神经网络小记-优化器
优化器是深度学习中用于优化神经网络模型的一类算法,其主要作用是根据模型的损失函数来调整模型的参数,使得模型能够更好地拟合训练数据,提高模型的性能和泛化能力。优化器在训练过程中通过不断更新模型的参数,使模型逐步接近最优解。
具体来说,优化器的作用包括:
-
参数更新:优化器根据损失函数计算出的梯度信息来更新模型的参数,使得模型能够朝着损失函数下降的方向调整,从而最小化损失函数。
-
收敛加速:优化器通过引入动量等技术,可以加速模型的收敛过程,从而更快地找到较好的参数组合。
-
避免梯度消失或爆炸:在深度神经网络中,由于多层的链式求导可能导致梯度消失或爆炸问题。优化器通过适当的学习率调整和梯度裁剪等技巧,可以缓解这些问题,保证模型的稳定训练。
-
自适应调整学习率:一些优化器如Adagrad、RMSprop和Adam等具有自适应学习率的特性,能够根据参数梯度的历史信息动态调整学习率,以适应不同参数的学习速度。
-
防止过拟合:优化器通过在训练过程中更新参数,可以在一定程度上防止模型在训练数据上过度拟合,提高模型的泛化能力。
ps:
同一个优化器通常可以用于分类和回归等不同类型的任务。优化器的作用是通过更新模型的参数来最小化损失函数,而损失函数的选择取决于具体的任务类型。
在深度学习中,优化器的选择一般与损失函数的选择是独立的。优化器的目标是最小化损失函数,而不同类型的损失函数对应着不同的任务。
不论是分类还是回归任务,我们都可以使用相同的优化器来最小化相应的损失函数。优化器的选择不依赖于任务类型,而是根据优化效果、收敛速度等因素来进行选择。可以将同一个优化器用于分类和回归等不同类型的任务,但在使用时需要注意选择合适的损失函数来匹配不同的任务类型。
常见的优化器
-
随机梯度下降(Stochastic Gradient Descent,SGD):
- SGD是最基础的优化算法之一,每次迭代从训练数据中随机选择一个样本来计算梯度,并更新模型参数。
- 优点:计算速度较快,易于实现和理解。
- 缺点:可能会陷入局部最优点,梯度更新不稳定。
-
动量(Momentum):
- 动量优化器在SGD的基础上加入了动量项,用于加速收敛并减少震荡。
- 动量可以理解为模拟物体在梯度方向上滚动的速度,有助于在陡峭的损失曲面上更快地前进。
- 优点:加速收敛,减少震荡。
- 缺点:可能会在平坦区域陷入局部最优。
-
自适应学习率优化器:
- Adagrad:Adagrad根据参数的历史梯度信息来调整学习率,适用于稀疏数据。
- RMSprop:RMSprop是对Adagrad的改进版本,通过引入一个衰减系数来防止学习率过快地下降。
- Adam:Adam是结合了动量和RMSprop的优化器,常用于深度学习中,具有较好的性能和鲁棒性。
- 优点:自适应调整学习率,对不同参数使用不同的学习率,收敛速度较快。
- 缺点:需要额外的超参数调优,可能会增加计算开销。
-
学习率衰减(Learning Rate Decay):
- 学习率衰减是一种在训练过程中逐渐减小学习率的技术,以便更好地优化模型。
- 通过逐步减小学习率,可以在训练初期较快地接近全局最优点,然后逐渐减小学习率以更细致地调整参数。
-
Nesterov Accelerated Gradient(NAG):
- NAG是对动量优化器的改进版本,在计算梯度时采用模型参数的更新值,有助于提高优化效率。
- 通过提前考虑动量项,可以更准确地估计参数更新,提高参数更新的准确性和稳定性。
-
AdaDelta:
- AdaDelta是对Adagrad的改进版本,通过动态调整历史梯度信息来避免学习率衰减过快的问题。
- 不需要手动设置全局学习率,参数更新更加稳定。
-
AdamW(Adam with Weight Decay):
- AdamW是对Adam的改进版本,在参数更新时对权重衰减进行更准确的处理,可以提高模型的泛化性能。
每种优化器都有其特点和适用场景。在选择优化器时,应考虑数据集的大小、模型的复杂程度、训练时间和计算资源的限制等因素,并通过实验比较不同优化器的性能,选择最适合当前任务的优化算法。
特点与应用场景
下面是各种优化器的特点和应用场景的简要总结,以表格形式呈现:
| 优化器 | 特点 | 应用场景 |
|---|---|---|
| SGD | 最基础的优化器,全局固定学习率,容易陷入局部最优,收敛较慢。 | 简单问题,数据集较小 |
| Momentum | 引入动量项,加速收敛,减少震荡,但可能在平坦区域陷入局部最优。 | 大规模数据集,复杂模型 |
| Adagrad | 自适应学习率,根据参数的历史梯度信息调整学习率,适用于稀疏数据。 | 稀疏数据集,特征稀疏 |
| RMSprop | 对Adagrad的改进,引入衰减系数,防止学习率过快下降。 | 非平稳数据集,复杂模型 |
| Adadelta | 对Adagrad的改进,动态调整学习率,避免全局学习率设置。 | 大规模数据集,复杂模型 |
| Adam | 结合了动量和RMSprop,自适应调整学习率,收敛较快,广泛应用于深度学习。 | 大多数情况下都适用,复杂模型 |
| AdamW | 在Adam的基础上加入权重衰减,提高模型的泛化性能。 | 大规模数据集,复杂模型 |
| Nadam | 在Adam的基础上加入Nesterov Accelerated Gradient,动态调整学习率,收敛更快。 | 大规模数据集,复杂模型 |
| L-BFGS | 二次优化方法,基于拟牛顿法,适用于小数据集和小规模模型。 | 小数据集,小规模模型 |
torch中常见优化器
- SGD(随机梯度下降):
import torch.optim as optimoptimizer = optim.SGD(model.parameters(), lr=learning_rate)
- Adam(自适应矩估计):
import torch.optim as optimoptimizer = optim.Adam(model.parameters(), lr=learning_rate)
- RMSprop(均方根传递):
