未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主@一点人工一点智能

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准确性和鲁棒性。![]() https://mp.weixin.qq.com/s/JztOQLpMRD1OueApQgISWg论文提出了名为RWM(Robotic World Model)的新型世界模型框架,通过双自回归机制和自我监督训练,解决了机器人控制中长期预测、误差累积和部分可观测性等核心挑战。文章将从摘要与引言、相关工作、方法框架、实验验证、局限性与结论等维度进行系统分析,重点剖析其技术创新点与实验设计,并评估其对机器人学与强化学习领域的贡献。通过这种结构化解读,我们将揭示该研究如何通过世界模型的精准预测与稳健策略优化,缩小仿真与现实间的鸿沟,为机器人控制提供新的解决方案。
https://mp.weixin.qq.com/s/JztOQLpMRD1OueApQgISWg论文提出了名为RWM(Robotic World Model)的新型世界模型框架,通过双自回归机制和自我监督训练,解决了机器人控制中长期预测、误差累积和部分可观测性等核心挑战。文章将从摘要与引言、相关工作、方法框架、实验验证、局限性与结论等维度进行系统分析,重点剖析其技术创新点与实验设计,并评估其对机器人学与强化学习领域的贡献。通过这种结构化解读,我们将揭示该研究如何通过世界模型的精准预测与稳健策略优化,缩小仿真与现实间的鸿沟,为机器人控制提供新的解决方案。
01 简介
论文提出了一种能够准确捕捉复杂、部分可观测和随机动力学的新型世界模型学习框架。该方法通过双自回归机制和自我监督训练,实现了不依赖领域特定归纳偏见的可靠长期预测,从而确保了跨多样化机器人任务的适应性。论文特别指出了该方法在"长时程预测"、"误差累积"和"仿真到现实迁移"三大挑战上的突破,这些问题正是当前基于模型的强化学习(MBRL)领域面临的主要瓶颈。
技术贡献被归纳为三个方面:
· 创新的网络架构与训练框架
· 涵盖多样化机器人任务的综合评估套件
· 利用学习到的世界模型进行高效策略优化的框架

引言部分系统性地构建了研究问题的背景与动机。作者首先指出当前机器人系统普遍存在的关键局限:策略部署后的适应能力不足,导致无法充分利用真实世界交互产生的宝贵数据。这种局限性在动态不确定环境中尤为突出,严重制约了系统的鲁棒性和应对场景变化的能力。通过对比模型自由RL方法(如PPO和SAC)与基于模型的方法,文章有力论证了样本高效的世界模型在真实机器人应用中的必要性——模型自由方法虽然在高保真仿真中表现优异,但其高昂的交互成本使其难以应用于现实场景。
