【java面试】微服务篇
【java面试】微服务篇
- 一、总体框架
- 二、Springcloud
- (一)Springcloud五大组件
- (二)服务注册和发现
- 1、Eureka
- 2、Nacos
- (三)负载均衡
- 1、Ribbon负载均衡流程
- 2、Ribbon负载均衡策略
- 3、自定义负载均衡策略
- 4、总结
- (四)服务雪崩、熔断降级
- 1、服务雪崩
- 1.1 情景描述
- 1.2 问题解决
- 2、熔断降级
- 3、总结
- (五)监控微服务
- 1、微服务监控
- 2、监控工具—— skywalking
- 2.1 问题定位
- 2.2 性能分析
- 2.3 服务关系
- 2.4 服务告警
- 3、总结
- 三、业务相关
- (一)限流
- 1、限流原因
- 2、限流方式
- 3、Nginx限流
- 3.1 控制速率(突发流量)——漏桶算法
- 3.2 控制并发的连接数
- 4、网关限流
- 5、总结
- (二)CPA和BASE
- 1、CAP定理
- 1.1 一致性-Consistency
- 1.2 可用性-Avaliability
- 1.3 分区容错性-Partition toleratance
- 2、BASE理论
- 3、总结
- (三)分布式事务解决方案
- 1、Seata架构
- 1.1 XA模式
- 1.2 AT模式
- 1.3 TCC模式
- 2、MQ分布式事务
- 3、总结
- (四)分布式服务接口幂等性
- 1、接口幂等——基于RESTful风格定义接口
- 2、解决幂等问题
- 2.1 token + redis
- 2.2 分布式锁
- 3、总结
- (五)分布式任务调度
- 1、xxl-job路由策略
- 2、xxl-job任务失败怎么解决
- 3、大数据量的任务同时都需要执行,怎么解决?
- 4、总结
- 四、消息中间件
- (一)RbbitMQ
- 1、消息不丢失
- 1.1 生产者确认机制
- 1.2 消息持久化
- 1.3 消费者确认
- 1.4 总结
- 2、重复消费问题
- 3、死信交换机(延迟队列)
- 3.1 死信交换机
- 3.2 TTL
- 3.3 延迟队列
- 3.4 总结
- 4、RabbitMQ消息堆积
- 5、RabbitMQ高可用机制
- 5.1 普通集群
- 5.2 镜像集群
- 5.3 仲裁队列
- 5.4 总结
- (二)Kafka
- 1、Kafka如何保证消息不丢失
- 1.1 生产者发送消息到Brocker丢失
- 1.2 消息在Brocker中存储丢失
- 1.3 消费者从Brocker中接收消息丢失
- 1.4 总结
- 2、Kafka如何保证消费顺序性
- 3、高可用机制
- 4、数据清理机制
- 4.1 文件存储机制
- 4.2 数据清理机制
- 4.3 总结
- 5、kafka实现高性能的设计
一、总体框架

二、Springcloud
(一)Springcloud五大组件

如上图按照业务进行微服务划分,微服务之间需要远程调用,每个服务的地址需要动态的管理起来,就需要用到注册中心。远程调用组要用到的组件:Feign。服务是有集群的,需要用到Ribbon集群负载均衡。在远程调用中可能会出现降级或者熔断,就要用到Hystrix服务熔断。微服务要对外暴露接口,统一使用的是网关Zuul/Gateway,网关是服务的入口。
(二)服务注册和发现
问:服务注册和发现是什么意思?Springcloud如何实现服务注册发现?
- 微服务中必须要使用的组件,考察我们使用微服务的程度
- 注册中心的核心作用是:服务注册和发现
- 常见的注册中心:
eureka、nocas、zookeeper
1、Eureka

服务注册:服务提供者将自己的数据注册带注册中心中。
服务发现:(比如订单要远程调用)消费者向要从注册中心拉取数据
健康监测机制:监控服务提供者宕机,服务提供者定期向注册中心发送心跳说明是一个健康的实例,如果某个实例一直未发送心跳超过预定时间,注册中心就认为当前某台实例挂机了,就从服务列表删除。


2、Nacos
如果是临时实例那么就和Eureka是一样的。




(三)负载均衡
项目负载均衡如何实现?
负载均衡Ribbon,发起远程调用feign就会使用Ribbon
Ribbon负载均衡策略有哪些?
如果想自定义负载均衡如何实现?
1、Ribbon负载均衡流程

2、Ribbon负载均衡策略
Ribbon负载均衡策略:Ribbon的七种负载均衡策略详解

3、自定义负载均衡策略
可以自己创建类实现IRule接口,然后再通过配置类或者配置文件配置即可,通过定义IRule实现可以修改负载均衡规则,有两种方式:

4、总结

(四)服务雪崩、熔断降级
1、服务雪崩
1.1 情景描述
服务雪崩:一个服务失败,导致整个链路的服务都失败的情况。

如图,服务D宕机导致全部服务失败的情况。
1.2 问题解决
①熔断降级(解决)——Hystix服务熔断降级
服务降级是服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃。

如图,更新正常没有问题,但是在保存时是不行的,加入降级思想(保存时提示:您的网络有问题,请稍后再试)

如图,当可以正常访问时,走的是第一个正常Feign远程调用,但是调用失败时。当访问失败就会走降级逻辑,即第二个返回“获取数据失败”。
②限流(预防)
2、熔断降级
熔断降级:熔断和降级的真实关系,图文并茂,看完秒懂
在当前降级后,仍有大量请求,达到一定阈值,就会触发熔断机制。
Hystrix 熔断机制,用于监控微服务调用情况,默认是关闭的,如果需要开启需要在引导类上添加注解:@EnableCircuitBreaker如果检测到10秒内请求的失败率超过50%,就触发熔断机制。之后每隔5秒重新尝试请求微服务,如果微服务不能响应,继续走熔断机制。如果微服务可达,则关闭熔断机制,恢复正常请求

3、总结

(五)监控微服务
- 为什么需要监控微服务?
- 微服务是如何监控的?
1、微服务监控

- 问题定位:PC端发送请求,需要用到服务A,服务A需要用到服务G、服务H,服务H需要用到服务K,此时服务宕机了,需要快速找到那个微服务出现错误。
- 性能分析:在以上服务需求的链路中,接口响应时间较长,当前链路有一个服务接口较慢都会导致这种情况,如何迅速定位分析
- 服务关系:微服务之前相互远程调用,服务之间的关系我们需要清楚
- 服务告警:服务链路出现问题后,迅速知悉
常见的服务监控工具:
- Springboot-admin
- prometheus+Gratanazipkin
- zipkin
- skywalking
微服务监控工具:九大微服务监控工具详解
2、监控工具—— skywalking
一个分布式系统的应用程序性能监控工具(Application Performance Managment ),提供了完善的链路追踪能力, apache的顶级项目(前华为产品经理吴晟主导开源))

