LangChain 中的文档加载器(Loader)与文本切分器(Splitter)详解《二》
🧠 LangChain 中 TextSplitter 的使用详解:从基础到进阶(附代码)
一、前言
在处理大规模文本数据时,特别是在构建知识库或进行大模型训练与推理时,文本切分(Text Splitting) 是一个非常关键的预处理步骤。LangChain 提供了多种灵活的文本切分器(TextSplitter),可以帮助开发者根据实际需求对文本进行合理划分。
本文将围绕你在实际项目中使用的 TextSplitter 类型展开讲解,并结合具体代码示例,帮助你更好地理解如何选择和配置不同的文本切分策略。
二、什么是 TextSplitter?
TextSplitter 是 LangChain 中用于将长文本分割成小块(chunks)的一个工具类。它的核心作用是:
- 将一段较长的文本按照指定规则切分为多个较小的段落;
- 支持设置每个段落的最大长度(chunk_size);
- 支持相邻段落之间的重叠部分(chunk_overlap),以保留上下文信息;
- 支持基于字符、语言模型 tokenizer 等方式切分。
三、常见的 TextSplitter 类型
LangChain 提供了多种类型的 TextSplitter,每种适用于不同的场景:
| 类名 | 说明 |
|---|---|
RecursiveCharacterTextSplitter | 按照指定字符递归切分,默认按 [“\n\n”, “\n”, " ", “”] 切分 |
SpacyTextSplitter | 基于 SpaCy 的语言模型进行句子级切分 |
MarkdownHeaderTextSplitter | 专门用于 Markdown 格式文档,根据标题层级切分 |
TokenTextSplitter | 基于 Token 数量进行切分,常用于 GPT 系列模型 |
四、实战代码解析
1. 定义 SPLITTER_CLASS_MAP 映射
为了方便切换不同的切分器,我们可以先定义一个映射字典:
SPLITTER_CLASS_MAP = {"RecursiveCharacterTextSplitter": RecursiveCharacterTextSplitter,"SpacyTextSplitter": SpacyTextSplitter,"MarkdownHeaderTextSplitter": MarkdownHeaderTextSplitter,"TokenTextSplitter": TokenTextSplitter,
}
这样可以根据字符串名称动态获取对应的切分器类。
2. 使用 from_tiktoken_encoder 构建切分器
TextSplitter = SPLITTER_CLASS_MAP["RecursiveCharacterTextSplitter"]
text_splitter = TextSplitter.from_tiktoken_encoder(encoding_name=text_splitter_dict["RecursiveCharacterTextSplitter"]["tokenizer_name_or_path"],chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE
)
这段代码使用的是 tiktoken 编码器来计算 token 数量,适用于 GPT-3/4 等 OpenAI 模型。其中:
encoding_name: 指定使用的编码器(如"cl100k_base");chunk_size: 每个 chunk 的最大 token 数;chunk_overlap: 相邻 chunk 的重叠 token 数。
3. 使用默认参数初始化 RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE
)
这是最常用的方式,适用于大多数中文文本的切分任务,不依赖特定的 tokenizer,而是通过字符方式进行切分。
4. 使用 HuggingFace 的 Tokenizer 初始化切分器
from transformers import GPT2TokenizerFast
from langchain.text_splitter import CharacterTextSplittertokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
text_splitter_1 = TextSplitter.from_huggingface_tokenizer(tokenizer=tokenizer,chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE
)
这种方式适用于需要与 HuggingFace 模型配合使用的场景,比如 LLaMA、Bloom 等开源模型。它会根据 tokenizer 来精确控制每个 chunk 的 token 数量。
五、总结与建议
| 切分方式 | 特点 | 推荐场景 |
|---|---|---|
RecursiveCharacterTextSplitter | 快速简单,支持自定义切分符 | 通用文本处理 |
SpacyTextSplitter | 支持多语言语义切分 | 英文为主、语义敏感任务 |
MarkdownHeaderTextSplitter | 按标题层级切分 | 文档类 Markdown 处理 |
TokenTextSplitter | 基于 token 数量切分 | 适配 GPT、LLM 输入限制 |
✅ 建议:如果你在处理中文文本,推荐优先使用
RecursiveCharacterTextSplitter,并搭配合适的 chunk_size(如 512 或 1024)和 overlap(如 64)。
六、区别
你提到的三个 TextSplitter 实例虽然都来自 LangChain 的 RecursiveCharacterTextSplitter 类,但它们使用了不同的初始化方式(构造方法),因此在底层处理文本的方式上也有所不同。下面我将详细分析这三者的区别:
🧩 一、整体结构回顾
你定义了一个映射字典:
SPLITTER_CLASS_MAP = {"RecursiveCharacterTextSplitter": RecursiveCharacterTextSplitter,...
}
然后通过字符串名称获取类并创建实例:
