视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!!
摘要
视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面已显示出巨大的潜力,但现有的基准测试在细粒度评估方面不足,尤其是在捕捉对视频生成至关重要的时空细节方面。为了解决这一差距,我们推出了细粒度视频字幕评估基准(VCapsBench),这是第一个大规模的细粒度基准,包含5,677(5K+)个视频和109,796(100K+)个问答对。这些问答对是根据21个细粒度维度(例如,相机运动和镜头类型)进行系统注释的,这些维度经经验证明对文本到视频生成至关重要。我们进一步引入了三个指标(准确率(AR)、不一致率(IR)、覆盖率(CR))和一个利用大型语言模型(LLM)的自动化评估流程,通过对比问答对分析来验证字幕质量。通过为字幕优化提供可操作的见解,我们的基准可以促进稳健的文本到视频模型的开发。数据集和代码可在网站https://github.com/GXYM/VCapsBench上获取。
1 引言
视频理解 [1, 2, 3, 4, 5, 6] 和生成 [7, 8, 9, 10] 方面的最新进展是由大型视觉-语言模型 (VLMs) 驱动的。对于视频理解,研究人员已经扩展了基于图像的架构(例如,LLaVA-Video [11]、PLLaVA [12] 和 CogVLM2-Video [3]),并探索了混合图像-视频训练方法(Qwen2-VL [13]、LLaVA-OneVision [14])。目前,诸如 Sora [7] 和 HunyuanVideo [10] 等视频生成系统使用 VLM 进行多模态字幕和提示工程。然而,当前的基准测试 [15, 16, 17, 18, 19, 20] 难以评估这些应用所需的详细时空方面。
在视觉生成中,现有的字幕评估指标主要分为两类:基于参考的(METEOR [21]、BLEU [22]、SPICE [23]和CIDEr [24])和无参考的(InfoMetIC [25]、CLIPScore [26]和TIGEr [27])。基于参考的指标 [21, 22, 23, 24] 通过将生成的字幕与真实字幕进行比较来评估字幕的质量。然而,这些分数高度依赖于参考字幕的格式。因此,FAIEr [28] 采用视觉和文本场景图来实现更稳健的基于参考的评估。无参考指标 [25, 26, 27] 使用来自参考图像的语义向量来评估字幕的相似性。这些方法在处理概念密集的字幕时会失效,因为它们会被大量的概念所淹没。最近的创新,如QACE [29]、DSG [30]、DPG-bench [31]和CapsBench [32],采用问答框架来解决图像字幕中密集概念的评估问题。值得注意的是,这些源于图像描述评估的方法在处理视频生成场景中的时空动态元素时,仍然存在显著的测量盲点,例如,相机运动(“慢速缩放”与“快速平移”)或动态空间关系(对象从“左前景”位移到“中心中景”)。在这些情况下,视频生成系统(例如,Sora)需要确保准确的文本-视频对齐。
