PaddleOCR #PP-OCR常见异常扫雷
异常一:ModuleNotFoundError: No module named ‘tools.infer’
实验案例: PaddleOCR #使用PaddleOCR进行光学字符识别(PP-OCR文本检测识别)
参考代码: 图片文本检测实验时,运行代码出现异常:ModuleNotFoundError: No module named ‘tools.infer’
# Importing required libraries.
import cv2
import os
import numpy as np
import sys
import re
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.image as img
import time
import numpy# Importing functions and methods for OCR
from tools.infer.predict_rec import *
import tools.infer.utility as utility
from ppocr.postprocess import build_post_process
from ppocr.utils.logging import get_logger
from ppocr.utils.utility import get_image_file_list, check_and_read_gif
异常信息:
import tools.infer.utility as utility
ModuleNotFoundError: No module named 'tools.infer'
异常原因: 这是由于 python 本来有个 tools,和 paddleocr 内部的 tools 冲突导致。可能是 paddleocr 版本问题,也可能是 python 环境问题。
解决方法:
方法1:找到 paddleocr 文件把所有导入 tools.infer 包的地方的前面加上 paddleocr. 即为 paddleocr.tools.infer
方法2:把 paddleocr/tools 下面的 infer 文件夹移动到 python 本身的 tools 里面
试过方法1,未能成功。
但按下面的方式,将当前目录添加到 python 的模块搜索路径中,可解决脚本方式出现这个异常:
# Importing required libraries.
import cv2
import os
import numpy as np
import sys
import re
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.image as img
import time
import numpy# 获取当前脚本文件的绝对路径所在的目录路径,并将其赋值给变量 __dir__。
__dir__ = os.path.dirname(os.path.abspath(__file__))
# 将当前脚本文件的绝对路径所在的目录路径添加到Python的模块搜索路径中。
sys.path.append(__dir__)
# 将当前脚本文件的上一级目录路径添加到Python的模块搜索路径中。os.path.join(__dir__, '..') 用于获取上一级目录的路径,os.path.abspath() 用于获取绝对路径。
sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '..')))import importlib
tools = importlib.import_module('.', 'tools')
ppocr = importlib.import_module('.', 'ppocr')# Importing functions and methods for OCR
from tools.infer.predict_rec import *
import tools.infer.utility as utility
from ppocr.postprocess import build_post_process
from ppocr.utils.logging import get_logger
from ppocr.utils.utility import get_image_file_list, check_and_read_gif
方法2亲测可行:
1)CMD 通过命令确认本地 python 的 tools 包位置

2)把 paddleocr/tools 下面的 infer 文件夹移动到 python 本身的 tools 文件夹中

注:场景2,CMD 方式的异常场景的原因可能各有不同,主要是因为本地安装的 paddleocr 版本各异。但主要原因可归为版本不兼容,可根据异常提示逐步补全依赖目录或文件解决,但比较繁琐。
异常二:ImportError: cannot import name ‘check_and_read_gif’ from ‘ppocr.utils.utility’
实验案例: PaddleOCR #使用PaddleOCR进行光学字符识别(PP-OCR文本检测识别)
Traceback (most recent call last):File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\runpy.py", line 197, in _run_module_as_mainreturn _run_code(code, main_globals, None,File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\runpy.py", line 87, in _run_codeexec(code, run_globals)File "D:\Tp_Mylocal\20_Install\python-3.9.13\Scripts\paddleocr.exe\__main__.py", line 4, in <module>File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\paddleocr\__init__.py", line 14, in <module>from .paddleocr import *File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\paddleocr\paddleocr.py", line 37, in <module>from tools.infer import predict_systemFile "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\tools\infer\predict_system.py", line 32, in <module>import tools.infer.predict_rec as predict_recFile "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\tools\infer\predict_rec.py", line 33, in <module>from ppocr.utils.utility import get_image_file_list, check_and_read_gif
ImportError: cannot import name 'check_and_read_gif' from 'ppocr.utils.utility' (D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\paddleocr\ppocr\utils\utility.py)
亦或者:
Traceback (most recent call last):File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\runpy.py", line 197, in _run_module_as_mainreturn _run_code(code, main_globals, None,File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\runpy.py", line 87, in _run_codeexec(code, run_globals)File "D:\Tp_Mylocal\20_Install\python-3.9.13\Scripts\paddleocr.exe\__main__.py", line 4, in <module>File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\paddleocr\__init__.py", line 14, in <module>from .paddleocr import *File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\paddleocr\paddleocr.py", line 41, in <module>from ppocr.utils.utility import check_and_read, get_image_file_list
ImportError: cannot import name 'check_and_read' from 'ppocr.utils.utility' (D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\ppocr\utils\utility.py)
异常原因: 此问题八成是你安装的 PaddleOCR 版本不兼容产生的问题,比如可能你通过下面的命令成功安装了 paddleocr、paddlepaddle
pip install paddlepaddle paddleocr
Successfully installed paddleocr-2.6.1.3 paddlepaddle-2.4.2
但通过 CMD 运行时,总是有异常说 xxx 包找不到,或者 xxx 方法引入不到。根本原因就是你执行的路径下的异常文件代码中(比如上述 path\python-3.x.xx\lib\site-packages\paddleocr\paddleocr.py)确实没有这些需要的目录或文件

解决方案:
方案1: 重新安装版本
1)使用 CMD 命令 pip uninstall paddlepaddle paddleocr 卸载 paddleocr
2)安装指定版本的 paddlepaddle
pip install paddlepaddle==2.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
3)安装指定版本的 paddleocr
pip install paddleocr==2.5.0.3
注:如果你本地下载过 opencv、paddleocr 的源码,可通过 paddleocr.py 代码查看你应该需要安装的 paddleocr 版本号:

方案2: 补全依赖目录或文件
根据异常提示,将缺省的文件或方法从源码中拷贝到 CMD 执行环境中,逐步补全依赖目录或文件解决,但比较繁琐。
比如在 paddleocr-2.6.1.3 版本中 paddleocr.py 代码的依赖是
from ppocr.utils.utility import check_and_read, get_image_file_list
但在 ppocr.utils.utility 这个对象中提供的函数却是 check_and_read_gif,自然是会执行异常。
通过方案1或方案2操作后,可通过 paddleocr --help 校验环境是否OK。
异常三:Please use PaddlePaddle with GPU version
实验案例: PaddleOCR #使用PaddleOCR进行光学字符识别(PP-OCR文本检测识别)
D:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR>python ./tools/infer/predict_det.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./inference/ch_PP-OCRv3_rec_infer/"
E0608 16:27:13.135995 15300 analysis_config.cc:110] Please use PaddlePaddle with GPU version.
异常原因: 实验机器不支持GPU模式。
解决方案:
确保你已安装了 CPU 版本的 PaddlePaddle。
通过将 --use_gpu 参数设置为 False,您告诉 PaddleOCR 在 CPU 上运行,不使用 GPU,如:
paddleocr --image_dir ./doc/imgs/japan_2.jpg --use_angle_cls true --use_gpu false
异常四:ModuleNotFoundError: No module named ‘ppocr’
实验案例: PaddleOCR #使用PaddleOCR进行光学字符识别(PP-OCR文本检测识别)
from ppocr.utils.logging import get_logger
ModuleNotFoundError: No module named 'ppocr'
异常信息:
ppocr = importlib.import_module('.', 'ppocr')File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\importlib\__init__.py", line 127, in import_modulereturn _bootstrap._gcd_import(name[level:], package, level)File "<frozen importlib._bootstrap>", line 1030, in _gcd_importFile "<frozen importlib._bootstrap>", line 1007, in _find_and_loadFile "<frozen importlib._bootstrap>", line 984, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'ppocr'
异常原因: ModuleNotFoundError: No module named ‘ppocr’ 错误表明您缺少了名为 ‘ppocr’ 的模块。这可能是由于以下原因之一导致的:
- 缺少依赖库: ‘ppocr’ 模块可能依赖其他库或模块。请确保您已经安装了所有必需的依赖库。您可以通过运行 pip install -r requirements.txt 命令安装项目所需的依赖库。
- 缺少 ‘ppocr’ 模块: 请确保 ‘ppocr’ 模块已经正确地安装在您的环境中。您可以使用 pip list 命令查看已安装的模块列表,确认 ‘ppocr’ 模块是否存在。
- 模块路径问题: 如果 ‘ppocr’ 模块不在默认的模块搜索路径中,您需要将其路径添加到 Python 搜索路径中。可以通过在脚本中添加以下代码来添加模块路径:
import sys
# 请确保将 /path/to/ppocr 替换为实际 'ppocr' 模块所在的路径
sys.path.append('/path/to/ppocr')
注意,请确保将 /path/to/ppocr 替换为实际 ‘ppocr’ 模块所在的路径。如果还是不行,可参考下面的解决方案:
解决方案:
# 获取当前脚本文件的绝对路径所在的目录路径,并将其赋值给变量 __dir__。
__dir__ = os.path.dirname(os.path.abspath(__file__))
# 将当前脚本文件的绝对路径所在的目录路径添加到Python的模块搜索路径中。
sys.path.append(__dir__)
# 将当前脚本文件的上一级目录路径添加到Python的模块搜索路径中。os.path.join(__dir__, '..') 用于获取上一级目录的路径,os.path.abspath() 用于获取绝对路径。
sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '..')))
注:与异常一类似。
异常五:UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xae’ in position 2: illegal multibyte sequence
实验案例: PaddleOCR #使用PaddleOCR进行光学字符识别 - OCR模型对比
异常现象: 在使用 PaddlePaddle-OCRv2 (PP-OCRv2) 进行实验时,出现异常:
[2023/06/09 19:06:19] ppocr INFO: Predicts of ../COCO-text/COCO_test\1087034.jpg:('皖S', 0.4052684009075165)
[2023/06/09 19:06:19] ppocr INFO: Predicts of ../COCO-text/COCO_test\1087141.jpg:('S AVe', 0.7147024273872375)
[2023/06/09 19:06:19] ppocr INFO: Predicts of ../COCO-text/COCO_test\1087170.jpg:('®', 0.054067403078079224)
Traceback (most recent call last):File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\applications\pp_ocr_v2.py", line 156, in <module>rec(utility.parse_args(), out_path, input_org, rec_model_dir, show = False)File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\applications\pp_ocr_v2.py", line 106, in recf.write(str(rec_res[ino]))
UnicodeEncodeError: 'gbk' codec can't encode character '\xae' in position 2: illegal multibyte sequence
异常原因: 这个错误是由于在写入文件时遇到了无法编码的字符导致的。根据错误信息,似乎是在将结果写入文件时遇到了特殊字符 ‘\xae’,导致无法使用 ‘gbk’ 编码进行写入。
解决方案: 尝试修改文件编码方式,将其设置为支持特殊字符的编码方式,例如 encoding='utf-8' 。比如,如果这里现在是写文件遇到特殊字符异常,那么就在读文件时将特殊字符进行 UTF-8 读取。
for ino in range(len(img_list)):logger.info("Predicts of {}:{}".format(valid_image_file_list[ino], rec_res[ino]))if save:cv2.imwrite(os.path.join(out_path, valid_image_file_list[ino].split('/')[-1].split('.')[0] + '_rec' + '.jpg'), img_list[ino])with open(os.path.join(out_path, valid_image_file_list[ino].split('/')[-1].split('.')[0] + '.txt'), 'w', encoding='utf-8') as f:f.write(str(rec_res[ino]))
异常六:ValueError: not find model file path ./inference/rec_r50_vd_srn_train/inference.pdmodel
实验案例: PaddleOCR #使用PaddleOCR进行光学字符识别 - OCR模型对比
[2023/06/12 15:32:34] ppocr INFO: 开始 ...
yes
Traceback (most recent call last):File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\applications\pp_ocr_srn.py", line 156, in <module>rec(utility.parse_args(), out_path, input_org, rec_model_dir, rec_image_shape = '1, 64, 256', rec_char_type = 'en', rec_algorithm = 'SRN', show = False)File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\applications\pp_ocr_srn.py", line 68, in rectext_recognizer = TextRecognizer(args)File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\tools\infer\predict_rec.py", line 74, in __init__utility.create_predictor(args, 'rec', logger)File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\tools\infer\utility.py", line 174, in create_predictorraise ValueError("not find model file path {}".format(
ValueError: not find model file path ./inference/rec_r50_vd_srn_train/inference.pdmodel
异常原因: 该错误提示表明代码无法在指定路径 ./inference/rec_r50_vd_srn_train/inference.pdmodel 中找到所需的模型文件。
解决方案:
1)检查模型文件路径是否正确:确保模型文件 inference.pdmodel 存在于指定的路径 ./inference/rec_r50_vd_srn_train/ 下,并且路径名称的大小写与实际文件系统匹配。如果文件在这个目录下,那么就是相对路径不全导致找不到文件。
2)重新生成模型文件放于当前目前下。
异常七:TypeError: ‘<’ not supported between instances of ‘tuple’ and ‘float’
实验案例: PaddleOCR #使用PaddleOCR进行光学字符识别 - OCR模型对比
异常原因: OCR 图片识别结果的数据结构与源码需要解析取值的数据结构不兼容
解决方案: 移除 OCR 图片识别结果的外部一维
# 图片识别
result = ocr.ocr(img_path)
print("OCR 图片识别结果:", result)# 通过使用 result = result[0] 移除外部的一维来解决 paddleocr\tools\infer\utility.py 文件中 draw_ocr 函数的 TypeError: '<' not supported between instances of 'tuple' and 'float'
result = result[0]
# print("移除一维后图片识别结果:", result)# 保存可视化OCR检测识别结果
save_ocr(img_path, out_path, result, font)
注:异常现象的处理方式与异常八相反
异常八:TypeError: ‘float’ object is not subscriptable
实验案例: PaddleOCR #使用PaddleOCR进行光学字符识别 - OCR模型对比
异常原因: OCR 图片识别结果的数据结构与源码需要解析取值的数据结构不兼容
Traceback (most recent call last):File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\applications\ocr_img_apply.py", line 55, in <module>ocr_img(img_path)File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\applications\ocr_img_util.py", line 49, in ocr_imgsave_ocr(img_path, out_path, result, font)File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\applications\ocr_img_util.py", line 65, in save_ocrtxts = [line[1][0] for line in result]File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\applications\ocr_img_util.py", line 65, in <listcomp>txts = [line[1][0] for line in result]
TypeError: 'float' object is not subscriptable
异常原因: OCR 图片识别结果的数据结构与源码需要解析取值的数据结构不兼容
解决方案: 直接使用 OCR 源码检测识别的结果进行可视化保存
def ocr_img(img_path):print("OCR 图片识别地址:", img_path)# 图片识别result = ocr.ocr(img_path)print("OCR 图片识别结果:", result)# 通过使用 result = result[0] 移除外部的一维来解决 paddleocr\tools\infer\utility.py 文件中 draw_ocr 函数的 TypeError: '<' not supported between instances of 'tuple' and 'float'# result = result[0]# print("移除一维后图片识别结果:", result)# 保存可视化OCR检测识别结果save_ocr(img_path, out_path, result, font)
注:异常现象的处理方式与异常六相反
异常九:AttributeError: module ‘numpy’ has no attribute ‘int’.
实验案例: PaddleOCR #使用PaddleOCR进行光学字符识别(PP-OCR文本检测识别)
Traceback (most recent call last):File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\applications\ocr_img_apply.py", line 55, in <module>ocr_img(img_path)File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\applications\ocr_img_util.py", line 41, in ocr_imgresult = ocr.ocr(img_path)File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\paddleocr.py", line 474, in ocrdt_boxes, rec_res = self.__call__(img, cls)File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\tools\infer\predict_system.py", line 69, in __call__dt_boxes, elapse = self.text_detector(img)File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\tools\infer\predict_det.py", line 242, in __call__File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\ppocr\postprocess\db_postprocess.py", line 188, in __call__boxes, scores = self.boxes_from_bitmap(pred[batch_index], mask,File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\ppocr\postprocess\db_postprocess.py", line 82, in boxes_from_bitmapscore = self.box_score_fast(pred, points.reshape(-1, 2))File "d:\Ct_ iSpace\Tan\opencv\learnopencv-master\Optical-Character-Recognition-using-PaddleOCR\PaddleOCR\ppocr\postprocess\db_postprocess.py", line 140, in box_score_fastxmin = np.clip(np.floor(box[:, 0].min()).astype(np.int), 0, w - 1)File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\numpy\__init__.py", line 305, in __getattr__raise AttributeError(__former_attrs__[attr])
AttributeError: module 'numpy' has no attribute 'int'.
`np.int` was a deprecated alias for the builtin `int`. To avoid this error in existing code, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you
wish to review your current use, check the release note link for additional information.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
异常原因:
在较旧的 NumPy 版本(1.19及更早版本)中,np.int 是合法的别名。但是从 NumPy 1.20 版本开始,np.int 被弃用并引发了警告。从 NumPy 1.21 版本开始,np.int 完全被移除,不再可用。
因此,如果你使用的是 NumPy 1.20或更高版本,将 np.int 替换为 int 是推荐的做法。对于较旧的 NumPy 版本,np.int 仍然可用,但不推荐使用,建议迁移到使用 int 类型。