TextSplitter = SPLITTER_CLASS_MAP["RecursiveCharacterTextSplitter"]
text_splitter = TextSplitter.from_tiktoken_encoder(...)
接着又分别使用了三种不同方式创建了三个 splitter 实例:
text_splitter: 使用.from_tiktoken_encoder(...)splitter: 直接使用默认构造函数RecursiveCharacterTextSplitter(...)text_splitter_1: 使用.from_huggingface_tokenizer(...)
这三个 splitter 都是 RecursiveCharacterTextSplitter 的实例,但它们的底层分词逻辑和 chunk 大小控制机制不同。
📌 二、逐个分析三个 splitter 的区别
✅ Splitter 1: text_splitter = TextSplitter.from_tiktoken_encoder(...)
初始化方式:
text_splitter = TextSplitter.from_tiktoken_encoder(encoding_name="cl100k_base",chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE
)
特点:
- 基于 OpenAI 的 tiktoken 编码器;
chunk_size是以 token 数量 为单位;- 更适合用于与 GPT-3/4 等模型配合使用;
- 不依赖具体的语言模型 tokenizer,而是使用 OpenAI 官方编码器;
- 支持中文(取决于使用的 encoding_name);
⚠️ 注意:tiktoken 的 token 划分方式不同于传统的空格或句子划分,它会将中英文混合切分为 subwords 或 bytes。
示例:
"你好 world" -> ["你", "好", "Ġworld"]
✅ Splitter 2: splitter = RecursiveCharacterTextSplitter(...)
初始化方式:
splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE
)
特点:
- 默认使用 字符长度(char length) 来计算 chunk 大小;
- 按照预设的一组字符递归切分(默认顺序是:
\n\n,\n," ",""); - 不依赖任何 tokenizer,只基于字符数量;
- 适用于通用文本处理,尤其适合中文场景;
- 最简单、最直接的切分方式;
示例:
text = "这是一个很长的段落..."
splitter.split_text(text)
# 输出:["这是...", "...下一段"]
✅ Splitter 3: text_splitter_1 = RecursiveCharacterTextSplitter.from_huggingface_tokenizer(...)
初始化方式:
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
text_splitter_1 = RecursiveCharacterTextSplitter.from_huggingface_tokenizer(tokenizer=tokenizer,chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE
)
特点:
- 使用的是 HuggingFace 的 transformers tokenizer(如 GPT2、LLaMA、Bloom 等);
chunk_size也是以 token 数量 为单位;- 更适合与开源 LLM 模型配合使用;
- 支持自定义 tokenizer(如中文 BERT tokenizer);
- 可以精确控制每个 chunk 的 token 数量,避免超出模型输入限制;
⚠️ 注意:这种方式需要安装 transformers 库,并且加载 tokenizer 可能较慢。
🔍 三、三者的核心区别总结
| 属性 | from_tiktoken_encoder(...) | __init__(...) | from_huggingface_tokenizer(...) |
|---|---|---|---|
| 切分依据 | token 数量(tiktoken 编码器) | 字符长度 | token 数量(HuggingFace tokenizer) |
| 是否依赖 tokenizer | 是(tiktoken) | 否 | 是(transformers) |
| chunk_size 单位 | token | char | token |
| 中文支持 | 视 encoding 而定(一般较好) | ✔️ 很好 | 视 tokenizer 而定 |
| 典型用途 | GPT-3/4 类模型适配 | 通用文本处理 | 开源 LLM(如 LLaMA、GPT-Neo)适配 |
| 性能 | 快速 | 极快 | 较慢(需加载 tokenizer) |
🎯 四、如何选择?
| 场景 | 推荐方式 |
|---|---|
| 使用 OpenAI GPT-3/4 API | from_tiktoken_encoder |
| 中文文档处理、快速构建本地知识库 | __init__() |
| 使用开源 LLM(如 LLaMA、Bloom、GPT-Neo) | from_huggingface_tokenizer |
| 需要严格控制 token 数量 | 后两者均可(根据 tokenizer) |
📌 五、补充建议
如果你使用的是中文场景,推荐如下组合:
splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", "。", "!", "?", ",", " ", ""],chunk_size=512,chunk_overlap=64
)
你可以自定义 separators,让它更适合中文语义断句。
相关文章:
与文本切分器(Splitter)详解《二》)
LangChain 中的文档加载器(Loader)与文本切分器(Splitter)详解《二》
🧠 LangChain 中 TextSplitter 的使用详解:从基础到进阶(附代码) 一、前言 在处理大规模文本数据时,特别是在构建知识库或进行大模型训练与推理时,文本切分(Text Splitting) 是一个…...

