M 个分类器被训练用于预测观看时长 y 是否大于第 m 个阈值 tm, 即公式(1)中的 ym, 并输出一系列概率: ϕ ^ m ( x i ; Θ m ) = P ( y > t m ∣ x i ) , 1 ≤ i ≤ N . \hat{\phi}_m(\boldsymbol{x}_i; \Theta_m) = P(y > t_m | \boldsymbol{x}_i), \quad 1 \leq i \leq N. ϕ^m(xi;Θm)=P(y>tm∣xi),1≤i≤N.
Restoration
给定 { ϕ ^ m } m = 1 M , 我们能够恢复预测的观看时长。恢复过程基于期望值的以下事实: \text{给定} \ \{\hat{\phi}_m\}_{m=1}^M, \ \text{我们能够恢复预测的观看时长。恢复过程基于期望值的以下事实:} 给定 {ϕ^m}m=1M, 我们能够恢复预测的观看时长。恢复过程基于期望值的以下事实: E ( y ∣ x i ) = ∫ t = 0 t M t P ( y = t ∣ x i ) d t = ∫ t = 0 t M P ( y > t ∣ x i ) d t ≈ ∑ m = 1 M P ( y > t m ∣ x i ) ( t m − t m − 1 ) . \begin{aligned} \mathbb{E}(y|\boldsymbol{x}_i) &= \int_{t=0}^{t_M} t P(y = t|\boldsymbol{x}_i) dt \\ &= \int_{t=0}^{t_M} P(y > t|\boldsymbol{x}_i) dt \\ &\approx \sum_{m=1}^M P(y > t_m|\boldsymbol{x}_i) (t_m - t_{m-1}). \end{aligned} E(y∣xi)=∫t=0tMtP(y=t∣xi)dt=∫t=0tMP(y>t∣xi)dt≈m=1∑MP(y>tm∣xi)(tm−tm−1).
从第一步到第二步有一些跳跃,但是是等价的,我这里也推导出来:
期望值的积分表达式
题目中的第一个公式为:
E ( y ∣ x i ) = ∫ 0 t M t P ( y = t ∣ x i ) d t , \mathbb{E}(y|\boldsymbol{x}_i) = \int_{0}^{t_M} t P(y = t|\boldsymbol{x}_i) dt, E(y∣xi)=∫0tMtP(y=t∣xi)dt,
其中 P ( y = t ∣ x i ) P(y = t|\boldsymbol{x}_i) P(y=t∣xi) 表示条件概率密度函数(若 y y y 是连续型变量)。
生存函数的积分形式
对于非负随机变量 ( y ),其期望值可以表示为生存函数的积分:
E ( y ∣ x i ) = ∫ 0 t M P ( y > t ∣ x i ) d t . \mathbb{E}(y|\boldsymbol{x}_i) = \int_{0}^{t_M} P(y > t|\boldsymbol{x}_i) dt. E(y∣xi)=∫0tMP(y>t∣xi)dt.
这一转换的依据是
∫ 0 t M P ( y > t ∣ x i ) d t = ∫ 0 t M ( ∫ t t M P ( y = s ∣ x i ) d s ) d t . \int_{0}^{t_M} P(y > t|\boldsymbol{x}_i) dt = \int_{0}^{t_M} \left( \int_{t}^{t_M} P(y = s|\boldsymbol{x}_i) ds \right) dt. ∫0tMP(y>t∣xi)dt=∫0tM(∫ttMP(y=s∣xi)ds)dt.
通过交换积分顺序(Fubini定理),变为:
∫ 0 t M ( ∫ 0 s d t ) P ( y = s ∣ x i ) d s = ∫ 0 t M s P ( y = s ∣ x i ) d s , \int_{0}^{t_M} \left( \int_{0}^{s} dt \right) P(y = s|\boldsymbol{x}_i) ds = \int_{0}^{t_M} s P(y = s|\boldsymbol{x}_i) ds, ∫0tM(∫0sdt)P(y=s∣xi)ds=∫0tMsP(y=s∣xi)ds,
这正是原期望的表达式。因此,两式等价。
于是最终我们有:
y ^ = ∑ m = 1 M ϕ ^ m ( t m − t m − 1 ) . \hat{y} = \sum_{m=1}^{M} \hat{\phi}_m (t_m - t_{m-1}). y^=m=1∑Mϕ^m(tm−tm−1).
EMD
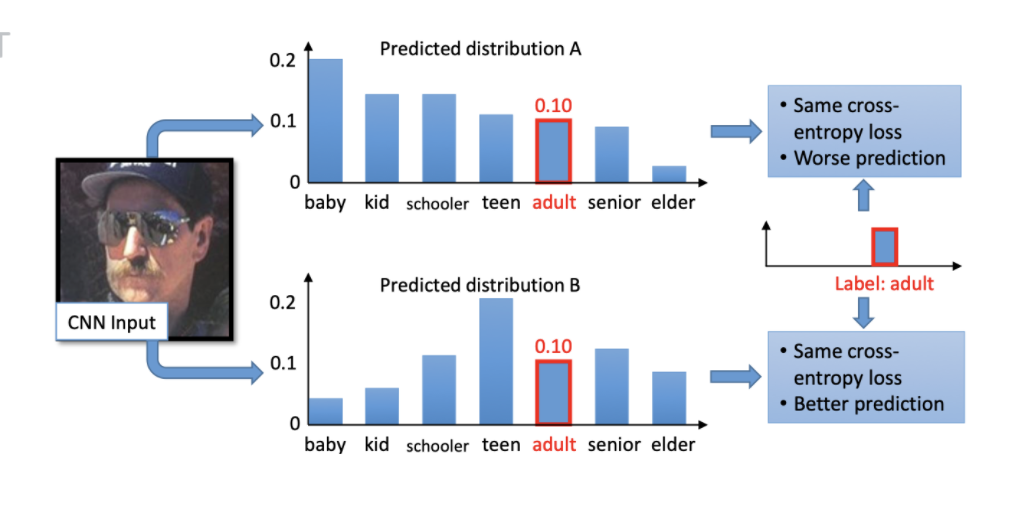
这篇论文其实是用来解决存在类别间依赖的分类问题,可以很方便的替换掉传统交叉熵,而且可以和Distill softmax进行配合使用。
EMD距离