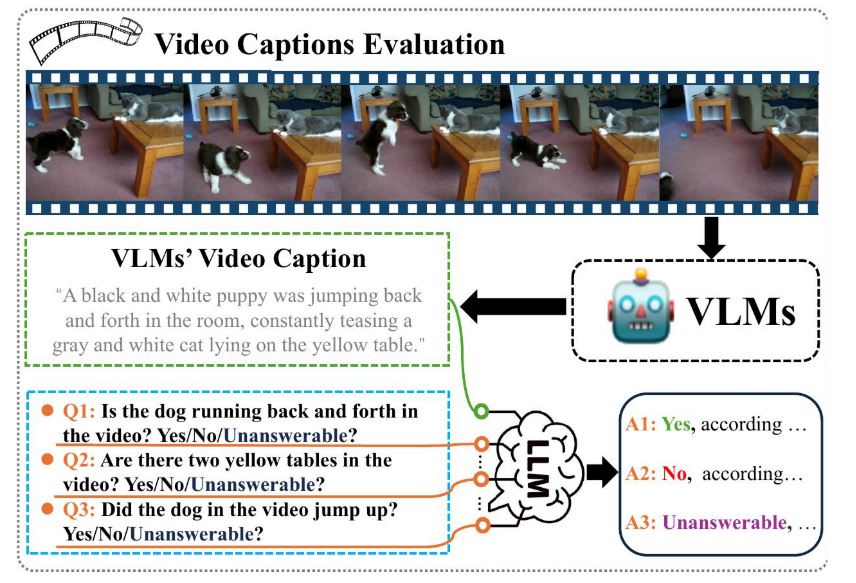
图1:VCapsBench视频字幕评估方法示意图。使用“是-否”问答对评估视频字幕的细节性、全面性和准确性。
当前的视频理解基准测试主要集中在整体语义对齐(MVBench [15],VideoVista [16])或特定技能评估(LVBench [17]),而忽略了视频生成必不可少的细粒度时空动态。当评估文本到视频系统时,这种差距变得至关重要,因为字幕的精确度直接影响视觉输出。例如,无法区分“慢速变焦”与“快速平移”的相机运动,或者错误地表示从“左前景”到“中央中景”的物体轨迹。虽然大规模地手动评估这些细微差别仍然不切实际,但由于传统评估范式的固有局限性,自动化指标在动态语义对齐方面也面临困难。为了解决这个问题,有必要重新审视视频描述评估指标的设计原则。
为了解决视频字幕评估中的关键差距,我们推出了VCapsBench,这是首个用于视频字幕评估的大规模细粒度基准。它包含5,677个不同的视频,带有109,796个人工验证的问题,从而可以对字幕质量进行细粒度评估。具体来说,我们采用基于文本的问答形式,涵盖21个类别,包括动作、相机运动(例如,变焦、摇摄和倾斜)、物体定位(绝对或相对位置)、实体和镜头类型等,并采用“是”、“否”和“无法回答”的三元判断。与像CapsBench [32]这样侧重于图像的字幕基准不同,我们的VCapsBench通过视频特定的查询(平均每个视频19个问题)来优先考虑时间连续性,同时通过“无法回答”选项来减轻LLM的幻觉。为了准确和全面地评估字幕质量,我们引入了三个指标:准确率(Accuracy, AR)、不一致率(Inconsistency Rate, IR)和覆盖率(Coverage Rate, CR)。为了自动计算这些指标,我们开发了一个评估流程,该流程利用强大的LLM进行客观的视频字幕质量测量,如图1所示。总而言之,我们的贡献如下:
我们引入了VCapsBench,这是首个大规模细粒度视频字幕评估基准,包含多样化的视频(5K+)和问答对(100K+)。
我们引入了三个指标:准确率(AR)、不一致率(IR)和覆盖率(CR),以及一个自动评估流程,以公平地评估视频字幕的正确性和覆盖范围。
我们评估了十个视觉语言模型,包括七个先进的开源模型(Qwen2VL、Qwen2.5VL、InternVL2.5、LLaVA-Video 和 VideoLLaMA3 等)和三个闭源模型 GPT-4o、Gemini2.5-Pro Flash 和 Preview,为社区提供了可靠的参考。
2 相关工作