Monorepo架构: Nx Cloud 扩展能力与缓存加速
借助 Nx Cloud 实现项目协同与加速构建 1 ) 缓存工作原理分析 在了解了本地缓存和远程缓存之后,我们来探究缓存是如何工作的。以计算文件的哈希串为例,若后续运行任务时文件哈希串未变,系统会直接使用对应的输出和制品文件。 2 …...
32单片机——基本定时器
STM32F103有众多的定时器,其中包括2个基本定时器(TIM6和TIM7)、4个通用定时器(TIM2~TIM5)、2个高级控制定时器(TIM1和TIM8),这些定时器彼此完全独立,不共享任何资源 1、定…...
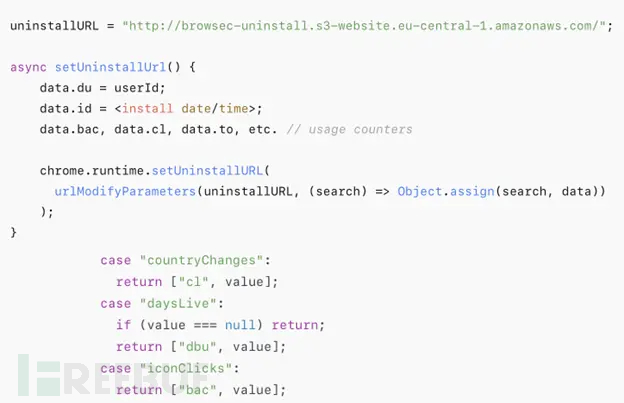
热门Chrome扩展程序存在明文传输风险,用户隐私安全受威胁
赛门铁克威胁猎手团队最新报告披露,数款拥有数百万活跃用户的Chrome扩展程序正在通过未加密的HTTP连接静默泄露用户敏感数据,严重威胁用户隐私安全。 知名扩展程序存在明文传输风险 尽管宣称提供安全浏览、数据分析或便捷界面等功能,但SEMR…...

