Mongodb 多文档聚合操作处理方法二(Map-reduce 函数)
聚合
聚合操作处理多个文档并返回计算结果。您可以使用聚合操作来:
-
将多个文档中的值分组在一起。
-
对分组数据执行操作以返回单个结果。
-
分析数据随时间的变化。
要执行聚合操作,您可以使用:
-
聚合管道
-
单一目的聚合方法
-
Map-reduce 函数
Map-reduce 函数
在mongoshell 中,该db.collection.mapReduce() 方法是命令的包装器mapReduce。下面的例子使用该db.collection.mapReduce()方法。
定义: db.collection.mapReduce(map,reduce, { <options> })
该map功能有以下要求:
-
在map函数中,将当前文档引用为函数中的this。
-
该map函数不应出于任何原因访问数据库。
-
该map函数应该是纯粹的,或者对函数之外没有影响(即副作用)。
-
该map函数可以选择调用emit(key,value)任意次数来创建key与关联的输出文档value。
# 原型如下:
function() {...emit(key, value);
}
该reduce函数表现出以下行为:
-
该reduce函数不应访问数据库,即使是执行读取操作。
-
该reduce功能不应影响外部系统。
-
reduceMongoDB 可以针对同一个键多次调用该函数。在这种情况下,该键的函数的先前输出将成为该键的reduce 下一个函数调用的输入值之一 。
-
该reduce函数可以访问参数中定义的变量scope。
# 该reduce函数具有以下原型:
function(key, values) {...return result;
}
插入测试数据。如下:
sit_rs1:PRIMARY> db.orders.insertMany([
... { _id: 1, cust_id: "A", ord_date: new Date("2023-06-01"), price: 15, items: [ { sku: "apple", qty: 5, price: 2.5 }, { sku: "apples", qty: 5, price: 2.5 } ], status: "1" },
... { _id: 2, cust_id: "A", ord_date: new Date("2023-06-08"), price: 60, items: [ { sku: "apple", qty: 8, price: 2.5 }, { sku: "banana", qty: 5, price: 10 } ], status: "1" },
... { _id: 3, cust_id: "B", ord_date: new Date("2023-06-08"), price: 55, items: [ { sku: "apple", qty: 10, price: 2.5 }, { sku: "pears", qty: 10, price: 2.5 } ], status: "1" },
... { _id: 4, cust_id: "B", ord_date: new Date("2023-06-18"), price: 26, items: [ { sku: "apple", qty: 10, price: 2.5 } ], status: "1" },
... { _id: 5, cust_id: "B", ord_date: new Date("2023-06-19"), price: 40, items: [ { sku: "banana", qty: 5, price: 10 } ], status: "1"},
... { _id: 6, cust_id: "C", ord_date: new Date("2023-06-19"), price: 38, items: [ { sku: "carrots", qty: 10, price: 1.0 }, { sku: "apples", qty: 10, price: 2.5 } ], status: "1" },
... { _id: 7, cust_id: "C", ord_date: new Date("2023-06-20"), price: 21, items: [ { sku: "apple", qty: 10, price: 2.5 } ], status: "1" },
... { _id: 8, cust_id: "D", ord_date: new Date("2023-06-20"), price: 76, items: [ { sku: "banana", qty: 5, price: 10 }, { sku: "apples", qty: 10, price: 2.5 } ], status: "1" },
... { _id: 9, cust_id: "D", ord_date: new Date("2023-06-20"), price: 51, items: [ { sku: "carrots", qty: 5, price: 1.0 }, { sku: "apples", qty: 10, price: 2.5 }, { sku: "apple", qty: 10, price: 2.5 } ], status: "1" },
... { _id: 10, cust_id: "D", ord_date: new Date("2023-06-23"), price: 23, items: [ { sku: "apple", qty: 10, price: 2.5 } ], status: "1" }
... ])
{"acknowledged" : true,"insertedIds" : [1,2,3,4,5,6,7,8,9,10]
}
sit_rs1:PRIMARY> db.orders.find()