- 服务(service) : 业务资源应用系统(微服务),可以理解为每个微服务就是一个服务,包括网关
- 端点(endpoint) :应用系统对外暴露的功能接口(接口)
- 实例(instance):物理机
2.1 问题定位

2.2 性能分析
追踪较慢的服务:

2.3 服务关系
标红表示当前服务不太健康

2.4 服务告警

3、总结

三、业务相关

(一)限流
1、限流原因
- 并发确实比较大(突发流量)
- 防止用户恶意刷接口

2、限流方式
①Tomcat:可以设置最大连接数微服务
如果是单体项目,可以使用,如果是分布式项目,那么每个微服务就是一个Tomcat,此时就不适用了

②Nginx:漏铜算法

③网关:令牌桶算法

④自定义拦截器
3、Nginx限流
3.1 控制速率(突发流量)——漏桶算法

语法: limit_req_zone key zone rate
- key:定义限流对象,binary_remote_addr就是一种key,基于客户端ip限流
- Zone:定义共享存储区来存储访问信息,10m可以存储16wip地址访问信息
- Rate:最大访问速率,rate=10r/s表示每秒最多请求10个请求
- burst=20:相当于桶的大小
- Nodelay:快速处理(来的请求快速处理,不让等待,桶满之后再来的请求快速抛弃)
3.2 控制并发的连接数

- limit_conn perip 20:对应的key是$binary_remote_addr,表示限制单个IP同时最多能持有20个连接
- limit_conn perserver 100:对应的key是$server_name,表示虚拟主机(server)同时能处理并发连接的总数(当前服务最多能够承受的并发连接数)。
- 还需在主机或者反向代理中配置
4、网关限流
yml配置文件中,微服务路由设置添加局部过滤器RequestRateLimiter

- key-resolver:定义限流对象( ip、路径、参数),需代码实现,使用spel表达式获取
- replenishRate :令牌桶每秒填充平均速率。
- urstCapacity :令牌桶总容量。
- 令牌需要存储到redis,在网关配置文件中需要配置redis连接

区别:令牌桶存储令牌处理速率不固定,漏桶存储请求且处理速率固定。
5、总结

(二)CPA和BASE
可以对分布式事务方案的指导,分布式系统设计方向,根据业务指导使用正确的技术选择
1、CAP定理
1998年,加州大学的计算机科学家Eric Brewer提出,分布式系统有三个指标:.
Consistency (一致性)Availability (可用性)Partition tolerance(分区容错性)
Eric Brewer说,分布式系统无法同时满足这三个指标。这个结论就叫做CAP定理。

1.1 一致性-Consistency

1.2 可用性-Avaliability
该结点是否能正常访问:

1.3 分区容错性-Partition toleratance

总结:
- 分布式系统节点之间肯定是需要网络连接的,分区(P)是必然存在的
- 如果保证访问的高可用性(A),可以持续对外提供服务,但不能保证数据的强一致性–>AP
- 如果保证访问的数据强一致性( C),就要放弃高可用性–>CP
2、BASE理论
BASE理论是对CAP的一种解决思路,包含三个思想:
- Basically Available(基本可用)︰分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- Soft State(软状态)︰在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性)︰虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。

3、总结

(三)分布式事务解决方案
只要是微服务就会发起远程调用,那么就会存在分布式事务。

1、Seata架构
Seata事务管理中有三个重要的角色:
- TC (Transaction Coordinator)-事务协调者:维护全局和分支事务的状态协调全局事务提交或回滚。
- TM((Transaction Manager)-事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM(Resource Manager)-资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。(可以认为是某一个微服务,也叫分支事物)
(简单理解:TC项目管理、TM开发小组leader、RM开发员工、员工负责各个微服务,leader只管把人拉群,项目管理负责协调各模块对接和进度)

1.1 XA模式
保证强一致性——CP

1.2 AT模式
性能较好,各个事务不用互相等待,都提交,不用长时间锁定——AP

1.3 TCC模式
性能较好——AP,但是需要手动代码实现

2、MQ分布式事务
异步,性能较好,但是实时性最差,强一致性要求不高可以使用

3、总结

(四)分布式服务接口幂等性

1、接口幂等——基于RESTful风格定义接口

2、解决幂等问题

2.1 token + redis
打开页面就向后台发送请求,为页面生成一个唯一token,存储到redis(用户是key token就是value),返回token给前端
点击提交订单,将刚才的token带过来,验证token存在处理业务并删除token(第二次第三次请求就不会成功),不存在则返回

2.2 分布式锁

3、总结

(五)分布式任务调度

1、xxl-job路由策略
实例1和实例2是集群的关系,都可以去执行这些任务,每个任务都需要去找一台机器执行,这种任务找机器的方式就是路由策略

- FIRST(第一个):固定选择第一个机器;
- LAST(最后一个)∶固定选择最后一个机器;
ROUND(轮询)- RANDOM(随机)︰随机选择在线的机器;
- CONSISTENT_HASH (一致性HASH)︰每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
- LEAST_FREQUENTLY_USED(最不经常使用)︰使用频率最低的机器优先被选举;
- LEAST_RECENTLY_USED(最近最久未使用)︰最久未使用的机器优先被选举;
FAILOVER(故障转移)∶按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;- BUSYOVER(忙碌转移)︰按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
2、xxl-job任务失败怎么解决


如何设置邮件告警:


3、大数据量的任务同时都需要执行,怎么解决?

①路由策略要设置为分片广播
②在代码中拿到index和total参数
4、总结

四、消息中间件
提供了消息之间的异步调用,让服务与服务之间解耦,还可以做到削峰填耦。

(一)RbbitMQ
1、消息不丢失
RabbitMQ如何保证消息不丢失?

RabbitMQ的使用场景:RabbitMQ的七中典型使用场景
RabbitMQ的日常业务使用场景:https://zhuanlan.zhihu.com/p/400899723
在三个层面都会发生消息丢失:

1.1 生产者确认机制
RabbitMQ提供了publisher confirm机制来避免消息发送到MQ过程中丢失。消息发送到MQ以后,会返回一个结果(ack)给发送者,表示消息是否处理成功

发送失败处理流程:
- 回调方法即时重发(收到失败结果时已经知道出现问题的地方,立即重新发送)
- 记录日志
- 保存到数据库然后定时重发,成功发送后即刻删除表中的数据
1.2 消息持久化
消息正常发送到队列中,但是MQ宕机了。
MQ默认是内存存储消息,开启持久化功能(将数据保存到磁盘上)可以确保缓存在MQ中的消息不丢失。
①交换机持久化

②队列持久化

③消息持久化:SpringAMQP中的的消息默认是持久的,可以通过MessageProperties中的DeliveryMode来指定

1.3 消费者确认
RabbitMQ支持消费者确认机制,即:消费者处理消息后可以向MQ发送ack回执,MQ收到ack回执后才会删除该消息。而SpringAMQP则允许配置三种确认模式:
- manual:手动ack,需要在业务代码结束后,调用api发送ack。
- auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack入
- none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除

