突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解到策略的最优解。现有的主流强化学习算法,包括A3C、TRPO、PPO、DSAC、DACER等,均使用这一机制进行求解,即需要对控制策略进行“一阶求导”,然后采用梯度下降原理更新策略的参数[1]。
然而,工业控制领域中,大量控制策略不具备“可导性”,这成为限制强化学习技术广泛应用的瓶颈难题。以两个典型场景为例:(1)当使用“有限状态机”或“决策树”为策略载体时,这类规则型策略导致系统运行状态不断跳转,决策动作呈现阶跃特性,就不具备可导性;(2)以“模型预测控制器”为核心的闭环控制系统中,控制动作是通过在线求解优化问题得到的,期间需经过多轮迭代计算,导致难以显式给出策略输出与策略参数之间的导数关系。对于这类控制策略的参数学习,长期以来都是研究者们亟待解决的难题。
让我们先看看机器学习领域怎么解决这一问题呢?当策略不可导的情形下,现有文献通常应用“零阶优化(Zeroth-Order Optimization)”方法。以典型零阶优化方法进化策略(Evolutionary strategies, ES)为例,在每一轮迭代中,当前策略 π μ \pi_\mu πμ在参数空间添加噪声进行探索。每个加噪策略 π θ i \pi_{\theta_i} πθi在环境中采样,得到单条轨迹的回合回报 R ( π θ i ) R(\pi_{\theta_i}) R(πθi),其中参数 θ i \theta_i θi在整条轨迹中保持不变。通过对噪声样本进行加权平均,就可以估计策略参数的“零阶梯度”:
∇ μ J ^ E S = ∑ i = 1 n R ( π θ i ) Σ − 1 ( θ i − μ ) \nabla_\mu\hat{J}_\mathrm{ES}=\sum_{i=1}^nR(\pi_{\theta_i})\Sigma^{-1}(\theta_i-\mu) ∇μJ^ES=i=1∑nR(πθi)Σ−1(θi−μ) 其中, n n n为单次迭代的样本数。公式(1)的这一想法是比较简单明了的,但是将其直接用于强化学习是否有效呢?
从梯度形式可以看出,梯度估计方差与噪声采样数量密切相关:(1)当 n n n很小时,估计值的方差会变得非常大而使学习过程不稳定;(2)当 n n n较大时,因为准确估计回报 R R R需要采样整条轨迹,导致每一轮交互的步数急剧增加,让训练效率急剧降低。对于强化学习问题而言,每一步的样本数据都是重新采集的,通常数量是比较少的,这使得梯度计算过程更加糟糕,甚至导致训练过程发散,不能收敛至最优解。这就是零阶强化学习方法固有的“样本效率”与“梯度方差”的平衡困境。针对这一难题,清华大学李升波教授课题组提出了完全依赖“零阶梯度”的高性能强化学习算法(Zeroth-Order Actor-Critic, ZOAC),通过实施逐时间步的参数空间加噪探索以及策略参数扰动的优势函数估计,破解了零阶强化学习算法易失稳,难求解的挑战,为有限状态机、决策树、规则化控制律等策略的训练提供了全新的工具[2][3]。
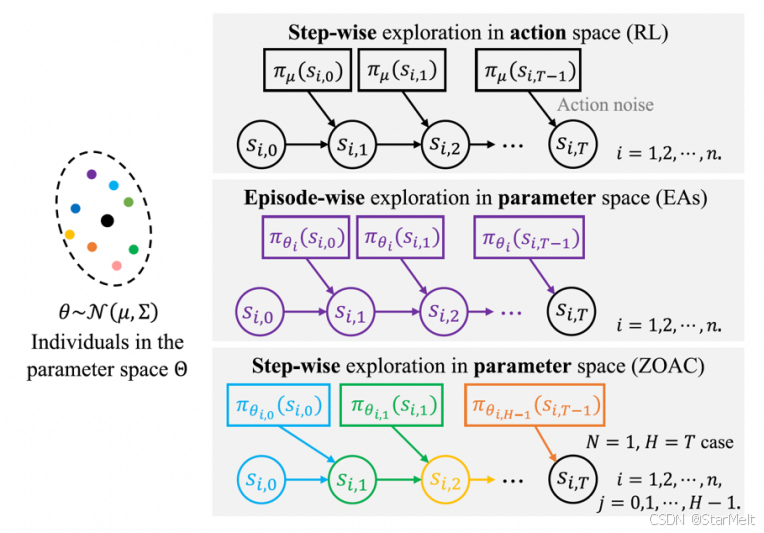
首先,为了解决样本效率和梯度方差的权衡问题,并充分提高学习过程中的探索能力,团队提出采用逐时间步的参数空间加噪探索策略 β μ , Σ \beta_{\mu,\Sigma} βμ,Σ,其中 μ \mu μ和 Σ \Sigma Σ分别为高斯噪声的均值和协方差矩阵,如图1所示。研究进一步推导了以最大化期望累计折扣奖励 J ( μ , Σ ) = E s ∼ d 0 v β μ , Σ ( s ) J(\mu,\Sigma)=\mathbb{E}_{s\sim d_{0}}v^{\beta_{\mu,\Sigma}}(s) J(μ,Σ)=Es∼d0vβμ,Σ(s)为目标的零阶策略梯度。实际算法可以通过采样求均值来近似期望值得到策略梯度的估计值:
∇ μ J ^ Z O A C = 1 n H ∑ i = 1 n ∑ j = 0 H − 1 ∑ k = 0 N − 1 ( γ λ ) k ( r i , j N + k + γ v i , j N + k + 1 β − v i , j N + k β ) Σ − 1 ( θ i , j − μ ) \nabla_\mu\hat{J}_\mathrm{ZOAC}=\frac1{nH}\sum_{i=1}^n\sum_{j=0}^{H-1}\sum_{k=0}^{N-1}(\gamma\lambda)^k\left(r_{i,jN+k}+\gamma v_{i,jN+k+1}^\beta-v_{i,jN+k}^\beta\right)\Sigma^{-1}(\theta_{i,j}-\mu) ∇μJ^ZOAC=nH1i=1∑nj=0∑H−1k=0∑N−1(γλ)k(ri,jN+k+γvi,jN+k+1β−vi,jN+kβ)Σ−1(θi,j−μ) 其中, n n n同样为每次迭代采样的轨迹数量,在单条轨迹中先后采样 H H H个带参数噪声的策略,每个策略向前执行 N N N步, λ \lambda λ为权衡偏差及方差的超参数。