{ "_id" : 4, "cust_id" : "B", "ord_date" : ISODate("2023-06-18T00:00:00Z"), "price" : 26, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 6, "cust_id" : "C", "ord_date" : ISODate("2023-06-19T00:00:00Z"), "price" : 38, "items" : [ { "sku" : "carrots", "qty" : 10, "price" : 1 }, { "sku" : "apples", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 1, "cust_id" : "A", "ord_date" : ISODate("2023-06-01T00:00:00Z"), "price" : 15, "items" : [ { "sku" : "apple", "qty" : 5, "price" : 2.5 }, { "sku" : "apples", "qty" : 5, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 2, "cust_id" : "A", "ord_date" : ISODate("2023-06-08T00:00:00Z"), "price" : 60, "items" : [ { "sku" : "apple", "qty" : 8, "price" : 2.5 }, { "sku" : "banana", "qty" : 5, "price" : 10 } ], "status" : "1" }
{ "_id" : 9, "cust_id" : "D", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 51, "items" : [ { "sku" : "carrots", "qty" : 5, "price" : 1 }, { "sku" : "apples", "qty" : 10, "price" : 2.5 }, { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 3, "cust_id" : "B", "ord_date" : ISODate("2023-06-08T00:00:00Z"), "price" : 55, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 }, { "sku" : "pears", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 5, "cust_id" : "B", "ord_date" : ISODate("2023-06-19T00:00:00Z"), "price" : 40, "items" : [ { "sku" : "banana", "qty" : 5, "price" : 10 } ], "status" : "1" }
{ "_id" : 7, "cust_id" : "C", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 21, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 8, "cust_id" : "D", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 76, "items" : [ { "sku" : "banana", "qty" : 5, "price" : 10 }, { "sku" : "apples", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 10, "cust_id" : "D", "ord_date" : ISODate("2023-06-23T00:00:00Z"), "price" : 23, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
示例:按客户统计
对集合 orders 执行map-reduce操作, 按 cust_id 进行分组, 然后统计每个客户的 price 计算总和,如下:
首先, 我们需要 定义map函数来处理每个输入文档:
- 在函数中,this指的是map-reduce操作正在处理的文档。
- 该函数将每个文档的 price 映射为 cust_id,并发出 cust_id 和 price 。
sit_rs1:PRIMARY> var myMapFun = function() {
... emit(this.cust_id, this.price);
... };sit_rs1:PRIMARY> print(myMapFun)
function() {emit(this.cust_id, this.price);
}
然后,用两个参数 keyCustId 和 valuesPrices 定义相应的reduce函数。 这里需要调用数组的 sum 方法计算客户订单总价。
- valuesPrices 是一个数组,其元素是map函数发出的price 字段的值,并按 keyCustId 分组。
- 该函数将 valuesPrice 数组缩减为其元素的总和
# 计算数组元素总和
sit_rs1:PRIMARY> Array.sum([2,2,6,8])
18# 计算数组平均值
sit_rs1:PRIMARY> Array.avg([1,2,3])
2sit_rs1:PRIMARY> var myReduceFun = function(keyCustId, valuesPrices) {
... return Array.sum(valuesPrices);
... };sit_rs1:PRIMARY> print(myReduceFun)
function(keyCustId, valuesPrices) {return Array.sum(valuesPrices);
}
最后,使用 myMapFun 函数和 myReduceFun 函数对集合 orders 中的所有文档执行map-reduce统计:
- out: 指定map-reduce操作结果的位置。您可以输出到集合、通过操作输出到集合或内联输出。
- 此操作将结果输出到名为 的集合 map_reduce_out。如果该 map_reduce_out 集合已存在,则该操作将使用此 Map-Reduce 操作的结果替换内容。
sit_rs1:PRIMARY> db.orders.mapReduce(
... myMapFun,
... myReduceFun,
... { out: "map_reduce_out" }
... )
{"result" : "map_reduce_out","ok" : 1,"$clusterTime" : {"clusterTime" : Timestamp(1690259241, 6),"signature" : {"hash" : BinData(0,"Kur+ueslJYcT5oExd8ujPIC/J3Q="),"keyId" : NumberLong("7205479298910650370")}},"operationTime" : Timestamp(1690259241, 6)
