在CSDN学Golang云原生(Kubernetes Pod 有状态部署)
一,StatefulSet部署MongoDB集群
Kubernetes StatefulSet 是 Kubernetes 中的一种资源类型,它能够保证有状态服务(Stateful Service)的唯一性和顺序部署,适用于需要持久化存储、网络标识、状态管理等场景。MongoDB 是一个非常流行的 NoSQL 数据库,下面我们介绍如何使用 Kubernetes StatefulSet 部署 MongoDB 集群。
- 创建一个 ConfigMap
ConfigMap 可以用来存放 MongoDB 的配置文件,包括副本集配置文件、启动脚本等。在创建 ConfigMap 时可以指定这些配置文件的内容,例如:
apiVersion: v1
kind: ConfigMap
metadata:name: mongodb-configmap
data:mongod.conf: |systemLog:destination: filepath: "/var/log/mongodb/mongod.log"logAppend: truestorage:dbPath: "/data/db"journal:enabled: trueprocessManagement:fork: falsenet:port: 27017replication:replSetName: rs0- 创建一个 Headless Service
Headless Service 指没有 cluster IP 的 service,在 Kubernetes 中可以通过 DNS 解析来访问服务实例。由于每个 MongoDB 实例都需要有自己的 hostname 和 network identity,所以我们需要创建一个 Headless Service 来为每个实例分配独立的 hostname。
apiVersion: v1
kind: Service
metadata:name: mongodb-service-headless
spec:ports:- name : mongo port: 27017targetPort: 27017clusterIP: Noneselector:app: mongodb - 创建一个 StatefulSet
下面是一个简单的 MongoDB StatefulSet 配置示例,其中 replicas 指定了副本数,serviceName 指定了使用的 Headless Service 名称,volumeClaimTemplates 定义了每个 Pod 使用的 PVC。
apiVersion: apps/v1
kind: StatefulSet
metadata:name: mongodb-statefulset
spec:serviceName: mongodb-service-headless replicas: 3 selector:matchLabels:app: mongodb template:metadata:labels:app: mongodb spec:containers:- name : mongo image : mongo command :- "mongod" - "--config" - "/etc/mongod.conf" ports :- containerPort : 27017name : mongovolumeMounts :- name : data-volumemountPath : /data/db/- name : config-volumemountPath : /etc/mongod.conf volumes :- name : data-volume persistentVolumeClaim :claimName : pvc-mongo-data - name : config-volume configMap :name : mongodb-configmap terminationGracePeriodSeconds: 10 dnsPolicy: ClusterFirstWithHostNet
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name:pvc-mongo-data
spec:accessModes:- ReadWriteOnce resources :requests :storage : 20Gi这个配置将创建三个 MongoDB 实例,每个实例都有自己的 PVC 存储卷和配置文件。StatefulSet 会按照 mongo-0、mongo-1、mongo-2 的顺序为 Pod 分配唯一的 hostname 和 network identity。我们可以使用 DNS 来访问这些实例:
mongo-0.mongodb-service-headless.default.svc.cluster.local
mongo-1.mongodb-service-headless.default.svc.cluster.local
mongo-2.mongodb-service-headless.default.svc.cluster.local这样,我们就成功地使用 Kubernetes StatefulSet 部署了一个 MongoDB 副本集。
二,StatefulSet部署Redis集群
Kubernetes StatefulSet 可以用来部署有状态的服务(Stateful Service),Redis 是一种非常流行的内存数据库,支持数据持久化和复制等功能。在 Kubernetes 中使用 StatefulSet 部署 Redis 集群需要注意以下几个方面。
- 创建一个 ConfigMap
ConfigMap 可以用来存放 Redis 的配置文件,包括启动脚本、Redis.conf 等。在创建 ConfigMap 时可以指定这些配置文件的内容,例如:
apiVersion: v1
kind: ConfigMap
metadata:name: redis-configmap
data:redis.conf: |bind 0.0.0.0port 6379cluster-enabled yescluster-config-file /data/nodes.confcluster-node-timeout 15000
- 创建一个 Headless Service
为了让每个 Redis 实例都有唯一的 hostname 和 network identity,我们需要创建一个 Headless Service 来分配独立的 hostname。
apiVersion: v1
kind: Service
metadata:name: redis-service-headless
spec:ports:- name : redis port: 6379targetPort: 6379clusterIP: Noneselector:app: redis- 创建一个 StatefulSet
下面是一个简单的 Redis StatefulSet 配置示例,其中 replicas 指定了副本数,serviceName 指定了使用的 Headless Service 名称,volumeClaimTemplates 定义了每个 Pod 使用的 PVC。
apiVersion: apps/v1
kind: StatefulSet
metadata:name: redis-statefulset
spec:serviceName: redis-service-headless replicas: 3 selector:matchLabels:app: redis template:metadata:labels:app: redis spec:containers:- name : redis image : redis command :- "redis-server" - "/etc/redis/redis.conf" ports :- containerPort : 6379name : redisvolumeMounts :- name : data-volumemountPath : /data - name : config-volumemountPath : /etc/redis/args: ["/etc/redis/redis.conf"]volumes :- name : data-volume persistentVolumeClaim :claimName : pvc-redis-data - name : config-volume configMap :name : redis-configmap terminationGracePeriodSeconds: 10 dnsPolicy: ClusterFirstWithHostNet
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name:pvc-redis-data
spec:accessModes:- ReadWriteOnce resources :requests :storage : 20Gi这个配置将创建三个 Redis 实例,每个实例都有自己的 PVC 存储卷和配置文件。StatefulSet 会按照 redis-0、redis-1、redis-2 的顺序为 Pod 分配唯一的 hostname 和 network identity。我们可以使用 DNS 来访问这些实例:
redis-0.redis-service-headless.default.svc.cluster.local
redis-1.redis-service-headless.default.svc.cluster.local
redis-2.redis-service-headless.default.svc.cluster.local这样,我们就成功地使用 Kubernetes StatefulSet 部署了一个 Redis 集群。
三,StatefulSet部署ES集群
Kubernetes StatefulSet 可以用来部署有状态的服务(Stateful Service),Elasticsearch 是一种非常流行的分布式搜索和数据分析引擎,支持集群部署和数据持久化等功能。在 Kubernetes 中使用 StatefulSet 部署 Elasticsearch 集群需要注意以下几个方面。
- 创建一个 ConfigMap
ConfigMap 可以用来存放 Elasticsearch 的配置文件,例如 elasticsearch.yml 和 jvm.options 等。在创建 ConfigMap 时可以指定这些配置文件的内容,例如:
apiVersion: v1
kind: ConfigMap
metadata:name: elasticsearch-configmap
data:elasticsearch.yml: |cluster.name: es-clusternode.name: ${HOSTNAME}network.host: "0.0.0.0"discovery.zen.ping.unicast.hosts: "es-discovery-0,es-discovery-1,es-discovery-2"discovery.zen.minimum_master_nodes: 2jvm.options: |-Xms512m-Xmx512m- 创建一个 Headless Service
为了让每个 Elasticsearch 实例都有唯一的 hostname 和 network identity,我们需要创建一个 Headless Service 来分配独立的 hostname。
apiVersion: v1
kind: Service
metadata:name: es-service-headless
spec:ports:- name : http port : 9200 targetPort : http clusterIP : None selector :app : elasticsearch- 创建一个 StatefulSet
下面是一个简单的 Elasticsearch StatefulSet 配置示例,其中 replicas 指定了副本数,serviceName 指定了使用的 Headless Service 名称,volumeClaimTemplates 定义了每个 Pod 使用的 PVC。
apiVersion: apps/v1
kind: StatefulSet
metadata:name: es-statefulset
spec:serviceName: es-service-headless replicas: 3 selector:matchLabels:app: elasticsearch template:metadata:labels:app: elasticsearch spec:containers:- name : elasticsearch image : docker.elastic.co/elasticsearch/elasticsearch:7.10.2ports :- containerPort : 9200name : http - containerPort : 9300 name : transport env :- name : cluster.name value : "es-cluster" - name : discovery.seed_hosts value : "es-discovery-0,es-discovery-1,es-discovery-2"- name : cluster.initial_master_nodes value : "es-0,es-1,es-2" volumeMounts :- name : data-volumemountPath : /usr/share/elasticsearch/data - name : config-volumemountPath : /usr/share/elasticsearch/config/args :["-Enode.name=${HOSTNAME}"]volumes :- name : data-volume persistentVolumeClaim :claimName : pvc-es-data - name : config-volume configMap :name : elasticsearch-configmap terminationGracePeriodSeconds: 10 dnsPolicy: ClusterFirstWithHostNet
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name:pvc-es-data
spec:accessModes:- ReadWriteOnce resources :requests :storage : 20Gi这个配置将创建三个 Elasticsearch 实例,每个实例都有自己的 PVC 存储卷和配置文件。StatefulSet 会按照 es-0、es-1、es-2 的顺序为 Pod 分配唯一的 hostname 和 network identity。我们可以使用 DNS 来访问这些实例:
http://es-0.es-service-headless.default.svc.cluster.local:9200
http://es-1.es-service-headless.default.svc.cluster.local:9200
http://es-2.es-service-headless.default.svc.cluster.local:9200这样,我们就成功地使用 Kubernetes StatefulSet 部署了一个 Elasticsearch 集群。
Golang云原生学习路线图、教学视频、文档资料、面试题资料(资料包括C/C++、K8s、golang项目实战、gRPC、Docker、DevOps等)免费分享 有需要的可以加qun:793221798领取
四,StatefulSet部署ETCD集群
在 Kubernetes 中使用 StatefulSet 部署 etcd 集群需要注意以下几个方面。
- 创建一个 ConfigMap
ConfigMap 可以用来存放 etcd 的配置文件,例如 etcd.conf 等。在创建 ConfigMap 时可以指定这些配置文件的内容,例如:
apiVersion: v1
kind: ConfigMap
metadata:name: etcd-configmap
data:etcd.conf: |name: "etcd-cluster"data-dir: "/var/lib/etcd"listen-peer-urls: "https://0.0.0.0:2380"listen-client-urls: "https://0.0.0.0:2379"initial-advertise-peer-urls: "https://$(hostname -f):2380"advertise-client-urls: "https://$(hostname -f):2379"- 创建一个 Headless Service
为了让每个 etcd 实例都有唯一的 hostname 和 network identity,我们需要创建一个 Headless Service 来分配独立的 hostname。
apiVersion: v1
kind: Service
metadata:name: etcd-service-headless
spec:ports:- name : client port : 2379 targetPort : client clusterIP : None selector :app : etcd- 创建一个 StatefulSet
下面是一个简单的 etcd StatefulSet 配置示例,其中 replicas 指定了副本数,serviceName 指定了使用的 Headless Service 名称,volumeClaimTemplates 定义了每个 Pod 使用的 PVC。
apiVersion: apps/v1
kind: StatefulSet
metadata:name: etcd-statefulset
spec:serviceName: etcd-service-headless replicas: 3 selector:matchLabels:app: etcd template:metadata:labels:app: etcd spec:containers:- name : etcd image : quay.io/coreos/etcd:v3.5.0command :- /usr/local/bin/etcd - --config-file=/etc/etcd/etcd.conf ports :- containerPort : 2379name : client - containerPort : 2380 name : peer env :- name : ETCD_NAME valueFrom :fieldRef :fieldPath : metadata.name - name : ETCD_INITIAL_CLUSTER_STATE value : new volumeMounts :- name : data-volumemountPath : /var/lib/etcd/data - name : config-volumemountPath : /etc/etcd/volumes :- name : data-volume persistentVolumeClaim :claimName : pvc-etcd-data - name : config-volume configMap :name : etcd-configmap terminationGracePeriodSeconds: 10 dnsPolicy: ClusterFirstWithHostNet
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name:pvc-etcd-data
spec:accessModes:- ReadWriteOnce resources :requests :storage : 20Gi这个配置将创建三个 etcd 实例,每个实例都有自己的 PVC 存储卷和配置文件。StatefulSet 会按照 etcd-0、etcd-1、etcd-2 的顺序为 Pod 分配唯一的 hostname 和 network identity。我们可以使用 DNS 来访问这些实例:
https://etcd-0.etcd-service-headless.default.svc.cluster.local:2379
https://etcd-1.etcd-service-headless.default.svc.cluster.local:2379
https://etcd-2.etcd-service-headless.default.svc.cluster.local:2379这样,我们就成功地使用 Kubernetes StatefulSet 部署了一个 etcd 集群。
五,StatefulSet部署Kafka集群