基于参考的度量方法[21, 22, 23, 24, 28]通过比较生成的标题与真实标题来评估标题质量。BLEU [22]是一种快速、经济高效且与语言无关的机器翻译指标,与人工评估具有良好的相关性。METEOR [21]也评估机器翻译,并显示出与人工判断的高度相关性,显著优于BLEU。CIDEr [24]衡量生成的句子与一组人工编写的真实句子之间的相似性,作为图像描述质量的自动共识指标。然而,这些指标主要侧重于n-gram重叠,这对于模拟人类判断既不是必需的,也不是充分的。为了解决这些局限性,SPICE引入了一种基于场景图的语义命题内容的度量标准,但其分数高度依赖于参考标题的格式。像FAIEr [28]这样的较新方法利用视觉和文本场景图进行更稳健的评估。
无参考指标方法[25, 26, 27]利用来自参考图像的语义向量来评估标题相似性。InfoMetIC [25]是一种用于无参考图像标题评估的信息性指标,能够以细粒度的精度识别不正确的单词和未提及的图像区域。它提供文本精确度分数、视觉召回率分数以及粗粒度级别的整体质量分数,后者在多个基准测试中显示出与人类判断的关联性明显优于现有指标。CLIPScore [26]采用CLIP [33]对图像标题进行稳健的自动评估,无需参考,侧重于图像-文本的兼容性。尽管CLIPScore与强调文本-文本相似性的基于参考的指标互补,但对于需要更丰富的上下文知识的任务(例如新闻标题)而言,CLIPScore相对较弱。TIGEr [27]通过评估图像内容的表示以及机器生成的标题与人工生成的标题的对齐情况来评估标题质量。
为了提高视觉生成任务中字幕质量的评估,已经开发了基于问题的评估方法[29, 30, 32]。QACE框架[29]通过从字幕生成问题来评估其质量。对于图像生成模型,也提出了类似的方法,其中戴维森场景图(DSG)[30]将问题组织成依赖关系图,从而有助于全面评估文本到图像的模型。受DSG和DPG-bench [31]的启发,Playground v3 [32]引入了CapsBench,这是一个用于图像字幕的基准,它使用“是-否”问答对。然而,这些基准仅侧重于图像字幕,而视频字幕需要考虑诸如动作、运动、摄像机运动和镜头类型等额外因素,这些因素对于文本到视频的生成至关重要。
3 VCapsBench基准测试
3.1 概述
正如第Sec. 讨论的那样,尽管现有的基准测试可以评估VLM生成的图像标题在各个维度上的质量。2,但它们在评估VLM生成的细粒度视频标题方面仍然不足。为了有效地衡量VLM在不同类型视频中的理解和描述能力,我们构建了一个大规模高质量的基准测试VCapsBench,用于视频标题质量评估。
3.2 数据集统计
数据维度。如图2所示,视频字幕的评估分为四个主要类别:“内容与实体”、“视觉与构图”、“色彩与光照”以及“电影摄影与氛围”。“内容与实体”包括七个子类别,重点关注动作、计数、实体、实体大小、实体形状、专有名词和关系等核心要素。“视觉与构图”与空间布局和视觉呈现相关,包含五个子类别:位置、相对位置、文本、模糊和背景。“色彩与光照”探讨这些元素如何增强情绪和风格,涵盖四个子类别:颜色、调色板、色彩分级和光照。最后,“电影摄影与氛围”包括五个子类别:摄像机运动、镜头类型、风格、氛围和情感,整合了拍摄技巧和艺术表达。通过对这些维度进行分类,可以更轻松地对不同类别的视频字幕质量进行统计分析。这为优化VLM的视频理解能力提供了更详细的指导。