}
查询 map_reduce_out 集合以验证结果是否正确:
sit_rs1:PRIMARY> db.map_reduce_out.find().sort( { _id: 1 } )
{ "_id" : "A", "value" : 75 }
{ "_id" : "B", "value" : 121 }
{ "_id" : "C", "value" : 59 }
{ "_id" : "D", "value" : 150 }# 检查 cust_id 为 A 的客户, 总和是 75 正确
sit_rs1:PRIMARY> db.orders.find({ "cust_id" : "A"}, {"price": 1})
{ "_id" : 1, "price" : 15 }
{ "_id" : 2, "price" : 60 }# 检查 cust_id 为 B 的客户,总和是 121 正确
sit_rs1:PRIMARY> db.orders.find({ "cust_id" : "B"}, {"price": 1})
{ "_id" : 4, "price" : 26 }
{ "_id" : 3, "price" : 55 }
{ "_id" : 5, "price" : 40 }示例:按日期统计
按日期统计,和上面示例一样,只需要把 map 函数重新定义如下,将每个文档的 price 映射为 ord_date,并发出 ord_date 和 price 。
sit_rs1:PRIMARY> var myMapFun2 = function() {
... emit(this.ord_date, this.price);
... };sit_rs1:PRIMARY> print(myMapFun2)
function() {emit(this.ord_date, this.price);
}
然后,用两个参数 keyOrdDate 和 valuesPrices 定义相应的reduce函数。 这里需要调用数组的 avg 方法计算平均客单价。
- valuesPrices 是一个数组,其元素是map函数发出的 price 字段的值,并按 keyOrdDate 分组。
- 该函数将 valuesPrice 数组缩减为其元素的总和的平均值
sit_rs1:PRIMARY> var myReduceFun2 = function(keyOrdDate, valuesPrices) {
... return Array.avg(valuesPrices);
... };sit_rs1:PRIMARY> print(myReduceFun2)
function(keyOrdDate, valuesPrices) {return Array.avg(valuesPrices);
}
最后,使用 myMapFun2 函数和 myReduceFun2 函数对集合 orders 中的所有文档执行map-reduce统计:
sit_rs1:PRIMARY> db.orders.mapReduce(
... myMapFun2,
... myReduceFun2,
... { out: "map_reduce_out2" }
... )
{"result" : "map_reduce_out2","ok" : 1,"$clusterTime" : {"clusterTime" : Timestamp(1690265083, 8),"signature" : {"hash" : BinData(0,"pCWskY3HjLGEjSk00ARYdZKECDE="),"keyId" : NumberLong("7205479298910650370")}},"operationTime" : Timestamp(1690265083, 8)
}
查询 map_reduce_out2 集合以验证结果是否正确:
sit_rs1:PRIMARY> db.map_reduce_out2.find()
{ "_id" : ISODate("2023-06-08T00:00:00Z"), "value" : 57.5 }
{ "_id" : ISODate("2023-06-01T00:00:00Z"), "value" : 15 }
{ "_id" : ISODate("2023-06-18T00:00:00Z"), "value" : 26 }
{ "_id" : ISODate("2023-06-20T00:00:00Z"), "value" : 49.333333333333336 }
{ "_id" : ISODate("2023-06-23T00:00:00Z"), "value" : 23 }
{ "_id" : ISODate("2023-06-19T00:00:00Z"), "value" : 39 }# 检查日期2023-06-08的订单平均值
sit_rs1:PRIMARY> db.orders.find({ "ord_date" : ISODate("2023-06-08T00:00:00Z")}, {"price": 1})
{ "_id" : 2, "price" : 60 }
{ "_id" : 3, "price" : 55 }
sit_rs1:PRIMARY> print((60+55)/2)
57.5# 检查日期2023-06-20的订单平均值
sit_rs1:PRIMARY> db.orders.find({ "ord_date" : ISODate("2023-06-20T00:00:00Z")}, {"price": 1})
{ "_id" : 9, "price" : 51 }
{ "_id" : 7, "price" : 21 }
{ "_id" : 8, "price" : 76 }sit_rs1:PRIMARY> print((51+21+76)/3)
49.333333333333336
对于需要自定义功能的 Map-Reduce 操作,MongoDB 从 4.4 版本开始提供 $accumulator 和 $function 聚合运算符。使用这些运算符在 JavaScript 中自定义聚合表达式。
-
聚合管道作为 Map-Reduce 的替代方案, 聚合管道提供比 Map-Reduce 操作更好的性能和可用性。
-
可以使用聚合管道运算符(例如 $group、$merge等)重写 Map-reduce 操作。
相关文章:
)
Mongodb 多文档聚合操作处理方法二(Map-reduce 函数)
聚合 聚合操作处理多个文档并返回计算结果。您可以使用聚合操作来: 将多个文档中的值分组在一起。 对分组数据执行操作以返回单个结果。 分析数据随时间的变化。 要执行聚合操作,您可以使用: 聚合管道 单一目的聚合方法 Map-reduce 函…...

