从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C++学习的STL哈希容器自主实现部分的学习分享
希望也能为你带来些帮助~
那咱们废话不多说,直接开始吧!
一、源码结构分析
1. SGISTL30实现剖析
// hash_set核心结构
template <class Value, class HashFcn, ...>
class hash_set {typedef hashtable<Value, Value, HashFcn, identity<Value>> ht;ht rep; // 复用哈希表
};// hash_map核心结构
template <class Key, class T, ...>
class hash_map {typedef hashtable<pair<const Key, T>, Key, ...> ht;
};不难看出无论是unordered_map还是unordered_set,内部的底层结构都是哈希表,基于这种事实我们可以用一句话来阐述这两个容器:
unordered_map和unordered_set是基于哈希表实现的、分别用于存储键值对和唯一键的、提供平均O(1)时间复杂度的快速查找、插入和删除操作但不保证元素的顺序性的无序关联容器。
2. HashTable关键设计
2.1 桶结构:vector<node*> buckets
核心作用
哈希表的底层存储是一个动态数组(vector),每个数组元素(称为“桶”)指向一个链表头节点(开链法解决冲突)。
-
数组下标:通过哈希函数将键(Key)映射到具体桶位置(
hash(key) % buckets.size())。 -
链表节点:同一桶内的元素以链表形式链接,解决哈希冲突(不同键映射到同一桶)。
vector<Node*> buckets; // 如buckets[3]指向链表:NodeA -> NodeB -> nullptr2.2 节点结构 _hashtable_node{ next; }
- 链表节点设计:每个节点需存储数据和指向下一节点的指针:
template<class T>
struct HashNode
{T _data;HashNode* _next;HashNode(const T& data):_data(data), _next(nullptr){}
};-
开链法(Separate Chaining):冲突时,新节点直接链接到桶对应的链表头部(头插法,O(1)时间)。
2.3 模板参数
在cplusplus上面两个容器的模板参数包含这几个:
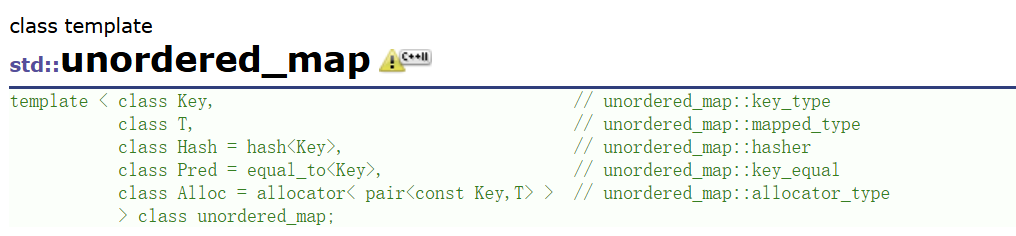
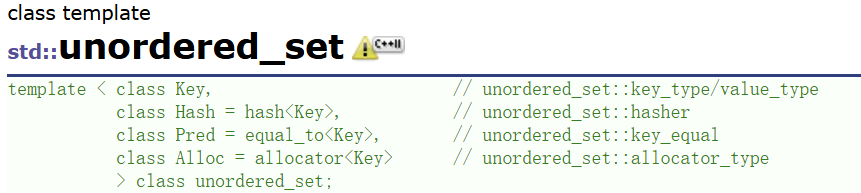
| 模板参数 | 作用 | 示例(unordered_map场景) |
|---|---|---|
Key | 键的类型,用于哈希计算和比较 | int、std::string |
T | 实际存储的数据类型(对unordered_set是Key,对unordered_map是pair) | pair<const int, string> |
Hash(KeyOfT) | 从Value中提取Key的仿函数(解决数据泛化问题) | 从pair<const int, string>提取int |
Pred | 判断两个Key是否相等的仿函数(默认std::equal_to) | 自定义字符串比较(如忽略大小写) |
Alloc | 内存分配器类型,用于管理pair<const Key, T>的内存分配(默认std::allocator) | 自定义内存池分配器 |
为什么需要 Hash?
-
统一接口:哈希表本身不知道
Value是Key(set)还是pair<Key, T>(map),需通过仿函数提取键。
// unordered_set的Hash(直接返回Key)
struct SetKeyOfT {const K& operator()(const K& key) { return key; }
};// unordered_map的Hash(返回pair.first)
struct MapKeyOfT {const K& operator()(const pair<K, V>& kv) { return kv.first; }
};为什么需要Pred?
