【向量库】Weaviate 搜索与索引技术:从基础概念到性能优化
文章目录
- 零、概述
- 一、搜索技术分类
- 1. 向量搜索:捕捉语义的智能检索
- 2. 关键字搜索:精确匹配的传统方案
- 3. 混合搜索:语义与精确的双重保障
- 二、向量检索技术分类
- 1. HNSW索引:大规模数据的高效引擎
- 2. Flat索引:小规模数据的轻量级方案
- 3. Dynamic索引:动态数据的智能适配
- 三、量化技术(与索引协同,提高搜索速度)
- 1. Product Quantization(PQ)
- 2. Binary Quantization(BQ)
- 3. Scalar Quantization(SQ)
- 四、重排序(Reranking):优化结果相关性的关键环节
零、概述
Weaviate通过向量搜索、关键字搜索、混合搜索的灵活组合,搭配HNSW、Flat、Dynamic索引及量化技术,提供了从语义理解到高效检索的完整解决方案。重排序模块进一步优化结果相关性,确保复杂场景下的搜索精度。
实际应用中,需根据数据规模、查询模式和业务需求动态调整技术栈,实现性能与效果的最佳平衡。
最佳实践:
- 索引选择指南
- 小规模数据(<1万条):Flat索引,配合BQ压缩提升磁盘性能。
- 中大规模数据(>10万条):HNSW索引,结合PQ量化优化内存占用。
- 动态数据场景:Dynamic索引,自动适配数据规模变化。
- 性能优化建议
- 向量量化优先:高维向量场景优先使用PQ+HNSW组合,平衡内存与速度。
- 参数调优:根据业务延迟要求调整HNSW的
ef参数(低延迟场景设为10-100,高召回场景设为500-1000)。- 重排序策略:对关键业务场景启用重排序,使用深度学习模型(如BERT)提升结果质量。
一、搜索技术分类
1. 向量搜索:捕捉语义的智能检索
向量搜索是基于相似度的核心技术,通过机器学习模型将文本、图像等数据转化为高维向量(如OpenAI的text-embedding-ada-002生成1536维向量),利用余弦相似度或欧氏距离度量向量间的语义关联。例如,查询“dark”时,向量搜索能匹配到语义相近的“noir”或“black”,因为它们在向量空间中距离较近。
核心原理:通过向量化器(Vectorizer)将数据转换为向量,存储于向量数据库中。查询时,系统将输入转换为向量,与库中向量进行批量比较,返回最相似的前n个结果。
适用场景:跨模态检索(如图片-文本匹配)、多语言语义搜索、推荐系统等需要理解内容语义的场景。
2. 关键字搜索:精确匹配的传统方案
关键字搜索基于BM25算法,通过统计查询词在文档中的出现频率(TF)和逆文档频率(IDF)计算相关性分数。例如,查询“法律条款”时,包含该短语且出现次数多的文档得分更高。
核心原理:分词后统计词频,结合全局词频分布评估重要性,适合精确匹配场景(如法律条文检索、医疗记录查询)。
适用场景:用户查询明确、需精确匹配术语的场景,如技术文档搜索、电商商品标题匹配。
3. 混合搜索:语义与精确的双重保障
混合搜索结合了向量搜索和关键字搜索的优点,同时考虑语义相似度和关键词精确匹配。它会并行执行两种搜索,并将结果融合,生成最终的相关性排序。
例如,查询“人工智能发展趋势”时,向量搜索捕获“AI技术演进”等语义相关结果,关键字搜索匹配“人工智能”出现频繁的文档,两者融合后提升结果全面性。
混合搜索会分别执行向量搜索和关键字搜索,然后根据设定的融合算法(如 rankedFusion 或 relativeScoreFusion)和参数(如 alpha 权重)将两者的结果合并,得到更全面且鲁棒的搜索结果。适用于主题广泛、用户输入不可预测或需要兼顾语义与精确匹配的场景Hybrid Search 概念。
二、向量检索技术分类
1. HNSW索引:大规模数据的高效引擎
HNSW(分层可导航小世界图)是Weaviate处理大规模向量数据的核心索引,通过多层图结构实现对数时间复杂度的搜索。高层图节点稀疏,用于快速定位大致区域;底层图节点密集,用于精细化搜索。
关键参数:
efConstruction:构建索引时的探索因子,数值越大(如100-500),索引质量越高但构建时间越长。ef:查询时的探索因子,数值越大(如10-1000),召回率越高但查询速度越慢。
典型应用:实时推荐系统(如电商商品推荐)、图像检索(如百万级图片库快速查询)。
2. Flat索引:小规模数据的轻量级方案
Flat索引采用线性扫描,直接遍历所有向量计算距离,无需复杂索引构建过程。适用于数据量小(如几千条)或更新频繁的场景(如开发测试阶段)。结合二进制量化(BQ)可减少磁盘I/O,提升扫描速度。
优势:简单直接,无需预处理,适合动态数据场景。
局限:数据规模增大时性能显著下降,不适合高并发或大规模数据集。
3. Dynamic索引:动态数据的智能适配
Dynamic索引根据数据规模自动切换策略:数据较小时使用Flat索引,数据量增大后自动切换为HNSW索引。无需手动调整,适合数据规模动态变化的场景(如日志数据实时写入)。
如下小结
| 索引类型 | 数据规模适用性 | 核心结构/原理 | 关键参数 | 典型结合量化技术 |
|---|---|---|---|---|
| HNSW | 大规模 | 分层导航小世界图 | efConstruction、ef | PQ |