Matlab实现任意伪彩色图像可视化显示
Matlab实现任意伪彩色图像可视化显示 1、灰度原始图像2、RGB彩色原始图像 在科研研究中,如何展示好看的实验结果图像非常重要!!! 1、灰度原始图像 灰度图像每个像素点只有一个数值,代表该点的亮度(或…...
0609)
书籍“之“字形打印矩阵(8)0609
题目 给定一个矩阵matrix,按照"之"字形的方式打印这个矩阵,例如: 1 2 3 4 5 6 7 8 9 10 11 12 ”之“字形打印的结果为:1,…...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...
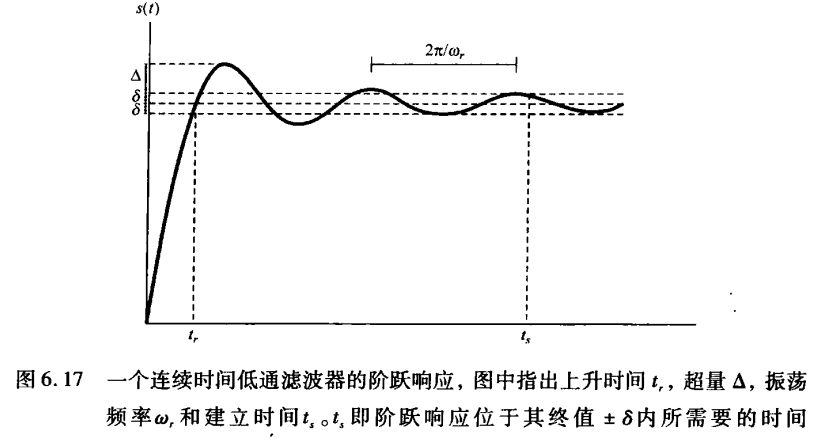
《信号与系统》第 6 章 信号与系统的时域和频域特性
目录 6.0 引言 6.1 傅里叶变换的模和相位表示 6.2 线性时不变系统频率响应的模和相位表示 6.2.1 线性与非线性相位 6.2.2 群时延 6.2.3 对数模和相位图 6.3 理想频率选择性滤波器的时域特性 6.4 非理想滤波器的时域和频域特性讨论 6.5 一阶与二阶连续时间系统 6.5.1 …...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...
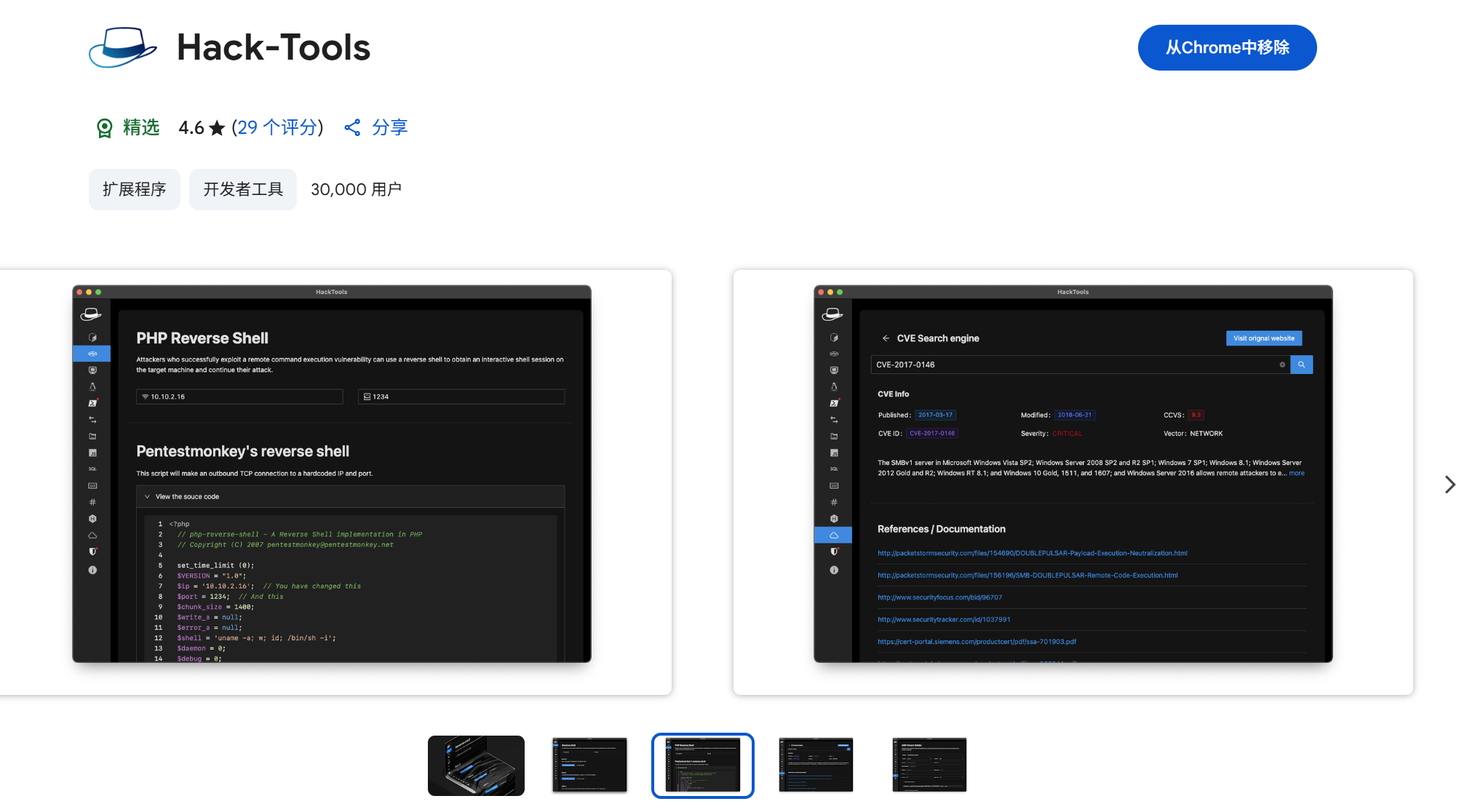
一些实用的chrome扩展0x01
简介 浏览器扩展程序有助于自动化任务、查找隐藏的漏洞、隐藏自身痕迹。以下列出了一些必备扩展程序,无论是测试应用程序、搜寻漏洞还是收集情报,它们都能提升工作流程。 FoxyProxy 代理管理工具,此扩展简化了使用代理(如 Burp…...
AxureRP-Pro-Beta-Setup_114413.exe (6.0.0.2887)
Name:3ddown Serial:FiCGEezgdGoYILo8U/2MFyCWj0jZoJc/sziRRj2/ENvtEq7w1RH97k5MWctqVHA 注册用户名:Axure 序列号:8t3Yk/zu4cX601/seX6wBZgYRVj/lkC2PICCdO4sFKCCLx8mcCnccoylVb40lP...

