redis 淘汰策略和持久化
文章目录
- 一、淘汰策略
- 1.1 背景
- 1.2 淘汰策略
- 二、持久化
- 2.1 AOF日志
- 2.1.1 AOF配置
- 2.1.2 AOF策略
- 2.1.3 AOF缺点
- 2.1.4 AOF Rewrite
- 2.1.5 AOF Rewrite配置
- 2.1.6 AOF Rewrite缺点
- 2.1.7 fork进程时的写时复制
- 2.1.8 大key对持久化的影响
- 2.2 RDB快照
- 2.2.1 RDB配置
- 2.2.2 RDB缺点
- 2.3 混合持久化
- 2.4 优缺点总结
- 2.5 持久化的数据安全
一、淘汰策略
1.1 背景
Redis 之所以有淘汰策略,是因为 Redis 是基于内存的高性能键值存储系统,它将数据全部加载到内存中进行读写操作。但是,内存资源是有限的,当 Redis 使用的内存接近或超过系统可用内存时,就需要通过一些策略来释放内存空间。
1)键过期:通过expire / pexpire 设置key的生存时间。当key的生存周期达到时,将对应的key-value删除。
# 设置 key 的过期时间
expire key seconds
pexpire key milliseconds
# 查看 key 的过期时间
ttl key
pttl key
2)键的空闲时间(空转时长):redis每次操作value时,会记录操作的时间戳和统计对key-value的操作次数。value 的类型有多种,底层由 redisObject 实现,这种通用的数据结构可以存储不同类型的 value。
typedef struct redisObject {unsigned type:4; // 对象类型:string, hash, list, setunsigned encoding:4; // 编码方式unsigned lru:LRU_BITS; // lru:24位,最近一次访问时间,单位秒,// lfu: 高16位,最近一次访问时间;低8位,逻辑访问次数int refcount; // 引用计数,计数为 0,对象无人引用,可以回收void *ptr; // 数据指针,指向对象内容
} robj;
lru字段用于记录操作value的时间,也会统计对key-value操作了多少次。可以使用object idletime key获取指定键的空闲时间。空闲时间指的是自上次对该键进行读取或写入操作以来所经过的时间。
# 对象空转时长
object idletime key
3)配置
redis.conf有两个参数配置淘汰策略,maxmemory和maxmemory-policy。
maxmemory限定redis可以使用的最大内存(单位是字节 ),一般设置为当前系统可用内存的一半;
maxmemory-policy用于制定淘汰策略。
# redis.conf
maxmemory <bytes>
maxmemory-policy noeviction
1.2 淘汰策略
1.2.1 针对过期key
- volatile-lru:从设置了过期时间的键中,选择最近最少使用(Least Recently Used)(最长时间没有使用)的键进行删除。这种模式下, lru整个字段都用于记录时间。
- volatile-lfu:从设置了过期时间的键中,选择最少使用次数的键进行删除。这种模式下 记录操作的时间和统计对key-value操作次数(8位统计次数,16位记录时间)。
- volatile-ttl:从设置了过期时间的键中,选择剩余时间最短(最近就要过期)的键进行删除。这种模式下,记录操作的时间和统计对key-value操作次数(8位统计次数,16位记录时间)。
- volatile-random:从设置了过期时间的键中,随机选择一个进行删除。ttl/pttl指令可以查询key还有多长时间到期。
1.2.2 针对所有key
allkeys-lru:从所有的键中,选择最近最少使用的键进行删除。无论键是否设置了过期时间。
allkeys-lfu,从所有的键中,选择最少使用次数的键进行删除。无论键是否设置了过期时间。
allkeys-random:从所有的键中,随机选择一个进行删除。无论键是否设置了过期时间。
1.2.3 禁止淘汰
noeviction:默认是禁止淘汰,如果数据达到了最大内存限制,在向redis中写入数据时会报错。
二、持久化
Redis 的数据全部在内存中,如果突然宕机,数据就会全部丢失。因此Redis 提供持久化机制,将内存中的数据以文件的形式存储到硬盘上, Redis 重启时加载持久化文件来恢复原来的数据。以此来保证Redis 的数据不会因为故障而丢失。
redis持久化的方式有:
- AOF(Append-Only File)日志:记录了 Redis 服务器收到的所有写操作命令,每执行一条写操作命令,就以文本格式追加到一个日志文件中,通过回放这些写命令可以还原数据。
- RDB(Redis Database)快照:以二进制形式将 Redis 数据库的快照(某一时刻的内存数据)保存在硬盘上,实现了数据的持久化存储。
- 混合持久化:AOF+ RDB
2.1 AOF日志
AOF(Append-Only File)是 Redis 数据库中的一种持久化方式,用于将写操作追加到文件中。
Redis 每执行一条写操作命令,将命令以追加的方式写入 aof日志文件。aof文件存储的是Redis 协议的命令文本格式,例如:记录命令 set key value
*3\r\n$3\r\nset\r\n$3\r\nkey\r\n$5\r\nvalue
Redis 重启时,通过重放(replay)AOF日志中指令序列来恢复 Redis 当前实例
的内存数据结构的状态;
2.1.1 AOF配置
通过修改 Redis 配置文件 redis.conf 进行设置,并在重启 Redis 服务后生效。
AOF(Append-Only File)持久化配置:
- appendonly:若配置为 yes,启用 AOF 持久化。
- appendfilename:设置 AOF 文件的名称。
- appendfsync:设置刷新 AOF 文件到磁盘的策略。可选择的值有 always(每次修改都刷新)、everysec(每秒刷新一次)和 no(由操作系统决定刷新时机)。
- no-appendfsync-on-rewrite:若配置为 yes,在执行 AOF 重写时禁止执行 AOF 文件刷新操作。
- auto-aof-rewrite-percentage 和 auto-aof-rewrite-min-size:配置 AOF 自动重写的触发条件,其中 auto-aof-rewrite-percentage 表示 AOF 文件大小相对于上次重写后的大小增长的百分比,而 auto-aof-rewrite-min-size 表示 AOF 文件最小大小。
# 开启 aof
appendonly yes
# 关闭 aof复写
auto-aof-rewrite-percentage 0
# 关闭 混合持久化
aof-use-rdb-preamble no
# 关闭 rdb
save ""
2.1.2 AOF策略
fsync 是一个与文件系统相关的系统调用,它用于将文件系统缓存区中的数据立即写入物理磁盘,主动刷盘。
Redis 写入 AOF 日志的过程:wirte 从用户缓冲写到内核缓冲,fysnc 从内核缓冲写到磁盘。
AOF 有三种策略:always、every_sec、no。这三种策略主要差异是fsync()的调用时机:
- appendfsync always:在每次写操作完成后,都会立即将写命令追加到 AOF 文件,并调用系统的fsync函数将数据同步到磁盘。这是最安全的方式,但也会带来较大的性能开销。
- appendfsync everysec:在每秒钟的间隔内,将写命令追加到 AOF 文件,然后调用系统的fsync函数将数据同步到磁盘。这种方式提供了较好的性能和较高的数据安全性之间的折中方案。在bio_aof_fsync线程中执行。
- appendfsync no:不自己调用fsync(),由系统决定什么时候调用fsync()将数据刷到磁盘文件中。
2.1.3 AOF缺点
AOF会把所有的写操作命令都追加到文件中,包括一些冗余过期的数据,比如
127.0.0.1:6379> set jack 100
OK
127.0.0.1:6379> set jack 200
OK
127.0.0.1:6379> set jack 300
OK
AOF会将三个命令都保存到文件中,恢复数据的时候也是执行了这三个命令。但实际只需要最后一次的命令即可。
因此,随着时间越长,AOF 日志会越来越长,如果 redis 重启,重放整个 AOF 日志会非常耗时,导致 redis 长时间无法对外提供服务。
2.1.4 AOF Rewrite
AOF Rewrite 是 Redis 中一种用于优化和压缩 Append-Only 文件(AOF)的机制。
在 Redis 的 AOF 持久化模式中,所有写操作都会以追加方式记录到 AOF 文件中。随着时间的推移,AOF 文件会不断增长,可能变得非常大,占用大量存储空间,并且读取和恢复时也会变得较慢。为了解决这个问题,Redis 提供了 AOF Rewrite 机制,用于重写并优化 AOF 文件。
AOF Rewrite 的过程如下:
-
启动 AOF Rewrite:当启动 AOF Rewrite 时,Redis 将fork一个子进程来执行 AOF Rewrite 操作,同时继续接受客户端的新命令。
-
创建新的 AOF 文件:子进程首先会创建一个新的空白 AOF 文件,用于存储重写后的命令序列。
-
遍历现有 AOF 文件:子进程会读取并解析现有的 AOF 文件,将其中的命令逐个读取并转化为对应的数据结构。
-
合并相同命令:在重写过程中,子进程会合并相同的命令,以减少生成的新命令数量。这样可以减小新 AOF 文件的大小并提高读取性能。
-
写入新的 AOF 文件:合并后的命令将按顺序写入新的 AOF 文件中。在写入期间,子进程会继续接收并处理来自客户端的新命令。
-
更新主进程状态:当子进程完成写入新 AOF 文件后,它将向主进程发送信号,主进程接收到信号后将完成 AOF Rewrite 的最后步骤。
-
切换到新的 AOF 文件:主进程将关闭当前的 AOF 文件,并将新的 AOF 文件设置为当前的 AOF 文件。这样,之后的写操作将会追加到新的 AOF 文件中。
-
完成 AOF Rewrite:一旦切换完成,AOF Rewrite 过程就完成了。新的 AOF 文件将包含原始 AOF 文件中的所有数据,但经过了优化和压缩。
需要注意的是,在 AOF Rewrite 过程中,Redis 仍然会继续处理客户端的命令请求,不会停止服务。重写期间,Redis增加一个AOF重写缓冲区,主进程将期间执行后的写操作命令记录到AOF重写缓冲区。当子进程完成AOF重写后,会将AOF重写期间的AOF增量(AOF重写缓冲区的数据)追加到新的 AOF 文件中。并将新的 AOF 文件设置为当前的 AOF 文件。