消息接收失败处理:我们可以利用Spring的retry机制,在消费者出现异常时利用本地重试,设置重试次数,当次数达到了以后,如果消息依然失败,将消息投递到异常交换机,交由人工处理

1.4 总结


2、重复消费问题

①消费者正常处理完消息,还没发送确认机制,此时网络抖动或者消费者挂了。
②网络恢复和消费者重启后,由于之前MQ没有收到确认,消息还在MQ中,加之设置了重试机制,消费者重新消费该消息。
解决方案:
- 每一条消息设置一个唯一的标识id(首选)
- 幂等方案【分布式锁、数据库锁(悲观锁、乐观锁)】

适用于任何MQ:
- Kafka
- RabbitMQ
- RocketMq
- …

3、死信交换机(延迟队列)
谈谈对RabbitMQ中死信交换机的理解?(RabbitMQ延迟队列有了解过吗)

3.1 死信交换机
当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter) :
- 消费者使用basic.reject或 basic.nack声明消费失败,并且消息的requeue参数设置为talse.
- 消息是一个过期消息,超时无人消费
- 要投递的队列消息堆积满了,最早的消息可能成为死信
如果该队列配置了dead-letter-exchange属性,指定了一个交换机(同时还要指定一个队列作为死信队列),那么队列中的死信就会投递到这个交换机中,而这个交换机称为死信交换机 (Dead Letter Exchange,简称DLX)。


3.2 TTL
TTL,也就是Time-To-Live。如果一个队列中的消息TTL结束仍未消费,则会变为死信,ttl超时分为两种情况(谁时间短就以谁为准):·
- 消息所在的队列设置了存活时间
- 消息本身设置了存活时间


3.3 延迟队列
延迟队列 = TTL + 死信交换机:消息设置TTL,到时间仍旧没被消费就变成死信,转发到死信交换机,绑定新的队列消费该消息。
另一种实现方式:延迟队列插件
DelayExchange插件,需要安装在RabbitMQ中,RabbitMQ有一个官方的插件社区,地址为: https://www.rabbitmq.com/community-plugins.html

DelayExchange的本质还是官方的三种交换机,只是添加了延迟功能。因此使用时只需要声明一个父换礼,父换类型可以是任意类型,然后设定delayed属性为true即可。


3.4 总结


4、RabbitMQ消息堆积

惰性队列(扩大内存容积,提高堆积上限)特征:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储
惰性队列开启方式:
①配置

②注解

总结:


5、RabbitMQ高可用机制

5.1 普通集群
普通集群,或者叫标准集群(classic cluster),具备下列特征:
①会在集群的各个节点间共享部分数据,包括:交换机、队列元信息。不包含队列中的消息。·
队列引用信息就是队列元信息,只起到引用作用,不包含队列中的消息

②当访问集群某节点时,如果队列不在该节点,会从数据所在节点传递到当前节点并返回。

③队列所在节点宕机,队列中的消息就会丢失

5.2 镜像集群
镜像集群:本质是主从模式,具备下面的特征:
- 交换机、队列、队列中的消息会在各个mq的镜像节点之间同步备份。
- 创建队列的节点被称为该队列的主节点,备份到的其它节点叫做该队列的镜像节点。
- 一个队列的主节点可能是另一个队列的镜像节点
- 所有操作都是主节点完成,然后同步给镜像节点
- 主结点宕机后,镜像节点会替代成新的主(替代方式——>仲裁队列)

5.3 仲裁队列
仲裁队列:仲裁队列是3.8版本以后才有的新功能,用来替代镜像队列,具备下列特征:。与镜像队列一样,都是主从模式,支持主从数据同步
- 使用非常简单,没有复杂的配置
- 主从同步基于Raft协议,强一致

5.4 总结


(二)Kafka
1、Kafka如何保证消息不丢失

Kafka发送消息,有同步的,异步的,但是同步的一般会产生阻塞,所以一般选择异步的。
1.1 生产者发送消息到Brocker丢失
①设置异步发送

如果消息发送失败,e!= null。但是有时候失败是因为网络抖动,那么启用消息重试机制。
②消息重试

1.2 消息在Brocker中存储丢失
- 发送确认机制


1.3 消费者从Brocker中接收消息丢失
一个Kafka集群是由多个Brocker组成,可以理解为Kafka实例,topic是消费者订阅的主题用来确定消费者从哪个队列里接收消息,topic是逻辑上的划分,分区是物理上的。

- Kafka中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区都是按照偏移量存储消息
- topic分区中消息只能由消费者组中的唯一一个消费者处理,不同的分区分配给不同的消费者(同一个消费者组)

消费偏移量:记录目前已经消费到哪里了。
重平衡:当某一个消费者宕机,由其他消费者接收它的分区,目前有存在已经消费但是还没有提交的偏移量(丢失数据),宕机前还没消费完,但是已经提交,下一个接受的消费者就会从上次提交的地方继续消费(重复消费)。

同步+异步提交:

1.4 总结


2、Kafka如何保证消费顺序性


一个消费者负责多个分区,每个分区都维护了偏移量,存储时在按照一定的策略找到不同的分区进行分区存储的,消费也是按照一定的策略从分区中取出,并不能保证消费消息的顺序性。
topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。


3、高可用机制


- Kafka的服务器端由被称为Broker的服务进程构成,即一个Kafka集群由多个Broker组成
- 这样如果集群中某一台机器宕机,其他机器上的Broker也依然能够对外提供服务。这其实就是Kafka 提供高可用的手段之一





4、数据清理机制

4.1 文件存储机制

4.2 数据清理机制
①根据消息的保留时间,当消息在kafka中保存的时间超过了指定的时间,就会触发清理过程

②根据topic存储的数据大小,当topic所占的日志文件大小大于一定的阈值,则开始删除最久的消息。需手动开启

4.3 总结


5、kafka实现高性能的设计

零拷贝:减少数据拷贝次数
正常拷贝过程:4次



相关文章:
【java面试】微服务篇
【java面试】微服务篇 一、总体框架二、Springcloud(一)Springcloud五大组件(二)服务注册和发现1、Eureka2、Nacos (三)负载均衡1、Ribbon负载均衡流程2、Ribbon负载均衡策略3、自定义负载均衡策略4、总结 …...

