系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程,并实现线性回归与多层感知机模型。
一、Tensor:PyTorch的核心数据结构
1.1 张量创建与基础操作
import torch
# 创建张量
scalar = torch.tensor(3.14) # 标量(0维)
vector = torch.tensor([1, 2, 3]) # 向量(1维)
matrix = torch.tensor([[1, 2], [3, 4]]) # 矩阵(2维)
tensor_3d = torch.randn(2, 3, 4) # 随机3维张量
print(f"标量: {scalar}\n形状: {scalar.shape}")
print(f"3D张量:\n{tensor_3d}\n形状: {tensor_3d.shape}")
# 基础运算
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
print("加法:", a + b) # 逐元素加法
print("乘法:", a * b) # 逐元素乘法
print("点积:", torch.dot(a, b)) # 向量点积
print("矩阵乘法:", matrix @ matrix.T) # 矩阵乘法
# 形状变换
original = torch.arange(12)
reshaped = original.view(3, 4) # 视图(不复制数据)
cloned = original.reshape(3, 4) # 新内存副本
print("原始张量:", original)
print("视图重塑:\n", reshaped)1.2 张量索引与广播
# 索引操作
tensor = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("第一行:", tensor[0]) # [1,2,3]
print("最后一列:", tensor[:, -1]) # [3,6,9]
print("子矩阵:\n", tensor[1:, :2]) # [[4,5],[7,8]]
# 广播机制
A = torch.tensor([[1, 2], [3, 4]])
B = torch.tensor([10, 20])
# B被广播为[[10,20],[10,20]]
print("广播加法:\n", A + B)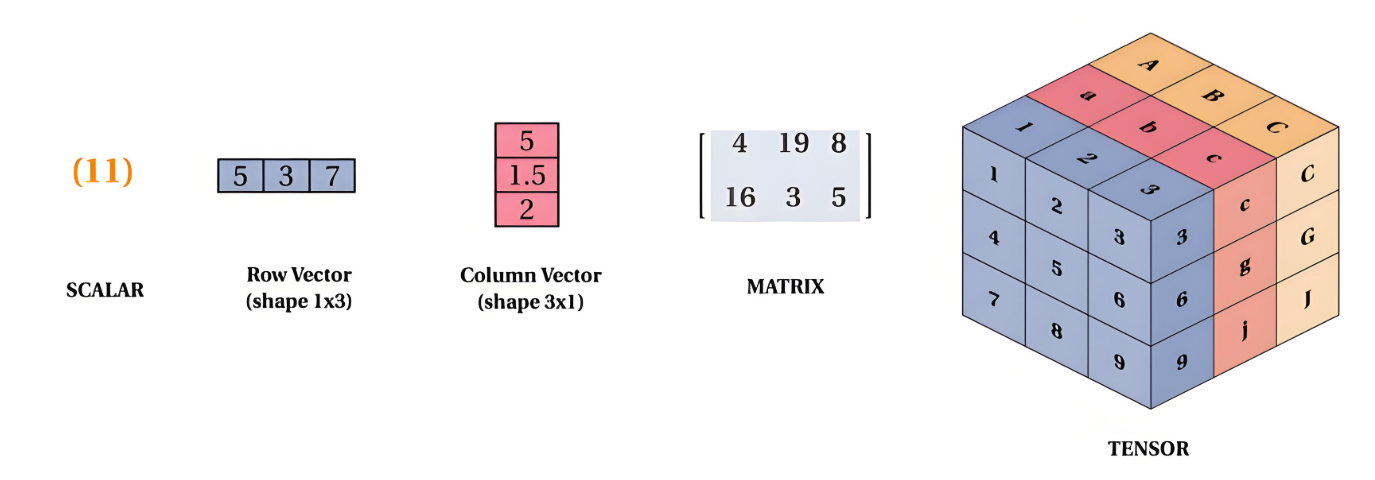
二、自动求导:Autograd引擎原理
2.1 梯度计算基础
# 创建需要梯度的张量
x = torch.tensor(2.0, requires_grad=True)
y = torch.tensor(3.0, requires_grad=True)
# 定义计算图
z = x**2 + y**3 + 10
# 反向传播计算梯度
z.backward()
print(f"dz/dx = {x.grad}") # 2x = 4
print(f"dz/dy = {y.grad}") # 3y² = 272.2 复杂函数梯度
# 多步骤计算
a = torch.tensor([1.0, 2.0], requires_grad=True)
b = torch.tensor([3.0, 4.0], requires_grad=True)
c = a * b # [3, 8]
d = c.sum() * 2 # (3+8)*2=22
d.backward()
print("a的梯度:", a.grad) # [6, 8]
print("b的梯度:", b.grad) # [2, 4]2.3 梯度累积与清零
x = torch.tensor(5.0, requires_grad=True)
# 第一次计算
y1 = x**2
y1.backward()
print("第一次梯度:", x.grad) # 2x=10
# 第二次计算(梯度累积)
y2 = x**3
y2.backward()
print("累积梯度:", x.grad) # 10 + 3x²=10+75=85
# 梯度清零
x.grad.zero_()
y3 = 2*x
y3.backward()
print("清零后梯度:", x.grad) # 2三、数据加载:Dataset与DataLoader
3.1 自定义Dataset
