SpringBoot集成Flink-CDC 采集PostgreSQL变更数据发布到Kafka
最近做的一个项目,使用的是pg数据库,公司没有成熟的DCD组件,为了实现数据变更消息发布的功能,我使用SpringBoot集成Flink-CDC 采集PostgreSQL变更数据发布到Kafka。
一、业务价值
监听数据变化,进行异步通知,做系统内异步任务。
架构方案(懒得写了,看图吧):

二、修改数据库配置
2.1、更改配置文件postgresql.conf
# 更改wal日志方式为logical(必须)
wal_level = logical # minimal, replica, or logical# 更改solts最大数量(默认值为10),flink-cdc默认一张表占用一个slots(每个文档都这么说,但根据我的实际操作来看,一个flink-cdc服务占用一个槽,但是要大于默认值10)
max_replication_slots = 20 # max number of replication slots# 更改wal发送最大进程数(默认值为10),这个值和上面的solts设置一样
max_wal_senders = 20 # max number of walsender processes
# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s)
wal_sender_timeout = 180s # in milliseconds; 0 disable
2.2、创建数据变更采集用户及赋权
-- 创建pg 高线数据同步用户
create user offline_data_user with password 'password';-- 给用户复制流权限
alter role offline_data_user replication;-- 给用户登录pmsdb数据库权限
grant connect on database 数据库名 to offline_data_user;-- 给用户授予数据库XXXX下某些SCHEMA的XXX表的读作权限
grant select on all tables in SCHEMA 某 to offline_data_user;grant usage on SCHEMA 某 to offline_data_user;
2.3、发布表
-- 设置表发布为true
update pg publication set pubalitables=true where pubname is not null;-- 发表所有表
create PUBLICATION dbz publication FOR ALL TABLES;
三、SpringBoot集成Flink-CDC
3.1、添加Flink-CDC的依赖
<properties><flink.version>1.16.0</flink.version><flink-pg.version>2.3.0</flink-pg.version>
</properties>
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-connector-postgres-cdc</artifactId><version>${flink-pg.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency>
</dependencies>
3.2 构建数据源
数据转换类,将从数据库采集的转成你想要的格式:
{
"beforeData": "",
"afterData": "",
"eventType": "",
"database": "",
"schema": "",
"tableName": "",
"changeTime": 0
}
数据实体类 DataChangeInfo
package com.jie.flink.cdc.doman;import lombok.Data;import java.io.Serializable;/*** @author zhanggj* @data 2023/1/31*/
@Data
public class DataChangeInfo implements Serializable {/*** 变更前数据*/private String beforeData;/*** 变更后数据*/private String afterData;/*** 变更类型 create=新增、update=修改、delete=删除、read=初始读*/private String eventType;/*** 数据库名*/private String database;/*** schema*/private String schema;/*** 表名*/private String tableName;/*** 变更时间*/private Long changeTime;
}
数据解析类PostgreSQLDeserialization
package com.jie.flink.cdc.flinksource;import com.esotericsoftware.minlog.Log;
import com.jie.flink.cdc.datafilter.PostgreSQLDataFilter;
import com.jie.flink.cdc.doman.DataChangeInfo;
import com.jie.flink.cdc.util.JsonUtils;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.Optional;/*** @author zhanggj* @data 2023/1/31* 数据转换*/
@Slf4j
public class PostgreSQLDeserialization implements DebeziumDeserializationSchema<String> {public static final String TS_MS = "ts_ms";public static final String DATABASE = "db";public static final String SCHEMA = "schema";public static final String TABLE = "table";public static final String BEFORE = "before";public static final String AFTER = "after";public static final String SOURCE = "source";/**** 反序列化数据,转为变更JSON对象* @param sourceRecord* @param collector* @return void* @author lei* @date 2022-08-25 14:44:31*/@Overridepublic void deserialize(SourceRecord sourceRecord, Collector<String> collector) {final String topic = sourceRecord.topic();log.debug("收到{}的消息,准备进行转换", topic);final DataChangeInfo dataChangeInfo = new DataChangeInfo();final Struct struct = (Struct) sourceRecord.value();final Struct source = struct.getStruct(SOURCE);dataChangeInfo.setBeforeData( getDataJsonString(struct, BEFORE));dataChangeInfo.setAfterData(getDataJsonString(struct, AFTER));//5.获取操作类型 CREATE UPDATE DELETEEnvelope.Operation operation = Envelope.operationFor(sourceRecord);dataChangeInfo.setEventType(operation.toString().toLowerCase());dataChangeInfo.setDatabase(Optional.ofNullable(source.get(DATABASE)).map(Object::toString).orElse(""));dataChangeInfo.setSchema(Optional.ofNullable(source.get(SCHEMA)).map(Object::toString).orElse(""));dataChangeInfo.setTableName(Optional.ofNullable(source.get(TABLE)).map(Object::toString).orElse(""));dataChangeInfo.setChangeTime(Optional.ofNullable(struct.get(TS_MS)).map(x -> Long.parseLong(x.toString())).orElseGet(System::currentTimeMillis));log.info("收到{}的{}类型的消息, 已经转换好了,准备发往sink", topic, dataChangeInfo.getEventType());//7.输出数据collector.collect(JsonUtils.toJSONString(dataChangeInfo));}private String getDataJsonString(final Struct struct, final String fieldName) {if (Objects.isNull(struct)) {return null;}final Struct element = struct.getStruct(fieldName);if (Objects.isNull(element)) {return null;}Map<String, Object> dataMap = new HashMap<>();Schema schema = element.schema();List<Field> fieldList = schema.fields();for (Field field : fieldList) {dataMap.put(field.name(), element.get(field));}return JsonUtils.toJSONString(dataMap);}@Overridepublic TypeInformation<String> getProducedType() {return TypeInformation.of(String.class);}