import torch.optim as optimoptimizer = optim.RMSprop(model.parameters(), lr=learning_rate)
- Adagrad(自适应学习率方法):
import torch.optim as optimoptimizer = optim.Adagrad(model.parameters(), lr=learning_rate)
- Adadelta:
import torch.optim as optimoptimizer = optim.Adadelta(model.parameters(), lr=learning_rate)
- AdamW(带权重衰减的Adam):
import torch.optim as optimoptimizer = optim.AdamW(model.parameters(), lr=learning_rate)
以上示例中,model.parameters()是用于优化的模型参数,lr是学习率(learning rate),它是优化器的一个重要超参数。可以根据具体任务和数据选择合适的优化器及超参数来进行模型训练和优化。
简单神经网络示例
神经网络一般流程:
-
前向传播:输入数据通过网络的一系列层,逐层进行线性变换和激活函数处理,得到最终的输出。
-
损失函数:根据模型的输出和真实标签计算损失,用于衡量模型的预测与真实值之间的差异。
-
反向传播:通过计算损失函数对模型参数的梯度,将梯度从输出层向输入层传播,用于更新网络参数。
-
优化器:优化器根据反向传播得到的梯度信息,以一定的优化算法来更新神经网络的参数,从而最小化损失函数。
-
参数更新:根据优化器计算得到的参数梯度,更新神经网络的权重和偏置,以使模型逐渐收敛于更优的状态。
-
迭代训练:通过多次迭代前向传播、反向传播和参数更新,使得神经网络在训练集上逐步调整参数,提高模型性能。
重点讲一下优化器:
-
优化器:优化器是神经网络训练中的重要组成部分,它决定了参数如何根据损失函数的梯度进行更新,从而使得模型逐步优化。
-
梯度下降:梯度下降是优化器最基本的思想,根据损失函数的梯度方向,对参数进行更新。其中,SGD(随机梯度下降)是最简单的梯度下降方法,但在训练过程中可能会出现震荡和收敛较慢的问题。
-
优化算法:为了解决梯度下降的问题,出现了多种优化算法。常见的优化器包括:Momentum、Adagrad、RMSprop、Adam等。这些优化算法在梯度下降的基础上引入了动量、学习率调整等机制,以加速收敛和提高优化效果。
-
超参数调整:优化器有一些重要的超参数,如学习率、动量等。合理选择这些超参数对模型的性能影响很大。通常需要进行超参数调优来找到最优的参数组合。
-
稳定性与泛化:优化器的选择和超参数的设置对于神经网络的稳定性和泛化性能有很大影响。不同的优化器和超参数组合可能会导致模型陷入局部最优或过拟合。
-
自适应学习率:近年来,自适应学习率的优化算法变得流行,如Adagrad、RMSprop和Adam。这些算法可以根据参数的历史梯度信息自适应地调整学习率,从而更有效地进行参数更新。
-
收敛性:优化器的选择也会影响神经网络是否能够达到较好的收敛性,即在合理的迭代次数内,模型能够趋于稳定状态,同时避免过度拟合。因此,在选择优化器时,需要考虑网络结构、数据集规模和训练策略。
在PyTorch中搭建神经网络和选择优化器的重点步骤如下:
- 定义神经网络模型:首先需要定义神经网络模型的结构。可以使用
torch.nn.Module来创建一个自定义的神经网络类,并在其构造函数__init__中定义各层和参数。
import torch
import torch.nn as nnclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.fc1 = nn.Linear(in_features, hidden_size)self.fc2 = nn.Linear(hidden_size, out_features)# 定义其他层...def forward(self, x):x = self.fc1(x)x = torch.relu(x)x = self.fc2(x)return x
- 实例化模型和损失函数:在使用模型之前,需要实例化模型,并选择适当的损失函数。同时,需要定义超参数,如学习率(lr)、权重衰减(weight decay)等。
# 实例化模型
model = MyModel()# 定义损失函数
criterion = nn.CrossEntropyLoss()# 定义优化器(标注重点)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
- 训练循环:在训练过程中,重点是优化器的使用。在每次迭代中,需要先将梯度清零,然后计算模型输出和损失,接着反向传播计算梯度,并最终通过优化器来更新模型参数。
# 训练循环
for epoch in range(num_epochs):for inputs, labels in dataloader:# 将梯度清零optimizer.zero_grad()# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播loss.backward()# 更新模型参数(优化器的重点操作)optimizer.step()
- 验证或测试:在训练后,可以对模型进行验证或测试。在验证或测试阶段,通常不需要进行梯度计算,因此可以使用
torch.no_grad()上下文管理器来关闭梯度计算,从而节省内存和计算资源。
# 验证或测试循环
with torch.no_grad():for inputs, labels in val_dataloader:# 前向传播(无需计算梯度)outputs = model(inputs)# 其他验证或测试操作...
以上是在PyTorch中搭建神经网络和标注优化器的主要步骤。选择合适的优化器和设置合理的超参数是训练神经网络的关键。根据任务的复杂度和数据量,可能需要进行不同优化器的尝试和超参数调整。
相关文章:

神经网络小记-优化器
优化器是深度学习中用于优化神经网络模型的一类算法,其主要作用是根据模型的损失函数来调整模型的参数,使得模型能够更好地拟合训练数据,提高模型的性能和泛化能力。优化器在训练过程中通过不断更新模型的参数,使模型逐步接近最优…...

200+行代码写一个简易的Qt界面贪吃蛇
照例先演示一下: 一个简单的Qt贪吃蛇,所有的图片都是我自己画的(得意)。 大致的运行逻辑和之前那个200行写一个C小黑窗贪吃蛇差不多,因此在写这个项目的时候,大多情况是在想怎么通过Qt给展现出来。 背景图…...
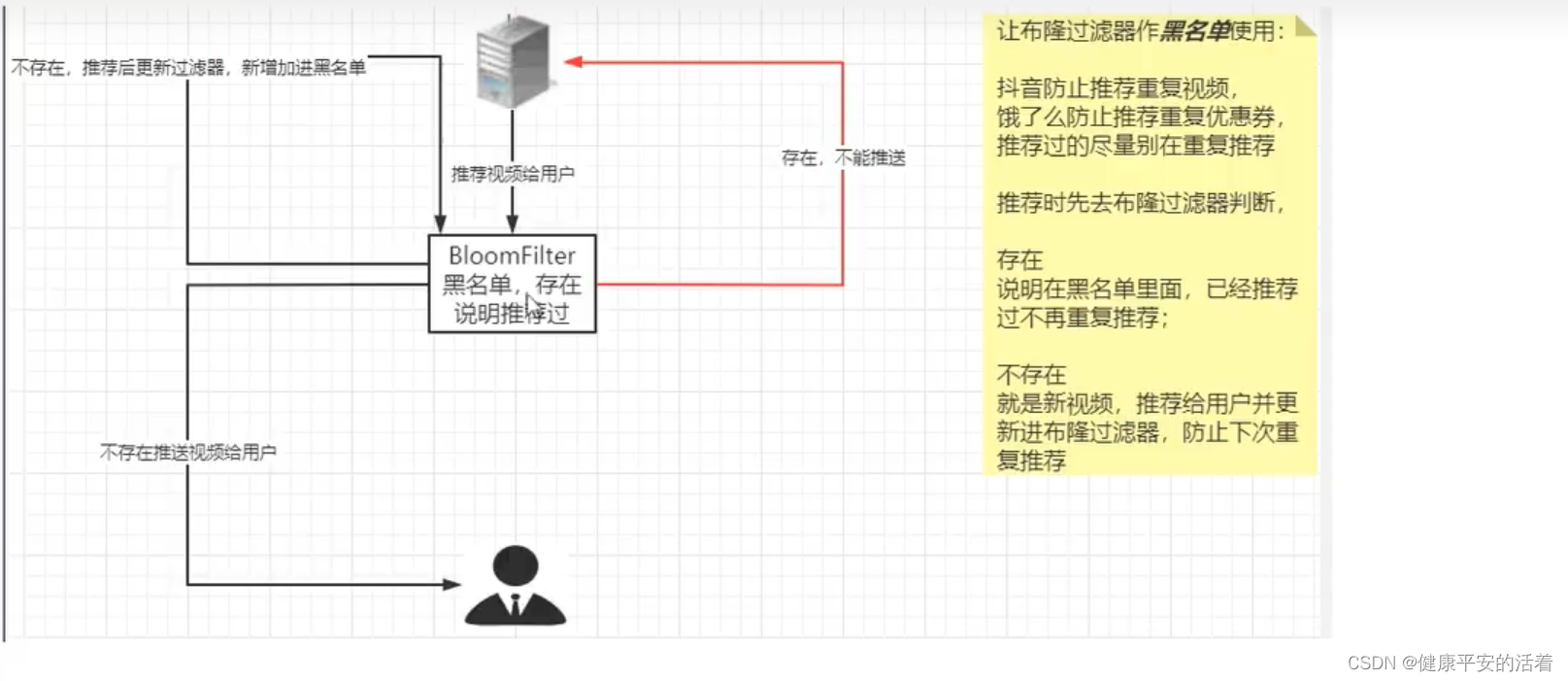
redis中使用bloomfilter的白名单功能解决缓存穿透问题
一 缓存预热 1.1 缓存预热 将需要的数据提前缓存到缓存redis中,可以在服务启动时候,或者在使用前一天完成数据的同步等操作。保证后续能够正常使用。 1.2 缓存穿透 在redis中,查询redis缓存数据没有内容,接着查询mysql数据库&…...
Spring Boot 2.7.8以后mysql-connector-java与mysql-connector-j
错误信息 如果升级到Spring Boot 2.7.8,可以看到因为找不到mysql-connector-java依赖而出现错误。 配置: <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId>&l…...

