SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来
一、选择题(可多选)
- 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C)
A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘
- A. 频繁模式挖掘:专注于发现数据中频繁出现的项集、序列或子结构。
- B. 分类和预测:用已标记数据训练模型,对新数据做类别判断或数值预测。
- C. 数据预处理:对原始数据做清洗、集成(合并多源数据)、变换(如归一化、离散化 )、维度规约(降维,减少特征数量 )、数值规约(压缩数值规模,如用均值替代细节值 )。
- D. 数据流挖掘:针对实时、连续的数据流,实时或近实时地挖掘模式、检测异常。
- 简单地将数据对象集划分成不重叠的子集,使得每个数据对象恰在一个子集中,这种聚类类型称作(B)。
A.层次聚类 B.划分聚类 C.非互斥聚类 D.模糊聚类
- 层次聚类:构建树状层级结构,通过合并或分裂逐步形成聚类,展现数据层次关系。
- 划分聚类:将数据硬性划分到互不重叠子集,每个对象仅属一个簇,如K-Means。
- 非互斥聚类:允许数据对象同时属于多个簇,突破“一对一”归属限制。
- 模糊聚类:用隶属度(0 - 1)表示对象属于各簇的程度,体现归属模糊性 。
- 下表是一个购物篮,假设支持度阈值为40%,其中(D)是频繁闭项集。
| TID | 项 |
|---|---|
| 1 | abc |
| 2 | abcd |
| 3 | bce |
| 4 | acde |
| 5 | de |
A. abc B. ad C.cd D.de
先算各选项项集支持度,支持度=包含项集的事务数/总事务数(总事务数为5 )。“de”出现在TID4、TID5,支持度为2/5 = 40%,满足阈值;且没有超集与它支持度相同,是频繁闭项集,选D。
- 某超市研究销售记录数据后发现,买啤酒的人很大概率也会购买尿布,这属于数据挖掘的哪类问题?(A)
A. 关联规则发现 B.聚类 C.分类 D.自然语言处理
- A. 关联规则发现:挖掘数据项之间的关联模式,找出“一个事件发生时另一个事件也大概率发生”的规则(如买啤酒→买尿布 )。
- B. 聚类:无监督地将数据划分成若干簇,让簇内数据相似、簇间数据差异大,实现数据的“自然分组”(如区分不同消费习惯的客群 )。
- C. 分类:用标记数据训练模型,对新数据判定类别(如区分垃圾邮件/正常邮件 、识别客户是“高价值”或“低价值” )。
- D. 自然语言处理:让计算机理解、处理人类语言文本,涉及分词、情感分析、文本生成等(如聊天机器人理解问题、新闻文本分类 ),本题场景不涉及语言处理,故不选。
- (B)是一个观测值,它与其他观测值的差别很大,以至于怀疑它是由不同的机制产生的。
A. 边界点 B.离群点 C.核心点 D.质心
- 边界点:处于簇边缘区域,密度低于核心点、高于离群点,是划分簇边界的过渡性点。
- 离群点:与其他观测值差异极大,疑似由不同生成机制产生的异常数据点 。
- 核心点:在密度聚类(如DBSCAN)中,邻域内数据点数量满足阈值,是簇的“核心组成”。
- 质心:聚类里代表簇中心的点(如K-Means的簇中心),是簇内点的“平均位置”。
-
影响聚类算法效果的主要原因有(ABC)。
A. 特征选取 B.模式相似性测度
C.分类准则 D.已知类别的样本质量 -
在分类问题中,我们经常会遇到正负样本数据量不等的情况,比如正样本有10万条数据,负样本只有1万条数据,以下最合适的处理方法是( )。
A. 将负样本重复10次,生成10万样本量,打乱顺序参与分类
B.直接进行分类,可以最大限度地利用数据
C.从10万正样本中随机抽取1万参与分类
D.将负样本每个权重设置为10,正样本权重为1,参与训练过程 -
在数据清理中,处理缺失值的方法是( )。
A. 估算 B.整列删除 C.变量删除 D.成对删除 -
Apriori算法的计算复杂度受( )影响。
A. 项数(维度) B.事务平均宽度 C.事务数 D.支持度例值 -
在关联规则中,有三个重要的指标:支持度(support)、可信度(confident)、提升度(lift),则对于规则的三个指标说法错误的是( )。其中,表示所有的样本item数目。
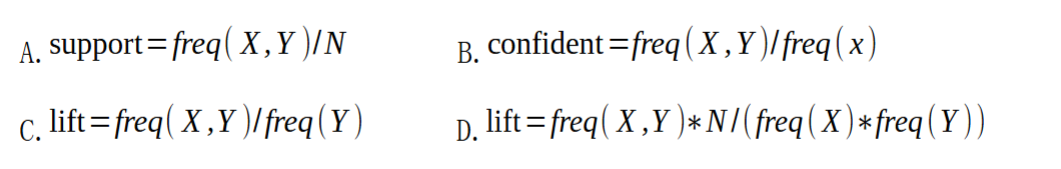
-
下列方法中,可以用于特征降维的方法包括( )。
A.主成分分析(PCA)
B.线性判别分析(LDA)
