开源 vGPU 方案:HAMi,实现细粒度 GPU 切分

本文主要分享一个开源的 GPU 虚拟化方案:HAMi,包括如何安装、配置以及使用。
相比于上一篇分享的 TimeSlicing 方案,HAMi 除了 GPU 共享之外还可以实现 GPU core、memory 得限制,保证共享同一 GPU 的各个 Pod 都能拿到足够的资源。
1.为什么需要 GPU 共享、切分等方案?
开始之前我们先思考一个问题,为什么需要 GPU 共享、切分等方案?
或者说是另外一个问题:明明直接在裸机环境使用,都可以多个进程共享 GPU,怎么到 k8s 环境就不行了。
推荐阅读前面几篇文章:这两篇分享了如何在各个环境中使用 GPU,在 k8s 环境则推荐使用 NVIDIA 提供的 gpu-operator 快速部署环境。
GPU 环境搭建指南:如何在裸机、Docker、K8s 等环境中使用 GPU
GPU 环境搭建指南:使用 GPU Operator 加速 Kubernetes GPU 环境搭建
这两篇则分析了 device-plugin 原理以及在 K8s 中创建一个申请 GPU 的 Pod 后的一些列动作,最终该 Pod 是如何使用到 GPU 的。
Kubernetes教程(二一)—自定义资源支持:K8s Device Plugin 从原理到实现
Kubernetes教程(二二)—在 K8S 中创建 Pod 是如何使用到 GPU 的:device plugin&nvidia-container-toolkit 源码分析
看完之后,大家应该就大致明白了。
资源感知
首先在 k8s 中资源是和节点绑定的,对于 GPU 资源,我们使用 NVIDIA 提供的 device-plugin 进行感知,并上报到 kube-apiserver,这样我们就能在 Node 对象上看到对应的资源了。
就像这样:
root@liqivm:~# k describe node gpu01|grep Capacity -A 7
Capacity:cpu: 128ephemeral-storage: 879000896Kihugepages-1Gi: 0hugepages-2Mi: 0memory: 1056457696Kinvidia.com/gpu: 8pods: 110
可以看到,该节点除了基础的 cpu、memory 之外,还有一个nvidia.com/gpu: 8 信息,表示该节点上有 8 个 GPU。
资源申请
然后我们就可以在创建 Pod 时申请对应的资源了,比如申请一个 GPU:
apiVersion: v1
kind: Pod
metadata:name: gpu-pod
spec:containers:- name: gpu-containerimage: nvidia/cuda:11.0-base # 一个支持 GPU 的镜像resources:limits:nvidia.com/gpu: 1 # 申请 1 个 GPUcommand: ["nvidia-smi"] # 示例命令,显示 GPU 的信息restartPolicy: OnFailure
apply 该 yaml 之后,kube-scheduler 在调度该 Pod 时就会将其调度到一个拥有足够 GPU 资源的 Node 上。
同时该 Pod 申请的部分资源也会标记为已使用,不会在分配给其他 Pod。
到这里,问题的答案就已经很明显的。
- 1)device-plugin 感知到节点上的物理 GPU 数量,上报到 kube-apiserver
- 2)kube-scheduler 调度 Pod 时会根据 pod 中的 Request 消耗对应资源
即:Node 上的 GPU 资源被 Pod 申请之后,在 k8s 中就被标记为已消耗了,后续创建的 Pod 会因为资源不够导致无法调度。
实际上:可能 GPU 性能比较好,可以支持多个 Pod 共同使用,但是因为 k8s 中的调度限制导致多个 Pod 无法正常共享。
因此,我们才需要 GPU 共享、切分等方案。
上一篇文章一文搞懂 GPU 共享方案: NVIDIA Time Slicing 中给大家分享了一个 GPU 共享方案。
可以实现多个 Pod 共享同一个 GPU,但是存在一个问题:Pod 之间并未做任何隔离,每个 Pod 能用到多少 GPU core、memory 都靠竞争,可能会导致部分 Pod 占用大部分资源导致其他 Pod 无法正常使用的情况。
今天给大家分享一个开源的 vGPU 方案 HAMi。
ps:NVIDIA 也有自己的 vGPU 方案,但是需要 license
2. 什么是 HAMi?