EMD被定义为将一个分布(直方图)的质量运输到另一个分布的最小成本。 质量运输定义了从一组供应商簇向一组消费者簇运输质量的问题。其正式定义为: 设 p = { ( a 1 , p 1 ) , ( a 2 , p 2 ) , … , ( a C , p C ) } 为供应商签名(分布或直方图),包含 C 个簇(箱),其中 a i 表示每个簇, p i 表示每个簇中的质量(值)。设 t = { ( b 1 , t 1 ) , ( b 2 , t 2 ) , … , ( b C ′ , t C ′ ) } 为消费者签名。 设 D 为基距离矩阵,其中其 i , j 项 D i , j 表示 a i 和 b j 之间的距离。矩阵 D 通常定义为簇之间的l范数距离: D i , j = ∣ ∣ a i − b j ∣ ∣ l ( 2 ) \text{EMD被定义为将一个分布(直方图)的质量运输到另一个分布的最小成本。} \\ \\ \text{质量运输定义了从一组供应商簇向一组消费者簇运输质量的问题。其正式定义为:} \\ \text{设} \ \mathbf{p} = \{(\mathbf{a}_1, p_1), (\mathbf{a}_2, p_2), \ldots, (\mathbf{a}_C, p_C)\} \ \text{为供应商签名(分布或直方图),包含} \ C \ \text{个簇(箱),其中} \\ \mathbf{a}_i \ \text{表示每个簇,} \ p_i \ \text{表示每个簇中的质量(值)。} \text{设} \ \mathbf{t} = \{(\mathbf{b}_1, t_1), (\mathbf{b}_2, t_2), \ldots, (\mathbf{b}_{C'}, t_{C'})\} \ \text{为消费者签名。} \\ \text{设} \ \mathbf{D} \ \text{为基距离矩阵,其中其} \ i, j \ \text{项} \ \mathbf{D}_{i,j} \ \text{表示} \ \mathbf{a}_i \ \text{和} \ \mathbf{b}_j \ \text{之间的距离。矩阵} \ \mathbf{D} \ \text{通常定义为簇之间的l范数距离:} \\ \mathbf{D}_{i,j} = ||\mathbf{a}_i - \mathbf{b}_j||_l \quad (2) EMD被定义为将一个分布(直方图)的质量运输到另一个分布的最小成本。质量运输定义了从一组供应商簇向一组消费者簇运输质量的问题。其正式定义为:设 p={(a1,p1),(a2,p2),…,(aC,pC)} 为供应商签名(分布或直方图),包含 C 个簇(箱),其中ai 表示每个簇, pi 表示每个簇中的质量(值)。设 t={(b1,t1),(b2,t2),…,(bC′,tC′)} 为消费者签名。设 D 为基距离矩阵,其中其 i,j 项 Di,j 表示 ai 和 bj 之间的距离。矩阵 D 通常定义为簇之间的l范数距离:Di,j=∣∣ai−bj∣∣l(2) 设 F 为运输矩阵,其中其 i , j 项 F i , j 表示从 a i 运输到 b j 的质量。有效的运输需满足以下四个约束条件: 第一,运输的质量必须为正: F i , j ≥ 0 对所有 i , j . ( 3 ) 第二,从供应商簇 p i 运输的质量不得超过其总质量: ∑ j = 1 C ′ F i , j ≤ p i 对所有 i . ( 4 ) 第三,运输到消费者簇 t j 的质量不得超过其总质量: ∑ i = 1 C F i , j ≤ t j 对所有 j . ( 5 ) 第四,总流量不得超过可运输的总质量: ∑ i = 1 C ∑ j = 1 C ′ F i , j = min ( ∑ i = 1 C p i , ∑ j = 1 C ′ t i ) . ( 6 ) 在上述约束条件下,定义流量 F 的总成本为: W ( b , t , F ) = ∑ i = 1 C ∑ j = 1 C ′ D i , j F i , j . ( 7 ) EMD是两个向量之间的距离,记作EMD(p,t),即满足约束条件(方程3、4、5、6)的最小工作成本,通过总流量归一化。 E M D ( p , t ) = inf F ∑ i = 1 C ∑ j = 1 C ′ D i , j F i , j ∑ i = 1 C ∑ j = 1 C ′ F i , j . \text{设} \ \mathbf{F} \ \text{为运输矩阵,其中其} \ i, j \ \text{项} \ \mathbf{F}_{i,j} \ \text{表示从} \ \mathbf{a}_i \ \text{运输到} \ \mathbf{b}_j \ \text{的质量。有效的运输需满足以下四个约束条件:}\\ \text{第一,运输的质量必须为正:} \\ \mathbf{F}_{i,j} \geq 0 \quad \text{对所有} \ i, j. \quad (3) \\ \text{第二,从供应商簇} \ p_i \ \text{运输的质量不得超过其总质量:} \\ \sum_{j=1}^{C'} \mathbf{F}_{i,j} \leq \mathbf{p}_i \quad \text{对所有} \ i. \quad (4) \\ \text{第三,运输到消费者簇} \ t_j \ \text{的质量不得超过其总质量:} \\ \sum_{i=1}^{C} \mathbf{F}_{i,j} \leq \mathbf{t}_j \quad \text{对所有} \ j. \quad (5)\\ \text{第四,总流量不得超过可运输的总质量:} \\ \sum_{i=1}^{C} \sum_{j=1}^{C'} \mathbf{F}_{i,j} = \min\left( \sum_{i=1}^{C} \mathbf{p}_i, \sum_{j=1}^{C'} \mathbf{t}_i \right). \quad (6)\\ \text{在上述约束条件下,定义流量} \ \mathbf{F} \ \text{的总成本为:}\\ W(\mathbf{b}, \mathbf{t}, \mathbf{F}) = \sum_{i=1}^{C} \sum_{j=1}^{C'} \mathbf{D}_{i,j} \mathbf{F}_{i,j}. \quad (7) \\ \text{EMD是两个向量之间的距离,记作EMD(p,t),即满足约束条件(方程3、4、5、6)的最小工作成本,通过总流量归一化。} \\ \mathbf{EMD(p,t)=\inf _{\mathbf{F}}\frac{\sum\limits_{i=1}^{C}\sum\limits_{j=1}^{C'}\mathbf{D}_{i,j}\mathbf{F}_{i,j}}{\sum\limits_{i=1}^{C}\sum\limits_{j=1}^{C'}\mathbf{F}_{i,j}}} . 设 F 为运输矩阵,其中其 i,j 项 Fi,j 表示从 ai 运输到 bj 的质量。有效的运输需满足以下四个约束条件:第一,运输的质量必须为正:Fi,j≥0对所有 i,j.(3)第二,从供应商簇 pi 运输的质量不得超过其总质量:j=1∑C′Fi,j≤pi对所有 i.(4)第三,运输到消费者簇 tj 的质量不得超过其总质量:i=1∑CFi,j≤tj对所有 j.(5)第四,总流量不得超过可运输的总质量:i=1∑Cj=1∑C′Fi,j=min i=1∑Cpi,j=1∑C′ti .(6)在上述约束条件下,定义流量 F 的总成本为:W(b,t,F)=i=1∑Cj=1∑C′Di,jFi,j.(7)EMD是两个向量之间的距离,记作EMD(p,t),即满足约束条件(方程3、4、5、6)的最小工作成本,通过总流量归一化。EMD(p,t)=Finfi=1∑Cj=1∑C′Fi,ji=1∑Cj=1∑C′Di,jFi,j.
顺序分类的基距离矩阵
t i t_i ti和 t j t_j tj的基距离矩阵是 ∥ i − j ∥ \|i-j\| ∥i−j∥
EMD^2顺序矩分类损失
EMD被证明等价于Mallows距离,后者具有闭式解[23],前提是基距离矩阵 D 和分布 p 和 t 满足一定条件,如[23]所示。 们将展示这些条件在有序分类问题中得以满足。 第一个条件是待比较的两个分布 p 和 t 必须具有相等的质量: ∑ i p i = ∑ j t j . 若 p 由softmax层产生,则该条件恒成立,因为softmax层的输出向量是总和为1的归一化概率密度函数。由于预测分布的类别数与目标分布相同,故 C = C ′ . 第二个条件是基距离矩阵 D 必须具有一维嵌入。假设在不失一般性的前提下, p 1 , p 2 , … , p C 和 t 1 , t 2 , … , t C ′ 按其固有等级值排序,则该条件可表示为 D i , j = S ( j − i ) , 其中 S 为常数,且对所有满足 i ≤ j 的 i , j 成立。显然,在有序分类问题中该假设总能满足。 第三个也是最后一个条件是待比较的分布必须是排序后的向量。由于我们假设 p 1 , p 2 , … , p C 和 t 1 , t 2 , … , t C ′ 已排序,故该条件也总能满足。基于Levina等人的结论[23],归一化EMD可精确且以闭式计算: E M D ( p , t ) = ( 1 C ) 1 l ∣ ∣ CDF ( p ) − CDF ( t ) ∣ ∣ l , 其中 CDF ( ⋅ ) 是返回输入累积密度函数的函数。 \text{EMD被证明等价于Mallows距离,后者具有闭式解[23],前提是基距离矩阵} \ \mathbf{D} \ \text{和分布} \ \mathbf{p} \ \text{和} \ \mathbf{t} \ \text{满足一定条件,如[23]所示。 \\ 们将展示这些条件在有序分类问题中得以满足。} \\ \\ \text{第一个条件是待比较的两个分布} \ \mathbf{p} \ \text{和} \ \mathbf{t} \ \text{必须具有相等的质量:} \ \sum_i p_i = \sum_j t_j. \\ \text{若} \ \mathbf{p} \ \text{由softmax层产生,则该条件恒成立,因为softmax层的输出向量是总和为1的归一化概率密度函数。由于预测分布的类别数与目标分布相同,故} \ C = C'. \\ \\ \text{第二个条件是基距离矩阵} \ \mathbf{D} \ \text{必须具有一维嵌入。假设在不失一般性的前提下,} \ p_1, p_2, \ldots, p_C \ \text{和} \ t_1, t_2, \ldots, t_{C'} \ \text{按其固有等级值排序,则该条件可表示为} \ \mathbf{D}_{i,j} = S(j - i), \\ \text{其中} \ S \ \text{为常数,且对所有满足} \ i \leq j \ \text{的} \ i, j \ \text{成立。