Mobile ALOHA全身模仿学习
一、题目
Mobile ALOHA:通过低成本全身远程操作学习双手移动操作
传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性
本论文优点:(1)在ALOHA系统上开发一个移动全身系统,用于模仿需要双手协作和全身控制的移动操作任务。(2)低成本收集数据,每个任务只需演示50次,然后将数据进行克隆,联合训练成功率可以达90%。
论文中可以实现的任务有哪些?
- 炒虾并上菜
- 打开双门壁壁柜放厨具
- 呼叫并进入电梯
- 打开厨房水龙头冲洗平底锅......

二、什么是模仿学习?
可能很多小伙伴都还没接触过模仿学习,下面先介绍一下什么是模仿学习。相信你之前一定听说过强化学习,强化学习是通过智能体与环境交互,以最大化累计奖励作为目标,不断试错并优化策略的学习过程。想要全面系统的了解强化学习强推小白入门资料强化学习入门(不是广,真的写的挺好的)。那么模仿学习则强调通过学习人类专家的示范行为,让智能体模仿专家策略的学习方式(强化学习是让智能体自己交互学习,无专家数据)。
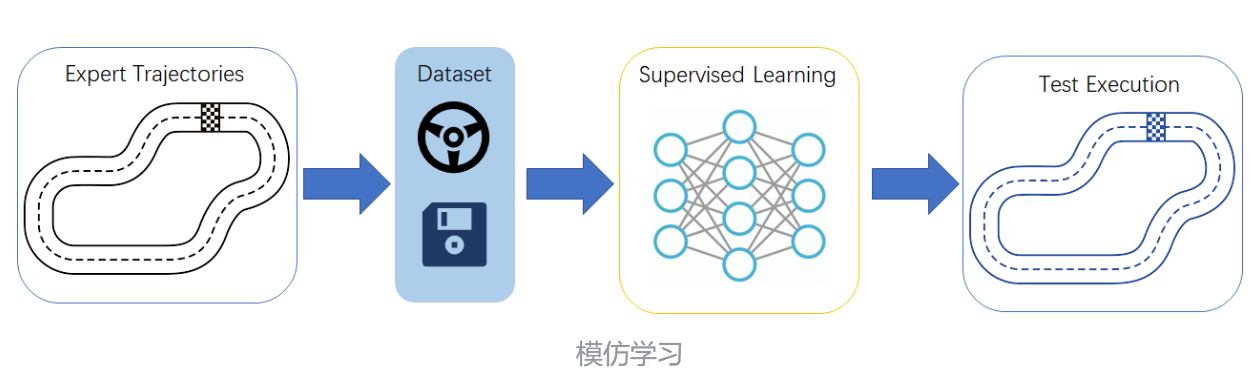
下面简单介绍一下模仿学习,可参考资料几种模仿学习介绍
2.1 行为克隆(Behavior Cloning, BC)
核心思想:直接拟合专家示范的 “状态 - 动作” 映射,将问题转化为监督学习任务。
模型结构:
- 设专家示范数据集为
,其中
为状态,
为专家动作。
- 目标是学习策略
,最小化预测动作与专家动作的分别差异,通常使用交叉熵损失(分类问题)或均方误差(回归问题)
,其中
是损失函数,如分类场景下:
技术细节:专家示范通常是 “最优路径”,而智能体执行时可能进入专家未覆盖的状态(分布偏移),导致性能下降(如自动驾驶中罕见路况)。
解决方法可以采用DAGGER 算法,通过迭代收集智能体在真实环境中的状态,让专家标注对应动作,扩充数据集以覆盖更多状态空间。数学迭代过程如下:
- 初始策略
由BC训练
- 用
