Pytest学习教程_装饰器(二)
前言
pytest装饰器是在使用 pytest 测试框架时用于扩展测试功能的特殊注解或修饰符。使用装饰器可以为测试函数提供额外的功能或行为。
以下是 pytest 装饰器的一些常见用法和用途:
| 装饰器 | 作用 |
|---|---|
| @pytest.fixture | 用于定义测试用例的前置条件和后置操作。可以创建可重用的测试环境或共享资源,并将其注入到测试函数中。通常,fixture 可以返回所需的对象或执行特定的设置和清理操作。 |
| @pytest.mark.parametrize | 用于参数化测试函数。通过在装饰的函数上提供参数列表,可以运行多组具有不同输入的测试用例。这样可以轻松地扩展测试范围并减少重复的测试代码。 |
| @pytest.mark.skip | 使用这个装饰器可以跳过不需要运行的测试用例。可以附带参数来提供跳过测试的原因或条件。 |
| @pytest.mark.skipif | 类似于 @pytest.mark.skip,这个装饰器可以基于条件来跳过特定的测试用例。可以使用预定义的环境变量、Python 版本、操作系统等作为条件。 |
| @pytest.mark.xfail | 这个装饰器标记所装饰的测试用例为 “expected failure”(预期失败)。也就是说,预计在某些条件下测试将失败,如果出现预期的失败,将被视为测试通过;如果测试用例没有失败,则会被标记为测试失败。 |
| @pytest.mark.repeat | 这个装饰器用于将测试用例重复运行多次。可以指定重复次数来确定运行次数。 |
| @pytest.mark.usefixtures | 使用此装饰器可以在测试函数中直接使用已定义的 fixture,而无需在函数签名中显式声明。这样可以简化测试函数的编写。 |
| @pytest.mark.dependency | 用于声明测试用例之间的依赖关系,以确保测试用例按正确的顺序执行。 |
一、@pytest.fixture装饰器
常用的参数列表及其简要说明:
| 参数 | 说明 |
|---|---|
| scope | 指定fixture的作用域,控制fixture的生命周期。可选值包括"function"(默认值,每个测试函数调用一次),“class”(每个测试类调用一次),“module”(每个模块调用一次),或"session"(整个测试会话过程中调用一次) |
| params | 为fixture指定不同的参数化值。可以是列表、元组或生成器。 |
| autouse | 控制fixture是否自动应用于测试用例。如果将其设置为True,则fixture将自动应用于所有使用它的测试用例。 |
| ids | 为参数化fixture中的每个参数指定一个名称或标识符列表,以便在测试报告中更好地识别不同的参数。 |
| name | 为fixture指定一个显示名称,用于在测试报告中更好地标识fixture。 |
import pytest
from selenium import webdriver
from selenium.webdriver.common.by import By
import time# @pytest.fixture 声明这是一个夹具
# scope="function" 指定了夹具的作用域为函数级别,也就是每个测试函数都会调用该夹具
# autouse=True 指定夹具为自动使用的,也就是不需要在测试函数中显式地调用夹具,它会自动应用于每个测试函数
@pytest.fixture(scope="function", autouse=True)
def setup_browser():"""设置和关闭浏览器的测试夹具"""driver = webdriver.Chrome() # 初始化Chrome浏览器驱动driver.get("https://www.baidu.com/") # 打开百度首页yield driver # 返回driver对象供测试使用driver.quit() # 测试结束后关闭浏览器# @pytest.fixture 声明这是一个夹具
# params=[("csdn"......)] 设置夹具的参数列表,夹具被参数化为两个元组,每个元组包含两个值,表示不同的搜索引擎关键字和期望结果
# name="search_engine" 给夹具指定一个名字,这样在测试函数中可以引用该夹具
# ids=["CSDN", "Baidu Knowledge"] 为每个参数设置一个标识符,这些标识符在测试报告中将用于标识参数化的实例
@pytest.fixture(params=[("csdn", "CSDN - 专业开发者社区"), ("百度知识", "百度知道 - 全球领先中文互动问答平台")],name="search_engine",ids=["CSDN", "Baidu Knowledge"])
def parametrize_search_engine(request):"""参数化的搜索引擎测试夹具"""return request.param # 返回包含关键字和期望结果的元组def test_search_home_page(setup_browser):"""测试在百度首页搜索功能"""assert "百度一下" in setup_browser.page_source # 检查页面源代码中是否包含"百度一下"def test_navigation(setup_browser, search_engine):"""测试导航功能,包括输入关键字搜索并选择第一个结果"""driver = setup_browser # 获取浏览器驱动对象keyword, engine = search_engine # 解包含有关键字和期望结果的元组# 输入指定关键字,例如"csdn"或"百度知识"driver.find_element(By.CSS_SELECTOR, '#kw').send_keys(keyword)# 点击搜索按钮driver.find_element(By.CSS_SELECTOR, '[class="bg s_btn"]').click()time.sleep(5)# 选择搜索结果中的第一个链接进行点击driver.find_element(By.CSS_SELECTOR, '[class="result c-container xpath-log new-pmd"] h3 a').click()time.sleep(5)# 切换到最新窗口的句柄driver.switch_to.window(driver.window_handles[-1])assert driver.title == engine # 检查打开的页面标题是否与期望结果一致def test_autouse_fixture():"""测试autouse=True是否生效"""assert 1 == 1if __name__ == '__main__':pytest.main(['test_run.py', '-v'])二、@pytest.mark.parametrize装饰器
import pytest# @pytest.mark.parametrize装饰器定义了一个参数化测试函数,允许我们一次运行多组数据进行测试
# 以下参数列表中的每个数据组都将分别传递给被装饰的测试函数
# 参数化允许我们在不同的输入值之间进行测试,以确保代码在各种情况下都能正常工作
@pytest.mark.parametrize("a, b, expected", [(2, 3, 5), # 测试用例1:当a=2,b=3时,预期的输出结果应为5(4, 5, 9), # 测试用例2:当a=4,b=5时,预期的输出结果应为9(6, 7, 13) # 测试用例3:当a=6,b=7时,预期的输出结果应为13
])
def test_addition(a, b, expected):# 断言语句用于检查表达式是否为真,以验证代码的正确性,# 如果表达式为False,则会引发AssertionError异常。assert a + b == expected # 检查a + b是否等于预期的输出结果# pytest.main()函数被调用来运行测试
# 运行名为'test_run.py'的测试文件,并通过'-v'参数显示每个测试用例的执行结果
if __name__ == '__main__':pytest.main(['test_run.py', '-v'])
三、@pytest.mark.skip装饰器
import pytest# 该测试用例标记为 `@pytest.mark.skip` 装饰器,表示该测试尚未实现,应跳过执行
# 跳过的原因被指定为 "尚未实现",这通常用于临时禁用尚未准备好或需要进一步开发的测试
@pytest.mark.skip(reason="Not implemented yet")
def test_multiply():assert 3 * 4 == 12if __name__ == '__main__':pytest.main(['test_run.py', '-v'])
四、@pytest.mark.skipif装饰器
import pytest
import platform# 使用 pytest.mark.skipif 装饰器为测试用例添加条件跳过的标记@pytest.mark.skipif(platform.system() == "Windows"and platform.release() == "10",reason="跳过 Windows 10 版本的测试用例")
def test_linux_run():# 仅在 Linux 系统下运行的测试代码assert 2 == 2@pytest.mark.skipif(platform.system() == "Linux",reason="跳过在 Linux 系统下运行的测试用例")
def test_windows_run():# 仅在 Windows 系统下运行的测试代码assert 2 == 2if __name__ == '__main__':pytest.main(['test_run.py', '-v'])