2.1.5 AOF Rewrite配置
修改 redis.conf 配置,开启 AOF 重写。
# 开启 aof
appendonly yes# 开启 aof复写
# 1. redis 会记录上次aof复写时的size,如果之后累计超过了
原来的size,则会发生aof复写;
auto-aof-rewrite-percentage 100
# 2. 为了避免策略1中,小数据量时产生多次发生aof复写,策略2
在满足策略1的前提下需要超过 64mb 才会发生aof复写;
auto-aof-rewrite-min-size 64mb# 关闭 混合持久化
aof-use-rdb-preamble no
# 关闭 rdb
save ""
2.1.6 AOF Rewrite缺点
AOF Rewrite 在 AOF 基础上实现了瘦身,但是 AOF 复写的数据量仍然很大;加载会非常慢。因为数据恢复还是通过重放(replay)方式,即重新执行命令的方式,需要消耗CPU,需要走命令处理流程。
2.1.7 fork进程时的写时复制
fork 是一个系统调用,在操作系统中创建一个子进程。其中的写时复制(Copy-on-Write,COW)是一种优化技术,用于减少 fork 操作时的内存消耗和复制数据的开销。
写时复制的过程如下:
-
父子进程共享相同的物理内存:在执行 fork 时,父进程的内存空间会被完整地复制给子进程。但是实际上,父子进程会共享相同的物理内存页,并且这些页被标记为“只读”。
-
写操作触发缺页中断:当父进程(或子进程)尝试对共享的内存页进行写操作时,操作系统会检测到这个写操作,因为这些页是只读的。从而触发缺页中断
-
复制需要修改的内存页:当发生写操作并产生缺页中断时,操作系统会为触发缺页错误的父进程分配一块新的物理内存页,并将原始只读页中需要修改的部分复制到新的内存页中。
-
更新页表:在完成内存页的复制后,操作系统会更新父进程和子进程的页表,将对应的虚拟内存页映射到新的物理内存页上。子进程的页表指向原来的物理内存,父进程的页表指向新的物理内存。
-
继续执行:一旦复制和更新操作完成,父子进程就可以继续各自独立地执行,并且它们在内存中的数据是彼此隔离的。
写时复制的好处是避免了昂贵的内存复制操作。在 fork 之后,父子进程只有在需要进行写操作时才会发生实际的内存复制,避免物理内存的复制时间过长导致父进程长时间阻塞。
当然,这也是AOF Rewrite的时候,为了避免主进程写时复制造成父子进程内存数据不一致,使得重写后 AOF 日志的数据与 Redis 中的数据不一致,Redis 增加了一个 AOF 重写缓冲区。