C.深度学习SparseAutoEncoder
D.最小二乘法 -
关于线性回归的描述,以下错误的是( )。
A.线性回归可以用于做连续值预测
B.线性回归模型通过最小化预测值与实际观测值之间的差异来确定最佳拟合直线。
C.线性回归假设自变量(预测变量)与因变量(响应变量)之间存在非线性关系,并尝试通过拟合一条直线或超平面来描述这种关系。
D.线性回归是一种用于建模两个或多个变量之间关系的统计方法。 -
假设属性income的最大/最小值分别是12000元和98000元。利用最大/最小规范化的方法将属性的值映射到0~1的范围内。对属性 income,73600元将被转化为:( )
A.0.821 B.1.224 C.1.458 D.0.716 -
只有非零值才重要的二元属性被称作( )。
A.计数属性 B.离散属性
C.非对称的二元属性 D.对称属性 -
将原始数据进行集成、变换、维度规约、数值规约是以下哪个步骤的任务?()
A.频繁模式挖掘 B.分类与预测
C.数据预处理 D.数据流挖掘 -
下面哪种不属于数据预处理的方法?( )
A.变量代换 B.离散化 C.聚集 D.估计遗漏值 -
设是频繁项集,则可由产生()个关联规则。
A.4 B.5 C.6 D.7 -
一个对象的离群点得分是该对象周围密度的逆。这是基于( )的离群点定义。
A.概率 B.邻近度 C.密度 D.聚类 -
利用Apriori算法计算频繁项集可以有效降低计算频繁集的时间复杂度。在以下的购物篮中产生支持度不小于3的候选3项集,在候选2项集中需要剪枝的是()。
| ID | 项集 |
|---|---|
| 1. | 面包、牛奶 |
| 2. | 面包、尿布、啤酒、鸡蛋 |
| 3. | 牛奶、尿布、啤酒、可乐 |
| 4. | 面包、牛奶、尿布、啤酒 |
| 5. | 面包、牛奶、尿布、可乐 |
A. 啤酒、尿布 B.啤酒、面包 C.面包、尿布 D.啤酒、牛奶
-
考虑值集,其截断均值(=20%)是( )。
A.2 B.3 C.3.5 D.5 -
假设用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13,15,16,16,19,20,20.21.22,22.25,25,25,30,33、33、35.35,36,40、45,46,52,70,问题:使用按箱平均值平滑方法对上述数据进行平滑,箱的深度为3。第二个箱的值为( )。
A.18.3 B.22.6 C.26.8 D.27.9 -
下列哪个不是专门用于可视化时间/空间数据的技术?( )
A.等高线图 B.饼图 C.曲面图 D.矢量场图 -
根据规则集,灰熊属于什么类别?( )
规则集:

A. 鸟 B.鱼 C.哺乳 D.爬行 -
神经网络分类器的特点包括( )。
A.普适近似,精度较高
B. 噪声敏感
C.训练非常耗时 -
标称类型数据可以利用的数学计算为( )。
A.众数 B.中位数 C.均值 D.方差 -
假设某同学使用贝叶斯分类模型时,由于失误操作,致使训练数据中两个维度重复表示。下列描述中正确的是( )。
A.被重复的维度在模型中作用被加强
B.模型效果精度降低
C.如果所有特征都被重复一遍,则预测结果不发生变化
D.以上说法均错误 -
关于K-Means算法,正确的描述是( )
A.能找到任意形状的聚类
B.初始值不同,最终结果可能不同
C.每次迭代的时间复杂度是 O ( n 2 ) {{O}\left({{{n}}^{{2}}}\right)} O(n2),其中n是样本数量
D.不能使用核函数 -
考虑以下问题:假设我们有一个5层的神经网络,这个神经网络在使用一个4GB显卡时需要花费3h来完成训练。而在测试过程中,单个数据需要花费2s。如果我们现在把架构变换一下,当评分是0.2和0.3时,分别在第2层和第4层添加Dropout,那么新架构的测试所用时间会变为多少?( )
A.少于 2s B.大于 2s C.仍是2s D.说不准 -
下面哪些属于可视化高维数据技术?( )
A.平行坐标系 B.直方图 C.散点图矩阵 D.切尔诺夫脸 -
以下关于感知机说法正确的是( )。
A.在Batch Learning模式下,权重调整出现在学习每个样本之后
B.只要参数设置得当,感知机理论上可以解决各种分类问题
C. 感知机的训练过程可以看作在误差空间进行梯度下降
D.感知机的激励函数必须采用门限函数 -
在误差逆传播算法中,隐含层节点的误差信息应当( )
A.根据自身的期望输出和实际输出的差值计算
B.根据所有输出层神经元的误差的均值计算
C.根据自身下游神经元的误差进行加权计算