五、@pytest.mark.xfail装饰器
import pytest# @pytest.mark.xfail 是Pytest测试框架中的一个装饰器,用于标记预期测试失败的测试用例
# 预期失败的测试用例,因为除以零会引发异常
@pytest.mark.xfail
def test_division():assert 1 / 0 == 2# 预期失败的测试用例,因为除以零不等于1,并且应该引发 ZeroDivisionError 异常
@pytest.mark.xfail(raises=ZeroDivisionError)
def test_division_zero():assert 1 / 0 == 1# 预期失败的测试用例,已知此加法操作会失败
@pytest.mark.xfail(reason="This test is known to fail")
def test_addition():assert 2 + 2 == 5# 预期失败的测试用例,这个测试实际上是正确的,但我们使用 xfail 标记将其标记为预期失败
@pytest.mark.xfail
def test_actually_correct():assert 1 + 1 == 2if __name__ == '__main__':pytest.main(['test_run.py', '-v'])
六、@pytest.mark.repeat装饰器
# pip install pytest-repeat 安装扩展插件
import pytest# @pytest.mark.repeat 是 Pytest 测试框架中的一个装饰器,用于指定一个测试用例的重复运行次数
# 将该测试用例重复执行3次
@pytest.mark.repeat(3)
def test_addition():result = 2 + 2assert result == 4if __name__ == '__main__':pytest.main(['test_run.py', '-v'])
七、@pytest.mark.usefixtures装饰器
import pytest@pytest.fixture
def setup_data():"""前置条件 - 准备测试数据"""print("前置条件-->准备测试数据")data = "test data"yield dataprint("后置条件-->清理测试数据")def test_example(setup_data):"""示例测试方法,使用了前置条件 fixture 'setup_data'"""data = setup_dataprint("执行示例测试")assert data == "test data"@pytest.mark.usefixtures("setup_data")
def test_method():"""方法测试,使用了前置条件 fixture 'setup_data',但不接收它作为参数"""print("执行方法测试")assert 1 + 1 == 2if __name__ == '__main__':pytest.main(['test_run.py', '-s'])
- 定义了两个测试函数test_example和test_method,它们都使用了名为setup_data的 fixture 作为测试的前置条件
- 在test_example中,setup_data fixture 被作为测试函数的参数使用。在函数内部,data变量被赋值为setup_data fixture 返回的值,然后用于测试
- 在test_method中,使用了@pytest.mark.usefixtures装饰器,并将"setup_data"作为参数传递。这样一来,setup_data fixture 的前置条件将在运行test_method之前自动执行。虽然在函数体内没有显式接收setup_data作为参数,但仍可以通过setup_data执行相关操作。
- 这两种写法分别适用于需要测试数据作为输入和不依赖测试数据作为输入的情况
八、@pytest.mark.dependency装饰器
# pip install pytest-dependency 安装扩展插件
import pytest@pytest.mark.dependency()