ant design vue j-modal 修改高度
问题描述 今天在项目中遇到关于j-modal组件修改弹窗大小问题,我尝试使用直接使用:height"300",没用效果,弹窗大小依然和没改之前一样,后来找到了这种方式可以去修改j-modal弹窗大小,下面来看下代码实现&…...

spring学习笔记七
一、自动装配 1.1、BookDao接口和实现类 public interface BookDao {void save(); } public class BookDaoImpl implements BookDao {public void save(){System.out.println("book dao save......");} } 1.2、BookService接口和实现类 public interface BookSer…...

hw技战法整理参考
目录 IP溯源反制 账户安全策略及预警 蜜罐部署联动方案...

uniapp 全局数据(globalData)的设置,获取,更改
globalData,这是一种简单的全局变量机制。这套机制在uni-app里也可以使用,并且全端通用 因为uniapp基本上都是将页面,或者页面中相同的部分,进行组件化,所以会存在父,子,(子…...
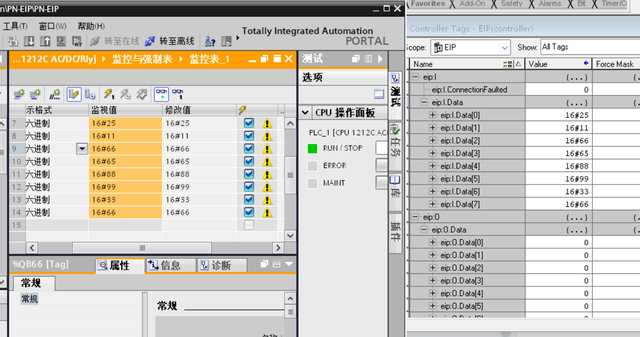
Profinet转EtherNet/IP网关连接AB PLC的应用案例
西门子S7-1500 PLC(profinet)与AB PLC以太网通讯(EtherNet/IP)。本文主要介绍捷米特JM-EIP-PN的Profinet转EtherNet/IP网关,连接西门子S7-1500 PLC与AB PLC 通讯的配置过程,供大家参考。 1, 新建工程&…...