在 Kubernetes 中使用 StatefulSet 部署 Kafka 集群需要注意以下几个方面。
- 创建一个 ConfigMap
ConfigMap 可以用来存放 Kafka 的配置文件,例如 server.properties 等。在创建 ConfigMap 时可以指定这些配置文件的内容,例如:
apiVersion: v1
kind: ConfigMap
metadata:name: kafka-configmap
data:server.properties: |broker.id=0listeners=PLAINTEXT://$(hostname -f):9092advertised.listeners=PLAINTEXT://$(hostname -f):9092log.dirs=/var/lib/kafka/datazookeeper.connect=zookeeper-service-headless:2181/kafka- 创建一个 Headless Service
为了让每个 Kafka 实例都有唯一的 hostname 和 network identity,我们需要创建一个 Headless Service 来分配独立的 hostname。
apiVersion: v1
kind: Service
metadata:name: kafka-service-headless
spec:ports:- name : client port : 9092 targetPort : client clusterIP : None selector :app : kafka- 创建一个 StatefulSet
下面是一个简单的 Kafka StatefulSet 配置示例,其中 replicas 指定了副本数,serviceName 指定了使用的 Headless Service 名称,volumeClaimTemplates 定义了每个 Pod 使用的 PVC。
apiVersion: apps/v1
kind: StatefulSet
metadata:name: kafka-statefulset
spec:serviceName: kafka-service-headless replicas: 3 selector:matchLabels:app: kafka template:metadata:labels:app: kafka spec:containers:- name : kafka image : wurstmeister/kafka:2.13-2.8.0command :- /bin/bash - -c - |/opt/kafka/bin/kafka-server-start.sh /etc/kafka/server.properties --override broker.id=$(hostname|awk -F'-' '{print $NF}') --override listeners=PLAINTEXT://$(hostname -f):9092 --override advertised.listeners=PLAINTEXT://$(hostname -f):9092ports :- containerPort : 9092name : client env :- name : KAFKA_ADVERTISED_HOST_NAME valueFrom :fieldRef :fieldPath : metadata.name - name : KAFKA_ZOOKEEPER_CONNECT value : zookeeper-service-headless:2181/kafka volumeMounts :- name : data-volumemountPath : /var/lib/kafka/data - name : config-volumemountPath : /etc/kafka/volumes :- name : data-volume persistentVolumeClaim :claimName : pvc-kafka-data - name : config-volume configMap :name : kafka-configmap terminationGracePeriodSeconds: 10 dnsPolicy: ClusterFirstWithHostNet
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name:pvc-kafka-data
spec:accessModes:- ReadWriteOnce resources :requests :storage : 20Gi这个配置将创建三个 Kafka 实例,每个实例都有自己的 PVC 存储卷和配置文件。StatefulSet 会按照 kafka-0、kafka-1、kafka-2 的顺序为 Pod 分配唯一的 hostname 和 network identity。我们可以使用 DNS 来访问这些实例:
PLAINTEXT://kafka-0.kafka-service-headless.default.svc.cluster.local:9092
PLAINTEXT://kafka-1.kafka-service-headless.default.svc.cluster.local:9092
PLAINTEXT://kafka-2.kafka-service-headless.default.svc.cluster.local:9092这样,我们就成功地使用 Kubernetes StatefulSet 部署了一个 Kafka 集群。
六,StatefulSet部署Mysql集群
在 Kubernetes 中使用 StatefulSet 部署 MySQL 集群需要注意以下几个方面。
- 创建一个 ConfigMap
ConfigMap 可以用来存放 MySQL 的配置文件,例如 my.cnf 等。在创建 ConfigMap 时可以指定这些配置文件的内容,例如:
apiVersion: v1
kind: ConfigMap
metadata:name: mysql-configmap
data:my.cnf: |[mysqld]server_id=1log-bin=mysql-bin binlog_format=row datadir=/var/lib/mysql- 创建一个 Headless Service
为了让每个 MySQL 实例都有唯一的 hostname 和 network identity,我们需要创建一个 Headless Service 来分配独立的 hostname。
apiVersion: v1
kind: Service
metadata:name: mysql-service-headless
spec:ports:- name : client port : 3306 targetPort : client clusterIP : None selector :app : mysql- 创建一个 StatefulSet
下面是一个简单的 MySQL StatefulSet 配置示例,其中 replicas 指定了副本数,serviceName 指定了使用的 Headless Service 名称,volumeClaimTemplates 定义了每个 Pod 使用的 PVC。
apiVersion: apps/v1
kind: StatefulSet
metadata:name: mysql-statefulset
spec:serviceName: mysql-service-headless replicas: 3 selector:matchLabels:app: mysql template:metadata:labels:app: mysql spec:containers:- name : mysql image : mysql:5.7env :- name : MYSQL_ROOT_PASSWORD value : root - name : MYSQL_ALLOW_EMPTY_PASSWORDvalue: "yes"ports :- containerPort : 3306name : client volumeMounts :- name : data-volumemountPath : /var/lib/mysql - name : config-volumemountPath : /etc/mysql/volumes :- name : data-volume persistentVolumeClaim :claimName : pvc-mysql-data - name : config-volume configMap :name : mysql-configmap terminationGracePeriodSeconds: 10 dnsPolicy: ClusterFirstWithHostNet
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name:pvc-mysql-data
spec:accessModes:- ReadWriteOnce resources :requests :storage : 20Gi这个配置将创建三个 MySQL 实例,每个实例都有自己的 PVC 存储卷和配置文件。StatefulSet 会按照 mysql-0、mysql-1、mysql-2 的顺序为 Pod 分配唯一的 hostname 和 network identity。我们可以使用 DNS 来访问这些实例:
mysql://root@mysql-0:mysql-service-headless.default.svc.cluster.local/
mysql://root@mysql-1:mysql-service-headless.default.svc.cluster.local/
mysql://root@mysql-2:mysql-service-headless.default.svc.cluster.local/这样,我们就成功地使用 Kubernetes StatefulSet 部署了一个 MySQL 集群。
相关文章:
)
在CSDN学Golang云原生(Kubernetes Pod 有状态部署)
一,StatefulSet部署MongoDB集群 Kubernetes StatefulSet 是 Kubernetes 中的一种资源类型,它能够保证有状态服务(Stateful Service)的唯一性和顺序部署,适用于需要持久化存储、网络标识、状态管理等场景。MongoDB 是一…...