-
自定义比较规则:默认使用
operator==,但某些场景需特殊处理(如字符串比较时忽略大小写)。 -
struct CaseInsensitiveEqual {bool operator()(const string& a, const string& b) const {return tolower(a[0]) == tolower(b[0]); // 仅比较首字母(示例)} };
2.4 工作流程示例(插入操作)
-
提取Key:通过
ExtractKey从Value中获取Key(如从pair<int,string>提取int)。 -
计算桶位置:对
Key调用哈希函数,取模得到桶下标。 -
处理冲突:遍历桶对应的链表,用
EqualKey比较是否已存在相同Key。 -
插入节点:若不存在,将新节点插入链表头部。
2.5 设计优势
-
泛化性:一套哈希表实现通过模板参数同时支持
unordered_map和unordered_set。 -
灵活性:允许用户自定义哈希函数(
Hash)和键比较规则(EqualKey)。 -
高效性:开链法在负载因子合理时(如0.7~1.0)保证O(1)操作。
二、模拟实现核心架构
1. 容器-哈希表关系图

不难看出,两种容器的底层是哈希表,且哈希表的底层是哈希桶以及迭代器,
同时哈希桶的底层又是节点HashNode,
因此在我们完整实现出unordered_map以及unordered_set之前,先将这两个基本元素完成就显得至关重要了
2. 关键仿函数设计:
2.1 统一键值提取接口
-
SetKeyOfT:
K -> K -
MapKeyOfT:
pair<K,V> -> K -
//unordered_map struct MapKeyOfT {const K& operator()(const pair<K, V>& kv){return kv.first;} };//unordered_set struct SetKeyOfT {const K& operator()(const K& key){return key;} };
2.2 哈希函数仿函数
作用:将键(Key)映射为一个size_t类型的哈希值- (同时考虑到在unordered_map中有很多将string类型作为key的情况,我们可以为string类型做一个特化处理专门用来应对这种情况)
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//特化
template<>
struct HashFunc<string>
{size_t operator()(const string& st){size_t hashi = 0;for (auto e : st){hashi += e;}return hashi;}
};三、哈希表详细实现
1. 基础结构
template<class T>
struct HashNode
{T _data;HashNode* _next; //开链法解决冲突HashNode(const T& data):_data(data), _next(nullptr){}
};template<class K, class T, class KeyOfT, class Hash >
class HashTable
{
private:vector<Node*> _tables; //桶数组size_t _n = 0; //插入元素计数
};2. 迭代器系统实现
2.1 迭代器设计难点
-
跨桶遍历(核心:
operator++实现) -
结构设计:
(当前节点指针, 哈希表指针)
2.2 关键代码
//迭代器
template<class K, class T, class Ref,class Ptr,class KeyOfT, class Hash >
struct HTIterator
{typedef HashNode<T> Node;typedef HashTable<K, T, KeyOfT, Hash> HT;typedef HTIterator<K, T, Ref, Ptr,KeyOfT, Hash> Self;//成员Node* _node;const HT* _ht;HTIterator(Node* node, const HT* ht):_node(node), _ht(ht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}Self& operator++(){if (_node->_next){_node = _node->_next;}else{KeyOfT kot;Hash hs;//算出目前在哪个桶里面size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();++hashi;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi]){_node = _ht->_tables[hashi];break;}else{++hashi;}}if (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;}bool operator!=(const Self& s) const{return _node != s._node;}bool operator==(const Self& s) const{return _node == s._node;}};2.3 容器迭代器封装
//unordered_map
typedef typename Hash_Bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::Iterator iterator;
typedef typename Hash_Bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::ConstIterator const_iterator;//unordered_set
typedef typename Hash_Bucket::HashTable<K, const K, SetKeyOfT, Hash>::Iterator iterator;
typedef typename Hash_Bucket::HashTable<K, const K, SetKeyOfT, Hash>::ConstIterator const_iterator;3. 哈希表核心操作实现
-
Insert():负载因子控制+扩容策略(素数表扩容)
pair<Iterator, bool> Insert(const T& data)
{Hash hs;KeyOfT kot;//若找得到,则已经插入过了,返回false//否则继续插入Iterator it = Find(data);if(it!=End())return {it,false};if (_n == _tables.size()){vector<Node*> newTables(__stl_next_prime(0), nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = hs(kot(cur->_data)) % newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}size_t hashi = hs(kot(data)) % _tables.size();Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return { {newnode,this},true };
}-
Find():哈希定位+链表遍历
Iterator Find(const T& data)
{Hash hs;KeyOfT kot;size_t hashi = hs(kot(data)) % _tables.size();Node* cur = _tables[hashi];while (cur){if (hs(kot(cur->_data)) == hs(kot(data))){return Iterator(cur,nullptr);}cur = cur->_next;}return End();
}-
Erase():链表节点删除
Iterator Erase(Iterator& it)
