Lesson5.1---Python 之 NumPy 简介和创建数组
一、NumPy 简介
- NumPy(Numerical Python)是 Python 的一种开源的数值计算扩展。
- 这种工具可用来存储和处理大型矩阵,比 Python 自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
- 使用 NumPy 可以方便的使用数据、矩阵进行计算,包含线性代数、傅里叶变化、随机数生成等大量函数。
1. 为什么要使用 NumPy
- Numpy 是 Python 各种数据科学类库的基础库,比如:Scipy,Scikit-Learn、TensorFlow、pandas等。
- 对于同样的数值计算任务,使用 NumPy 比直接使用 Python 代码实现有如下优点:
(1) 代码更简洁:NumPy 直接以数组、矩阵为粒度计算并且支撑大量的数学函数,而 python 需要用 for 循环从底层实现;
(2) 性能更高效:NumPy 的数组存储效率和输入输出计算性能,比 Python 使用 List 或者嵌套 List 好很多。 - 这里有两点需要注意需要注意是,其一,Numpy 的数据存储和 Python 原生的 List 是不一样的。
- 其二,NumPy 的大部分代码都是 C 语言实现的,这是 Numpy 比纯 Python 代码高效的原因。
2. NumPy 数据类型
- NumPy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。
- 下表列举了常用 NumPy 基本类型:
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
- NumPy 的数值类型实际上是 dtype 对象的实例,并对应唯一的字符,包括 np.bool_,np.int32,np.float32,等等。
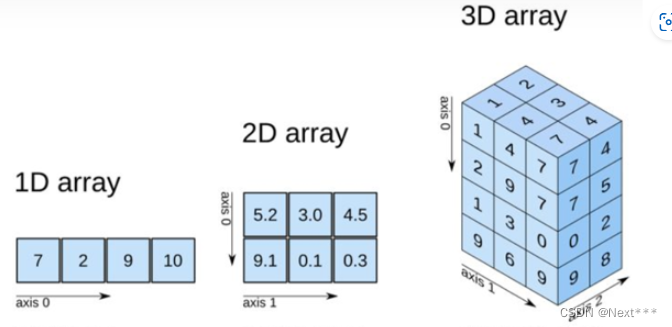
3. NumPy 数组属性
- NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。
- 在 NumPy 中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。
- 比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
- 很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
- NumPy 的数组中比较重要 ndarray 对象属性有:
| 属性 | 说明 |
|---|---|
| ndarray.ndim | 秩,即轴的数量或维度的数量 |
| ndarray.shape | 数组的维度,对于矩阵,n 行 m 列 |
| ndarray.size | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 对象的元素类型 |
| ndarray.itemsize | ndarray 对象中每个元素的大小,以字节为单位 |
| ndarray.flags | ndarray 对象的内存信息 |
| ndarray.real | ndarray 元素的实部 |
| ndarray.imag | ndarray 元素的虚部 |
| ndarray.data | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性 |
- NumPy 定义了一个 n 维数组对象,简称 ndarray 对象,它是一个一系列相同类型元素组成的数组集合。数组中的每个元素都占有大小相同的内存块。
- ndarray 对象采用了数组的索引机制,将数组中的每个元素映射到内存块上,并且按照一定的布局对内存块进行排列(行或列)。
4.NumPy 的 ndarray 对象
二、numpy.array() 创建数组
1. 基础理论
- 基本的 ndarray 是使用 NumPy 中的数组函数创建的,如下所示:
numpy.array
- 它从任何暴露数组接口的对象,或从返回数组的任何方法创建一个 ndarray。
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
- 上面的构造器接受以下参数:
| 参数 | 描述 |
|---|---|
| object | 表示一个数组序列 |
| dtype | 可选参数,通过它可以更改数组的数据类型 |
| copy | 可选参数,当数据源是ndarray时表示数组能否被复制,默认是 True |
| order | 可选参数,以哪种内存布局创建数组,有 3 个可选值,分别是 C(行序列)、F(列序列)、A(默认) |
| subok | 可选参数,类型为bool值,默认 False。为 True,使用object的内部数据类型;False:使用object数组的数据类型 |
| ndmin | 可选参数,用于指定数组的维度 |
2.基础操作演示
- 在代码编写之前,我们需要先引入 NumPy。
# 注意默认都会给numpy包设置别名为np
import numpy as np
- NumPy 引入完成后,实现 array 创建数组。
- 在 array() 函数当中,括号内可以是列表、元组、数组、迭代对象,生成器等。
- 其中,列表和元组的整体相同,但是列表属于可变序列,它的元素可以随时修改或删除,元组是不可变序列,其中元素不可修改,只能整体替换。
(1) 列表:
np.array([1,2,3,4,5])
#array([1, 2, 3, 4, 5])
(2) 元组:
np.array((1,2,3,4,5))
#array([1, 2, 3, 4, 5])
(3) 数组
a = np.array([1,2,3,4,5]) #创建一个数组
np.array(a)
#array([1, 2, 3, 4, 5])
(4) 迭代对象:
np.array(range(10))
#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