解决方案:
- 在代码中将 np.int 替换为 int。
- 如果代码中存在其他使用了 np.int 的地方,也需要进行相应的替换。
- 确保你正在使用最新版本的 NumPy 库。
可以使用以下命令升级到最新版本的 NumPy:
pip install --upgrade numpy
或者,升级到指定版本的 NumPy:
pip install numpy==1.21.1

注意:如果你的项目有其他依赖项依赖于较新的 NumPy 版本,降级 NumPy 可能会导致冲突。在执行降级操作之前,请确保你的项目不会受到这种影响,并仔细考虑可能的后果。
opencv源码参考文档: https://learnopencv.com/optical-character-recognition-using-paddleocr/
相关文章:
PaddleOCR #PP-OCR常见异常扫雷
异常一:ModuleNotFoundError: No module named ‘tools.infer’ 实验案例: PaddleOCR #使用PaddleOCR进行光学字符识别(PP-OCR文本检测识别) 参考代码: 图片文本检测实验时,运行代码出现异常:M…...

Qt加载字体文件
本文记录如何使用 Qt 加载外部字体文件,并遍历字体名称和样式名称。 bool LoadFont(const QString& fontPath) {const int fontId QFontDatabase::addApplicationFont(fontPath);if (fontId -1) {return false;}// 遍历字体名和样式名 #if QT_VERSION > QT…...

3ds MAX绘制简单动画
建立一个长方体和茶壶: 在界面右下角点击时间配置: 这是动画制作的必要步骤 选择【自动】,接下来,我们只要在对应的帧改变窗口中图形的位置,就能自动记录该时刻的模样 这就意味着,我们通过电脑记录某几个…...

页面访问控制远程仓库
页面访问权限控制 什么是jwt身份认证 在前后端分离模式的开发中,服务器如何知道来访者的身份呢? 在登录后,服务器会响应给用户一个 令牌 (token)令牌中会包括该用户的id等唯一标识浏览器收到令牌后,自己…...
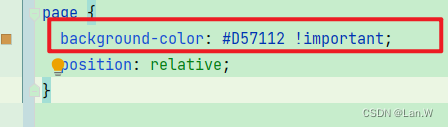
小程序 user agent stylesheet 覆盖了page下wxss背景色
如下图: login页面的page下的背景色,被:user agent stylesheet覆盖。 分析与解决: 1、user agent stylesheet是浏览器默认样式表,是浏览器默认样式。 2、不同浏览器的默认样式不同个,甚至同种浏览器不同版…...
)
Vue.js高阶学习和常用知识(二)
目录 1. Vue 实例2. 组件3. 指令4. 计算属性5. 监听器6. 生命周期钩子 Vue.js 是一个流行的 Web 前端框架,它由 Evan You 于 2014 年创建。Vue.js 的设计目标是简单、灵活和易于使用,同时具有高性能和可扩展性。 Vue.js 基于组件化的思想,将页…...

html实现蜂窝菜单
效果图 CSS样式 keyframes _fade-in_mkmxd_1 {0% {filter: blur(20px);opacity: 0}to {filter: none;opacity: 1} } keyframes _drop-in_mkmxd_1 {0% {transform: var(--transform) translateY(-100px) translateZ(400px)}to {transform: var(--transform)} } ._examples_mkmx…...