| Flat | 小规模 | 线性扫描 | 无复杂参数 | BQ |
| Dynamic | 动态变化 | 自动切换 | 无专属参数 | 按需结合 |
三、量化技术(与索引协同,提高搜索速度)
向量量化通过压缩 向量嵌入 的内存占用,降低部署成本并提升向量相似性搜索速度。Weaviate支持三种技术:Binary Quantization(BQ)、Product Quantization(PQ)、Scalar Quantization(SQ)。
1. Product Quantization(PQ)
a. 核心原理
- 两步压缩:先将向量维度分割为多个segments(段),再对每段独立量化为低精度表示(如8位整数)。
- 质心训练:通过K-means(无监督学习聚类算法)等算法为每段生成256个质心(默认),构成码本(codebook),用最近质心ID压缩向量段。
b. 关键参数与效果
- segments数量:需整除原始向量维度,影响内存与召回(越多segments→越高内存/召回)。 例:OpenAI text-embedding-ada-002(1536维)支持512/384/256等segments(见表1)。
- 压缩比:768维向量从3072字节(float32)压缩至128字节(128 segments×1字节),压缩约24倍。
c. 适用场景:与HNSW索引结合,减少内存占用并支持高维向量搜索。
表1:常见向量器的segments配置
| 模块 | 模型 | 维度 | 支持segments |
|---|---|---|---|
| openai | text-embedding-ada-002 | 1536 | 512, 384, 256, 192, 96 |
| cohere | multilingual-22-12 | 768 | 384, 256, 192, 96 |
| huggingface | sentence-transformers/all-MiniLM-L12-v2 | 384 | 192, 128, 96 |
2. Binary Quantization(BQ)
- 核心原理:将每个向量维度转为二进制(1位/维度),压缩比达32倍(如32位→1位)。
- 特点:
- 有损压缩:信息损失显著,距离计算精度较低。
- 适用模型:Cohere V3系列(如embed-multilingual-v3.0)和OpenAI ada-002表现较好,需结合业务数据测试。
- 优化:启用 向量缓存(vector cache) 减少磁盘读取,但需平衡内存占用(n_dimensions位/向量)。
- 适用场景:配合flat索引(磁盘型),加速搜索速度。
3. Scalar Quantization(SQ)
- 核心原理:将32位浮点值转为8位整数,通过256个均匀分布桶映射数值(基于训练数据的最小/最大值)。
- 压缩比:4倍(如32位→8位),精度高于BQ。
- 优化机制: 过.fetch与重打分(Rescoring):按
rescoreLimit多获取候选向量,用原始向量重新计算距离。 例:查询limit=10,rescoreLimit=200→先取200条压缩结果,再用原始向量筛选前10条。 - 训练配置:默认10万条数据/分片,自动推导桶边界。
四、重排序(Reranking):优化结果相关性的关键环节
重排序通过重新排序搜索结果提升相关性,解决初始检索结果相关性不足的问题。例如,混合搜索返回的结果可通过重排序模块基于特定属性(如文本字段)和查询词进一步优化排序。
基本原理:
- 对每个 (查询, 数据对象) 计算 相关性分数,按分数从高到低排序。
- 仅作用于检索后的较小数据子集,避免对全量数据计算,降低计算成本。
- 可采用更复杂、计算成本更高的模型(如深度学习模型(bert))提升精度。
GraphQL示例:
{Get {JeopardyQuestion(nearText: { concepts: "flying" } // 混合搜索阶段limit: 10) {answerquestion_additional {rerank(property: "answer" // 基于answer属性重排序query: "floating" // 重排序查询词) {score // 重排序分数}}}}
}
如上查询,先通过nearText执行混合搜索,返回10条结果;再通过rerank基于answer属性和查询"floating"重排序,返回每条结果的score。
关键参数:
property:指定用于重排序的对象属性(如文本字段)。query:重排序时使用的查询词,可与检索阶段不同。
相关文章:

【向量库】Weaviate 搜索与索引技术:从基础概念到性能优化
文章目录 零、概述一、搜索技术分类1. 向量搜索:捕捉语义的智能检索2. 关键字搜索:精确匹配的传统方案3. 混合搜索:语义与精确的双重保障 二、向量检索技术分类1. HNSW索引:大规模数据的高效引擎2. Flat索引:小规模数据…...

ABB馈线保护 REJ601 BD446NN1XG
配电网基本量程数字继电器 REJ601是一种专用馈线保护继电器,用于保护一次和二次配电网络中的公用事业和工业电力系统。该继电器在一个单元中提供了保护和监控功能的优化组合,具有同类产品中最佳的性能和可用性。 REJ601是一种专用馈线保护继电器…...