与环境进行交互,手机状态集合
- 专家标注动作
,更新数据集
- 用新数据集训练得到
,重复直至收敛
行为克隆要求训练数据和测试数据是独立同分布的,比如训练数据是晴天拍摄的照片,测试数据也是晴天图像,那么就是独立同分布,行为克隆的表现就会良好。但是如果测试数据是雨天图像(分布不同)行为克隆就会失效,因此后面提出逆强化学习。就类似于行为克隆像学生死记硬背答案,但考试题目一变就懵。而用逆模仿学习,像学生理解了出题逻辑(奖励函数),即使遇到新题也能推理。
2.2 逆强化学习(Inverse Reinforcement Learning, IRL)
核心思想:从专家示范的数据中推断潜在的奖励函数,再用强化学习求解最优策略。
模型结构:
- 假设专家策略
是关于奖励函数
的最优策略,即
,其中
为折扣因子。
- IRL的目标是求解
,使得专家轨迹
的期望奖励高于其他轨迹
:
,其中
为KL散度,
为策略
生成轨迹
经典算法:最大熵 IRL(MaxEnt IRL):
- 假设专家行为满足 “最大熵” 原则(即专家在最优轨迹附近有随机性),则奖励函数可表示为:
,其中
为专家动作分布,
为随机策略分布。
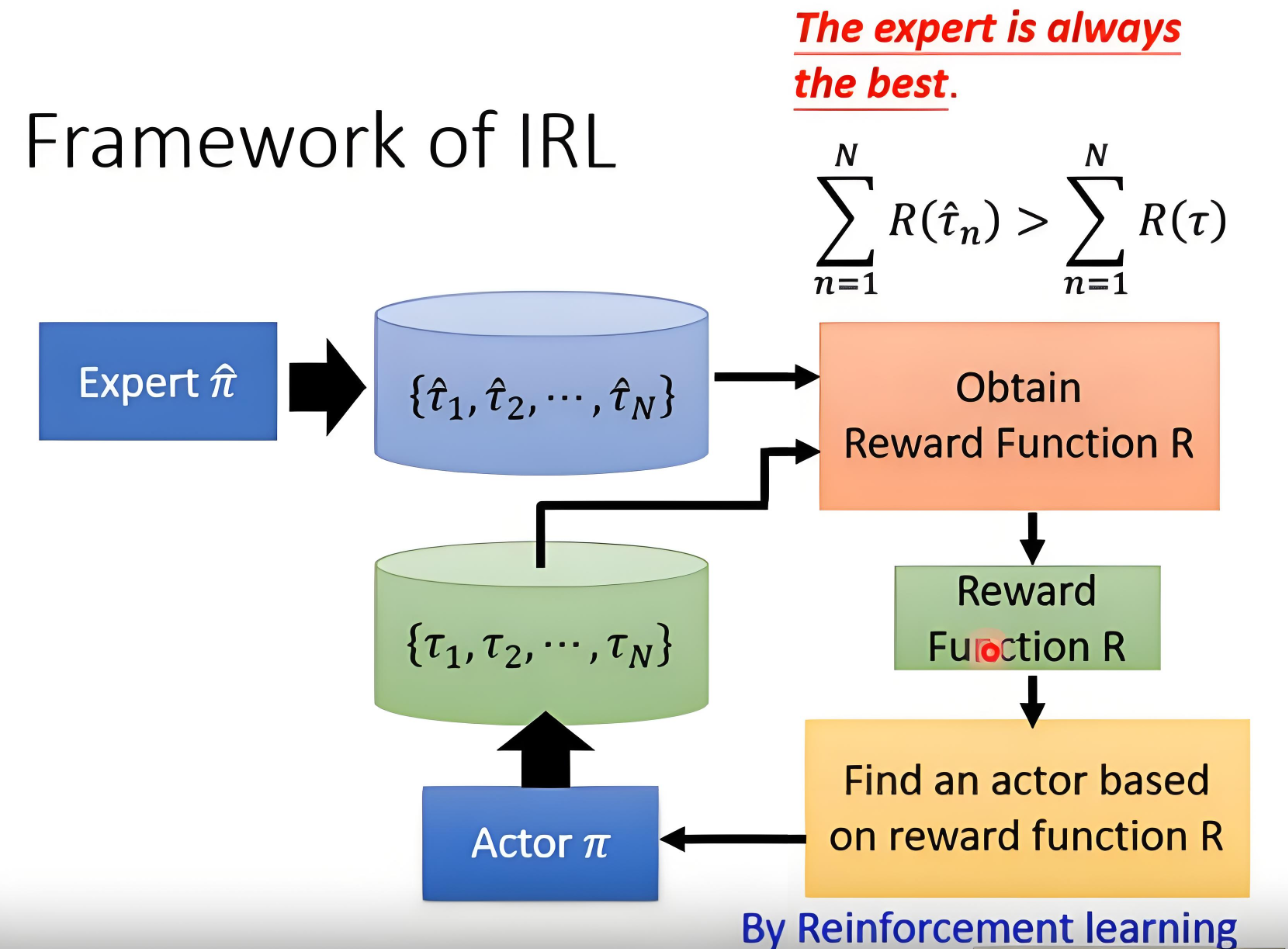
逆强化学习缺点:
(1)需要对奖励函数显式建模,从专家数据中反推奖励函数还是挺困难的。
(2)每一步都可能是迭代过程,如最大熵IRL需要反复运行RL,计算成本极高。
(3)奖励函数不唯一,IRL需要引入强假设(如最大熵)来约束解空间,但仍可能学到不合理的奖励。
(4)若RL部分不稳定(如稀疏奖励问题),最终策略效果差。
因此进一步的提出了对抗强化学习,就不用学习显示的奖励函数了。
2.3 对抗性模仿学习(Adversarial Imitation Learning, AIL)
核心思想:通过生成对抗网络(GAN)区分专家轨迹与智能体轨迹,推动智能体模仿。
模型结构:
(1)初始化
- 专家数据集
(来自专家演示)。
- 策略(生成器):生成轨迹
,通常用神经网络参数化(如PPO、TRPO)。