引言中对世界模型的讨论尤为深入,将其定位为环境预测模型,能够通过"想象中学习"实现规划与策略优化。作者客观评价了现有方法的不足:大多数工作通过引入领域特定的归纳偏见(如结构化状态表示或手工设计的网络架构)来提高模型保真度,这种做法虽然有效但牺牲了方法的通用性和可扩展性。相比之下,本文提出的RWM框架强调在不依赖手工设计表示或专门架构偏见的条件下,实现长期预测的鲁棒性和准确性。这是首个完全无需领域特定知识、仅依靠学习到的神经网络模拟器训练策略并成功部署到物理硬件上的框架,且性能损失最小,这一主张在后续实验部分得到了充分验证。
02 相关工作
论文对世界模型和基于模型的强化学习(MBRL)领域进行了系统性梳理,展现了作者对研究领域的全面把握。在世界模型方面,文献回顾从两个维度展开:应用领域与模型设计方法。
应用上,作者指出世界模型已成为机器人学中捕捉系统动力学、实现高效规划与控制的基石,具体应用涵盖机器人控制、基于视觉的任务以及需要丰富感知输入的任务。
模型设计方法上,文献重点对比了黑盒神经网络与融合物理原理的设计思路,前者灵活性高但泛化能力受限,后者性能优异但需要大量领域知识,这种二元对立恰恰凸显了RWM框架的创新价值——在不引入领域特定归纳偏见的前提下实现良好的泛化能力。
作者对潜在空间动力学模型的讨论尤为深入,以Deep Planning Network(PlaNet)和Dreamer系列工作为例,展示了这类方法在连续控制和视觉导航任务中的卓越性能。这些框架通过将状态空间抽象为紧凑表示,实现了高效的长期规划,并已成功扩展到真实机器人部署中。文献还特别提到将已知物理结构(如刚体动力学、半结构化拉格朗日动力学模型)融入模型设计的方法,这些工作虽然展示了令人印象深刻的结果,但需要强大的领域知识和精心设计的归纳偏见,这自然引出了本文工作的动机——开发更通用的框架。
在MBRL部分,论文从方法演进的角度进行了梳理,从早期PETS(使用概率神经网络集合建模环境动力学)到PlaNet(在学习的潜在空间中直接规划),再到Dreamer(将actor-critic框架整合到潜在动力学模型中)。这种历时性回顾清晰地展示了MBRL领域的技术发展路径。作者特别强调了混合方法的价值,如MBPO(基于模型的方法用于规划和策略优化,但使用模型自由更新细化策略)和MOPO(扩展到完全离线设置)。这些方法试图结合基于模型方法的样本效率和模型自由方法的鲁棒性,而本文提出的MBPO-PPO框架正是沿袭了这一思路但有所创新。
值得注意的是,相关工作中对梯度优化方法的讨论(如SHAC)为后续实验部分的对比埋下了伏笔。这些方法通过世界模型传播梯度来优化策略,允许在复杂高维环境中进行更精确的策略更新,但在处理不连续动力学(如腿部运动中的接触变化)时面临挑战。整个相关工作章节不仅展示了作者对领域的深刻理解,更通过精准的文献选择和组织,构建起本文工作的创新背景和技术定位。
03 方法框架
3.1 问题表述与基础理论