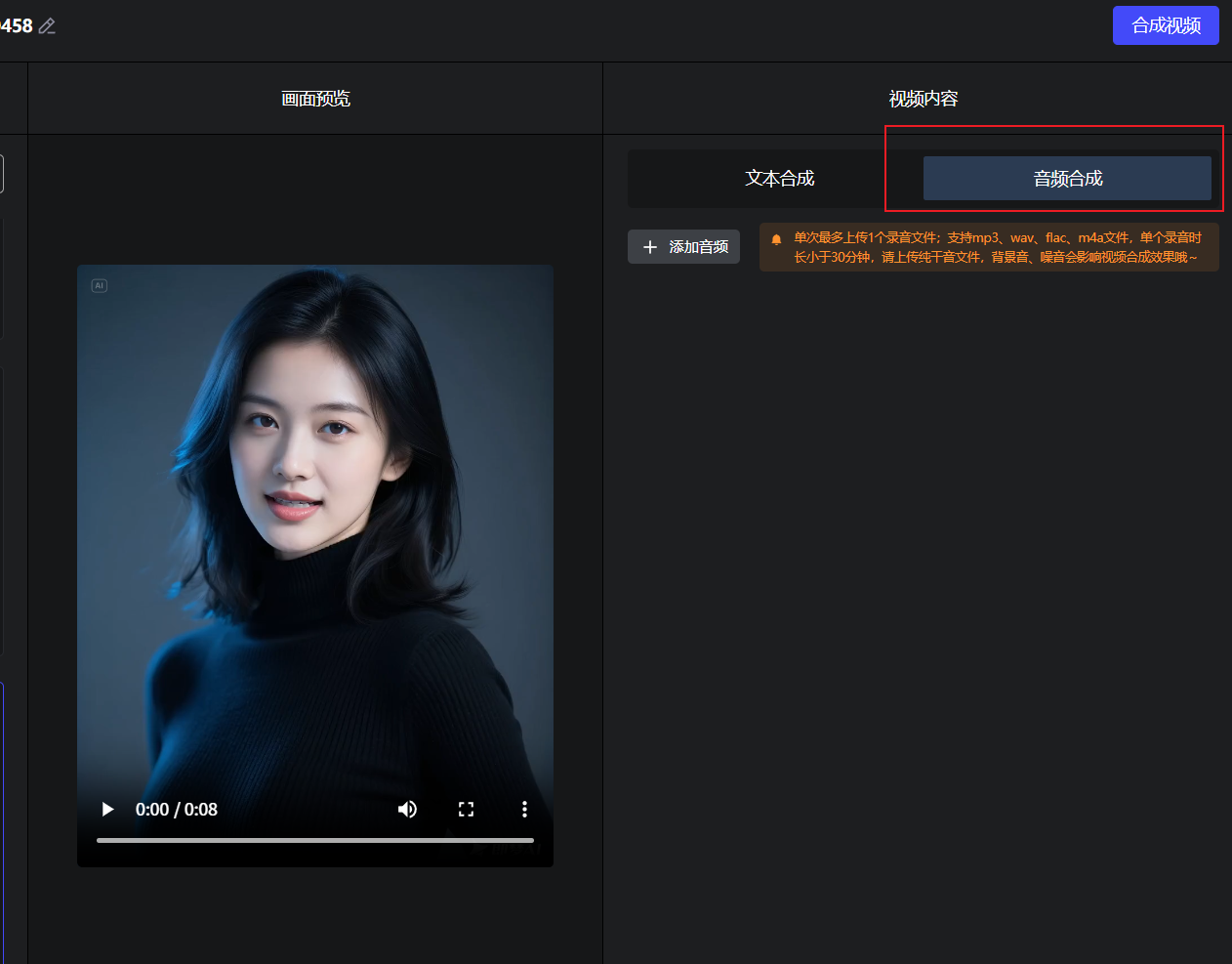
Heygem50系显卡合成的视频声音杂音模糊解决方案
如果你在使用50系显卡有杂音的情况,可能还是官方适配问题,可以使用以下方案进行解决: 方案一:剪映替换音色(简单适合普通玩家) 使用剪映换音色即可,口型还是对上的,没有剪映vip的&…...
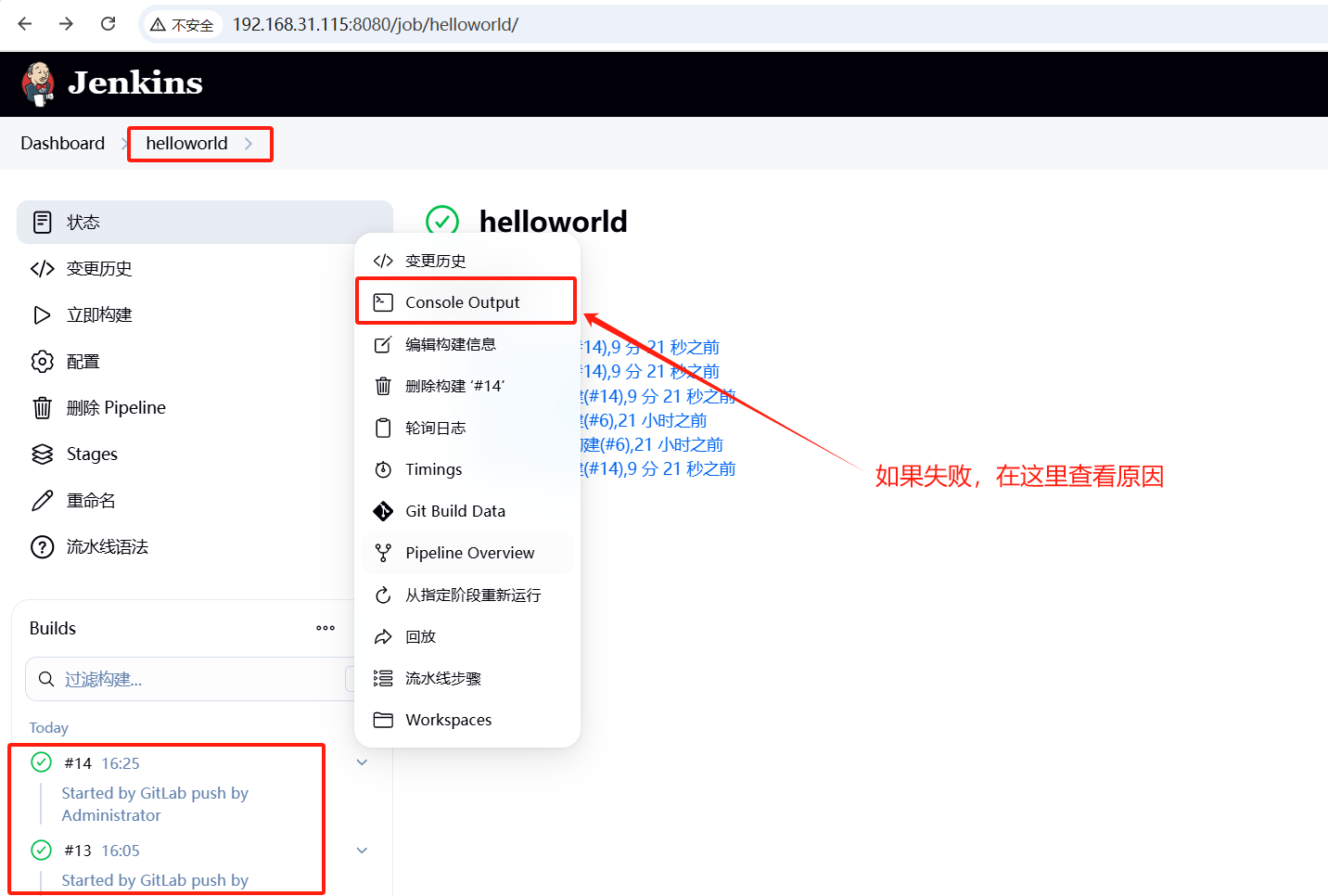
Gitlab + Jenkins 实现 CICD
CICD 是持续集成(Continuous Integration, CI)和持续交付/部署(Continuous Delivery/Deployment, CD)的缩写,是现代软件开发中的一种自动化流程实践。下面介绍 Web 项目如何在代码提交到 Gitlab 后,自动发布…...