sql-从一个或多个表中向一个表中插入 多行
INSERT还可以将SELECT语句查询的结果插入到表中,此时不需要把每一条记录的值一个一个输入,只需 要使用一条INSERT语句和一条SELECT语句组成的组合语句即可快速地从一个或多个表中向一个表中插入 多行。 基本语法格式如下: INSERT INTO 目标表…...

ElementUI 实现动态表单数据校验(已解决)
文章目录 🍋前言:🍍正文1、探讨需求2、查阅相关文档([element官网](https://element.eleme.cn/#/zh-CN/component/form))官方动态增减表单项示例3、需求完美解决4、注意事项 🎃专栏分享: &#…...
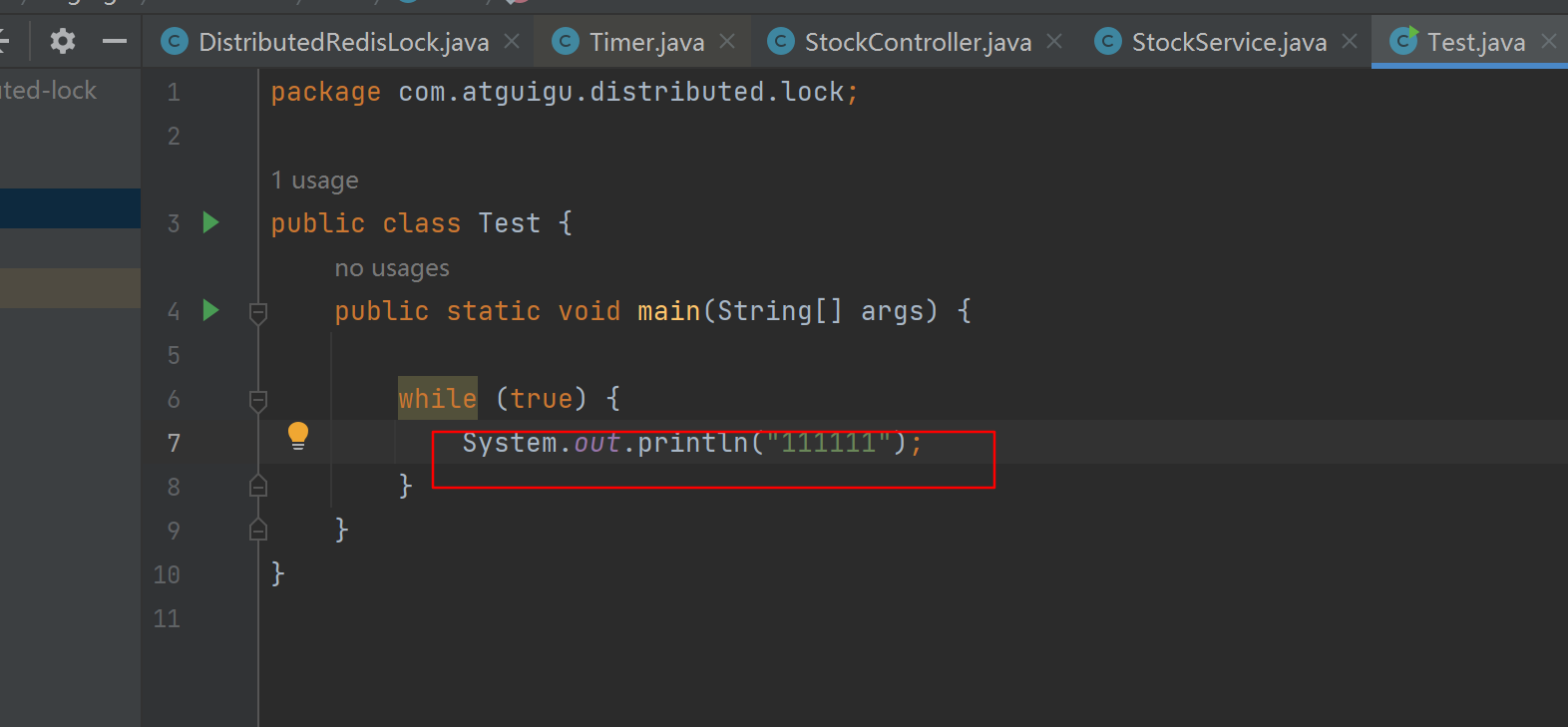
Linux上定位线上CPU飙高
【模拟场景】 写一个java main函数,死循环打印 System.out.println(“111111”) , 将其打成jar包放在linux中执行 1、通过TOP命令找到CPU耗用最厉害的那个进程的PID 2、top -H -p 进程PID 找到进程下的所有线程 可以看到 pid 为 94384的线程耗用cpu …...