from torch.utils.data import Dataset, DataLoader
import numpy as np
class CustomDataset(Dataset):def __init__(self, data_size=100):self.X = np.random.rand(data_size, 3) # 3个特征self.y = self.X[:,0]*2 + self.X[:,1]*3 - self.X[:,2]*1.5def __len__(self):return len(self.X)def __getitem__(self, idx):features = torch.tensor(self.X[idx], dtype=torch.float32)target = torch.tensor(self.y[idx], dtype=torch.float32)return features, target
# 实例化数据集
dataset = CustomDataset(1000)
# 可视化数据分布
import matplotlib.pyplot as plt
plt.figure(figsize=(12,4))
plt.subplot(131)
plt.scatter(dataset.X[:,0], dataset.y)
plt.title('特征1 vs 目标值')
plt.subplot(132)
plt.scatter(dataset.X[:,1], dataset.y)
plt.title('特征2 vs 目标值')
plt.subplot(133)
plt.scatter(dataset.X[:,2], dataset.y)
plt.title('特征3 vs 目标值')
plt.tight_layout()
plt.show()3.2 DataLoader使用
# 创建数据加载器
dataloader = DataLoader(dataset,batch_size=32,shuffle=True,num_workers=2
)
# 迭代获取批次数据
for batch_idx, (inputs, targets) in enumerate(dataloader):print(f"批次 {batch_idx}:")print(f"输入形状: {inputs.shape}")print(f"目标形状: {targets.shape}")# 仅展示前两个批次if batch_idx == 1:break四、模型构建:nn.Module模块
4.1 线性回归模型
import torch.nn as nn
class LinearRegression(nn.Module):def __init__(self, input_dim):super().__init__()self.linear = nn.Linear(input_dim, 1)def forward(self, x):return self.linear(x)
# 实例化模型
model = LinearRegression(input_dim=3)
print("模型结构:\n", model)
# 查看模型参数
for name, param in model.named_parameters():print(f"{name}: {param.shape}")4.2 多层感知机(MLP)
class MLP(nn.Module):def __init__(self, input_size, hidden_size, output_size):super().__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, output_size)def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.fc2(x)return x
# 创建MLP模型
mlp = MLP(input_size=3, hidden_size=16, output_size=1)
print("MLP结构:\n", mlp)
五、训练流程:完整训练循环
5.1 训练框架代码
# 配置训练参数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LinearRegression(3).to(device)
criterion = nn.MSELoss() # 均方误差损失