无头浏览器技术:Python爬虫如何精准模拟搜索点击
1. 无头浏览器技术概述 1.1 什么是无头浏览器? 无头浏览器是一种没有图形用户界面(GUI)的浏览器,它通过程序控制浏览器内核(如Chromium、Firefox)执行页面加载、JavaScript渲染、表单提交等操作。由于不渲…...
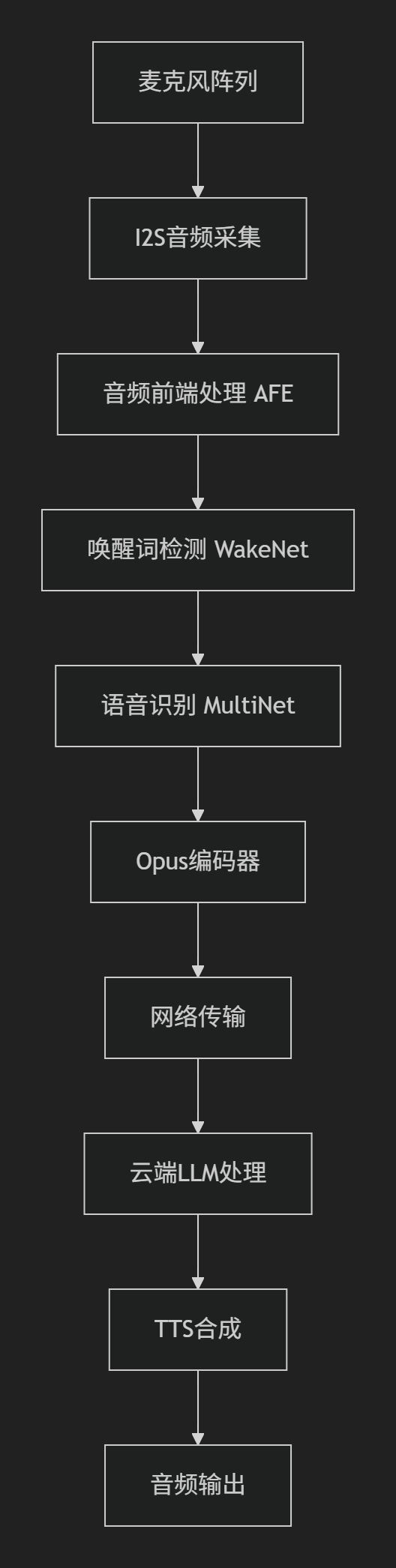
SDU棋界精灵——硬件程序ESP32实现opus编码
一、 音频处理框架 该项目基于Espressif的音频处理框架构建,核心组件包括 ESP-ADF 和 ESP-SR,以下是完整的音频处理框架实现细节: 1.核心组件 (1) 音频前端处理 (AFE - Audio Front-End) main/components/audio_pipeline/afe_processor.c功能: 声学回声…...