论文第三章"Approach"系统性地阐述了RWM的方法框架,首先从理论基础上将环境建模为部分可观测马尔可夫决策过程(POMDP),定义为元组(S,A,O,T,R,O,γ),其中S、A和O分别表示状态、动作和观测空间。这种形式化表述明确了问题的数学边界,特别是通过观测函数O:S→O显式处理了部分可观测性这一关键挑战。值得注意的是,作者采用了非标准符号O表示观测函数(通常记为Ω),这可能是为了与观测空间O区分,但需要在阅读时特别注意。
世界模型的核心任务是近似环境动力学,即学习,通过在"想象"中实现模拟环境交互来促进策略优化。论文清晰地勾勒出典型训练流程的三个迭代步骤:
(1)从真实环境交互收集数据;
(2)使用收集的数据训练世界模型;
(3)在世界模型产生的模拟环境中优化策略。
这种循环框架反映了Dyna算法的核心思想,但作者指出现有方法在复杂低级别机器人控制应用中仍面临重大挑战,由此引出RWM的创新价值。
RWM通过历史上下文和自回归训练的引入,专门针对部分可观测和不连续动力学环境中的误差累积等挑战进行了优化。与传统世界模型相比,RWM的独特之处在于其双自回归机制——既在训练阶段通过历史观测-动作序列进行条件预测,又在预测阶段将自身预测反馈回模型以实现长期推演。这种双重机制使模型能够捕获不可观测的动力学特征,同时减轻长期预测中的误差累积问题。
3.2 自监督自回归训练机制
RWM的核心创新之一是其自监督自回归训练框架,该框架使世界模型能够通过利用历史观测-动作序列及其自身预测来预测未来观测。具体实现上,模型输入包含跨越M个历史步骤的观测-动作对序列,在每个时间步t预测下一个观测的分布
。预测以自回归方式生成:每一步的预测观测
被追加到历史记录中,与下一个动作at+1组合作为后续预测的输入。这个过程在N步的预测范围内重复,产生未来预测序列。
数学上,k步前的预测观测可表示为:
![]()
这种公式化表达清晰地展现了自回归预测的马尔可夫性质,其中每个预测步骤都依赖于有限的历史窗口和先前的预测。值得注意的是,类似的流程也被应用于预测特权信息c(如接触信息),这提供了额外的学习目标,隐式嵌入了准确长期预测所需的关键信息。
训练目标函数设计体现了对长期预测稳定性的考量:
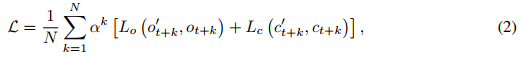
其中和
量化预测与真实观测及特权信息间的差异,α表示衰减因子。这种多步预测误差的加权和设计具有双重目的:一方面通过
的指数衰减减轻远期预测的梯度影响,另一方面强制隐藏状态编码支持准确长期预测的表示。数据构建采用在收集的轨迹上滑动大小为M+N的窗口的方法,为预测目标提供足够的历史上下文。

论文详细解释了重参数化技巧的应用,这使得端到端优化能够有效通过自回归预测传播梯度。通过纳入历史观测,RWM能够捕获不可观测的动力学,解决了部分可观测和潜在不连续环境中的挑战。与常用的teacher-forcing训练范式(图2b)相比,这种自回归训练(图2a)显著减轻了长期预测中的误差累积,同时消除了对手工设计表示或领域特定归纳偏见的依赖,增强了跨多样化任务的泛化能力。
3.3 双自回归网络架构