D.根据自身下游神经元的误差的均值计算 -
训练神经网络时,以下哪种激活函数最容易造成梯度消失?( )
A.Tanh B.sigmoid C.ReLU D.leakyReLU -
关于数据预处理,以下说法错误的是( )。
A.可以通过聚类分析方法找出离群点
B.数据质量的三个基本属性(指标)是正确性、精确性和完整性
C.聚类和回归算法可在数据预处理中做数据规约操作
D.数据集成包括内容集成和结构集成 -
如果对相同的数据进行逻辑回归,将花费更少的时间,并给出比较相似的精度(也可能不一样),怎么办?(假设在庞大的数据集上使用Logistic回归模型。可能遇到一个问题,Logistic回归需要很长时间才能训练。)( )
A.降低学习率,减少迭代次数 B.降低学习率,增加迭代次数
C.提高学习率,增加迭代次数 D.增加学习率,减少迭代次数 -
神经网络模型是受人脑的结构启发发明的。神经网络模型由很多神经元组成,每个神经元都接受输入,进行计算并输出结果,那么以下选项描述正确的是( )。
A.每个神经元只有单一的输入和单一的输出
B. 每个神经元有多个输入而只有一个输出
C.每个神经元只有一个输入而有多个输出
D.每个神经元有多个输入和多个输出 -
主成分分析(PCA)是一种重要的降维技术,以下对于PCA的描述正确的是( )
A.主成分分析是一种无监督方法
B.主成分数量一定小于等于特征的数量
C.各个主成分之间相互正交
D.原始数据在第一主成分上的投影方差最小 -
下列哪个不是数据对象的别名( )。
A.样品 B.实例 C.维度 D.元组 -
数字图像处理中常使用主成分分析(PCA)来对数据进行降维,下列关于PCA算法说法错误的是( )。
A.PCA是最小绝对值误差意义下的最优正交变换
B.PCA第一个主成分拥有最大的方差
C.PCA算法是用较少数量的特征对样本进行描述以达到降低特征空间维数的方法
D.PCA算法通过对协方差矩阵做特征分解获得最优投影子空间,从而消除模式特征之间的相关性、突出差异性 -
逻辑回归为什么是一个分类算法而不是回归算法?( )
A.是由于激活函数sigmod 把回归问题转化成了二分类问题
B.是由于激活函数maxsoft把回归问题转化成了二分类问题
C.是由于激活函数Tanh把回归问题转化成了二分类问题
D.是由于激活函数Relu把回归问题转化成了二分类问题 -
以下关于逻辑回归说法错误的是( )。
A.特征归一化有助于模型效果
B.逻辑回归是一种广义线性模型
C.逻辑回归相比最小二乘法分类器对异常值更敏感
D.逻辑回归可以看成只有输入层和输出层且输出层为单一神经元的神经网络 -
在NumPy数组操作中,哪个概念描述的是"不同形状数组间执行算术运算的机制"?
A. 向量化
B. 广播
C. 重塑
D. 索引 -
在数据统计分析中,箱线图(Boxplot)的箱体部分主要表示什么统计量?
A) 数据全距
B) 数据均值
C) 数据四分位距
D) 数据标准差 -
Pandas中,哪种数据结构最适合存储和操作带标签的一维数据?
A) DataFrame
B) Panel
C) Series
D) Index -
下列哪种属性用数字表示符号或名称,但仅用于区分对象类别?
A. 二元属性
B. 序数属性
C. 标称属性
D. 数值属性 -
余弦相似性主要用于度量哪种数据的相似性?
A. 二元属性
B. 序数属性
C. 文档关键词向量
D. 混合类型属性 -
下列哪个统计量对噪声数据最敏感?
A. 中位数
B. 众数
C. 均值
D. 四分位数 -
非对称二元属性中,通常如何编码重要状态?
A. 用0表示重要状态
B. 用1表示重要状态(通常是稀有结果)
C. 必须对称编码(0和1等价)
D. 用负数表示重要状态 -
盒图(箱线图)中,异常值的判定依据是?
A. 超出均值±2倍标准差
B. 超出Q1-1.5×IQR或Q3+1.5×IQR
C. 小于最小值或大于最大值
D. 与众数的距离超过阈值 -
在数据预处理中,以下哪项描述最准确地解释了“噪声数据”的来源?
A. 数据采集设备故障或传输错误导致的随机误差
B. 属性命名不一致引起的冗余问题
C. 不同数据源的结构差异导致的不一致
D. 人为录入时故意省略部分数据值 -
关于数据集成中的“实体识别”,以下说法正确的是?
A. 用于检测重复元组并删除冗余记录
B. 解决不同数据源中相同属性的命名差异问题(如 customer_id 与 cust_no)
C. 通过分箱或回归技术处理数据中的离群点
D. 将数据从高维空间投影到低维空间以减少特征数量 -
在数据变换策略中,“离散化”的主要目的是?