}
构建PG数据源PostgreSQLDataChangeSource
package com.jie.flink.cdc.flinksource;import com.jie.flink.cdc.datafilter.PostgreSQLReadDataFilter;
import com.ververica.cdc.connectors.postgres.PostgreSQLSource;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import lombok.Data;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;import java.util.Properties;
import java.util.UUID;/*** @author zhanggj* @data 2023/2/10* flink pg 数据源配置*/
@Data
@Component
public class PostgreSQLDataChangeSource {/*** 数据库hostname*/private String hostName;/*** 数据库 端口*/private Integer port;/*** 库名*/private String database;/*** 用户名*/@Value("${spring.datasource.username}")private String userName;/*** 密码*/@Value("${spring.datasource.password}")private String password;/*** schema 组*/@Value("${jie.flink-cdc.stream.source.schemas:test_schema}")private String[] schemaArray;/*** 要监听的表*/@Value("${jie.flink-cdc.stream.source.schemas:test_table}")private String[] tableArray;/*** 是否忽略初始化扫描数据*/@Value("${jie.flink-cdc.stream.source.init-read.ignore:false}")private Boolean initReadIgnore;@Value("${spring.datasource.url}")private void splitUrl(String url) {final String[] urlSplit = StringUtils.split(url, "/");final String[] hostPortSplit = StringUtils.split(urlSplit[1], ":");this.hostName = hostPortSplit[0];this.port = Integer.parseInt(hostPortSplit[1]);this.database = StringUtils.substringBefore(urlSplit[2], "?");}@Bean("pgDataSource")public DebeziumSourceFunction<String> buildPostgreSQLDataSource() {Properties properties = new Properties();// 指定连接器启动时执行快照的条件:****重要*****//initial- 连接器仅在没有为逻辑服务器名称记录偏移量时才执行快照。//always- 连接器每次启动时都会执行快照。//never- 连接器从不执行快照。//initial_only- 连接器执行初始快照然后停止,不处理任何后续更改。//exported- 连接器根据创建复制槽的时间点执行快照。这是一种以无锁方式执行快照的绝佳方式。//custom- 连接器根据snapshot.custom.class属性的设置执行快照properties.setProperty("debezium.snapshot.mode", "initial");properties.setProperty("snapshot.mode", "initial");// 好像不起作用使用slot.nameproperties.setProperty("debezium.slot.name", "pg_cdc" + UUID.randomUUID());properties.setProperty("slot.name", "flink_slot" + UUID.randomUUID());properties.setProperty("debezium.slot.drop.on.top", "true");properties.setProperty("slot.drop.on.top", "true");// 更多参数配置参考debezium官网 https://debezium.io/documentation/reference/1.2/connectors/postgresql.html?spm=a2c4g.11186623.0.0.4d485fb3rgWieD#postgresql-property-snapshot-mode// 或阿里文档 https://help.aliyun.com/document_detail/184861.htmlPostgreSQLDeserialization deserialization = null;if (initReadIgnore) {properties.setProperty("debezium.snapshot.mode", "never");properties.setProperty("snapshot.mode", "never");deserialization = new PostgreSQLDeserialization(new PostgreSQLReadDataFilter());} else {deserialization = new PostgreSQLDeserialization();}return PostgreSQLSource.<String>builder().hostname(hostName).port(port).username(userName).password(password).database(database).schemaList(schemaArray).tableList(tableArray).decodingPluginName("pgoutput").deserializer(deserialization).debeziumProperties(properties).build();}
}
改正:数据源配置的slot.name不能配置随机的id,需要固定,因为这个涉及到wal日志采集,一个槽记录了一种客户端的采集信息(里面会有当前客户端的checkpoint)。因此对于一个数据源来说这个slot.name应该是固定的。至于高可用,只有主备这种方案……
3.3、构建kafkaSink
package com.jie.flink.cdc.flinksink;import lombok.Data;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;/*** @author zhanggj* @data 2023/2/10* flink kafka sink配置*/
@Data
@Component
public class FlinkKafkaSink {@Value("${jie.flink-cdc.stream.sink.topic:offline_data_topic}")private String topic;@Value("${spring.kafka.bootstrap-servers}")private String kafkaBootstrapServers;@Bean("kafkaSink")public KafkaSink buildFlinkKafkaSink() {return KafkaSink.<String>builder().setBootstrapServers(kafkaBootstrapServers).setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic(topic).setValueSerializationSchema(new SimpleStringSchema()).build()).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();}
