【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一)
系列文章
【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一)
【如何训练一个中英翻译模型】LSTM机器翻译模型训练与保存(二)
【如何训练一个中英翻译模型】LSTM机器翻译模型部署(三)
【如何训练一个中英翻译模型】LSTM机器翻译模型部署之onnx(python)(四)
训练一个翻译模型,我们需要一份数据集,以cmn.txt数据集为例:
取前两行数据来看看,如下:
Wait! 等等!
Hello! 你好。
对于中译英,我们希望让网络输入:“Wait!”,输出:“等等!”,输入:“Hello!”,输出:“你好。”
那么问题来了,这样的数据要如何输入网络进行训练呢?
显然需要进行编码,大白话说就是用“0101…”这样的数据来表示这些文字(为了方便表达,后面称为字符)。
先假设,我们的训练数据只取第一行,那就是只有“Wait! 等等!”,那么,我们开始对它进行编码,读取cmn.txt文件,并取第一行数据中英文分别保存在target_texts ,input_texts,,然后将所有的字符取出来,中英文字符并分别保存在target_characters ,input_characters
input_texts = [] # 保存英文数据集
target_texts = [] # 保存中文数据集
input_characters = set() # 保存英文字符,比如a,b,c
target_characters = set() # 保存中文字符,比如,你,我,她
with open(data_path, 'r', encoding='utf-8') as f:lines = f.read().split('\n')# 一行一行读取数据
for line in lines[: min(num_samples, len(lines) - 1)]: # 遍历每一行数据集(用min来防止越出)input_text, target_text = line.split('\t') # 分割中英文# We use "tab" as the "start sequence" character# for the targets, and "\n" as "end sequence" character.target_text = '\t' + target_text + '\n'input_texts.append(input_text)target_texts.append(target_text)for char in input_text: # 提取字符if char not in input_characters:input_characters.add(char)for char in target_text:if char not in target_characters:target_characters.add(char)input_characters = sorted(list(input_characters)) # 排序一下
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters) # 英文字符数量
num_decoder_tokens = len(target_characters) # 中文文字数量
max_encoder_seq_length = max([len(txt) for txt in input_texts]) # 输入的最长句子长度
max_decoder_seq_length = max([len(txt) for txt in target_texts])# 输出的最长句子长度print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
可以得到这样的数据:
#原始数据:Wait! 等等!input_texts = ['Wait!']
target_texts = ['\t等等!\n']input_characters = ['!', 'W', 'a', 'i', 't']
target_characters = ['\t', '\n', '等', '!']
然后我们就可以开始编码啦。