03|「如何写好一个 Prompt」
前言 Prompt 文章目录 前言一、通用模板和范式1. 组成2. 要求1)文字描述2)注意标点符号 一、通用模板和范式 1. 组成 指令(角色) 生成主体 额外要求 指令:模型具体完成的任务描述。例如,翻译一段文字&…...
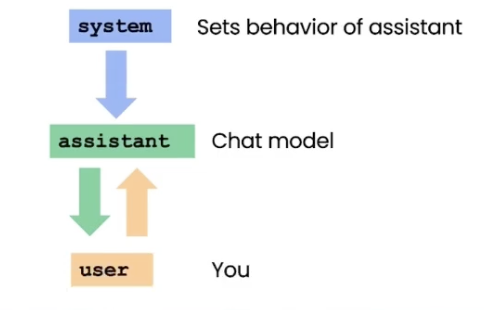
关于提示词 Prompt
Prompt原则 原则1 提供清晰明确的指示 注意在提示词中添加正确的分割符号 prompt """ 请给出下面文本的摘要: <你的文本> """可以指定输出格式,如:Json、HTML提示词中可以提供少量实例,…...

【Linux多线程】线程的互斥与同步(附抢票案例代码+讲解)
线程的互斥与同步 💫 概念引入⭐️临界资源(Critical Resource):🌟临界区(Critical Section):✨互斥(Mutex): ⚡️结合代码看互斥☄️ 代码逻辑&a…...
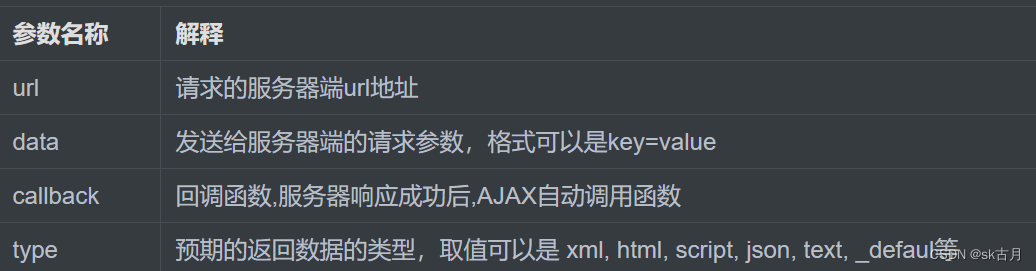
ajax概述
目录 1.什么是ajax 2.ja原生ajax 3.jQuery框架的ajax 4.综合案例 1.什么是ajax Ajax 即"Asynchronous Javascript And XML"(异步 JavaScript 和 XML),是指一种创建交互式网页应用的网页开发技术。Ajax 异步 JavaScript 和 XML&…...
小白带你学习linux的mysql服务(主从mysql服务和读写分离三十一)
目录 二、MySQL Replication优点: 三、MySQL复制类型 1、异步复制(Asynchronous repication) 2、全同步复制(Fully synchronous replication) 3、半同步复制(Semisynchronous replication)…...

【低代码专题方案】iPaaS运维方案,助力企业集成平台智能化高效运维
01 场景背景 随着IT行业的发展和各家企业IT建设的需要,信息系统移动化、社交化、大数据、系统互联、数据打通等需求不断增多,企业集成平台占据各个企业领域,成为各业务系统数据传输的中枢。 集成平台承接的业务系统越多,集成平台…...
Android SDK 上手指南||第一章 环境需求||第二章 IDE:Eclipse速览
第一章 环境需求 这是我们系列教程的第一篇,让我们来安装Android的开发环境并且把Android SDK运行起来! 介绍 欢迎来到Android SDK入门指南系列文章,如果你想开始开发Android App,这个系列将从头开始教你所须的技能。我们假定你…...

Amazon Linux上使用ec2-user来设置开机自启动的shell脚本
要在Amazon Linux上使用ec2-user来设置开机自启动的shell脚本,可以按照以下步骤操作: 1. 确保您拥有要设置自启动的shell脚本。假设脚本的路径是/home/ec2-user/myscript.sh。 2. 使用以下命令打开/etc/rc.d/rc.local文件: shell sudo nano /…...

【Spring】Spring 下载及其 jar 包
根据 【动力节点】最新Spring框架教程,全网首套Spring6教程,跟老杜从零学spring入门到高级 以及老杜的原版笔记 https://www.yuque.com/docs/share/866abad4-7106-45e7-afcd-245a733b073f?# 《Spring6》 进行整理, 文档密码:mg9b…...