HAMi 全称是:Heterogeneous AI Computing Virtualization Middleware,HAMi 给自己的定位或者希望是做一个异构算力虚拟化平台。
原 第四范式 k8s-vgpu-scheduler, 这次改名 HAMi 同时也将核心的 vCUDA 库 libvgpu.so 也开源了。
但是现在比较完善的是对 NVIDIA GPU 的 vGPU 方案,因此我们可以简单认为他就是一个 vGPU 方案。
整体架构如下:
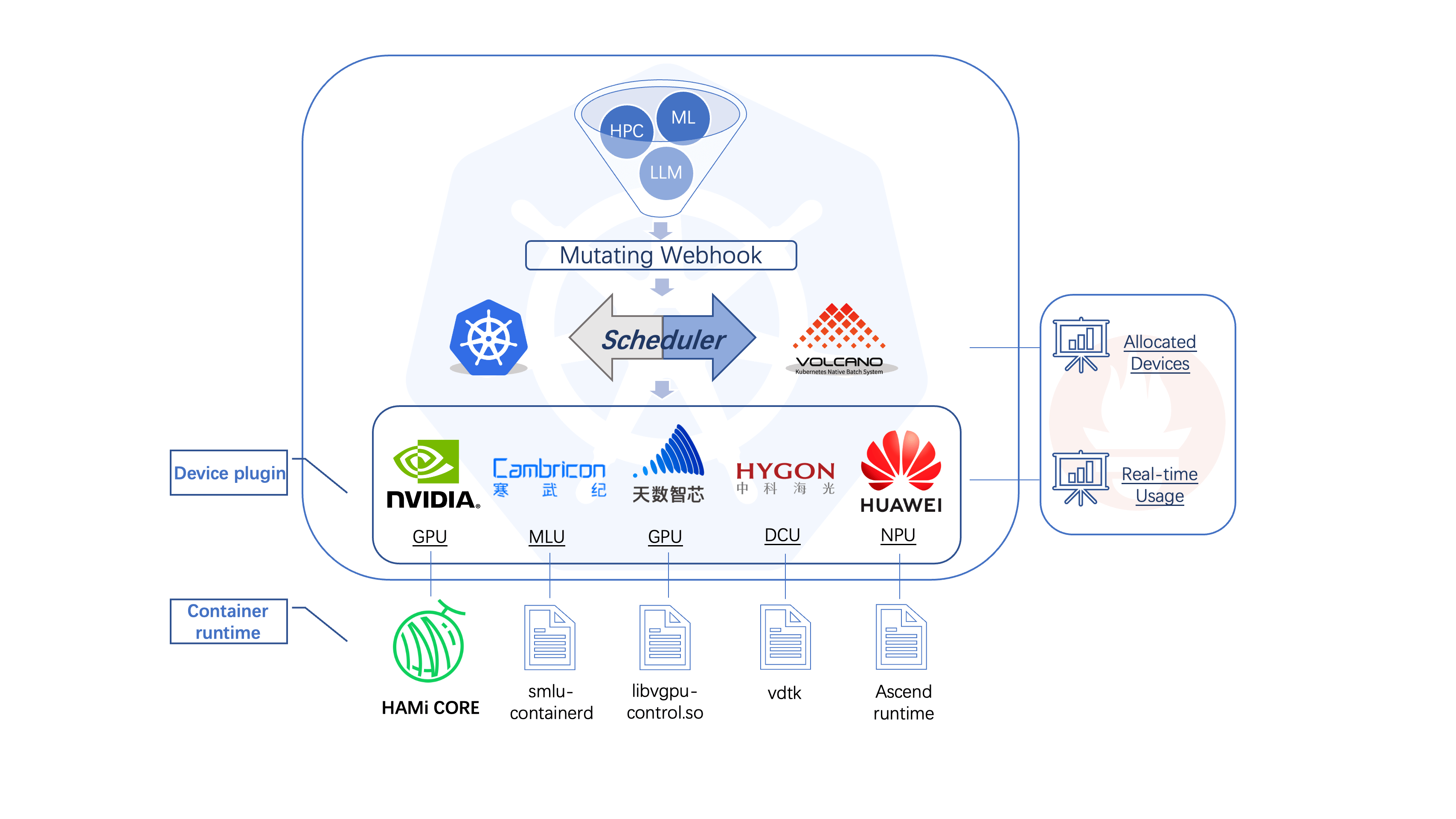
可以看到组件还是比较多的,设计到 Webhook、Scheduler、Device Plugin、HAMi-Core 等等。
这篇文章只讲使用,因此架构、原理就一笔带过,后续也会有相关文章,欢迎关注~。
Feature
使用 HAMi 最大的一个功能点就是可以实现 GPU 的细粒度的隔离,可以对 core 和 memory 使用 1% 级别的隔离。
具体如下:
apiVersion: v1
kind: Pod
metadata:name: gpu-pod
spec:containers:- name: ubuntu-containerimage: ubuntu:18.04command: ["bash", "-c", "sleep 86400"]resources:limits:nvidia.com/gpu: 1 # 请求1个vGPUsnvidia.com/gpumem: 3000 # 每个vGPU申请3000m显存 (可选,整数类型)nvidia.com/gpucores: 30 # 每个vGPU的算力为30%实际显卡的算力 (可选,整数类型)
- nvidia.com/gpu:请求一个 GPU
- nvidia.com/gpumem:只申请使用 3000M GPU Memory
- nvidia.com/gpucores:申请使用 30% 的 GPU core,也就是该 Pod 只能使用到 30% 的算力
相比于上文分享了 TimeSlicing 方案,HAMi 则是实现了 GPU core 和 memory 的隔离。
在开源方案里面已经算是比较优秀的了。
Design
HAMi 实现GPU core 和 memory 隔离、限制是使用的 vCUDA 方案,具体设计如下:
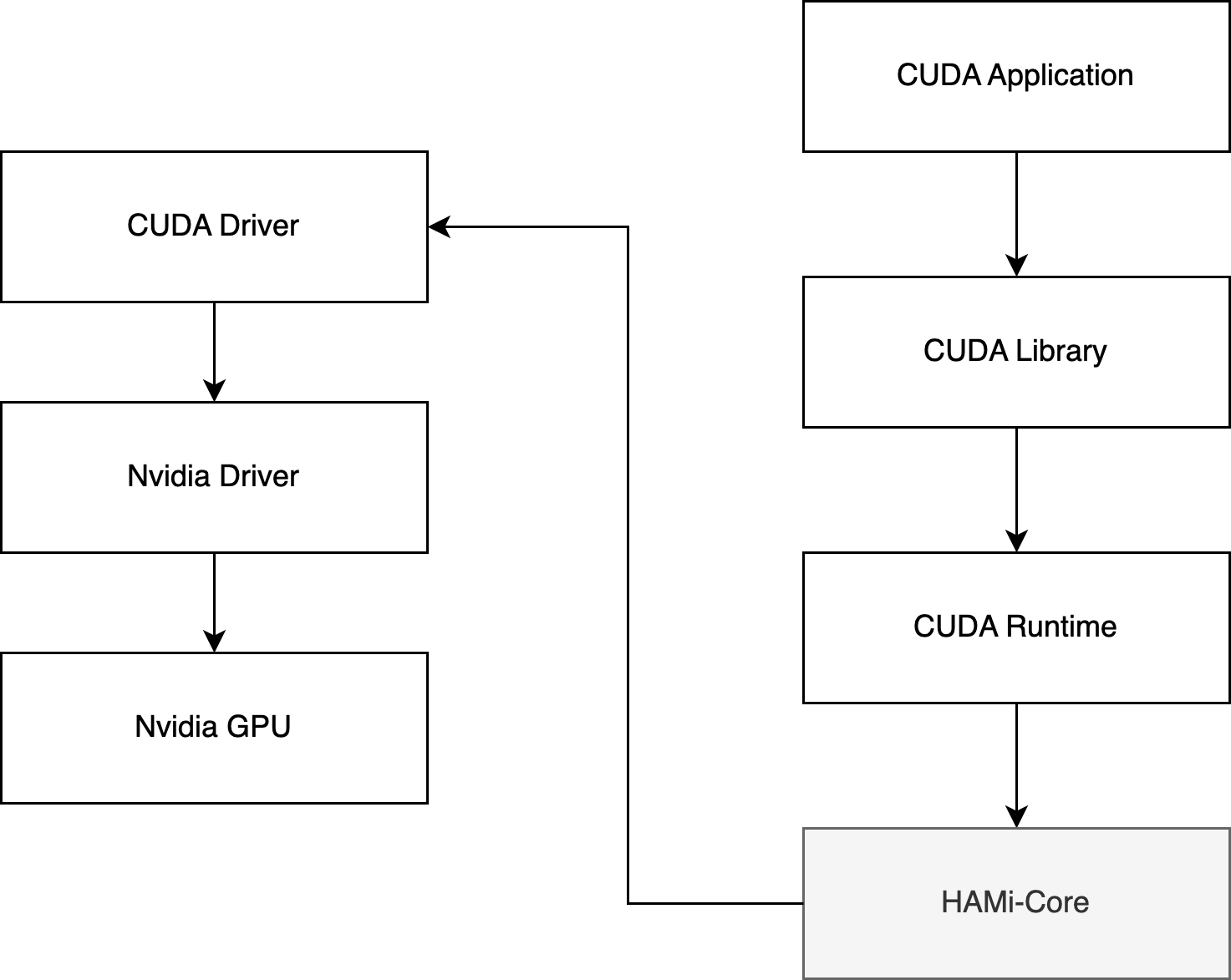
大部分使用 GPU 的应用都是用的 CUDA,HAMi 也是用的 vCUDA 方案,对 NVIDIA 原生的 CUDA 驱动进行重写,然后挂载到 Pod 中进行替换,然后在自己的实现的 CUDA 驱动中对 API 进行拦截,使用资源隔离以及限制的效果。
例如:原生 CUDA 驱动进行内存分配,只有在 GPU 内存真的用完的时候才会提示 CUDA OOM,但是对于 HAMi CUDA 驱动来说,检测到 Pod 中使用的内存超过了 Resource 中的申请量就直接返回 OOM,从而实现资源的一个限制。
然后在执行 nvidia-smi 命令查看 GPU 信息时,也只返回 Pod Resource 中申请的资源,这样在查看时也进行隔离。
ps:需要对 CUDA 和 NVML 的部分 API 拦截。
3. HAMi 部署
HAMi 提供了 Helm Chart 安装也是比较简单的。
部署 GPU Operator
需要注意的是 HAMi 会依赖 NVIDIA 的那一套,因此推荐先部署 GPU-Operator。
参考这篇文章 --> GPU 环境搭建指南:使用 GPU Operator 加速 Kubernetes GPU 环境搭建
部署好 GPU Operator 之后在部署 HAMi。
部署 HAMi
首先使用 helm 添加我们的 repo
helm repo add hami-charts https://project-hami.github.io/HAMi/
随后,使用下列指令获取集群服务端版本
这里使用的是 v1.27.4 版本
kubectl version
在安装过程中须根据集群服务端版本(上一条指令的结果)指定调度器镜像版本,例如集群服务端版本为 v1.27.4,则可以使用如下指令进行安装
helm install hami hami-charts/hami --set scheduler.kubeScheduler.imageTag=v1.27.4 -n kube-system
通过kubectl get pods指令看到 vgpu-device-plugin 与 vgpu-scheduler 两个pod 状态为Running 即为安装成功