(5) 生成器:
np.array([i**2 for i in range(10)])
#array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81])
- 当数组内的元素数据类型不相同时,那么数组内哪种数据类型存储的结果最大,就按哪种数据类型进行存储。
- 如下例子,在数组当中,包含整型,浮点型和字符串,其中字符串的数据类型存储结果最大,因此,数组内的所有元素均按字符串进行存储。
np.array([1,1.5,3,4.5,'5'])
#array(['1', '1.5', '3', '4.5', '5'], dtype='<U32')
(1) 整型:
ar1 = np.array(range(10)) # 整型
ar1
#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
(2)浮点型(浮点型的数据存储大于整型的数据存储,因此全部转换为浮点型):
ar2 = np.array([1,2,3.14,4,5])
ar2
#array([1. , 2. , 3.14, 4. , 5. ])
(3) 二维数组(嵌套序列(列表,元组均可)):
ar3 = np.array([[1,2,3],('a','b','c')])
ar3
#array([['1', '2', '3'],
# ['a', 'b', 'c']], dtype='<U11')(4) 当二维数组嵌套序列数量不一致:
ar4 = np.array([[1,2,3],('a','b','c','d')])
ar4
#array([list([1, 2, 3]), ('a', 'b', 'c', 'd')], dtype=object)
上述例子的秩是 1,可以通过 ar4.ndim 进行查看。
3. numpy.array() 参数详解
(1) 设置 dtype 参数,默认自动识别。
a = np.array([1,2,3,4,5])
print(a)
# 设置数组元素类型
has_dtype_a = np.array([1,2,3,4,5],dtype='float')
has_dtype_a
#[1 2 3 4 5]
#array([1., 2., 3., 4., 5.])
如果将浮点型的数据,设置为整形,那么,数组内元素会自动舍弃尾数,转换为整型数据,具体输出如下所示。
np.array([1.1,2.5,3.8,4,5],dtype='int')
#array([1, 2, 3, 4, 5])
(2) 设置 copy 参数,默认为 True。
我们设置 a 数组,然后,通过 a 数组复制得出 b 数组,此时,a 数组和 b 数组的地址不相同,创建了新的对象。
那么,对 a 数组和 b 数组的任意修改都不会影响另一个数组的元素。
a = np.array([1,2,3,4,5])
b = np.array(a)
print('a:', id(a), ' b:', id(b))
print('以上看出a和b的内存地址')
b[0] = 10
print(a)
#a: 2066732212352 b: 2066732213152
#以上看出a和b的内存地址
#[1 2 3 4 5]
当我们修改 b 数组的元素时,a 数组不会发生变化。
b[0] = 10
print('a:', a,' b:', b)
#a: [1 2 3 4 5] b: [10 2 3 4 5]
当设置 copy 参数为 Fasle 时,不会创建副本,两个变量会指向相同的内容地址,没有创建新的对象。
此时,由于 a 数组和 b 数组指向的是相同的内存地址,因此当修改 b 数组的元素时,a 数组对应的元素会发生变化。
a = np.array([1,2,3,4,5])
b = np.array(a, copy=False)
print('a:', id(a), ' b:', id(b))
print('以上看出a和b的内存地址')
b[0] = 10
print('a:',a,' b:',b)
#a: 2066732267520 b: 2066732267520
#以上看出a和b的内存地址
#a: [10 2 3 4 5] b: [10 2 3 4 5]
(3) ndmin 用于指定数组的维度。
将一维数组转换为二维数组。
a = np.array([1,2,3])
print(a)
a = np.array([1,2,3], ndmin=2)
a
#[1 2 3]
#array([[1, 2, 3]])
(4) subok 参数,类型为 bool 值,默认 False。为 True 时,使用 object 的内部数据类型;False:使用 object 数组的数据类型。
- 首先,创建一个 a 矩阵,然后输出 a 矩阵的数据类型,便于后面的比较。
- 其次,通过 a 矩阵生成 at 和 af 两个数组,at 数组的 subok 参数设置为 True,at 数组的 subok 参数不设置,即默认为 False。
- 最后,输出 at 数组和 af 数组的数据类型,用于比较观察。
a = np.mat([1,2,3,4])
print(type(a))
at = np.array(a,subok=True)
af = np.array(a)
print('at,subok为True:',type(at))
print('af,subok为False:',type(af))
print(id(at),id(a))
#<class 'numpy.matrix'>
#at,subok为True: <class 'numpy.matrix'>
#af,subok为False: <class 'numpy.ndarray'>
#2066738151720 2066738151608
书写代码时需要注意的内容:
先定义一个 a 数组。
a = np.array([2,4,3,1])
在定义 b 数组时,如果想复制 a 数组,有如下几种方案:
(1) 使用 np.array()。
(2) 使用数组的 copy() 方法。
b = np.array(a)