HTTPS证书一年多少钱?
HTTPS证书作为保障网站数据传输安全的重要工具,成为众多网站运营者的必备选择。然而,面对市场上种类繁多的HTTPS证书,其一年费用究竟是多少,又受哪些因素影响呢? 首先,HTTPS证书通常在PinTrust这样的专业平…...
Python环境安装与虚拟环境配置详解
本文档旨在为Python开发者提供一站式的环境安装与虚拟环境配置指南,适用于Windows、macOS和Linux系统。无论你是初学者还是有经验的开发者,都能在此找到适合自己的环境搭建方法和常见问题的解决方案。 快速开始 一分钟快速安装与虚拟环境配置 # macOS/…...
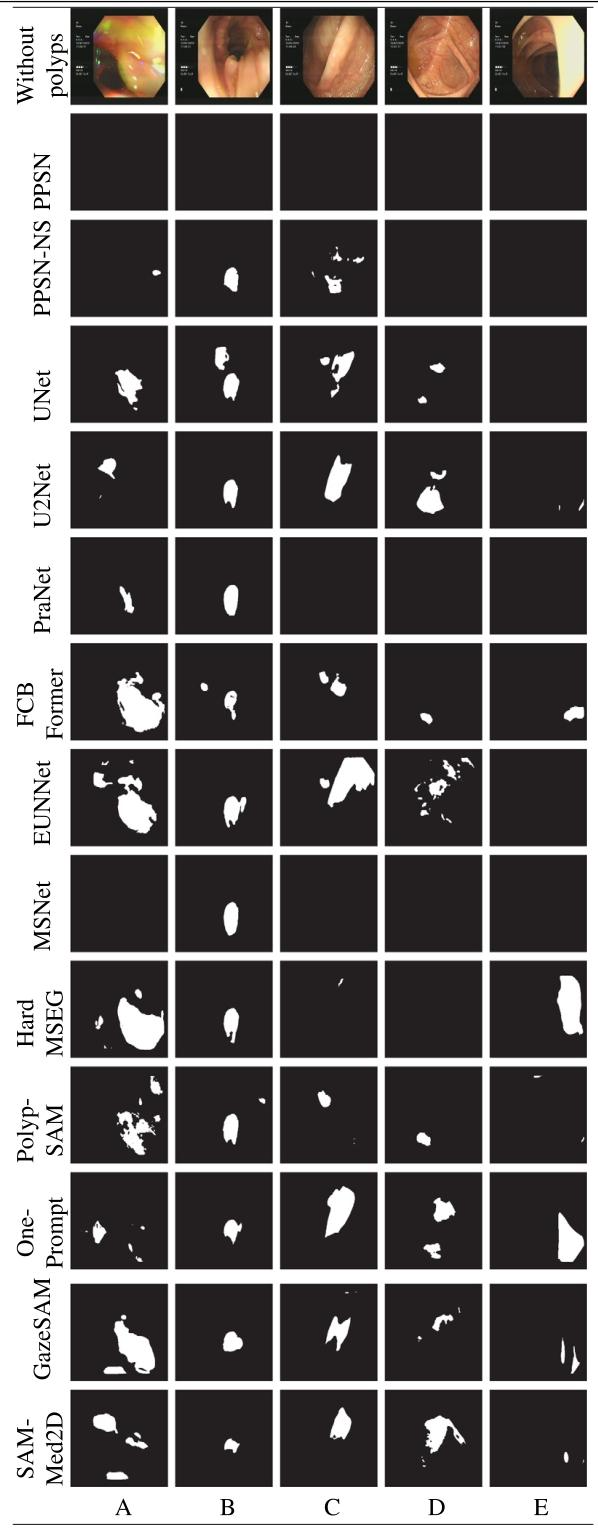
内窥镜检查中基于提示的息肉分割|文献速递-深度学习医疗AI最新文献
Title 题目 Prompt-based polyp segmentation during endoscopy 内窥镜检查中基于提示的息肉分割 01 文献速递介绍 以下是对这段英文内容的中文翻译: ### 胃肠道癌症的发病率呈上升趋势,且有年轻化倾向(Bray等人,2018&#x…...
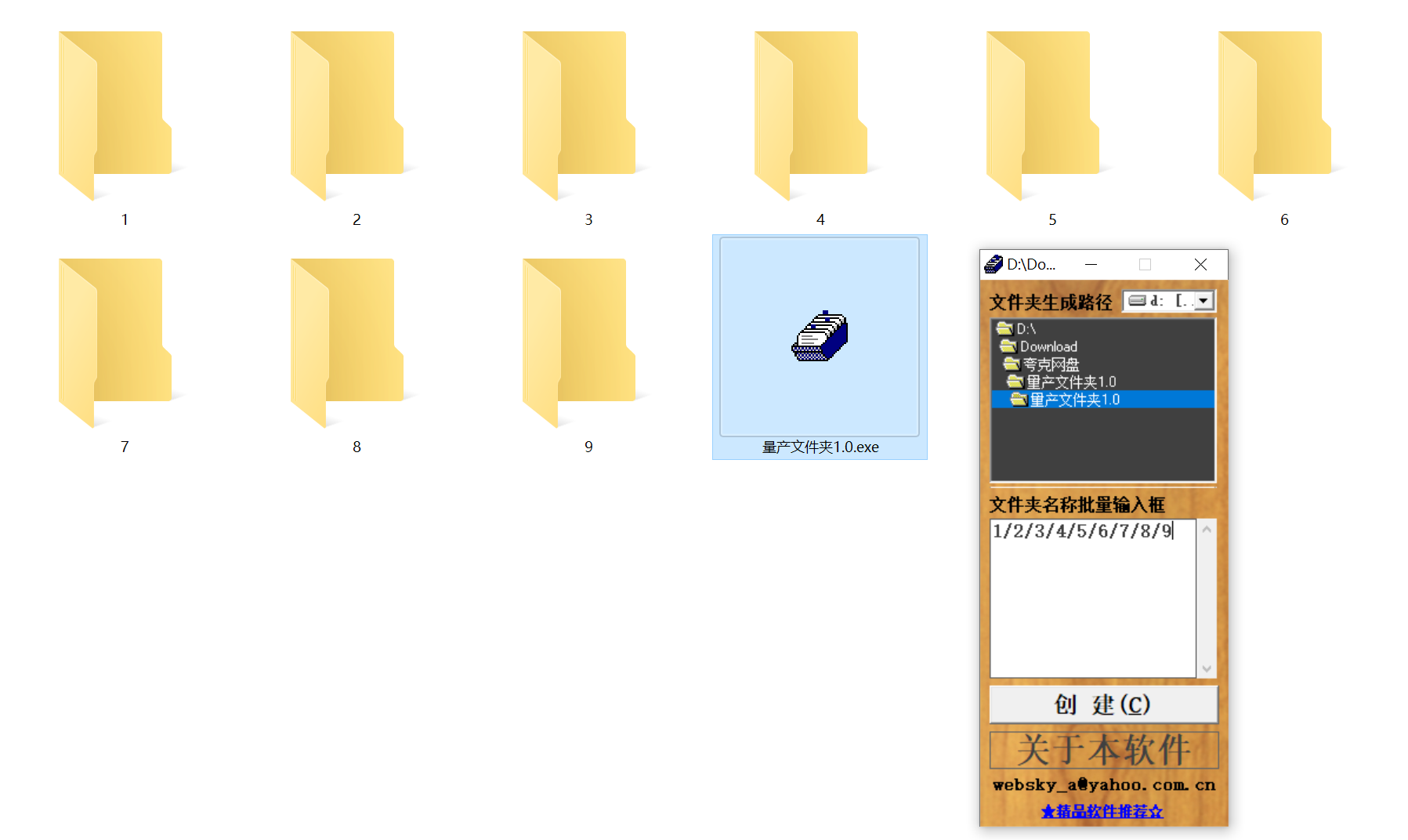
结构化文件管理实战:实现目录自动创建与归类
手动操作容易因疲劳或疏忽导致命名错误、路径混乱等问题,进而引发后续程序异常。使用工具进行标准化操作,能有效降低出错概率。 需要快速整理大量文件的技术用户而言,这款工具提供了一种轻便高效的解决方案。程序体积仅有 156KB,…...
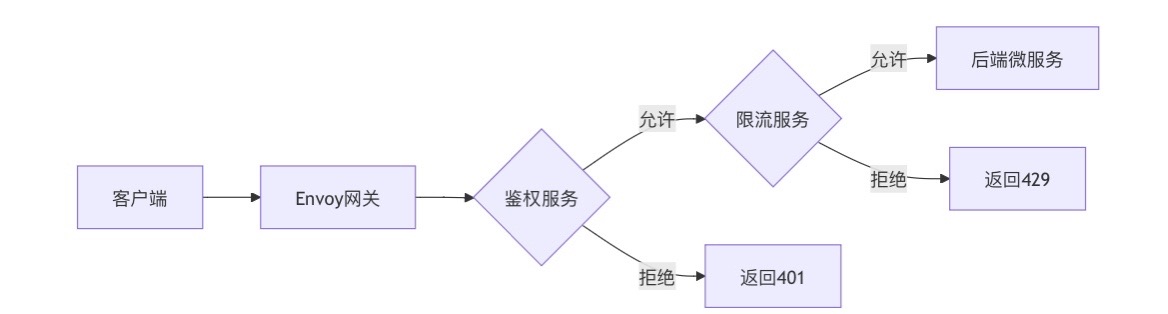
云原生安全实战:API网关Envoy的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关 作为微服务架构的统一入口,负责路由转发、安全控制、流量管理等核心功能。 2. Envoy 由Lyft开源的高性能云原生…...