}
3.4、创建flink-cdc监听
利用springboot的特性, 实现CommandLineRunner将flink-cdc 作为一个项目启动时需要运行的分支子任务即可
package com.jie.flink.cdc.listener;import com.jie.flink.cdc.flinksink.DataChangeSink;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;import java.time.Duration;/*** @author zhanggj* @data 2023/1/31* 监听数据变更*/
@Component
public class PostgreSQLEventListener implements CommandLineRunner {private final DataChangeSink dataChangeSink;private final KafkaSink<String> kafkaSink;private final DebeziumSourceFunction<String> pgDataSource;public PostgreSQLEventListener(final DataChangeSink dataChangeSink,final KafkaSink<String> kafkaSink,final DebeziumSourceFunction<String> pgDataSource) {this.dataChangeSink = dataChangeSink;this.kafkaSink = kafkaSink;this.pgDataSource = pgDataSource;}@Overridepublic void run(final String... args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.disableOperatorChaining();env.enableCheckpointing(6000L);// 配置checkpoint 超时时间env.getCheckpointConfig().setCheckpointTimeout(Duration.ofMinutes(60).toMillis());//指定 CK 的一致性语义env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);//设置任务关闭的时候保留最后一次 CK 数据env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 避免扫描快照超时env.getCheckpointConfig().setTolerableCheckpointFailureNumber(100);env.getCheckpointConfig().setCheckpointInterval(Duration.ofMinutes(10).toMillis());// 指定从 CK 自动重启策略env.setRestartStrategy(RestartStrategies.fixedDelayRestart(Integer.MAX_VALUE, 2000L));//设置状态后端env.setStateBackend(new HashMapStateBackend());DataStreamSource<String> pgDataStream = env.addSource(pgDataSource, "PostgreSQL-source").setParallelism(1);// sink到kafkapgDataStream.sinkTo(kafkaSink).name("sink2Kafka");env.execute("pg_cdc-kafka");}}
四、遇到的问题与解决
1、pg配置没有修改,DBA说一般情况下都有改过wal_level,呵呵,一定要确认wal_level = logical是必须的。
2、Creation of replication slot failed …… FATAL:number of requested standby connections exceeds max_wal_senders (currently 10)
求DBA大佬吧,需要改
3、Failed to start replication stream at LSN{0/1100AA50}; when setting up multiple connectors for the same database host, please make sure to use a distinct replication slot name for each.
很多文档理提供的创建数据源的代码里都只是指定了一个固定的slot.name 当你启动多个SpringBoot服务时,会报这个错误,我这个代码里直接用了UUID,其他能区分不同服务的也可以的。
properties.setProperty("debezium.slot.name", "pg_cdc" + UUID.randomUUID());properties.setProperty("slot.name", "flink_slot" + UUID.randomUUID());4、服务启动后一直在扫描快照数据,看日志,报了超时异常(异常找不到了,有空了造个再发出来)。
原因:(官网)During scanning snapshot of database tables, since there is no recoverable position, we can’t perform checkpoints. In order to not perform checkpoints, Postgres CDC source will keep the checkpoint waiting to timeout. The timeout checkpoint will be recognized as failed checkpoint, by default, this will trigger a failover for the Flink job. So if the database table is large, it is recommended to add following Flink configurations to avoid failover because of the timeout checkpoints:【Postgres CDC暂不支持在全表扫描阶段执行Checkpoint。如果您的作业在全表扫描阶段触发Checkpoint,则可能由于Checkpoint超时导致作业Failover。因此,建议您在作业开发页面高级配置的更多Flink配置中配置如下参数,避免在全量同步阶段由于Checkpoint超时导致Failover。】
execution.checkpointing.interval: 10min execution.checkpointing.tolerable-failed-checkpoints: 100 restart-strategy: fixed-delay restart-strategy.fixed-delay.attempts: 2147483647
代码:
// 避免扫描快照超时env.getCheckpointConfig().setTolerableCheckpointFailureNumber(100);env.getCheckpointConfig().setCheckpointInterval(Duration.ofMinutes(10).toMillis());// 指定从 CK 自动重启策略env.setRestartStrategy(RestartStrategies.fixedDelayRestart(Integer.MAX_VALUE, 2000L));或者改超时时间配置
// 配置checkpoint 超时时间env.getCheckpointConfig().setCheckpointTimeout(Duration.ofMinutes(600).toMillis());没错,上面的时600分钟,其实对于我们的数据量(8千多万)60分钟这个配置还是不够的(单机),因此用了600分钟,但是,真正运行后报了另外的问题 OOM:Java heap space……
最后,直接关掉了快照数据的扫描
properties.setProperty("debezium.snapshot.mode", "never");properties.setProperty("snapshot.mode", "never");五、参考文档
Postgres的CDC源表
Debezium官网参数说明
flink cdc 整理
相关文章:
SpringBoot集成Flink-CDC 采集PostgreSQL变更数据发布到Kafka
最近做的一个项目,使用的是pg数据库,公司没有成熟的DCD组件,为了实现数据变更消息发布的功能,我使用SpringBoot集成Flink-CDC 采集PostgreSQL变更数据发布到Kafka。 一、业务价值 监听数据变化,进行异步通知…...