蓝桥杯2023年第十四届省赛-飞机降落
题目描述 N 架飞机准备降落到某个只有一条跑道的机场。其中第 i 架飞机在 Ti 时刻到达机场上空,到达时它的剩余油料还可以继续盘旋 Di 个单位时间,即它最早 可以于 Ti 时刻开始降落,最晚可以于 Ti Di 时刻开始降落。降落过程需要 Li个单位时…...
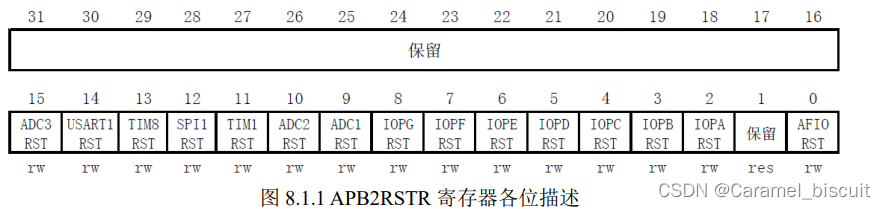
STM32 串口实验(学习一)
本章将实现如下功能:STM32通过串口和上位机对话,STM32在收到上位机发过来的字符串后,原原本本返回给上位机。 STM32 串口简介 串口作为MCU的重要外部接口,同时也是软件开发重要的调试手段,其重要性不言而喻。现在基本…...
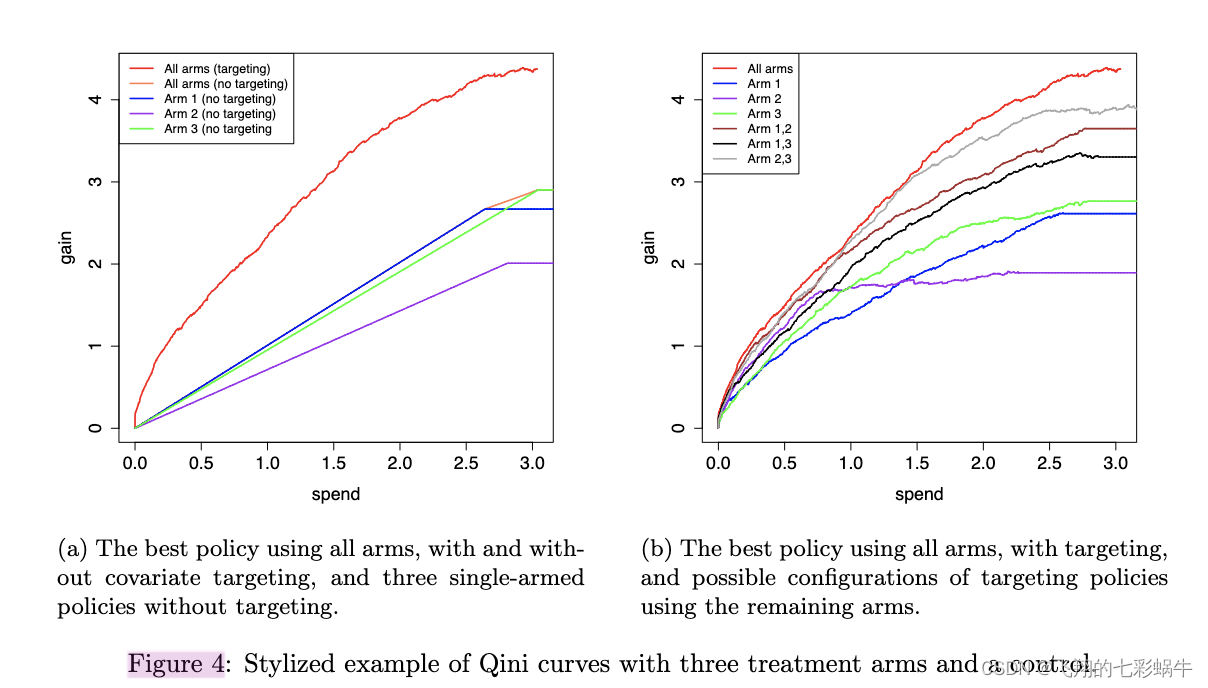
多臂治疗规则的 Qini 曲线(Stefan Wager)