显然,在有序分类问题中该假设总能满足。} \\ \\ \text{第三个也是最后一个条件是待比较的分布必须是排序后的向量。由于我们假设} \ p_1, p_2, \ldots, p_C \ \text{和} \ t_1, t_2, \ldots, t_{C'} \ \text{已排序,故该条件也总能满足。基于Levina等人的结论[23],归一化EMD可精确且以闭式计算:} \\ \mathbf{EMD(\mathbf{p}, \mathbf{t}) = \left( \frac{1}{C} \right)^{\frac{1}{l}} ||\text{CDF}(\mathbf{p}) - \text{CDF}(\mathbf{t})||_l}, \\ \text{其中} \ \text{CDF}(\cdot) \ \text{是返回输入累积密度函数的函数。} EMD被证明等价于Mallows距离,后者具有闭式解[23],前提是基距离矩阵 D 和分布 p 和 t 满足一定条件,如[23]所示。 们将展示这些条件在有序分类问题中得以满足。第一个条件是待比较的两个分布 p 和 t 必须具有相等的质量: i∑pi=j∑tj.若 p 由softmax层产生,则该条件恒成立,因为softmax层的输出向量是总和为1的归一化概率密度函数。由于预测分布的类别数与目标分布相同,故 C=C′.第二个条件是基距离矩阵 D 必须具有一维嵌入。假设在不失一般性的前提下, p1,p2,…,pC 和 t1,t2,…,tC′ 按其固有等级值排序,则该条件可表示为 Di,j=S(j−i),其中 S 为常数,且对所有满足 i≤j 的 i,j 成立。显然,在有序分类问题中该假设总能满足。第三个也是最后一个条件是待比较的分布必须是排序后的向量。由于我们假设 p1,p2,…,pC 和 t1,t2,…,tC′ 已排序,故该条件也总能满足。基于Levina等人的结论[23],归一化EMD可精确且以闭式计算:EMD(p,t)=(C1)l1∣∣CDF(p)−CDF(t)∣∣l,其中 CDF(⋅) 是返回输入累积密度函数的函数。
这里是用的平方损失,可以将损失替换为交叉熵,参照推荐系统时长建模的常用方案 - Blog,可以得到和上一个方案的近似工程实现,不再赘述
Distill softmax
Distill Softmax是一种用于推荐系统时长建模的方法,它通过生成平滑的多分类软标签来考虑类别之间的关系。具体来说,Distill Softmax将时长信息转换为平滑的概率分布,而不是传统的独热编码(one-hot encoding)。以下是Distill Softmax的主要步骤:
- 时长分区间:将时长分成多个区间,例如10个区间。
- 生成平滑标签:对于真实时长所在的区间,生成一个平滑的概率分布。例如,如果真实时长在第5个区间,传统的多分类标签是[0,0,0,0,1,0,0,0,0,0],而Distill Softmax会生成一个平滑的分布,如[0.001,0.005,0.03,0.1,0.7,0.1,0.05,0.008,0.005,0.001]。这样,相邻区间的概率会逐渐降低,从而更好地反映时长的连续性。
- 损失函数:使用多分类交叉熵作为损失函数,训练模型以预测这些平滑的概率分布。
- 线上预估:在实际应用中,通过累积概率分布来还原预测的时长。
Distill Softmax的优点在于它能够更好地利用类别之间的语义关系,提高模型的预测精度。它可以与其他方法(如EMD)结合使用,进一步提升效果。
总结来说,Distill Softmax通过生成平滑的软标签,使得模型在训练时能够更好地捕捉时长的连续性和类别之间的关系,从而提高预测的准确性。
Reference
-
推荐系统时长建模的常用方案 - Blog
-
https://zhuanlan.zhihu.com/p/678883395
-
https://arxiv.org/pdf/1611.05916
-
https://zhuanlan.zhihu.com/p/642620900
-
https://zhuanlan.zhihu.com/p/671950137
-
https://arxiv.org/pdf/2306.03392
-
快手提出基于因果消偏的观看时长预估模型D2Q,解决短视频推荐视频时长bias难题_澎湃号·湃客_澎湃新闻-The Paper
-
https://zhuanlan.zhihu.com/p/20897774896
-
https://arxiv.org/pdf/2412.20211v3
-
https://zhuanlan.zhihu.com/p/16412852825
相关文章:
短视频时长预估算法调研
weighted LR o d d s T p 1 − p ( 1 − p ) o d d s T p ( T p o d d s ∗ p ) o d d s p o d d s T o d d s odds \frac{Tp}{1-p} \newline (1-p)odds Tp \newline (Tp odds * p) odds \newline p \frac{odds}{T odds} \newline odds1−pTp(1−p)oddsTp(Tpodds…...