06-行向量列向量_向量的运算 加法,数乘,减法,转置
行向量和列向量 行向量是按行把向量排开(横着来写), 列向量是按列把向量排开(竖着来写) 在数学中我们更多的把数据写成列向量,在编程语言中更多的把数据存成行向量! 如果想在编程语言中把行向量转化成列…...
)
基于Matlab实现最大类间方差阈值与遗传算法的道路分割(附上完整源码+图像+程序运行说明)
道路分割是计算机视觉和图像处理中的一个重要任务,它在交通监控、自动驾驶和地图制作等领域具有广泛的应用。其中,最大类间方差阈值和遗传算法是道路分割中常用的方法之一。本文将介绍如何使用Matlab实现最大类间方差阈值与遗传算法进行道路分割。 文章目…...

13.4.2 【Linux】sudo
相对于 su 需要了解新切换的使用者密码 (常常是需要 root 的密码), sudo 的执行则仅需要自己的密码即可。sudo 可以让你以其他用户的身份执行指令 (通常是使用 root 的身份来执行指令),因此并非所有人都能够…...

电脑软件:键盘按键修改器——keytweak使用介绍
对你的电脑键盘的布局不满意、键盘上的某个按键坏掉了等等键盘问题如何解决?有了KeyTweak这一切就可以轻松解决了,KeyTweak是一个免费软件程序,使用它可让你重新映射键盘键。如果您改变主意并想将其改回原样,只需点击一下即可容易…...

软件工程学术顶会——ICSE 2023 议题(网络安全方向)清单与摘要
按语:IEEE/ACM ICSE全称International Conference on Software Engineering,是软件工程领域公认的旗舰学术会议,中国计算机学会推荐的A类国际学术会议,Core Conference Ranking A*类会议,H5指数74,Impact s…...