root@iZj6c5dnq07p1ic04ei9vwZ:~# kubectl get pods -n kube-system|grep hami
hami-device-plugin-b6mvj 2/2 Running 0 42s
hami-scheduler-7f5c5ff968-26kjc 2/2 Running 0 42s
自定义配置
官方文档:HAMi-config-cn.md
你可以在安装过程中,通过-set来修改以下的客制化参数,例如:
helm install vgpu vgpu-charts/vgpu --set devicePlugin.deviceMemoryScaling=5 ...
devicePlugin.deviceSplitCount: 整数类型,预设值是 10。GPU 的分割数,每一张GPU 都不能分配超过其配置数目的任务。若其配置为N的话,每个 GPU 上最多可以同时存在 N 个任务。devicePlugin.deviceMemoryScaling:浮点数类型,预设值是1。NVIDIA 装置显存使用比例,可以大于1(启用虚拟显存,实验功能)。对于有 M显存大小的 NVIDIA GPU,如果我们配置devicePlugin.deviceMemoryScaling参数为 S ,在部署了我们装置插件的Kubenetes 集群中,这张 GPU 分出的 vGPU 将总共包含S * M显存。devicePlugin.migStrategy:字符串类型,目前支持"none“与“mixed“两种工作方式,前者忽略 MIG 设备,后者使用专门的资源名称指定 MIG 设备,使用详情请参考mix_example.yaml,默认为"none"devicePlugin.disablecorelimit:字符串类型,"true"为关闭算力限制,“false"为启动算力限制,默认为"false”scheduler.defaultMem:整数类型,预设值为 5000,表示不配置显存时使用的默认显存大小,单位为 MBscheduler.defaultCores:整数类型(0-100),默认为0,表示默认为每个任务预留的百分比算力。若设置为 0,则代表任务可能会被分配到任一满足显存需求的 GPU 中,若设置为100,代表该任务独享整张显卡scheduler.defaultGPUNum:整数类型,默认为1,如果配置为0,则配置不会生效。当用户在 pod 资源中没有设置 nvidia.com/gpu 这个 key 时,webhook 会检查 nvidia.com/gpumem、resource-mem-percentage、nvidia.com/gpucores 这三个 key 中的任何一个 key 有值,webhook 都会添加 nvidia.com/gpu 键和此默认值到 resources limit中。resourceName:字符串类型, 申请vgpu个数的资源名, 默认: “nvidia.com/gpu”resourceMem:字符串类型, 申请vgpu显存大小资源名, 默认: “nvidia.com/gpumem”resourceMemPercentage:字符串类型,申请vgpu显存比例资源名,默认: “nvidia.com/gpumem-percentage”resourceCores:字符串类型, 申请vgpu算力资源名, 默认: “nvidia.com/cores”resourcePriority:字符串类型,表示申请任务的任务优先级,默认: “nvidia.com/priority”
除此之外,容器中也有对应配置
GPU_CORE_UTILIZATION_POLICY:字符串类型,“default”, “force”, “disable” 代表容器算力限制策略, "default"为默认,"force"为强制限制算力,一般用于测试算力限制的功能,"disable"为忽略算力限制ACTIVE_OOM_KILLER:字符串类型,“true”, “false” 代表容器是否会因为超用显存而被终止执行,"true"为会,"false"为不会
我们只是简单 Demo 就不做任何配置直接部署即可。
4. 验证
查看 Node GPU 资源
类似于上一篇分享的 TimeSlicing 方案,在安装之后,Node 上可见的 GPU 资源也是增加了。
环境中只有一个物理 GPU,但是 HAMi 默认会扩容 10 倍,理论上现在 Node 上能查看到 1*10 = 10 个 GPU。
默认参数就是切分为 10 个,可以设置。