先对input_characters 于target_characters 进行编号,也就是
['!', 'W', 'a', 'i', 't']0 1 2 3 4
['\t', '\n', '等', '!']0 1 2 3
代码如下:
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])
编号完之后就是:
input_token_index ={'!': 0,'W': 1,'a': 2,'i': 3,'t': 4}
target_token_index ={'\t': 0,'\n': 1,'等': 2,'!': 3}
有了input_token_index 与target_token_index ,我们就可以开始对输入输出进行编码,先来看输入。
假设我们的输入只有一个字符W,那么根据input_token_index 对W进行编码就如下:
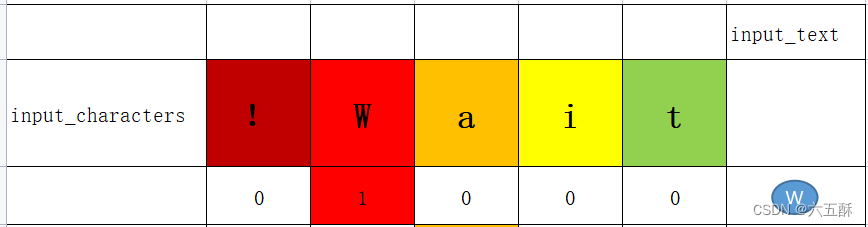
可看到W用向量01000表示了,只有W的那个位置被标为1,其余标为0
依次类推对Wait!进行编码,结果如下:
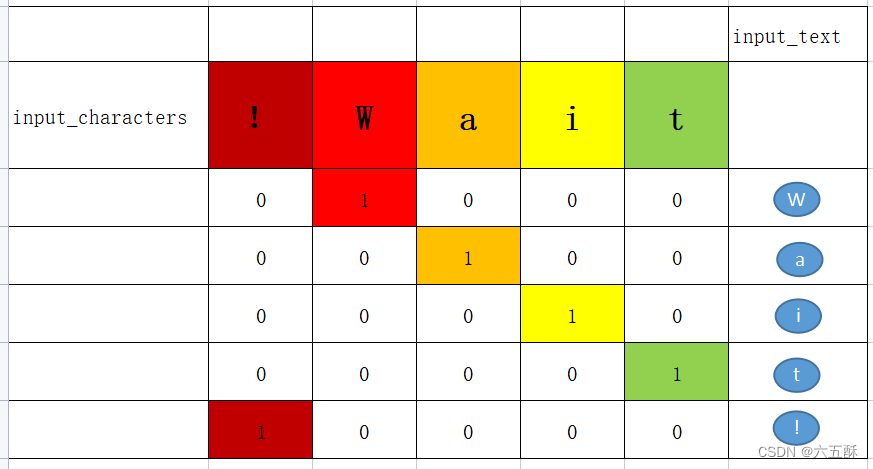
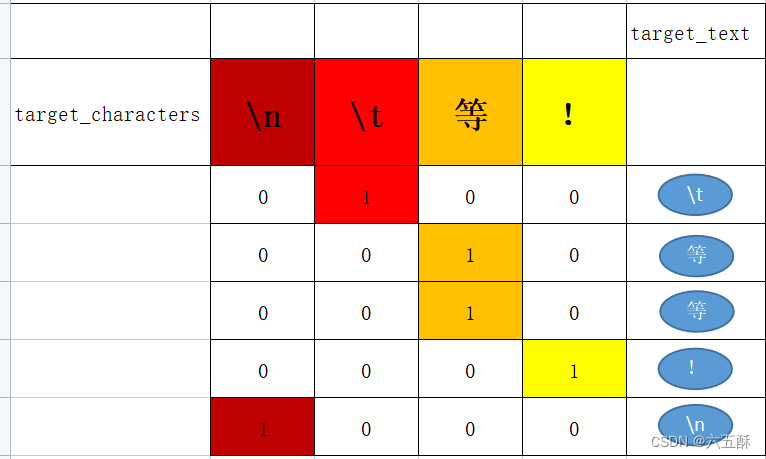
对中文进行编码也是一样的操作:
因此输入输出分别可以用encoder_input_data与decoder_input_data这两个矩阵来表示了,这两个矩阵里面的值是一堆01
['!', 'W', 'a', 'i', 't']
encoder_input_data
[[[0. 1. 0. 0. 0.] W[0. 0. 1. 0. 0.] a[0. 0. 0. 1. 0.] i[0. 0. 0. 0. 1.] t[1. 0. 0. 0. 0.]]] !target_texts通过编码得到
['\t', '\n', '等', '!']
decoder_input_data
[[[1. 0. 0. 0.] \t[0. 0. 1. 0.] 等[0. 0. 1. 0.] 等[0. 0. 0. 1.] ![0. 1. 0. 0.]]] \n
为了进一步说明,我们这时候将训练集改为2,也就是num_samples = 2,那么
input_texts = ['Wait!', 'Hello!']
target_texts = ['\t等等!\n', '\t你好。\n']
input_characters = ['!', 'H', 'W', 'a', 'e', 'i', 'l', 'o', 't']
target_characters = ['\t', '\n', '。', '你', '好', '等', '!']
分别对输入输出的内容进行编码,可得到:
encoder_input_data =
[[[0. 0. 1. 0. 0. 0. 0. 0. 0.] # 第一句 Wait![0. 0. 0. 1. 0. 0. 0. 0. 0.][0. 0. 0. 0. 0. 1. 0. 0. 0.][0. 0. 0. 0. 0. 0. 0. 0. 1.][1. 0. 0. 0. 0. 0. 0. 0. 0.][0. 0. 0. 0. 0. 0. 0. 0. 0.]][[0. 1. 0. 0. 0. 0. 0. 0. 0.] # 第二句 Hello[0. 0. 0. 0. 1. 0. 0. 0. 0.][0. 0. 0. 0. 0. 0. 1. 0. 0.][0. 0. 0. 0. 0. 0. 1. 0. 0.][0. 0. 0. 0. 0. 0. 0. 1. 0.][1. 0. 0. 0. 0. 0. 0. 0. 0.]]]decoder_input_data =
[[[1. 0. 0. 0. 0. 0. 0.] # 第一句 \t等等!\n[0. 0. 0. 0. 0. 1. 0.][0. 0. 0. 0. 0. 1. 0.][0. 0. 0. 0. 0. 0. 1.][0. 1. 0. 0. 0. 0. 0.]][[1. 0. 0. 0. 0. 0. 0.] # 第二句 \t你好。\n[0. 0. 0. 1. 0. 0. 0.][0. 0. 0. 0. 1. 0. 0.][0. 0. 1. 0. 0. 0. 0.][0. 1. 0. 0. 0. 0. 0.]]]
