ceph集群中RBD的性能测试、性能调优
文章目录
- rados bench
- rbd bench-write
- 测试工具Fio
- 测试ceph rbd块设备的iops性能
- 测试ceph rbd块设备的带宽
- 测试ceph rbd块设备的延迟
- 性能调优
rados bench
参考:https://blog.csdn.net/Micha_Lu/article/details/126490260
rados bench为ceph自带的基准测试工具,rados bench用于测试rados存储池底层性能,该工具可以测试写、顺序读、随机读三种类型.
写入速率测试:
rados bench -p rbd-bak 10 write --no-cleanup
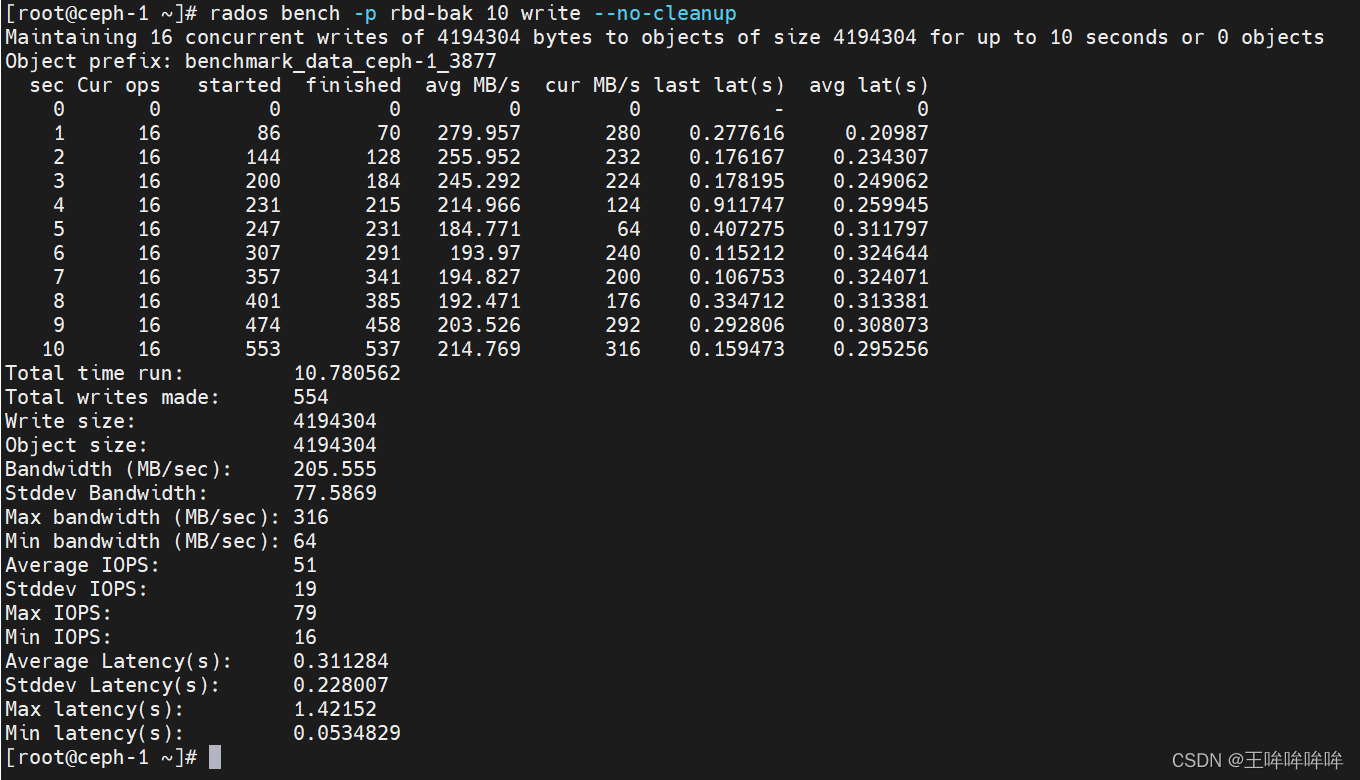
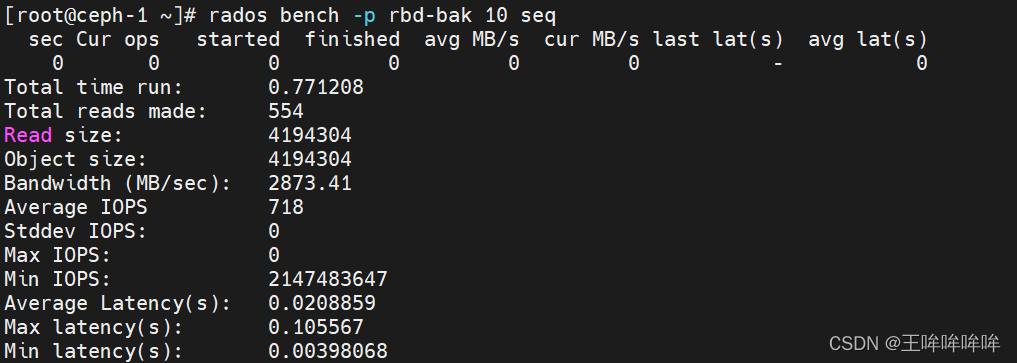
顺序读速率测试:
rados bench -p rbd-bak 10 seq
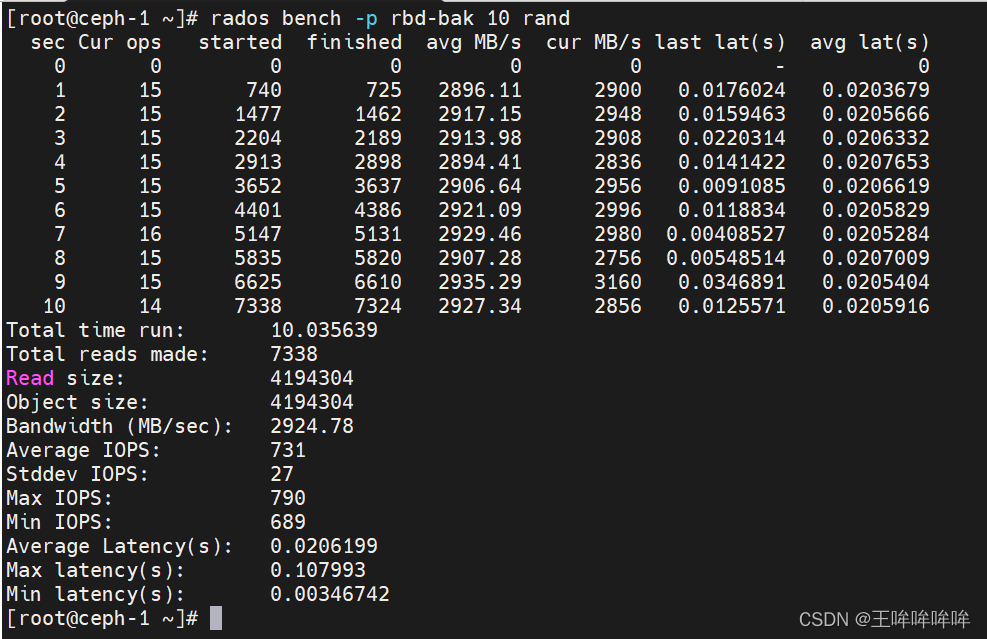
随机读速率测试:
rados bench -p rbd-bak 10 rand
rbd bench-write
rbd bench-write为ceph自带的基准性能测试工具,rbd bench-write用于测试块设备的简单写入测试。
rbd bench-write rbd-bak/image1 --io-size 1M --io-pattern seq --io-threads 32 --io-total 10G
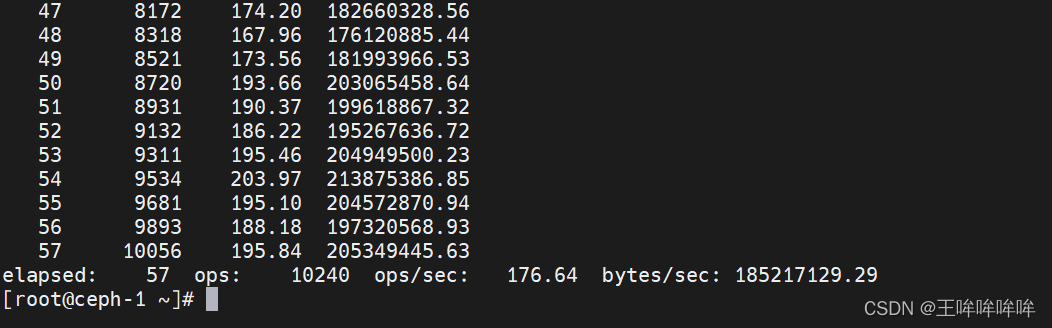
测试结果取最后一行elapsed的值,带宽为bytes/sec对应参数值(单位为bytes/sec,可根据需要转换为MB/s),IOPS为ops/sec对应参数值
测试工具Fio
yum install fio -y
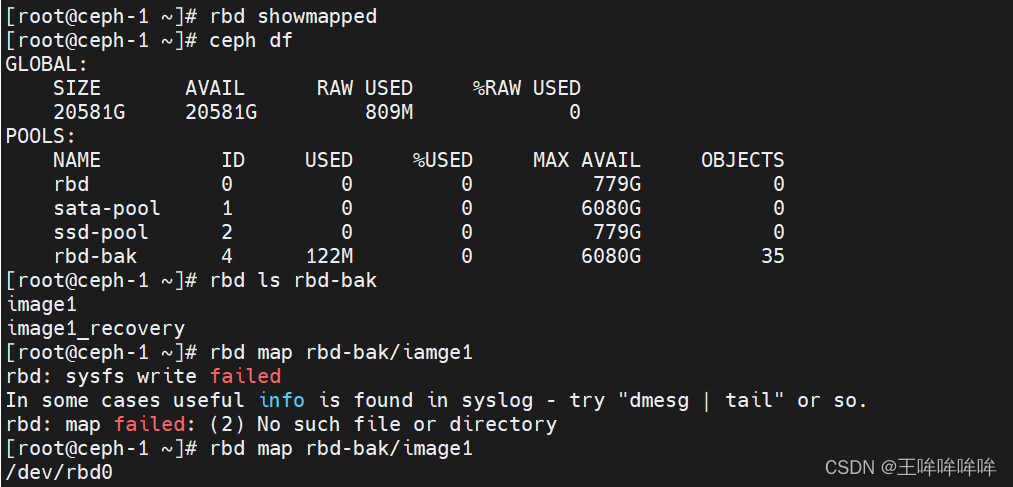
测试ceph rbd块设备的iops性能
关于fio命令的参数,参考:https://blog.csdn.net/zhiboqingyun/article/details/123368887