云原生训练营课程大纲
第一部分:Go 语****言基础 模块一:Go 语言特性 教学目标: 理解 Go 语言基本语法 理解 Go 语言常用数据类型 理解 Go 语言常用小技巧 深入理解 Go 语言的多线程编程 针对的用户痛点: 云原生从业者因为未熟练掌握 Go 语言&#…...

【Ajax】笔记-同源策略
同源策略(Same-Origin Policy),是浏览器的一种安全策略 同源(即url相同):协议、域名、端口号 必须完全相同。(请求是来自同一个服务) 跨域:违背了同源策略,即跨域。 ajax请求是遵循…...
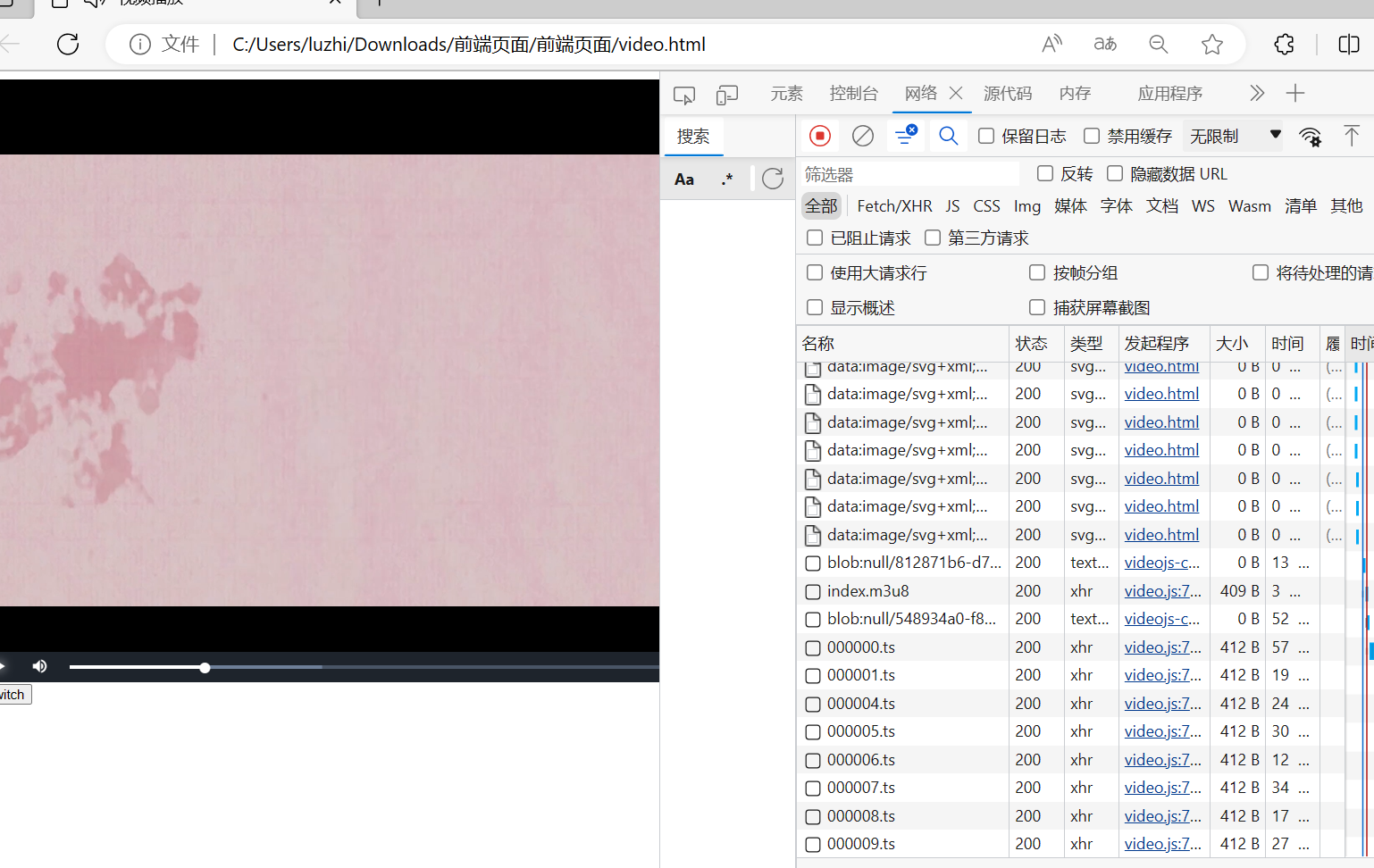