A. 将数据缩放到特定区间(如 [0,1])以消除量纲影响
B. 构造新属性以增强数据表达能力
C. 将连续型数据转换为离散区间,适应分类算法需求
D. 对稀疏数据进行中心化处理以保留数据结构 -
回归分析主要用于解决什么问题?
A. 预测离散型因变量
B. 研究因变量与自变量之间的统计关系
C. 处理图像分类任务
D. 降低数据维度 -
若因变量是二分类变量(如“是/否”),应选择哪种回归技术?
A. 线性回归
B. 多项式回归
C. 逻辑回归
D. 岭回归 -
关于一元线性回归的假设,以下哪项是错误的?
A. 自变量与因变量需有线性关系
B. 对异常值不敏感
C. 需避免多重共线性
D. 通过最小二乘法估计参数 -
Apriori算法利用什么性质压缩搜索空间?
A. 闭项集性质
B. 极大项集性质
C. 先验性质(频繁项集的子集必频繁)
D. 支持度单调性 -
FP-growth算法的核心思想是什么?
A. 生成候选项集并剪枝
B. 将事务数据库压缩为FP树
C. 使用垂直数据格式
D. 基于抽样减少计算量 -
以下关于极大频繁项集的定义,正确的是?
A. 支持度最高的项集
B. 不存在包含它的频繁超项集
C. 其所有子集都是频繁的
D. 支持度等于最小支持度阈值 -
规则 A⇒B 的置信度如何计算?
A. support_count(A∪B)/support_count(A)
B. support_count(A)/support_count(B)
C. support_count(A∪B)/总事务数
D. support_count(B)/support_count(A) -
在决策树算法中,C4.5相比ID3的主要改进是什么?
A. 使用信息增益作为属性选择度量
B. 引入增益率并支持连续属性和缺失值处理
C. 改用基尼指数作为属性选择度量
D. 取消了树剪枝步骤以简化算法 -
支持向量机(SVM)的硬间隔最大化要求?
A. 允许部分样本分类错误
B. 训练数据必须严格线性可分
C. 使用核函数映射到高维空间
D. 调整支持向量的权重 -
关于模型评估中的ROC曲线,以下描述正确的是?
A. 横轴是召回率(Recall),纵轴是精度(Precision)
B. 曲线下面积(AUC)越小表示模型性能越好
C. 每个点对应不同分类阈值下的真正例率和假正例率
D. 主要用于处理类别不平衡问题 -
随机森林算法中,构建单棵决策树的关键步骤是?
A. 从原始训练集无放回抽样选取样本
B. 在分裂结点时随机选择部分特征进行划分
C. 所有树使用完全相同的训练样本和特征
D. 仅使用信息增益作为分裂标准 -
正则化在机器学习模型选择中的作用是?
A. 提高模型在训练集上的拟合能力
B. 通过添加惩罚项降低模型复杂度,控制过拟合
C. 直接优化验证集的准确率
D. 增加特征维度以提升模型表达能力 -
关于无监督学习,以下描述正确的是?
A. 需要预先标记数据类别
B. 主要功能是发现数据分布特点和离群样本
C. 适用于特征维度低的数据降维
D. 与监督学习的核心区别是模型复杂度更高 -
K-Means算法的核心缺点是什么?
A. 无法处理高维数据
B. 必须预先指定簇数量且对噪声敏感
C. 计算复杂度高达 O(n²)
D. 只能使用欧氏距离度量相似性 -
层次聚类中“凝聚方法”的特点是什么?
A. 从全数据集开始逐步分裂簇
B. 从单个对象开始逐步合并簇
C. 仅适用于凸形状的簇
D. 必须使用最长距离法度量簇间距离 -
DBSCAN算法中“核心点”的定义是?
A. 任意两个对象密度可达的点
B. Eps邻域内对象数不少于MinPts的点
C. 落在其他核心点邻域内的点
D. 与所有对象距离均小于Eps的点 -
轮廓系数(Silhouette Coefficient)的作用是?
A. 估计数据集的聚类趋势
B. 确定最佳簇数量
C. 衡量聚类结果的簇内紧凑度和簇间分离度
D. 计算聚类结果与真实标签的匹配度 -
神经网络的基本组成单元是什么?
A. 树突
B. 轴突
C. 神经元
D. 突触 -
感知机(Perceptron)的主要局限性是什么?
A. 只能处理线性可分问题
B. 训练效率过高导致过拟合
C. 适用于多分类任务
D. 基于支持向量机原理 -
BP神经网络中,反向传播算法的核心策略是什么?
A. 随机初始化权重
B. 基于梯度下降调整参数
C. 使用卷积运算优化
D. 仅依赖正向传播计算 -
深度学习中,卷积神经网络(CNN)的“权值共享”机制的主要作用是什么?
A. 增加网络参数数量以提高复杂度
B. 减少参数数量并保证特征识别一致性
C. 适用于序列数据处理
D. 加速梯度下降收敛 -
以下哪种神经网络最适合处理时间序列数据(如语音或股票预测)?