虽然提出的自回归训练框架可应用于任何网络架构,但RWM选择了GRU基础结构,因其能够在处理低维输入的同时保持长期历史上下文。网络预测描述下一个观测的高斯分布的均值和标准差,这种概率输出形式有助于捕捉环境的内在随机性。
RWM的创新架构体现为双自回归机制:
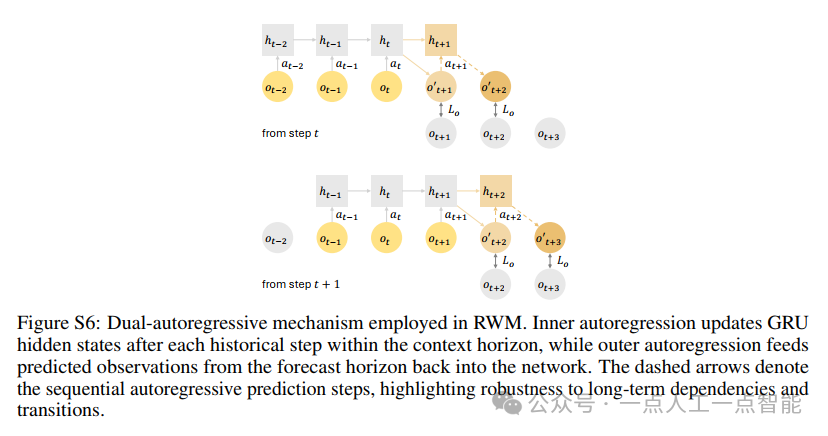
(1)内部自回归在上下文视界M内的每个历史步骤后自回归更新GRU隐藏状态;
(2)外部自回归将来自预测视界N的预测观测反馈回网络。
这种设计(图S6)确保了对长期依赖和转换的鲁棒性,使RWM适用于复杂的机器人应用。值得注意的是,这种双机制架构与传统的递归神经网络有本质区别——它不仅通过时间递归传递状态,还显式管理历史上下文窗口和预测反馈路径,形成了更为复杂的记忆系统。
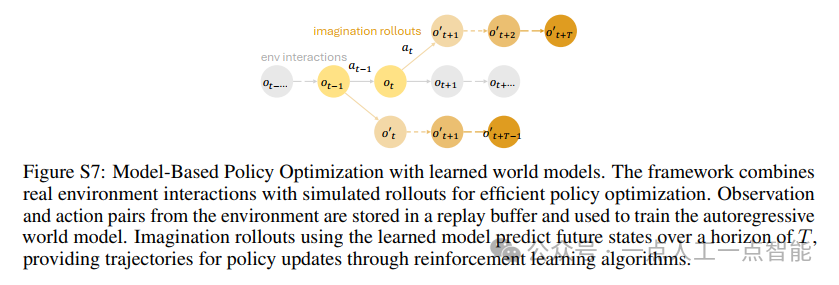
3.4 基于世界模型的策略优化
RWM中的策略优化采用学习到的世界模型,遵循受MBPO和Dyna算法启发的框架。在想象过程中,动作由策略πθ递归生成,条件是世界模型pϕ预测的观测,而世界模型又条件于先前的预测。时间t+k的动作可表示为:
![]()
其中根据公式(1)自回归地从分布中抽取。这种方法结合了基于模型的想象与模型自由强化学习,实现了高效稳健的策略优化,如算法1所述。

回放缓冲区D聚合由单个智能体收集的真实环境交互。世界模型pϕ按照3.2节描述的自回归方案在这些数据上进行训练。想象智能体从D中的样本初始化,并使用世界模型模拟T步的轨迹,通过强化学习算法实现策略更新。训练示意图见图S7。
论文特别讨论了PPO在 learned world models上训练的独特挑战。模型不准确性可能在策略学习过程中被利用,导致想象动态与真实动态间的差异。这个问题因PPO所需的扩展自回归推演而加剧,会放大预测误差。作者将这种方法称为MBPO-PPO,并强调RWM能够成功地通过MBPO-PPO优化超过100个自回归步骤的策略,远超MBPO、Dreamer或TD-MPC等现有框架的能力。这一结果证明了所提训练方法的准确性和稳定性,以及其在硬件上合成可部署策略的能力。
04 实验验证
4.1 自回归轨迹预测评估
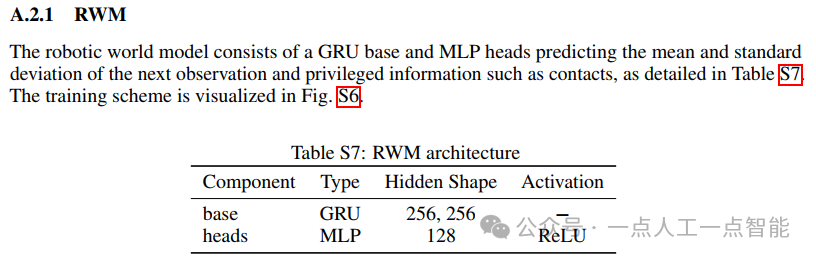
论文第四章"Experiments"通过一系列精心设计的实验验证RWM的有效性。在自回归轨迹预测评估中,作者使用ANYmalD硬件收集的轨迹分析RWM的自回归预测性能,控制频率设为50Hz。模型采用历史视界M=32和预测视界N=8进行训练,网络架构和训练参数的细节分别总结在附录A.2.1和A.3.1节中。
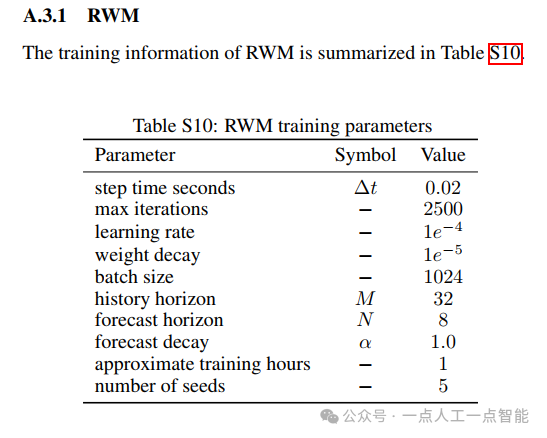