数据收集。为了充分支持视频理解和生成任务中的字幕评估任务,我们在VCapsBench的数据收集中优先考虑了美学和内容的复杂性。我们从10个公开可用的数据集中获取视频,以确保多样性:Panda-70M[34]、Ego4D[35]、BDD100K[36]、Pixabay [37]、Pexel [37]、VIDGEN-1M[38]、ChronomicBench [39]、FineVideo [40]、FunQA [39]和LiFT-HRA-20K [41]。如图3所示,我们从Panda-70M[34]中精心挑选了988个高分辨率视频,涵盖了广泛的场景,如野生动物、烹饪、体育、电视节目、游戏和3D渲染。这些视频通常包含复杂的内容和转换,为理解各种现实场景提供了坚实的基础。此外,我们还包括了来自Pexels的494个高分辨率视频和来自Pixabay的298个视频,这两个平台都以其风景优美的景观和人类活动而闻名,其特点是具有很高的美学质量和详细的图像。为了进一步确保数据的多样性,我们从FineVideo[40]中抽取了1,018个视频,该数据集包含6个主要类别和122个子类别。尽管它们的分辨率较低(低于640
×
360),但我们通过从VIDGEN-1M[38]中抽取333个超高分辨率视频(2K、3K和4K)来平衡这一点,这些视频通常用于训练文本到视频模型,因为它们具有高细节和高质量。我们的数据集还通过来自Ego4D[35]和BDD100K[36]的视频得到了进一步丰富,以涵盖以自我为中心的人类活动和自动驾驶场景,确保了对现实世界场景的全面表示。为了评估VLM模型对物体运动和物理定律的理解,我们从ChronomicBench中包含了1,549个视频,涵盖了四个主要类别(例如,生物、人工、气象和物理),共75个子类别。为了进一步使我们的数据集多样化,我们从FunQA中抽取了227个视频,从LiFT-HRA-20K中抽取了200个视频。FunQA的特色是以人为中心的内容,如幽默片段、创意表演和视觉错觉,而LiFT-HRA-20K由合成视频数据组成。
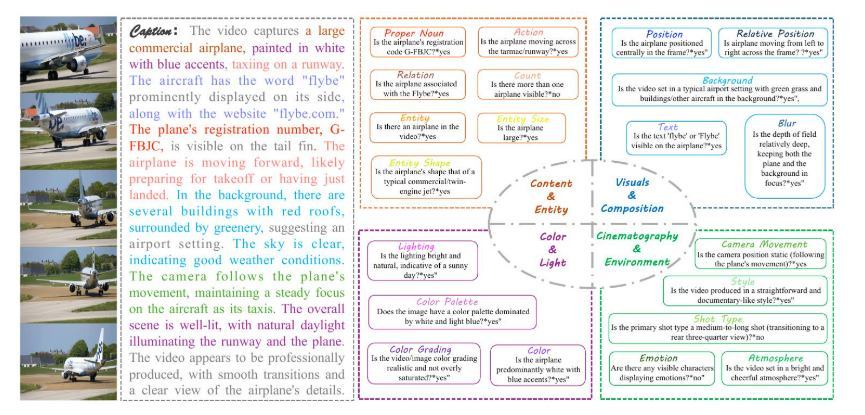
图2:VCapsBench中视频字幕和问答对的示例。
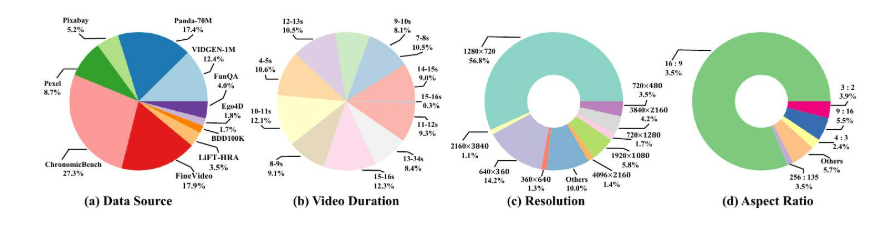
图 3:(a) 视频来源分布;(b) 视频时长分布;(c) 视频分辨率分布;(d) 视频宽高比分布。