Java使用FFmpeg实现mp4转m3u8
Java使用FFmpeg实现mp4转m3u8 前言FFmpegM3U8 一、需求及思路分析二、安装FFmpeg1.windows下安装FFmpeg2.linux下安装FFmpegUbuntuCentOS 三、代码实现1.引入依赖2.修改配置文件3.工具类4.Controlle调用5.Url转换MultipartFile的工具类 四、播放测试1.html2.nginx配置3.效果展示…...
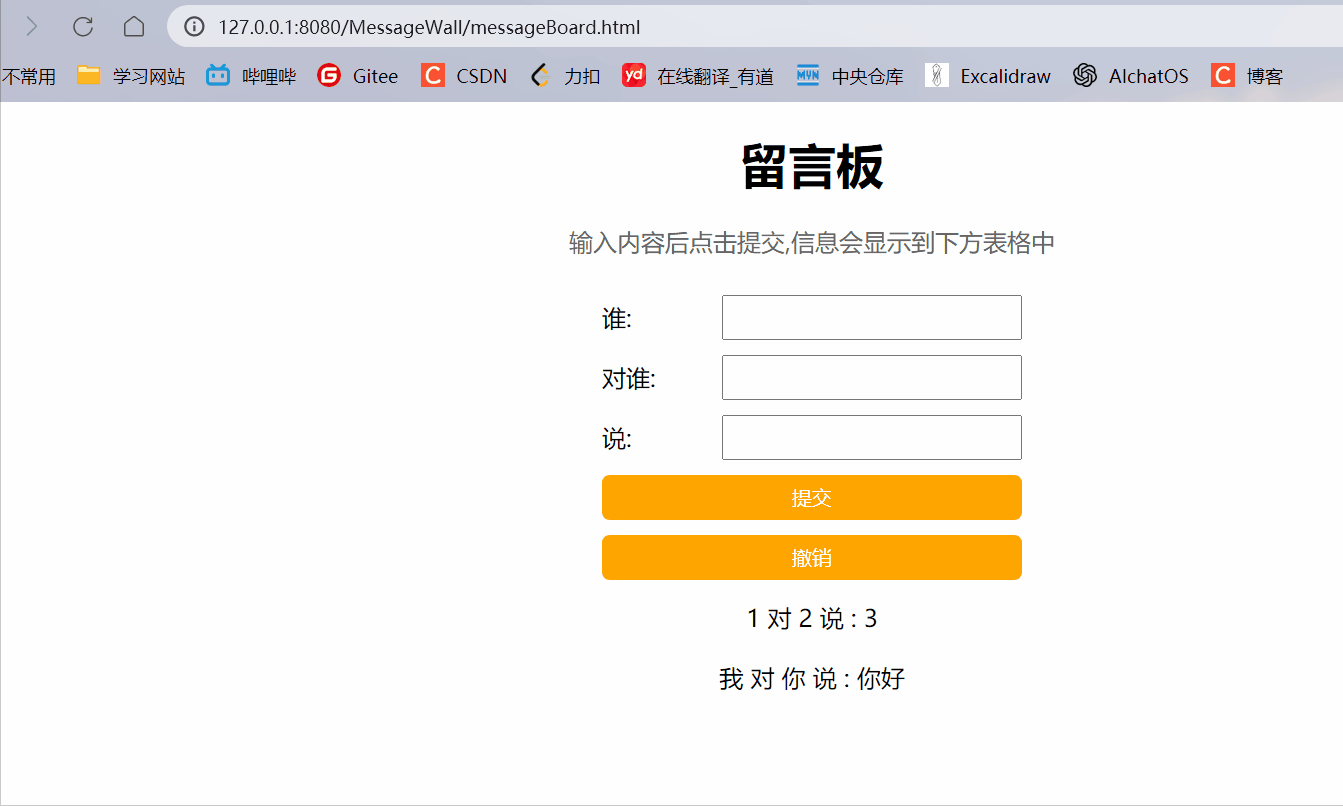