实验结果(图3a)表明,RWM在所有观测变量上展现出预测轨迹与真实轨迹的显著对齐。这种一致性在扩展推演中持续存在,展示了模型减轻复合误差的能力——这是长期预测中的关键挑战。这种性能归功于3.2节引入的双自回归机制,即使在训练期间使用较短的预测视界也能稳定预测。图1(底部)对比了RWM预测与真实模拟的状态演变,可视化表明RWM能够在远超训练预测视界的范围内保持轨迹预测的一致性,这对稳定策略学习和部署至关重要。
作者特别分析了历史视界M和预测视界N选择的关键作用。附录A.4.1的消融研究表明,虽然延长M和N都能提高准确性,但计算成本的现实考量需要仔细调整这些超参数以获得最佳性能。这种平衡反映了机器学习中的经典权衡——模型复杂度与计算效率之间的关系,在机器人应用中尤为突出。
4.2 噪声条件下的鲁棒性测试
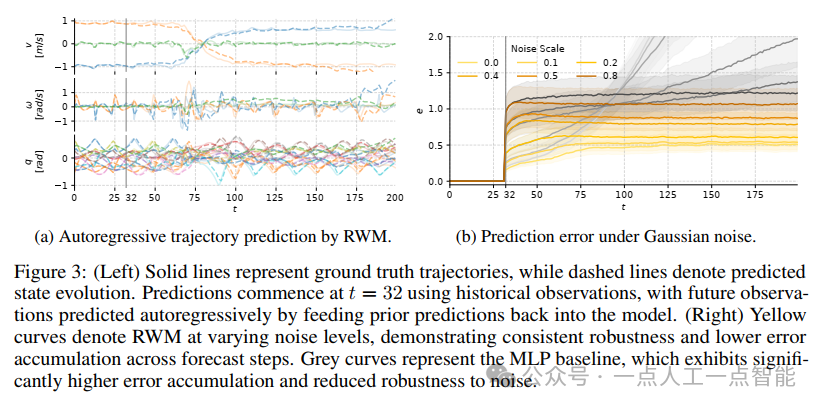
世界模型训练的关键挑战是其在噪声条件下的泛化能力,特别是当预测依赖自回归推演时。为评估RWM的鲁棒性,作者分析了在观测和动作上应用高斯噪声扰动时的性能表现,并将结果与同样采用自回归训练的MLP基线进行比较(图3b)。
结果显示,在所有噪声水平上,RWM相对MLP基线具有明显优势。随着预测步骤增加,MLP模型的相对预测误差显著增长,比RWM发散得更快。相比之下,RWM表现出更优的稳定性,即使在高噪声水平下也能保持较低的预测误差。这种鲁棒性可归因于3.2节引入的双自回归机制,该机制通过不断针对长期预测优化状态表示,最小化噪声输入下的误差累积。
值得注意的是,噪声鲁棒性实验设计反映了真实机器人部署的典型条件——传感器噪声和执行器不确定性无处不在。RWM在此条件下的优异表现为其在现实世界应用中的潜力提供了有力证据。
4.3 跨机器人环境的通用性评估
为评估RWM在多样化机器人环境中的通用性和鲁棒性,作者比较了其与多种基线方法的性能,包括MLP、循环状态空间模型(RSSM)和基于Transformer的架构。这些基线代表了动力学建模和策略优化中广泛采用的方法。所有模型在训练和评估期间获得相同的上下文,其训练参数详见附录A.2.2节。
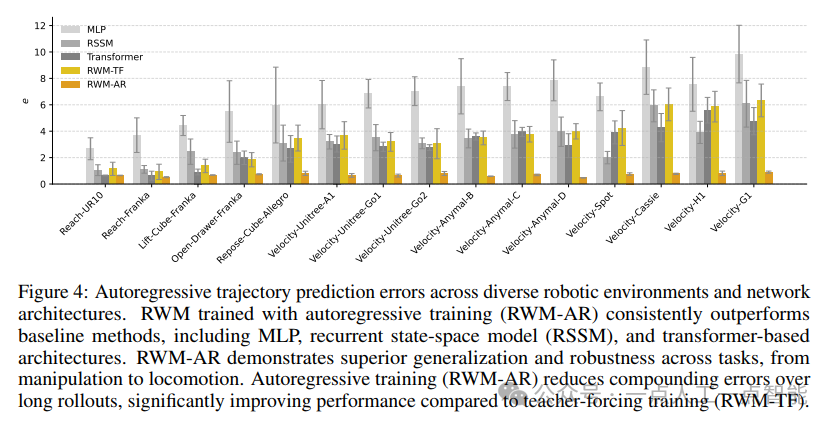
结果(图4)突出表明,采用自回归训练的RWM(RWM-AR)在所有环境中** consistently实现最低预测误差**。性能差距在复杂动态任务(如腿式机器人的速度跟踪)中尤为明显,这类任务中准确的长期预测对有效控制至关重要。对比还显示RWM-AR显著优于其teacher-forcing对应方法(RWM-TF),证实了自回归训练在减轻长期推演中复合预测误差方面的重要性。
作者特别指出,虽然基线传统上采用teacher forcing训练,但提出的自回归训练框架是架构无关的,也可应用于基线模型。当采用自回归训练时,RSSM达到了与提出的GRU架构相当的性能。然而,作者基于简化和计算效率的考量选择了GRU基础模型。另一方面,用自回归训练Transformer架构效果不佳,因为自回归预测中的多步梯度传播会导致GPU内存限制。这些结果有力证明,结合自回归训练的RWM在多样化机器人任务中实现了鲁棒且可泛化的性能。