def test_login():# 登录测试assert True# 指定 test_login 为依赖
@pytest.mark.dependency(depends=["test_login"])
def test_search():# 搜索测试assert True# 指定 test_login 和 test_search 为依赖
@pytest.mark.dependency(depends=["test_login", "test_search"])
def test_checkout():# 结账测试assert Trueif __name__ == '__main__':pytest.main(['test_run.py', '-v'])
- test_login 测试函数没有指定任何依赖关系
- test_search 测试函数指定了 test_login 作为依赖,因此在运行 test_search 之前,会先运行
test_login - test_checkout 测试函数指定了 test_login 和 test_search 作为依赖,因此在运行test_checkout 之前,会先运行 test_login 和 test_search
- 这样可以确保测试按正确的顺序运行,并且测试之间的依赖关系得到满足。如果某个测试的依赖失败,那么依赖它的测试也将被跳过执行
九、自定义装饰器
import pytest# 定义一个自定义装饰器,用于对测试用例进行分组
@pytest.mark.group1
def test_addition():assert (1 + 2) == 3# 定义第二个分组
@pytest.mark.group1
def test_subtraction():assert (5 - 3) == 2# 定义第三个分组
@pytest.mark.group2
def test_multiplication():assert (2 * 3) == 6# 定义第四个分组
@pytest.mark.group2
def test_division():assert (10 / 2) == 5# 如果当前文件被直接执行(而不是被导入为模块),则执行以下代码
if __name__ == '__main__':# 运行 Pytest 并指定只运行属于 'group1' 分组的测试用例pytest.main(['test_run.py', '-m', 'group1'])
- 通过使用 @pytest.mark.group1 和 @pytest.mark.group2装饰器,我们可以将测试用例进行逻辑分组。这样做的好处是可以只运行特定分组的测试用例,而不是运行所有测试用例
- 在上述代码中,test_addition() 和 test_subtraction() 被分组为’group1’,test_multiplication() 和 test_division() 被分组为 ‘group2’
- 运行以上示例会有警告信息,这时我们需要把group1 和group2 注册到 pytest中,在项目目录中创建一个pytest.ini(如果你尚未创建),并在其中定义自定义标记。下面是在pytest.ini 中注册group1和group2 标记的示例:
[pytest]
markers =group1: group1 测试的描述group2: group2 测试的描述
相关文章:
Pytest学习教程_装饰器(二)
前言 pytest装饰器是在使用 pytest 测试框架时用于扩展测试功能的特殊注解或修饰符。使用装饰器可以为测试函数提供额外的功能或行为。 以下是 pytest 装饰器的一些常见用法和用途: 装饰器作用pytest.fixture用于定义测试用例的前置条件和后置操作。可以创建可重…...
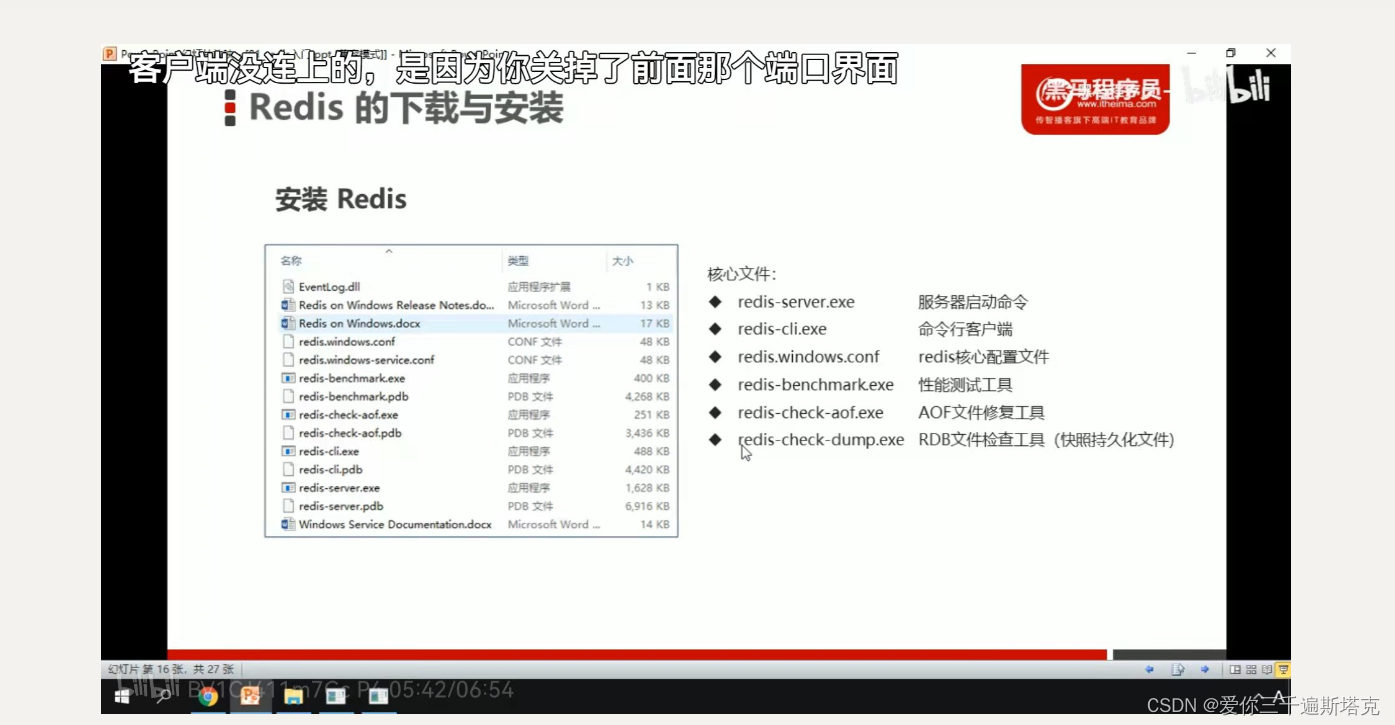
redis的如何使用
1、redis的使用 1.1windows安装 安装包下载地址:Releases dmajkic/redis GitHub 1.2 redis中常使用的几个文件 1.3 redis中运行 双击redis-server,既可以运行。 1.4使用redis客户单来连接redis 1.5redis的常用指标 redis-serve 服务端,端口号&am…...

