NoSQL--------- Redis配置与优化
目录
一、关系型数据库与非关系型数据库
1.1关系型数据库
1.2非关系型数据库Nosql
1.3关系与非关系区别
1.4非关系产生的背景
1.5总结
二、Redis介绍
2.1Redis简介
2.3Redis优点
2.4 Redis为什么这么快?
三、Redis安装部署
3.1安装redis
3.2测试redis
3.3redis-benchmark 测试工具
3.4Redis 数据库常用命令
四、Redis高可用
五、Redis 持久化
5.1RDB 持久化
(1)手动触发
(2)自动触发
(3) 执行流程
5.2AOF 持久化
5.2.1. 开启AOF
5.3 RDB和AOF的优缺点
5.3.1RDB持久化
5.3.2AOF持久化
六、Redis主从复制
一、关系型数据库与非关系型数据库
1.1关系型数据库
关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,是一种基于关系型数据库的语言,用于执行对关系型数据库中数据的检索和操作.
主流的关系型数据库包括 Oracle、MySQL、SQL Server、Microsoft Access、DB2、PostgreSQL 等。
1.2非关系型数据库Nosql
NoSQL(NoSQL = Not Only SQL ),意思是“不仅仅是 SQL”,是非关系型数据库的总称。
除了主流的关系型数据库外的数据库,都认为是非关系型。
不需要预先建库建表定义数据存储表结构,每条记录可以有不同的数据类型和字段个数(比如微信群聊里的文字、图片、视频、音乐等)。
主流的 NoSQL 数据库有 Redis、MongBD、Hbase、Memcached 等。
1.3关系与非关系区别
(1)数据存储方式不同
关系型数据天然就是表格式的。数据表可以彼此关联协作存储,也很容易提取数据。
非关系型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。(2)扩展方式不同
要支持更多并发量,SQL数据库是纵向扩展,也就是说提高处理能力,使用速度更快速的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多克服。虽然SQL数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限个表,这都需要通过提高计算机性能来。
而NoSQL数据库是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。(3)对事务性的支持不同
如果计数据操作需要高事务性或者复杂数据查询需要控制执行划,那么传统的SQL数据库从性能和稳定性方面考虑是你的最佳选择。SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务。
虽然NoSQL数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较,所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面。
1.4非关系产生的背景
(1)High performance——对数据库高并发读写需求
(2)Huge Storage——对海量数据高效存储与访问需求
(3)High Scalability && High Availability——对数据库高可扩展性与高可用性需求
1.5总结
非关系数据库
1、数据保存在缓存中,利于读取速度/查询数据
2、架构位置灵活
3、分布式、扩展性高关系数据库
1、安全性高(持久化)
2、事务处理能力强
3、任务控制能力强
4、可以做日志备份、恢复、容灾的能力更强一点
二、Redis介绍
2.1Redis简介
Redis(远程字典服务器) 是一个开源的、使用 C 语言编写的 NoSQL 数据库。
Redis 基于内存运行并支持持久化,采用key-value(键值对)的存储形式,是目前分布式架构中不可或缺的一环。Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率。若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降;若在同一台服务器上开启多个Redis进程,Redis在提高并发处理能力的同时会给服务器的CPU造成很大压力。即:在实际生产环境中,需要根据实际的需求来决定开启多少个Redis进程。若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程。若CPU资源比较紧张,采用单进程即可。
2.3Redis优点
(1)具有极高的数据读写速度:数据读取的速度最高可达到 110000 次/s,数据写入速度最高可达到 81000 次/s。
(2)支持丰富的数据类型:支持 key-value(键值)、Strings(字符串)、Lists(列表)、Hashes(哈希散列值)、Sets(有序) 及 Sorted Sets(无序排序) 等数据类型操作。
(3)支持数据的持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
(4)原子性:Redis 所有操作都是原子性的。
(5)支持数据备份:即 master-salve 模式的数据备份。
2.4 Redis为什么这么快?
1、Redis是一款纯内存结构,避免了磁盘I/o等耗时操作。
2、Redis命令处理的核心模块为单线程,减少了锁竞争,以及频繁创建线程和销毁线程的代价,减少了线程上下文切换的消耗。
3、采用了 I/O 多路复用机制,大大提升了并发效率。
注:在 Redis 6.0 中新增加的多线程也只是针对处理网络请求过程采用了多线性,而**数据的读写命令,仍然是单线程处理的。
三、Redis安装部署
3.1安装redis
systemctl stop firewalld
setenforce 0yum install -y gcc gcc-c++ maketar zxvf redis-5.0.7.tar.gz -C /opt/cd /opt/redis-5.0.7/
make
make PREFIX=/usr/local/redis install
#由于Redis源码包中直接提供了 Makefile 文件,所以在解压完软件包后,不用先执行 ./configure 进行配置,可直接执行 make 与 make install 命令进行安装。#执行软件包提供的 install_server.sh 脚本文件设置 Redis 服务所需要的相关配置文件