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练循环
num_epochs = 100
loss_history = []
for epoch in range(num_epochs):epoch_loss = 0# 批次训练for inputs, targets in dataloader:inputs, targets = inputs.to(device), targets.to(device)# 前向传播outputs = model(inputs)loss = criterion(outputs, targets.unsqueeze(1))# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()epoch_loss += loss.item()# 记录平均损失avg_loss = epoch_loss / len(dataloader)loss_history.append(avg_loss)# 每10轮打印损失if (epoch+1) % 10 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')
# 绘制损失曲线
plt.plot(loss_history)
plt.title('训练损失变化')
plt.xlabel('Epochs')
plt.ylabel('MSE Loss')
plt.grid(True)
plt.show()5.2 模型评估方法
# 切换到评估模式
model.eval()
# 禁用梯度计算
with torch.no_grad():test_inputs = torch.tensor(dataset.X, dtype=torch.float32)predictions = model(test_inputs)actuals = torch.tensor(dataset.y, dtype=torch.float32).unsqueeze(1)# 计算评估指标mse = criterion(predictions, actuals)mae = torch.mean(torch.abs(predictions - actuals))print(f'测试集MSE: {mse.item():.4f}')print(f'测试集MAE: {mae.item():.4f}')# 可视化预测结果plt.scatter(actuals, predictions, alpha=0.6)plt.plot([actuals.min(), actuals.max()], [actuals.min(), actuals.max()], 'r--')plt.title('预测值 vs 真实值')plt.xlabel('真实值')plt.ylabel('预测值')plt.grid(True)plt.show()六、实战项目:线性回归与MLP
6.1 线性回归完整实现
# 生成合成数据
X = torch.linspace(0, 10, 100).reshape(-1, 1)
y = 3 * X + 2 + torch.randn(100, 1) * 2
# 定义模型
class LinearReg(nn.Module):def __init__(self):super().__init__()self.linear = nn.Linear(1, 1)def forward(self, x):return self.linear(x)
# 训练配置
model = LinearReg()
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
criterion = nn.MSELoss()
# 训练循环
for epoch in range(200):# 前向传播preds = model(X)loss = criterion(preds, y)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()# 可视化训练过程if epoch % 50 == 0:plt.scatter(X, y, label='原始数据')plt.plot(X, preds.detach().numpy(), 'r-', lw=3, label='模型预测')plt.title(f'Epoch {epoch}, Loss: {loss.item():.4f}')plt.legend()plt.show()plt.pause(0.1)plt.clf()