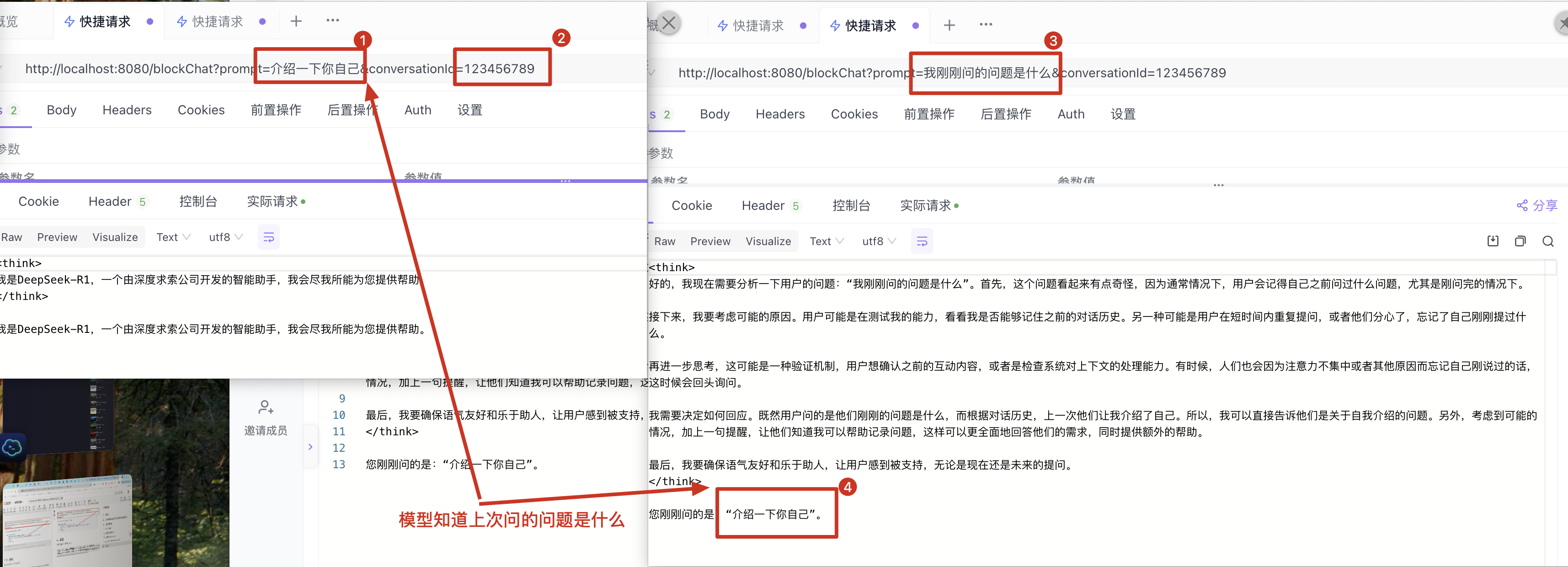
Spring AI中使用ChatMemory实现会话记忆功能
文章目录 1、需求2、ChatMemory中消息的存储位置3、实现步骤1、引入依赖2、配置Spring AI3、配置chatmemory4、java层传递conversaionId 4、验证5、完整代码6、参考文档 1、需求 我们知道大型语言模型 (LLM) 是无状态的,这就意味着他们不会保…...
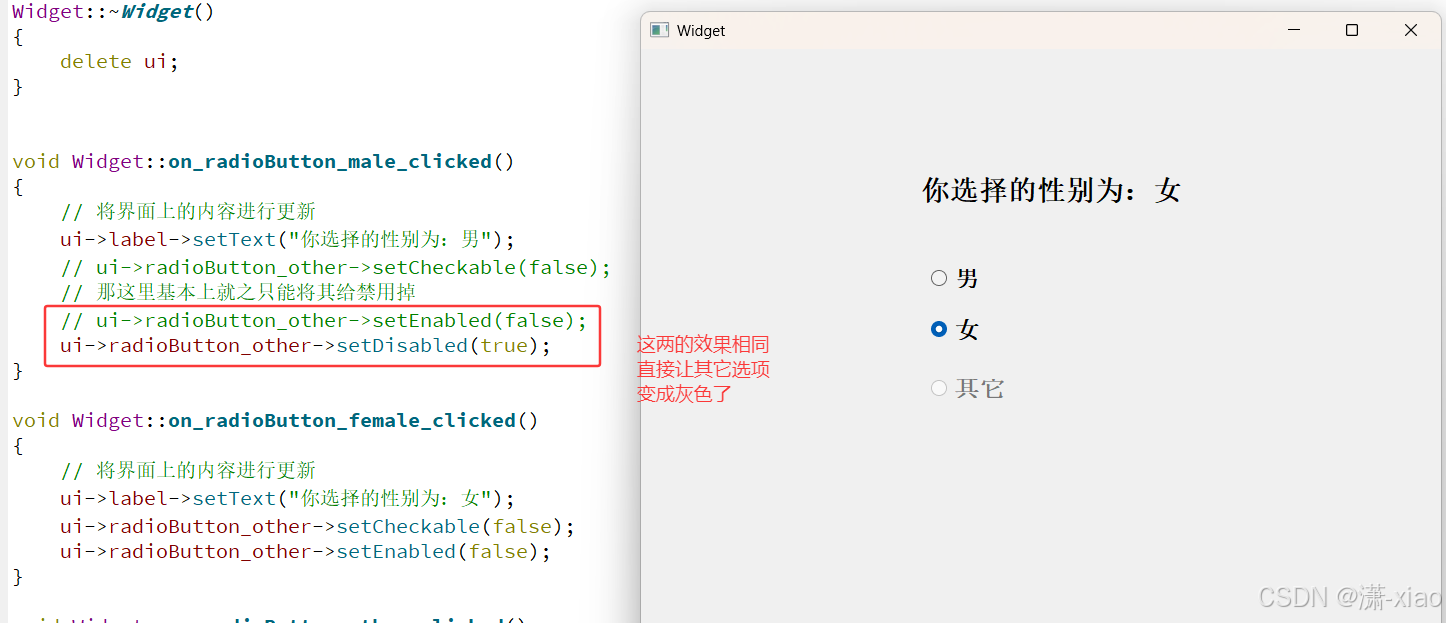
Qt 按钮类控件(Push Button 与 Radio Button)(1)
文章目录 Push Button前提概要API接口给按钮添加图标给按钮添加快捷键 Radio ButtonAPI接口性别选择 Push Button(鼠标点击不放连续移动快捷键) Radio Button Push Button 前提概要 1. 之前文章中所提到的各种跟QWidget有关的各种属性/函数/方法&#…...