式(2)与式(1)的形式相似,梯度通过噪声向量的加权平均得到,规避了对策略端到端求导的需求,保证了方法的泛用性。然而区别在于,每个受扰策略仅与环境交互 N N N步,远远小于整条轨迹的长度。 对于参数空间中的每个噪声向量 θ i , j \theta_{i,j} θi,j,利用序贯决策问题的Markov属性估计了其优势函数 r i , j N + k + γ v i , j N + k + 1 β − v i , j N + k β r_{i,jN+k}+\gamma v_{i,jN+k+1}^{\beta}-v_{i,jN+k}^{\beta} ri,jN+k+γvi,jN+k+1β−vi,jN+kβ,作为轨迹总体回报值 R ( π θ i , j ) R\left(\pi_{\theta_{i,j}}\right) R(πθi,j)的高效而准确的替代。这与主流强化学习方法中对输出动作的优势函数有所区别,在策略参数空间中进行估计保证了与零阶优化迭代机制的深度融合。对理论分析表明,相同环境交互步数的前提下,ZOAC方法所估计的梯度在保证无偏的同时有着更低的方差,有利于提高策略训练速度和稳定性。
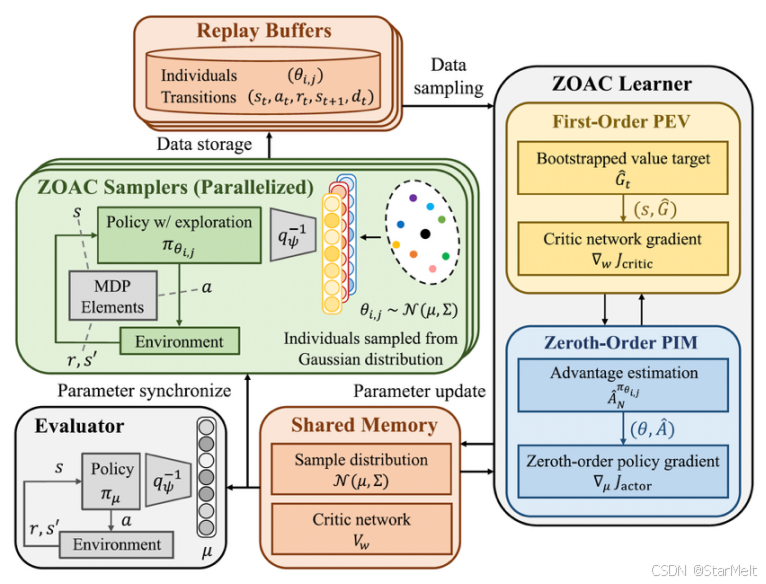
以此为基础,设计了如图2所示的适用于不可导策略的强化学习算法框架。学习器负责对策略进行迭代更新,主要包含两个交替执行的部分:(1)一阶策略评估(First-Order Policy Evaluation, PEV),算法引入值函数网络 V ( s ; w ) V(s; w) V(s;w)以近似状态值函数 v β ( s ) v^\beta(s) vβ(s)。根据经验池的状态经验样本,通过自举法估计状态价值目标,并通过最小化值函数网络输出值与状态价值目标的均方误差(Mean Squared Error, MSE)对网络参数 w w w执行更新;(2)零阶策略改进(Zeroth-Order Policy Improvement, PIM),根据采集到的轨迹片段,依托值函数网络对式(2)中的状态价值 v β v^\beta vβ进行近似估计,然后基于优势函数对策略参数的扰动方向进行加权平均,最终通过梯度上升更新策略参数 μ \mu μ。

综上所述,本研究针对现有静态零阶优化方法探索能力受限、学习效率低下的难题,提出了零阶强化学习方法ZOAC,结合了逐时间步的参数空间加噪探索方法,推导了考虑序贯决策问题Markov属性的零阶策略梯度,引入了策略参数扰动方向的优势函数以降低策略梯度估计方差,并进一步融合二元交替迭代求解架构,通过充分利用问题本身的时序结构加速策略训练过程。以此为基础,依托分布式计算框架搭建了决控策略的强化学习训练系统,并应用于规则型自动驾驶决控策略训练,验证了所提方法的可行性和有效性。
参考文献
[1]Li S E. Reinforcement learning for sequential decision and optimal control[M]. Singapore: Springer Verlag, 2023.
[2]Lei Y, Lyu Y, Zhan G, et al. Zeroth-Order Actor-Critic: An Evolutionary Framework for Sequential Decision Problems[J]. IEEE Transactions on Evolutionary Computation, 2025, 29(2). 555-569.
[3]Lei Y, Chen J, Li S E, et al. Performance-Driven Controller Tuning via Derivative-Free Reinforcement Learning[C]//2022 IEEE 61st Conference on Decision and Control (CDC). IEEE, 2022: 115-122.
相关文章:
突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...