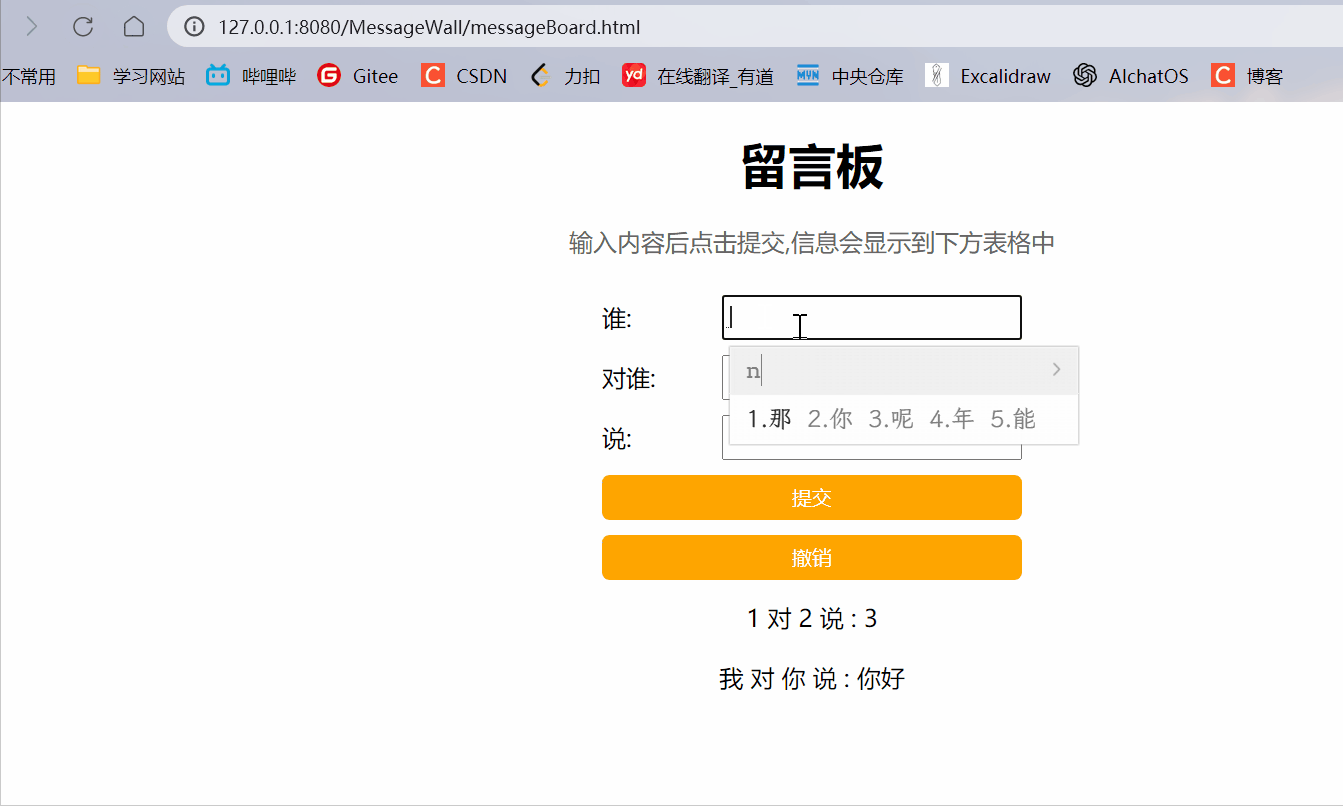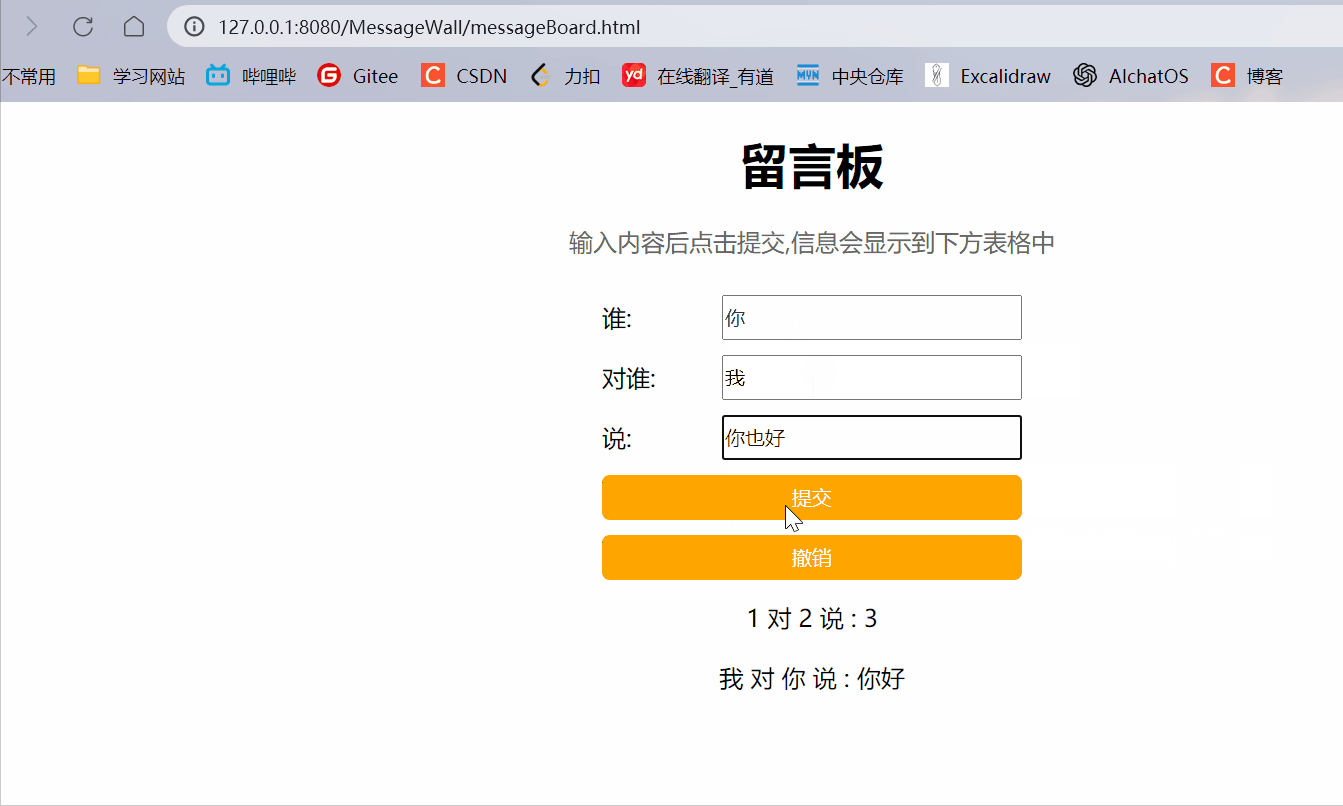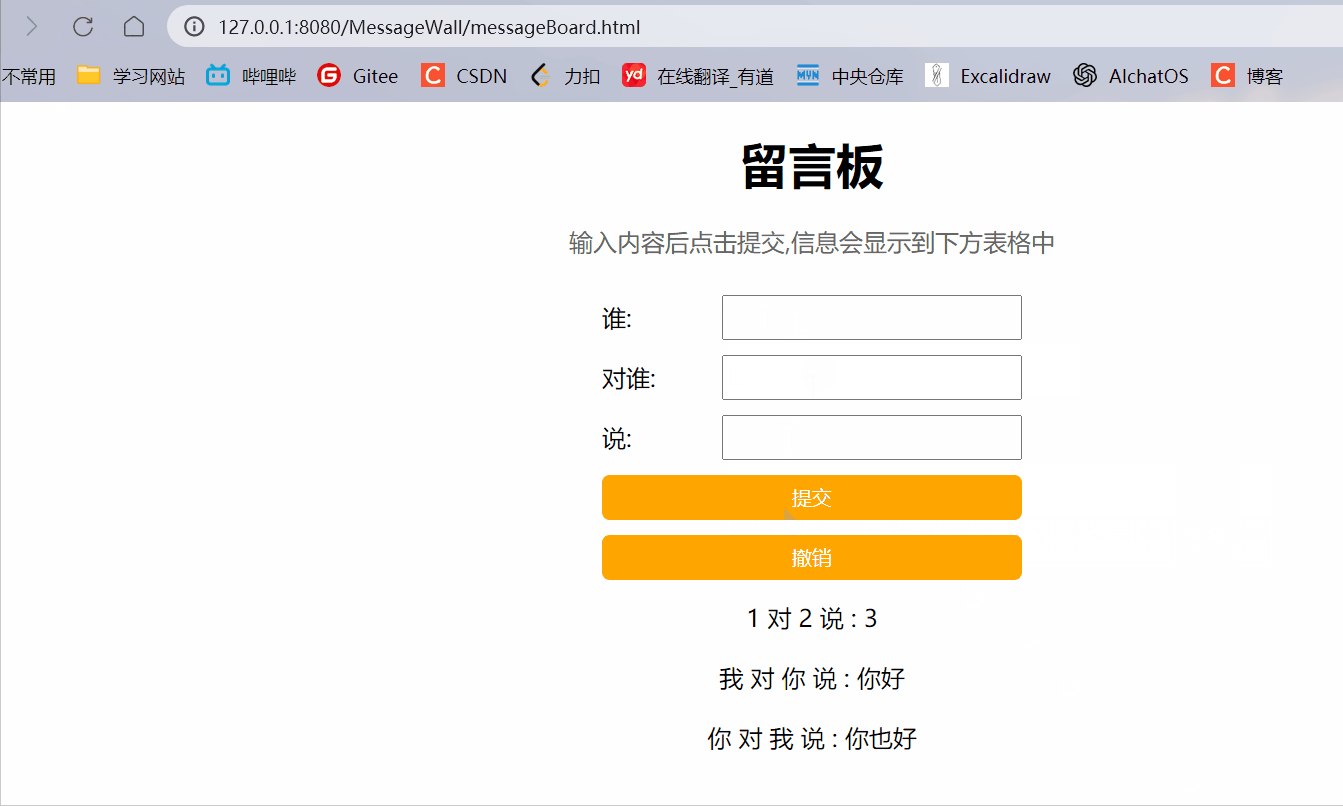
【JavaEE初阶】Servlet (三)MessageWall
在我们之前博客中写到的留言墙页面,有很严重的问题:(留言墙博客) 如果刷新页面/关闭页面重开,之前输入的消息就不见了.如果一个机器上输入了数据,第二个机器上是看不到的. 针对以上问题,我们的解决思如如下: 让服务器来存储用户提交的数据,由服务器保存. 当有新的浏览器打开页…...