2.1.8 大key对持久化的影响
大 key:Key 对应的 Value 很大,占用大量的空间。
1)fsync()压力大。比如AOF的always,它是在主线程中做的持久化,如果value非常的大,会长时间占用主线程,这就是一个耗时的操作,会影响redis的响应性能;大key对AOF的every_sec的影响较小,因为它在另外的线程 (bio_aof_fsync线程)进行持久化的;AOF的no对redis的影响也较小,因为fsync()由系统决定,因此压力在系统上。
2)fork时间比较长。redis中有一个object_info,会记录fork的时间,如果主线程fork超过1s,那么它的效率是非常低的,阻塞主线程。同时,写时复制造成持久化时间过长。
2.2 RDB快照
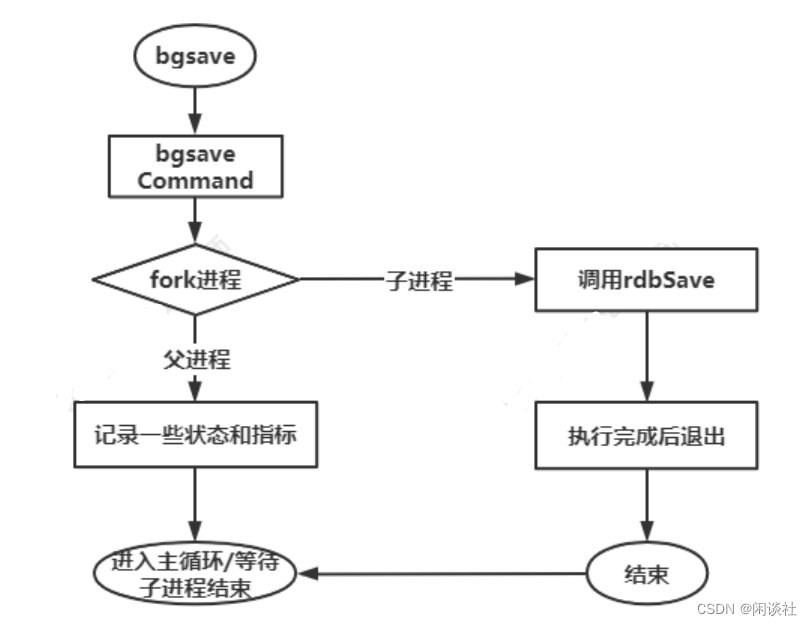
基于 AOF或 AOF Rewrite文件大的缺点,RDB是一种快照持久化;它通过 fork 进程,在子进程中将某一瞬间内存当中的数据键值对按照存储方式持久化到 RDB文件中;
RDB是基于内存中(所有数据)对象编码(ziplist、quiklist、intset、skiplist、int、embstr、raw等)直接持久化,存储的是经过压缩的二进制数据;由于是二进制数据,不管是落盘速度还是恢复数据速度都是最快的。
2.2.1 RDB配置
# 关闭 aof 同时也关闭了 aof复写
appendonly no
# 关闭 aof复写
auto-aof-rewrite-percentage 0
# 关闭 混合持久化
aof-use-rdb-preamble no
# 开启 rdb 也就是注释 save ""
# save ""# redis 默认策略如下:
# 注意:写了多个 save 策略,只需要满足一个则开启rdb持久化
# 3600 秒内有以1次修改
save 3600 1
# 300 秒内有100次修改
save 300 100
# 60 秒内有10000次修改
save 60 10000
Redis 提供 save 和 bgsave 命令来生成 RDB 文件
# 自动开启 RDB
# 如果在 seconds 秒内,对 redis 共执行至少 changes 次修改,则自动执行命令
# 主线程生成 RDB 文件,阻塞主线程
save <seconds> <changes>
# 子线程生成 RDB 文件,不阻塞主线程
bgsave <seconds> <changes>
2.2.2 RDB缺点
1)RDB的持久化方式是以某一时刻所有的内存数据为单位,而AOF持久化是以单条命令为单位。所以若采用 RDB持久化,一旦 redis 宕机,redis 将丢失一段时间的
内存数据,RDB方式丢失数据是最严重的。
2)RDB 需要经常 fork 子进程来保存数据集到硬盘上,当数据集比较大的时候,fork 的过程是非常耗时的,可能会导致 Redis 在一些毫秒级内不能响应客户端的请求。如果数据集巨大并且 CPU性能不是很好的情况下,这种情况会持续1秒,AOF Rewrite 也需要 fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度。
2.3 混合持久化
从上面知道,RDB文件小且加载快但丢失多,AOF文件大且加载慢但丢失少;混合持久化是吸取 RDB和 AOF两者优点的一种持久化方案;AOF Rewrite 的时候实际持久化的内容是 RDB,等持久化后,持久化期间修改的数据以AOF的形式附加到文件的尾部。
在混合持久化配置下,Redis 会同时进行 RDB 快照和 AOF 日志追加。这样,在遇到灾难性故障时,可以使用 RDB 文件进行快速恢复,而 AOF 文件可以提供更详细的日志记录并保证数据的更高持久性。
混合持久化的流程是:
1)当开启混合持久化时,在 AOF 重写日志时,fork 出来的子进程先根据与主线程共享的内存数据以 RDB 的方式写入新的 AOF 文件。主线程对 Redis 的写操作会记录到 AOF 重写缓冲区。
2)当 RDB 持久化结束后,重写缓冲区里的增量命令以 AOF 的形式追加到新的 AOF 文件。写入完成后,子线程通知主线程将新的的 AOF 文件替换旧的 AOF 文件。这样生成的 AOF 文件是: RDB 格式的全量数据 + AOF 格式的增量数据。
3)Redis 重启时,先加载 RDB 的内容,然后再重放增量 AOF 日志。