4.4 策略学习与硬件迁移实验
使用MBPO-PPO,作者训练了一个以目标为条件的ANYmal D速度跟踪策略,利用RWM进行学习。策略的观测和动作空间详见附录A.1.1节,架构描述见A.2.3节。奖励公式由A.1.2节提供,训练参数总结在A.3.2节。作者将MBPO-PPO与两个基线进行比较:Short-Horizon Actor-Critic(SHAC)和DreamerV3。
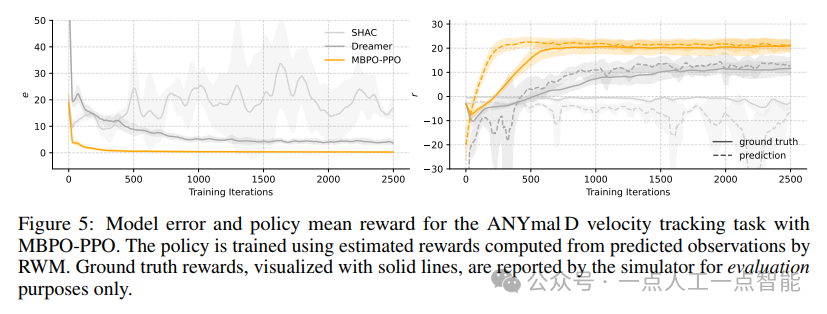
图5(左)显示了策略优化过程中的模型误差e。虽然MBPO-PPO展示了模型误差随训练的显著降低,但SHAC在整个过程中都面临高且波动的模型误差。SHAC依赖一阶梯度进行优化,这不适合腿部运动中的不连续动力学,导致训练期间机器人行为混乱。这些混乱行为反过来又为更新RWM产生了低质量训练数据,加剧了模型不准确性。尽管Dreamer有效利用了其潜在空间动力学模型进行策略优化,但训练期间较短规划视界的依赖限制了其处理长期依赖的能力,导致策略学习中遇到适度的复合误差。
图5右侧的奖励r曲线显示,MBPO-PPO的预测奖励(虚线)最初由于策略利用模型乐观估计中的小不准确性而超过地面真实值(实线)。随着训练进行,预测与地面真实更加吻合,保持足够准确性以指导有效学习。相比之下,SHAC未能收敛,产生不稳定的行为,降低了策略和模型质量。Dreamer表现出部分收敛,相比SHAC获得更高奖励但显著落后于MBPO-PPO。
为评估学习策略的鲁棒性,作者在零样本迁移设置下将其部署到ANYmal D硬件上。如图1所示,使用MBPO-PPO学习的策略在跟踪目标条件速度命令和在外界干扰(如意外冲击和地形条件)下保持稳定性方面展现出可靠而鲁棒的性
05 局限性
论文第五章"Limitations"客观讨论了RWM框架的局限性,展现了作者严谨的科研态度。虽然通过RWM和MBPO-PPO学习的策略在鲁棒性和泛化性方面超越了现有MBRL方法,但其性能仍落后于在高保真模拟器上训练的良好调优的模型自由RL方法。这种坦诚的比较反映了当前MBRL领域的真实状况——模型自由RL作为一个更成熟、经过广泛优化的范式,在可以与近乎完美的模拟器进行无限交互的环境中确实表现更优。

作者清晰地划定了MBRL的优势领域:在精确或高效模拟不可行的场景中,如复杂现实环境下的学习和适应。表1提供了与基于高保真模拟器的PPO方法在计算和性能方面的详细比较,显示了RWM在样本效率上的显著优势(6M vs 250M状态转换)和可比较的最终性能(跟踪奖励0.90±0.04 vs 0.90±0.03),这为方法选择提供了实用参考。
论文指出了几个关键的技术限制:
(1)世界模型预训练需求——当前框架使用模拟数据预训练世界模型以减少训练不稳定性(附录A.4.3),但从零开始训练仍具挑战性,因为策略可能在探索过程中利用模型不准确性,导致低效和不稳定;