cd /opt/redis-5.0.7/utils
./install_server.sh
...... #一直回车Please select the redis executable path [/usr/local/bin/redis-server] /usr/local/redis/bin/redis-server #需要手动修改为 /usr/local/redis/bin/redis-server ,注意要一次性正确输入Selected config:
Port : 6379 #默认侦听端口为6379
Config file : /etc/redis/6379.conf #配置文件路径
Log file : /var/log/redis_6379.log #日志文件路径
Data dir : /var/lib/redis/6379 #数据文件路径
Executable : /usr/local/redis/bin/redis-server #可执行文件路径Cli Executable : /usr/local/bin/redis-cli #客户端命令工具#把redis的可执行程序文件放入路径环境变量的目录中便于系统识别
ln -s /usr/local/redis/bin/* /usr/local/bin/#当 install_server.sh 脚本运行完毕,Redis 服务就已经启动,默认监听端口为 6379
netstat -natp | grep redis#Redis 服务控制
/etc/init.d/redis_6379 stop #停止
/etc/init.d/redis_6379 start #启动
/etc/init.d/redis_6379 restart #重启
/etc/init.d/redis_6379 status #状态#修改配置 /etc/redis/6379.conf 参数
vim /etc/redis/6379.conf
bind 127.0.0.1 192.168.10.23 #70行,添加 监听的主机地址
port 6379 #93行,Redis默认的监听端口
daemonize yes #137行,启用守护进程
pidfile /var/run/redis_6379.pid #159行,指定 PID 文件
loglevel notice #167行,日志级别
logfile /var/log/redis_6379.log #172行,指定日志文件/etc/init.d/redis_6379 restart
3.2测试redis
redis-cli -h 【ip】 -p 【端口号】
3.3redis-benchmark 测试工具
redis-benchmark 是官方自带的 Redis 性能测试工具,可以有效的测试 Redis 服务的性能。
基本的测试语法:redis-benchmark [选项] [选项值]。
-h :指定服务器主机名。
-p :指定服务器端口。
-s :指定服务器 socket
-c :指定并发连接数。
-n :指定请求数。
-d :以字节的形式指定 SET/GET 值的数据大小。
-k :1=keep alive 0=reconnect 。
-r :SET/GET/INCR 使用随机 key, SADD 使用随机值。
-P :通过管道传输<numreq>请求。
-q :强制退出 redis。仅显示 query/sec 值。
--csv :以 CSV 格式输出。
-l :生成循环,永久执行测试。
-t :仅运行以逗号分隔的测试命令列表。
-I :Idle 模式。仅打开 N 个 idle 连接并等待。#向 IP 地址为 192.168.10.23、端口为 6379 的 Redis 服务器发送 100 个并发连接与 100000 个请求测试性能
redis-benchmark -h 192.168.10.23 -p 6379 -c 100 -n 100000#测试存取大小为 100 字节的数据包的性能
redis-benchmark -h 192.168.10.161 -p 6379 -q -d 100#测试本机上 Redis 服务在进行 set 与 lpush 操作时的性能
redis-benchmark -t set,lpush -n 100000 -q3.4Redis 数据库常用命令
set:存放数据,命令格式为 set key value
get:获取数据,命令格式为 get key
127.0.0.1:6379> set teacher zhangsan
OK
127.0.0.1:6379> get teacher
"zhangsan"# keys 命令可以取符合规、?等选项来使用。
127.0.0.1:6379> set k1 1则的键值列表,通常情况可以结合*
127.0.0.1:6379> set k2 2
127.0.0.1:6379> set k3 3
127.0.0.1:6379> set v1 4
127.0.0.1:6379> set v5 5
127.0.0.1:6379> set v22 5127.0.0.1:6379> KEYS * #查看当前数据库中所有键127.0.0.1:6379> KEYS v* #查看当前数据库中以 v 开头的数据127.0.0.1:6379> KEYS v? #查看当前数据库中以 v 开头后面包含任意一位的数据127.0.0.1:6379> KEYS v?? #查看当前数据库中以 v 开头 v 开头后面包含任意两位的数据
# exists 命令可以判断键值是否存在。
127.0.0.1:6379> exists teacher #判断 teacher 键是否存在
(integer) 1 # 1 表示 teacher 键是存在
127.0.0.1:6379> exists tea
(integer) 0 # 0 表示 tea 键不存在# del 命令可以删除当前数据库的指定 key。
127.0.0.1:6379> keys *
127.0.0.1:6379> del v5
127.0.0.1:6379> get v5# type 命令可以获取 key 对应的 value 值类型。
127.0.0.1:6379> type k1
string# rename 命令是对已有 key 进行重命名。(覆盖)
命令格式:rename 源key 目标key
使用rename命令进行重命名时,无论目标key是否存在都进行重命名,且源key的值会覆盖目标key的值。在实际使用过程中,建议先用 exists 命令查看目标 key 是否存在,然后再决定是否执行 rename 命令,以避免覆盖重要数据。127.0.0.1:6379> keys v*