【Python】jupyter Linux服务器使用
文章目录 环境使用访问 环境 pip install jupyter 使用 在你想访问的目录下执行: jupyter notebook --ip0.0.0.0jupyter 给出提示: [I 2023-07-28 14:32:43.589 ServerApp] Package notebook took 0.0000s to import [I 2023-07-28 14:32:43.597 Ser…...
element 级联 父传子
html代码例子 父组件 <el-cascaderstyle"width: 100%"change"unitIdChange":options"unitOptions"filterablev-model"formInline.unitId":props"unitProps"/></el-form-item>//改变级联传值到这个组件里面<r…...

【MTI 6.S081 Lab】Copy-on-write
【MTI 6.S081 Lab】Copy-on-write The problemThe solutionImplement copy-on-write fork (hard)实验任务Hints解决方案问题解决思考uvmcopykfreekallockpagerefcow_handlertrap 虚拟内存提供了一定程度的间接性:内核可以通过将PTE标记为无效或只读来拦截内存引用&a…...
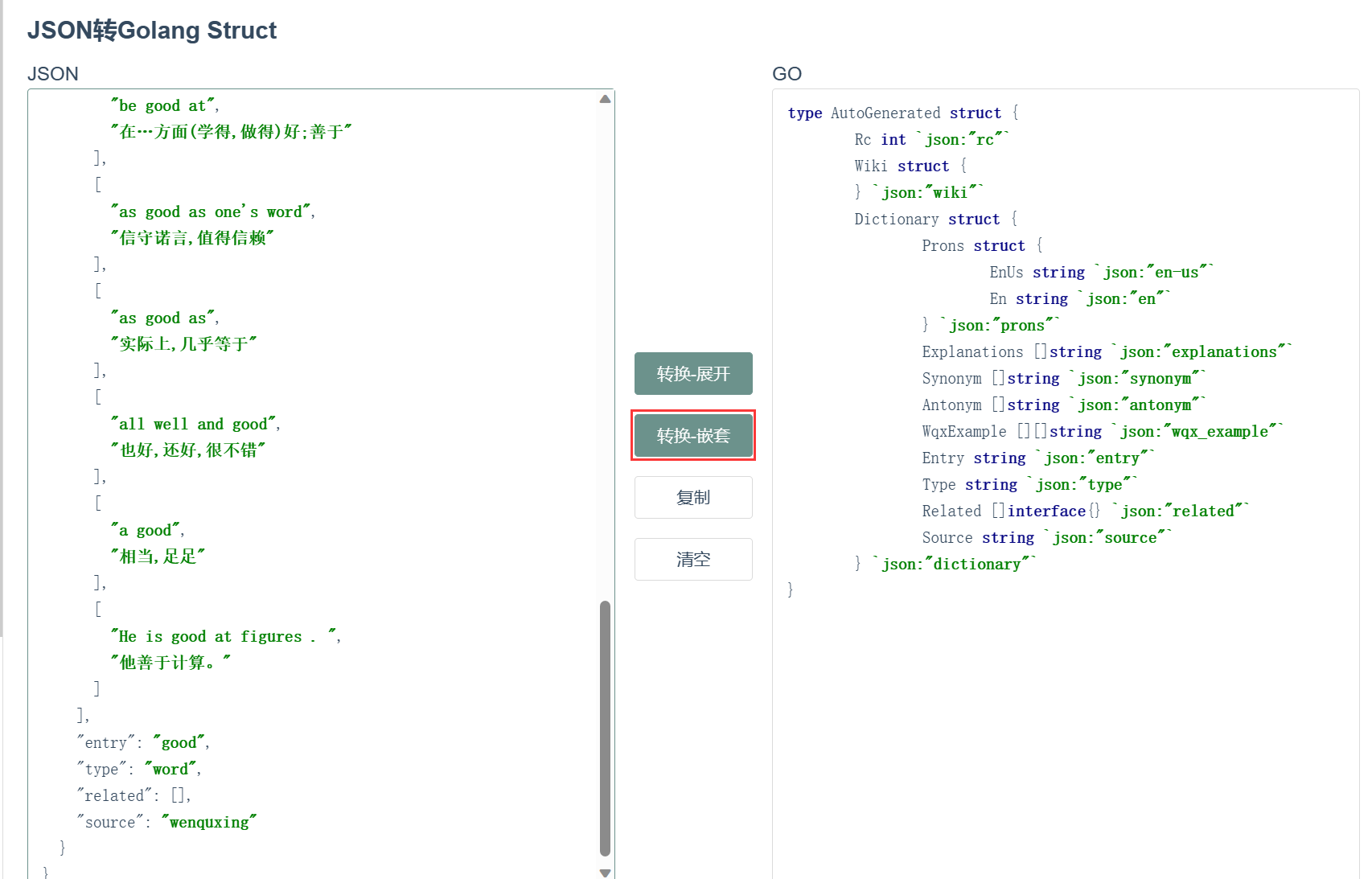
【GO】go语言入门实战 —— 命令行在线词典
文章目录 程序介绍抓包代码生成生成request body解析respond body完整代码 字节青训营基础班学习记录。 程序介绍 在运行程序的时候以命令行的形式输入要查询的单词,然后程序返回单词的音标、释义等信息。 示例如下: 抓包 我们选择与网站https://fany…...
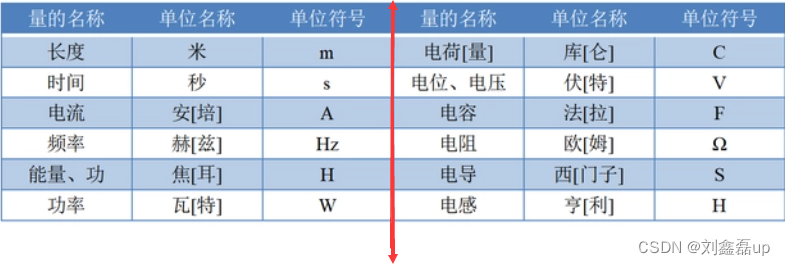
模电模电基础知识学习笔记汇总
来源:一周搞(不)定数电模电全集,电子基础知识 11小时 一:模电学习笔记 模电主要讲述:对模拟信号进行产生、放大和处理的模拟集成电路重点知识:常用电子元器件:电阻、电容、电感、保…...
招商银行秋招攻略和考试内容详解
招商银行秋招简介 招商银行是一家股份制商业银行,银行的服务理念已经深入人心,在社会竞争愈来愈烈的今天,招商银行的招牌无疑是个香饽饽,很多人也慕名而至,纷纷向招商银行投出了简历。那么秋招银行的秋招开始时间是多…...