到这里,我们就清楚了这些文字用向量是怎么表示的,有了向量我们可以进行计算,也就是可以搭建一个网络来训练这些数据了,这个网络的输入是一堆0 1矩阵,输出也是一堆0 1矩阵,输入矩阵在输入字符那里索引得出这个矩阵是什么句子,而输出矩阵在输出字符那里索引得出这个句子代表什么句子,因此我们就可以来训练一个翻译模型了。
总结下来:翻译模型实际上就是输入一个0 1矩阵,输出另外一个0 1矩阵。
句子->输入矩阵->运算->输出矩阵->句子
下面是相应的代码:
# mapping token to index, easily to vectors
# 处理方便进行编码为向量
# {
# 'a': 0,
# 'b': 1,
# 'c': 2,
# ...
# 'z': 25
# }
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])# np.zeros(shape, dtype, order)
# shape is an tuple, in here 3D
encoder_input_data = np.zeros( # (12000, 32, 73) (数据集长度、句子长度、字符数量)(len(input_texts), max_encoder_seq_length, num_encoder_tokens),dtype='float32')
decoder_input_data = np.zeros( # (12000, 22, 2751)(len(input_texts), max_decoder_seq_length, num_decoder_tokens),dtype='float32')
decoder_target_data = np.zeros( # (12000, 22, 2751)(len(input_texts), max_decoder_seq_length, num_decoder_tokens),dtype='float32')# 遍历输入文本(input_texts)和目标文本(target_texts)中的每个字符,
# 并将它们转换为数值张量以供深度学习模型使用。
#编码如下
#我,你,他,这,国,是,家,人,中
#1 0 0 0 1 1 0 1 1,我是中国人
#1 0 1 0 0 1 1 1 0,他是我家人
# input_texts contain all english sentences
# output_texts contain all chinese sentences
# zip('ABC','xyz') ==> Ax By Cz, looks like that
# the aim is: vectorilize text, 3D
# zip(input_texts, target_texts)成对取出输入输出,比如input_text = 你好,target_text = you goodfor i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):for t, char in enumerate(input_text):# 3D vector only z-index has char its value equals 1.0encoder_input_data[i, t, input_token_index[char]] = 1.for t, char in enumerate(target_text):# decoder_target_data is ahead of decoder_input_data by one timestepdecoder_input_data[i, t, target_token_index[char]] = 1.if t > 0:# decoder_target_data will be ahead by one timestep# and will not include the start character.# igone t=0 and start t=1, meansdecoder_target_data[i, t - 1, target_token_index[char]] = 1.
在进行模型推理的时候,你同样需要相同的一份input_token_index 与target_token_index ,那么就需要将input_characters与target_characters保存下来,在推理之前,将你输入的内容进行编码,因为只有同一份位置编码,你的网络才能认识,要不然全乱套了,下面是将input_characters与target_characters保存为txt与读取的方法:
# 将 input_characters保存为 input_words.txt 文件
with open('input_words.txt', 'w', newline='') as f:for char in input_characters:if char == '\t':f.write('\\t\n')elif char == '\n':f.write('\\n\n')else:f.write(char + '\n')# 将 target_characters保存为 target_words.txt 文件
with open('target_words.txt', 'w', newline='') as f:for char in target_characters:if char == '\t':f.write('\\t\n')elif char == '\n':f.write('\\n\n')else:f.write(char + '\n')# 从 input_words.txt 文件中读取字符串
with open('input_words.txt', 'r') as f:input_words = f.readlines()input_characters = [line.rstrip('\n') for line in input_words]# 从 target_words.txt 文件中读取字符串
with open('target_words.txt', 'r', newline='') as f:target_words = [line.strip() for line in f.readlines()]target_characters = [char.replace('\\t', '\t').replace('\\n', '\n') for char in target_words]#字符处理,以方便进行编码
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])
相关文章:
【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一)
系列文章 【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一) 【如何训练一个中英翻译模型】LSTM机器翻译模型训练与保存(二) 【如何训练一个中英翻译模型】LSTM机器翻译模型部署(三) 【如何训…...