酷开系统壁纸模式,将氛围感死死拿捏!
古希腊哲学家柏拉图曾经说过:“美感是起于视觉、听觉产生的快感,以人的感官所能达到的范围为极限。”而电视则恰恰就是视觉听觉的完美融合体,当一台开启的电视可以给我们带来视听享受的时候,一台待机状态下的电视又如何取悦于我们…...

第0章 一些你可能正感到迷惑的问题
操作系统是什么 操作系统是控制管理计算机系统的硬软件,分配调度资源的系统软件。 由操作系统把资源获取到后台给用户进程,但为了保护计算机系统不被损坏,不允许用户进程直接访问硬件资源。 操作系统相当于是一个分配资源的机构,…...
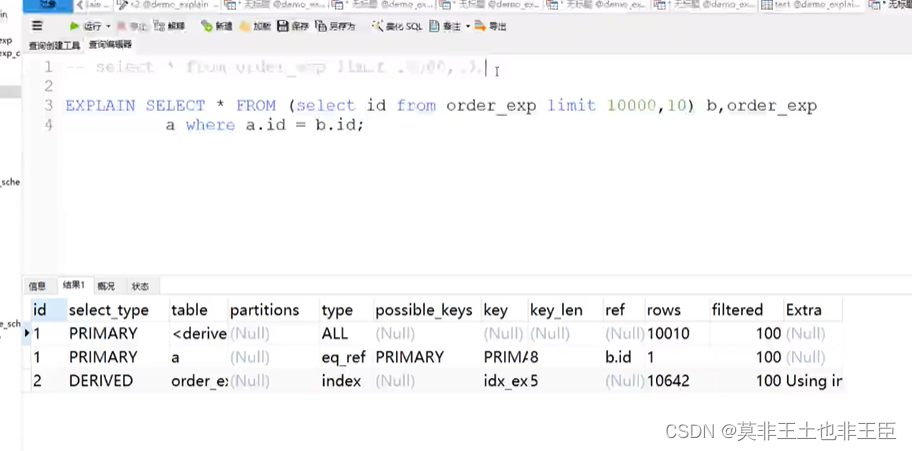
MYSQL实战
SQL的处理 缓存解析查询优化(查询优化器) 重写查询;表的读取顺序;选择索引1.不要在索引上做任何操作 表达式函数 2.尽量全值匹配 联合索引中搜素条件后会根据最优条件排序进行查询,联合索引尽量都使用起来。搜索条…...

少儿户外拓展北斗定位解决方案
一、项目背景户外拓展训练是指通过专业的机构,对久居城市的人进行的一种野外生存训练。拓展训练通常利用崇山峻岭、翰海大川等自然环境,通过精心设计的活动达到“磨练意志、陶冶情操、完善人格、熔炼团队”的培训目的。针对户外拓展人员安全管理存在的实…...
更换ssl证书
更换ssl证书常用证书查看以及转换网址阿里云判断流量以及配置证书判断接入点阿里云控制台配置证书WAFAzure判断流量以及配置证书:判断接入点Azure配置证书CDNAPP GateWay常用证书查看以及转换网址 https://www.chinassl.net/ssltools/convert-ssl.htmlhttps://myss…...
线程池源码解析项目中如何配置线程池
目录 基础回顾 线程池执行任务流程 简单使用 构造函数 execute方法 execute中出现的ctl属性 execute中出现的addWorker方法 addWorker中出现的addWorkerFailed方法 addWorker中出现的Worker类 Worker类中run方法出现的runWorker方法 runWorker中出现的getTask runWo…...
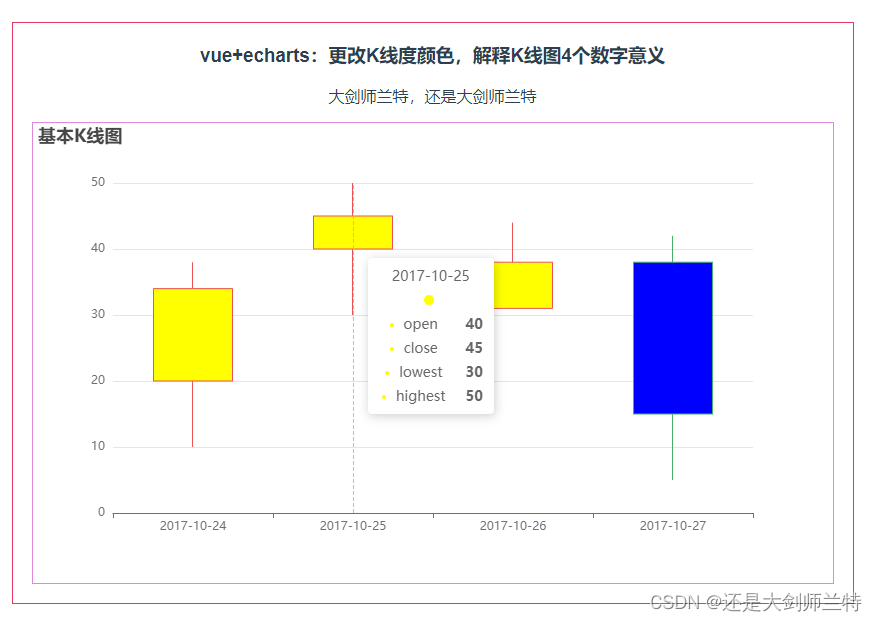
Echarts 更改K线度颜色,解释K线图4个数字意义
第019个点击查看专栏目录本示例修改K线度的颜色,方法参考源代码。 这里面讲一下K线图的四个数字,如[20, 34, 10, 38], 第一位:20代表开盘价格, 第二位:34代表闭盘价格, 第三位:10代表最低价&…...

