小白的进阶之路系列之十四----人工智能从初步到精通pytorch综合运用的讲解第七部分
通过示例学习PyTorch
本教程通过独立的示例介绍PyTorch的基本概念。
PyTorch的核心提供了两个主要特性:
-
一个n维张量,类似于numpy,但可以在gpu上运行
-
用于构建和训练神经网络的自动微分
我们将使用一个三阶多项式来拟合问题 y = s i n ( x ) y=sin(x) y=sin(x),作为我们的例子。网络将有四个参数,并将通过最小化网络输出与真实输出之间的欧几里得距离来训练梯度下降以拟合随机数据。
张量
热身:numpy
在介绍PyTorch之前,我们将首先使用numpy实现网络。
Numpy提供了一个n维数组对象,以及许多用于操作这些数组的函数。Numpy是科学计算的通用框架;它对计算图、深度学习或梯度一无所知。然而,我们可以很容易地使用numpy来拟合正弦函数的三阶多项式,通过使用numpy操作手动实现网络的向前和向后传递:
# -*- coding: utf-8 -*-
import numpy as np
import math# Create random input and output data
x = np.linspace(-math.pi, math.pi, 2000)
y = np.sin(x)# Randomly initialize weights
a = np.random.randn()
b = np.random.randn()
c = np.random.randn()
d = np.random.randn()learning_rate = 1e-6
for t in range(2000):# Forward pass: compute predicted y# y = a + b x + c x^2 + d x^3y_pred = a + b * x + c * x ** 2 + d * x ** 3# Compute and print lossloss = np.square(y_pred - y).sum()if t % 100 == 99:print(t, loss)# Backprop to compute gradients of a, b, c, d with respect to lossgrad_y_pred = 2.0 * (y_pred - y)grad_a = grad_y_pred.sum()grad_b = (grad_y_pred * x).sum()grad_c = (grad_y_pred * x ** 2).sum()grad_d = (grad_y_pred * x ** 3).sum()# Update weightsa -= learning_rate * grad_ab -= learning_rate * grad_bc -= learning_rate * grad_cd -= learning_rate * grad_dprint(f'Result: y = {a} + {b} x + {c} x^2 + {d} x^3')
输出为:
99 245.74528761103798
199 173.39611738368987
299 123.2440921752332
399 88.44419578924933
499 64.27442600584153
599 47.47246235496093
699 35.78209704113
799 27.641356008462985
899 21.967808007623955
999 18.010612761588764
1099 15.248450766474248
1199 13.319031005970338
1299 11.970356120179034
1399 11.026994992046731
1499 10.366717947337667
1599 9.904294863860954
1699 9.58024957389446
1799 9.353047171709575
1899 9.193661409658082
1999 9.081793826477744
Result: y = -0.016362745280289488 + 0.8518166048235671 x + 0.0028228458381066635 x^2 + -0.09262995903014938 x^3
PyTorch:张量
Numpy是一个很好的框架,但是它不能利用gpu来加速它的数值计算。对于现代深度神经网络,gpu通常提供50倍或更高的速度,因此不幸的是,numpy不足以用于现代深度学习。
这里我们介绍PyTorch最基本的概念:张量(Tensor)。PyTorch张量在概念上与numpy数组相同:张量是一个n维数组,PyTorch提供了许多函数来操作这些张量。在幕后,张量可以跟踪计算图和梯度,但它们作为科学计算的通用工具也很有用。
与numpy不同的是,PyTorch张量可以利用gpu来加速它们的数值计算。要在GPU上运行PyTorch Tensor,你只需要指定正确的设备。
这里我们使用PyTorch张量来拟合正弦函数的三阶多项式。像上面的numpy示例一样,我们需要手动实现网络中的正向和反向传递:
# -*- coding: utf-8 -*-import torch
import mathdtype = torch.float
# device = torch.device("cpu")
device = torch.device("cuda:0") # Uncomment this to run on GPU# Create random input and output data
x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype)
y = torch.sin(x)# Randomly initialize weights
a = torch.randn((), device=device, dtype=dtype)
b = torch.randn((), device=device, dtype=dtype)
c = torch.randn((), device=device, dtype=dtype)
d = torch.randn((), device=device, dtype=dtype)learning_rate = 1e-6
for t in range(2000):# Forward pass: compute predicted yy_pred = a + b * x + c * x ** 2 + d * x ** 3# Compute and print lossloss = (y_pred - y).pow(2).sum().item()if t % 100 == 99:print(t, loss)# Backprop to compute gradients of a, b, c, d with respect to lossgrad_y_pred = 2.0 * (y_pred - y)grad_a = grad_y_pred.sum()grad_b = (grad_y_pred * x).sum()grad_c = (grad_y_pred * x ** 2).sum()grad_d = (grad_y_pred * x ** 3).sum()# Update weights using gradient descenta -= learning_rate * grad_ab -= learning_rate * grad_bc -= learning_rate * grad_cd -= learning_rate * grad_dprint(f'Result: y = {a.item()} + {b.item()} x + {c.item()} x^2 + {d.item()} x^3')
输出为:
99 80.36772918701172
199 56.39781951904297
299 40.46946716308594
399 29.881393432617188
499 22.840898513793945
599 18.157623291015625
699 15.041072845458984
799 12.966400146484375
899 11.584661483764648
999 10.664037704467773
1099 10.050336837768555
1199 9.641047477722168
1299 9.367938041687012
1399 9.185595512390137
1499 9.063775062561035
1599 8.982349395751953
1699 8.92789077758789
1799 8.89144515991211
1899 8.867034912109375
1999 8.85067367553711
Result: y = 0.0030112862586975098 + 0.8616413474082947 x + -0.0005194980767555535 x^2 + -0.09402744472026825 x^3
Autograd
PyTorch:张量和自梯度
在上面的例子中,我们必须手动实现神经网络的向前和向后传递。对于一个小型的两层网络来说,手动实现向后传递并不是什么大问题,但对于大型复杂网络来说,可能很快就会变得非常棘手。
值得庆幸的是,我们可以使用自动微分来自动计算神经网络中的逆向传递。PyTorch中的autograd包提供了这个功能。当使用autograd时,网络的前向传递将定义一个计算图;图中的节点将是张量
相关文章:

小白的进阶之路系列之十四----人工智能从初步到精通pytorch综合运用的讲解第七部分
通过示例学习PyTorch 本教程通过独立的示例介绍PyTorch的基本概念。 PyTorch的核心提供了两个主要特性: 一个n维张量,类似于numpy,但可以在gpu上运行 用于构建和训练神经网络的自动微分 我们将使用一个三阶多项式来拟合问题 y = s i n ( x ) y=sin(x) y=sin(x),作为我们的…...

JavaScript性能优化实战大纲
性能优化的核心目标 降低页面加载时间,减少内存占用,提高代码执行效率,确保流畅的用户体验。 代码层面的优化 减少全局变量使用,避免内存泄漏 // 不好的实践 var globalVar I am global;// 好的实践 (function() {var localV…...
Python 解释器安装全攻略(适用于 Linux / Windows / macOS)
目录 一、Windows安装Python解释器1.1 下载并安装Python解释1.2 测试安装是否成功1.3 设置pip的国内镜像------永久配置 二、macOS安装Python解释器三、Linux下安装Python解释器3.1 Rocky8.10/Rocky9.5安装Python解释器3.2 Ubuntu2204/Ubuntu2404安装Python解释器3.3 设置pip的…...
Java多线程从入门到精通
一、基础概念 1.1 进程与线程 进程是指运行中的程序。 比如我们使用浏览器,需要启动这个程序,操作系统会给这个程序分配一定的资源(占用内存资源)。 线程是CPU调度的基本单位,每个线程执行的都是某一个进程的代码的某…...

【芯片仿真中的X值:隐藏的陷阱与应对之道】
在芯片设计的世界里,X值(不定态)就像一个潜伏的幽灵。它可能让仿真测试顺利通过,却在芯片流片后引发灾难性后果。本文将揭开X值的本质,探讨其危害,并分享高效调试与预防的实战经验。 一、X值的本质与致…...