1) "v1"
2) "v22"
127.0.0.1:6379> rename v22 v2
OK
127.0.0.1:6379> keys v*
1) "v1"
2) "v2"
127.0.0.1:6379> get v1
"4"
127.0.0.1:6379> get v2
"5"
127.0.0.1:6379> rename v1 v2
OK
127.0.0.1:6379> get v1
(nil)
127.0.0.1:6379> get v2
"4"# renamenx 命令的作用是对已有 key 进行重命名,并检测新名是否存在,如果目标 key 存在则不进行重命名。(不覆盖)
命令格式:renamenx 源key 目标key
127.0.0.1:6379> keys *
127.0.0.1:6379> get teacher
"zhangsan"
127.0.0.1:6379> get v2
"4"
127.0.0.1:6379> renamenx v2 teacher
(integer) 0
127.0.0.1:6379> keys *
127.0.0.1:6379> get teacher
"zhangsan"
127.0.0.1:6379> get v2
"4"# dbsize 命令的作用是查看当前数据库中 key 的数目。
127.0.0.1:6379> dbsize#使用config set requirepass yourpassword命令设置密码
127.0.0.1:6379> config set requirepass 123456#使用config get requirepass命令查看密码(一旦设置密码,必须先验证通过密码,否则所有操作不可用)
127.0.0.1:6379> auth 123456
127.0.0.1:6379> config get requirepass---- Redis 多数据库常用命令 ----
Redis 支持多数据库,Redis 默认情况下包含 16 个数据库,数据库名称是用数字 0-15 来依次命名的。
多数据库相互独立,互不干扰。#多数据库间切换
命令格式:select 序号
使用 redis-cli 连接 Redis 数据库后,默认使用的是序号为 0 的数据库。127.0.0.1:6379> select 10 #切换至序号为 10 的数据库127.0.0.1:6379[10]> select 15 #切换至序号为 15 的数据库127.0.0.1:6379[15]> select 0 #切换至序号为 0 的数据库#多数据库间移动数据
格式:move 键值 序号127.0.0.1:6379> set k1 100
OK
127.0.0.1:6379> get k1
"100"
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> get k1
(nil)
127.0.0.1:6379[1]> select 0 #切换至目标数据库 0
OK
127.0.0.1:6379> get k1 #查看目标数据是否存在
"100"
127.0.0.1:6379> move k1 1 #将数据库 0 中 k1 移动到数据库 1 中
(integer) 1
127.0.0.1:6379> select 1 #切换至目标数据库 1
OK
127.0.0.1:6379[1]> get k1 #查看被移动数据
"100"
127.0.0.1:6379[1]> select 0
OK
127.0.0.1:6379> get k1 #在数据库 0 中无法查看到 k1 的值
(nil)#清除数据库内数据
FLUSHDB :清空当前数据库数据
FLUSHALL :清空所有数据库的数据,慎用!四、Redis高可用
在web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常服务(99.9%、99.99%、99.999%等等)。
但是在Redis语境中,高可用的含义似乎要宽泛一些,除了保证提供正常服务(如主从分离、快速容灾技术),还需要考虑数据容量的扩展、数据安全不会丢失等。
在Redis中,实现高可用的技术主要包括持久化、主从复制、哨兵和 Cluster集群,下面分别说明它们的作用,以及解决了什么样的问题。
●持久化:持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
●主从复制:主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
●哨兵:在主从复制的基础上,哨兵实现了自动化的故障恢复。缺陷:写操作无法负载均衡;存储能力受到单机的限制。
●Cluster集群:通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
五、Redis 持久化
持久化的功能:Redis是内存数据库,数据都是存储在内存中,为了避免服务器断电等原因导致Redis进程异常退出后数据的永久丢失,需要定期将Redis中的数据以某种形式(数据或命令)从内存保存到硬盘;当下次Redis重启时,利用持久化文件实现数据恢复。除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置。
Redis 提供两种方式进行持久化:
●RDB 持久化:原理是将 Reids在内存中的数据库记录定时保存到磁盘上。
●AOF 持久化(append only file):原理是将 Reids 的操作日志以追加的方式写入文件,类似于MySQL的binlog。
5.1RDB 持久化
RDB持久化是指在指定的时间间隔内将内存中当前进程中的数据生成快照保存到硬盘(因此也称作快照持久化),用二进制压缩存储,保存的文件后缀是rdb;当Redis重新启动时,可以读取快照文件恢复数据。
(1)手动触发
save命令和bgsave命令都可以生成RDB文件。
save命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在Redis服务器阻塞期间,服务器不能处理任何命令请求。
而bgsave命令会创建一个子进程,由子进程来负责创建RDB文件,父进程(即Redis主进程)则继续处理请求。bgsave命令执行过程中,只有fork子进程时会阻塞服务器,而对于save命令,整个过程都会阻塞服务器,因此save已基本被废弃,线上环境要杜绝save的使用。
(2)自动触发
在自动触发RDB持久化时,Redis也会选择bgsave而不是save来进行持久化。