$ kubectl get node xxx -oyaml|grep capacity -A 7capacity:cpu: "4"ephemeral-storage: 206043828Kihugepages-1Gi: "0"hugepages-2Mi: "0"memory: 15349120Kinvidia.com/gpu: "10"pods: "110"
验证显存和算力限制
使用以下 yaml 来创建 Pod,注意 resources.limit 除了原有的 nvidia.com/gpu 之外还新增了 nvidia.com/gpumem 和 nvidia.com/gpucores,用来指定显存大小和算力大小。
- nvidia.com/gpu:请求的 vgpu 数量,例如 1
- nvidia.com/gpumem :请求的显存数量,例如 3000M
- nvidia.com/gpumem-percentage:显存百分百,例如 50 则是请求 50%显存
- nvidia.com/priority: 优先级,0 为高,1 为底,默认为 1。
- 对于高优先级任务,如果它们与其他高优先级任务共享 GPU 节点,则其资源利用率不会受到
resourceCores的限制。换句话说,如果只有高优先级任务占用 GPU 节点,那么它们可以利用节点上所有可用的资源。 - 对于低优先级任务,如果它们是唯一占用 GPU 的任务,则其资源利用率也不会受到
resourceCores的限制。这意味着如果没有其他任务与低优先级任务共享 GPU,那么它们可以利用节点上所有可用的资源。
- 对于高优先级任务,如果它们与其他高优先级任务共享 GPU 节点,则其资源利用率不会受到
完整 gpu-test.yaml 内容如下:
apiVersion: v1
kind: Pod
metadata:name: gpu-pod
spec:containers:- name: ubuntu-containerimage: ubuntu:18.04command: ["bash", "-c", "sleep 86400"]resources:limits:nvidia.com/gpu: 1 # 请求1个vGPUsnvidia.com/gpumem: 3000 # 每个vGPU申请3000m显存 (可选,整数类型)nvidia.com/gpucores: 30 # 每个vGPU的算力为30%实际显卡的算力 (可选,整数类型)
Pod 能够正常启动
root@iZj6c5dnq07p1ic04ei9vwZ:~# kubectl get po
NAME READY STATUS RESTARTS AGE
gpu-pod 1/1 Running 0 48s
进入 Pod执行 nvidia-smi 命令,查看 GPU 信息,可以看到展示的限制就是 Resource 中申请的 3000M。
root@iZj6c5dnq07p1ic04ei9vwZ:~# kubectl exec -it gpu-pod -- bash
root@gpu-pod:/# nvidia-smi
[HAMI-core Msg(16:139711087368000:libvgpu.c:836)]: Initializing.....
Mon Apr 29 06:22:16 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.14 Driver Version: 550.54.14 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 On | 00000000:00:07.0 Off | 0 |
| N/A 33C P8 15W / 70W | 0MiB / 3000MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------++-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
[HAMI-core Msg(16:139711087368000:multiprocess_memory_limit.c:434)]: Calling exit handler 16
根据最后的日志就是 HAMi 的 CUDA 驱动打印的。
[HAMI-core Msg(16:139711087368000:multiprocess_memory_limit.c:434)]: Calling exit handler 16
**【Kubernetes 系列】**持续更新中,搜索公众号【探索云原生】订阅,文章。