[JAVAee]文件操作-IO
本文章讲述了通过java对文件进行IO操作 IO:input/output,输入/输出. 建议配合文章末尾实例食用 目录 文件 文件的管理 文件的路径 文件的分类 文件系统的操作 File类的构造方法 File的常用方法 文件内容的读写 FileInputStream读取文件 构造方法 常用方法 Scan…...
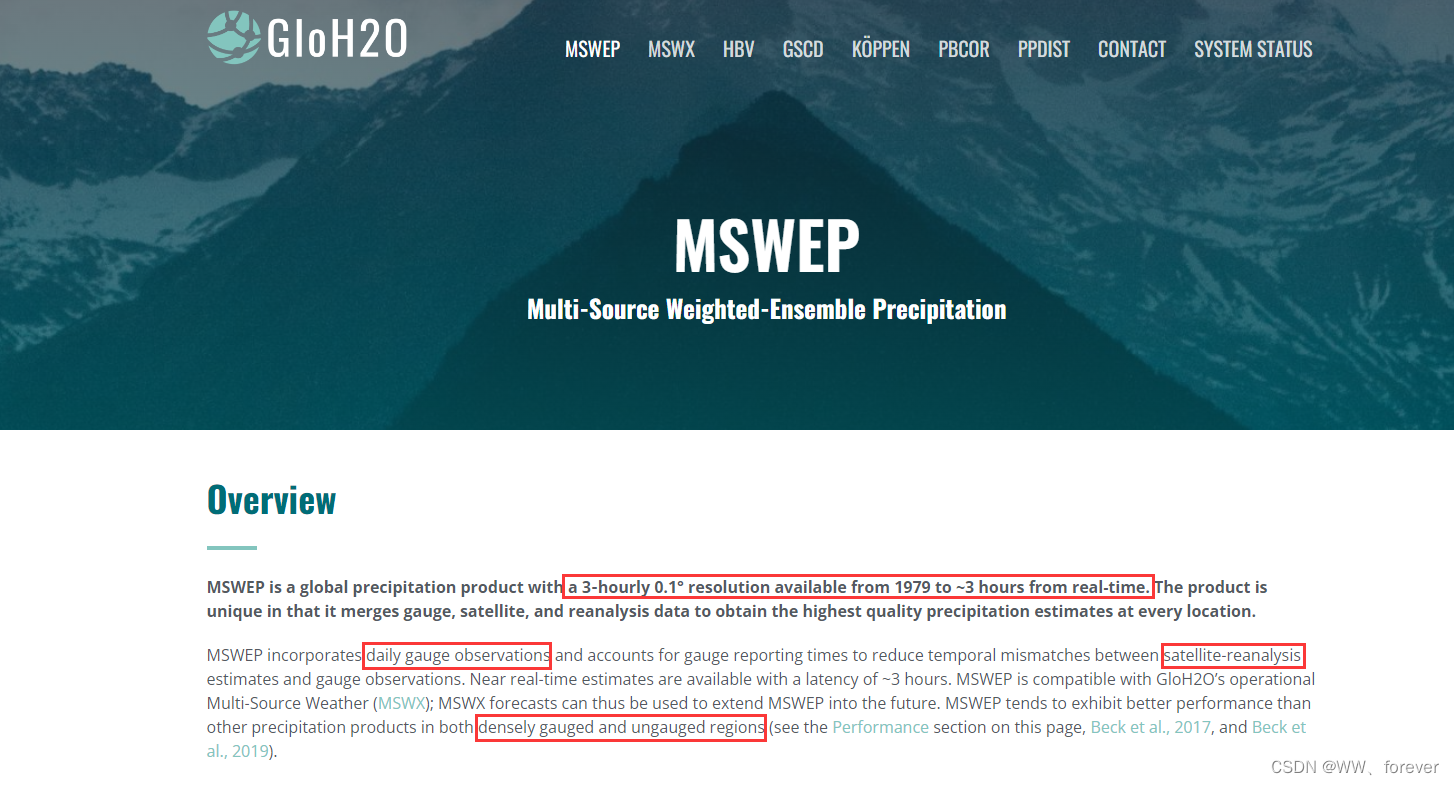
【数据集】3小时尺度降水数据集-MSWEPV2
1 MSWEP V2 precipitation product 官网-MSWEP V2降水产品 参考...
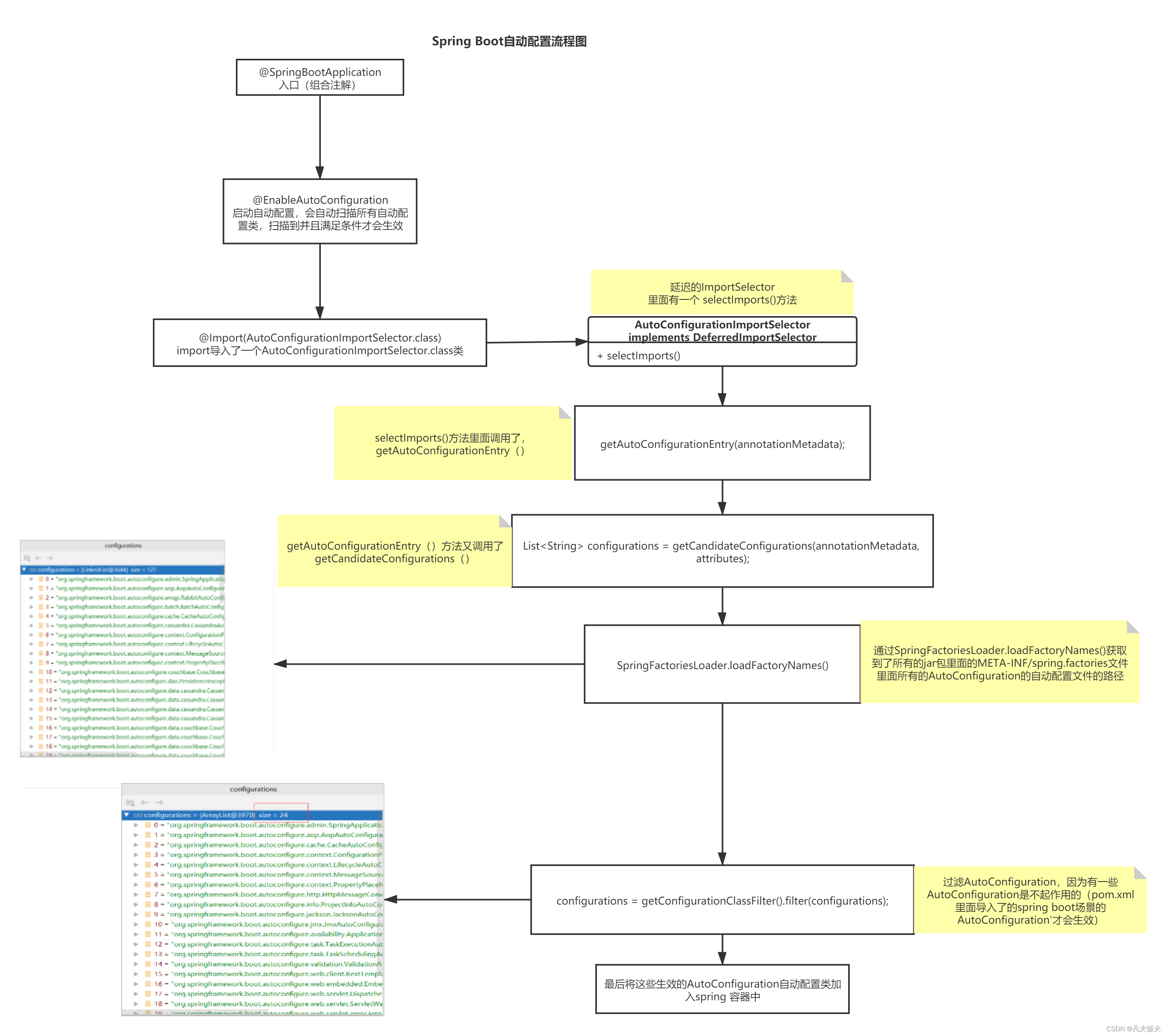
Springboot之把外部依赖包纳入Spring容器管理的两种方式
前言 在Spring boot项目中,凡是标记有Component、Controller、Service、Configuration、Bean等注解的类,Spring boot都会在容器启动的时候,自动创建bean并纳入到Spring容器中进行管理,这样就可以使用Autowired等注解,…...

更安全,更省心丨DolphinDB 数据库权限管理系统使用指南
在数据库产品使用过程中,为保证数据不被窃取、不遭破坏,我们需要通过用户权限来限制用户对数据库、数据表、视图等功能的操作范围,以保证数据库安全性。为此,DolphinDB 提供了具备以下主要功能的权限管理系统: 提供用户…...