2.3.1 配置
混合持久化实际上是在 AOF Rewrite基础上进行优化;所以需要先开启 AOF Rewrite。
# 开启 aof
appendonly yes
# 开启 aof复写
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 开启 混合持久化
aof-use-rdb-preamble yes
# 关闭 rdb
save ""
2.3.2 缺点
启用混合持久化会带来额外的存储空间占用和性能开销,因为需要同时维护 RDB 文件和 AOF 文件。
2.4 优缺点总结
AOF
- 优点:数据可靠,丢失较少。持久化鬼哟踩代价较低(只记录写命令)。
- 缺点:AOF文件过大,数据恢复慢。
RDB:
- 优点:RDB文件小,数据恢复快。
- 缺点:数据一旦丢失,则丢失的数据量比较多。且持久化过程代价比较高(记录内存所以数据)。
混合持久化:
- 优点:充分利用 RDB 和 AOF 持久化各自的优点,以提供更好的数据安全性和快速恢复能力
- 缺点:带来额外的存储空间占用和性能开销,因为需要同时维护 RDB 文件和 AOF 文件。
2.5 持久化的数据安全
1)数据安全要考虑两个问题:
- 节点宕机(redis 是内存数据库,宕机数据会丢失)
- 磁盘故障
上述持久化方式只考虑到了节点宕机问题,但若磁盘故障,则无法恢复数据。因此,需要定期将持久化文件拷贝到其他地方。
2)拷贝持久化文件是安全的。
持久化文件一旦被创建, 就不会进行任何修改。 当服务器要创建一个新的持久化文件时, 它先将文件的内容保存在一个临时文件里面, 当临时文件写入完毕时, 程序才使用rename(2) 原子地用临时文件替换原来的持久化文件。
3)具体措施
- 创建一个定期任务 (cron job), 每小时将一个 RDB 文件备份到一个文件夹, 并且每天将一个 RDB 文件备份到另一个文件夹。
- 确保快照的备份都带有相应的日期和时间信息, 每次执行定期任务脚本时, 使用 find 命令来删除过期的快照。比如说, 你可以保留最近 48 小时内的每小时快照, 还可以保留最近一两个月的每日快照。
- 至少每天一次, 将 RDB 备份到数据中心之外,或者至少是备份到运行 redis 服务器的物理机器之外。
相关文章:
redis 淘汰策略和持久化
文章目录 一、淘汰策略1.1 背景1.2 淘汰策略 二、持久化2.1 AOF日志2.1.1 AOF配置2.1.2 AOF策略2.1.3 AOF缺点2.1.4 AOF Rewrite2.1.5 AOF Rewrite配置2.1.6 AOF Rewrite缺点2.1.7 fork进程时的写时复制2.1.8 大key对持久化的影响 2.2 RDB快照2.2.1 RDB配置2.2.2 RDB缺点 2.3 混…...
Redis学习路线(6)—— Redis的分布式锁
一、分布式锁的模型 (一)悲观锁: 认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行。例如Synchronized、Lock都属于悲观锁。 优点: 简单粗暴缺点: 性能略低 &#x…...
一、创建自己的docker python容器环境;支持新增python包并更新容器;离线打包、加载image
1、创建自己的docker python容器环境 参考:https://blog.csdn.net/weixin_42357472/article/details/118991485 首先写Dockfile,注意不要有txt等后缀 Dockfile # 使用 Python 3.9 镜像作为基础 FROM python:3.9# 设置工作目录 WORKDIR /app# 复制当前…...
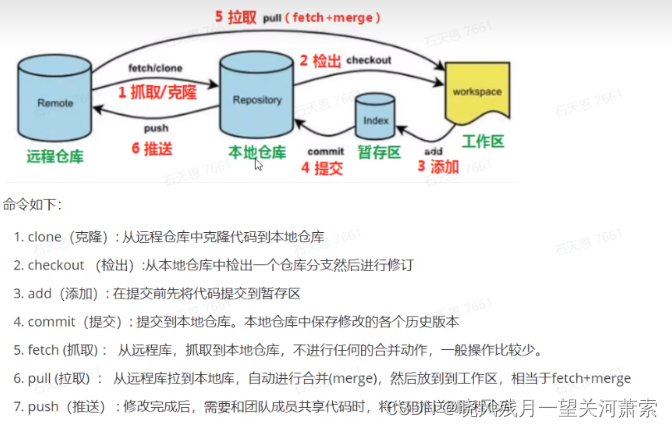
【Git】git企业开发命令整理,以及注意点
1.git企业开发过程 业务的分支大概有以下几个: master:代码随时可能上线 develop:代码最新 feature/xxx:实际业务开发分支 release/xxx:预发布分支 fix:修复bug分支 过程大概是这样的: 首…...

使用Django自带的后台管理系统进行数据库管理的实例
Django自带的后台管理系统主要用来对数据库进行操作和管理。它是Django框架的一个强大功能,可以让你快速创建一个管理界面,用于管理你的应用程序的数据模型。 使用Django后台管理系统,你可以轻松地进行以下操作: 数据库管理&…...
1254 - 1266 题)
leetcode解题思路分析(一百四十五)1254 - 1266 题
统计封闭岛屿的数目 二维矩阵 grid 由 0 (土地)和 1 (水)组成。岛是由最大的4个方向连通的 0 组成的群,封闭岛是一个 完全 由1包围(左、上、右、下)的岛。请返回 封闭岛屿 的数目。 BFS或者DFS…...

使用 GORM 连接数据库并实现增删改查操作
步骤 1:安装 GORM 首先,我们需要安装 GORM 包。在终端中运行以下命令: shell go get -u gorm.io/gorm 步骤 2:导入所需的包 在 Go 代码的开头导入以下包: import ("gorm.io/driver/mysql" // 如果你使用…...

kafka集群搭建(Linux环境)
zookeeper搭建,可以搭建集群,也可以单机(本地学习,没必要搭建zookeeper集群,单机完全够用了,主要学习的是kafka) 1. 首先官网下载zookeeper:Apache ZooKeeper 2. 下载好之后上传到…...
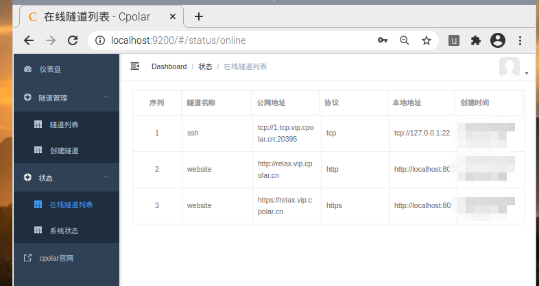
树莓派本地快速搭建web服务器,并发布公网访问
文章目录 树莓派本地快速搭建web服务器,并发布公网访问 树莓派本地快速搭建web服务器,并发布公网访问 随着科技的发展,电子工业也在不断进步,我们身边的电子设备也在朝着小型化和多功能化演进,以往体积庞大的电脑也在…...