Python组合模式介绍、使用方法
一、Python组合模式介绍 概念: 组合模式(Composite Pattern)是一种结构型设计模式,它通过将对象组合成树状结构来表示“整体/部分”层次结构,让客户端可以以相同的方式处理单个对象和组合对象。 功能: 统一对待组合对象和叶子对…...
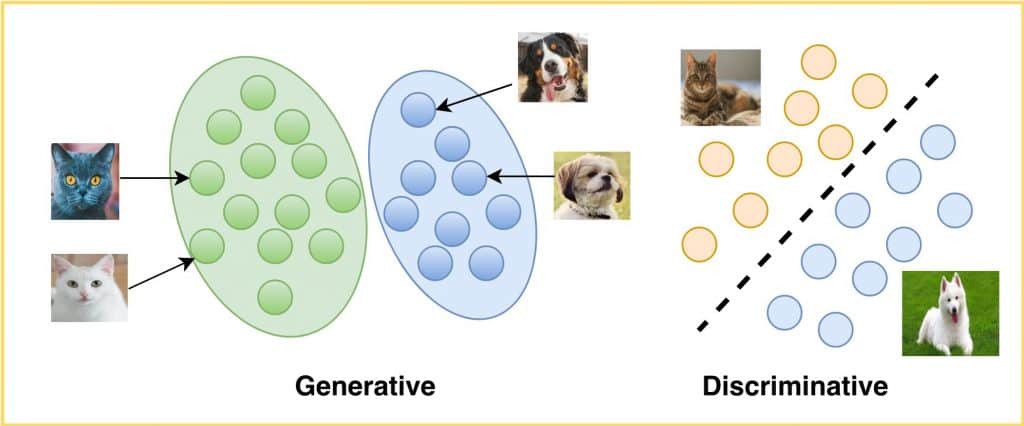
生成模型和判别模型工作原理介绍
您解决的大多数机器学习和深度学习问题都是从生成模型和判别模型中概念化的。在机器学习中,人们可以清楚地区分两种建模类型: 将图像分类为狗或猫属于判别性建模生成逼真的狗或猫图像是一个生成建模问题神经网络被采用得越多,生成域和判别域就增长得越多。要理解基于这些模型…...

shardingsphere读写分离配置
注: 如果是升级之前的单库单表,要将之前的 数据库接池 druid-spring-boot-starter 注释掉,换成 druid,否则无法连接数据库。 原因: 因为数据连接池的starter(比如druid)可能会先加载并且其创…...
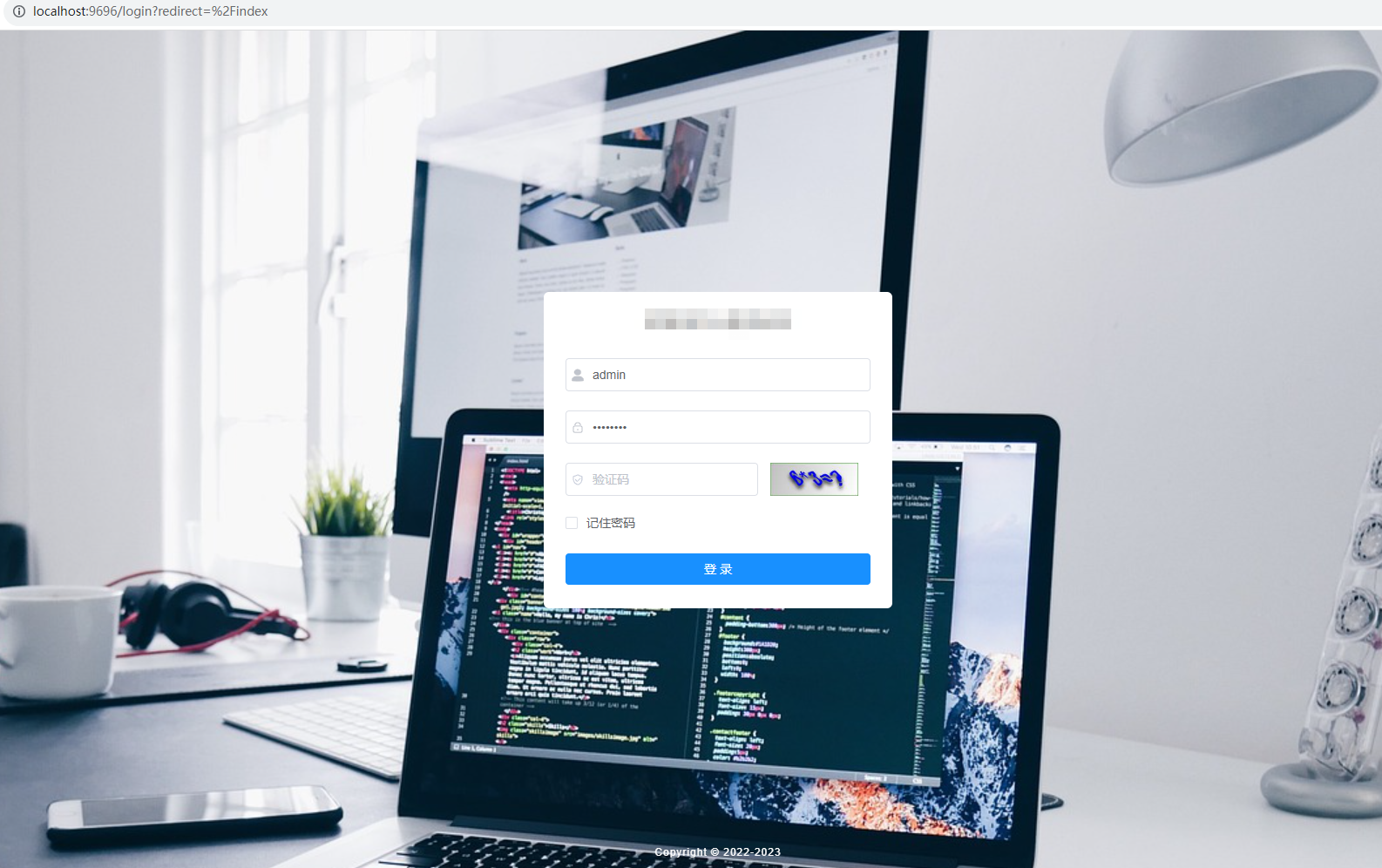
登录报错 “msg“:“Request method ‘GET‘ not supported“,“code“:500
1. 登录失败 2. 排查原因, 把 PostMapping请求注释掉, 或改成GetMapping请求就不会报错 3. 找到SecurityConfig.java , 新增 .antMatchers("/**/**").permitAll() //匹配允许所有路径 4. 登录成功...