每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一;
测试随机写4kb文件的iops性能
fio --name=4krandwrite_iops --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=libaio --direct=1 --randrepeat=0 --norandommap --rw=randwrite --group_reporting --iodepth=512 --iodepth_batch=128 --iodepth_batch_complete=128 --gtod_reduce=1 --runtime=10
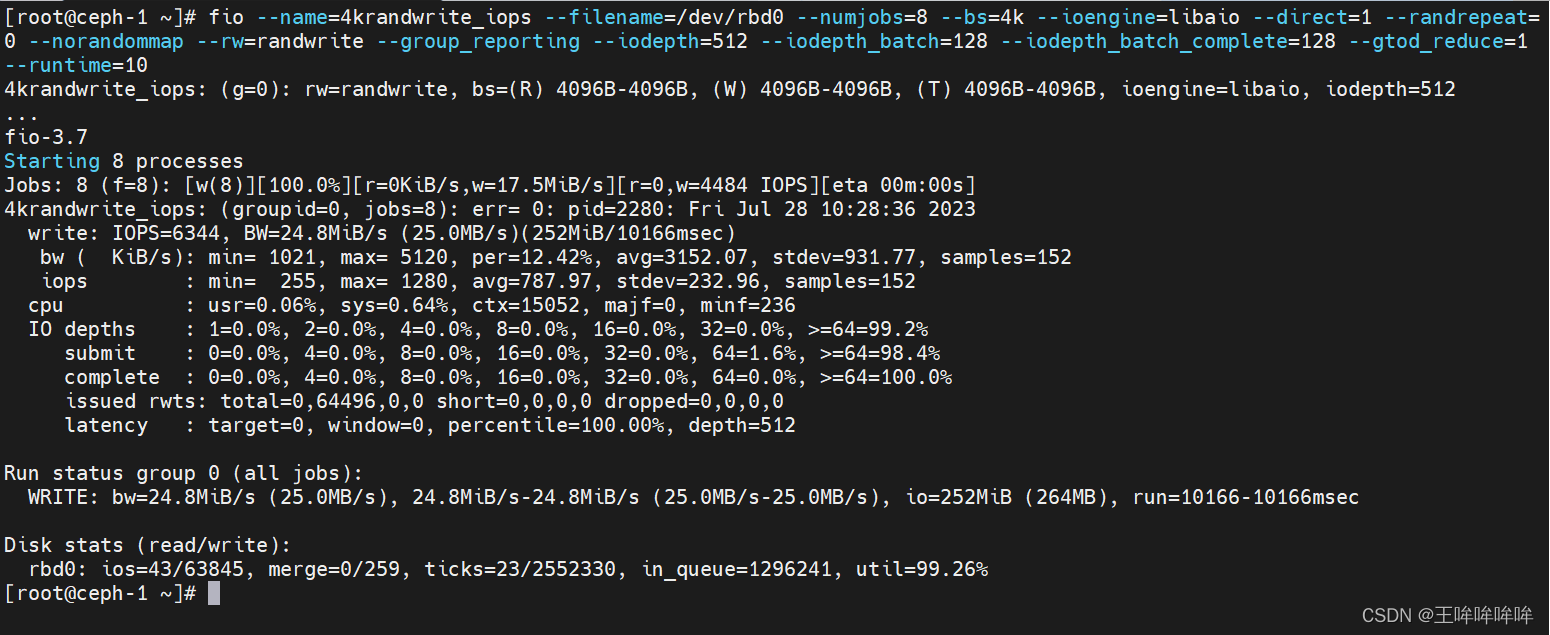
顺序写4kb文件的iops性能
fio --name=4kwrite_iops --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=libaio --direct=1 --randrepeat=0 --norandommap --rw=write --group_reporting --iodepth=512 --iodepth_batch=128 --iodepth_batch_complete=128 --gtod_reduce=1 --runtime=10
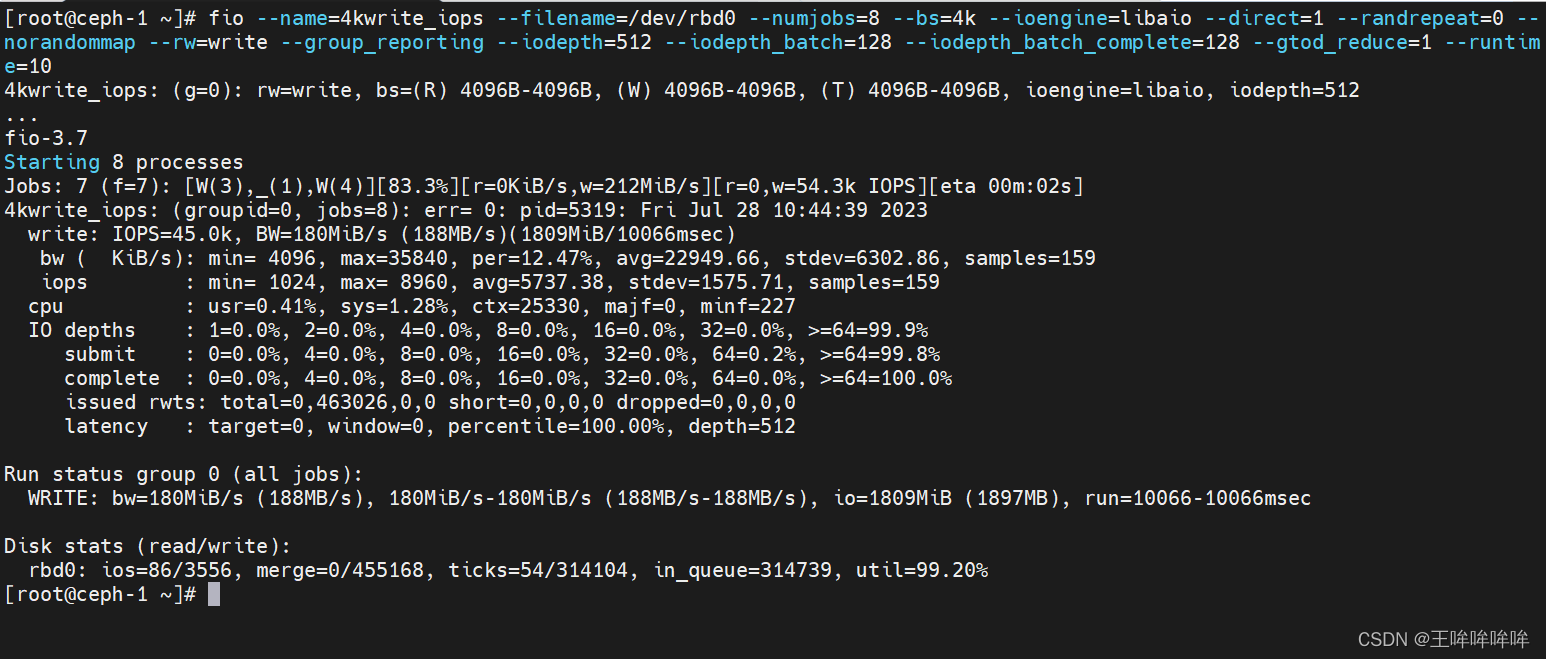
顺序读4kb文件的iops性能
fio --name=4kread_iops --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=libaio --direct=1 --randrepeat=0 --norandommap --rw=read --group_reporting --iodepth=512 --iodepth_batch=128 --iodepth_batch_complete=128 --gtod_reduce=1 --runtime=10
随机读4kb文件的iops性能