生成对抗网络(GAN)损失函数解读
GAN损失函数的形式: 以下是对每个部分的解读: 1. , :这个部分表示生成器(Generator)G的目标是最小化损失函数。 :判别器(Discriminator)D的目标是最大化损失函数。 GAN的训…...
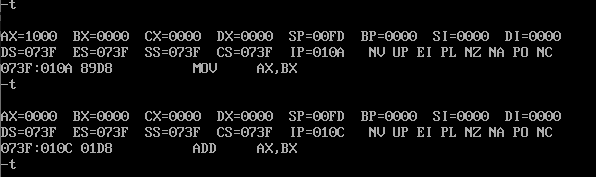
汇编语言学习(三)——DoxBox中debug的使用
目录 一、安装DoxBox,并下载汇编工具(MASM文件) 二、debug是什么 三、debug中的命令 一、安装DoxBox,并下载汇编工具(MASM文件) 链接: https://pan.baidu.com/s/1IbyJj-JIkl_oMOJmkKiaGQ?pw…...
和向下转型(Downcasting))
【Java基础】向上转型(Upcasting)和向下转型(Downcasting)
在面向对象编程中,转型(Casting) 是指改变对象的引用类型,主要涉及 继承关系 和 多态。 向上转型(Upcasting) ⬆️ 定义 将 子类对象 赋值给 父类引用(自动完成,无需强制转换&…...
)
GitHub 常见高频问题与解决方案(实用手册)
1.Push 提示权限错误(Permission denied) 问题: Bash Permission denied (publickey) fatal: Could not read from remote repository. 原因: 没有配置 SSH key 或使用了 HTTPS 而没有权限…...
数据可视化交互
目录 【实验目的】 【实验原理】 【实验环境】 【实验步骤】 一、安装 pyecharts 二、下载数据 三、实验任务 实验 1:AQI 横向对比条形图 代码说明: 运行结果: 实验 2:AQI 等级分布饼图 实验 3:多城市 AQI…...

安宝特方案丨从依赖经验到数据驱动:AR套件重构特种装备装配与质检全流程
在高压电气装备、军工装备、石油测井仪器装备、计算存储服务器和机柜、核磁医疗装备、大型发动机组等特种装备生产型企业,其产品具有“小批量、多品种、人工装配、价值高”的特点。 生产管理中存在传统SOP文件内容缺失、SOP更新不及、装配严重依赖个人经验、产品装…...
【JavaEE】万字详解HTTP协议
HTTP是什么?-----互联网的“快递小哥” 想象我们正在网上购物:打开淘宝APP,搜索“蓝牙耳机”,点击商品图片,然后下单付款。这一系列操作背后,其实有一个看不见的“快递小哥”在帮我们传递信息,…...
)
Vue3学习(接口,泛型,自定义类型,v-for,props)
一,前言 继续学习 二,TS接口泛型自定义类型 1.接口 TypeScript 接口(Interface)是一种定义对象形状的强大工具,它可以描述对象必须包含的属性、方法和它们的类型。接口不会被编译成 JavaScript 代码,仅…...