英文题目: Qini Curves for Multi-Armed Treatment Rules 中文题目:多臂治疗规则的 Qini 曲线 单位:Stefan Wager 论文链接: 代码:GitHub - grf-labs/maq: Treatment rule evaluation via the multi-armed Qini …...

NOSQL之Redis配置及优化
目录 一、关系型数据库 二、非关系型数据库 三、关系型数据库和非关系型数据库区别 1、数据存储方式不同 2、扩展方式不同 3、对事务性的支持不同 四、Redis简介 五、Redis优点 (1)具有极高的数据读写速度 (2)支持丰富的…...
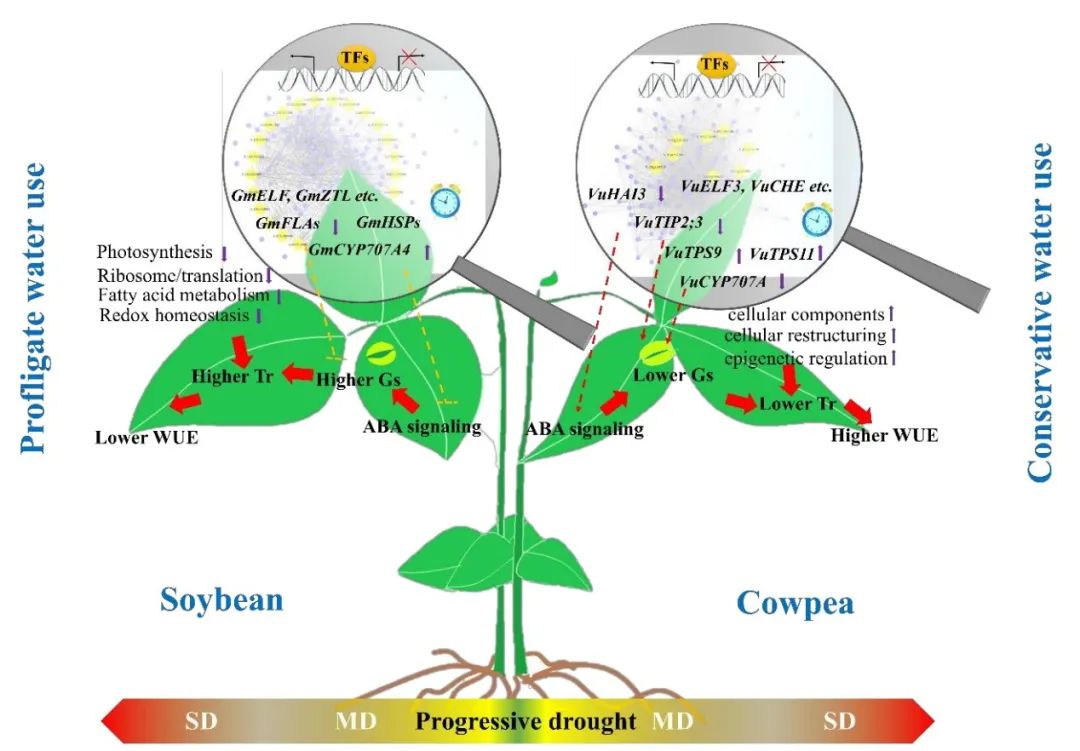
植物一区HR | 植物生理组+转录组:揭示豆科植物响应干旱胁迫机制
PlantArray 植物高通量生理学表型监测系统 是一套以植物生理学为基础的高精度,高通量,自动化表型监测系统,集合实验设置、数据分析、决策工具于一身,能够高通量实时动态监测并进行全天候生理及环境参数采集,是进行植物…...