print('b = np.array(a):',id(b),id(a))
c = a.copy()
print('c = a.copy():',id(c),id(a))
#b = np.array(a): 2066731363744 2066731901216
#c = a.copy(): 2066732267520 2066731901216
注意不能直接使用 = 号复制,直接使用 = 号,会使 2 个变量指向相同的内存地址。
三、numpy.arange() 生成区间数组
3.1根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个 ndarray。
numpy.arange(start, stop, step, dtype)
3.2其参数含义如下:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 起始值,默认为 0 |
| 2 | stop | 终止值(不包含) |
| 3 | step | 步长,默认为 1 |
| 4 | dtype | 返回 ndarray 的数据类型,如果没有提供,则会使用输入数据的类型 |
3.2示例
(1)如果只有一个参数,那么起始值就是 0,终止值就是那个参数,步长就是 1。
(2)如果有两个参数,那么,第一个参数就是起始值,第二个参数就是终止值。
np.arange(10)
#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
(3)可以使用浮点型数值
np.arange(3.1)
#array([0., 1., 2., 3.])
(4)返回浮点型的,也可以指定类型
x = np.arange(5, dtype = float)
x
#array([0., 1., 2., 3., 4.])
(5)设置了起始值、终止值及步长:
- 起始值是 10,终止值是 20,步长是 2。
np.arange(10,20,2)
#array([10, 12, 14, 16, 18])
- 起始值是 0,终止值是 20,步长是 3。
ar2 = np.arange(0,20,3)
print(ar2)
ar3 = np.arange(20,step=3) #指定传参
ar3
#[ 0 3 6 9 12 15 18]
#array([ 0, 3, 6, 9, 12, 15, 18])
(6)如果数组太大而无法打印,NumPy 会自动跳过数组的中心部分,并只打印边角。
np.arange(10000)
#array([ 0, 1, 2, ..., 9997, 9998, 9999])
四、numpy.linspace() 创建等差数列
4.1返回在间隔 [开始,停止] 上计算的 num 个均匀间隔的样本。数组是一个等差数列构成。
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
4.2其参数含义如下:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 必填项,序列的起始值 |
| 2 | stop | 必填项,序列的终止值,如果endpoint为true,该值包含于数列中 |
| 3 | num | 要生成的等步长的样本数量,默认为50 |
| 4 | endpoint | 该值为 true 时,数列中包含stop值,反之不包含,默认是True |
| 5 | baset | 对数 log 的底数 |
| 6 | dtype | ndarray 的数据类型 |
4.3示例
(1)以下例子用到三个参数,设置起始点为 1 ,终止点为 10,数列个数为 10。
a = np.linspace(1,10,10)
a
#array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
如果,我们将 endpoint 设置为 False,就不会包含 10,此时,默认步长是 50。
a = np.linspace(1,10,endpoint=False)
a
#array([1. , 1.18, 1.36, 1.54, 1.72, 1.9 , 2.08, 2.26, 2.44, 2.62, 2.8 ,
# 2.98, 3.16, 3.34, 3.52, 3.7 , 3.88, 4.06, 4.24, 4.42, 4.6 , 4.78,
# 4.96, 5.14, 5.32, 5.5 , 5.68, 5.86, 6.04, 6.22, 6.4 , 6.58, 6.76,
# 6.94, 7.12, 7.3 , 7.48, 7.66, 7.84, 8.02, 8.2 , 8.38, 8.56, 8.74,
# 8.92, 9.1 , 9.28, 9.46, 9.64, 9.82])
(2)以下实例用到三个参数,设置起始位置为 2.0,终点为 3.0,数列个数为 5。
ar1 = np.linspace(2.0, 3.0, num=5)
ar1
#array([2. , 2.25, 2.5 , 2.75, 3. ])
将参数 endpoint 设置为 False 时,不包含终止值,
ar1 = np.linspace(2.0, 3.0, num=5, endpoint=False)
ar1
#array([2. , 2.2, 2.4, 2.6, 2.8])
设置 retstep 显示计算后的步长
ar1 = np.linspace(2.0,3.0,num=5, retstep=True)
print(ar1)
type(ar1)
#(array([2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)
#tuple
将 endpoint 设置为 False,不包含终止值,再设置 retstep 显示计算后的步长
ar1 = np.linspace(2.0,3.0,num=5,endpoint=False,retstep=True)
ar1
#(array([2. , 2.2, 2.4, 2.6, 2.8]), 0.2)