Python 日期和时间
Python 日期和时间 Python 程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能。 Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。 时间间隔是以秒为单位的浮点小数。 每个时间戳都以自从1970年1月1日午夜(历元&…...
pytorch的发展历史,与其他框架的联系
我一直是这样以为的:pytorch的底层实现是c(这一点没有问题,见下边的pytorch结构图),然后这个部分顺理成章的被命名为torch,并提供c接口,我们在python中常用的是带有python接口的,所以被称为pytorch。昨天无意中看到Torch是由lua语言写的&…...

Kibana-elastic--Elastic Stack--ELK Stack
Kibana 是什么? | Elastic 将数据转变为结果、响应和解决方案 使用 Kibana 针对大规模数据快速运行数据分析,以实现可观测性、安全和搜索。对来自任何来源的任何数据进行全面透彻的分析,从威胁情报到搜索分析,从日志到应用程序监测…...

Docker复杂命令便捷操作
启动所有状态为Created的容器 要启动所有状态为"created"的Docker容器,可以使用以下命令: docker container start $(docker container ls -aq --filter "statuscreated")上述命令执行了以下步骤: docker container l…...
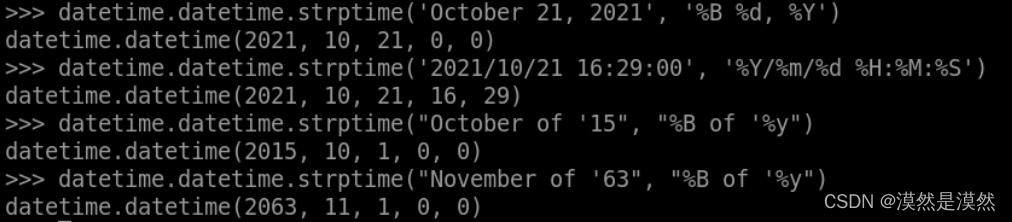
Python中的datetime模块
time模块用于取得UNIX纪元时间戳,并加以处理。但是,如果以方便的格式显示日期,或对日期进行算数运算,就应该使用datetime模块。 目录 1. datetime数据类型 1) datetime.datetime.now()表示特定时刻 2)da…...
Flutter - 微信朋友圈、十字滑动效果(微博/抖音个人中心效果)
demo 地址: https://github.com/iotjin/jh_flutter_demo 代码不定时更新,请前往github查看最新代码 前言 一般APP都有类似微博/抖音个人中心的效果,支持上下拉刷新,并且顶部有个图片可以下拉放大,图片底部是几个tab,可…...