如图3所示,我们的VCapsBench数据集包含5,677个视频,涵盖了广泛的场景,例如,自然景观、动物、人类活动、物理现象、游戏、3D渲染和合成视频(超过100个子类别)。VCapsBench还具有不同的视频时长(4到16秒)、分辨率(125种不同的分辨率)和宽高比(87种不同的比例)。这个广泛的集合允许对VLM模型在各种视频类型中的理解和洞察力进行彻底的评估,从而确保对视频字幕的稳健评估。
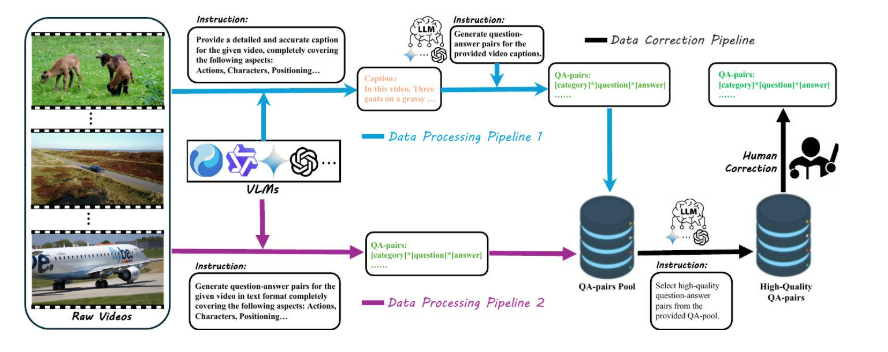
图4:QA对的生成流程,包括多个数据处理流程和一个数据校正流程。
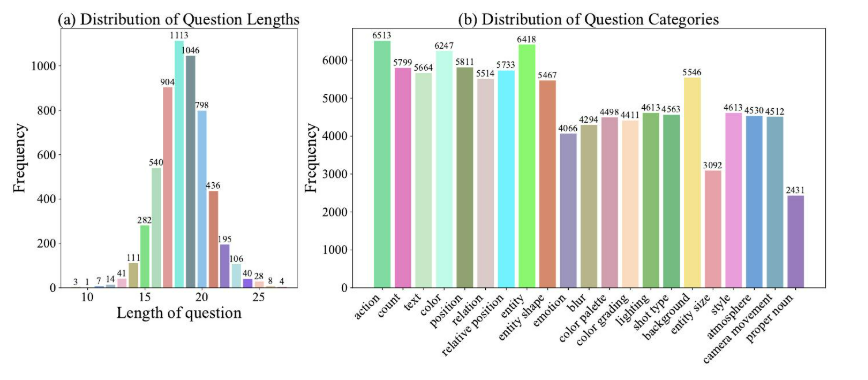
图5:问题长度和类别分布。
3.3 注释细节
受 DPG-bench [31] 和 CapsBench [32] 的启发,我们开发了一种使用多维问答对来评估视频字幕质量的方法。基于原始视频,我们生成“是-否”问答对作为注释。如图 4 所示,我们的“数据处理流程”创建了这些问答对,并将其存储在“问答对池”中。每个问答对包括类别、问题和答案,格式为“[类别][问题][答案]”,以便于处理。为了确保多样性和准确性,我们设计了两个数据生产流程。第一个流程使用各种视觉语言模型(VLMs),如 Geinimi、Qwen 和 HunYuan,从预定义的提示生成详细的视频字幕。然后,像 GPT-4、Gemini 和 Qwen72B 这样的大型语言模型(LLMs)使用这些字幕和额外的提示来创建问答对。第二种方法直接利用视觉语言模型(VLMs)从视频和提示生成问答对。然后,将来自两个流程的输出合并到一个综合的问答池中。
为了提高问答对的质量,我们建立了一个数据校正流程。该流程以来自同一视频的多组问答对和字幕作为输入,并使用具有预定义指令的先进LLM(Gemini1.5)来去重、过滤并保留高质量的问答对。这些指令引导LLM合并相似的问答对,过滤掉那些问题相同但答案不同的问答对,并删除只出现一次的问答对,因为它们很可能是无效的。
人工校正。在生成高质量的候选问答对后,我们根据纬度对数据进行采样,以确保数据更侧重于重要纬度,然后进行最终的人工质量控制流程。人工审核员重新检查这些问答对,删除那些问题不合理或不正确的问答对,并更正那些答案错误的问答对。经过这次人工修订后,我们建立了一个基准(VCapsBench),其中包含5,677个视频和109,796个问答对。如图5所示,每个视频包含10到27个问答对,每个类别包含2,431到6,513个问答对。这些问题被组织成四个主要类别和21个子类别。大多数答案是“是”,这清楚地表明
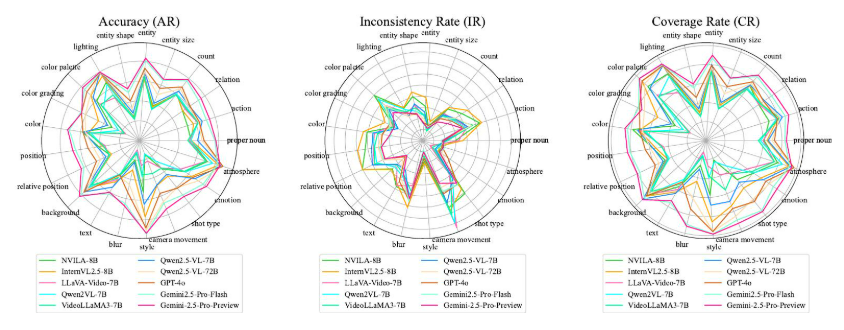
图 6:Gemini-2.5-Pro-Preview 字幕生成评估结果,按类别组织。正确性,而较少数量的“否”答案有助于评估视频字幕是否包含幻觉或不准确之处。
3.4 字幕评估