A. 多层感知机(MLP)
B. 卷积神经网络(CNN)
C. 生成对抗网络(GAN)
D. 循环神经网络(RNN)
二、判断题
-
离群点可以是合法的数据对象或者值。( )
-
关联规则挖掘过程是发现满足最小支持度的所有项集代表的规则。( )
-
K均值是一种产生划分聚类的基于密度的聚类算法,簇的个数由算法自动确定。( )
-
如果一个对象不属于任何簇,那么该对象是基于聚类的离群点。( )
-
数据挖掘的主要任务是从数据中发现潜在的规则,从而能更好地完成描述数据、预测数据等任务。( )
-
数据挖掘的目标不在于数据采集策略,而在于对已经存在的数据进行模式的发掘。( )
-
用于分类的离散化方法之间的根本区别在于是否使用类信息。( )
-
特征提取技术并不依赖于特定的领域。( )
-
定量属性可以是整数值或者是连续值。( )
-
利用先验原理可以帮助减少频繁项集产生时需要探查的候选项个数。( )
-
先验原理可以表述为:如果一个项集是频繁的,则包含它的所有项集也是频繁的。( )
-
分类和回归都可用于预测,分类的输出是离散的类别值,而回归的输出是连续数值。( )
-
贝叶斯法是一种在已知后验概率与类条件概率的情况下的模式分类方法,待分样本的分类结果取决于各类域中样本的全体。( )
-
分类模型的误差大致分为两种:训练误差和泛化误差。( )
-
在聚类分析当中,簇内的相似性越大,簇间的差别越大,聚类的效果就越差。( )
-
给定由两次运行K均值产生的两个不同的簇集,误差的平方和最大的那个应该被视为较优。( )
-
线性回归模型由于自身的局限性只能描述变量间的线性关系。( )
-
基于模型的聚类与基于分割的聚类相比,对数据分布有更好的描述性。( )
-
具有较高的支持度的项集具有较高的置信度。( )
-
可以利用概率统计方法估计数据的分布参数,再进一步估计待测试数据的概率,以此来实现贝叶斯分类。( )
-
数据库中某属性缺失值比较多时,数据清理可以采用忽略元组的方法。( )
-
逻辑回归等同于一个使用交叉熵loss,且没有隐藏层的神经网络。( )
-
分类和回归都可用于预测,分类的输出是连续数值,而回归的输出是离散的类别值。( )
-
皮尔逊相关系数可用来判断X和Y之间的因果关系。( )
-
样品是数据对象的别名。( )
-
杰卡德系数用来度量非对称的二进制属性的相似性。( )
-
K均值聚类的核心目标是将给定的数据集划分为K个簇,并给出每个数据对应的簇中心点。( )
-
离散属性总是具有有限个值。( )
-
聚类是这样的过程:它找出描述并区分数据类或概念的模型(或函数),以便能够使用模型预测类标记未知的对象类。( )
-
K-Means++能够解决初始点影响聚类效果的问题。( )
-
聚类分析可以看作一种非监督的分类。( )
-
Python中,元组(Tuple)和字符串(String)都属于不可变数据类型。( )
-
NumPy的广播机制(broadcasting)要求参与运算的两个数组必须具有完全相同的形状。( )
-
Pandas的DataFrame数据结构可以看作是由多个共用同一个索引的Series组成的字典。( )
-
Scikit-learn主要支持传统机器学习算法(如SVM、随机森林),不支持深度学习算法。( )
-
序数属性的取值之间具有明确的数值差。( )
-
混合类型属性的相似性度量需先对每种属性类型单独标准化。( )
-
维(Dimension)、特征(Feature)和属性(Attribute)在数据挖掘中可互换使用。( )
-
均值对噪声数据敏感,而中位数对噪声数据的鲁棒性更强。( )
-
序数属性可计算算术均值以度量中心趋势。( )
-
散点图属于几何投影可视化技术,可展示二维数据分布。( )
-
混合类型属性的相似性计算需对所有属性统一标准化后再度量。( )
-
数据预处理的必要性源于现实世界数据常存在噪声、缺失和不一致问题,高质量数据需满足准确性、完整性和一致性。( )
-
在数据归约中,“维归约”通过抽样技术减少数据量,例如用随机子集代表整体数据集。( )
-
多项式回归可以通过增加高次项拟合非线性数据,但可能导致过拟合。( )
-
岭回归通过加入L1正则项剔除不重要的自变量,解决多重共线性问题。( )
-
在变量选择中,逐步回归法通过统计指标(如R²、AIC)自动添加或删除自变量。( )
-
关联规则的支持度反映规则的有用性,置信度反映规则的确定性。( )
-
极大频繁项集(Maximal Frequent Itemset)一定是闭频繁项集(Closed Itemset)。( )
-
Apriori算法在挖掘k项频繁集时,需要扫描数据库k次。( )
-
FP-growth算法在挖掘过程中不需要生成候选项集。( )
-
提升度(Lift)> 1 表示规则中的项集具有正相关性。( )
-
在决策树剪枝中,后剪枝方法先构建完整决策树,再自底向上进行剪枝。( )
-
SVM处理非线性数据时,必须显式计算高维映射后的特征向量。( )
-
k-折交叉验证中,当k等于样本总量时称为简单交叉验证。( )
-
袋装(Bagging)方法中,每个基分类器的投票权重根据其准确率动态调整。( )
-
随机森林的Forest-RI方法通过属性线性组合创建新特征进行分裂。( )
-
K-means++算法通过随机选择初始中心点,避免收敛到局部最优解。( )
-
在层次聚类中,“类平均法”以两类中心点的距离作为簇间距离。( )
-
DBSCAN算法能有效识别任意形状的簇,但对参数Eps和MinPts敏感。( )