# 输出学习到的参数
print("权重:", model.linear.weight.item())
print("偏置:", model.linear.bias.item())6.2 MLP分类实战(MNIST)
from torchvision import datasets, transforms
# 数据预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])
# 加载MNIST数据集
train_data = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_data = datasets.MNIST('./data', train=False, transform=transform)
# 创建数据加载器
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=1000)
# 定义MLP模型
class MLPClassifier(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(28*28, 512)self.fc2 = nn.Linear(512, 256)self.fc3 = nn.Linear(256, 10)self.relu = nn.ReLU()self.dropout = nn.Dropout(0.2)def forward(self, x):x = x.view(-1, 28*28) # 展平x = self.relu(self.fc1(x))x = self.dropout(x)x = self.relu(self.fc2(x))x = self.fc3(x)return x
# 训练函数
def train(model, device, train_loader, optimizer, criterion, epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()if batch_idx % 100 == 0:print(f'Train Epoch: {epoch} [{batch_idx*len(data)}/{len(train_loader.dataset)}'f' ({100.*batch_idx/len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
# 测试函数
def test(model, device, test_loader, criterion):model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)accuracy = 100. * correct / len(test_loader.dataset)print(f'\n测试集: 平均损失: {test_loss:.4f}, 准确率: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')return accuracy
# 主训练循环
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MLPClassifier().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
accuracy_history = []
for epoch in range(1, 11):train(model, device, train_loader, optimizer, criterion, epoch)acc = test(model, device, test_loader, criterion)accuracy_history.append(acc)
# 绘制准确率曲线
plt.plot(accuracy_history)
plt.title('MNIST分类准确率')
plt.xlabel('Epochs')
plt.ylabel('Accuracy (%)')
plt.grid(True)
plt.show()