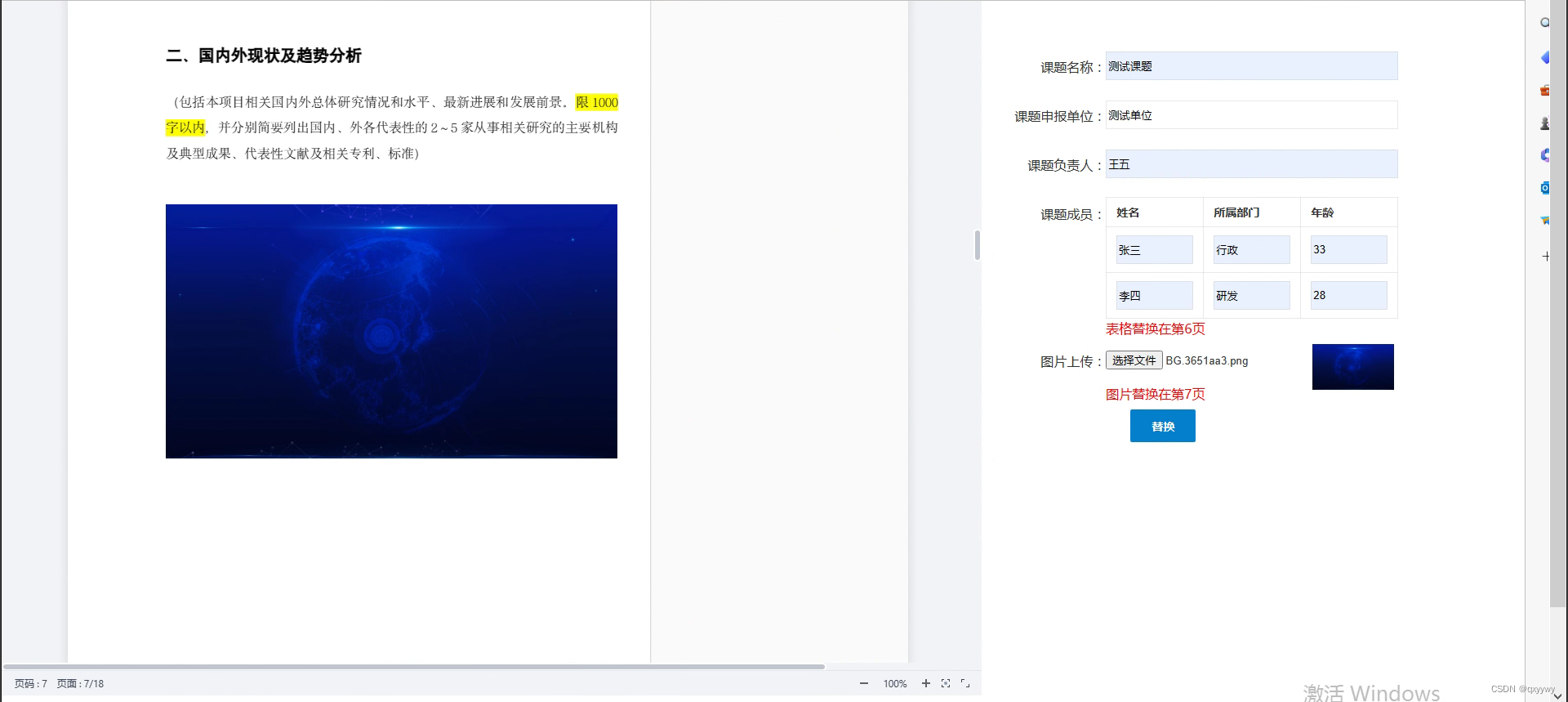
WPS本地镜像化在线文档操作以及样例
一个客户项目有引进在线文档操作需求,让我这边做一个demo调研下,给我的对接文档里有相关方法的说明,照着对接即可。但在真正对接过程中还是踩过不少坑,这儿对之前的对接工作做个记录。 按照习惯先来一个效果: Demo下载…...