-
模糊C均值聚类(FCM)要求每个数据点严格属于单一簇。( )
-
霍普金斯统计量(Hopkins statistic)接近0.5时,表明数据具有显著聚类趋势。( )
-
神经网络可以用于分类任务和数值预测任务。( )
-
BP神经网络的训练效率高且收敛速度快,适合大规模数据场景。( )
-
深度学习模型参数越多,模型复杂度越高,但大数据可以降低过拟合风险。( )
-
生成对抗网络(GAN)的训练依赖于生成模型和判别模型的相互博弈。( )
-
卷积神经网络(CNN)的池化层主要用于增加特征图的维度以提升精度。( )
三、简答题
-
基于正态分布的离群点检测
假设某城市过去10年中7月份的平均温度按递增序排列,结果为24℃、28.9℃、28.9℃、29℃、29.1℃、29.1℃、29.2℃、29.2℃、29.3℃和29.4℃。假定平均温度服从正态分布,由两个参数决定:均值和标准差。假设数据分布在这个区间(以平均值标准差为区间)之外,该数据对象即为离群点。
(1)利用最大似然估计求均值和标准差。
(2)寻找上述10个对象中的所有离群点。 -
研究学习时间( x x x,小时)与考试成绩( y y y,分)的关系。现有5组样本数据:
| x x x | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| y y y | 50 | 60 | 70 | 80 | 90 |
(1)参数估计:用最小二乘法求回归方程 y = β 0 + β 1 x y=β_0+β_1x y=β0+β1x的系数 β 0 β_0 β0和 β 1 β_1 β1(给出计算过程)。
(2)预测:若学习时间 x x x=6 小时,预测考试成绩 y y y。
(3)拟合优度:计算判定系数 R 2 R^2 R2。
-
预测房价( y y y,万元)与房屋面积( x 1 x_1 x1,㎡)和房龄( x 2 x_2 x2,年)的关系。回归模型为: y = β 0 + β 1 x 1 + β 2 x 2 + ϵ y=β_0+β_1x_1+β_2x_2+ϵ y=β0+β1x1+β2x2+ϵ
已知正规方程组的解为:
{ β 0 = 50 β 1 = 0.8 β 2 = − 2 \left\{{\begin{matrix}β_0=50\\β_1=0.8\\β_2=-2\\\end{matrix}}\right. ⎩ ⎨ ⎧β0=50β1=0.8β2=−2
问题:
(1)预测:求面积 x 1 x_1 x1=100㎡、房龄 x 2 x_2 x2=5年的房价预测值 y y y。
(2)系数解释:说明 β 1 β_1 β1=0.8 和 β 2 β_2 β2=-2 的实际意义。
(3)共线性问题:若 x 1 x_1 x1与 x 2 x_2 x2的相关系数为0.95,对模型有何影响?应如何处理? -
Apriori算法在数据挖掘中被广泛使用,已知有5000名球迷看奥运会,看乒乓球比赛和看篮球比赛的人数分别如下表所示:
| 看乒乓球 | 没看乒乓球 | 合计(行) | |
|---|---|---|---|
| 看篮球 | 2000 | 1750 | 3750 |
| 没看篮球 | 1000 | 250 | 1250 |
| 合计(列) | 3000 | 2000 | 5000 |
计算“”的支持度比例(Support)、置信度比例(Confidence)、提升度(Lift)。
-
事务数据库(min_sup=40%):
T1: {A, B, C}
T2: {A, B, D}
T3: {A, C}
T4: {B, C}
T5: {A, B}
(1)列出所有频繁1项集和频繁2项集(支持度用分数表示)。
(2)判断项集{A,B}是否为闭频繁项集,并说明理由。
(3)找出极大频繁项集(需写出推理过程)。 -
事务数据库(min_sup=50%):
T1: {牛奶, 面包}
T2: {面包, 尿布}
T3: {牛奶, 尿布}
T4: {面包, 牛奶, 尿布}
T5: {牛奶}
(1)写出Apriori算法求解频繁项集的过程(从L₁到L₃,需包含连接、剪枝步骤)。
(2)若最小置信度为75%,从频繁项集{牛奶, 面包}生成关联规则,并计算规则置信度。 -
事务数据库(min_sup=40%):
T1: {A, B, C}
T2: {A, C}
T3: {A, D}
T4: {B, C, E}
(1)按支持度降序排列项,并画出FP树结构(需包含项头表)。
(2)求项C的条件模式基,并基于此推导C的频繁项集。 -
给定规则:牛奶 → 尿布,统计信息如下:
支持度(牛奶, 尿布) = 0.4
支持度(牛奶) = 0.6
支持度(尿布) = 0.5
(1)计算规则置信度。
(2)计算提升度(Lift),并解释其意义。
(3)若提升度=1.2,说明该规则是否有意义?为什么? -
认识数据
假设描述学生的信息包含以下属性:性别,籍贯,年龄。记录,和,的信息如下,分别求出记录和簇彼此之间的距离。

-
已知:训练集合中垃圾邮件的比例为P(h+)=0.2;训练集合中正常邮件的比例为P(h-)=0.8;单词出现频率表如下:
| 分词 | 在垃圾邮件中出现的比例 | 在正常邮件中出现的比例 |
|---|---|---|
| 免费 | 0.3 | 0.01 |
| 奖励 | 0.2 | 0.01 |
| 网站 | 0.2 | 0.2 |
求解:判断一封邮件D=<“免费”“奖励”“网站”>是否是垃圾邮件?