JavaScript和Java两种方法实现百度地图和高德、腾讯地图的相互转换
目录一、常见的经纬度标准二、百度地图和高德、腾讯地图经纬度的转换1、前端JavaScript转换2、后端Java实现转换一、常见的经纬度标准 高德、腾讯(使用GCJ02) GCJ-02坐标系,也称火星坐标系,由中国国家测绘局在02年发布࿰…...

Vue中常见的几种组件间通信方法
1.props(父传子) 父组件Parent.vue <template><child :msg"message"></child> </template>父组件通过:val"value"的形式定义要传给子组件的值value绑定到val上 子组件Child.vue export default {//写法一…...
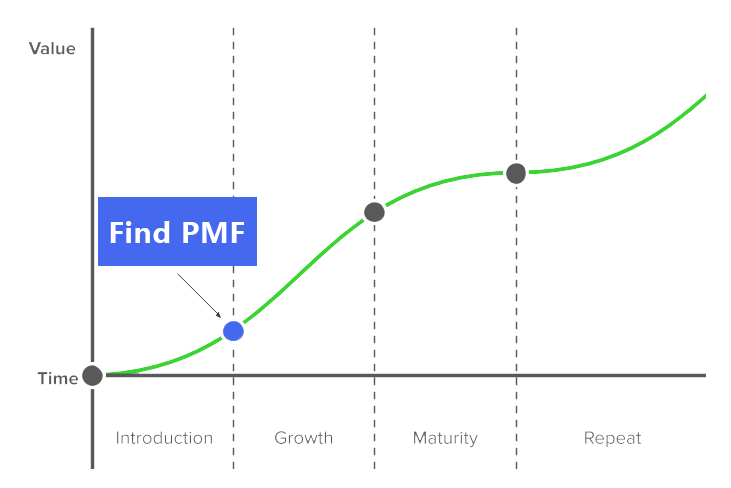
Outcome VS. Output:研发效能提升中,谁会更胜一筹?
2007 年,网景通信公司(Netscape)的联合创始人 Marc Andreessen 在博客 The Pmarca Guide to Startups 中提出 「Product/Market Fit」 ,他写道, 「这意味着在一个良好的市场中,拥有能够满足该市场的产品。」…...

ptp4l与phc2sys进行系统时钟同步
linuxptp用于时钟同步。安装采用apt install linuxptp主要包含2个程序,ptp4l 进行时钟同步,实时网卡时钟与远端的时钟同步,支持1588 和 802.1AS 两种协议phc2sys 将网卡上的时钟同步到操作系统,或者反之命令demo:某主机P通过eth2连…...