TCP粘包问题
TCP粘包问题 TCP粘包问题造成TCP粘包的原因发送方原因接收方原因 如何处理TCP粘包发送方接收方应用层 为什么UDP没有粘包问题 TCP粘包问题 TCP粘包就是指发送方发送的若干包数据到达接收方时粘成了一包,从接收缓冲区来看,后一包数据的头紧接着前一包数据…...
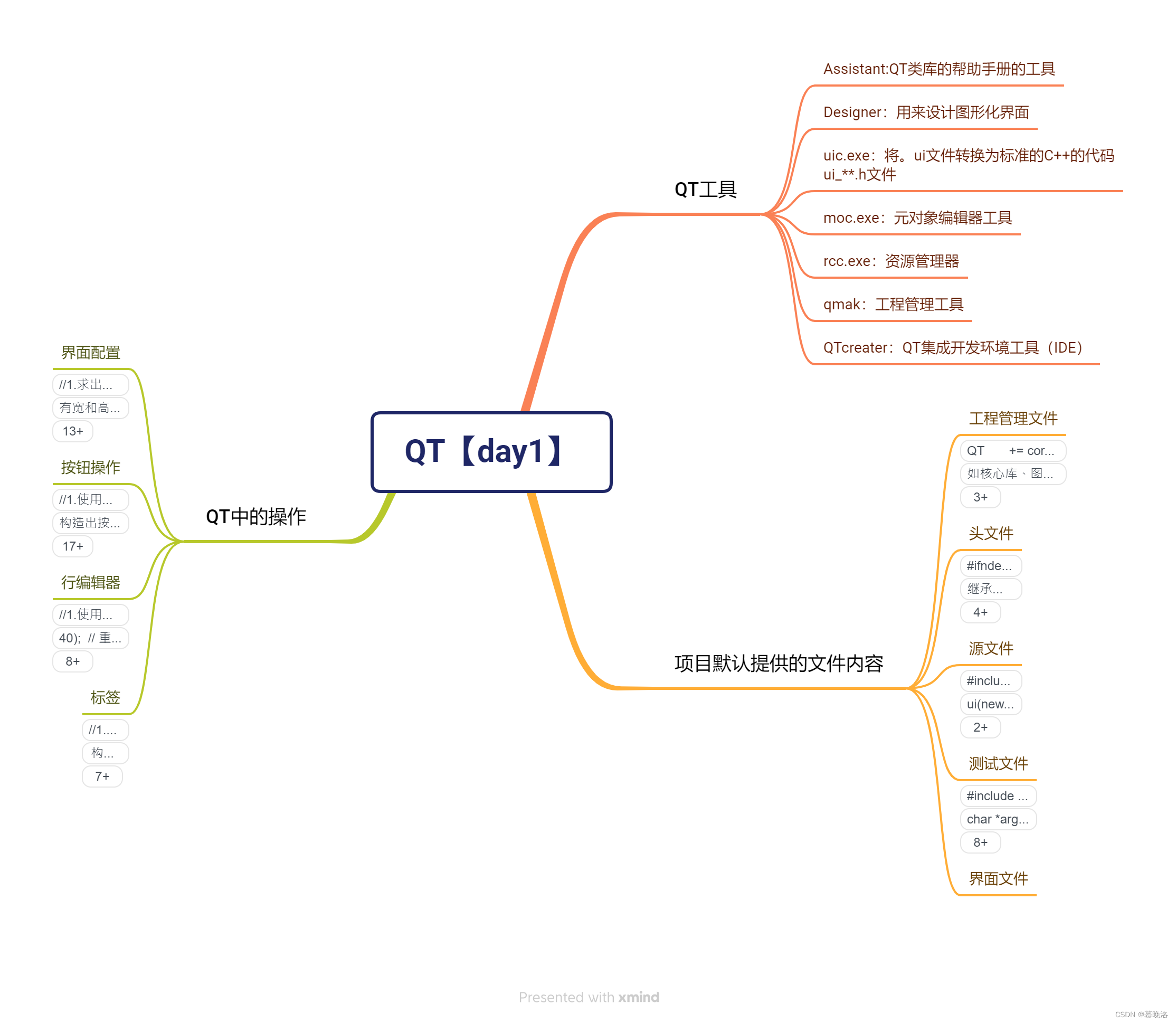
QT【day1】
登录框: #include "mainwindow.h"MainWindow::MainWindow(QWidget *parent): QMainWindow(parent) {//窗口设置this->setFixedSize(600,600); //大小this->setWindowTitle("MUMU"); //文本内容this->setWindowOpacity(0.8); //透…...