MyBatis(二)
文章目录 一.MyBatis的模式开发1.1 定义数据表和实体类1.2 配置数据源和MyBatis1.3 编写Mapper接口和增加xxxMapper.xml1.4 测试我们功能的是否实现. 二. Mybatis的增删查改操作2.1 单表查询2.2 多表查询三.动态SQL的实现3.1 什么是动态SQL3.2 动态SQL的使用if标签的使用trim标…...
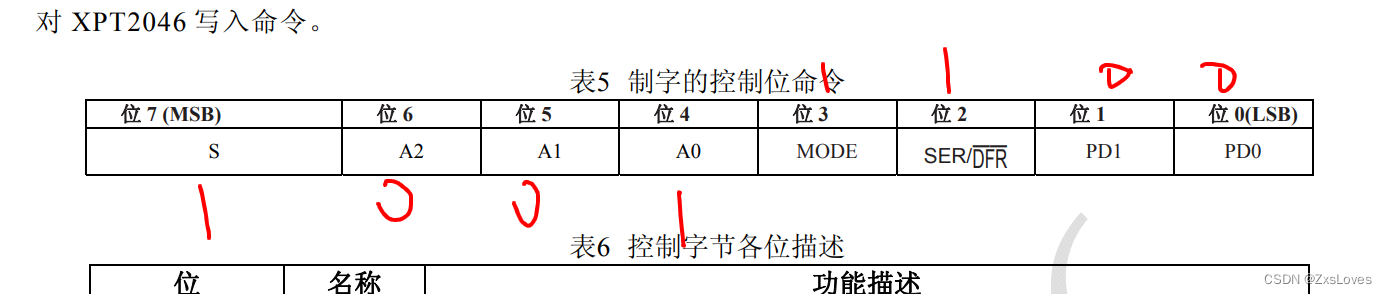
【【51单片机AD转换模块】】
代码是简单的,板子是坏的,电阻是识别不出来的 main.c #include <REGX52.H> #include "delay.h" #include "LCD1602.h" #include "XPT2046.h"unsigned int ADValue;void main(void) {LCD_Init();LCD_ShowString(1,1…...
)
Longest Divisors Interval(cf)
题意:给定一个正整数n,求正整数的区间[l,r]的最大大小,使得对于区间中的每个i(即l≤i≤r),n是i的倍数。给定两个整数l≤r,区间[l,r]的大小为r−l1(即…...