D. Make It Round
在Berlandia发生了通货膨胀,所以商店需要改变商品的价格。 商品n的当前价格已经给出。允许将该商品的价格提高k倍,1≤k≤m,k为整数。输出商品的最圆的可能的新价格。也就是在最后有最大数量的零的那个。 例如,数字481000比数字1…...

Python网站页面开发HTML总结
Python网站页面开发HTML总结 一、HTML基础语法 1.HTML是什么? ●HTML是HyperText Mark-up Language的首字母简写,即超文本标记语言。 ●HTML不是一种编程语言,而是一种标记语言。 ●超文本指的是超链接,标记指的是标签…...
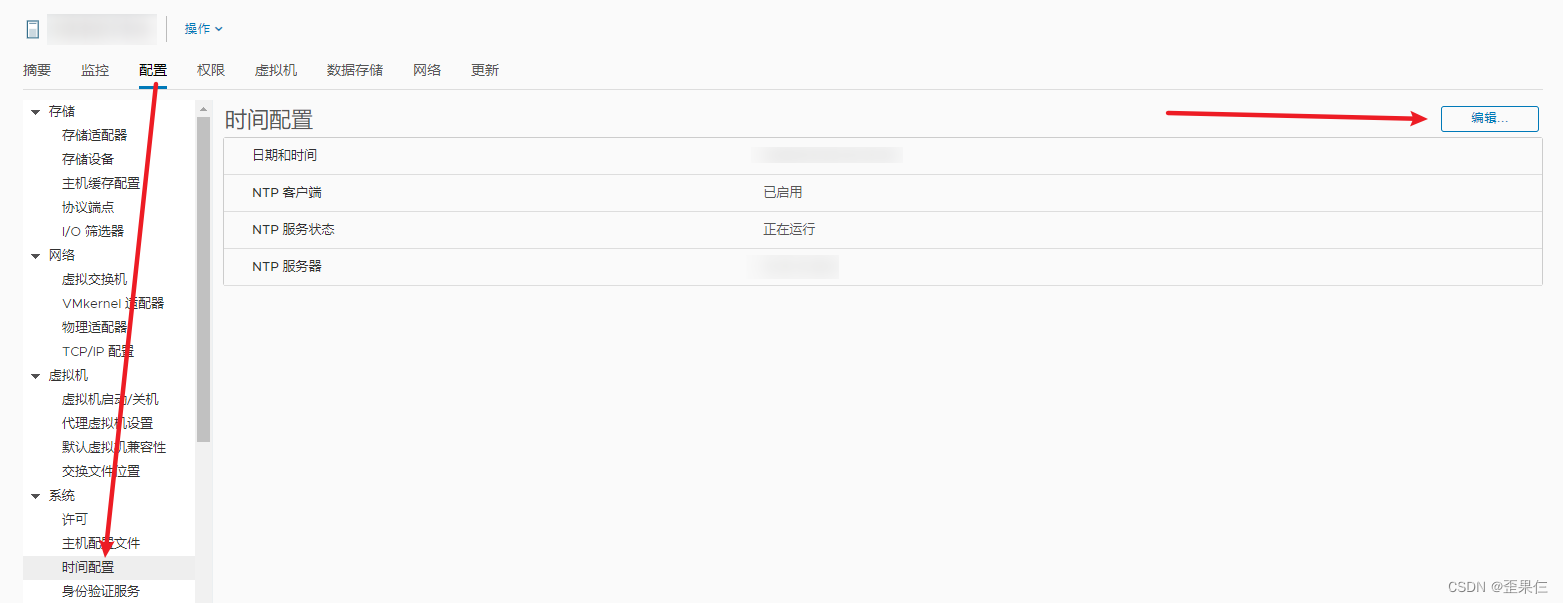
[个人笔记] vCenter设置时区和NTP同步
VMware虚拟化 - 运维篇 第三章 vCenter设置时区和NTP同步 VMware虚拟化 - 运维篇系列文章回顾vCenter设置时区和NTP同步(附加)ESXi设置alias参考链接 系列文章回顾 第一章 vCenter给虚机添加RDM磁盘 第二章 vCenter回收活跃虚拟机的剩余可用空间 vCente…...
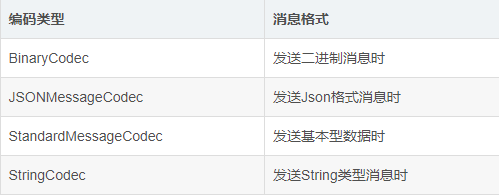
(原创)Flutter与Native通信的方式:EventChannel和BasicMessageChannel
前言 上一篇博客主要介绍了MethodChannel的使用方式 Flutter与Native通信的方式:MethodChannel 这篇博客接着讲另外两种通信方式 EventChannel和BasicMessageChannel EventChannel用于从native向flutter发送通知事件,例如flutter通过其监听Android的重…...
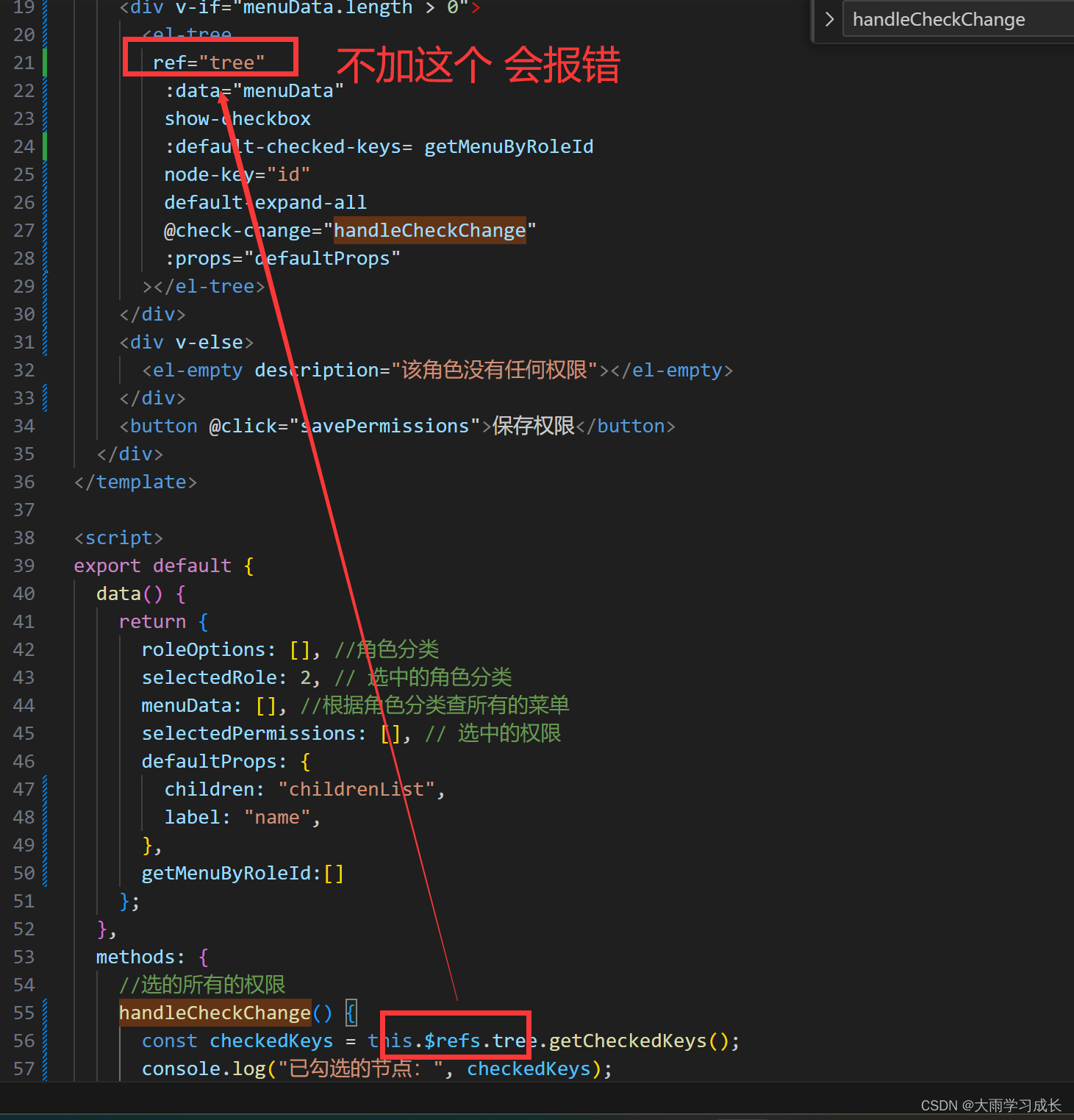
【解决】el-tree报Cannot read property ‘getCheckedKeys‘ of undefined
如果你报错 Cannot read property getCheckedKeys of undefined 或者 Cannot read property getCheckedNodes of undefined 只要在你的在<el-tree>上加个这个,就可以了 ref"tree"...