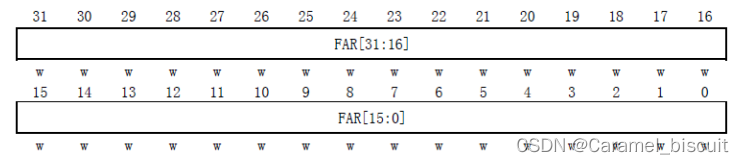
STM32 Flash学习(一)
STM32 FLASH简介 不同型号的STM32,其Flash容量也不同。 MiniSTM32开发板选择的STM32F103RCT6的FLASH容量为256K字节,属于大容量产品。 STM32的闪存模块由:主存储器、信息块和闪存存储器接口寄存器等3部分组成。 主存储器,该部分…...
Spring中IOC容器常用的接口和具体的实现类
在Spring框架没有出现之前,在Java语言中,程序员们创建对象一般都是通过关键字new来完成,那时流行一句话“万物即可new,包括女朋友”。但是这种创建对象的方式维护成本很高,而且对于类之间的相互关联关系很不友好。鉴于…...

【MySQL】索引特性
🌠 作者:阿亮joy. 🎆专栏:《零基础入门MySQL》 🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根 目录 👉没…...

【深度学习笔记】动量梯度下降法
本专栏是网易云课堂人工智能课程《神经网络与深度学习》的学习笔记,视频由网易云课堂与 deeplearning.ai 联合出品,主讲人是吴恩达 Andrew Ng 教授。感兴趣的网友可以观看网易云课堂的视频进行深入学习,视频的链接如下: 神经网络和…...
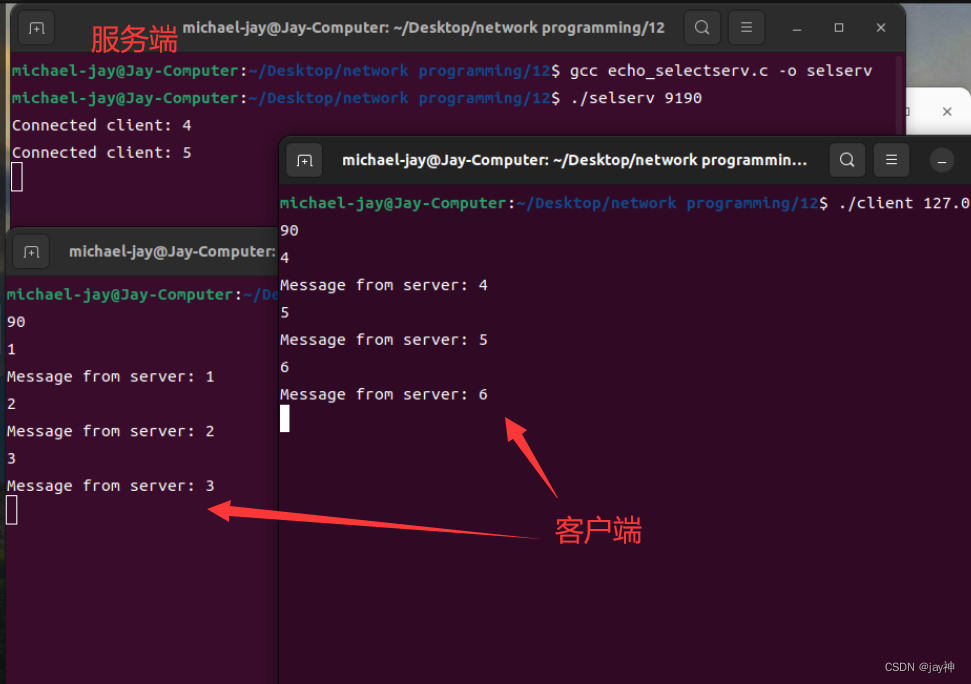
《TCP IP网络编程》第十二章
第 12 章 I/O 复用 12.1 基于 I/O 复用的服务器端 多进程服务端的缺点和解决方法: 为了构建并发服务器,只要有客户端连接请求就会创建新进程。这的确是实际操作中采用的一种方案,但并非十全十美,因为创建进程要付出很大的代价。…...

基于CNN卷积神经网络的调制信号识别算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 1. 卷积神经网络(CNN) 2. 调制信号识别 3.实现过程 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 MATLAB2022A 3.部分核心程序 % 构建调制类型…...

正则,JS:this,同步异步,原型链笔记整理
一 正则表达式 正则表达式(regular expression)是一种表达文本模式(即字符串结构)的方法,有点像字符串的模板,常常用来按照“给定模式”匹配文本 正则表达式可以用于以下常见操作: 匹配&…...