配置文件、request对象请求方法、Django连接MySQL、Django中的ORM、ORM增删改查字段、ORM增删改查数据
一、配置文件的介绍 1.注册应用的 INSTALLED_APPS [django.contrib.admin,django.contrib.auth,django.contrib.contenttypes,django.contrib.sessions,django.contrib.messages,django.contrib.staticfiles,app01.apps.App01Config, ]################中间件###############…...
CTF学习路线指南(附刷题练习网址)
前言: PWN,Reverse:偏重对汇编,逆向的理解; Gypto:偏重对数学,算法的深入学习; Web:偏重对技巧沉淀,快速搜索能力的挑战; Mic:则更为复杂&…...

【Rust 基础篇】Rust默认泛型参数:简化泛型使用
导言 Rust是一种以安全性和高效性著称的系统级编程语言,其设计哲学是在不损失性能的前提下,保障代码的内存安全和线程安全。在Rust中,泛型是一种非常重要的特性,它允许我们编写一种可以在多种数据类型上进行抽象的代码。然而&…...
从源码分析Handler面试问题
Handler 老生常谈的问题了,非常建议看一下Handler 的源码。刚入行的时候,大佬们就说 阅读源码 是进步很快的方式。 Handler的基本原理 Handler 的 重要组成部分 Message 消息MessageQueue 消息队列Lopper 负责处理MessageQueue中的消息 消息是如何添加…...

shell编程 变量作用域
变量 变量赋值不用$,访问值时用$,赋值时两边不留空格,双引号括起来的变量被值替换{}标记变量开始和结束,变量名区分大小写,所有bash变量的值变量不区分类型,统一为字符串 变量类型 环境变量,子进程可以继承父进程环境…...

华为eNSP:isis的配置
一、拓扑图 二、路由器的配置 配置接口IP AR1: <Huawei>system-view [Huawei]int g0/0/0 [Huawei-GigabitEthernet0/0/0]ip add 1.1.1.1 24 [Huawei-GigabitEthernet0/0/0]qu AR2: <Huawei>system-view [Huawei]int g0/0/0 [Huawei-GigabitEthe…...