- 假设正常对象被分类为离群点的概率是0.01,而离群点被分类为离群点概率为0.99,如果99%的对象都是正常的,那么检测率和假警告率各为多少?(使用下面的定义)
检测率=检测出的离群点个数/离群点的总数
假警告率=假离群点个数/被分类为离群点的个数
- 从某超市顾客中随机抽取5名,他们的购物篮数据的二元0/1表示如下:
| 顾客号 | 面包 | 牛奶 | 尿布 | 啤酒 | 鸡蛋 | 可乐 |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 1 | 1 | 1 | 0 |
| 3 | 0 | 1 | 1 | 1 | 0 | 1 |
| 4 | 1 | 1 | 1 | 1 | 0 | 0 |
| 5 | 1 | 1 | 1 | 0 | 0 | 1 |
某学生依据这些数据做关联分析,考虑规则{牛奶,尿布}→{啤酒},请计算该规则的支持度(support)、置信度(confidence)。
-
相异性计算
给定两个元组(22,1,42,10)和(20,0,36,8):
(1)计算这两个对象之间的欧几里得距离。
(2)计算这两个对象之间的曼哈顿距离。
(3)使用 p = 3 p=3 p=3,计算这两个对象之间的闵可夫斯基距离。
(4)计算这两个对象之间的上确界距离。 -
对于数据:{12,9,7,6,20,100,35,21,11,18,25,37},完成以下任务:
(1)计算它的平均值,20%的截断均值和中位数,并说明这三个统计特征在描述数据集方面的特点。
(2)使用最小-最大规范方法将其中的6,100,35转换到[0,1]。
(3)对数据按照深度为4进行划分,再写出按边界值进行平滑后的结果。 -
假设我们手上有60个正样本,40个负样本,我们要找出所有的正样本,系统查找出50个,其中只有40个是真正的正样本,计算上述各指标。
请计算:
(1)TP(将正类预测为正类数)
(2)FN(将正类预测为负类数)
(3)FP(将负类预测为正类数)
(4)TN(将负类预测为负类数)
(5)准确率(accuracy)
(6)精确率(precision)
(7)召回率(recall) -
(1) 给定二分类混淆矩阵:
TP=40, FP=10, FN=20, TN=30
计算准确率(Accuracy)、召回率(Recall)和F1值(F1-score)。
(2) 简述ROC曲线的绘制步骤,并解释AUC的含义。
(3) 什么是过拟合?在决策树中如何防止过拟合?
(4) 现有数据集采用5折交叉验证:
描述第2折的训练集和验证集如何划分。
为什么交叉验证可以用于模型选择? -
证明反向传播公式
已知条件:
神经网络结构:输入层 → 隐藏层(第 l l l 层)→ 输出层(第 k k k 层)
激活函数:Sigmoid ,其导数 σ ′ ( z ) = σ ( z ) ( 1 − σ ( z ) ) \sigma'(z) = \sigma(z)(1-\sigma(z)) σ′(z)=σ(z)(1−σ(z))
损失函数:均方误差 L = 1 2 ( y − y ^ ) 2 L = \frac{1}{2}(y - \hat{y})^2 L=21(y−y^)2,其中 y ^ \hat{y} y^ 为输出层预测值, y y y 为真实标签
符号定义:
z j ( l ) z_j^{(l)} zj(l):第 l l l 层神经元 j j j 的预激活值(加权输入)
a j ( l ) a_j^{(l)} aj(l):第 l l l 层神经元 j j j 的激活输出
w i j ( l ) w_{ij}^{(l)} wij(l):连接第 l l l 层神经元 j j j 与第 l + 1 l+1 l+1 层神经元 i i i 的权重
δ j ( l ) \delta_j^{(l)} δj(l):输出层误差项
待证明公式:
隐藏层误差项满足: δ j ( l ) = σ ′ ( z j ( l ) ) ∑ i w i j ( l ) δ i ( l + 1 ) \delta_j^{(l)} = \sigma'(z_j^{(l)}) \sum_{i} w_{ij}^{(l)} \delta_i^{(l+1)} δj(l)=σ′(zj(l))∑iwij(l)δi(l+1)
四、应用题
-
给定圆的半径为 ϵ \epsilon ϵ,令MinPts=3,考虑下面两幅图,以 ϵ \epsilon ϵ 为例。
(题目中未明确图示内容,保留原题格式)
(1)哪些对象是核心对象?