基于Java的离散数学题库系统设计与实现:附完整源码与论文
JAVASQL离散数学题库管理系统 一、系统概述 本系统采用Java Swing开发桌面应用,结合SQL Server数据库实现离散数学题库的高效管理。系统支持题型分类(选择题、填空题、判断题等)、难度分级、知识点关联,并提供智能组卷、在线测试…...
)
板凳-------Mysql cookbook学习 (十--2)
5.12 模式匹配中的大小写问题 mysql> use cookbook Database changed mysql> select a like A, a regexp A; ------------------------------ | a like A | a regexp A | ------------------------------ | 1 | 1 | --------------------------…...
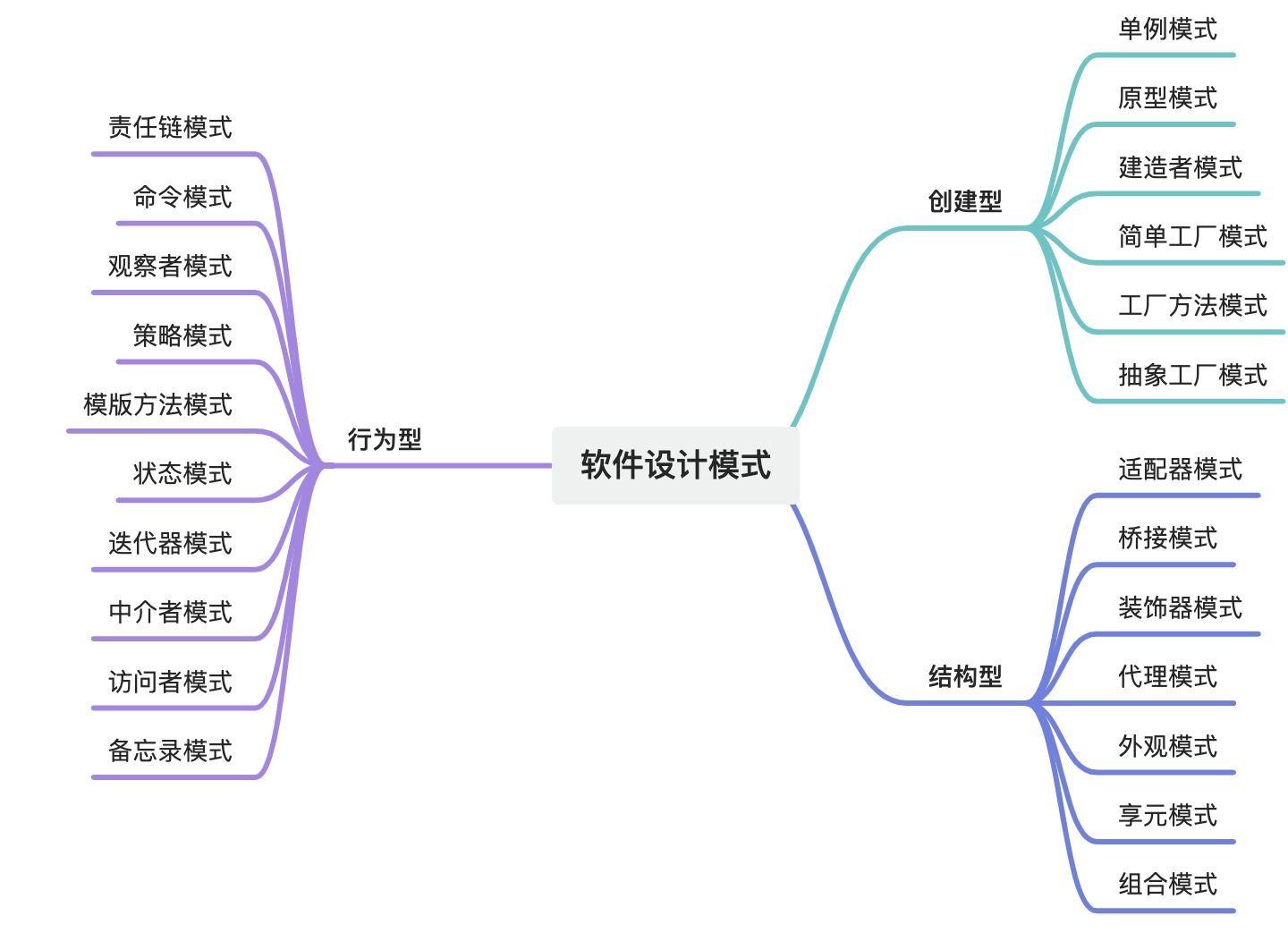
设计模式域——软件设计模式全集
摘要 软件设计模式是软件工程领域中经过验证的、可复用的解决方案,旨在解决常见的软件设计问题。它们是软件开发经验的总结,能够帮助开发人员在设计阶段快速找到合适的解决方案,提高代码的可维护性、可扩展性和可复用性。设计模式主要分为三…...
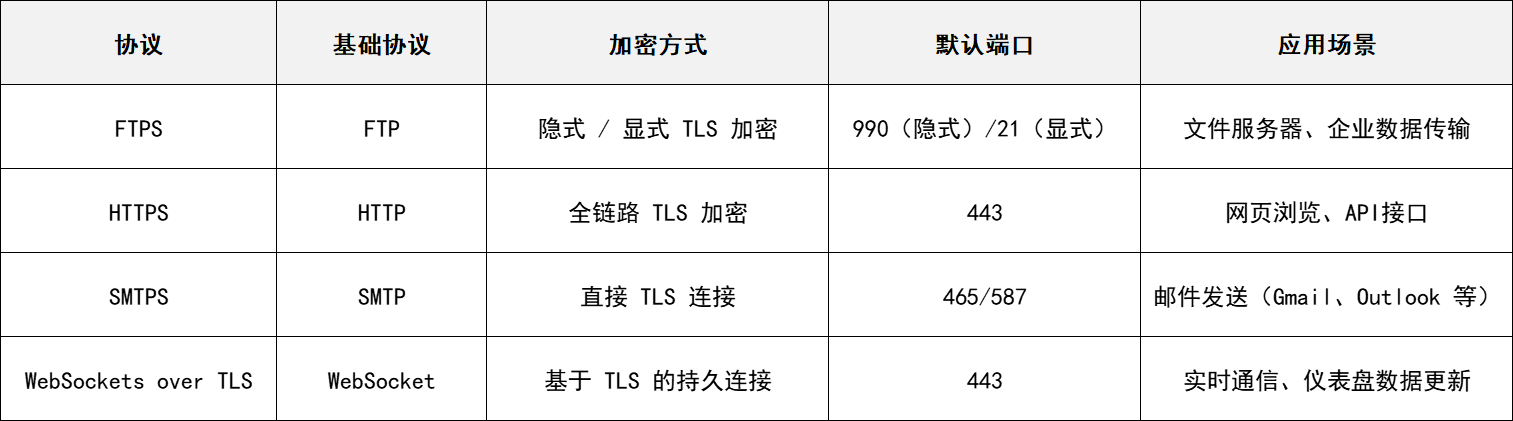
FTPS、HTTPS、SMTPS以及WebSockets over TLS的概念及其应用场景
一、什么是FTPS? FTPS,英文全称File Transfer Protocol with support for Transport Layer Security (SSL/TLS),安全文件传输协议,是一种对常用的文件传输协议(FTP)添加传输层安全(TLS)和安全套接层(SSL)加密协议支持的扩展协议。…...
--uboot系统之外设与PMIC详解)
RK3568项目(七)--uboot系统之外设与PMIC详解
目录 一、引言 二、按键 ------>2.1、按键种类 ------------>2.1.1、RESET ------------>2.1.2、UPDATE ------------>2.1.3、PWRON 部分 ------------>2.1.4、RK809 PMIC ------------>2.1.5、ADC按键 ------------>2.1.6、ADC按键驱动 ------…...
)
Three.js进阶之粒子系统(一)
一些特定模糊现象,经常使用粒子系统模拟,如火焰、爆炸等。Three.js提供了多种粒子系统,下面介绍粒子系统 一、Sprite粒子系统 使用场景:下雨、下雪、烟花 ce使用代码: var materialnew THRESS.SpriteMaterial();//…...