(3)等差数列在线性回归经常作为样本集,例如:生成 x_data,值为 [0, 100] 之间 500 个等差数列数据集合作为样本特征,根据目标线性方程 y=3×x+2y = 3 × x + 2y=3×x+2 ,生成相应的标签集合 y_data
x_data = np.linspace(0,100,500)
x_data
五、numpy.logspace() 创建等比数列
5.1 返回在间隔 [开始,停止] 上计算的 num 个均匀间隔的样本。数组是一个等比数列构成。
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
5.2其参数含义如下:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 必填项,序列的起始值 |
| 2 | stop | 必填项,序列的终止值,如果endpoint为true,该值包含于数列中 |
| 3 | num | 要生成的等步长的样本数量,默认为50 |
| 4 | endpoint | 该值为 true 时,数列中包含stop值,反之不包含,默认是True |
| 5 | baset | 对数 log 的底数 |
| 6 | dtype | ndarray 的数据类型 |
5.3示例
a = np.logspace(0,9,10,base=2)
a
#array([ 1., 2., 4., 8., 16., 32., 64., 128., 256., 512.])
上述代码可以理解为 202^{0}20到292^{9}29
np.logspace(A,B,C,base=D) 中的参数分别是如下含义:
A:生成数组的起始值为 D 的 A 次方。
B:生成数组的结束值为 D 的 B 次方。
C:总共生成 C 个数。
D:指数型数组的底数为 D,当省略 base=D 时,默认底数为 10。
(1)我们先使用前 3 个参数,将 [1,5] 均匀分成 3 个数,得到 {1,3,5},然后利用第 4 个参数 base=2(默认是 10)使用指数函数可以得到最终输出结果21,23,252^{1},2^{3},2^{5}21,23,25
np.logspace(1,5,3,base=2)
#array([ 2., 8., 32.])
(2)取得 1 到 2 之间 10 个常用对数
np.logspace(1.0,2.0,num=10)
#array([ 10. , 12.91549665, 16.68100537, 21.5443469 ,
# 27.82559402, 35.93813664, 46.41588834, 59.94842503,
# 77.42636827, 100. ]
上述实际上是 10110^{1}101到10210^{2}102
六、numpy.zeros() 创建全零数列
6.1创建指定大小的数组,数组元素以 0 来填充。
numpy.zeros(shape, dtype = float, order = 'C')
6.2其参数含义如下:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | shape | 数组形状 |
| 2 | dtype | 数据类型,可选 |
6.3示例
(1)默认的数据类型是浮点数
np.zeros(5)
#array([0., 0., 0., 0., 0.])
(2)将数据类型设置为整型
np.zeros((5,), dtype = 'int')
array([0, 0, 0, 0, 0])
(3)生成一个 2 行 2 列的全 0 数组
np.zeros((2,2))
#array([[0., 0.],
# [0., 0.]])
(4)使用 zeros_like 可以返回具有与给定数组相同的形状和类型的零数组
ar1 = np.array([[1,2,3],[4,5,6]])
np.zeros_like(ar1)
#array([[0, 0, 0],
# [0, 0, 0]])
七、np.ones() 创建一数列
ar5 = np.ones(9)
ar6 = np.ones((2,3,4))
ar7 = np.ones_like(ar3)
print('ar5:',ar5)
print('ar6:',ar6)
print('ar7:',ar7)
#ar5: [1. 1. 1. 1. 1. 1. 1. 1. 1.]
#ar6: [[[1. 1. 1. 1.]
# [1. 1. 1. 1.]
# [1. 1. 1. 1.]]
#
# [[1. 1. 1. 1.]
# [1. 1. 1. 1.]
# [1. 1. 1. 1.]]]
#ar7: [1 1 1 1 1 1 1]
相关文章:
Lesson5.1---Python 之 NumPy 简介和创建数组
一、NumPy 简介 NumPy(Numerical Python)是 Python 的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比 Python 自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示…...
Exchange 2013升级以及域名绑定等若干问题
环境简介Exchange 2013服务器位于ad域中,系统为Windows server 2012 R2,其内部域名为:mail.ad.com一. Exchange客户端无法在浏览器中正常运行在域中部署Exchange服务器后,除了可以通过outlook、foxmail等邮件客户端来使用邮箱功能…...
linux安装jenkins
1. 官网寻找安装方式 进入到jenkins官网,找到对应的下载页面:https://www.jenkins.io/download/ 根据自己系统还有想要使用的版本,进行选择即可。这里我们使用CentOS作为示例,版本选择长期支持版(LTS) 2.…...
【MySQL】MySQL表的增删改查(CRUD)
✨个人主页:bit me👇 ✨当前专栏:MySQL数据库👇 ✨算法专栏:算法基础👇 ✨每日一语:生命久如暗室,不碍朝歌暮诗 目 录🔓一. CRUD🔒二. 新增(Creat…...