(2)哪些对象是直接密度可达的?
(3)哪些对象是密度可达的?
(4)哪些对象是密度相连的?
(5) 假设给定一个非空二维数据点集P,给定圆的半径为 ϵ \epsilon ϵ,MinPts=3,使用python实现基于密度的聚类算法,需给出具体的算法步骤。 -
数据集:给定二维数据集,需划分为 k k k 个簇。初始聚类中心为 C 1 C_1 C1 和 C 2 C_2 C2。目标:完成一次完整的K-means迭代(分配数据点 + 更新中心)。
(1)K-means算法的核心步骤是什么?需说明迭代终止条件。
(2)计算点到聚类中心的欧氏距离。
(3)判断以下说法是否正确并说明理由:
“K-means对初始中心敏感,可能陷入局部最优;轮廓系数可评估聚类质量,其值越接近1表示聚类效果越好。”
(4)假设分配后,簇1包含点集 S 1 S_1 S1,簇2包含点集 S 2 S_2 S2。求更新后的聚类中心 C 1 ′ C_1' C1′ 和 C 2 ′ C_2' C2′ 的坐标表达式。
(5)Python实现K-Means聚类代码。 -
对于如下的前馈神经网络,假设现在有一个训练样本, x 1 = 1 x_1=1 x1=1, x 2 = 0 x_2=0 x2=0, x 3 = 1 x_3=1 x3=1,其对应的类标号(标签)为1,节点4、5、6的激活函数为sigmoid函数,结构如下图所示:(p279)
(题目中未明确图示内容,保留原题格式)
网络的初始输入、权值( w w w)和偏置值(4、5、6节点分别为 b 4 b_4 b4、 b 5 b_5 b5、 b 6 b_6 b6)如下表所示:
| x 1 | x 2 | x 3 | w 14 | w 15 | w 24 | w 25 | w 34 | w 35 | w 46 | w 56 | θ 4 | θ 5 | θ 6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 0.2 | -0.3 | 0.4 | 0.1 | -0.5 | 0.2 | -0.3 | -0.2 | -0.4 | 0.2 | 0.1 |
(1)请计算节点4、5、6的净输入和输出。
(2)请计算节点4、5、6的误差。
(3)假设学习率为0.9,请计算上表中所有权值和偏置的一次更新。
(4)请问什么是梯度消失?
(5)请使用Python实现批量梯度下降法算法,先给出具体的算法步骤,再给出相应的代码。
- 前馈神经网络
网络结构:
输入层:2个神经元(输入 x 1 , x 2 x_1, x_2 x1,x2)
隐藏层:2个神经元(激活函数为 Sigmoid)
输出层:1个神经元(激活函数为 Sigmoid)
参数:
输入层→隐藏层权重 W ( 1 ) W^{(1)} W(1),偏置 b ( 1 ) b^{(1)} b(1)
隐藏层→输出层权重 W ( 2 ) W^{(2)} W(2),偏置 b ( 2 ) b^{(2)} b(2)
损失函数:均方误差 L = 1 2 ( y − y ^ ) 2 L = \frac{1}{2}(y - \hat{y})^2 L=21(y−y^)2( y y y 为真实标签, y ^ \hat{y} y^ 为预测输出)。
(1)前馈神经网络的信息流动方向是什么?隐藏层和输出层的激活函数分别起什么作用?
(2)给定输入样本 ( x 1 , x 2 ) (x_1, x_2) (x1,x2),求隐藏层神经元的净输入 z ( 1 ) z^{(1)} z(1)、激活输出 a ( 1 ) a^{(1)} a(1) 及输出层神经元的净输入 z ( 2 ) z^{(2)} z(2)、最终输出 y ^ \hat{y} y^ 的表达式。
(3)判断以下说法是否正确并说明理由:
“前馈神经网络因信息单向传播,无法处理序列数据(如时间序列预测)。”
(4) 假设前向传播后得到输出 y ^ \hat{y} y^,真实标签为 y y y。推导输出层误差项 δ ( 2 ) \delta^{(2)} δ(2) 和隐藏层误差项 δ ( 1 ) \delta^{(1)} δ(1) 的表达式(需写出链式法则过程)。
(5) 将上述前馈神经网络的代码使用python代码实现。
相关文章:
SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...