七、关键要点总结
Tensor核心操作:
graph TD
A[创建张量] --> B[基础运算]
B --> C[形状变换]
C --> D[索引切片]
D --> E[广播机制]自动求导三步骤:
# 1. 设置requires_grad=True
x = torch.tensor(2.0, requires_grad=True)
# 2. 前向计算
y = x**2 + 3*x + 1
# 3. 反向传播
y.backward()
print(x.grad) # 导数: 2x+3 = 7数据加载最佳实践:
-
自定义Dataset类实现
__len__和__getitem__ -
使用DataLoader进行批次加载和混洗
-
多进程加速设置
num_workers>0
模型构建模式:
class CustomModel(nn.Module):def __init__(self):super().__init__()# 定义网络层def forward(self, x):# 定义数据流向return output训练循环模板:
for epoch in range(epochs):for data in dataloader:inputs, labels = data# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()调试技巧:
-
使用
torch.sum()检查张量值 -
print(model)查看网络结构 -
torch.autograd.set_detect_anomaly(True)检测梯度异常
更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。
相关文章:
系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...

go 里面的指针
指针 在 Go 中,指针(pointer)是一个变量的内存地址,就像 C 语言那样: a : 10 p : &a // p 是一个指向 a 的指针 fmt.Println(*p) // 输出 10,通过指针解引用• &a 表示获取变量 a 的地址 p 表示…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...

Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement
Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement 1. LAB环境2. L2公告策略2.1 部署Death Star2.2 访问服务2.3 部署L2公告策略2.4 服务宣告 3. 可视化 ARP 流量3.1 部署新服务3.2 准备可视化3.3 再次请求 4. 自动IPAM4.1 IPAM Pool4.2 …...

数学建模-滑翔伞伞翼面积的设计,运动状态计算和优化 !
我们考虑滑翔伞的伞翼面积设计问题以及运动状态描述。滑翔伞的性能主要取决于伞翼面积、气动特性以及飞行员的重量。我们的目标是建立数学模型来描述滑翔伞的运动状态,并优化伞翼面积的设计。 一、问题分析 滑翔伞在飞行过程中受到重力、升力和阻力的作用。升力和阻力与伞翼面…...
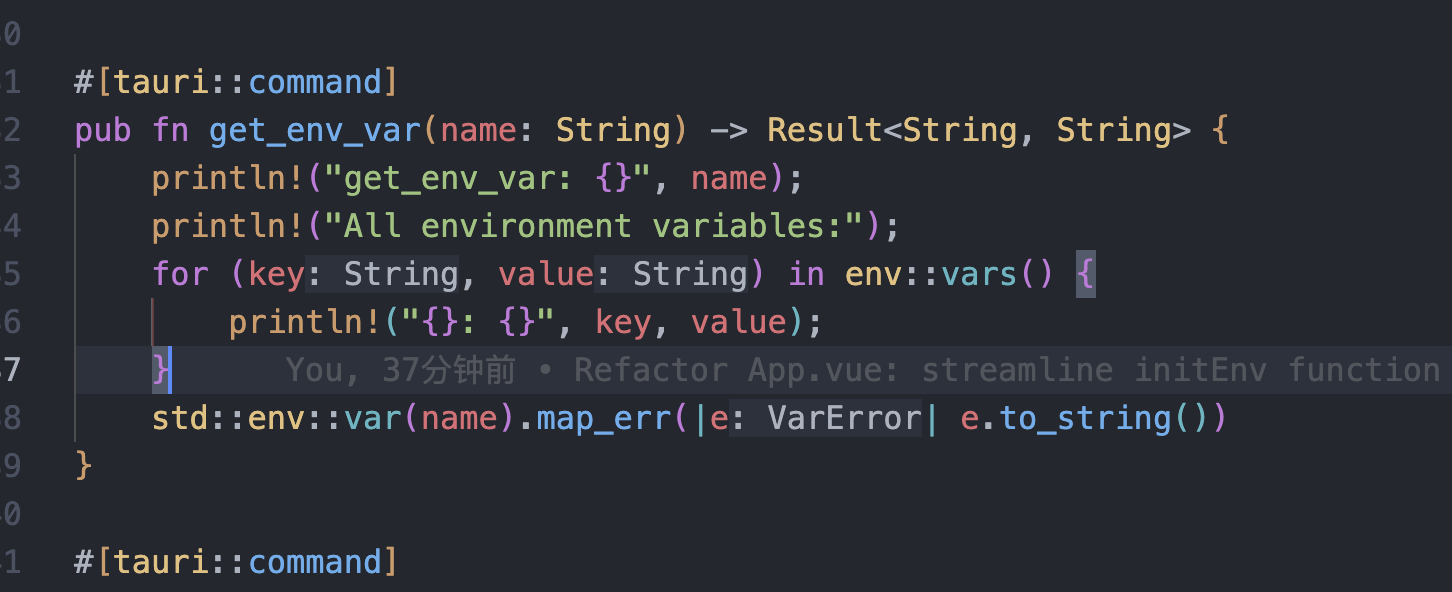
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...
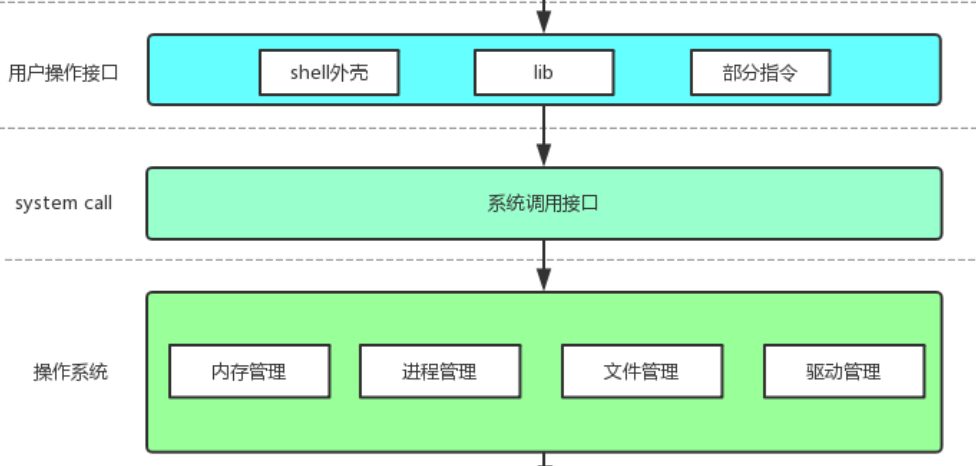
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...
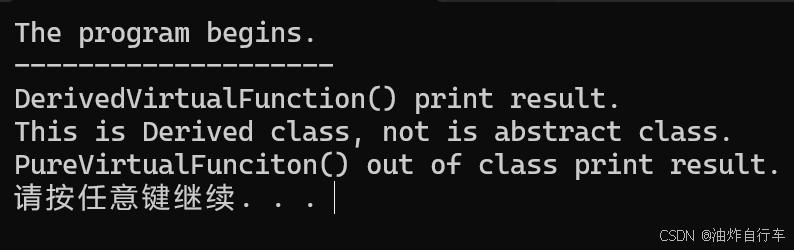
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...

springboot 日志类切面,接口成功记录日志,失败不记录
springboot 日志类切面,接口成功记录日志,失败不记录 自定义一个注解方法 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;/***…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...