C++ 变量和基本类型
1、变量的声明和定义 1.1、变量声明规定了变量的类型和名字。定义初次之外,还申请存储空间,也可能会为变量赋一个初始值。 如果想声明一个变量而非定义它,就在变量名前添加关键字extern,而且不要显式地初始化变量: e…...

LeetCode第244题_最短单词距离II
LeetCode第244题:最短单词距离II 问题描述 设计一个类,接收一个单词数组 wordsDict,并实现一个方法,该方法能够计算两个不同单词在该数组中出现位置的最短距离。 你需要实现一个 WordDistance 类: WordDistance(String[] word…...

Linux 中替换文件中的某个字符串
如果你想在 Linux 中替换文件中的某个字符串,可以使用以下命令: 1. 基本替换(sed 命令) sed -i s/原字符串/新字符串/g 文件名示例:将 file.txt 中所有的 old_text 替换成 new_text sed -i s/old_text/new_text/g fi…...

python3GUI--基于PyQt5+DeepSort+YOLOv8智能人员入侵检测系统(详细图文介绍)
文章目录 一.前言二.技术介绍1.PyQt52.DeepSort3.卡尔曼滤波4.YOLOv85.SQLite36.多线程7.入侵人员检测8.ROI区域 三.核心功能1.登录注册1.登录2.注册 2.主界面1.主界面简介2.数据输入3.参数配置4.告警配置5.操作控制台6.核心内容显示区域7.检…...

5. TypeScript 类型缩小
在 TypeScript 中,类型缩小(Narrowing)是指根据特定条件将变量的类型细化为更具体的过程。它帮助开发者编写更精确、更准确的代码,确保变量在运行时只以符合其类型的方式进行处理。 一、instanceof 缩小类型 TypeScript 中的 in…...

Python_day48随机函数与广播机制
在继续讲解模块消融前,先补充几个之前没提的基础概念 尤其需要搞懂张量的维度、以及计算后的维度,这对于你未来理解复杂的网络至关重要 一、 随机张量的生成 在深度学习中经常需要随机生成一些张量,比如权重的初始化,或者计算输入…...

【QT】qtdesigner中将控件提升为自定义控件后,css设置样式不生效(已解决,图文详情)
目录 0.背景 1.解决思路 2.详细代码 0.背景 实际项目中遇到的问题,描述如下: 我在qtdesigner用界面拖了一个QTableView控件,object name为【tableView_electrode】,然后【提升为】了自定义的类【Steer_Electrode_Table】&…...
【Docker 02】Docker 安装
🌈 一、各版本的平台支持情况 ⭐ 1. Server 版本 Server 版本的 Docker 就只有个命令行,没有界面。 Platformx86_64 / amd64arm64 / aarch64arm(32 - bit)s390xCentOs√√Debian√√√Fedora√√Raspbian√RHEL√SLES√Ubuntu√√√√Binaries√√√ …...

【大厂机试题+算法可视化】最长的指定瑕疵度的元音子串
题目 开头和结尾都是元音字母(aeiouAEIOU)的字符串为元音字符串,其中混杂的非元音字母数量为其瑕疵度。比如: “a” 、 “aa”是元音字符串,其瑕疵度都为0 “aiur”不是元音字符串(结尾不是元音字符) “…...
shellcode混淆uuid/ipv6/mac)
【免杀】C2免杀技术(十五)shellcode混淆uuid/ipv6/mac
针对 shellcode 混淆(Shellcode Obfuscation) 的实战手段还有很多,如下表所示: 类型举例目的编码 / 加密XOR、AES、RC4、Base64、Poly1305、UUID、IP/MAC改变字节特征,避开静态签名或 YARA结构伪装PE Stub、GIF/PNG 嵌入、RTF OLE、UUID、IP/MAC看起来像合法文件/数据,弱…...

Java严格模式withResolverStyle解析日期错误及解决方案
在Java中使用DateTimeFormatter并启用严格模式(ResolverStyle.STRICT)时,解析日期字符串"2025-06-01"报错的根本原因是:模式字符串中的年份格式yyyy被解释为YearOfEra(纪元年份),而非…...