GCC for openEuler 数据库性能优化实践
GCC for openEuler是基于开源GCC开发的编译器工具链(包含编译器,汇编器,链接器),在openEuler社区开源发布,并通过鲲鹏社区免费提供二进制包,支持aarch64处理器架构。 关键特性 支持鲲鹏微架构芯…...

【C++】类和对象(第二篇)
文章目录1. 类的6个默认成员函数2. 构造函数2.1 构造函数的引出2.2 构造函数的特性3. 析构函数3.1 析构函数的引出3.2 析构函数的特性4. 拷贝构造函数4.1 概念4.2 特性5.赋值运算符重载5.1 运算符重载概念注意练习5.2 赋值重载实现赋值重载的特性6. const成员函数7. 取地址及co…...

MySQL数据库(数据库约束)
目录 数据库约束 数据库约束的类型: null约束 : unique约束(唯一约束): default约束(默认值约束): primary key约束(主键约束): for…...
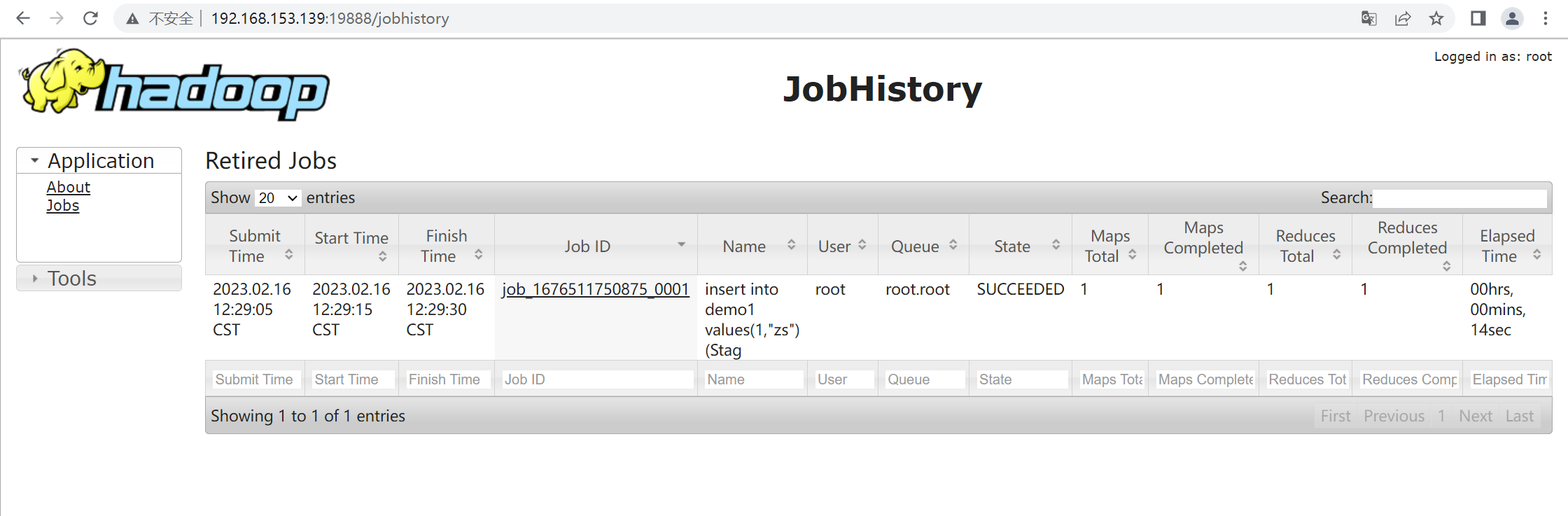
Hive的安装与配置
一、配置Hadoop环境先看看伪分布式下的集群环境有没有错误的情况:输入命令:start-all.sh jps查看伪分布式的所有进程是否完善二、解压并配置HiveHive压缩包→ https://pan.baidu.com/s/1eOF_ICZV8rV-CEh3nX-7Xw 提取码: m31e 复制这段内容后打开百度网盘…...