MySQL检索数据和排序数据
目录 一、select语句 1.检索单个列(SELECT 列名 FROM 表名;) 2.检索多个列(SELECT 列名1,列名2,列名3 FROM 表名;) 3.检索所有的列(SELECT * FROM 表名;) 4.检索不同的行&#x…...
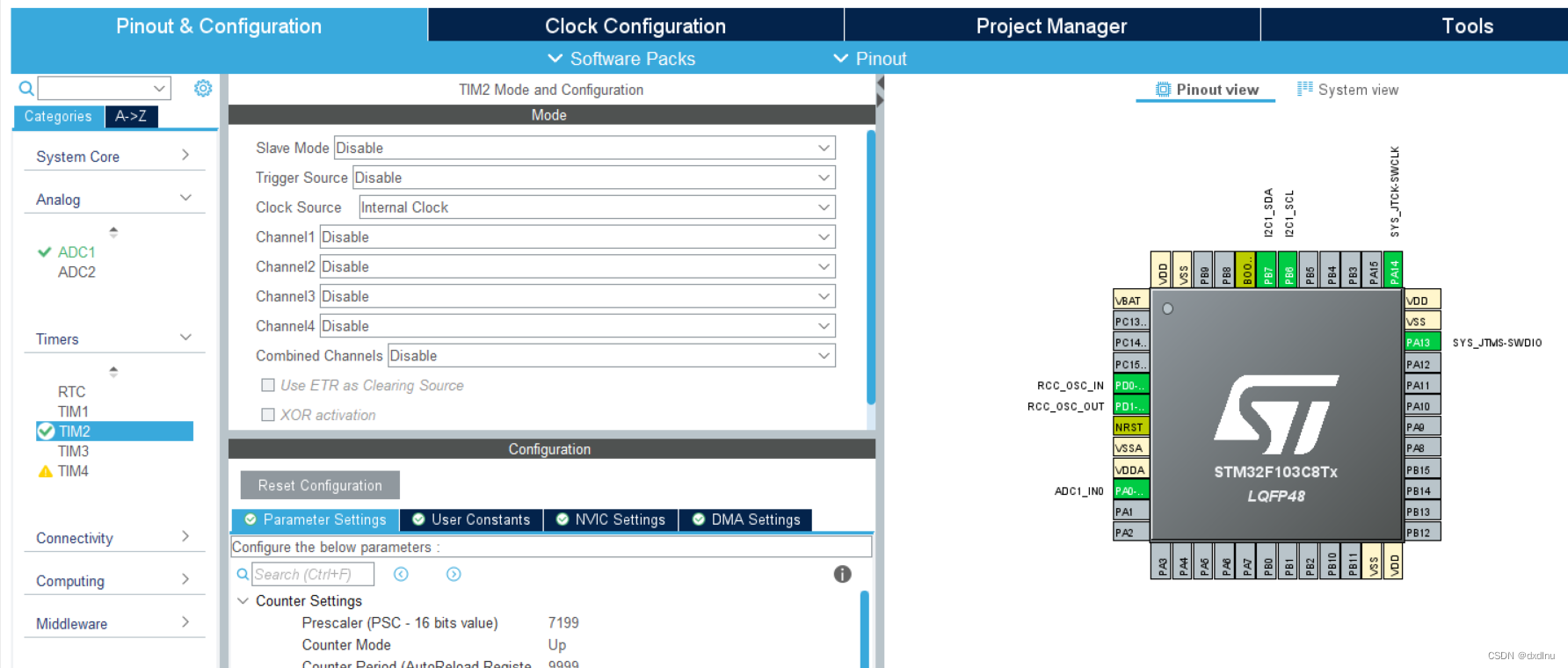
通过STM32内部ADC将烟雾传感器发送的信号值显示在OLED上
一.CubeMX配置 首先我们在CubeMX配置ADC1, 设置一个定时器TIM2定时1s采样一次以及刷新一次OLED, 打开IIC用于驱动OLED显示屏。 二.程序 在Keil5中添加好oled的显示库,以及用来显示的函数、初始化函数、清屏函数等。在主程序中初始化oled,并将其清屏。…...