集合中的数据结构
栈 先进后出入口跟出口在同一侧 队列 先进先出入口跟出口在不同的一层 数组 查询快、增删慢查询快是因为数组的地址是连续的,我们通过数组的首地址就可以找到数组,之后通过数组的下标就可以访问数组的每一个元素。增删慢是因为数组的长度是固定的&…...
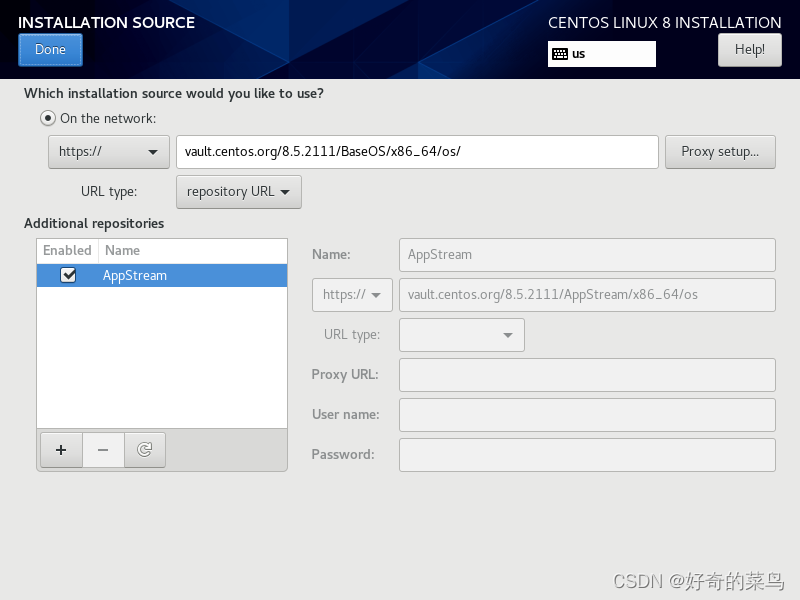
CentOS 8 错误: Error setting up base repository
配置ip、掩码、网关、DNS VMware网关可通过如下查看 打开网络连接 配置镜像的地址 vault.centos.org/8.5.2111/BaseOS/x86_64/os/...

java外观模式
在Java中,外观模式(Facade Design Pattern)用于为复杂的子系统提供一个简单的接口,以方便客户端的使用。外观模式是一种结构型设计模式,它隐藏了系统的复杂性,将多个类的复杂操作封装在一个外观类中&#x…...
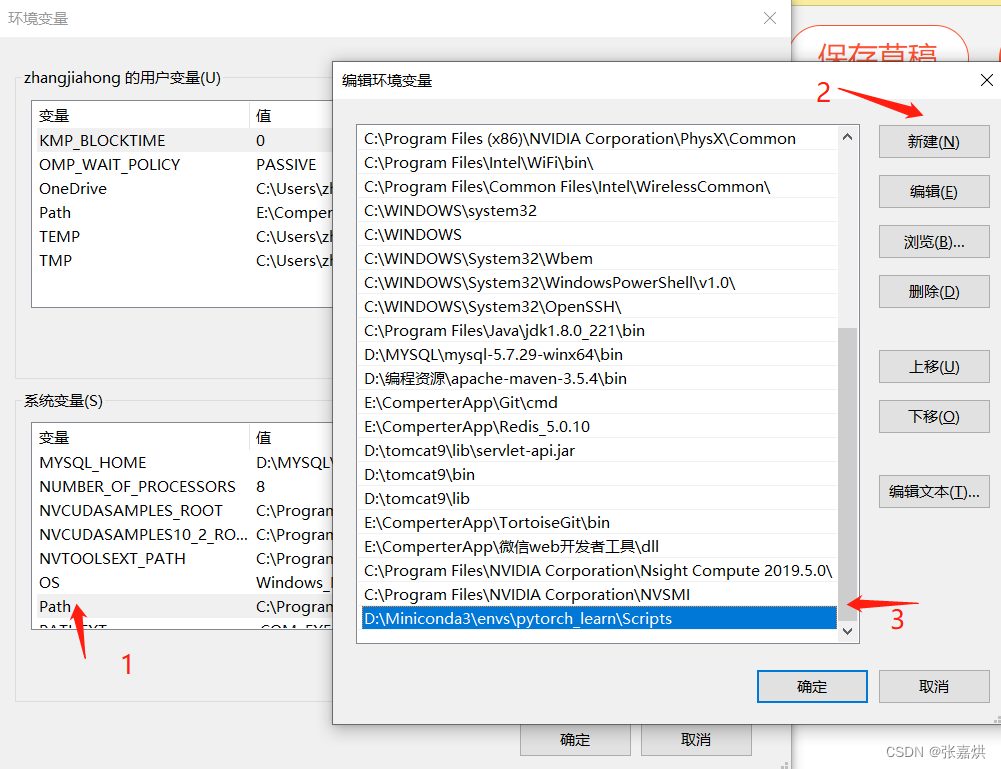
3秒快速打开 jupyter notebook
利用 bat 脚本,实现一键打开 minconda 特点: 1、可指定 python 环境 2、可指定 jupyter 目录 一、配置环境 minconda 可以搭建不同的 python 环境,所以我们需要找到 minconda 安装目录,把对应目录添加到电脑环境 PATH 中&#…...
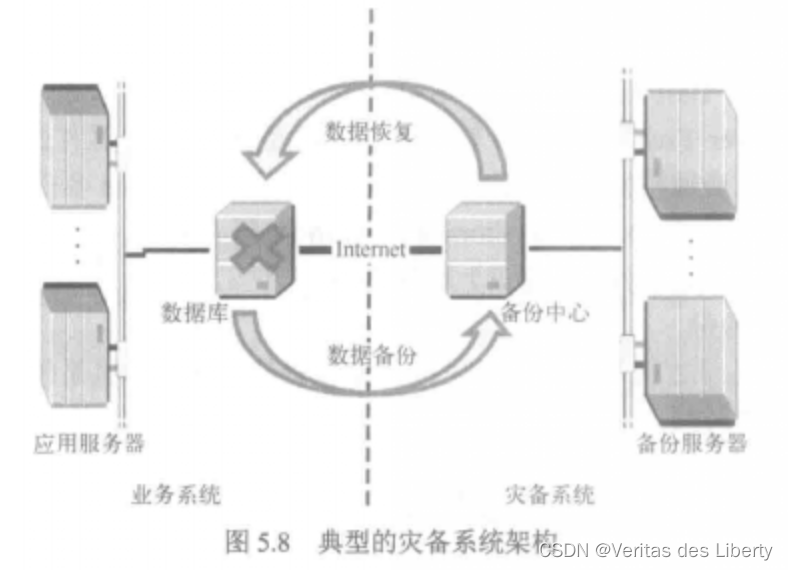
数据安全
数据的备份与恢复 1. 数据备份技术 任何数据在长期使用过程中,都存在一定的安全隐患。由于认为操作失误或系统故障,例如认为错误、程序出错、计算机失效、灾难和偷窃,经常造成数据丢失,给个人和企业造成灾难性的影响。在这种情况…...
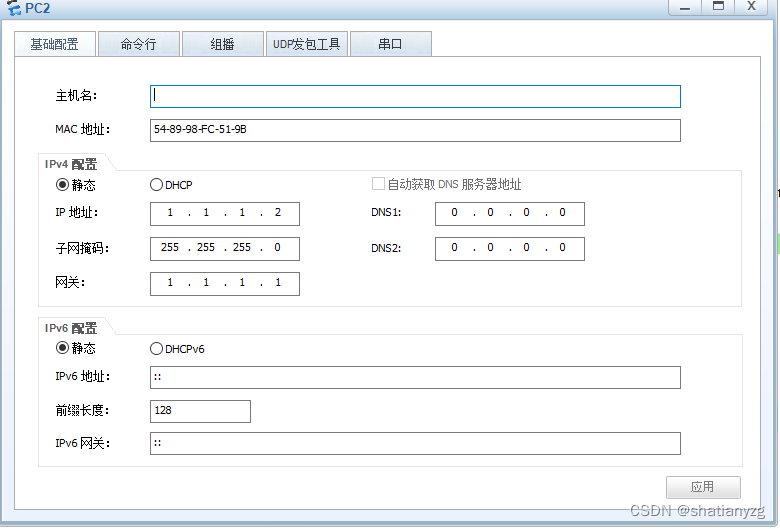
华为nat64配置
1.前期环境准备 环境拓扑 拓扑分为两个区域,左边为trust区域,使用IPv4地址互访,右边为untrust区域,使用IPv6地址互访 2.接口地址配置 pc1地址配置 pc2地址配置 FW接口配置 (1)首先进入防火墙配置界面 注:防火墙初始账号密码为user:admin,pwd:Admin@123,进入之后…...