二维FDTD算法仿真
二维FDTD算法仿真,并带完全匹配层,输入波形为高斯波、平面波 FDTD_二维/FDTD.zip , 6075 FDTD_二维/FDTD_31.m , 1029 FDTD_二维/FDTD_32.m , 2806 FDTD_二维/FDTD_33.m , 3782 FDTD_二维/FDTD_34.m , 4182 FDTD_二维/FDTD_35.m , 4793...
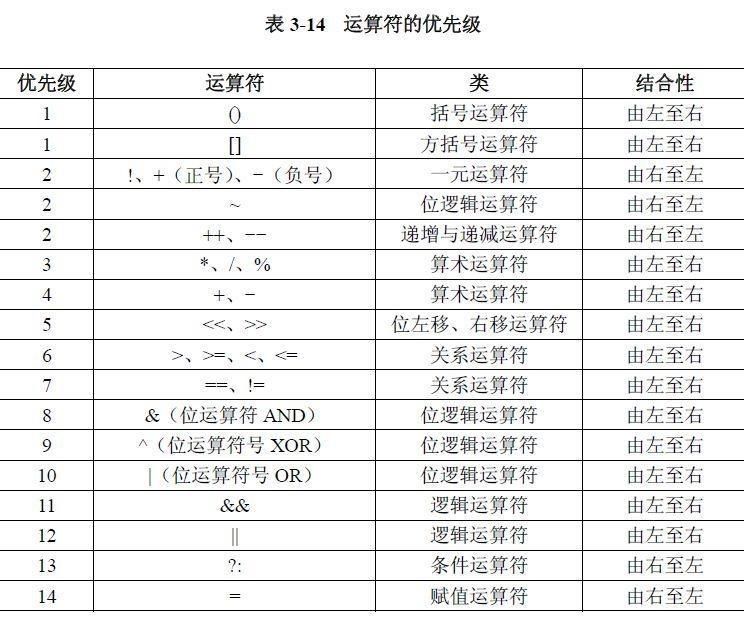
02.运算符
目录 什么是运算符 算术运算符 1.基本四则运算符 2.增量运算符 3.自增/自减运算符 关系运算符 逻辑运算符 &&:逻辑与 ||:逻辑或 !:逻辑非 短路求值 位运算符 按位与&: 按位或 | 按位取反~ …...
:LeetCode 142. 环形链表 II(Linked List Cycle II)详解)
Java详解LeetCode 热题 100(26):LeetCode 142. 环形链表 II(Linked List Cycle II)详解
文章目录 1. 题目描述1.1 链表节点定义 2. 理解题目2.1 问题可视化2.2 核心挑战 3. 解法一:HashSet 标记访问法3.1 算法思路3.2 Java代码实现3.3 详细执行过程演示3.4 执行结果示例3.5 复杂度分析3.6 优缺点分析 4. 解法二:Floyd 快慢指针法(…...