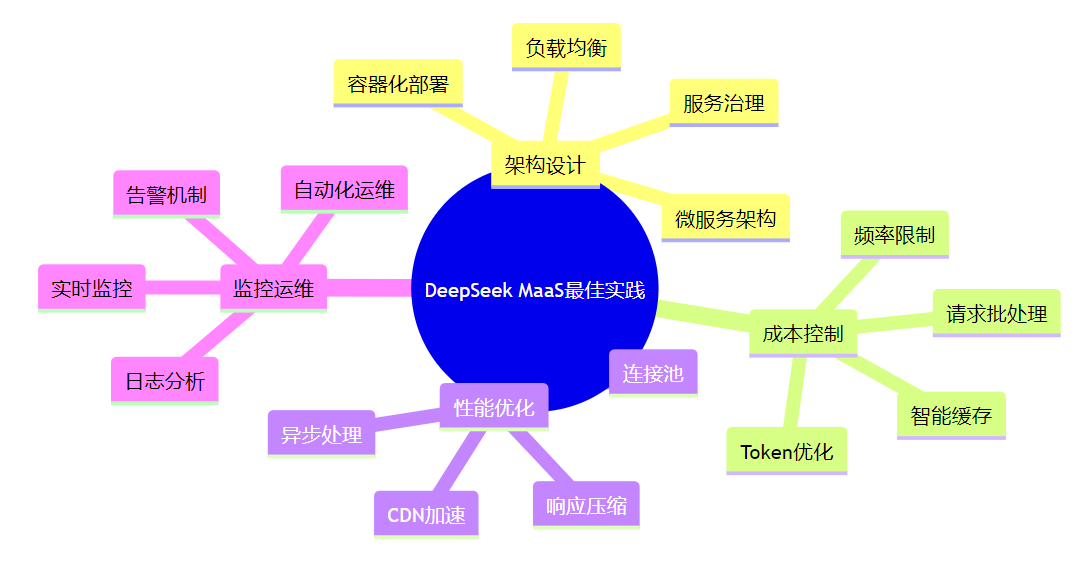
华为云Flexus+DeepSeek征文 | MaaS平台避坑指南:DeepSeek商用服务开通与成本控制
作者简介 我是摘星,一名专注于云计算和AI技术的开发者。本次通过华为云MaaS平台体验DeepSeek系列模型,将实际使用经验分享给大家,希望能帮助开发者快速掌握华为云AI服务的核心能力。 目录 作者简介 前言 一、技术架构概览 1.1 整体架构设…...

WEB3全栈开发——面试专业技能点P8DevOps / 区块链部署
一、Hardhat / Foundry 进行合约部署 概念介绍 Hardhat 和 Foundry 都是以太坊智能合约开发的工具套件,支持合约的编译、测试和部署。 它们允许开发者在本地或测试网络快速开发智能合约,并部署到链上(测试网或主网)。 部署过程…...

【动态规划】B4336 [中山市赛 2023] 永别|普及+
B4336 [中山市赛 2023] 永别 题目描述 你做了一个梦,梦里有一个字符串,这个字符串无论正着读还是倒着读都是一样的,例如: a b c b a \tt abcba abcba 就符合这个条件。 但是你醒来时不记得梦中的字符串是什么,只记得…...

可下载旧版app屏蔽更新的app市场
软件介绍 手机用久了,app越来越臃肿,老手机卡顿成常态。这里给大家推荐个改善老手机使用体验的方法,还能帮我们卸载不需要的app。 手机现状 如今的app不断更新,看似在优化,实则内存占用越来越大,对手机性…...
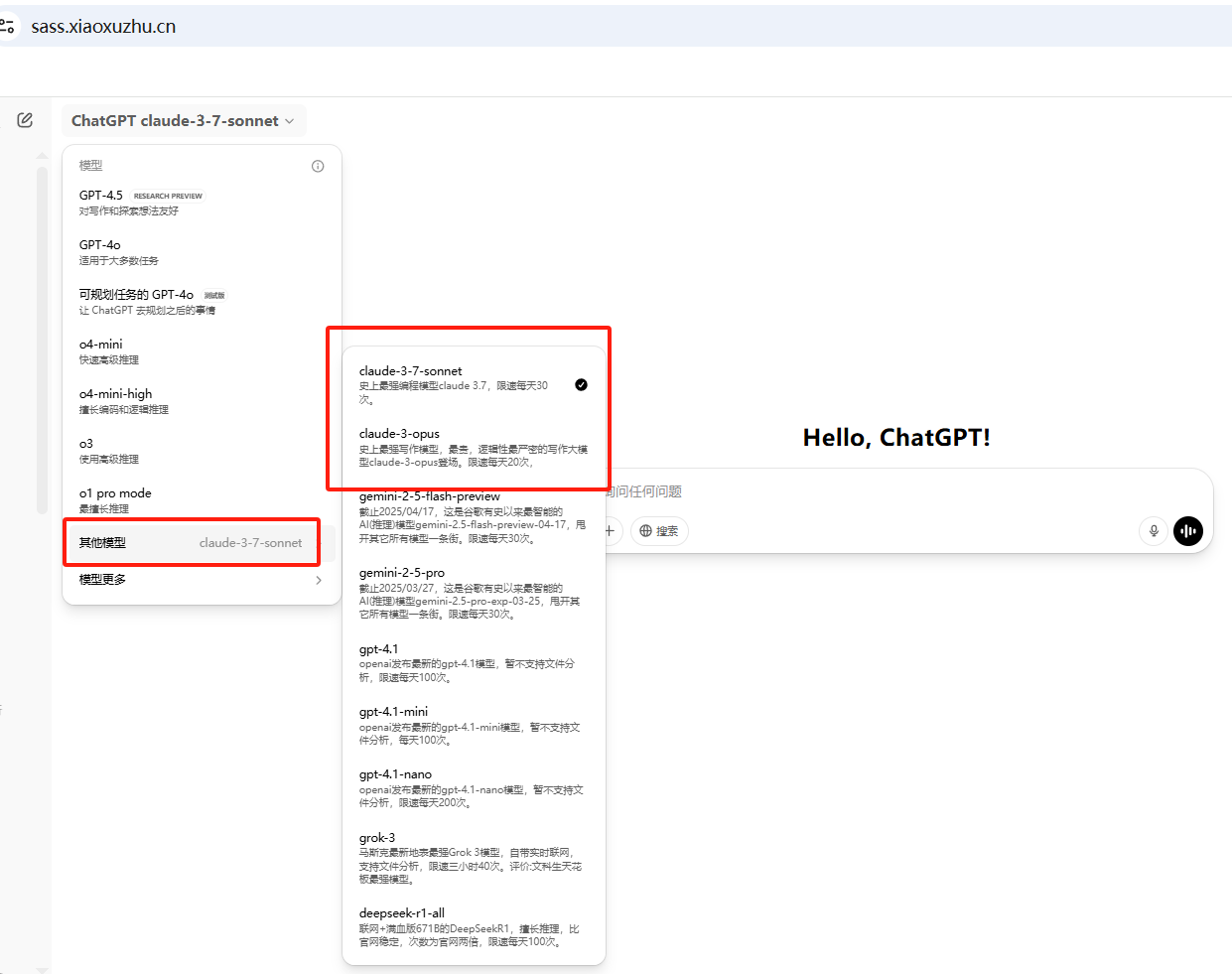
claude3.7高阶玩法,生成系统架构图,国内直接使用
文章目录 零、前言一、操作指南操作指导 二、提示词模板三、实战图书管理系统通过4o模型生成系统描述通过claude3.7生成系统架构图svg代码转换成图片 在线考试系统通过4o模型生成系统描述通过claude3.7生成系统架构图svg代码转换成图片 四、感受 零、前言 现在很多AI大模型可以…...