写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里
写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里 脚本1 #!/bin/bash #定义变量 ip10.1.1 #循环去ping主机的IP for ((i1;i<10;i)) doping -c1 $ip.$i &>/dev/null[ $? -eq 0 ] &&am…...

Django RBAC项目后端实战 - 03 DRF权限控制实现
项目背景 在上一篇文章中,我们完成了JWT认证系统的集成。本篇文章将实现基于Redis的RBAC权限控制系统,为系统提供细粒度的权限控制。 开发目标 实现基于Redis的权限缓存机制开发DRF权限控制类实现权限管理API配置权限白名单 前置配置 在开始开发权限…...
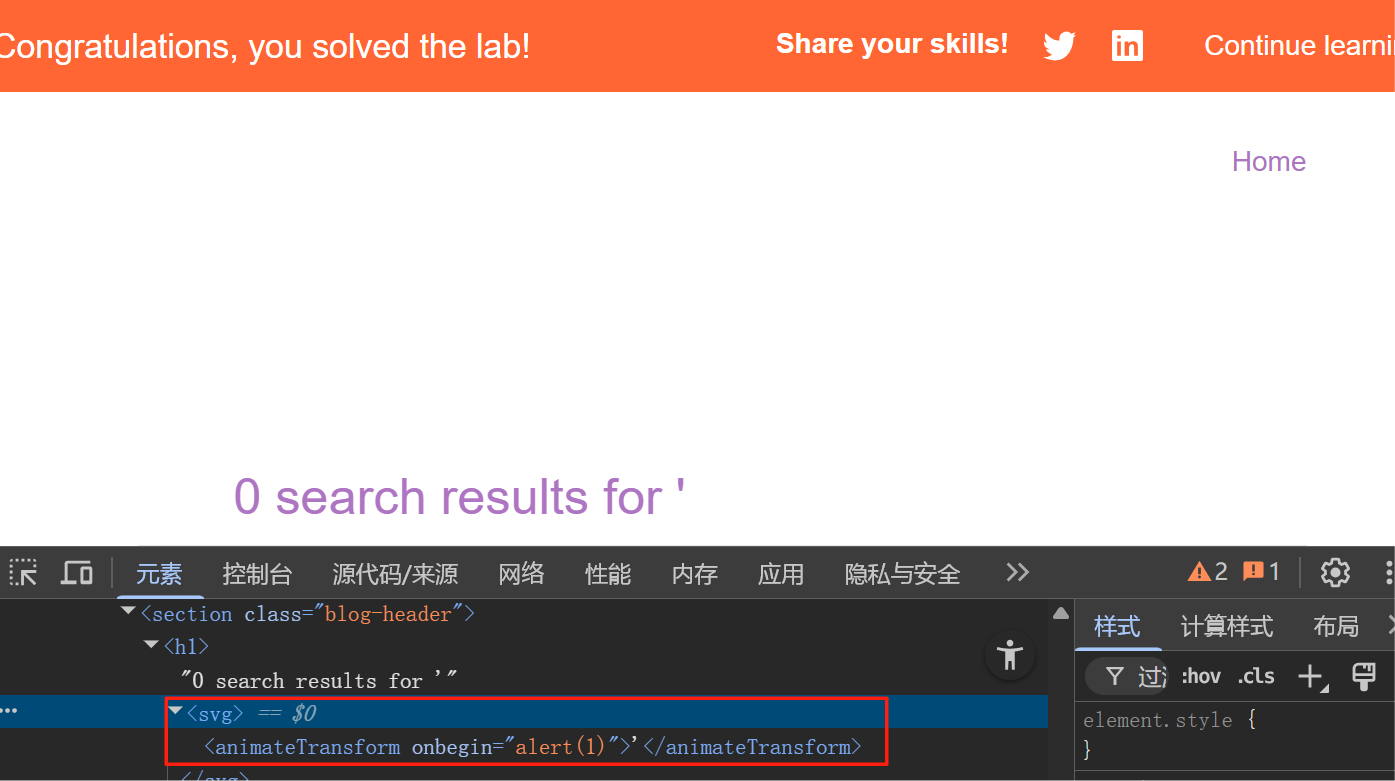
渗透实战PortSwigger Labs指南:自定义标签XSS和SVG XSS利用
阻止除自定义标签之外的所有标签 先输入一些标签测试,说是全部标签都被禁了 除了自定义的 自定义<my-tag onmouseoveralert(xss)> <my-tag idx onfocusalert(document.cookie) tabindex1> onfocus 当元素获得焦点时(如通过点击或键盘导航&…...
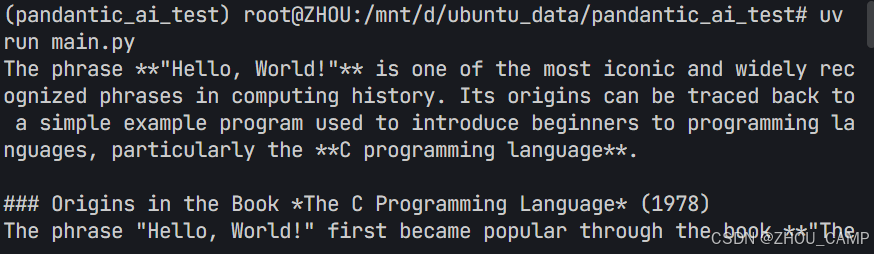
PydanticAI快速入门示例
参考链接:https://ai.pydantic.dev/#why-use-pydanticai 示例代码 from pydantic_ai import Agent from pydantic_ai.models.openai import OpenAIModel from pydantic_ai.providers.openai import OpenAIProvider# 配置使用阿里云通义千问模型 model OpenAIMode…...