使用注解JSON序列化
JsonSerialize(using ToStringSerializer.class) 将返回数据转成String序列化 JsonFormat(pattern "yyyy-MM-dd hh:mm",timezone"GMT8") 将日期数据转换成特定格式 使用JsonSerialize自定义注解接口 定义接口 import java.lang.annotation.ElementTyp…...
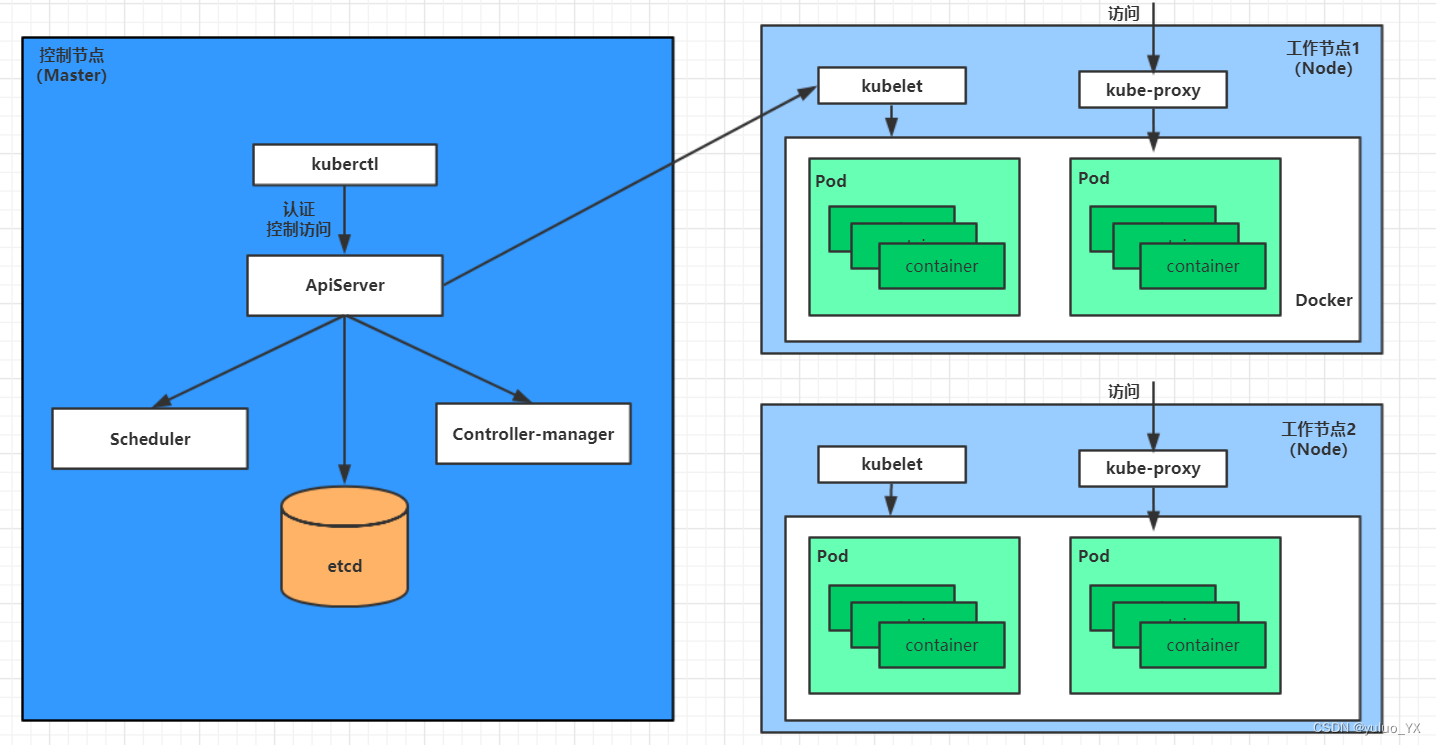
kubernetes教程 --Pod生命周期
Pod生命周期 pod创建过程运行初始化容器(init container)过程运行主容器(main container)过程 容器启动后钩子(post start)、容器终止前钩子(pre stop)容器的存活性探测(…...
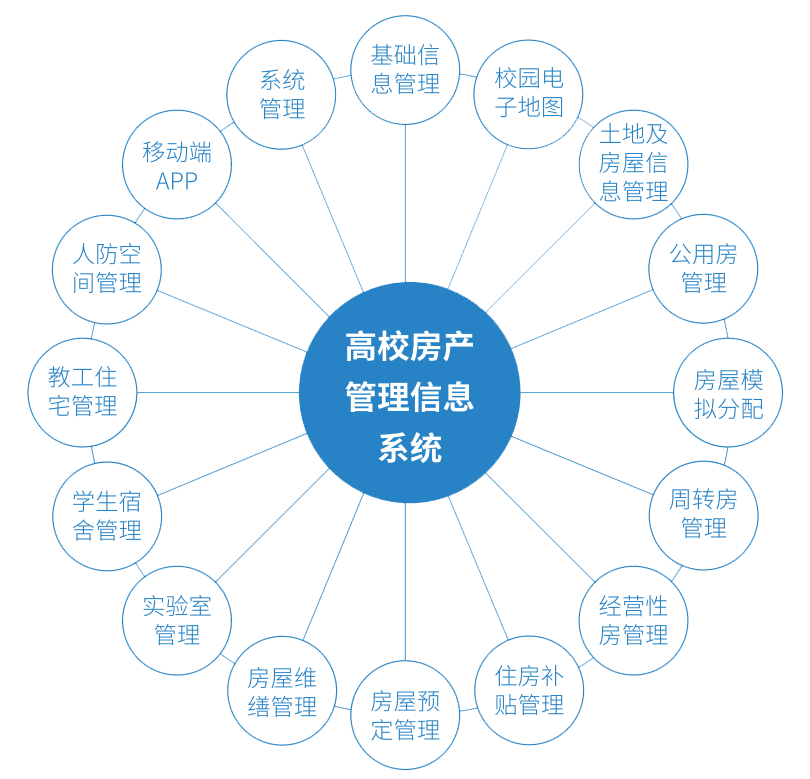
高校房产管理系统用到了哪些技术?
数图互通高校房产管理系统是基于公司自主研发的FMCenterV5.0平通过在中国100多所高校的成功实施和迭代,形成了一套成熟、完善、全生命周期的房屋资源管理解决方案。台,是针对中国高校房产的管理特点和管理要求,研发的一套标准产品;…...
)
【Python学习笔记】37.Python3 MySQL - mysql-connector 驱动(2)
前言 本章继续介绍MySQL - mysql-connector 驱动。 where 条件语句 如果我们要读取指定条件的数据,可以使用 where 语句: demo_mysql_test.py 读取 name 字段为 CSDN 的记录: import mysql.connectormydb mysql.connector.connect(host…...