save m n
自动触发最常见的情况是在配置文件中通过save m n,指定当m秒内发生n次变化时,会触发bgsave。
vim /etc/redis/6379.conf
--219行--以下三个save条件满足任意一个时,都会引起bgsave的调用
save 900 1 :当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsave
save 300 10 :当时间到300秒时,如果redis数据发生了至少10次变化,则执行bgsave
save 60 10000 :当时间到60秒时,如果redis数据发生了至少10000次变化,则执行bgsave
--254行--指定RDB文件名
dbfilename dump.rdb
--264行--指定RDB文件和AOF文件所在目录
dir /var/lib/redis/6379
--242行--是否开启RDB文件压缩
rdbcompression yes
(3) 执行流程
(1)Redis父进程首先判断:当前是否在执行save,或bgsave/bgrewriteaof的子进程,如果在执行则bgsave命令直接返回。 bgsave/bgrewriteaof的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题。
(2)父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令
(3)父进程fork后,bgsave命令返回”Background saving started”信息并不再阻塞父进程,并可以响应其他命令
(4)子进程创建RDB文件,根据父进程内存快照生成临时快照文件,完成后对原有文件进行原子替换
(5)子进程发送信号给父进程表示完成,父进程更新统计信息
5.2AOF 持久化
DB持久化是将进程数据写入文件,而AOF持久化,则是将Redis执行的每次写、删除命令记录到单独的日志文件中,查询操作不会记录; 当Redis重启时再次执行AOF文件中的命令来恢复数据。
与RDB相比,AOF的实时性更好,因此已成为主流的持久化方案。
5.2.1. 开启AOF
Redis服务器默认开启RDB,关闭AOF;要开启AOF,需要在配置文件中配置:
vim /etc/redis/6379.conf
--700行--修改,开启AOF
appendonly yes
--704行--指定AOF文件名称
appendfilename "appendonly.aof"
--796行--是否忽略最后一条可能存在问题的指令
aof-load-truncated yes/etc/init.d/redis_6379 restart5.3 RDB和AOF的优缺点
5.3.1RDB持久化
优点:RDB文件紧凑,体积小,网络传输快,适合全量复制;恢复速度比AOF快很多。当然,与AOF相比,RDB最重要的优点之一是对性能的影响相对较小。
缺点:RDB文件的致命缺点在于其数据快照的持久化方式决定了必然做不到实时持久化,而在数据越来越重要的今天,数据的大量丢失很多时候是无法接受的,因此AOF持久化成为主流。此外,RDB文件需要满足特定格式,兼容性差(如老版本的Redis不兼容新版本的RDB文件)。
对于RDB持久化,一方面是bgsave在进行fork操作时Redis主进程会阻塞,另一方面,子进程向硬盘写数据也会带来IO压力。
5.3.2AOF持久化
与RDB持久化相对应,AOF的优点在于支持秒级持久化、兼容性好,缺点是文件大、恢复速度慢、对性能影响大。
对于AOF持久化,向硬盘写数据的频率大大提高(everysec策略下为秒级),IO压力更大,甚至可能造成AOF追加阻塞问题。
AOF文件的重写与RDB的bgsave类似,会有fork时的阻塞和子进程的IO压力问题。相对来说,由于AOF向硬盘中写数据的频率更高,因此对 Redis主进程性能的影响会更大。
六、Redis主从复制
systemctl stop firewalld
setenforce 0-----安装 Redis-----
yum install -y gcc gcc-c++ maketar zxvf redis-5.0.7.tar.gz -C /opt/wget -p /opt http://download.redis.io/releases/redis-5.0.9.tar.gz
cd /opt/redis-5.0.7/
make
make PREFIX=/usr/local/redis installcd /opt/redis-5.0.7/utils
./install_server.sh
......
Please select the redis executable path [/usr/local/bin/redis-server] /usr/local/redis/bin/redis-server ln -s /usr/local/redis/bin/* /usr/local/bin/-----修改 Redis 配置文件(Master节点操作)-----
vim /etc/redis/6379.conf redis.conf
bind 0.0.0.0 #70行,修改监听地址为0.0.0.0
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172行,指定日志文件目录
dir /var/lib/redis/6379 #264行,指定工作目录
appendonly yes #700行,开启AOF持久化功能/etc/init.d/redis_6379 restart-----修改 Redis 配置文件(Slave节点操作)-----
vim /etc/redis/6379.conf
bind 0.0.0.0 #70行,修改监听地址为0.0.0.0
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172行,指定日志文件目录
dir /var/lib/redis/6379 #264行,指定工作目录 #288行,指定要同步的Master节点IP和端口
replicaof 192.168.10.22 6379
appendonly yes #700行,开启AOF持久化功能/etc/init.d/redis_6379 restart-----验证主从效果-----
在Master节点上看日志:
tail -f /var/log/redis_6379.log 在Master节点上验证从节点:
redis-cli info replication相关文章:

NoSQL--------- Redis配置与优化
目录 一、关系型数据库与非关系型数据库 1.1关系型数据库 1.2非关系型数据库Nosql 1.3关系与非关系区别 1.4非关系产生的背景 1.5总结 二、Redis介绍 2.1Redis简介 2.3Redis优点 2.4 Redis为什么这么快? 三、Redis安装部署 3.1安装redis 3.2测试redis 3.3r…...

Ubuntu中关闭防火墙
在Ubuntu中关闭防火墙可以通过以下步骤进行: 查看防火墙状态: sudo ufw status如果防火墙状态为active(活动状态),则执行以下命令来停用防火墙: sudo ufw disable输入以下命令确认是否停用防火墙&#x…...

java-马踏棋盘
在8x8的国际棋盘上,按照马走日的规则,验证是否能够走遍棋盘。 1、创建棋盘 chessBoard,是一个二维数组。 2、将当前位置设置为已经访问,然后根据当前位置,计算马儿还能走哪些位置,并放入到一个集合中&…...
系统架构设计师-软件架构设计(4)
目录 一、软件架构评估 1、敏感点 2、权衡点 3、风险点 4、非风险点 5、架构评估方法 5.1 基于调查问卷或检查表的方式 5.2 基于度量的方式 5.3 基于场景的方式 6、基于场景的评估方法 6.1 软件架构分析法(SAAM) 6.2 架构权衡分析法(ATAM&am…...
51单片机--AD/DA
AD/DA介绍 AD和DA是模拟信号和数字信号之间的转换过程。 AD,全称为模拟到数字(Analog-to-Digital),指的是将模拟信号转换为数字信号的过程。在AD转换中,模拟信号经过采样、量化和编码等步骤,被转换为离散的…...
网络安全-防御需知
目录 网络安全-防御 1.网络安全常识及术语 资产 漏洞 0day 1day 后门 exploit APT 2.什么会出现网络安全问题? 网络环境的开放性 协议栈自身的脆弱性 操作系统自身的漏洞 人为原因 客观原因 硬件原因 缓冲区溢出攻击 缓冲区溢出攻击原理 其他攻击…...
C#百万数据处理
C#百万数据处理 在我们经验的不断增长中不可避免的会遇到一些数据量很大操作也复杂的业务 这种情况我们如何取优化如何去处理呢?一般都要根据业务逻辑和背景去进行合理的改进。 文章目录 C#百万数据处理前言一、项目业务需求和开发背景项目开发背景数据量计算业务需…...