- 判别器:
,输出一个标量(0~1),表示
来自专家的概率。分类轨迹是来自专家 还是生成器。
(2)对抗训练过程
GAIL 的训练是一个极小化极大(MinMax)博弈:
- 判别器(D)的目标:对专家数据
应接近 1(判为专家数据)。对智能体数据
应接近 0(判为非专家数据)。相当于训练一个二分类器(类似GAN的判别器)。
- 策略(生成器)的目标:让
尽可能接近 1(即让判别器误判智能体的数据为专家数据)。由于
是“对抗奖励”(Adversarial Reward)。
是策略的熵(鼓励探索,防止模式坍塌)。
技术细节:AIL 通过对抗训练隐式学习奖励函数,避免了 IRL 中复杂的奖励函数设计,适用于高维状态空间。
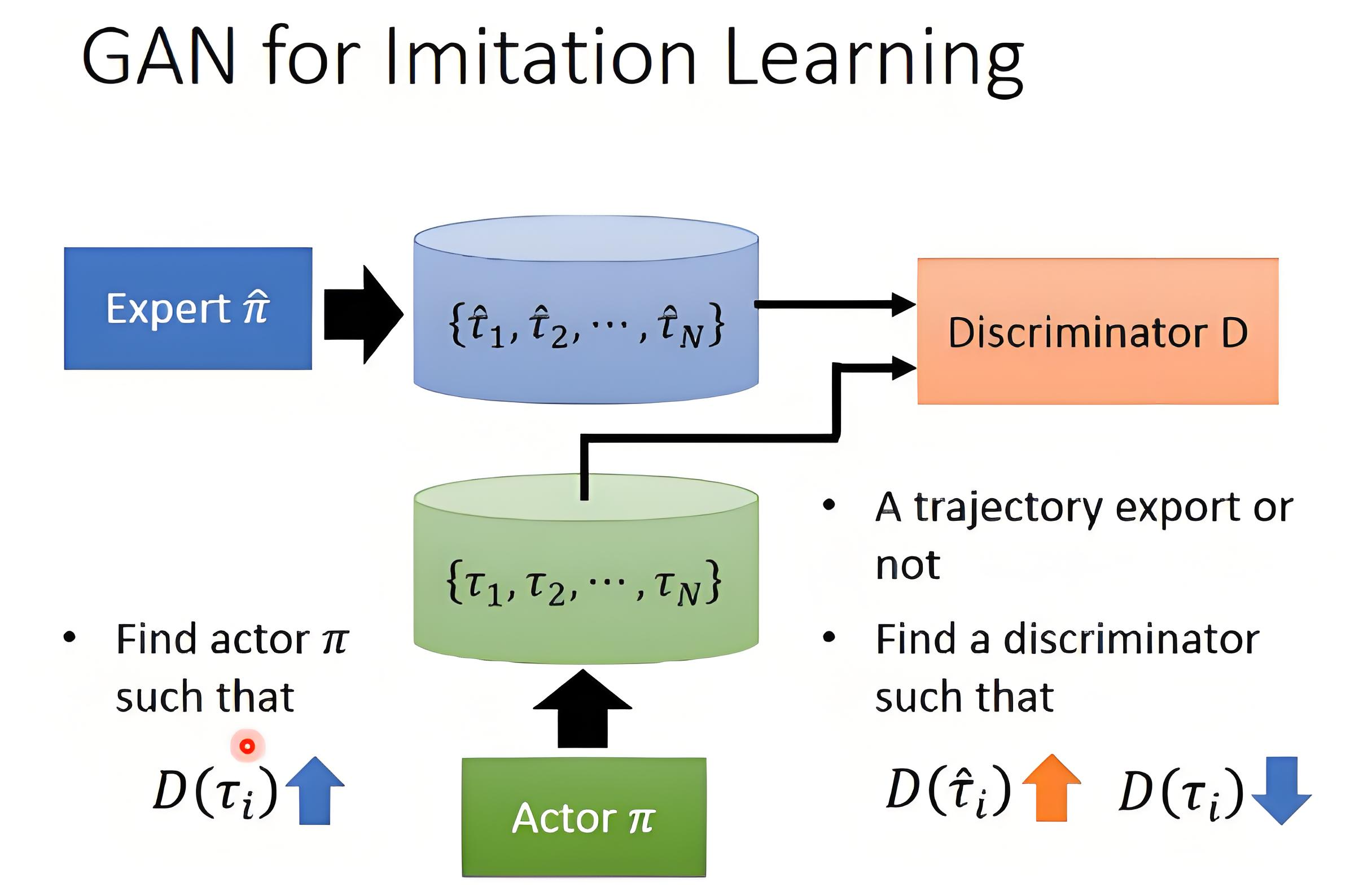
2.4 机械臂抓取任务模仿学习
(1)场景描述:
- 目标:训练机械臂模仿人类示范,完成不同形状物体的抓取(如杯子、积木)。
- 示范数据:人类通过动作捕捉设备记录抓取时的机械臂关节角度、末端执行器位置,以及物体状态(位置、朝向)。
(2)技术实现:行为克隆 + DAGGER
步骤 1:数据收集与预处理
- 专家进行 100 次不同物体的抓取示范,记录状态 s=(物体位置 po,机械臂关节角度 θ,末端执行器位置 pe),动作 a=(关节角度变化 Δθ)。
- 数据预处理:标准化状态空间,将动作离散化为 “抓取”“移动” 等子动作类别。
步骤2:行为克隆训练
- 模型选择:多层感知机(MLP)或卷积神经网络(CNN,若输入包含视觉图像)。
- 损失函数:均方误差(回归任务),优化目标:
- 初始训练结果:在示范过的物体上抓取成功率约 70%,但对新物体或不同摆放角度失败率高(分布偏移问题)。
步骤 3:DAGGER 迭代优化
- 用初始策略
控制机械臂在环境中尝试抓取新物体,收集失败状态(如物体滑动、抓取位置错误)的状态集合
。
- 专家对这些状态标注正确动作
,扩充数据集。
- 重复 5 次迭代后,新物体抓取成功率提升至 90%,原因是数据集覆盖了更多未见过的状态(如物体倾斜、部分遮挡)。