【NOIP】小鱼的数字游戏题解
author:&Carlton tag:递归,栈 topic:【NOIP】小鱼的数字游戏题解 language:C website:洛谷 date:2023年7月29日 目录 我的题解思路 优化 别人的优秀思路: 我的题解思路 题…...
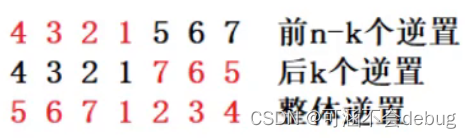
算法的时间复杂度、空间复杂度如何比较?
目录 一、时间复杂度BigO 大O的渐进表示法: 例题一: 例题2: 例题3:冒泡排序的时间复杂度 例题4:二分查找的时间复杂度 书写对数的讲究: 例题5: 实例6: 利用时间复杂度解决编…...

We are the Lights 2023牛客暑期多校训练营4-L
登录—专业IT笔试面试备考平台_牛客网 题目大意:有n*m盏灯,q次操作,每次可以将一整行或一整列的等打开或关闭 1<n,m<1e6;1<q<1e6 思路:对于同一行或者同一列来说,只要最后一次操作时开或者关࿰…...

ant-design-vue中table组件使用customRender渲染v-html
ant-design-vue遇到table中列表数据需要高亮渲染 1、customRender可以使用,但是使用v-html发现不生效还报错 const columns [title: name,dataIndex: name,customRender: (val, row) > {return <span v-html{val}></span>} ]2、customeRender函数…...

若依框架实现后端防止用户重复点击
若依框架实现后端防止用户重复点击 基于自定义注解、切面、Redis实现 1. 添加自定义注解: 代码放置位置:com/ruoyi/common/annotation/RepeatClick.java time: 时间默认0; unit:单位默认 秒; key: 默认空字符串 package com.ruoyi.fra…...

PCA对手写数字数据集的降维
手写数字的数据集结构为(42000, 784),用KNN跑一次半小时,得到准确率在96.6%上下,用随机森林跑一次12秒,准确率在93.8%,虽然KNN效果好,但由于数据量太大,KNN计算太缓慢,所以我们不得不选用随机森林。我们使用了各种技术对手写数据集进行特征选择,最后使用嵌入 法Select…...
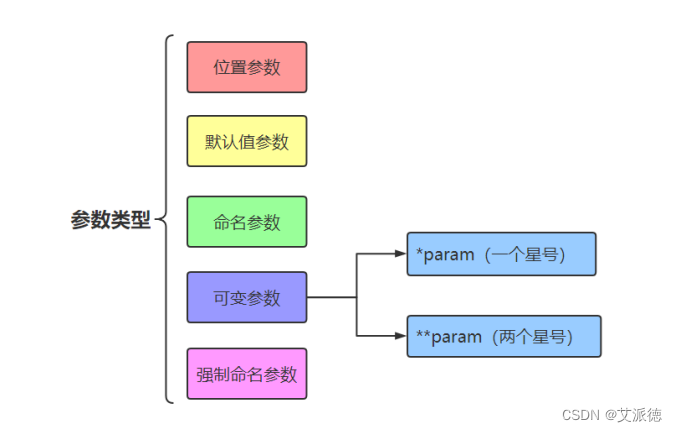
Python入门【变量的作用域(全局变量和局部变量)、参数的传递、浅拷贝和深拷贝、参数的几种类型 】(十一)
👏作者简介:大家好,我是爱敲代码的小王,CSDN博客博主,Python小白 📕系列专栏:python入门到实战、Python爬虫开发、Python办公自动化、Python数据分析、Python前后端开发 📧如果文章知识点有错误…...

echarts中heatmap鼠标滚动禁用缩放,向下滚动
配置如下效果如下...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 [特殊字符]
defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 🚀 【免费下载链接】defx.nvim :file_folder: The dark powered file explorer implementation for neovim/Vim8 项目地址: https://gitcode.com/gh_mirrors/de/defx.nvim defx.nvim …...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对?
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...
)
在线文档协作工具选型必看:14款产品对比(2026版)
一、在线文档协作工具的概念解析及其核心功能 在线文档协作工具是基于云端的文档创建、编辑、共享与协同沟通平台,核心目标是让团队在同一份资料上“实时共同工作”,减少反复传文件、版本混乱与沟通成本。 企业常见的核心能力包括: 多人实…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕
BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法保存B站视频字幕而烦恼࿱…...