{if (it == End()){return End();}Hash hs;KeyOfT kot;Node* to_delete = it->_node;Node* prev = nullptr;size_t hashi = hs(kot(it->_data)) % _tables.size();Node* cur = _tables[hashi];//已经定位到目标哈希桶,找目标节点while (cur != to_delete && cur != nullptr){prev = cur;cur = cur->_next;}//通常情况下不会发生if (cur == nullptr){return End();}//删头节点if (prev == nullptr){_tables[hashi] = cur->_next;}//正常情况else{prev->_next = cur->_next;}//保存下一个迭代器Node* next_node = cur->_next;Iterator next_it({ next_node,this });delete cur;--_n;if (next_node != nullptr){return next_it;}else{++hashi;while (hashi < _tables.size() && _tables[hashi] != nullptr){++hashi;}if (hashi < _tables.size()){return Iterator({ _tables[hashi],this });}else{return End();}}
}4. 素数扩容机制
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291
};//取素数的函数
inline unsigned long __stl_next_prime(unsigned long n)
{const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;
}四、容器接口封装
1. unordered_set实现
template<class K,class Hash = Hash_Bucket::HashFunc<K>>
class unordered_set
{struct SetKeyOfT{const K& operator()(const K& key){return key;}};
public://typedef typename Hash_Bucket::HashTable<K, const K, SetKeyOfT, Hash>::Iterator iterator;//typedef typename Hash_Bucket::HashTable<K, const K, SetKeyOfT, Hash>::ConstIterator const_iterator;//另一种用法,和上面的意思是一样的,但using有更多的一些用途using iterator = typename Hash_Bucket::HashTable<K, const K, SetKeyOfT, Hash>::Iterator;using const_iterator = typename Hash_Bucket::HashTable<K, const K, SetKeyOfT, Hash>::ConstIterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin() const{return _ht.Begin();}const_iterator end() const{return _ht.End();}pair<iterator,bool> insert(const K& key){return _ht.Insert(key);}size_t count(const K& key){return _ht.Count(key);}size_t size(){return _ht.Size();}bool empty(){return _ht.Empty();}bool erase(const K& key){return _ht.Erase(key);}iterator erase(const iterator& it){return _ht.Erase(it);}size_t bucket_count(){return _ht.Bucket_Count();}size_t bucket_size(size_t i){return _ht.Bucket_Size(i);}private:Hash_Bucket::HashTable<K, const K,SetKeyOfT, Hash> _ht;
};2. unordered_map实现
template<class K, class V, class Hash = Hash_Bucket::HashFunc<K>>
class unordered_map
{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename Hash_Bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::Iterator iterator;typedef typename Hash_Bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::ConstIterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}pair<iterator,bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}V& operator[](const K& key){//没有的话就创建,有的话就传迭代求所在位置pair<iterator, bool> ret = insert({ key,V() });return ret.first->second; }iterator find(const K& key){return _ht.Find(key);}const_iterator find(const K& key)const{return _ht.Find(key);}const V& operator[](const K& key) const{const_iterator it = _ht.Find({key,V()});if (it == _ht.End()){throw out_of_range("The key is out of range");}return it->second;}size_t count(const K& key){return _ht.Count({key,V()});}size_t size(){return _ht.Size();}bool empty(){return _ht.Empty();}bool erase(const K& key){return _ht.Erase(key);}iterator erase(iterator& it){return _ht.Erase(it);}size_t bucket_size(size_t i){return _ht.Bucket_Size(i);}size_t bucket_count(){return _ht.Bucket_Count();}private:Hash_Bucket::HashTable<K, pair<const K,V>,MapKeyOfT, Hash> _ht;
};其中,operator[ ]为此容器的特殊支持
四、关键问题解决方案
1. 类型封装问题
通过KeyOfT仿函数屏蔽K/pair差异
2. 迭代器失效问题
扩容时整体迁移(不保留原指针,在Erase()函数中尤为体现)
3. 哈希函数特化
满足字符串的哈希实现
五、总结
1. 设计亮点
-
单一哈希表支撑双容器
-
仿函数解决数据提取泛化
2. 性能分析
-
O(1)平均复杂度 vs 最差O(n)
3. 扩展方向
-
多线程安全支持
-
更优哈希冲突策略
附录
完整代码文件结构:
-
HashTable.h(哈希表/迭代器) -
MyUnorderedSet.h -
MyUnorderedMap.h
完整代码:
HashTable.h
#pragma once
#include<iostream>
#include<vector>
using namespace std;namespace Hash_Bucket