(3)关键技术点
- 状态表示:结合视觉(摄像头图像)和运动学数据(关节角度),使用 CNN+MLP 融合特征。
- 动作空间离散化:将连续动作(如关节角度)转化为离散子任务(如 “移动至物体上方”“闭合夹具”),降低学习难度。
- 安全性设计:机械臂在示教学习时处于低速模式,且有人工监控,避免碰撞风险。
三、Mobile ALOHA总体框架
3.1 难点
现有双手移动操作机器人成本高。先前的机器人学习工作尚未展示出针对复杂任务的高性能双手移动操作。尽管许多最近的工作表明,高度表达性的策略类别,如扩散模型和 Transformer,可以在细粒度、多模态操作任务上表现良好,但在移动操作中是否同样适用在很大程度上尚不明确:随着添加更多的自由度,手臂和底座动作之间的交互可能变得复杂,底座姿势的小偏差可能导致手臂末端执行器姿势的大漂移。
3.2 创新点
(1)硬件方面:
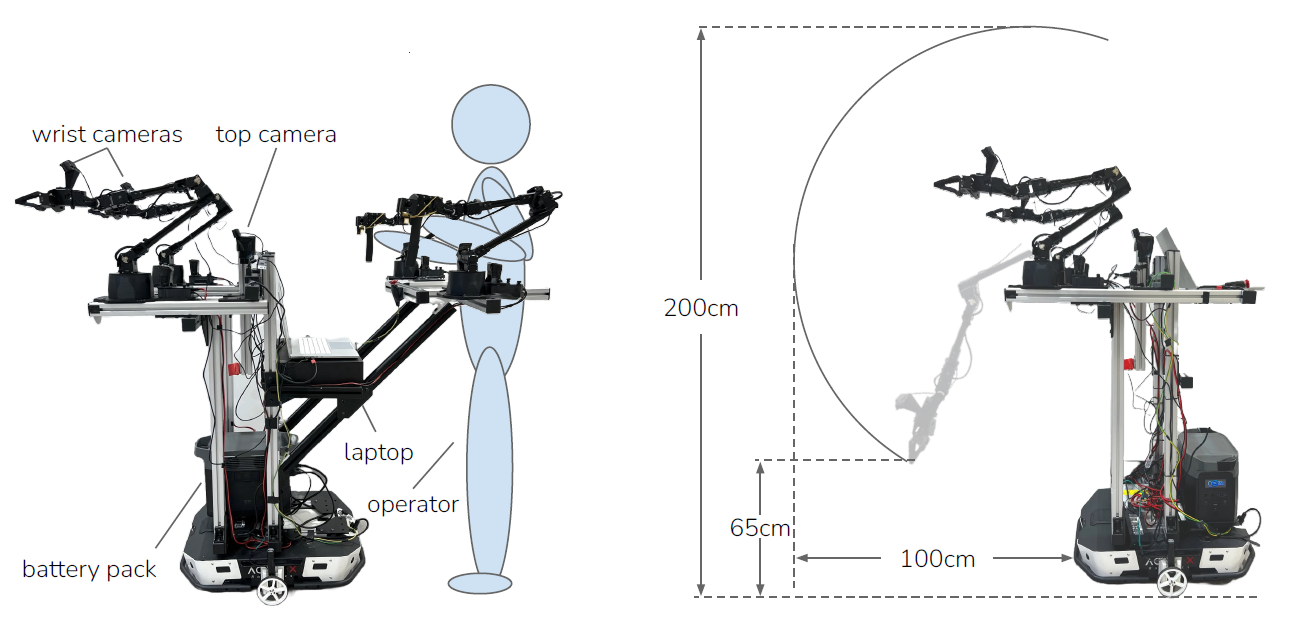
将原来的ALOHA——低成本且灵巧的双手操作装置,扩展到Mobile ALOHA——有移动的低成本的全身远程操作系统。具体是怎么实现移动的呢?就是将人的腰部固定在移动机器人上,类似于推婴儿车的形式用腰部控制移动的方向,然后双手操作的就是原始的ALOHA装置。具体示意图如下
(2)算法方面:
将 ALOHA 的 14 个自由度关节位置(为什么是14个自由度?因为双臂模拟真实的人类手臂,一个手臂对应7个自由度)与移动底座的线速度和角速度连接起来,形成一个 16 维的动作向量。为什么直接粗暴的就把维度拼接起来?因为可以直接借助之前原始的ALOHA(14维)的深度模仿学习算法。
由于没有现成的双手移动操作的数据集。利用静态双手数据集的数据,这些数据更容易收集且更丰富,尤其是通过RT-X版本获得的ALOHA数据集,它包含 825 个情节,任务与 Mobile ALOHA 任务不重叠,并且双臂的安装位置不同。这里还有一个全球最大开源机器人数据集:Open X-Embodiment,关于他的详细介绍可以参考资料深度剖析全球最大开源机器人数据集:Open X-Embodiment全球最大开源机器人数据集:Open X-Embodiment![]() https://zhuanlan.zhihu.com/p/1903549634137290696ALOHA静态双手数据集