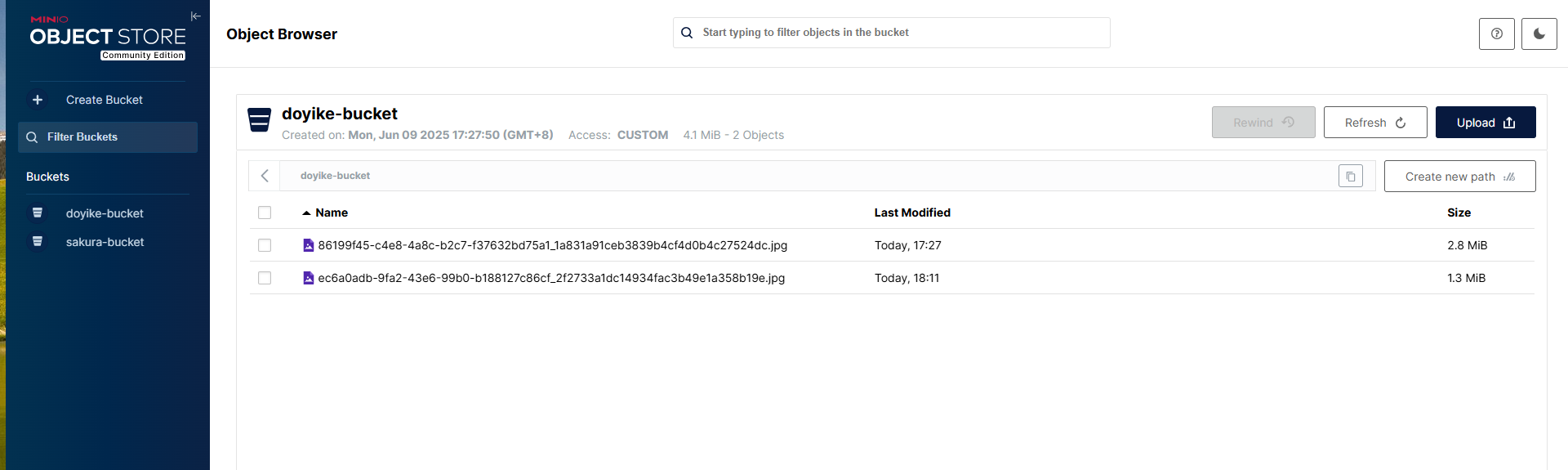
Linux部署私有文件管理系统MinIO
最近需要用到一个文件管理服务,但是又不想花钱,所以就想着自己搭建一个,刚好我们用的一个开源框架已经集成了MinIO,所以就选了这个 我这边对文件服务性能要求不是太高,单机版就可以 安装非常简单,几个命令就…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...

Vue 模板语句的数据来源
🧩 Vue 模板语句的数据来源:全方位解析 Vue 模板(<template> 部分)中的表达式、指令绑定(如 v-bind, v-on)和插值({{ }})都在一个特定的作用域内求值。这个作用域由当前 组件…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...

HTML前端开发:JavaScript 获取元素方法详解
作为前端开发者,高效获取 DOM 元素是必备技能。以下是 JS 中核心的获取元素方法,分为两大系列: 一、getElementBy... 系列 传统方法,直接通过 DOM 接口访问,返回动态集合(元素变化会实时更新)。…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...
)
uniapp 集成腾讯云 IM 富媒体消息(地理位置/文件)
UniApp 集成腾讯云 IM 富媒体消息全攻略(地理位置/文件) 一、功能实现原理 腾讯云 IM 通过 消息扩展机制 支持富媒体类型,核心实现方式: 标准消息类型:直接使用 SDK 内置类型(文件、图片等)自…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...