GAN模式奔溃的探讨论文综述(一)
简介 简介:今天带来一篇关于GAN的,对于模式奔溃的一个探讨的一个问题,帮助大家更好的解决训练中遇到的一个难题。 论文题目:An in-depth review and analysis of mode collapse in GAN 期刊:Machine Learning 链接:...

数据分析六部曲?
引言 上一章我们说到了数据分析六部曲,何谓六部曲呢? 其实啊,数据分析没那么难,只要掌握了下面这六个步骤,也就是数据分析六部曲,就算你是个啥都不懂的小白,也能慢慢上手做数据分析啦。 第一…...
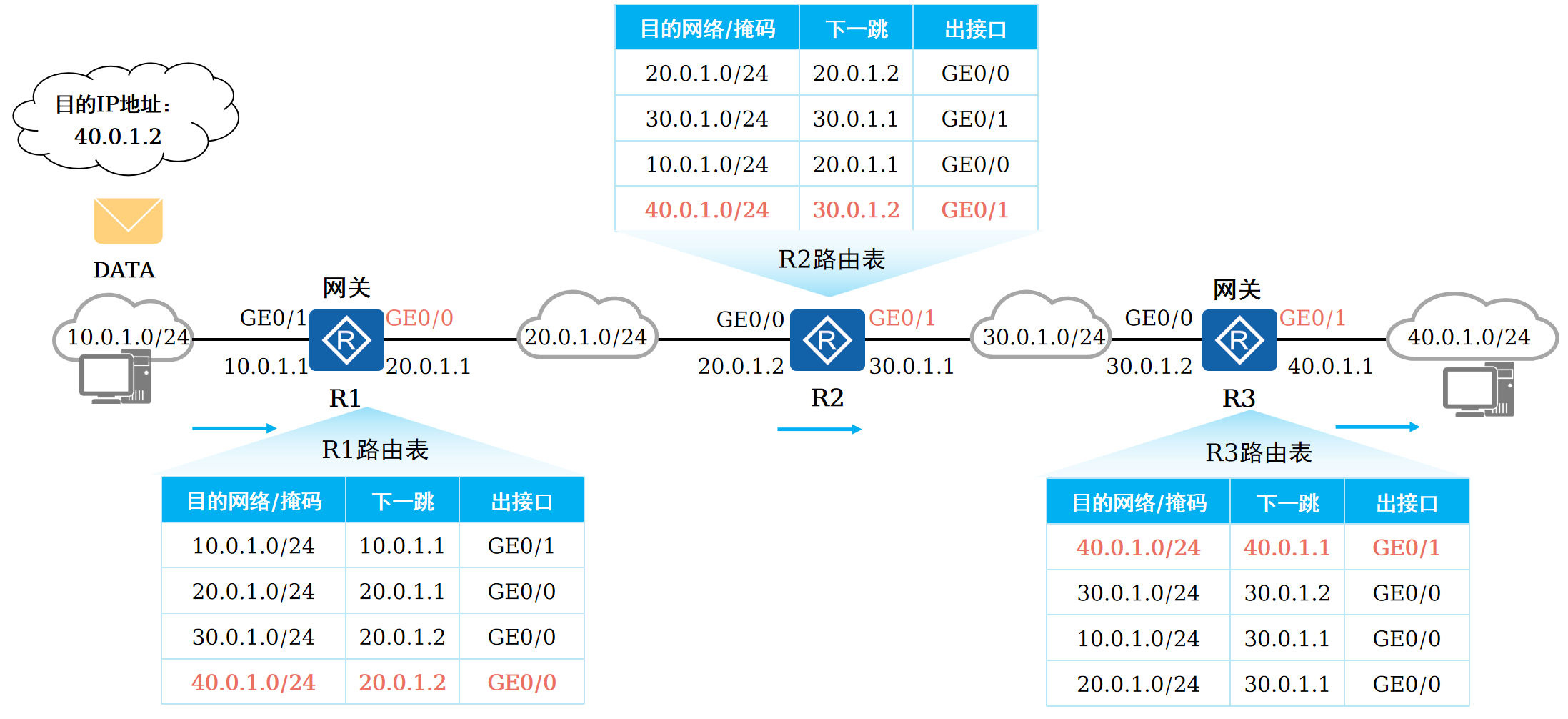
路由基础-路由表
本篇将会向读者介绍路由的基本概念。 前言 在一个典型的数据通信网络中,往往存在多个不同的IP网段,数据在不同的IP网段之间交互是需要借助三层设备的,这些设备具备路由能力,能够实现数据的跨网段转发。 路由是数据通信网络中最基…...

CTF show 数学不及格
拿到题目先查一下壳,看一下信息 发现是一个ELF文件,64位的 用IDA Pro 64 打开这个文件 然后点击F5进行伪代码转换 可以看到有五个if判断,第一个argc ! 5这个判断并没有起太大作用,主要是下面四个if判断 根据题目…...

React父子组件通信:Props怎么用?如何从父组件向子组件传递数据?
系列回顾: 在上一篇《React核心概念:State是什么?》中,我们学习了如何使用useState让一个组件拥有自己的内部数据(State),并通过一个计数器案例,实现了组件的自我更新。这很棒&#…...

【大模型】RankRAG:基于大模型的上下文排序与检索增强生成的统一框架
文章目录 A 论文出处B 背景B.1 背景介绍B.2 问题提出B.3 创新点 C 模型结构C.1 指令微调阶段C.2 排名与生成的总和指令微调阶段C.3 RankRAG推理:检索-重排-生成 D 实验设计E 个人总结 A 论文出处 论文题目:RankRAG:Unifying Context Ranking…...