windows端口占用
1.查看当前端口被哪个进程占用了(进入到CMD中) netstat -ano|findstr "8990"输出结果为: TCP 127.0.0.1:8990 0.0.0.0:0 LISTENING 2700 我们发现8990端口被2700进程占用了 2.基于进程号找进程名称 tasklist|findstr "2700&qu…...

如何理解Diffusion
Diffusion算法可以有多个角度进行理解,不同的理解方式只是对目标函数进行了不同的解释。其主体思想是不变的,可以归纳为: 训练时通过图片逐步添加噪声,变为一个纯噪声。然后学习每一步的噪声。推理时给定一个随机噪声图片&#x…...
-[聊天模型(Chat Models):使用少量示例和响应流式传输])
自然语言处理从入门到应用——LangChain:模型(Models)-[聊天模型(Chat Models):使用少量示例和响应流式传输]
分类目录:《自然语言处理从入门到应用》总目录 使用少量示例 本部分的内容介绍了如何在聊天模型(Chat Models)中使用少量示例。关于如何最好地进行少量示例提示尚未形成明确的共识。因此,我们尚未固定任何关于此的抽象概念&#…...

Java在线OJ项目(三)、前后端交互API模块
Java在线OJ项目(三)、前后端交互API模块 1. 客户端向服务器请求所有题目 或者 单个题目前端获取所有题目获取一个题目 后端 2. 后端读取前端提交的代码,进行编译运行,返回结果前端提交代码后端处理 1. 客户端向服务器请求所有题目…...

项目——负载均衡在线OJ
目录 项目介绍开发环境所用技术项目宏观结构编写思路1. 编写compile_server1.1 编译模块编写1.2 运行功能1.3compile_runner 编译与运行1.4 编写compile_server.cpp调用compile_run模块,形成网络服务 2. 编写基于MVC的oj_server2.1 oj_server.cpp的编写2.2 oj_model…...