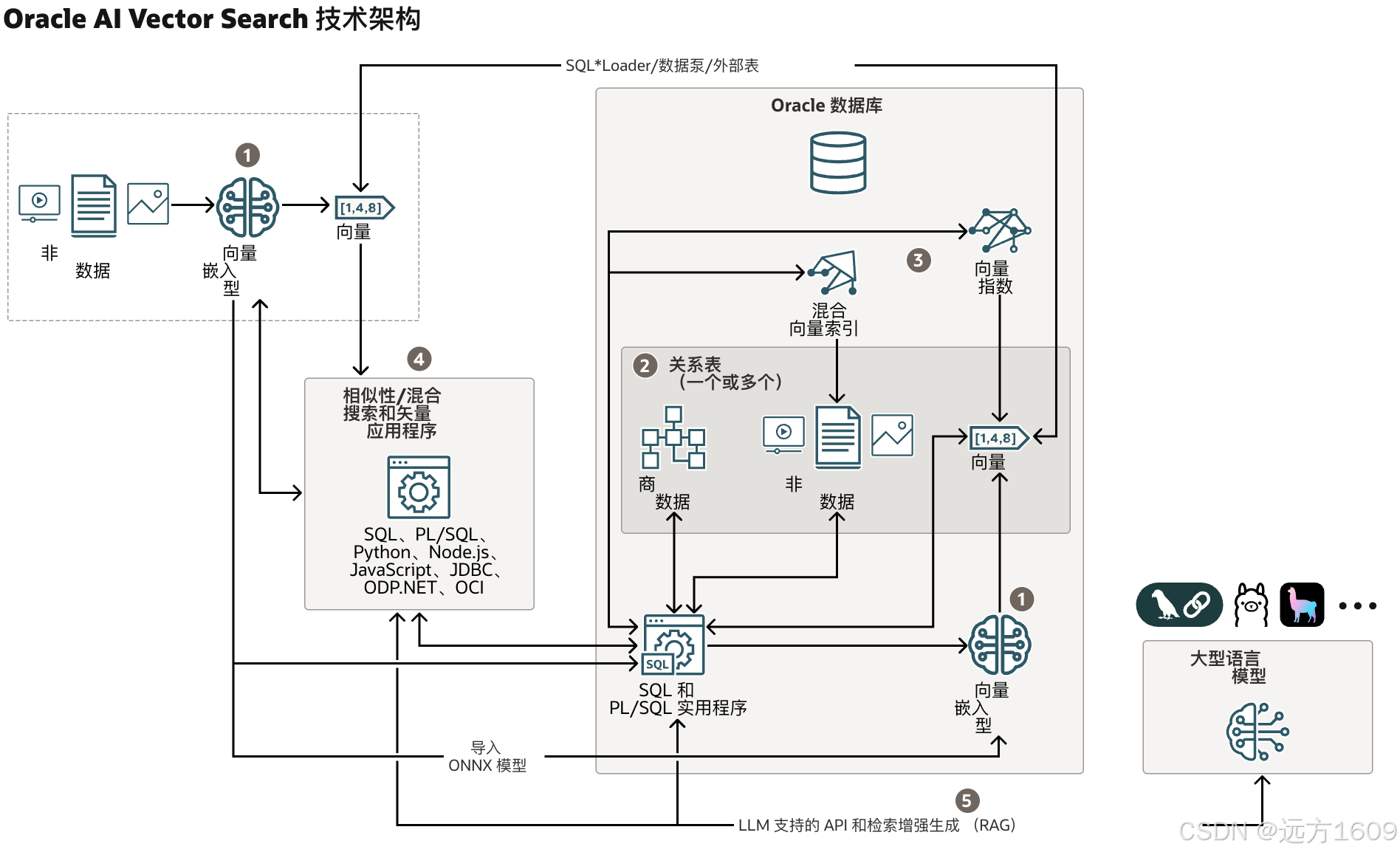
9-Oracle 23 ai Vector Search 特性 知识准备
很多小伙伴是不是参加了 免费认证课程(限时至2025/5/15) Oracle AI Vector Search 1Z0-184-25考试,都顺利拿到certified了没。 各行各业的AI 大模型的到来,传统的数据库中的SQL还能不能打,结构化和非结构的话数据如何和…...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...