{static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};//取素数的函数inline unsigned long __stl_next_prime(unsigned long n){const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;}template<class T>struct HashNode{T _data;HashNode* _next;HashNode(const T& data):_data(data), _next(nullptr){}};template<class K>struct HashFunc{size_t operator()(const K& key){return (size_t)key;}};//特化template<>struct HashFunc<string>{size_t operator()(const string& st){size_t hashi = 0;for (auto e : st){hashi += e;}return hashi;}};//前置声明template<class K, class T, class Ref, class Ptr,class KeyOfT, class Hash >struct HTIterator;template<class K, class T, class KeyOfT, class Hash >class HashTable{//友元template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>friend struct HTIterator;typedef HashNode<T> Node;public:typedef HTIterator<K, T, T& , T*, KeyOfT, Hash> Iterator;typedef HTIterator<K, T, const T&, const T*, KeyOfT, Hash> ConstIterator;Iterator Begin(){for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return Iterator({_tables[i],this});}}return End();}Iterator End(){return Iterator({ nullptr,this });}//这里后面蓝色的const是修饰在_tables上的,但是这里的const _table传回给HashTable类的构造函数的时候,参数HT _ht会出现权限放大的问题//因此我们就在HashTable的第二个成员也就是HT _ht的类型前加上了个const,这样就避免了权限放大的问题ConstIterator Begin() const{for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return ConstIterator({ _tables[i],this });}}return End();}ConstIterator End() const{return ConstIterator({ nullptr,this });}HashTable(size_t size = __stl_next_prime(0)):_tables(size, nullptr){}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Empty(){if (Size() == 0){return true;}return false;}size_t Size(){return _n;}pair<Iterator, bool> Insert(const T& data){Hash hs;KeyOfT kot;//若找得到,则已经插入过了,返回false//否则继续插入Iterator it = Find(data);if(it!=End())return {it,false};if (_n == _tables.size()){vector<Node*> newTables(__stl_next_prime(0), nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = hs(kot(cur->_data)) % newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}size_t hashi = hs(kot(data)) % _tables.size();Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return { {newnode,this},true };}Iterator Find(const T& data){Hash hs;KeyOfT kot;size_t hashi = hs(kot(data)) % _tables.size();Node* cur = _tables[hashi];while (cur){if (hs(kot(cur->_data)) == hs(kot(data))){return Iterator(cur,nullptr);}cur = cur->_next;}return End();}ConstIterator Find(const T& data)const{Hash hs;KeyOfT kot;size_t hashi = hs(kot(data)) % _tables.size();Node* cur = _tables[hashi];while (cur){if (hs(kot(cur->_data)) == hs(kot(data))){return ConstIterator(cur, nullptr);}cur = cur->_next;}return End();}size_t Count(const T& data){Hash hs;KeyOfT kot;size_t hashi = hs(kot(data)) % _tables.size();Node* cur = _tables[hashi];while (cur){if (hs(kot(cur->_data)) == hs(kot(data))){return 1;}cur = cur->_next;}return 0;}bool Erase(const K& key) {Hash hs;KeyOfT kot;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur) {if (kot(cur->_data) == key) { // 仅比较键if (prev == nullptr) {_tables[hashi] = cur->_next;}else {prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}Iterator Erase(Iterator& it){if (it == End()){return End();}Hash hs;KeyOfT kot;Node* to_delete = it->_node;Node* prev = nullptr;size_t hashi = hs(kot(it->_data)) % _tables.size();Node* cur = _tables[hashi];//已经定位到目标哈希桶,找目标节点while (cur != to_delete && cur != nullptr){prev = cur;cur = cur->_next;}//通常情况下不会发生if (cur == nullptr){return End();}//删头节点if (prev == nullptr){_tables[hashi] = cur->_next;}//正常情况else{prev->_next = cur->_next;}//保存下一个迭代器Node* next_node = cur->_next;Iterator next_it({ next_node,this });delete cur;--_n;if (next_node != nullptr){return next_it;}else{++hashi;while (hashi < _tables.size() && _tables[hashi] != nullptr){++hashi;}if (hashi < _tables.size()){return Iterator({ _tables[hashi],this });}else{return End();}}}size_t Bucket_Count(){return _tables.size();}size_t Bucket_Size(size_t