5. 小结
本文主要分享了开源 vGPU 方案 HAMi,并通过简单 Demo 进行了验证。
为什么需要 GPU 共享、切分?
在 k8s 中使用默认 device plugin 时,GPU 资源和物理 GPU 是一一对应的,导致一个物理 GPU 被一个 Pod 申请后,其他 Pod 就无法使用了。
为了提高资源利用率,因此我们需要 GPU 共享、切分等方案。
HAMi 大致实现原理
通过替换容器中的 libvgpu.so 库,实现 CUDA API 拦截,最终实现对 GPU core 和 memory 的隔离和限制。
更加详细的原理分析,可以期待后续文章~
最后在贴一下相关文章,推荐阅读:
-
GPU 环境搭建指南:如何在裸机、Docker、K8s 等环境中使用 GPU
-
GPU 环境搭建指南:使用 GPU Operator 加速 Kubernetes GPU 环境搭建
-
Kubernetes教程(二一)—自定义资源支持:K8s Device Plugin 从原理到实现
-
Kubernetes教程(二二)—在 K8S 中创建 Pod 是如何使用到 GPU 的:device plugin&nvidia-container-toolkit 源码分析
-
一文搞懂 GPU 共享方案: NVIDIA Time Slicing
相关文章:
开源 vGPU 方案:HAMi,实现细粒度 GPU 切分
本文主要分享一个开源的 GPU 虚拟化方案:HAMi,包括如何安装、配置以及使用。 相比于上一篇分享的 TimeSlicing 方案,HAMi 除了 GPU 共享之外还可以实现 GPU core、memory 得限制,保证共享同一 GPU 的各个 Pod 都能拿到足够的资源。…...