OCR MLLM Evaluation
为什么需要评测体系?——背景与矛盾 能干的事: 看清楚发票、身份证上的字(准确率>90%),速度飞快(眨眼间完成)。干不了的事: 碰到复杂表格(合并单元…...

React从基础入门到高级实战:React 实战项目 - 项目五:微前端与模块化架构
React 实战项目:微前端与模块化架构 欢迎来到 React 开发教程专栏 的第 30 篇!在前 29 篇文章中,我们从 React 的基础概念逐步深入到高级技巧,涵盖了组件设计、状态管理、路由配置、性能优化和企业级应用等核心内容。这一次&…...
uni-app学习笔记三十五--扩展组件的安装和使用
由于内置组件不能满足日常开发需要,uniapp官方也提供了众多的扩展组件供我们使用。由于不是内置组件,需要安装才能使用。 一、安装扩展插件 安装方法: 1.访问uniapp官方文档组件部分:组件使用的入门教程 | uni-app官网 点击左侧…...
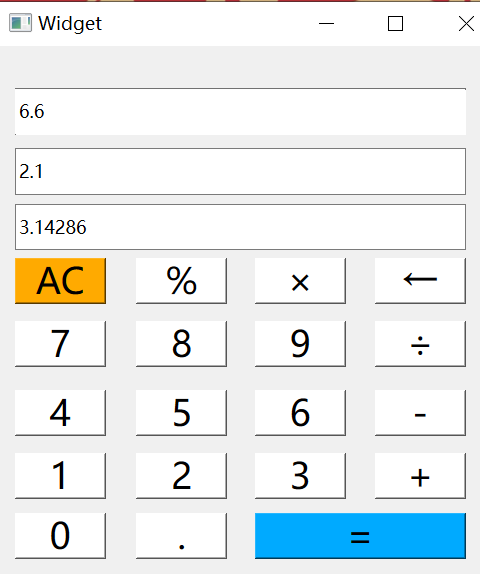
6.9-QT模拟计算器
源码: 头文件: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QMouseEvent>QT_BEGIN_NAMESPACE namespace Ui { class Widget; } QT_END_NAMESPACEclass Widget : public QWidget {Q_OBJECTpublic:Widget(QWidget *parent nullptr);…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...

【HarmonyOS 5】鸿蒙中Stage模型与FA模型详解
一、前言 在HarmonyOS 5的应用开发模型中,featureAbility是旧版FA模型(Feature Ability)的用法,Stage模型已采用全新的应用架构,推荐使用组件化的上下文获取方式,而非依赖featureAbility。 FA大概是API7之…...

土建施工员考试:建筑施工技术重点知识有哪些?
《管理实务》是土建施工员考试中侧重实操应用与管理能力的科目,核心考查施工组织、质量安全、进度成本等现场管理要点。以下是结合考试大纲与高频考点整理的重点内容,附学习方向和应试技巧: 一、施工组织与进度管理 核心目标: 规…...
java高级——高阶函数、如何定义一个函数式接口类似stream流的filter
java高级——高阶函数、stream流 前情提要文章介绍一、函数伊始1.1 合格的函数1.2 有形的函数2. 函数对象2.1 函数对象——行为参数化2.2 函数对象——延迟执行 二、 函数编程语法1. 函数对象表现形式1.1 Lambda表达式1.2 方法引用(Math::max) 2 函数接口…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...

Linux安全加固:从攻防视角构建系统免疫
Linux安全加固:从攻防视角构建系统免疫 构建坚不可摧的数字堡垒 引言:攻防对抗的新纪元 在日益复杂的网络威胁环境中,Linux系统安全已从被动防御转向主动免疫。2023年全球网络安全报告显示,高级持续性威胁(APT)攻击同比增长65%,平均入侵停留时间缩短至48小时。本章将从…...

数据结构第5章:树和二叉树完全指南(自整理详细图文笔记)
名人说:莫道桑榆晚,为霞尚满天。——刘禹锡(刘梦得,诗豪) 原创笔记:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 上一篇:《数据结构第4章 数组和广义表》…...
Windows电脑能装鸿蒙吗_Windows电脑体验鸿蒙电脑操作系统教程
鸿蒙电脑版操作系统来了,很多小伙伴想体验鸿蒙电脑版操作系统,可惜,鸿蒙系统并不支持你正在使用的传统的电脑来安装。不过可以通过可以使用华为官方提供的虚拟机,来体验大家心心念念的鸿蒙系统啦!注意:虚拟…...

CppCon 2015 学习:Time Programming Fundamentals
Civil Time 公历时间 特点: 共 6 个字段: Year(年)Month(月)Day(日)Hour(小时)Minute(分钟)Second(秒) 表示…...

基于江科大stm32屏幕驱动,实现OLED多级菜单(动画效果),结构体链表实现(独创源码)
引言 在嵌入式系统中,用户界面的设计往往直接影响到用户体验。本文将以STM32微控制器和OLED显示屏为例,介绍如何实现一个多级菜单系统。该系统支持用户通过按键导航菜单,执行相应操作,并提供平滑的滚动动画效果。 本文设计了一个…...

yaml读取写入常见错误 (‘cannot represent an object‘, 117)
错误一:yaml.representer.RepresenterError: (‘cannot represent an object’, 117) 出现这个问题一直没找到原因,后面把yaml.safe_dump直接替换成yaml.dump,确实能保存,但出现乱码: 放弃yaml.dump,又切…...