我们采用VCapsBench来评估各种视觉-语言模型(VLMs)生成的视频字幕,包括Gemini-1.5等顶级专有模型。对于每个测试视频,一个具备评估能力的VLM会根据特定指南和输出模式生成详细的字幕。此字幕连同视频问答对中的每个问题,都会被输入到一个大型语言模型(LLM)中。如图1所示,LLM根据字幕回答每个问题,并以“[答案],[理由]”的格式提供答案。我们指示LLM在以下三种情况下评估字幕:
积极:标题准确描述了相关内容,并且大型语言模型(LLM)的响应与答案一致。
负面: 标题提到了相关内容,但LLM的回复与答案不符。
无法回答:说明文字不涉及该维度的相关内容。
为了全面评估字幕的质量,我们开发了三种专门针对这些场景的指标。字幕的质量使用以下度量标准进行评估:

准确率 (AR):此指标评估“肯定”响应的百分比,表明标题正确描述了相关内容并与 LLM 的响应一致。较高的 AR 值表示更准确和可靠的标题,反映了 LLM 输出中更好的质量。
不一致率(IR):该指标衡量的是在所有引用相关内容的回复(包括“肯定”和“否定”)中,“否定”回复所占的百分比。较低的IR表示更准确的字幕,表明当字幕涉及相关内容时,它更可能与真实的视频内容保持一致。
覆盖率 (CR):此指标评估“肯定”和“否定”响应的总百分比,反映字幕是否包含相关内容,与LLM响应的一致性无关。较高的CR表示字幕内容更丰富,因为它表明字幕包含了视频中更多的相关内容。
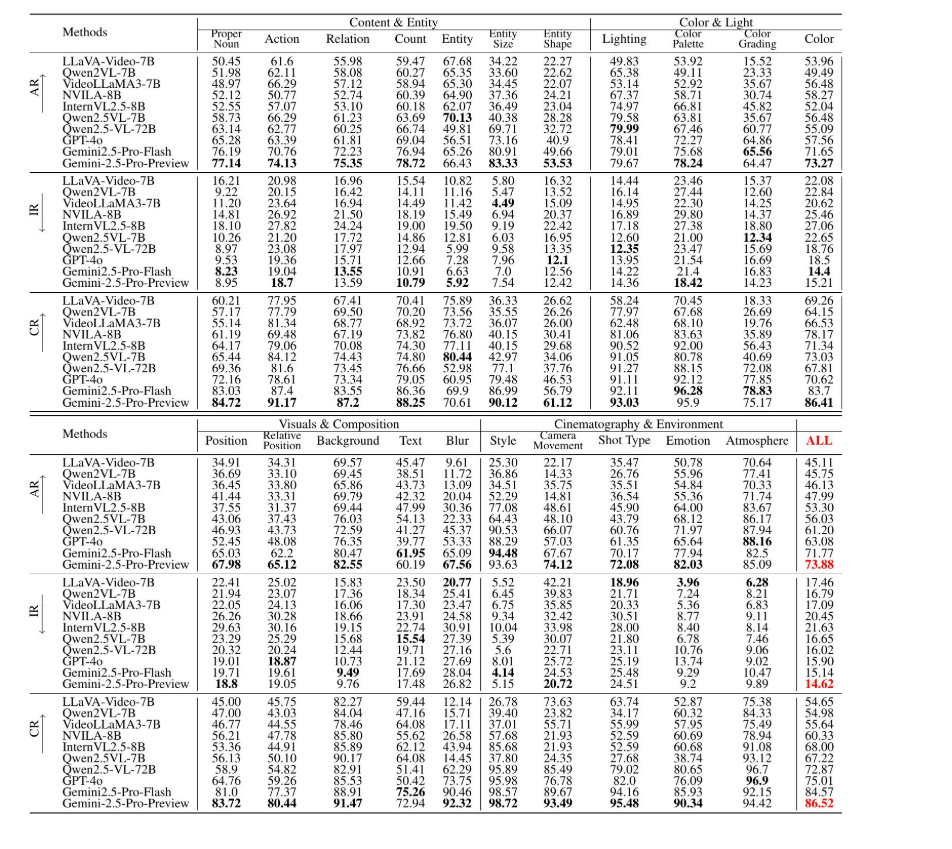
表1:VLM方法在所有维度上的准确率(AR)、不一致率(IR)和覆盖率(CR),其中Gemini-2.5-Pro-Preview作为TextQA专家。符号“↑”表示数值越大越好;符号“↓”表示数值越小越好。
4 实验
实验设置。我们评估了几种流行的开源视觉-语言模型(VLMs),包括 Qwen2VL [13]、Qwen2.5VL [42]、InternVL2.5 [42]、LLaVA-Video [43]、NVILA [44] 和 VideoLLaMA3 [45],以及通过 API 访问的闭源 Gemini-2.5 和 GPT-4o。所有模型都以相同的方式提示,以生成跨 21 个维度的详细视频描述。为了更好地评估,我们采用了两种强大的 LLM(例如,Gemini-2.5-Pro-Pre view 和 GPT-4.1)作为 TextQA 专家,根据生成的描述回答 VCapsBench 问题。评估指标源自它们的响应,并在表中呈现。1 和附录 A.1 表。3。 按照 Playground v3 协议 [32],每个字幕被查询三次,并获得一致的响应,以最大限度地减少输出变化并确保一致性。
4.1 主要结果
准确率(AR):如表1和图6所示,在使用准确率(AR)指标进行评估时,Gemini-2.5-Pro-Preview在各个维度上始终超越所有其他模型。例如,在“内容&实体”维度中,特别是关于动作方面,Gemini-2.5-Pro-Preview的AR达到了74.13%,而其他模型通常在40%到70%之间。在“颜色&光线”维度中,特别是对于光照方面,Gemini-2.5-Pro-Preview获得了令人印象深刻的79.67%的AR,显著优于其他模型。