Async-profiler 内存采样机制解析:从原理到实现
引言 在 Java 性能调优的工具箱中,async-profiler 是一款备受青睐的低开销采样分析器。它不仅能分析 CPU 热点,还能精确追踪内存分配情况。本文将深入探讨 async-profiler 实现内存采样的多种机制,结合代码示例解析其工作原理。 为什么需要内…...

C++ 使用 ffmpeg 解码 rtsp 流并获取每帧的YUV数据
一、简介 FFmpeg 是一个开源的多媒体处理框架,非常适用于处理音视频的录制、转换、流化和播放。 二、代码 示例代码使用工作线程读取rtsp视频流,自动重连,支持手动退出,解码并将二进制文件保存下来。 注意: 代…...

Java毕业设计:办公自动化系统的设计与实现
JAVA办公自动化系统 一、系统概述 本办公自动化系统基于Java EE平台开发,实现了企业日常办公的数字化管理。系统包含文档管理、流程审批、会议管理、日程安排、通讯录等核心功能模块,采用B/S架构设计,支持多用户协同工作。系统使用Spring B…...
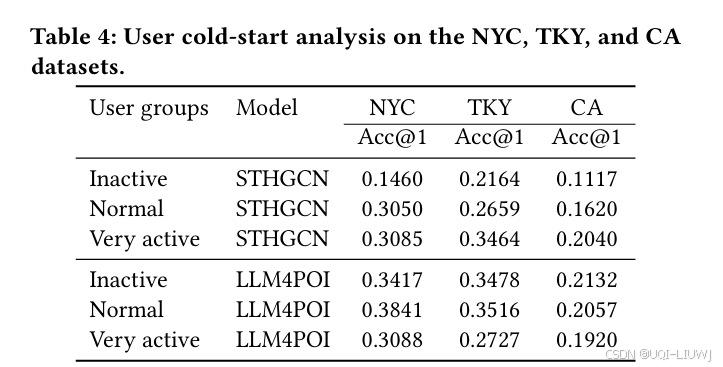
论文笔记:Large Language Models for Next Point-of-Interest Recommendation
SIGIR 2024 1 intro 传统的基于数值的POI推荐方法在处理上下文信息时存在两个主要限制 需要将异构的LBSN数据转换为数字,这可能导致上下文信息的固有含义丢失仅依赖于统计和人为设计来理解上下文信息,缺乏对上下文信息提供的语义概念的理解 ——>使用…...

LeetCode 2894.分类求和并作差
目录 题目: 题目描述: 题目链接: 思路: 思路一详解(遍历 判断): 思路二详解(数学规律/公式): 代码: Java思路一(遍历 判断&a…...

n8n:解锁自动化工作流的无限可能
在当今快节奏的数字时代,无论是企业还是个人,都渴望提高工作效率,减少重复性任务的繁琐操作。而 n8n,这个强大的开源自动化工具,就像一位智能的数字助手,悄然走进了许多人的工作和生活,成为提升…...

链结构与工作量证明7️⃣:用 Go 实现比特币的核心机制
链结构与工作量证明:用 Go 实现比特币的核心机制 如果你用 Go 写过区块、算过哈希,也大致理解了非对称加密、数据序列化这些“硬核知识”,那么恭喜你,现在我们终于可以把这些拼成一条完整的“区块链”。 不过别急,这一节我们重点搞懂两件事: 区块之间是怎么连接成“链”…...

CMake系统学习笔记
CMake系统学习笔记 基础操作 最基本的案例 // code #include <iostream>int main() {std::cout << "hello world " << std::endl;return 0; }// CMakeLists.txt cmake_minimum_required(VERSION 3.0)# 定义当前工程名称 project(demo)add_execu…...

CCF 开源发展委员会 “开源高校行“ 暨红山开源 + OpenAtom openKylin 高校行活动在西安四所高校成功举办
点击蓝字 关注我们 CCF Opensource Development Committee CCF开源高校行 暨红山开源 openKylin 高校行 西安站 5 月 26 日至 28 日,CCF 开源发展委员会 "开源高校行" 暨红山开源 OpenAtom openKylin 高校行活动在西安四所高校(西安交通大学…...