LangChain【6】之输出解析器:结构化LLM响应的关键工具
文章目录 一 LangChain输出解析器概述1.1 什么是输出解析器?1.2 主要功能与工作原理1.3 常用解析器类型 二 主要输出解析器类型2.1 Pydantic/Json输出解析器2.2 结构化输出解析器2.3 列表解析器2.4 日期解析器2.5 Json输出解析器2.6 xml输出解析器 三 高级使用技巧3…...

【深尚想】TPS54618CQRTERQ1汽车级同步降压转换器电源芯片全面解析
1. 元器件定义与技术特点 TPS54618CQRTERQ1 是德州仪器(TI)推出的一款 汽车级同步降压转换器(DC-DC开关稳压器),属于高性能电源管理芯片。核心特性包括: 输入电压范围:2.95V–6V,输…...
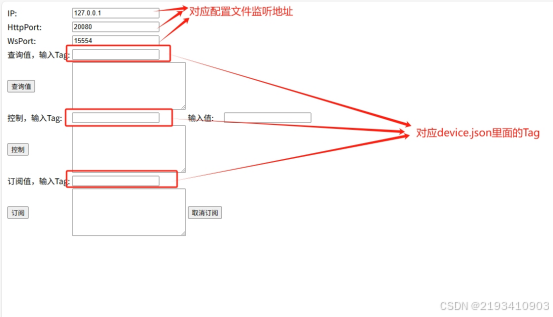
如何把工业通信协议转换成http websocket
1.现状 工业通信协议多数工作在边缘设备上,比如:PLC、IOT盒子等。上层业务系统需要根据不同的工业协议做对应开发,当设备上用的是modbus从站时,采集设备数据需要开发modbus主站;当设备上用的是西门子PN协议时…...

高效的后台管理系统——可进行二次开发
随着互联网技术的迅猛发展,企业的数字化管理变得愈加重要。后台管理系统作为数据存储与业务管理的核心,成为了现代企业不可或缺的一部分。今天我们要介绍的是一款名为 若依后台管理框架 的系统,它不仅支持跨平台应用,还能提供丰富…...
深入解析光敏传感技术:嵌入式仿真平台如何重塑电子工程教学
一、光敏传感技术的物理本质与系统级实现挑战 光敏电阻作为经典的光电传感器件,其工作原理根植于半导体材料的光电导效应。当入射光子能量超过材料带隙宽度时,价带电子受激发跃迁至导带,形成电子-空穴对,导致材料电导率显著提升。…...

拟合问题处理
在机器学习中,核心任务通常围绕模型训练和性能提升展开,但你提到的 “优化训练数据解决过拟合” 和 “提升泛化性能解决欠拟合” 需要结合更准确的概念进行梳理。以下是对机器学习核心任务的系统复习和修正: 一、机器学习的核心任务框架 机…...
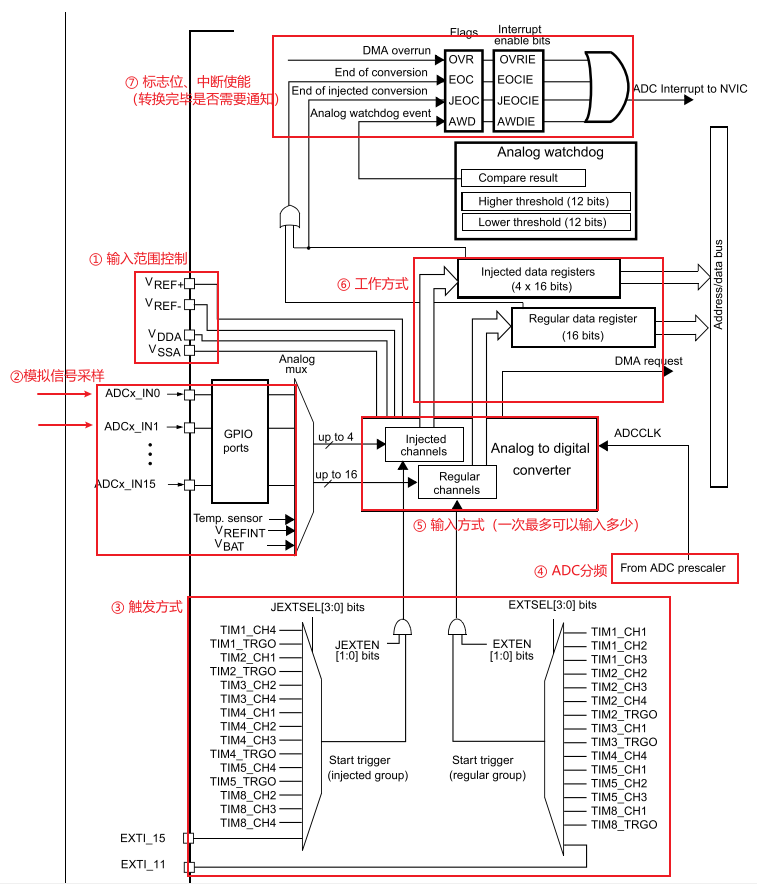
leetcode_69.x的平方根
题目如下 : 看到题 ,我们最原始的想法就是暴力解决: for(long long i 0;i<INT_MAX;i){if(i*ix){return i;}else if((i*i>x)&&((i-1)*(i-1)<x)){return i-1;}}我们直接开始遍历,我们是整数的平方根,所以我们分两…...
大模型——基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程
基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程 下载安装Docker Docker官网:https://www.docker.com/ 自定义Docker安装路径 Docker默认安装在C盘,大小大概2.9G,做这行最忌讳的就是安装软件全装C盘,所以我调整了下安装路径。 新建安装目录:E:\MyS…...

32位寻址与64位寻址
32位寻址与64位寻址 32位寻址是什么? 32位寻址是指计算机的CPU、内存或总线系统使用32位二进制数来标识和访问内存中的存储单元(地址),其核心含义与能力如下: 1. 核心定义 地址位宽:CPU或内存控制器用32位…...

2.2.2 ASPICE的需求分析
ASPICE的需求分析是汽车软件开发过程中至关重要的一环,它涉及到对需求进行详细分析、验证和确认,以确保软件产品能够满足客户和用户的需求。在ASPICE中,需求分析的关键步骤包括: 需求细化:将从需求收集阶段获得的高层需…...