关于医院医用医疗隔离电源系统应用案例的分析探讨
【摘要】:介绍该三级医院采用安科瑞医用隔离电源柜,使用落地式安装方式,从而实现将TN系统转化为IT系统,同时监测系统绝缘情况。 【关键词】医用隔离电源柜;IT系统;绝缘情况;中西医结合医院&…...
【LeetCode】剑指 Offer 07. 重建二叉树 p62 -- Java Version
题目链接:https://leetcode.cn/problems/zhong-jian-er-cha-shu-lcof/ 1. 题目介绍(07. 重建二叉树) 输入某二叉树的前序遍历和中序遍历的结果,请构建该二叉树并返回其根节点。 假设输入的前序遍历和中序遍历的结果中都不含重复的…...

ERROR 1114 (HY000): The table ‘tt2‘ is full
insert 操作时提示is full 问题原因 rootlocalhost 11:55:41 [t]>show table status from t like ‘tt2’ \G ; *************************** 1. row *************************** Name: tt2 Engine: MEMORY Version: 10 Row_format: Fixed Rows: 7056 Avg_row_length: 944…...
考了PMP证后工资大概是多少 ?(含pmp资料)
这个岗位的不同还有每个公司的薪资也是不一样的,具体的数字肯定是没有的,但大概的比例还是有的,据PMI调查,在获得PMP证书的人当中,在PMP认证一年后,年薪有所增长的比例为66%,上涨幅度主要集中在…...
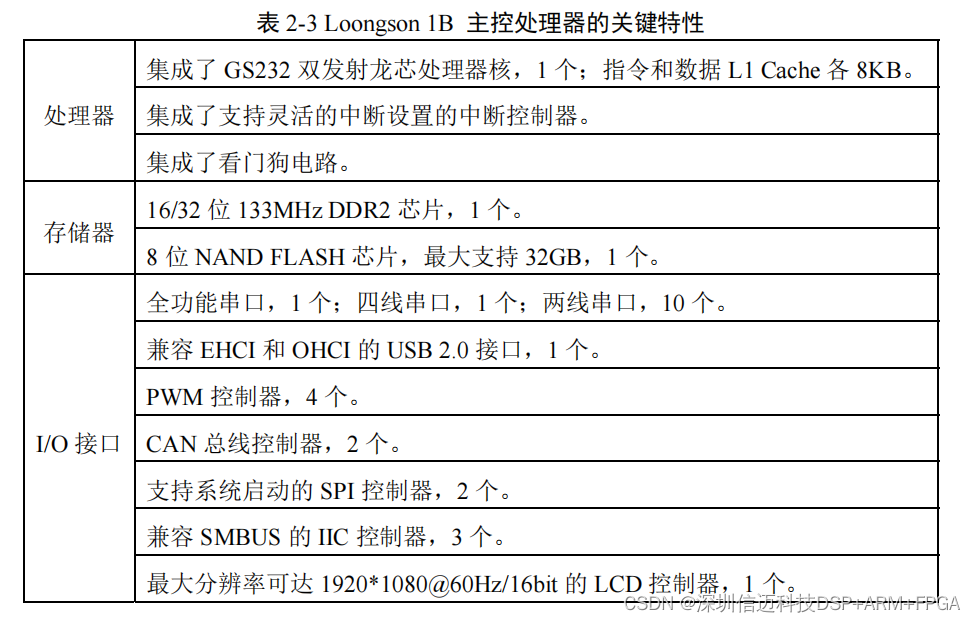
基于国产龙芯 CPU 的气井工业网关研究与设计(一)
当前,我国气田的自动化控制程度还未完全普及,并且与世界已普及的气井站的自 动化程度也存在一定的差距。而在天然气资源相对丰富的国家,开采过程中设备研发资 金投入较大,研发周期较长,更新了一代又一代的自动化开采系…...
40/365 javascript 数据类型
1.数据类型 number类型:整数,小数都属于这一类,不具体区分 字符串:hello, "hello" 布尔类型:true,false 逻辑运算符: && || ! 比较运算符: : 类型不一致&#x…...