【Linux】四、开发工具
一、vim 编辑器(只能写代码) 1、只关注如何写代码,不会关注代码的正确性; 2、一般写代码在Windows环境下写,而vim是Linux下相对来说功能最强的编辑器; 二、vim的操作 vim ---打开vim shift键 加 ࿱…...
前后端分离实现博客系统
文章目录 博客系统前言1. 前端1.1 登陆页面1.2 博客列表页面1.3 博客详情页面1.4 博客编辑页面 2. 后端2.1 项目部署2.1.1 创建maven项目2.1.2 引入依赖2.1.3 创建目录结构2.1.4 部署程序 2.2 逻辑设计2.2.1 数据库设计2.2.2 实体类设计2.2.3 Dao层设计2.2.3.1 BlogDao 2.2.4 D…...
:TypeScript 中的泛型是什么?)
面试题-TS(六):TypeScript 中的泛型是什么?
面试题-TS(6):TypeScript 中的泛型是什么? 在TypeScript中,泛型(Generics)是一种强大的特性,它允许我们在编写可重用的代码时增加灵活性。泛型使得我们可以编写不特定数据类型的代码,从而提高代…...
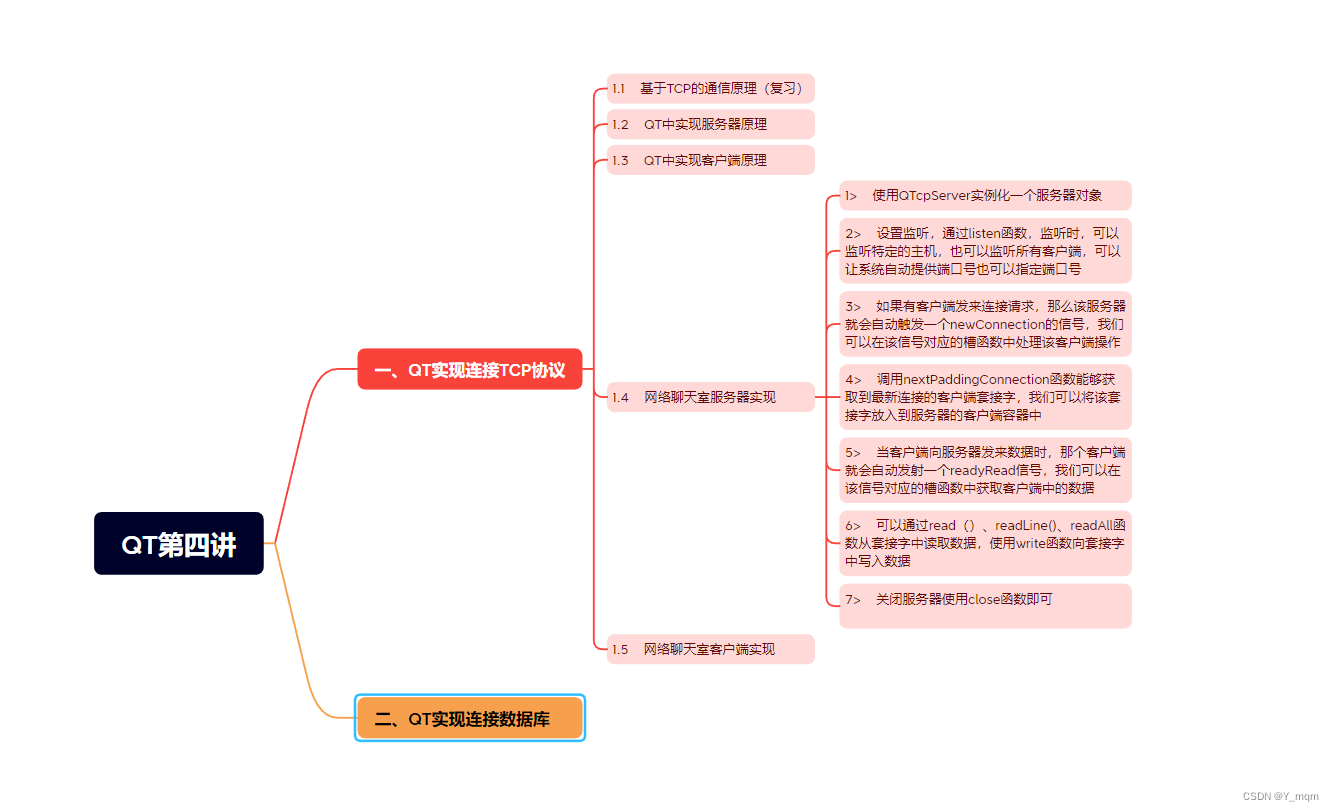
QT DAY4
1.思维导图 2.手动完成服务器的实现,并具体程序要注释清楚 头文件 #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QTcpServer> #include <QTcpSocket> #include <QMessageBox> #include <QList> #include <QD…...