ZEPHYR 快速开发指南
简介 国内小伙伴在学习zephyr的时候,有以下几个痛点: 学习门槛过高github访问不畅,下载起来比较费劲。 这篇文章将我自己踩的坑介绍一下,顺便给大家优化一些地方,避免掉所有的坑。 首先用virtualbox 来安装一个ubu…...

【FPGA + 串口】功能完备的串口测试模块,三种模式:自发自收、交叉收发、内源
【FPGA 串口】功能完备的串口测试模块,三种模式:自发自收、交叉收发、内源 VIO 控制单元 wire [1:0] mode;vio_uart UART_VIO (.clk(ad9361_l_clk), // input wire clk.probe_out0(mode) // output wire [1 : 0] probe_out0 );将 mod…...

在Python项目中实现故障转移通过Taotoken自动切换备用大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Python项目中实现故障转移通过Taotoken自动切换备用大模型 应用场景类,面向构建高可用AI应用的中高级开发者。当核心…...
)
DeepSeek限流配置全链路解析(从Token Bucket到Sentinel熔断的7层校验机制)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek限流策略配置全景概览 DeepSeek模型服务在高并发场景下需依赖精细化的限流机制保障系统稳定性与资源公平性。限流策略不仅作用于API网关层,还贯穿模型推理服务、缓存中间件及后端调…...

光声光谱结合机器学习实现乳腺癌早期无创诊断的技术解析
1. 项目概述:当光声光谱遇上机器学习,我们如何“听”出乳腺癌的早期信号?在生物医学检测领域,我们一直在寻找一种能够“透视”组织生化本质的非侵入性“慧眼”。传统的超声看结构,MRI看水分子,但它们对早期…...

CAXA工艺图表中文版全流程下载与安装教程实录
如大家所熟悉的,CAXA工艺图表是一款功能强大且十分专业的计算机辅助工艺设计(CAPP)软件工具,专为制造业企业打造,集2D/3D图形编辑、图文混排、工艺知识库、典型工艺重用与结构化工艺数据管理于一体,用于高效…...
)
【紧急预警】DeepSeek v2.3.1已确认存在默认策略绕过漏洞——立即核查你的access_control.yaml配置(附热补丁)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek访问控制配置 DeepSeek模型服务在企业级部署中需严格遵循最小权限原则,访问控制配置是保障API调用安全与资源隔离的核心环节。DeepSeek官方SDK及OpenAPI网关均支持基于Token的细粒度…...

Betaflight 2025.12:从飞行控制器到飞行艺术家——开源飞控系统的架构演进与实践
Betaflight 2025.12:从飞行控制器到飞行艺术家——开源飞控系统的架构演进与实践 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight 在无人机技术快速发展的今天,飞行…...

分布式事务方案:Seata XA、AT、TCC 与 MQ
只要一个业务操作同时写多个服务的数据,就会遇到分布式事务问题。比如下单要写订单、扣库存、扣余额,任意一步失败都可能造成数据不一致。 一句话概括:Seata 通过 TC、TM、RM 协调全局事务和分支事务;XA 追求强一致但性能差&#…...
)
DeepSeek日志异常检测实战:基于时序大模型的动态基线算法(已通过金融级等保三级日志审计验证)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek日志分析方案概述 DeepSeek系列大模型在推理与训练过程中会产生海量结构化与半结构化日志,涵盖请求元数据、token级耗时、KV缓存命中率、显存占用、错误堆栈等关键维度。本方案聚焦…...

Windows上安装安卓应用终极指南:APK安装器完整教程
Windows上安装安卓应用终极指南:APK安装器完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行手机应用吗?告别笨…...
20岁写出Transformer的人,真开源了2180亿大模型
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信号:CVer2233,小助手拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶…...