从分片传输到并行传输之大文件传输加速技术
随着大文件的传输需求越来越多,传输过程中也会遇到很多困难,比如传输速度慢、文件安全性低等。为了克服这些困难,探讨各种大文件传输加速技术。其中,分片传输和并行传输是两种比较常见的技术,下面将对它们进行详细说明…...
mybatisPlus入门篇
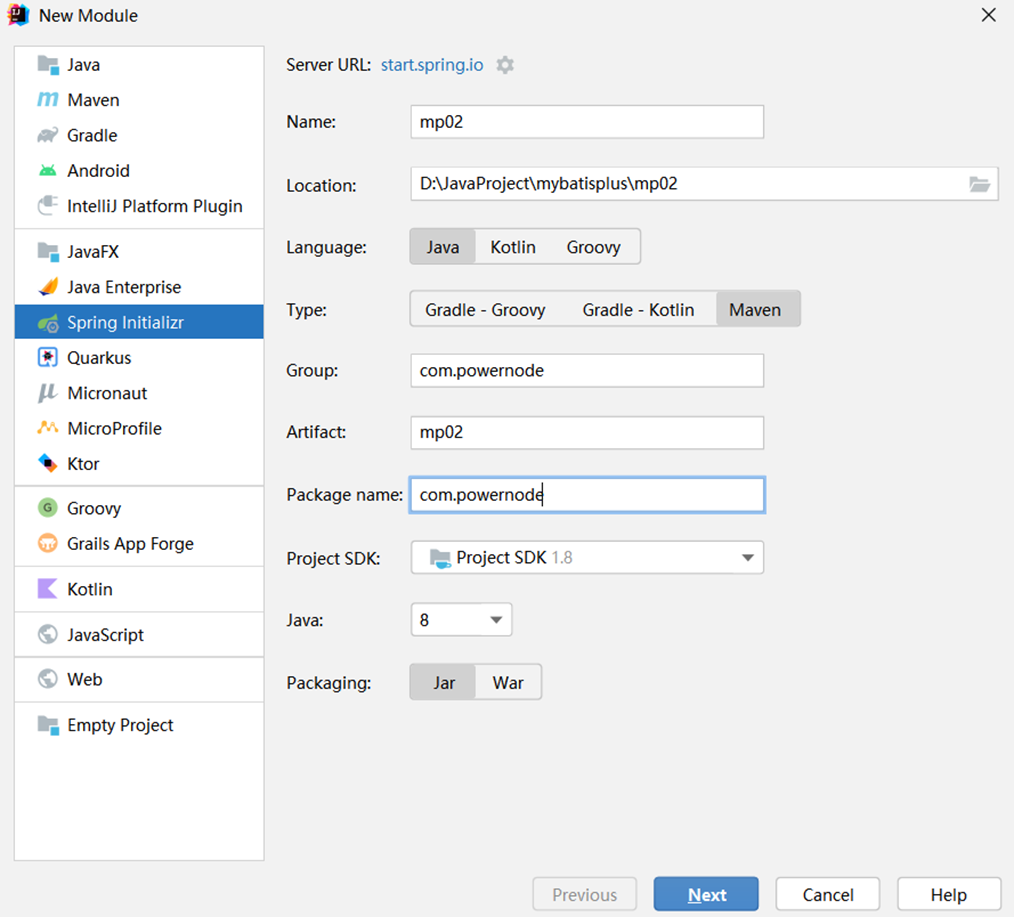
文章目录 初窥门径1.1 初识MybatisPlus1.2 MybatisPlus的特性1.3 MybatisPlus的架构模型 入门案例2.1 准备相关开发环境2.2 搭建springboot工程2.3 创建数据库2.4 引入相关依赖2.5 创建实体类2.6 集成MybatisPlus2.7 单元测试2.8 springboot日志优化 初窥门径 1.1 初识Mybatis…...