【仿生机器人】刀剑神域——爱丽丝苏醒计划,需求文档
仿生机器人"爱丽丝"系统架构设计需求文档 一、硬件基础 已完成头部和颈部硬件搭建 25个舵机驱动表情系统 颈部旋转功能 眼部摄像头(视觉输入) 麦克风阵列(听觉输入) 颈部发声装置(语音输出)…...

小白的进阶之路系列之十四----人工智能从初步到精通pytorch综合运用的讲解第七部分
通过示例学习PyTorch 本教程通过独立的示例介绍PyTorch的基本概念。 PyTorch的核心提供了两个主要特性: 一个n维张量,类似于numpy,但可以在gpu上运行 用于构建和训练神经网络的自动微分 我们将使用一个三阶多项式来拟合问题 y = s i n ( x ) y=sin(x) y=sin(x),作为我们的…...

JavaScript性能优化实战大纲
性能优化的核心目标 降低页面加载时间,减少内存占用,提高代码执行效率,确保流畅的用户体验。 代码层面的优化 减少全局变量使用,避免内存泄漏 // 不好的实践 var globalVar I am global;// 好的实践 (function() {var localV…...
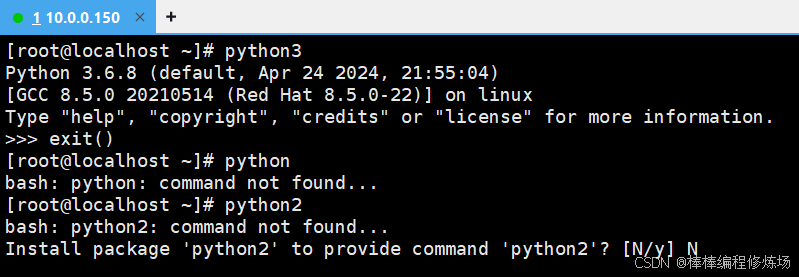
Python 解释器安装全攻略(适用于 Linux / Windows / macOS)
目录 一、Windows安装Python解释器1.1 下载并安装Python解释1.2 测试安装是否成功1.3 设置pip的国内镜像------永久配置 二、macOS安装Python解释器三、Linux下安装Python解释器3.1 Rocky8.10/Rocky9.5安装Python解释器3.2 Ubuntu2204/Ubuntu2404安装Python解释器3.3 设置pip的…...
Java多线程从入门到精通
一、基础概念 1.1 进程与线程 进程是指运行中的程序。 比如我们使用浏览器,需要启动这个程序,操作系统会给这个程序分配一定的资源(占用内存资源)。 线程是CPU调度的基本单位,每个线程执行的都是某一个进程的代码的某…...