EC2安装WebRTC sdk-c环境、构建、编译
1、登录新的ec2实例,证书可以跟之前的实例用一个: ssh -v -i ~/Documents/cert/qa.pem ec2-user70.xxx.165.xxx 2、按照sdk-c demo中readme的描述开始安装环境: https://github.com/awslabs/amazon-kinesis-video-streams-webrtc-sdk-c 2…...

盲盒一番赏小程序:引领盲盒新潮流
在盲盒市场日益火爆的今天,如何才能在众多盲盒产品中脱颖而出?盲盒一番赏小程序给出了答案,它以创新的玩法和优质的服务,引领着盲盒新潮流。 一番赏小程序的最大特色在于其独特的赏品分级制度。赏品分为多个等级,从普…...

边缘计算设备全解析:边缘盒子在各大行业的落地应用场景
随着工业物联网、AI、5G的发展,数据量呈爆炸式增长。但你有没有想过,我们生成的数据,真的都要发回云端处理吗?其实不一定。特别是在一些对响应时间、网络带宽、数据隐私要求高的行业里,边缘计算开始“火”了起来&#…...

Linux实现线程同步的方式有哪些?
什么是线程同步? 想象一下超市收银台:如果所有顾客(线程)同时挤向同一个收银台(共享资源),场面会一片混乱。线程同步就是给顾客们发"排队号码牌",确保: 有序访…...

python打卡day47
昨天代码中注意力热图的部分顺移至今天 知识点回顾: 热力图 作业:对比不同卷积层热图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import D…...
python学习day39
图像数据与显存 知识点回顾 1.图像数据的格式:灰度和彩色数据 2.模型的定义 3.显存占用的4种地方 a.模型参数梯度参数 b.优化器参数 c.数据批量所占显存 d.神经元输出中间状态 4.batchisize和训练的关系 import torch import torchvision import torch.nn as nn imp…...

Ansible+Zabbix-agent2快速实现对多主机监控
ansible Ansible 是一款开源的自动化工具,用于配置管理(Configuration Management)、应用部署(Application Deployment)、任务自动化(Task Automation)和编排(Orchestration…...

年度峰会上,抖音依靠人工智能和搜索功能吸引广告主
上周早些时候举行的第五届年度TikTok World产品峰会上,TikTok推出了一系列旨在增强该应用对广告主吸引力的功能。 新产品列表的首位是TikTok Market Scope,这是一个全新的分析平台,为广告主提供整个考虑漏斗的全面视图,使他们能够…...

Vuex:Vue.js 应用程序的状态管理模式
什么是Vuex? Vuex 是专门为 Vue.js 应用程序开发的状态管理模式 库。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。 在大型单页应用中,当多个组件共享状态时,简单的单向数据流…...