河北对口计算机高考MySQL笔记(完结版)(2026高考)持续更新~~~~
MySQL 基础概念 数据(Data):文本,数字,图片,视频,音频等多种表现形式,能够被计算机存储和处理。 **数据库(Data Base—简称DB):**存储数据的仓库…...
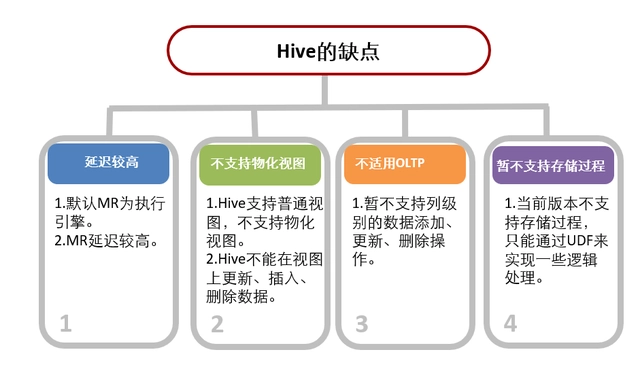
2025-06-01-Hive 技术及应用介绍
Hive 技术及应用介绍 参考资料 Hive 技术原理Hive 架构及应用介绍Hive - 小海哥哥 de - 博客园https://cwiki.apache.org/confluence/display/Hive/Home(官方文档) Apache Hive 是基于 Hadoop 构建的数据仓库工具,它为海量结构化数据提供类 SQL 的查询能力…...

DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model
一、研究背景与创新点 (一)现有方法的局限性 当前智驾系统面临两大核心挑战:一是长尾问题,即系统在遇到新场景时可能失效,例如突发交通状况或非常规道路环境;二是可解释性问题,传统方法无法解释智驾系统的决策过程,用户难以理解车辆行为的依据。传统语言模型(如 BERT…...
AI书签管理工具开发全记录(十八):书签导入导出
文章目录 AI书签管理工具开发全记录(十八):书签导入导出1.前言 📝2.书签结构分析 📖3.书签示例 📑4.书签文件结构定义描述 🔣4.1. 整体文档结构4.2. 核心元素类型4.3. 层级关系4.…...

codeforces C. Cool Partition
目录 题目简述: 思路: 总代码: https://codeforces.com/contest/2117/problem/C 题目简述: 给定一个整数数组,现要求你对数组进行分割,但需满足条件:前一个子数组中的值必须在后一个子数组中…...

TMC2226超静音步进电机驱动控制模块
目前已经使用TMC2226量产超过20K,发现在静音方面做的还是很不错。 一、TMC2226管脚定义说明 二、原理图及下载地址 一、TMC2226管脚定义说明 引脚编号类型功能OB11电机线圈 B 输出 1BRB2线圈 B 的检测电阻连接端。将检测电阻靠近该引脚连接到地。使用内部检测电阻时,将此引…...
docker容器互联
1.docker可以通过网路访问 2.docker允许映射容器内应用的服务端口到本地宿主主机 3.互联机制实现多个容器间通过容器名来快速访问 一 、端口映射实现容器访问 1.从外部访问容器应用 我们先把之前的删掉吧(如果不删的话,容器就提不起来,因…...

安宝特案例丨寻医不再长途跋涉?Vuzix再次以AR技术智能驱动远程医疗
加拿大领先科技公司TeleVU基于Vuzix智能眼镜打造远程医疗生态系统,彻底革新患者护理模式。 安宝特合作伙伴TeleVU成立30余年,沉淀医疗技术、计算机科学与人工智能经验,聚焦医疗保健领域,提供AR、AI、IoT解决方案。 该方案使医疗…...

Modbus转Ethernet IP深度解析:磨粉设备效率跃升的底层技术密码
在建材矿粉磨系统中,开疆智能Modbus转Ethernet IP网关KJ-EIP-101的应用案例是一个重要的技术革新。这个转换过程涉及到两种主要的通信协议:Modbus和Ethernet IP。Modbus是一种串行通信协议,广泛应用于工业控制系统中。它简单、易于部署和维护…...