【高级Java】高级Java实验
一、反射与动态代理1、(4分)请通过反射技术,为附件中的Person.class生成相应的.java代码,java代码中的方法的方法体为空,即方法内部代码不用生成。请注意生成的java代码的格式。2、(3分)请为第1…...
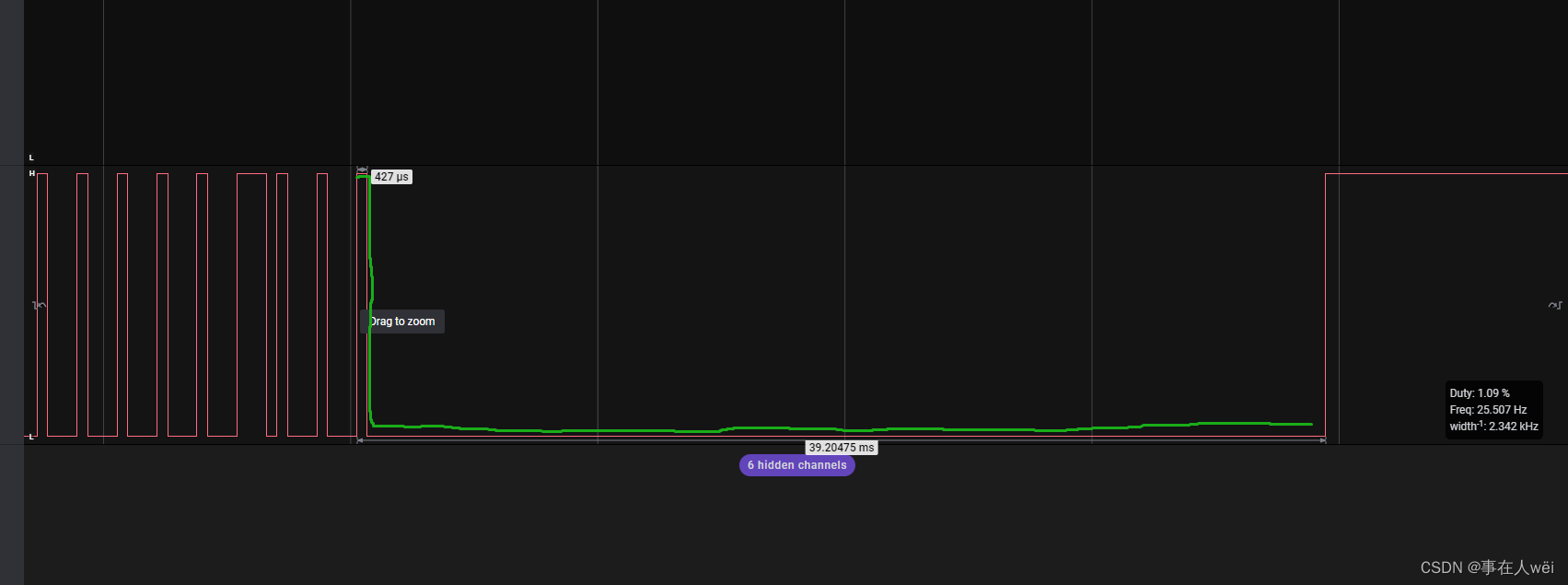
SYN480R 解码
目录1.空载情况下2.当有按键被按下3.数据帧分析4.同步码5.数据码6.对24位数据帧分析1.空载情况下 在空载情况下,syn480r 输出引脚,输出的是杂乱无序的波形 2.当有按键被按下 按下按键,会连续输出相同的脉冲波形,放大分析 3.数据…...
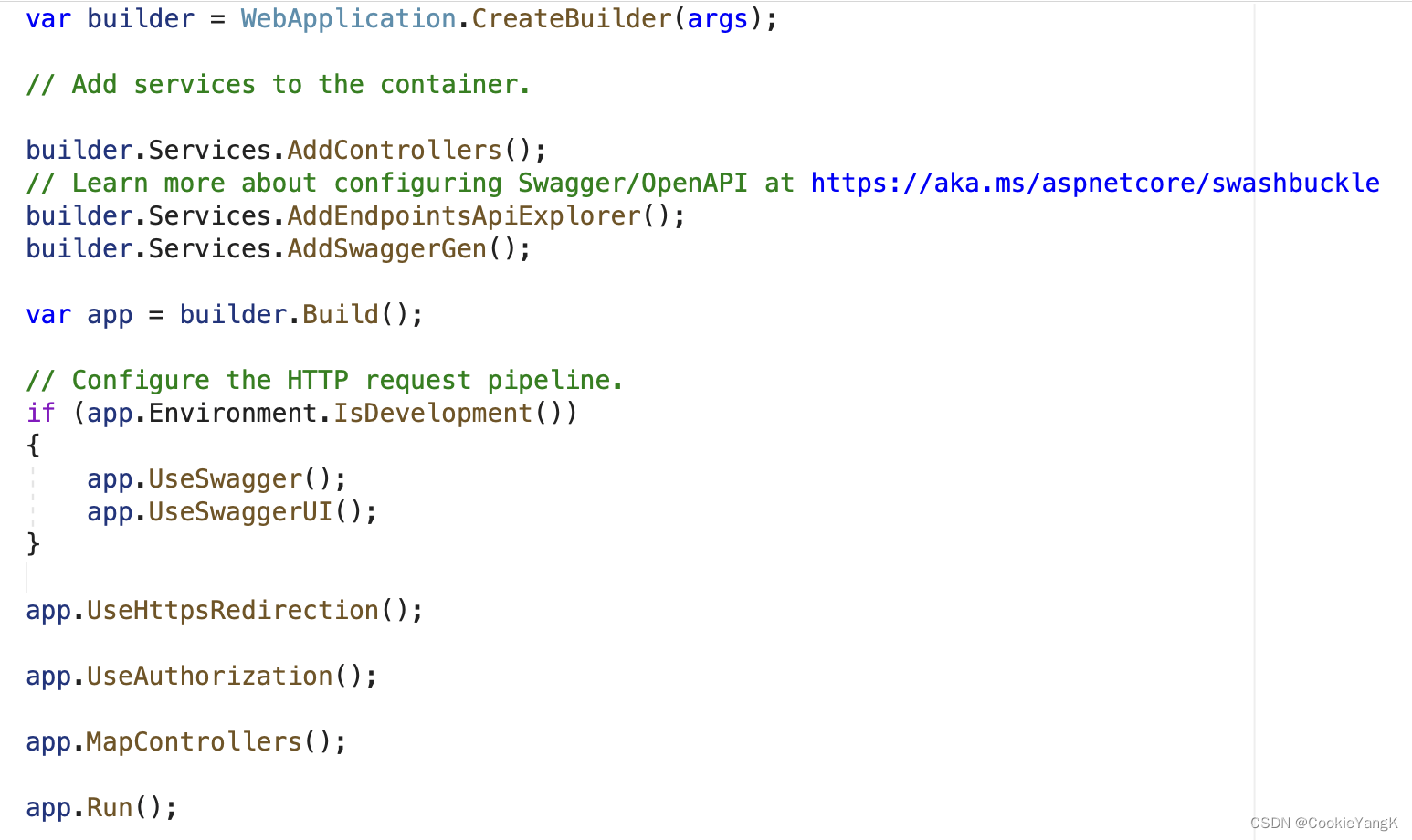
ASP .NET(基于.NET 6.0)源码解读
这几天一直在琢磨在我现有技术认知基础上,未来如何做技术提升。 日思夜想,我整理出了我自己的一套学习规划方案,并希望在实施过程中能够不断调整学习方案与方式,以接近自我提升的效率最大化。 从以下几个大的方面来得到提升&…...