【中间件】Web服务、消息队列、缓存与微服务治理:Nginx、Kafka、Redis、Nacos 详解
Nginx 是什么:高性能的HTTP和反向代理Web服务器。怎么用:通过配置文件定义代理规则、负载均衡、静态资源服务等。为什么用:提升Web服务性能、高并发处理、负载均衡和反向代理。优缺点:轻量高效,但动态处理能力较弱&am…...
如何使用CodeRider插件在IDEA中生成代码
一、环境搭建与插件安装 1.1 环境准备 名称要求说明操作系统Windows 11JetBrains IDEIntelliJ IDEA 2025.1.1.1 (Community Edition)硬件配置推荐16GB内存50GB磁盘空间 1.2 插件安装流程 步骤1:市场安装 打开IDEA,进入File → Settings → Plugins搜…...
电脑定时关机工具推荐
软件介绍 本文介绍一款轻量级的电脑自动关机工具,无需安装,使用简单,可满足定时关机需求。 工具简介 这款关机助手是一款无需安装的小型软件,文件体积仅60KB,下载后可直接运行,无需复杂配置。 使用…...

Ubuntu 可执行程序自启动方法
使用 autostart(适用于桌面环境) 适用于 GNOME/KDE 桌面环境(如 Ubuntu 图形界面) 1. 创建 .desktop 文件 sudo vi ~/.config/autostart/my_laser.desktop[Desktop Entry] TypeApplication NameMy Laser Program Execbash -c &…...

Springboot多数据源配置实践
Springboot多数据源配置实践 基本配置文件数据库配置Mapper包Model包Service包中业务代码Mapper XML文件在某些复杂的业务场景中,我们可能需要使用多个数据库来存储和管理不同类型的数据,而不是仅仅依赖于单一数据库。本技术文档将详细介绍如何在 Spring Boot 项目中进行多数…...

第6章:Neo4j数据导入与导出
在实际应用中,数据的导入与导出是使用Neo4j的重要环节。无论是初始数据加载、系统迁移还是数据备份,都需要高效可靠的数据传输机制。本章将详细介绍Neo4j中的各种数据导入与导出方法,帮助读者掌握不同场景下的最佳实践。 6.1 数据导入策略 …...

uni-app学习笔记二十三--交互反馈showToast用法
showToast部分文档位于uniapp官网-->API-->界面:uni.showToast(OBJECT) | uni-app官网 uni.showToast(OBJECT) 用于显示消息提示框 OBJECT参数说明 参数类型必填说明平台差异说明titleString是提示的内容,长度与 icon 取值有关。iconString否图…...

Go爬虫开发学习记录
Go爬虫开发学习记录 基础篇:使用net/http库 Go的标准库net/http提供了完善的HTTP客户端功能,是构建爬虫的基石: package mainimport ("fmt""io""net/http" )func fetchPage(url string) string {// 创建自定…...

前端异步编程全场景解读
前端异步编程是现代Web开发的核心,它解决了浏览器单线程执行带来的UI阻塞问题。以下从多个维度进行深度解析: 一、异步编程的核心概念 JavaScript的执行环境是单线程的,这意味着在同一时间只能执行一个任务。为了不阻塞主线程,J…...

分布式光纤声振传感技术原理与瑞利散射机制解析
分布式光纤传感技术(Distributed Fiber Optic Sensing,简称DFOS)作为近年来迅速发展的新型感知手段,已广泛应用于边界安防、油气管道监测、结构健康诊断、地震探测等领域。其子类技术——分布式光纤声振传感(Distribut…...
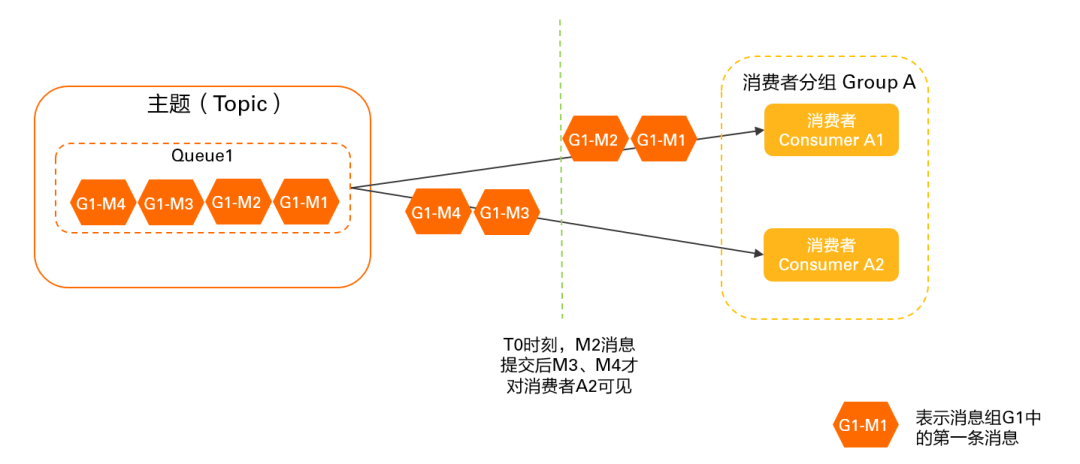
RocketMQ 客户端负载均衡机制详解及最佳实践
延伸阅读:🔍「RocketMQ 中文社区」 持续更新源码解析/最佳实践,提供 RocketMQ 专家 AI 答疑服务 前言 本文介绍 RocketMQ 负载均衡机制,主要涉及负载均衡发生的时机、客户端负载均衡对消费的影响(消息堆积/消费毛刺等…...