idea连接远程服务器上传war包文件
idea连接远程服务器&上传war包 文章目录 idea连接远程服务器&上传war包1. 连接服务器2.上传war包 1. 连接服务器 选择Tools -> Start SSH Session 添加配置 连接成功 2.上传war包 Tools -> Deployment -> Browse Remote Host 点击右侧标签,点击&…...
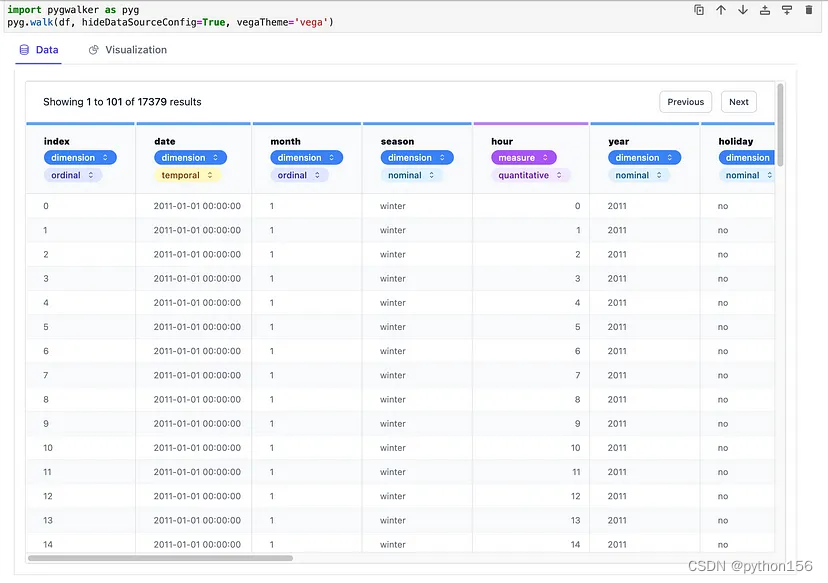
使用PyGWalker可视化分析表格型数据
大家好,可以想象一下在Jupyter Notebook中拥有大量数据,想要对其进行分析和可视化。PyGWalker就像一个神奇的工具,能让这项工作变得超级简单。它能获取用户的数据,并将其转化为一种特殊的表格,可以与之交互,…...

Visual C++中的虚函数和纯虚函数(以外观设计模式为例)
我是荔园微风,作为一名在IT界整整25年的老兵,今天来说说Visual C中的虚函数和纯虚函数。该系列帖子全部使用我本人自创的对比学习法。也就是当C学不下去的时候,就用JAVA实现同样的代码,然后再用对比的方法把C学会。 直接说虚函数…...

电子元器件选型与实战应用—01 电阻选型
大家好, 我是记得诚。 这是《电子元器件选型与实战应用》专栏的第一篇文章,今天的主角是电阻,在每一个电子产品中,都少不了电阻的身影,其重要性不言而喻。 文章目录 1. 入门知识1.1 基础1.2 常用品牌1.3 电阻的种类2. 贴片电阻标识2.1 三位数标注法2.2 四位数标注法2.3 小…...
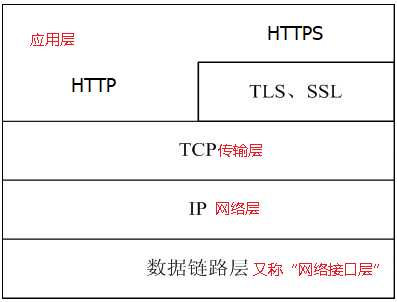
javascript 模板引擎
使用场景 在实际开发中,一般都是使用动态请求数据来更新页面,服务器端通常返回json格式的数据,正常操作是我们手动的去拼装HTML,但麻烦且容易出错,因此出现了一些用模版生成HTML的的框架叫js模板引擎如:jq…...
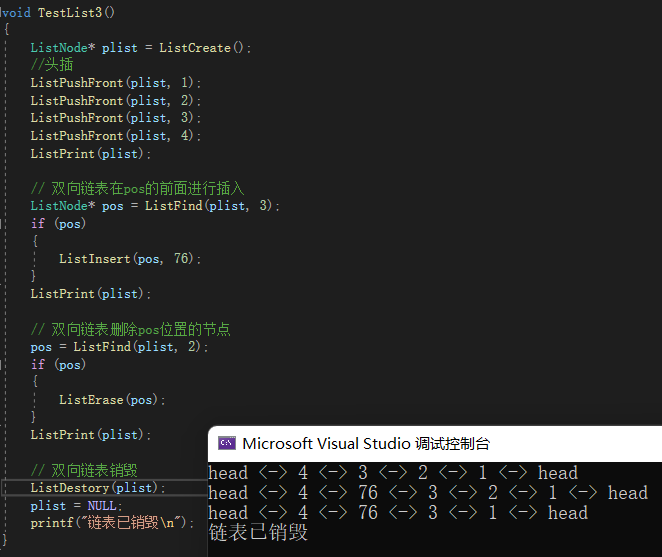
【数据结构】带头+双向+循环链表(DList)(增、删、查、改)详解
一、带头双向循环链表的定义和结构 1、定义 带头双向循环链表,有一个数据域和两个指针域。一个是前驱指针,指向其前一个节点;一个是后继指针,指向其后一个节点。 // 定义双向链表的节点 typedef struct ListNode {LTDataType dat…...
接口自动化测试平台
下载了大神的EasyTest项目demo修改了下<https://testerhome.com/topics/12648 原地址>。也有看另一位大神的HttpRunnerManager<https://github.com/HttpRunner/HttpRunnerManager 原地址>,由于水平有限,感觉有点复杂~~~ 【整整200集】超超超…...