https://zhuanlan.zhihu.com/p/1903549634137290696ALOHA静态双手数据集![]() https://arxiv.org/abs/2310.08864该论文第一个发现与静态操作数据集联合训练可以提高移动操作策略的性能和数据效率的。
https://arxiv.org/abs/2310.08864该论文第一个发现与静态操作数据集联合训练可以提高移动操作策略的性能和数据效率的。
3.3 核心算法
静态 ALOHA 数据集总共有 825 个演示,用于包括 Ziploc 密封、拿起叉子、糖果包装、撕纸巾、打开带盖的塑料分装杯、玩乒乓球、胶带分配、使用咖啡机、铅笔移交、固定魔术贴电缆、插入电池和递螺丝刀等任务。请注意,静态 ALOHA 数据都是在黑色桌面上收集的,双臂固定为面对面。这种设置与 Mobile ALOHA 不同,Mobile ALOHA 的背景随着移动底座而变化,并且双臂平行放置朝前。我们在联合训练中没有对静态 ALOHA 数据的 RGB 观察或双手动作使用任何特殊的数据处理技术。
将聚合的静态 ALOHA 数据表示为,任务 m 的 Mobile ALOHA 数据集表示为
。双手动作被表示为目标关节位置
,其中包括两个连续的 gripper 动作,底座动作被表示为目标底座线速度和角速度
。任务 m 的移动操作策略
的训练目标为:
其中是由两个手腕摄像头 RGB 观察、安装在双臂之间的一个第一人称顶部摄像头 RGB 观察,以及手臂的关节位置组成的观察,L 是模仿损失函数。我们从静态 ALOHA 数据
和 Mobile ALOHA 数据