后勤管理系统—服务台管理功能
数图互通是一家IT类技术型软件科技公司,专业的不动产、工作场所、空间、固定资产、设备家具、设施运维及可持续性管理解决方案软件供应商。 一、后勤管理系统服务台管理功能包含: 1、专业自动化、集中管理的自助服务助理,随时响应服务请求。…...

Spring Boot 是什么,应该如何学习,有哪些优缺点
1、Spring Boot 是什么? Spring Boot是一个基于Spring框架的开源项目,它简化了Spring应用程序的开发过程,提供了一种快速、便捷、可扩展的方式来构建Spring应用程序。 Spring Boot通过自动化配置机制简化了Spring应用程序的配置过程&#x…...
使用yolov5和强化学习训练一个AI智能欢乐斗地主(一)
这里写自定义目录标题项目介绍项目过程介绍训练yolov5目标检测斗地主收集数据集yolov5调参项目介绍 你好! 欢迎阅读我的文章,本章将介绍,如何使用yolov5和强化学习训练一个AI斗地主,本项目将分为三个部分,其中包含&am…...

C++ 浅谈之 AVL 树和红黑树
C 浅谈之 AVL 树和红黑树 HELLO,各位博友好,我是阿呆 🙈🙈🙈 这里是 C 浅谈系列,收录在专栏 C 语言中 😜😜😜 本系列阿呆将记录一些 C 语言重要的语法特性 dz…...

【Kotlin】Kotlin函数那么多,你会几个?
目录标准函数letrunwithapplyalsotakeIftakeUnlessrepeat小结作用域函数的区别作用域函数使用场景简化函数尾递归函数(tailrec)扩展函数高阶函数内联函数(inline)inlinenoinlinecrossinline匿名函数标准函数 Kotlin标准库包含几个…...
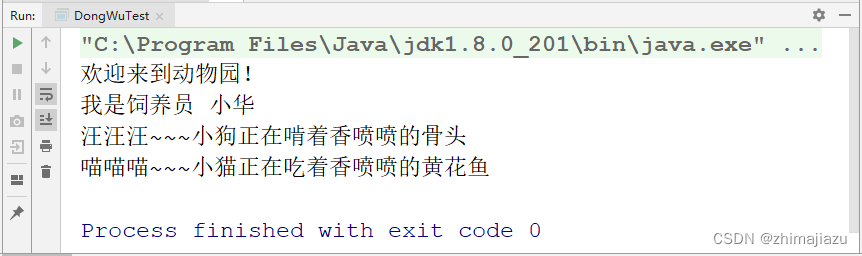
饲养员喂养动物-课后程序(JAVA基础案例教程-黑马程序员编著-第四章-课后作业)
【案例4-2】饲养员喂养动物 记得 关注,收藏,评论哦,作者将持续更新。。。。 【案例目标】 案例描述 饲养员在给动物喂食时,给不同的动物喂不同的食物,而且在每次喂食时,动物都会发出欢快的叫声。例如&…...