Q1起重机指挥理论备考要点分析
Q1起重机指挥理论备考要点分析 一、考试重点内容概述 Q1起重机指挥理论考试主要包含三大核心模块:安全技术知识(占40%)、指挥信号规范(占30%)和法规标准(占30%)。考试采用百分制,8…...

c++算法学习3——深度优先搜索
一、深度优先搜索的核心概念 DFS算法是一种通过递归或栈实现的"一条路走到底"的搜索策略,其核心思想是: 深度优先:从起点出发,选择一个方向探索到底,直到无路可走 回溯机制:遇到死路时返回最近…...

如何让非 TCP/IP 协议驱动屏蔽 IPv4/IPv6 和 ARP 报文?
——从硬件过滤到协议栈隔离的完整指南 引言 在现代网络开发中,许多场景需要定制化网络协议(如工业控制、高性能计算),此时需确保驱动仅处理特定协议,避免被标准协议(如 IPv4/IPv6/ARP)干扰。本文基于 Linux 内核驱动的实现,探讨如何通过硬件过滤、驱动层拦截和协议栈…...

组合模式:构建树形结构的艺术
引言:处理复杂对象结构的挑战 在软件开发中,我们常遇到需要处理部分-整体层次结构的场景: 文件系统中的文件与文件夹GUI中的容器与组件组织结构中的部门与员工菜单系统中的子菜单与菜单项组合模式正是为解决这类问题而生的设计模式。它允许我们将对象组合成树形结构来表示&…...

【SSM】SpringMVC学习笔记7:前后端数据传输协议和异常处理
这篇学习笔记是Spring系列笔记的第7篇,该笔记是笔者在学习黑马程序员SSM框架教程课程期间的笔记,供自己和他人参考。 Spring学习笔记目录 笔记1:【SSM】Spring基础: IoC配置学习笔记-CSDN博客 对应黑马课程P1~P20的内容。 笔记2…...

Spring Boot SQL数据库功能详解
Spring Boot自动配置与数据源管理 数据源自动配置机制 当在Spring Boot项目中添加数据库驱动依赖(如org.postgresql:postgresql)后,应用启动时自动配置系统会尝试创建DataSource实现。开发者只需提供基础连接信息: 数据库URL格…...

TI德州仪器TPS3103K33DBVR低功耗电压监控器IC电源管理芯片详细解析
1. 基本介绍 TPS3103K33DBVR 是 德州仪器(Texas Instruments, TI) 推出的一款 低功耗电压监控器(Supervisor IC),属于 电源管理芯片(PMIC) 类别,主要用于 系统复位和电压监测。 2. …...
C++课设:实现本地留言板系统(支持留言、搜索、标签、加密等)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、项目功能概览与亮点分析1. 核心功能…...
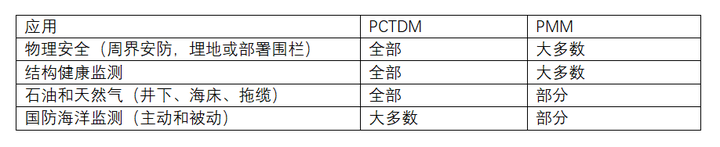
【见合八方平面波导外腔激光器专题系列】用于干涉光纤传感的低噪声平面波导外腔激光器2
----翻译自Mazin Alalus等人的文章 摘要 1550 nm DWDM 平面波导外腔激光器具有低相位/频率噪声、窄线宽和低 RIN 等特点。该腔体包括一个半导体增益芯片和一个带布拉格光栅的平面光波电路波导,采用 14 引脚蝶形封装。这种平面波导外腔激光器设计用于在振动和恶劣的…...