【芯片仿真中的X值:隐藏的陷阱与应对之道】
在芯片设计的世界里,X值(不定态)就像一个潜伏的幽灵。它可能让仿真测试顺利通过,却在芯片流片后引发灾难性后果。本文将揭开X值的本质,探讨其危害,并分享高效调试与预防的实战经验。 一、X值的本质与致…...

C++ 变量和基本类型
1、变量的声明和定义 1.1、变量声明规定了变量的类型和名字。定义初次之外,还申请存储空间,也可能会为变量赋一个初始值。 如果想声明一个变量而非定义它,就在变量名前添加关键字extern,而且不要显式地初始化变量: e…...

LeetCode第244题_最短单词距离II
LeetCode第244题:最短单词距离II 问题描述 设计一个类,接收一个单词数组 wordsDict,并实现一个方法,该方法能够计算两个不同单词在该数组中出现位置的最短距离。 你需要实现一个 WordDistance 类: WordDistance(String[] word…...

Linux 中替换文件中的某个字符串
如果你想在 Linux 中替换文件中的某个字符串,可以使用以下命令: 1. 基本替换(sed 命令) sed -i s/原字符串/新字符串/g 文件名示例:将 file.txt 中所有的 old_text 替换成 new_text sed -i s/old_text/new_text/g fi…...

python3GUI--基于PyQt5+DeepSort+YOLOv8智能人员入侵检测系统(详细图文介绍)
文章目录 一.前言二.技术介绍1.PyQt52.DeepSort3.卡尔曼滤波4.YOLOv85.SQLite36.多线程7.入侵人员检测8.ROI区域 三.核心功能1.登录注册1.登录2.注册 2.主界面1.主界面简介2.数据输入3.参数配置4.告警配置5.操作控制台6.核心内容显示区域7.检…...

5. TypeScript 类型缩小
在 TypeScript 中,类型缩小(Narrowing)是指根据特定条件将变量的类型细化为更具体的过程。它帮助开发者编写更精确、更准确的代码,确保变量在运行时只以符合其类型的方式进行处理。 一、instanceof 缩小类型 TypeScript 中的 in…...

Python_day48随机函数与广播机制
在继续讲解模块消融前,先补充几个之前没提的基础概念 尤其需要搞懂张量的维度、以及计算后的维度,这对于你未来理解复杂的网络至关重要 一、 随机张量的生成 在深度学习中经常需要随机生成一些张量,比如权重的初始化,或者计算输入…...

【QT】qtdesigner中将控件提升为自定义控件后,css设置样式不生效(已解决,图文详情)
目录 0.背景 1.解决思路 2.详细代码 0.背景 实际项目中遇到的问题,描述如下: 我在qtdesigner用界面拖了一个QTableView控件,object name为【tableView_electrode】,然后【提升为】了自定义的类【Steer_Electrode_Table】&…...
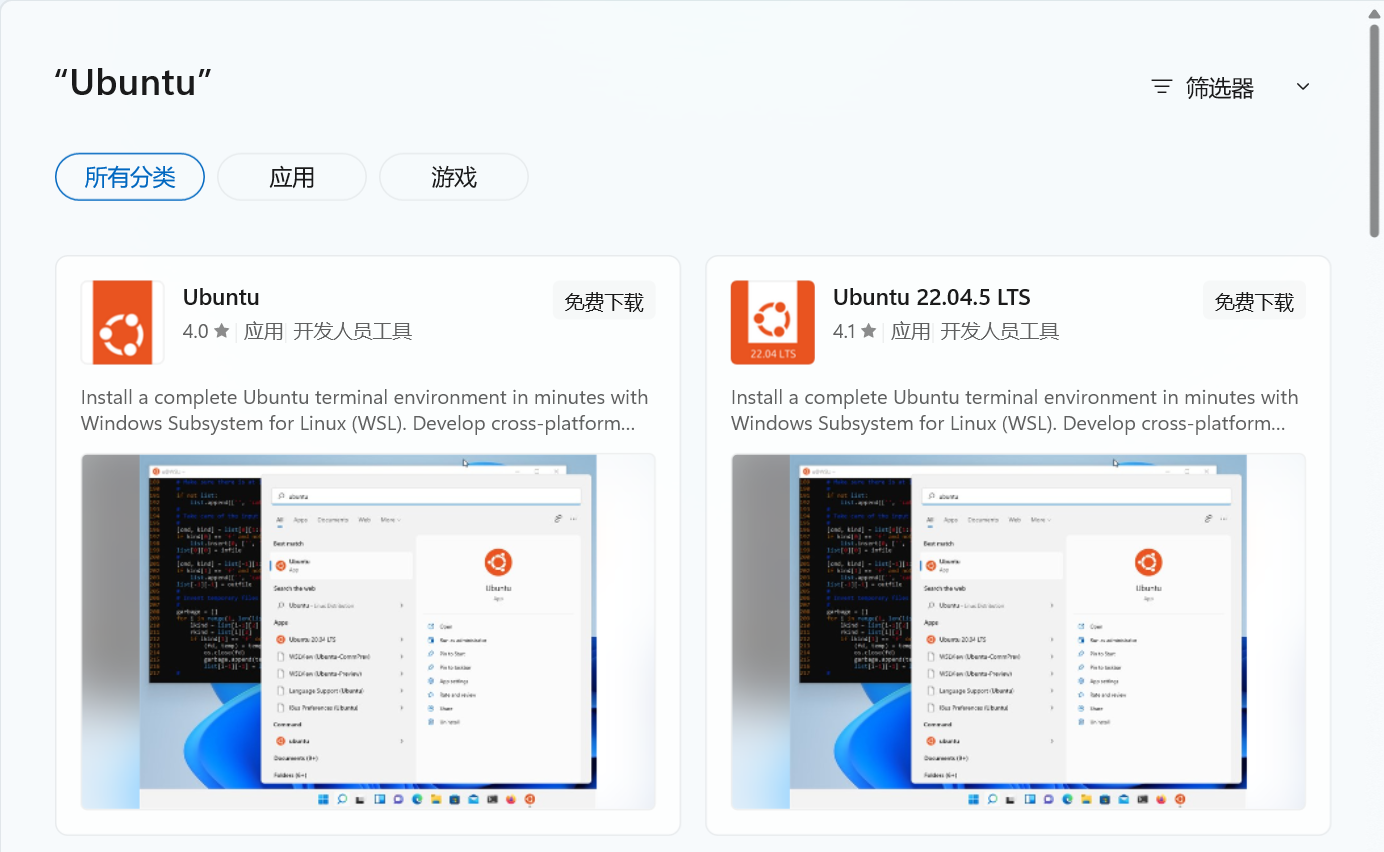
【Docker 02】Docker 安装
🌈 一、各版本的平台支持情况 ⭐ 1. Server 版本 Server 版本的 Docker 就只有个命令行,没有界面。 Platformx86_64 / amd64arm64 / aarch64arm(32 - bit)s390xCentOs√√Debian√√√Fedora√√Raspbian√RHEL√SLES√Ubuntu√√√√Binaries√√√ …...