(2)在线学习挑战——需要与环境进行额外交互来微调世界模型,而直接在硬件上实现安全有效的在线学习仍然困难;
(3)安全约束整合不足——当前模拟训练避免了潜在的硬件损坏,但将安全约束和鲁棒不确定性估计纳入RWM和MBPO-PPO对于现实世界的终身学习场景至关重要。
这些限制揭示了MBRL框架中固有的权衡:在数据效率、安全性和性能之间取得平衡,同时解决真实世界机器人系统的复杂性。特别是安全约束问题,作者在附录A.5"Ethics and Societal Impacts"中进一步探讨,承认该方法可能被滥用于监视或自主执法系统等应用的双重用途潜力,同时强调了当前安全措施(如仅在模拟中训练、限制在领域偏移下验证的策略部署)的重要性。
未来研究方向可能包括:
(1)开发不确定性感知世界模型,通过概率输出或集成方法量化预测不确定性,减少策略对模型误差的利用;
(2)设计安全感知的策略优化框架,将安全约束明确纳入目标函数;
(3)实现更高效的在线适应机制,减少对预训练的依赖;
(4)开发自动恢复策略,处理硬件部署中的故障情况。
这些方向对于推动MBRL在现实机器人应用中的广泛采用至关重要。
06 结论
作者强调,RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准确性和鲁棒性。这一主张得到了全面实验验证的支持,包括与RSSM和基于Transformer架构等最先进方法的系统比较。
技术贡献可归纳为三个层面:
(1)提出了结合双自回归机制的新型世界模型框架,通过历史上下文和自监督长期预测训练实现准确稳健的预测;
(2)开发了MBPO-PPO策略优化方法,利用世界模型的长时程推演能力进行高效学习;
(3)展示了从模拟到硬件的零样本策略迁移能力,在ANYmal D机器人上实现了可靠部署。
这些贡献共同推进了基于模型的强化学习领域,为实现适应性强、鲁棒性高的机器人系统奠定了基础。
从方法论角度看,论文的实验设计涵盖了自回归预测精度、噪声鲁棒性、跨环境通用性和硬件部署等多个维度,并提供了详尽的附录材料(包括网络架构细节、训练参数和额外可视化)。特别是图S9展示的多样化机器人环境中的想象推演与真实模拟对比,直观证明了RWM的泛化能力。

在理论意义上,这项工作为构建通用世界模型提供了新思路,弥合了专用物理模型与纯数据驱动方法之间的鸿沟。实践价值方面,RWM框架的样本效率和部署能力使其在真实机器人应用中具有直接实用性,可能降低对高成本硬件迭代的依赖。
总体而言,这篇论文代表了机器人学习和MBRL领域的重要进展,通过创新的架构设计和训练方法,推动了世界模型在复杂机器人控制中的应用边界。虽然存在一些局限性,但作者明确指出了未来改进方向,为后续研究提供了有价值的路标。这项工作为开发能够在非结构化现实环境中可靠运行的自主机器人系统做出了实质性的贡献。
相关文章:
未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...