Codex:不只是程序员的代码助手,更是办公人士的高效伙伴
Codex:不只是程序员的代码助手,更是办公人士的高效伙伴 面向团队协作、文档处理、数据分析和日常执行的智能工作台 当人们谈到 Codex,第一反应往往是“写代码”。这当然是它的强项,但如果只把 Codex 看成程序员的专属工具&#…...

基于Agent架构的轻量级自托管部署工具Ship实战指南
1. 项目概述:一个为开发者而生的轻量级部署工具最近在折腾一个前后端分离的小项目,从本地开发到服务器部署,中间那套流程真是让人头大。代码提交、构建、测试、再到服务器上拉取、重启服务,一套组合拳下来,少说也得十几…...

ML:Q 学习的基本原理与实现
在强化学习中,模型面对的不是一批固定样本,而是一个可以不断交互的环境。智能体(Agent)在某个状态下采取动作,环境给出奖励,并进入新的状态。智能体的目标不是只看当前一步是否得分,而是学习一种…...

Colmap生成的点云太密?试试这个‘瘦身’组合拳:用Colmap稠密点云驱动OpenMVS高效建模
Colmap点云优化与OpenMVS高效建模实战指南 三维重建领域的技术迭代日新月异,但硬件资源与计算效率始终是开发者面临的现实瓶颈。当Colmap生成的稠密点云数据量超出内存承载能力,或OpenMVS重建过程陷入性能泥潭时,一套精准的优化策略比盲目升级…...

2026主流远控软件综合横测:4款工具全方位测试,谁更适合你?
用心测评,全程无广2026主流远控软件综合横测:4款工具全方位测试,谁更适合你?远程控制已成为个人办公、家庭协助、企业运维、游戏串流的刚需工具。本次横测聚焦ToDesk、向日葵、TeamViewer、网易 UU 远程四款主流产品,从连接性能、…...

从ARM到FPGA:手把手教你用Vivado双口RAM IP核搭建跨芯片通信桥
从ARM到FPGA:构建高性能双口RAM通信桥的工程实践 在异构计算架构中,FPGA与处理器的协同工作已成为提升系统性能的关键方案。Xilinx Vivado工具链中的双口RAM IP核,为解决跨芯片数据交换提供了硬件级的优雅实现。本文将深入探讨如何将这一技术…...

AI营销技能库:模块化设计提升Claude Code与智能体工作流效率
1. 项目概述:一个为AI营销工作流设计的技能库如果你正在用Claude Code、Cursor这类AI编程工具做营销、内容创作或增长相关的工作,并且感觉每次都要花大量时间写重复的提示词,或者希望团队能有一套标准化的AI工作流程,那么这个名为…...

容器技术从入门到精通:Docker核心概念、Dockerfile与生产实践全解析
1. 项目概述:从零到一构建容器化认知体系最近在技术社区里,经常看到有朋友在讨论stephrobert/containers-training这个仓库。乍一看,这像是一个个人或团队维护的关于容器技术的培训材料。对于刚接触 Docker 和容器生态的开发者、运维工程师&a…...

会话搜索服务器实战:从架构设计到生产部署的完整指南
1. 项目概述与核心价值最近在折腾一个挺有意思的玩意儿,叫session_search_server。这名字乍一看有点抽象,但如果你做过聊天机器人、客服系统,或者任何需要处理多轮对话、历史记录查询的应用,那你肯定遇到过类似的痛点:…...

Cursor-Buddy:基于AI的Web界面语音交互与视觉引导助手
1. 项目概述与核心价值最近在捣鼓一个挺有意思的开源项目,叫cursor-buddy。简单来说,它是一个能“住”在你鼠标光标里的AI助手,专门为Web应用设计。想象一下,你在浏览一个复杂的后台管理系统或者一个数据看板,突然想找…...