FS.05-SAS-UP-Methodology
FS.05-SAS-UP-Methodology-v9.2.pdf 附录 D 数据处理审核 作为现场数据处理系统和支持流程审核的一部分,受审核方最好在审核日期之前准备一些 SAS 特定的测试数据文件。 本文件提供了建议的方法; 受审核方和审核团队将就每次审核的具体方法达成一致。 …...
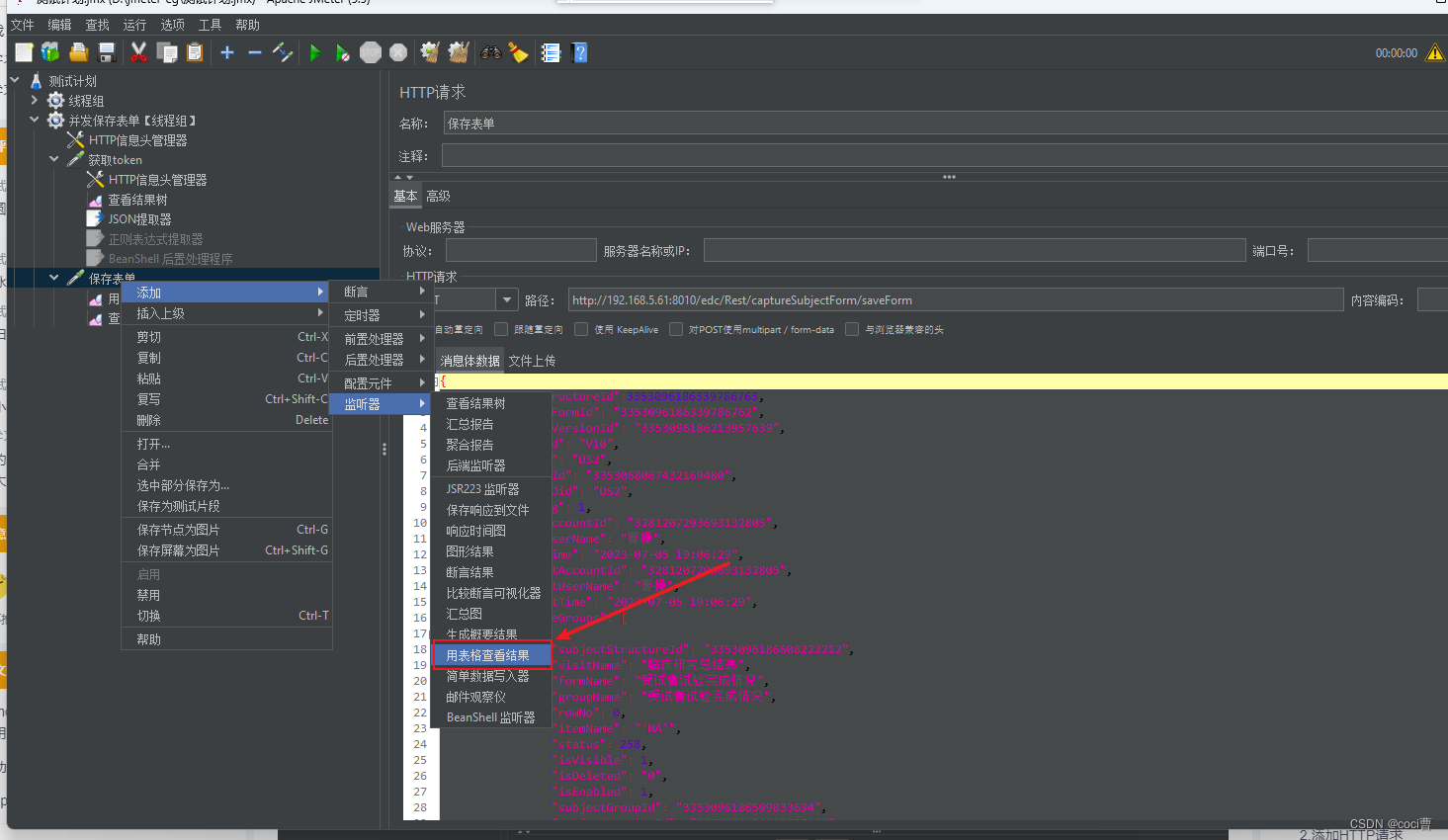
Jmeter并发测试
基本步骤 1、新建线程组 测试计划右键——>添加——>线程(用户)——>线程组 2、 添加HTTP请求 线程组右键——>添加——>取样器——>HTTP请求 3、 添加HTTP信息头管理器 线程组右键——>添加——>配置元件——>HTTP信息头…...