深度解析:etcd 在 Milvus 向量数据库中的关键作用
目录 🚀 深度解析:etcd 在 Milvus 向量数据库中的关键作用 💡 什么是 etcd? 🧠 Milvus 架构简介 📦 etcd 在 Milvus 中的核心作用 🔧 实际工作流程示意 ⚠️ 如果 etcd 出现问题会怎样&am…...
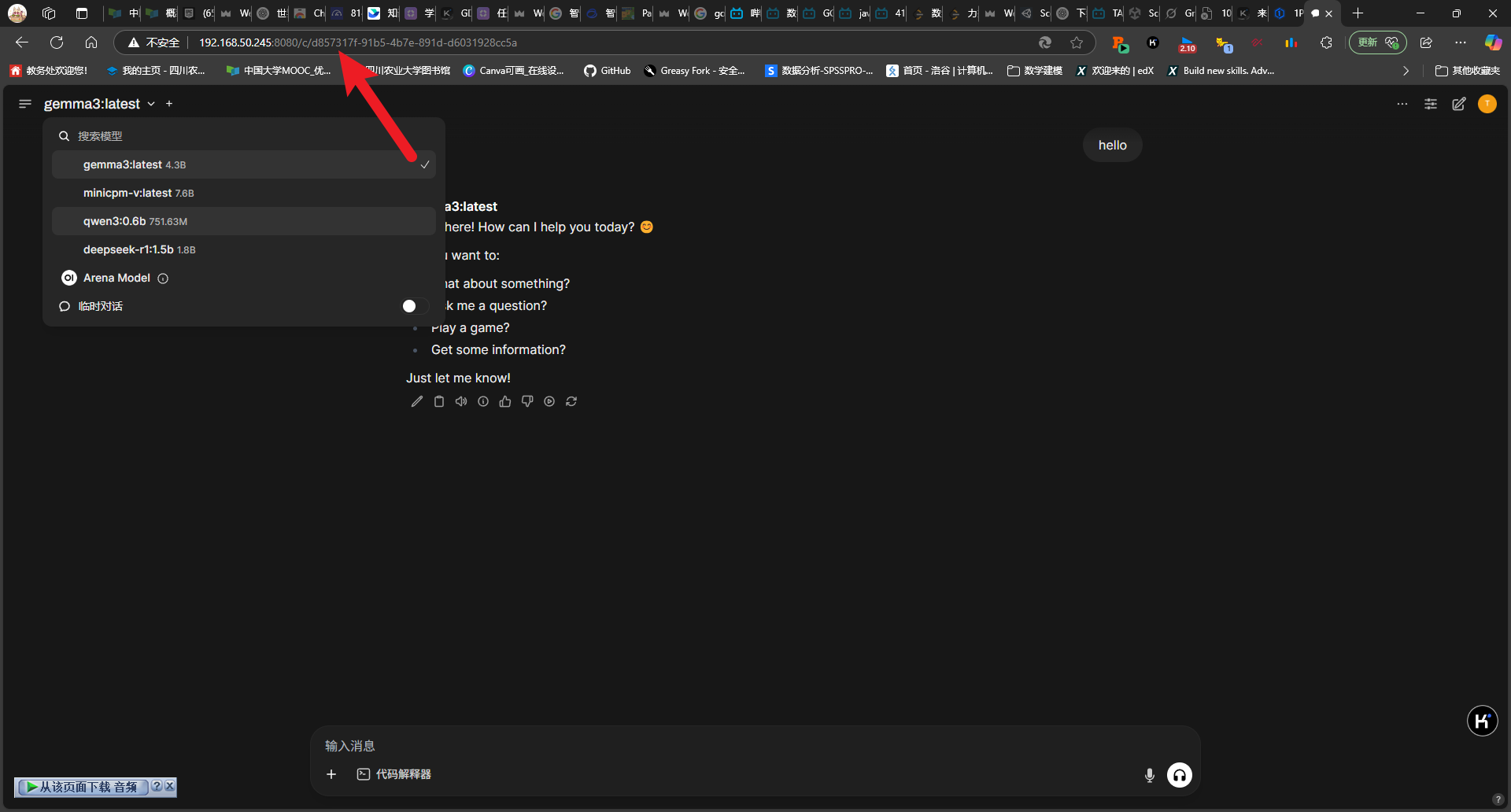
2025-05-08-deepseek本地化部署
title: 2025-05-08-deepseek 本地化部署 tags: 深度学习 程序开发 2025-05-08-deepseek 本地化部署 参考博客 本地部署 DeepSeek:小白也能轻松搞定! 如何给本地部署的 DeepSeek 投喂数据,让他更懂你 [实验目的]:理解系统架构与原…...

js 设置3秒后执行
如何在JavaScript中延迟3秒执行操作 在JavaScript中,要设置一个操作在指定延迟后(例如3秒)执行,可以使用 setTimeout 函数。setTimeout 是JavaScript的核心计时器方法,它接受两个参数: 要执行的函数&…...
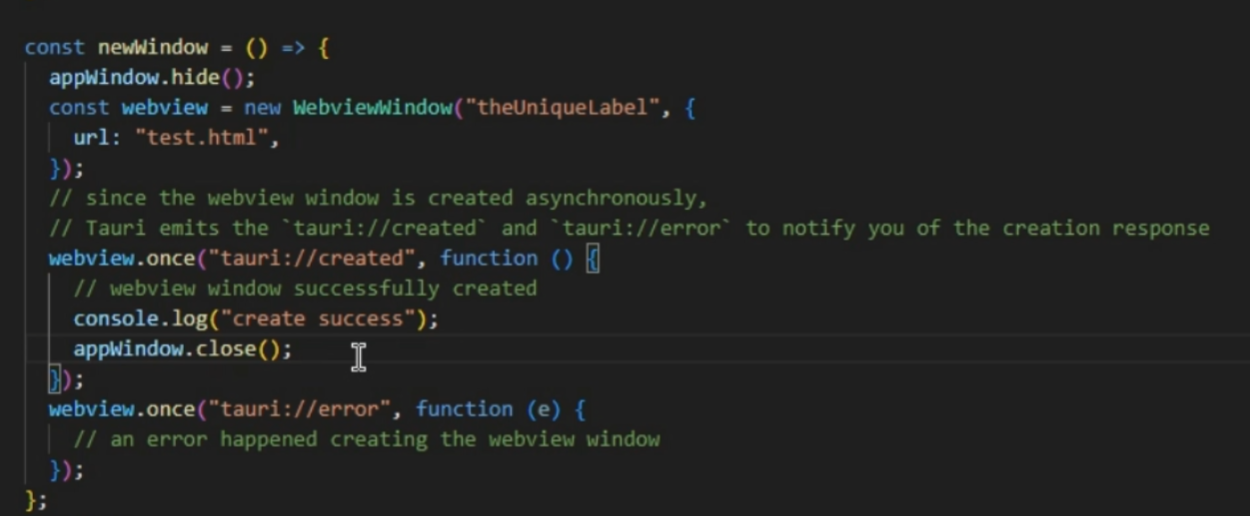
Tauri2学习笔记
教程地址:https://www.bilibili.com/video/BV1Ca411N7mF?spm_id_from333.788.player.switch&vd_source707ec8983cc32e6e065d5496a7f79ee6 官方指引:https://tauri.app/zh-cn/start/ 目前Tauri2的教程视频不多,我按照Tauri1的教程来学习&…...