别再乱用电容了!从稳压芯片电路入手,搞懂电解电容和贴片电容到底该怎么搭配
电解电容与贴片电容的黄金组合:稳压电路设计实战解析 在电子电路设计中,稳压芯片的输入输出端常见一大一小两个电容并联的经典配置,这种设计看似简单却蕴含着深刻的电路原理。对于刚入行的硬件工程师或电子爱好者来说,理解这种组…...

ARMv8调试状态下LDR指令未定义问题解析
1. 问题背景与现象分析在ARMv8-A架构的调试过程中,开发者经常会遇到一个令人困惑的现象:当外部调试器暂停核心执行后,向EDITR寄存器注入LDR X1, [X0]指令(机器码0xf9400001)时,Tarmac日志显示该指令被标记为…...

体验Taotoken的模型广场如何辅助开发者快速选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken的模型广场如何辅助开发者快速选型 对于需要接入大模型能力的开发者而言,面对市场上众多的模型提供商和复…...

VideoDownloadHelper:免费视频下载插件终极使用指南
VideoDownloadHelper:免费视频下载插件终极使用指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 你是否经常遇到想要保存网页视…...

抖音内容自动化下载:3大技术挑战与实战解决方案
抖音内容自动化下载:3大技术挑战与实战解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖…...

UVa 273 Jack Straws
题目分析 本题的题目背景源自一种名为 “Jack Straws\texttt{Jack Straws}Jack Straws” 的游戏,玩家需要从桌上一堆杂乱摆放的塑料或木质 “稻草” 中逐根取出,而不扰动其他稻草。本题不关心游戏过程,只关心一个问题:给定若干根稻…...

从BJT到CMOS:运放偏置电流的前世今生,以及它对高阻抗传感器电路设计的实际影响
从BJT到CMOS:运放偏置电流的前世今生,以及它对高阻抗传感器电路设计的实际影响 在精密测量领域,运算放大器的偏置电流就像一位隐形的"电流小偷",悄无声息地影响着测量精度。想象一下,当你试图测量一个微弱的…...

开源大模型核心组件解析:从权重、代码到训练数据的完整拼图
1. 项目概述:一次关于“开源”的深度追问最近在社区和几个朋友聊天,发现一个挺有意思的现象:大家聊起“开源大模型”都兴致勃勃,但当我问“那它到底开源了啥?源码在哪儿下?”时,场面往往会安静几…...
)
告别滑动窗口!用Python手把手复现红外小目标检测的LCM算法(附完整代码)
告别滑动窗口!用Python手把手复现红外小目标检测的LCM算法 红外小目标检测在军事侦察、安防监控等领域具有重要应用价值。传统滑动窗口方法计算量大、效率低下,而局部对比度测量(LCM)算法通过巧妙设计实现了高效检测。本文将带您从…...

昇腾CANN amct:模型压缩工具的量化和部署实践
amct(Ascend Model Compression Toolkit)是 CANN 内置的模型压缩工具,不是 AtomGit 上的独立开源仓库——它在 CANN AOE 调优引擎里作为一个子模块运行。amct 做三件事:量化(INT8/FP16)、剪枝(结…...