最新Ai创作源码ChatGPT商用运营源码/支持GPT4.0+支持ai绘画+支持Mind思维导图生成
本系统使用Nestjs和Vue3框架技术,持续集成AI能力到本系统! 支持GPT3模型、GPT4模型Midjourney专业绘画(全自定义调参)、Midjourney以图生图、Dall-E2绘画Mind思维导图生成应用工作台(Prompt)AI绘画广场自定…...

ScienceDecrypting:终极PDF文档解密教程,永久解除CAJViewer时间限制
ScienceDecrypting:终极PDF文档解密教程,永久解除CAJViewer时间限制 【免费下载链接】ScienceDecrypting 破解CAJViewer带有效期的文档,支持破解科学文库、标准全文数据库下载的文档。无损破解,保留文字和目录,解除有效…...
:单例模式——全局唯一实例的正确打开方式)
设计模式实战解读(一):单例模式——全局唯一实例的正确打开方式
本文是「设计模式实战解读」系列第一篇。系列文章统一按照 定义 → 痛点场景 → 模式结构 → 核心实现 → 真实应用 → 常见变种 → 优缺点 → 避坑指南 → FAQ 的结构展开,每篇聚焦一个模式讲透。一句话定义 单例模式(Singleton):…...

DouYinBot 抖音无水印视频解析工具:3分钟快速搭建个人解析服务
DouYinBot 抖音无水印视频解析工具:3分钟快速搭建个人解析服务 【免费下载链接】DouYinBot 该项目仅自用,不提供抖音视频下载 项目地址: https://gitcode.com/gh_mirrors/do/DouYinBot 在抖音内容创作日益普及的今天,如何快速获取无水…...
)
别再只调包了!手把手教你用Python+SVM从零搭建一个中文情感分析系统(附完整代码)
从零构建中文情感分析系统:SVM实战与避坑指南第一次尝试用机器学习处理中文文本时,我被"的得地"分词的混乱结果震惊了——这堆毫无意义的字符组合,真的能训练出识别情感的模型吗?三年前那个深夜,当我看着自己…...
)
023、PCB设计软件选择与安装(Altium Designer)
023、PCB设计软件选择与安装(Altium Designer) 从一块烧掉的板子说起 去年冬天,我接手一个同事离职留下的项目——一块四层板的电机驱动板。原理图看着没问题,Layout也走通了,打样回来上电,MOS管直接冒烟。排查三天,最后发现是电源回路的地线回流路径被一根细长的走线…...

Java+Selenium等待机制实战:显式等待、FluentWait与SPA适配
1. 为什么“等”这件事,比写代码还难? 在JavaSelenium项目里,我见过太多人把WebDriver写得行云流水,结果一跑自动化脚本就卡在“元素找不到”上——不是代码写错了,是 没等对 。你点一个按钮,页面跳转、数…...

近场通信连续孔径阵列技术与波传播建模
1. 近场通信中的连续孔径阵列技术在无线通信领域,近场通信技术正经历着从传统离散天线阵列向连续孔径阵列的范式转变。这种技术演进的核心在于对电磁波前进行前所未有的精细控制,特别是在6G及未来通信系统的研发中展现出巨大潜力。连续孔径阵列与传统天线…...

3D层析SAR与AutoML融合:实现高精度森林树种自动识别
1. 项目概述:当3D雷达“透视”森林,机器学习如何识别每一棵树?在森林资源管理与生态研究中,准确识别树种一直是个既基础又棘手的难题。传统的野外调查方法,依赖人力跋山涉水,不仅成本高昂、效率低下&#x…...

混沌时间序列预测:轻量级方法为何完胜复杂深度学习模型?
1. 项目概述与核心洞察在时间序列预测这个领域,尤其是在处理像洛伦兹系统这样的低维混沌动力系统时,我们常常会陷入一个思维定式:模型越复杂、参数越多、计算量越大,预测效果就应该越好。这个想法很自然,毕竟深度学习在…...

Claude API文档不是说明书,而是契约:用Swagger UI+Postman Collection+TypeScript SDK三件套构建零歧义协作协议
更多请点击: https://kaifayun.com 第一章:Claude API文档不是说明书,而是契约 Claude API 文档的本质并非操作指南或功能速查手册,而是一份具有技术约束力的**双向契约**——它明确定义了客户端与 Anthropic 服务之间在请求结构…...