当考虑整个数据集时,Gemini-2.5-Pro-Preview的AR达到了73.88%,明显优于其他开源模型。在这些模型中,最新的Qwen2.5-VL-72B表现最佳,AR为61.20%,但仍远低于Gemini-2.5-Pro-Preview。这突显了Gemini-2.5-Pro-Preview卓越的准确捕捉和描述视频内容的能力,从而提供更高质量的描述和见解。
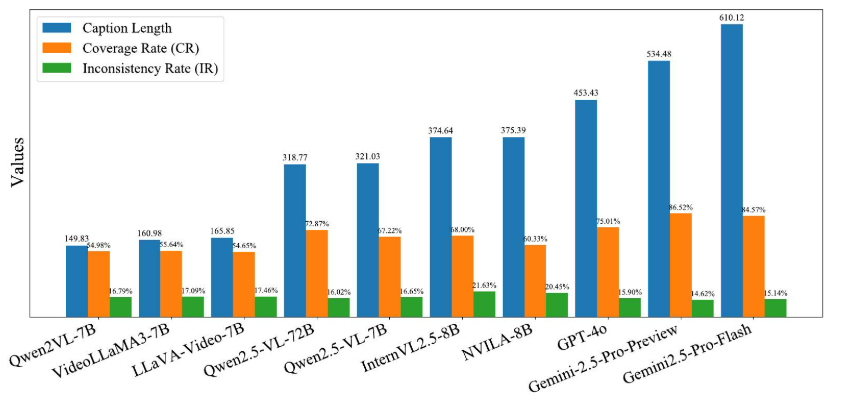
图 7:CR、IR 与标题长度之间的关系,其中 Gemini-2.5-Pro-Preview 作为 TextQA 专家。标题长度为标题中的单词数,不包括特殊符号。
不一致率(IR):Gemini-2.5-Pro-Preview在IR指标方面表现突出,实现了最低的IR值。例如,在“视觉与构图”类别中,尤其是在背景方面,Gemini-2.5-Pro-Preview记录的IR仅为9.76%,而其他模型通常在10%至20%之间。在“电影摄影与环境”类别中,尤其是在照明方面,Gemini2.5-Pro-Flash的IR仅为14.22%。
覆盖率(CR):在CR指标方面,Gemini-2.5-Pro-Preview再次展现出卓越的性能。在“内容 & 实体”类别中,Gemini-2.5-Pro-Preview的最低CR出现在“实体形状”子类别中,为61.12%,而最高CR出现在“实体”子类别中,为90.12%。其他开源模型的CR值在所有类别中均低10%以上。总体而言,Gemini-2.5-Pro-Preview实现了令人印象深刻的86.52%的CR。在开源模型中,InternVL2.5-8B表现最佳,CR为68.00%,比Gemini-2.5-Pro-Preview低18.52%。这表明Gemini-2.5-Pro-Preview可以覆盖视频中更多相关内容,从而提供更全面的覆盖,而与描述一致性无关。
Gemini-2.5-Pro-Preview 在生成视频描述方面表现出色,展示出高准确率(AR)、一致性(IR)和全面覆盖率(CR)。这突显了其在生成高质量、详细且一致的描述方面优于其他模型的性能。VCapsBench 强调了现有开源 VLM 的缺点,例如在描述中缺乏详细的物体形状、大小、颜色和光照。对于需要高度详细和完整字幕的应用,例如文本到视频生成模型和高级视频分析工具,这些缺陷尤其成问题。
4.2 评估分析
尽管Gemini在各个方面都超越了开源VLMs,展示了其先进的视频理解能力,但必须承认的是,Gemini的字幕被用于创建QA对,这可能会影响其较高的CR。尽管如此,Gemini的指标是有价值的,因为它们为开源模型建立了一个基准,强调了视频内容理解方面的差距。这一见解有助于指导开源VLMs的优化。