【物联网】微信小程序接入阿里云物联网平台
微信小程序接入阿里云物联网平台 一 阿里云平台端 1.登录阿里云 阿里云物联网平台 点击进入公共实例,之前没有的点进去申请 2.点击产品,创建产品 3.产品名称自定义,按项目选择类型,节点类型选择之恋设备,联网方式W…...

达梦数据库-收缩数据库表空间步骤及示例记录总结
1达梦数据库-收缩数据库表空间步骤及示例记录总结 注:收缩表空间,如果空闲空间都在尾部,可以直接收缩成功,如果尾部不空闲,中部空闲,则需要移走使用尾部的表后再收缩,生产环境,如果…...

AI编程助手的真实效能:20-30%增效背后的工程逻辑与落地框架
1. 这不是泼冷水,而是把被营销话术遮住的显微镜递给你 “AI coding agent will boost your productivity 10x”——这句话过去两年在技术社区、招聘JD、内部OKR甚至投资人尽调材料里反复刷屏,像一句不容置疑的技术咒语。我本人从2023年Q4开始,…...

SSDD数据集技术深度解析:从数据构建到模型优化的SAR舰船检测实战指南
SSDD数据集技术深度解析:从数据构建到模型优化的SAR舰船检测实战指南 【免费下载链接】Official-SSDD SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis 项目地址: https://gitcode.com/gh_mirrors/of/Official-SSDD S…...

前端实战:CSS 实现经典对联式悬浮广告
一、效果介绍对联广告是网页中非常经典的广告布局,特点:左右两侧各一个广告栏,像对联一样悬挂页面上下滚动,广告固定不动、悬浮跟随屏幕中间是网站主体内容,互不遮挡、互不影响核心技术:CSS fixed 固定定位…...

在不同网络环境下测试Taotoken API端点的连接稳定性与路由表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在不同网络环境下测试Taotoken API端点的连接稳定性与路由表现 对于依赖大模型API进行开发的团队而言,服务的连接稳定性…...

Claude投资回报率究竟怎么算?揭秘企业级ROI模型的7个隐藏变量与实时测算模板
更多请点击: https://kaifayun.com 第一章:Claude投资回报率的核心定义与行业基准 Claude投资回报率(ROI)并非传统软件许可模型下的简单成本收益比,而是衡量企业将Claude系列大模型深度集成至核心业务流程后ÿ…...

ComfyUI-Impact-Pack V8:AI图像细节增强的终极指南
ComfyUI-Impact-Pack V8:AI图像细节增强的终极指南 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: https://git…...

零基础转行工业AI视觉全攻略|从入门学习、项目积累、求职就业到副业接单完整路径
摘要:当下传统自动化、机械、普通编程岗位普遍存在内卷严重、薪资天花板低、成长空间有限等问题。而工业AI视觉作为智能制造核心刚需赛道,具备岗位缺口大、薪资溢价高、技术生命周期长、可主业就业副业接单的核心优势,成为应届生、职场转行、…...

国产芯片独角兽IPO热潮来袭,百度昆仑芯与阿里平头哥角逐RISC-V弯道超车机遇
国产芯片好消息不断,长鑫科技与长江存储启动IPO,百度昆仑芯、阿里平头哥也有相关动作。互联网大厂钟情自研AI芯片,昆仑芯与平头哥发展路径不同,RISC-V或是弯道超车关键。国产芯片独角兽登场被誉为“存储双雄”的长鑫科技与长江存储…...

基于EM9283与FPGA的工业便携式WiFi数据终端设计实战
1. 项目概述:一个工业现场的便携式WiFi数据终端在工业现场,数据采集与无线传输的需求无处不在,但环境往往复杂多变:布线困难、设备需要移动、供电不便。传统的方案要么是拖着长长的线缆,要么是依赖工控机加外置模块&am…...