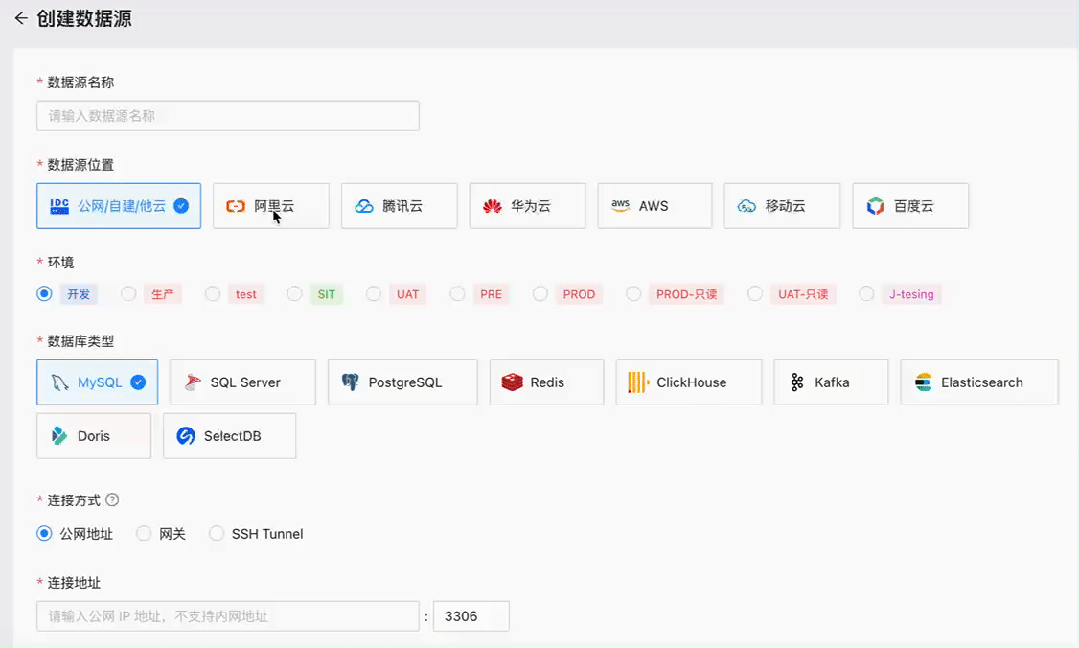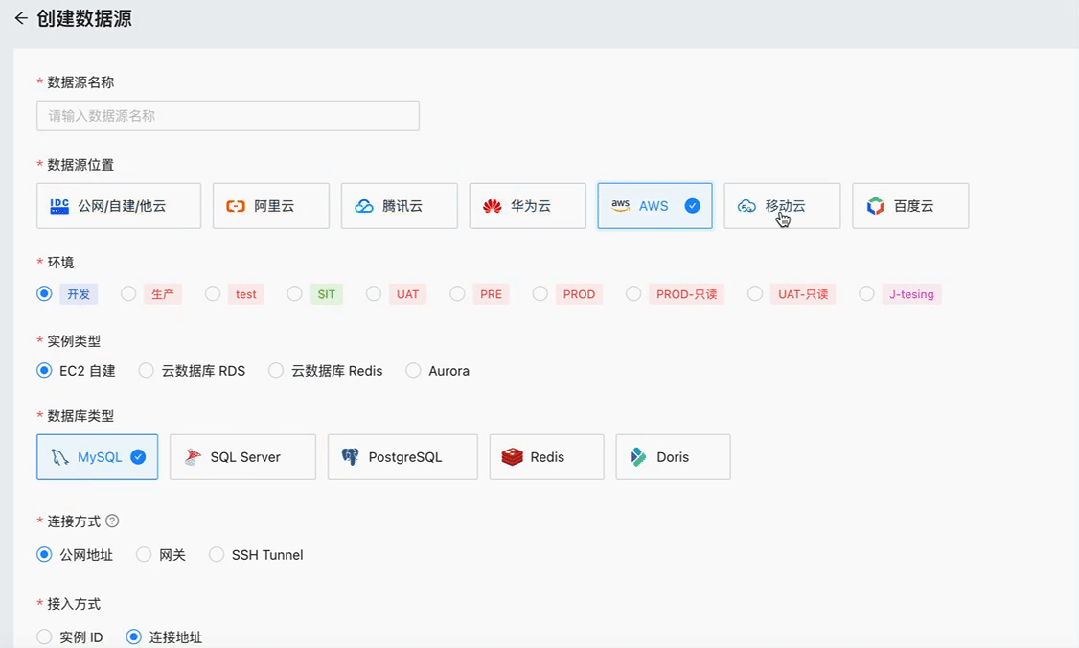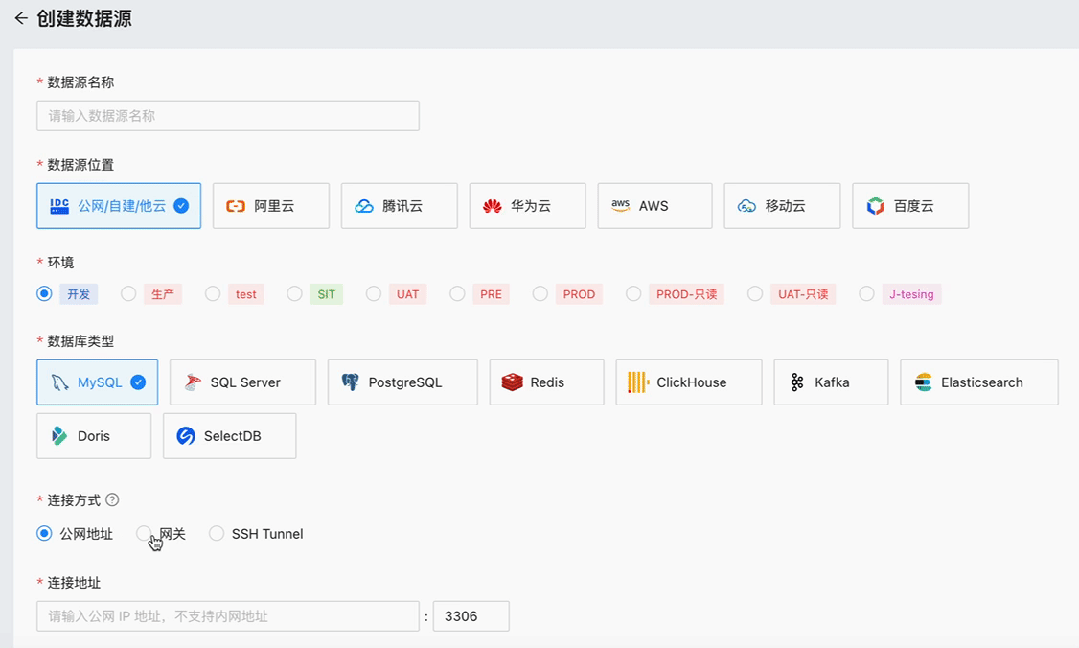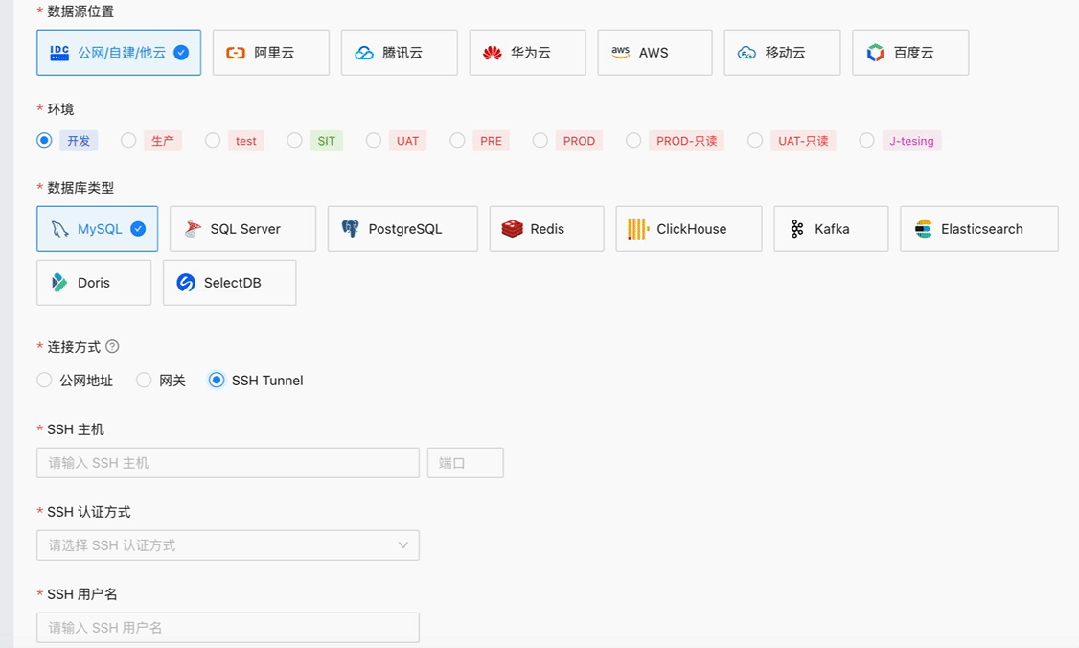
NineData支持最受欢迎数据库PostgreSQL
根据在 Stack Overflow 发布的 2023 开发者调研报告中显示,PostgreSQL 以 45% vs 41% 的受欢迎比率战胜 MySQL,成为新的最受欢迎的数据库。NineData 也在近期支持了 PostgreSQL,用户可以在 NineData 平台上进行创建数据库/Schema、管理用户与…...