标题长度分布分析。我们还探讨了标题长度,以确定较长的标题是否与较高的评估覆盖率(CR)相关,如图7所示。代表性样本分析。为了进一步检验各种模型的优势和劣势,我们对标题进行了定性分析。在图9中,我们展示了一个来自VCapsBench的视频,该视频具有大量主题和复杂的细节,对VLMs提出了重大挑战。表格。2列出了此视频的问题以及从标题中得出的答案。显而易见的是,不同的VLMs在不同的维度上表现出不同的性能。一些类别,如“氛围”和“背景”,对于所有VLMs来说都相对容易,而另一些类别,如“相对位置”,则对所有模型都提出了挑战。然而,每个视频在不同的类别中都有独特的问题。该综合数据集包含大量问题,足以彻底评估VLM理解和观察视频细节的能力。更多结果见附录A.1、A.2和A.3。

图 8:来自 VCapsBench 的代表性视频。表 2:来自 VCapsBench 的代表性视频的问题。“Q2.5-72B”、“LV-7B”、“Q2-7B”、“VL-7B”、“NV-8B”、“I2.5-8B”、“Q2.5-7B”、“G2.5”分别代表“Qwen2.5VL-72B”、“LLaVA-Video7B”、“Qwen2VL-7B”、“VideoLLaMA3-7B”、“NVILA-8B”、“InternVL2.5-8B”、“Qwen2.5VL-7B”和“Gemini-2.5-Pro-Pre view”。“"”、“%”、“•”分别代表“Positive”、“Negative”和“Unanswerable”。

附录A.1中的图11展示了所评估模型的标题词语长度的直方图。我们的研究结果表明,随着模型生成的标题长度增加,CR通常会提高。然而,长度的增加也会导致一些开源模型,如Qwen2VL-7B、VideoLLaMA3-7B、LLaVA-Video-7B和InternVL2.5-8B,出现更多的错误。有趣的是,像Qwen2.5-VL-72B这样的开源VLM和闭源VLM Gemini-2.5,尽管生成了更长的标题,但与其他VLM相比,错误率更低。此外,Qwen2.5-VL-7B以更短的标题实现了比VILA-8B更高的CR,并以更短的标题实现了比LLaVA-Video-7B更低的IR。这表明对视频内容的深刻理解使得模型能够生成简洁、但全面且准确的描述。
5 结论
在这项工作中,我们介绍了VCapsBench,这是一个新的大规模细粒度基准,用于评估视频字幕质量。VCapsBench经过精心设计,旨在支持详细的长字幕,从而推进视频理解领域的研究和基准测试。该基准包含超过5千个视频和超过10万个问答对,评估视频生成的21个关键维度。我们使用此基准评估了各种开源和闭源模型生成的字幕质量。全面的分析突出了这些模型在生成准确和详细字幕方面的优势和劣势。我们相信,VCapsBench将在指导视频字幕生成的优化方面发挥关键作用,从而推进文本到视频模型的发展,并提高对视频内容的整体理解。
相关文章:
视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...