阿里工作7年,一个30岁女软件测试工程师的心路历程
简单的先说一下,坐标杭州,14届本科毕业,算上年前在阿里巴巴的面试,一共有面试了有6家公司(因为不想请假,因此只是每个晚上去其他公司面试,所以面试的公司比较少) 其中成功的有4家&am…...

一站式解决Windows程序运行问题的Visual C++运行库修复指南
一站式解决Windows程序运行问题的Visual C运行库修复指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时突然弹窗提示"缺少msv…...

如何在Windows电脑上轻松安装安卓应用:5步完成轻量级跨平台部署
如何在Windows电脑上轻松安装安卓应用:5步完成轻量级跨平台部署 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想在Windows电脑上运行安卓应用&…...

从自由建模到精确设计:CAD_Sketcher如何为Blender带来工程级草图绘制能力
从自由建模到精确设计:CAD_Sketcher如何为Blender带来工程级草图绘制能力 【免费下载链接】CAD_Sketcher Constraint-based geometry sketcher for blender 项目地址: https://gitcode.com/gh_mirrors/ca/CAD_Sketcher 你是否曾在使用Blender进行机械设计时&…...

Gmail只读命令行工具gcli:云端自动化邮件查询与SSH隧道授权方案
1. 项目概述:一个专为自动化场景设计的Gmail只读命令行工具 如果你和我一样,经常需要在没有图形界面的云服务器上处理邮件查询任务,那你一定对Gmail API的授权流程深恶痛绝。传统的OAuth流程要求你在浏览器里点来点去,但服务器上哪…...

管理幅度怎样设置才合理?
https://mp.weixin.qq.com/s/aoUgKUmsOUyC7wWOONMIIw...

中国行政区划数据生成器:开发者的地理数据基础设施解决方案
中国行政区划数据生成器:开发者的地理数据基础设施解决方案 【免费下载链接】chinese-address-generator 中国地址生成器 - 三级地址 四级地址 随机生成完整地址 项目地址: https://gitcode.com/gh_mirrors/ch/chinese-address-generator 在现代软件开发过程…...

效率翻倍!用 ModelSim 2019.2 给 Vivado 2020.2 工程做仿真的几个高级技巧
效率翻倍!用 ModelSim 2019.2 给 Vivado 2020.2 工程做仿真的几个高级技巧 对于已经熟悉Vivado与ModelSim基础联合仿真流程的开发者来说,真正的挑战往往在于如何突破常规操作的限制,在大型工程中实现高效调试。本文将分享三个经过实战验证的高…...

为什么你需要LRCGET:5步为离线音乐库实现完美歌词同步
为什么你需要LRCGET:5步为离线音乐库实现完美歌词同步 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 还在为数千首离线音乐缺少歌词而烦恼…...
)
从机器学习转做DFT计算?手把手教你用Python ASE库搞定VASP输入文件(含VC++14安装避坑)
从机器学习转做DFT计算?用Python ASE库高效构建VASP输入文件全指南 当机器学习背景的研究者首次接触第一性原理计算时,往往会被VASP等传统软件的复杂输入文件格式所困扰。POSCAR、INCAR、KPOINTS这些文件的手动编写不仅耗时,还容易出错。本文…...

NAND闪存市场演进:从消费电子到AI时代的技术博弈与产业洞察
1. 从一篇旧闻说起:NAND闪存市场的“过山车”与底层逻辑最近在整理资料时,翻到一篇2012年的行业旧闻,标题是《平板电脑需求推动NAND闪存增长》。文章的核心观点很明确:以智能手机、平板电脑(当时还是iPad和安卓平板争锋…...