车载软件架构 —— 信息安全与基础软件
车载软件架构 —— 信息安全与基础软件 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 没有人关注你。也无需有人关注你。你必须承认自己的价值,你不能站在他人的角度来反对自己。人生在世,最怕…...
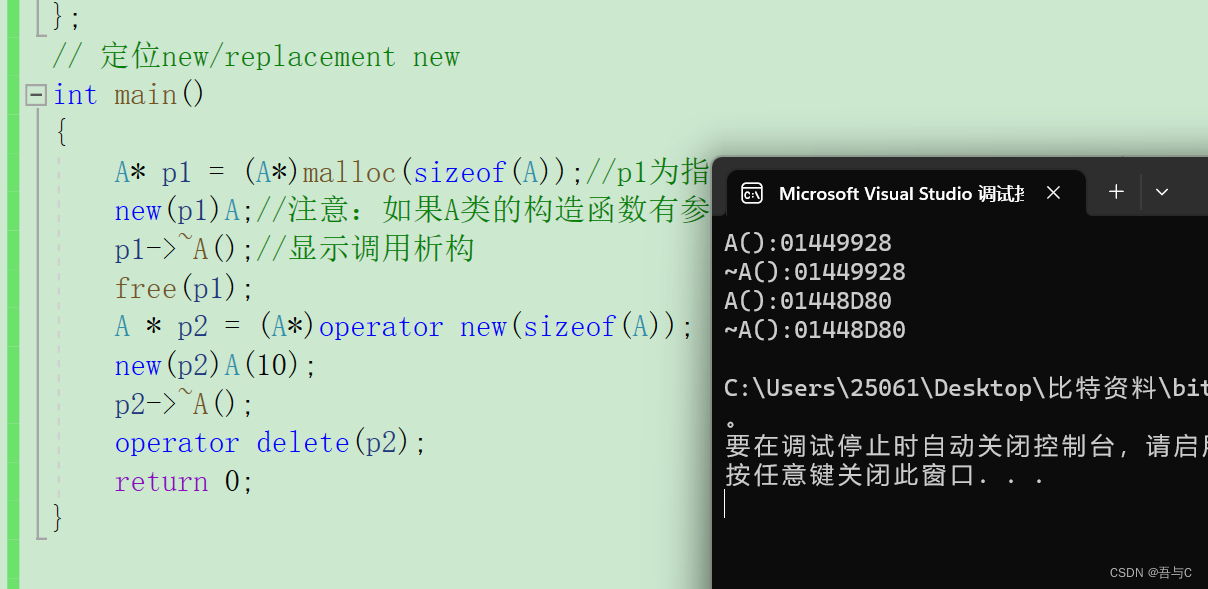
C\C++内存管理
目录 1.C/C内存分布2.C语言中动态内存管理方式3.C中动态内存管理3.1new/delete内置类型3.2new和delete操作自定义类型 4.operator new与operator delete函数4.2重载operator new与operator delete(了解) 5.new和delete的实现原理5.1内置类型5.2 自定义类…...

会议室预约系统-检验是否被预约核心SQL
会议室预约时,判断能否被预约,即查询是否已经有预约记录,存在不能被预约。 s,e;表示已经预约的开始结束时间; ns,ne,表示表单提交的预约时间; 只需要(ns,ne)与(s,e)区间没有交集,可…...

C++11类模板
类模板是用来生成类的蓝图,与函数模板的不同之处是,编译器不能为类模板推断模板参数类型。 所以我们在使用类的时候要带上<>并且指定类型如下 vector<int> v; // 需要带上<int> 哦定义类模板 如下,和函数模板差不多都是…...
)
YOLOv8道路交通信号标志识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 道路交通信号标志的自动检测是智能驾驶与交通管理系统中的核心环节。本文基于YOLOv8目标检测算法,构建了一个涵盖21类常见交通信号标志的检测系统,包括禁令标志、指示标志、警告标志及信号灯等。模型在包含1376张训练图像、488张验证图像和229张测…...

揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式
更多请点击: https://intelliparadigm.com 第一章:揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式 Midjourney V6 在启用云雾(mist/fog/haze)类视觉效果时,…...

3步掌握ROS虚拟机器人:零硬件算法验证全攻略
3步掌握ROS虚拟机器人:零硬件算法验证全攻略 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 想象一下这个场景:深夜两点,你终于调试完了最新的SLAM算法,准备在真实机器人上…...

如何5分钟搭建暗黑破坏神2存档编辑器:终极可视化解决方案指南
如何5分钟搭建暗黑破坏神2存档编辑器:终极可视化解决方案指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑破坏神2复杂的存档编辑而烦恼吗?想要自由调整角色属性却无从下手?d2s-…...

10分钟掌握D3KeyHelper:告别手酸,暗黑3游戏效率翻倍的终极指南
10分钟掌握D3KeyHelper:告别手酸,暗黑3游戏效率翻倍的终极指南 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗…...

从自然语言到可视化洞察:ChartGPT如何用AI重构数据图表生成范式
从自然语言到可视化洞察:ChartGPT如何用AI重构数据图表生成范式 【免费下载链接】chart-gpt AI tool to build charts based on text input 项目地址: https://gitcode.com/gh_mirrors/ch/chart-gpt 在数据驱动的决策时代,业务人员与技术团队之间…...
)
别再只用JSON了!用Protobuf给Go微服务接口性能提升10倍(附完整代码)
别再只用JSON了!用Protobuf给Go微服务接口性能提升10倍(附完整代码) 在微服务架构中,接口性能往往是决定系统吞吐量的关键因素。许多开发者习惯性地使用JSON作为数据交换格式,却不知道这可能在无形中成为性能瓶颈。本…...

c++乱码问题
大家下载vs2026或者更新时,可能会出现乱码问题点击工具,进入选项,在环境列表里找到文档,下滑到底部,勾选使用特定编码保存文件然后退出就可以了。如果还是存在问题,将自己的代码保存,重新新建一…...

Beyond Compare 5完整激活教程:3种方法快速生成永久授权密钥
Beyond Compare 5完整激活教程:3种方法快速生成永久授权密钥 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 还在为Beyond Compare 5的30天试用期结束后无法继续使用而烦恼吗&#x…...

告别U盘!用CentOS 7.9 + iPXE + dnsmasq搭建一个能同时装CentOS 7、AlmaLinux 8和Ubuntu 22.04的万能PXE服务器
打造全能PXE装机服务器:CentOS 7.9iPXEdnsmasq混合系统部署指南 当机房里的服务器数量超过两位数时,U盘安装系统就像用滴管给游泳池注水——效率低得令人发指。我曾用三个通宵手动安装了50台服务器,直到发现PXE网络装机这个"工业级"…...