【JVM】浅看JVM的运行流程和垃圾回收
1.JVM是什么 JVM( Java Virtual Machine)就是Java虚拟机。 Java的程序都运行在JVM中。 2.JVM的运行流程 JVM的执行流程: 程序在执行之前先要把java代码转换成字节码(class文件),JVM 首先需要把字节码通过…...

使用低代码开发,需要注意哪些?
低代码平台的历史相对较短,大约始于 2000 年初,源于快速应用程序开发工具。随着低代码平台和工具的日益普及和优势,它不断发展以满足各种领域和角色的需求。 本文将研究各种低代码和无代码应用程序开发方法、业务用例、挑战和未来预测等。 一…...

面试总结-Redis篇章(八)——Redis分布式锁
JAVA 面试总结-Redis分布式锁 模拟抢券场景通过下面方法添加Synchronized锁来防止上述情况,如果上面是单体服务没有问题,但是如果项目是集群部署,会出现下面的问题,因为Synchronized是属于本地的锁端口8080和8081同时访问…...

压力测试-商场项目
1.压力测试 压力测试是给软件不断加压,强制其在极限的情况下运行,观察它可以运行到何种程度,从而发现性能缺陷,是通过搭建与实际环境相似的测试环境,通过测试程序在同一时间内或某一段时间内,向系统发送预…...
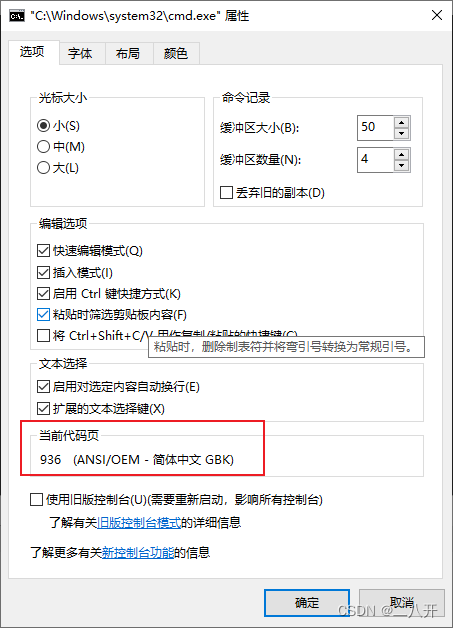
IDEA中文UT方法执行报错问题、wps默认保存格式
wps默认保存格式、IDEA中文UT方法执行报错问题 背景 1、wps修改文件后,编码格式从UTF-8-bom变成UTF-8(notepad可以查看); 2、IDEA中文UT执行报错: 解决方案 1、语言设置中不要勾选 “Beta版。。。。” 2、cmd中执…...
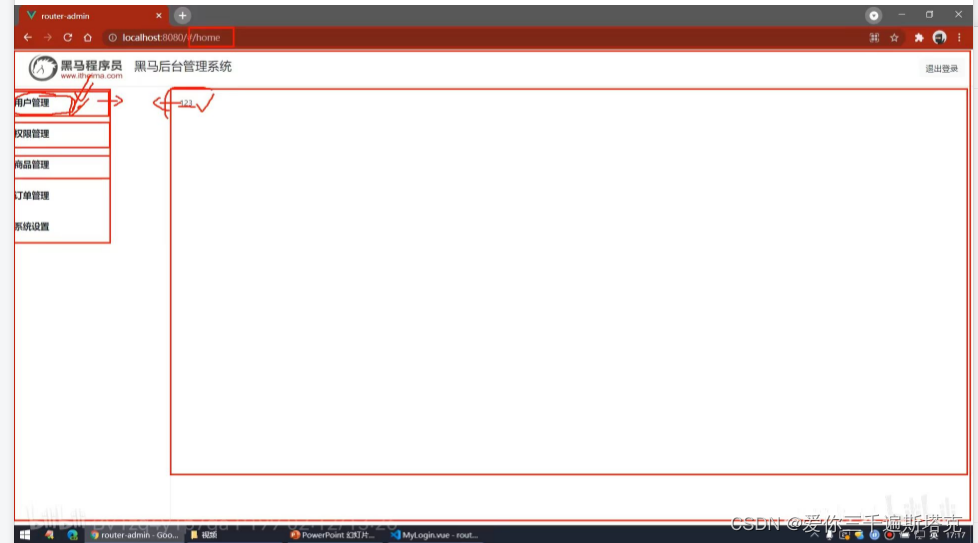
Vue如何实现编程式导航声明方法,前进和后退导航
编程式导航声明方法,前进和后退导航 在router中设置路由导航跳转函数 只要发生跳转 导航的声明函数 访问控制系统如何形成 就这三种 导航守卫的案例,写一个Main.Vue 和login .Vue 后台主页 如果想要展示后台主页,就用这种方法 想实现路由跳转…...