i){if (_tables[i] == nullptr){return 0;}else{Node* cur = _tables[i];size_t count = 0;while (cur){++count;cur = cur->_next;}return count;}}private:vector<Node*> _tables;size_t _n = 0;};///迭代器template<class K, class T, class Ref,class Ptr,class KeyOfT, class Hash >struct HTIterator{typedef HashNode<T> Node;typedef HashTable<K, T, KeyOfT, Hash> HT;typedef HTIterator<K, T, Ref, Ptr,KeyOfT, Hash> Self;//成员Node* _node;const HT* _ht;HTIterator(Node* node, const HT* ht):_node(node), _ht(ht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}Self& operator++(){if (_node->_next){_node = _node->_next;}else{KeyOfT kot;Hash hs;//算出目前在哪个桶里面size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();++hashi;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi]){_node = _ht->_tables[hashi];break;}else{++hashi;}}if (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;}bool operator!=(const Self& s) const{return _node != s._node;}bool operator==(const Self& s) const{return _node == s._node;}};}MyUnorderedSet.h
#pragma once
#include"HashTable.h"namespace sp
{//注意这里在加上自己写的仿函数时,因为命名空间不同,需要在前面加上命名空间template<class K,class Hash = Hash_Bucket::HashFunc<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public://typedef typename Hash_Bucket::HashTable<K, const K, SetKeyOfT, Hash>::Iterator iterator;//typedef typename Hash_Bucket::HashTable<K, const K, SetKeyOfT, Hash>::ConstIterator const_iterator;//另一种用法,和上面的意思是一样的,但using有更多的一些用途using iterator = typename Hash_Bucket::HashTable<K, const K, SetKeyOfT, Hash>::Iterator;using const_iterator = typename Hash_Bucket::HashTable<K, const K, SetKeyOfT, Hash>::ConstIterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin() const{return _ht.Begin();}const_iterator end() const{return _ht.End();}pair<iterator,bool> insert(const K& key){return _ht.Insert(key);}size_t count(const K& key){return _ht.Count(key);}size_t size(){return _ht.Size();}bool empty(){return _ht.Empty();}bool erase(const K& key){return _ht.Erase(key);}iterator erase(const iterator& it){return _ht.Erase(it);}size_t bucket_count(){return _ht.Bucket_Count();}size_t bucket_size(size_t i){return _ht.Bucket_Size(i);}void Print(const unordered_set<int>& s){unordered_set<int>::const_iterator it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;}private:Hash_Bucket::HashTable<K, const K,SetKeyOfT, Hash> _ht;};
}MyUnorderedMap.h
#pragma once
#include"HashTable.h"namespace sp
{template<class K, class V, class Hash = Hash_Bucket::HashFunc<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename Hash_Bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::Iterator iterator;typedef typename Hash_Bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::ConstIterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}pair<iterator,bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}V& operator[](const K& key){//没有的话就创建,有的话就传迭代求所在位置pair<iterator, bool> ret = insert({ key,V() });return ret.first->second; }iterator find(const K& key){return _ht.Find(key);}const_iterator find(const K& key)const{return _ht.Find(key);}const V& operator[](const K& key) const{const_iterator it = _ht.Find({key,V()});if (it == _ht.End()){throw out_of_range("The key is out of range");}return it->second;}size_t count(const K& key){return _ht.Count({key,V()});}size_t size(){return _ht.Size();}bool empty(){return _ht.Empty();}bool erase(const K& key){return _ht.Erase(key);}iterator erase(iterator& it){return _ht.Erase(it);}size_t bucket_size(size_t i){return _ht.Bucket_Size(i);}size_t bucket_count(){return _ht.Bucket_Count();}private:Hash_Bucket::HashTable<K, pair<const K,V>,MapKeyOfT, Hash> _ht;};
}那么本次关于STL容器自主实现的知识分享就此结束了~
非常感谢你能够看到这里~
如果感觉对你有些许的帮助也请给我三连 这会给予我莫大的鼓舞!
之后依旧会继续更新C++学习分享
那么就让我们
下次再见~
相关文章:
从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...