【大厂机试题+算法可视化】最长的指定瑕疵度的元音子串
题目 开头和结尾都是元音字母(aeiouAEIOU)的字符串为元音字符串,其中混杂的非元音字母数量为其瑕疵度。比如: “a” 、 “aa”是元音字符串,其瑕疵度都为0 “aiur”不是元音字符串(结尾不是元音字符) “…...
shellcode混淆uuid/ipv6/mac)
【免杀】C2免杀技术(十五)shellcode混淆uuid/ipv6/mac
针对 shellcode 混淆(Shellcode Obfuscation) 的实战手段还有很多,如下表所示: 类型举例目的编码 / 加密XOR、AES、RC4、Base64、Poly1305、UUID、IP/MAC改变字节特征,避开静态签名或 YARA结构伪装PE Stub、GIF/PNG 嵌入、RTF OLE、UUID、IP/MAC看起来像合法文件/数据,弱…...

Java严格模式withResolverStyle解析日期错误及解决方案
在Java中使用DateTimeFormatter并启用严格模式(ResolverStyle.STRICT)时,解析日期字符串"2025-06-01"报错的根本原因是:模式字符串中的年份格式yyyy被解释为YearOfEra(纪元年份),而非…...

Async-profiler 内存采样机制解析:从原理到实现
引言 在 Java 性能调优的工具箱中,async-profiler 是一款备受青睐的低开销采样分析器。它不仅能分析 CPU 热点,还能精确追踪内存分配情况。本文将深入探讨 async-profiler 实现内存采样的多种机制,结合代码示例解析其工作原理。 为什么需要内…...

C++ 使用 ffmpeg 解码 rtsp 流并获取每帧的YUV数据
一、简介 FFmpeg 是一个开源的多媒体处理框架,非常适用于处理音视频的录制、转换、流化和播放。 二、代码 示例代码使用工作线程读取rtsp视频流,自动重连,支持手动退出,解码并将二进制文件保存下来。 注意: 代…...

Java毕业设计:办公自动化系统的设计与实现
JAVA办公自动化系统 一、系统概述 本办公自动化系统基于Java EE平台开发,实现了企业日常办公的数字化管理。系统包含文档管理、流程审批、会议管理、日程安排、通讯录等核心功能模块,采用B/S架构设计,支持多用户协同工作。系统使用Spring B…...
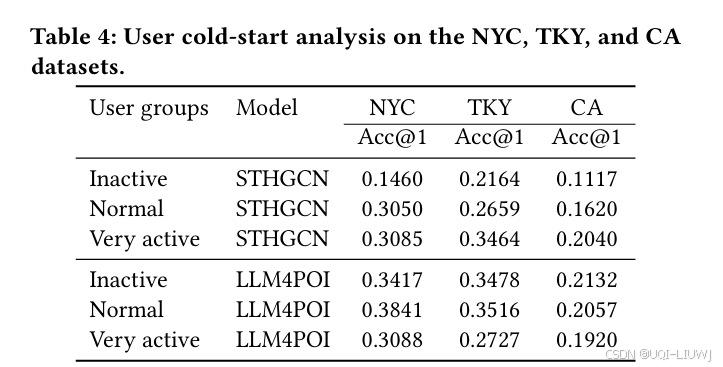
论文笔记:Large Language Models for Next Point-of-Interest Recommendation
SIGIR 2024 1 intro 传统的基于数值的POI推荐方法在处理上下文信息时存在两个主要限制 需要将异构的LBSN数据转换为数字,这可能导致上下文信息的固有含义丢失仅依赖于统计和人为设计来理解上下文信息,缺乏对上下文信息提供的语义概念的理解 ——>使用…...

LeetCode 2894.分类求和并作差
目录 题目: 题目描述: 题目链接: 思路: 思路一详解(遍历 判断): 思路二详解(数学规律/公式): 代码: Java思路一(遍历 判断&a…...

n8n:解锁自动化工作流的无限可能
在当今快节奏的数字时代,无论是企业还是个人,都渴望提高工作效率,减少重复性任务的繁琐操作。而 n8n,这个强大的开源自动化工具,就像一位智能的数字助手,悄然走进了许多人的工作和生活,成为提升…...