torch.load 报错 ModuleNotFoundError 或 AttributeError
Python 3.11.3 (main, Apr 7 2023, 19:25:52) [Clang 14.0.0 (clang-1400.0.29.202)] on darwin Type "help", "copyright", "credits" or "license" for more information.正常情况下,我们会使用 torch.save 保存模型的 …...

如何攻克Sunshine虚拟手柄延迟与兼容性难题?深度解析实战解决方案
如何攻克Sunshine虚拟手柄延迟与兼容性难题?深度解析实战解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾遇到过这样的困境:在Moonlight客…...
)
【紧急通知】ChatGPT桌面版v1.5.2已悄然下架旧安装包!仅剩72小时可获取官方签名安装器(附SHA256校验码)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT桌面版下载安装 OpenAI 官方尚未发布官方支持的 ChatGPT 桌面应用程序,但社区提供了多个稳定、安全且功能完善的第三方桌面客户端。目前主流推荐方案为基于 Electron 构建的开源项目…...

明日方舟游戏素材资源库:创作者与开发者的数字宝藏
明日方舟游戏素材资源库:创作者与开发者的数字宝藏 【免费下载链接】ArknightsGameResource 明日方舟客户端素材 项目地址: https://gitcode.com/gh_mirrors/ar/ArknightsGameResource 还在为明日方舟相关的创作项目寻找高质量素材而烦恼吗?无论是…...

Zotero Duplicates Merger:终极文献去重解决方案,告别重复文献困扰
Zotero Duplicates Merger:终极文献去重解决方案,告别重复文献困扰 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 你是…...

抖音批量下载工具:如何快速提取无水印视频和背景音乐
抖音批量下载工具:如何快速提取无水印视频和背景音乐 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

高性能日志分析系统架构设计:LogExpert企业级监控解决方案
高性能日志分析系统架构设计:LogExpert企业级监控解决方案 【免费下载链接】LogExpert Windows tail program and log file analyzer. 项目地址: https://gitcode.com/gh_mirrors/lo/LogExpert LogExpert是一款专为Windows平台设计的高性能图形化日志分析工具…...

为什么说Full Page Screen Capture是Chrome网页截图的终极解决方案?
为什么说Full Page Screen Capture是Chrome网页截图的终极解决方案? 【免费下载链接】full-page-screen-capture-chrome-extension One-click full page screen captures in Google Chrome 项目地址: https://gitcode.com/gh_mirrors/fu/full-page-screen-capture…...

通过 Taotoken 用量看板分析各模型消耗并优化 Token 使用策略
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 Taotoken 用量看板分析各模型消耗并优化 Token 使用策略 作为项目管理者,在引入多个大模型 API 支持不同业务场景…...

从科学哲学到AI:普特南的批判与解释倾向如何映射机器学习预测与可解释性
1. 项目概述:当科学哲学遇见机器学习作为一名长期在人工智能领域摸爬滚打的从业者,我常常思考一个看似跨界的问题:我们训练出的那些“黑箱”模型,它们做出预测的逻辑,与科学家们构建和选择理论的过程,究竟有…...

DS4Windows:让PS4手柄在Windows电脑上焕发新生!5个超实用功能解锁游戏新境界
DS4Windows:让PS4手柄在Windows电脑上焕发新生!5个超实用功能解锁游戏新境界 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PC游戏不支持PS4手柄而烦恼吗&a…...