【Go语言基础【6】】字符串格式化说明
文章目录 零、格式化常用场景一、Go 字符串格式化核心概念二、常用格式化占位符1. 整数类型2. 浮点数类型3. 字符串与布尔类型4. 指针与通用类型 三、宽度与精度控制1. 宽度控制2. 精度控制(浮点数/字符串) 零、格式化常用场景 数值转字符串:…...

调试快捷键 pycharm vscode
目录 调试快捷键 pycharm vscode 修改快捷键 方法 1:通过菜单打开 方法 2:用快捷键打开 调试快捷键 pycharm Resume Program F9 Step Over F8 两个离的比较近,比较方便,比vscode的好。 vscode Continue F5 改为F9 S…...
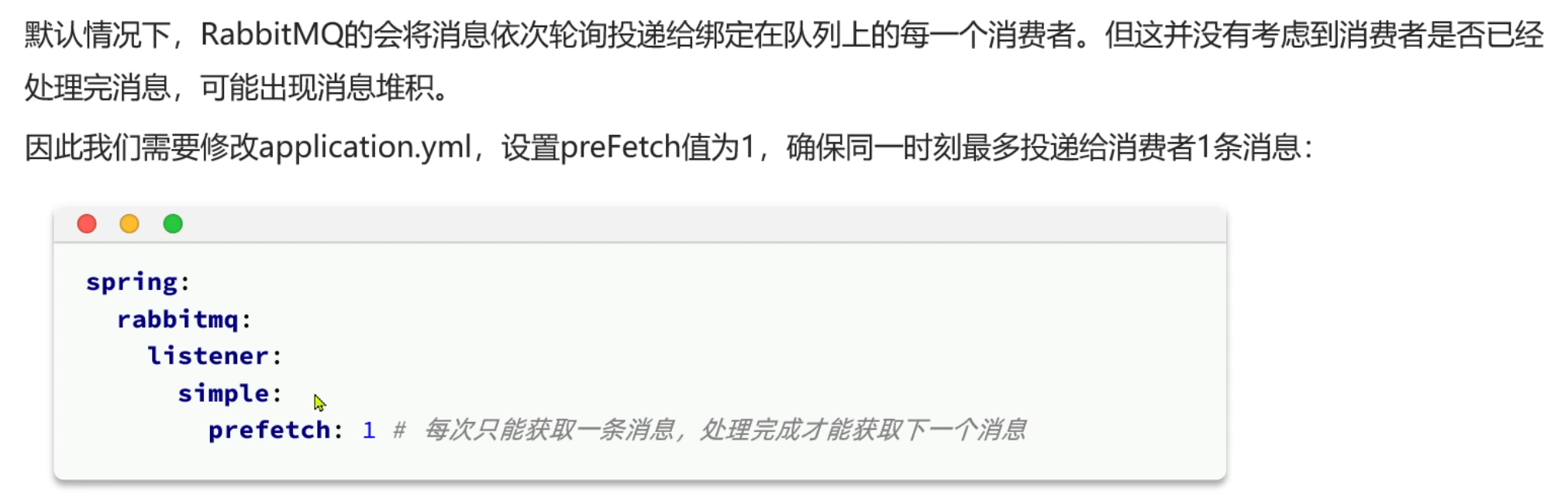
RabbitMQ work模型
Work 模型是 RabbitMQ 最基础的消息处理模式,核心思想是 多个消费者竞争消费同一个队列中的消息,适用于任务分发和负载均衡场景。同一个消息只会被一个消费者处理。 当一个消息队列绑定了多个消费者,每个消息消费的个数都是平摊的&a…...
基于微信小程序的作业管理系统源码数据库文档
作业管理系统 摘 要 随着社会的发展,社会的方方面面都在利用信息化时代的优势。互联网的优势和普及使得各种系统的开发成为必需。 本文以实际运用为开发背景,运用软件工程原理和开发方法,它主要是采用java语言技术和微信小程序来完成对系统的…...

C++参数传递 a与a的区别
在 C 中,&a(引用)和 a(值传递) 的关键区别在于 参数如何传递给函数,以及由此引发的 性能、语义和安全问题。 最核心的在于你想不想传入的参数被改变,如果想,就用参数传递&#…...