Redis配置类
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

【前端知识】React 基础巩固(三十六)——RTK中的异步操作
React 基础巩固(三十六)——RTK中的异步操作 一、RTK中使用异步操作 引入RTK中的createAsyncThunk,在extraReducers中监听执行状态 import { createSlice, createAsyncThunk } from "reduxjs/toolkit"; import axios from "axios";export cons…...

为什么92%的社交App在AI Agent接入后用户停留时长暴跌?——资深架构师亲授5层调优框架
更多请点击: https://kaifayun.com 第一章:为什么92%的社交App在AI Agent接入后用户停留时长暴跌? 当AI Agent以“智能助手”“聊天搭子”“情绪陪伴者”等名义大规模嵌入社交App时,产品团队普遍预期用户活跃度与停留时长将显著提…...

如何快速上手SVG编辑:免费在线工具Method Draw完全指南
如何快速上手SVG编辑:免费在线工具Method Draw完全指南 【免费下载链接】Method-Draw Method Draw, the SVG Editor for Method of Action 项目地址: https://gitcode.com/gh_mirrors/me/Method-Draw 你是否曾经需要快速创建或编辑矢量图形,却被复…...

res-downloader终极指南:5分钟掌握全平台资源高效下载秘籍
res-downloader终极指南:5分钟掌握全平台资源高效下载秘籍 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 想要轻…...


在多模型聚合调用中体验到的路由与失败切换流畅度
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型聚合调用中体验到的路由与失败切换流畅度 效果展示类,分享开发者在实际编程中,当配置了多个备用模…...

轨迹在线识别导向的3D折线焊缝机器人摆动GMAW实时跟踪系统【附程序】
✨ 长期致力于3D折线焊缝、机器人、GMAW、轨迹在线识别、焊缝跟踪研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于激光位移传感与密度聚类点云在线…...

别再手动刷新了!用HomePage v0.8.2+Docker Compose,一键监控所有容器和网站状态
别再手动刷新了!用HomePage v0.8.2Docker Compose,一键监控所有容器和网站状态 每次登录服务器都要挨个检查容器是否运行正常?网站挂了却要等用户反馈才知道?这种被动式运维早该淘汰了。今天介绍的这套方案,能让你的H…...

PaperXie 期刊论文写作全解析|从选题到成稿,一键适配普通 / 核心 / SCI 期刊
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/期刊论文https://www.paperxie.cn/ai/journalArticleshttps://www.paperxie.cn/ai/journalArticles 一、前言:期刊论文写作的痛点,你中了几个? 在学术圈,期刊…...

保姆级教程:用MATLAB R2019a搞定小波分析,从数据导入到等值线图绘制全流程
MATLAB小波分析实战:从数据清洗到可视化呈现的完整指南 小波分析作为时频域分析的利器,在信号处理、地球物理、生物医学等领域广泛应用。但对于刚接触MATLAB的研究生或数据分析师而言,如何将Excel中的原始数据一步步转化为专业的小波系数图和…...

COMET:基于深度学习的翻译质量评估技术革命
COMET:基于深度学习的翻译质量评估技术革命 【免费下载链接】COMET A Neural Framework for MT Evaluation 项目地址: https://gitcode.com/gh_mirrors/com/COMET 在机器翻译技术快速发展的今天,翻译质量评估已成为连接技术研发与实际应用的关键…...