中以相等的概率采样。我们将批量大小设置为 16。由于静态 ALOHA 数据点没有移动底座动作,我们对动作标签进行零填充,使来自两个数据集的动作具有相同的维度。我们还忽略静态 ALOHA 数据中的前摄像头,以便两个数据集都有 3 个摄像头。我们仅基于 Mobile ALOHA 数据集
的统计数据对每个动作进行归一化。在我们的实验中,我们将这种联合训练方法与多种基础模仿学习方法相结合,包括 ACT 、Diffusion Policy 和 VINN 。
作为初步,我们将要检验的所有方法都采用 “动作分块”,即策略预测未来动作序列,而不是在每个时间步预测一个动作。这已经是 ACT 和 Diffusion Policy 方法的一部分,并且对于 VINN 来说很容易添加。我们发现动作分块对于操作至关重要,它提高了生成轨迹的连贯性,并减少了每步策略推理的延迟。动作分块还为 Mobile ALOHA 提供了独特的优势:更灵活地处理硬件不同部分的延迟。我们观察到我们的移动底座的目标速度和实际速度之间存在延迟,而位置控制的手臂的延迟要小得多。为了考虑移动底座的 d 步延迟,我们的机器人执行长度为 k 的动作块的前k−d个手臂动作和后k−d个底座动作
我们从 ACT [104] 开始,这是与 ALOHA 一起推出的方法,并在有和没有联合训练的情况下对所有 7 个任务进行训练。然后,我们在现实世界中评估每个策略,按照描述的机器人和物体配置进行随机化。为了计算子任务的成功率,我们将成功次数除以尝试次数。例如,在 “举起杯子并擦拭” 子任务的情况下,尝试次数等于前一个子任务 “抓住毛巾” 的成功次数,因为机器人可能在任何子任务中失败并停止。这也意味着最终成功率等于所有子任务成功率的乘积。
【参考论文】
Fu, Zipeng, Tony Z. Zhao, and Chelsea Finn. "Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation." arxiv preprint arxiv:2401.02117 (2024).
相关文章:
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...