fio --name=4krandread_iops --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=libaio --direct=1 --randrepeat=0 --norandommap --rw=randread --group_reporting --iodepth=512 --iodepth_batch=128 --iodepth_batch_complete=128 --gtod_reduce=1 --runtime=10
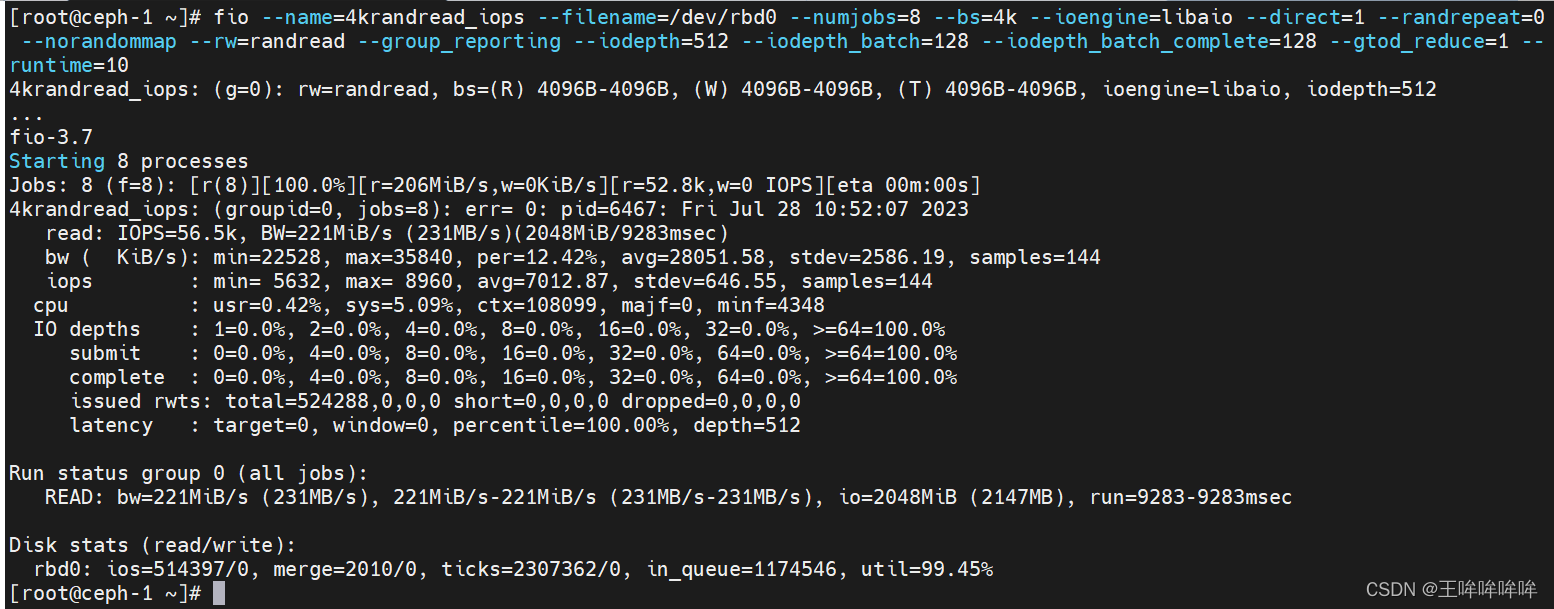
测试ceph rbd块设备的带宽
测试ceph rbd设备写4MB文件的极限带宽性能
fio --name=4mwrite_bw --filename=/dev/rbd0 --numjobs=8 --bs=4m --ioengine=libaio --direct=1 --randrepeat=0 --norandommap --rw=write --group_reporting --iodepth=512 --iodepth_batch=128 --iodepth_batch_complete=128 --gtod_reduce=1 --runtime=10
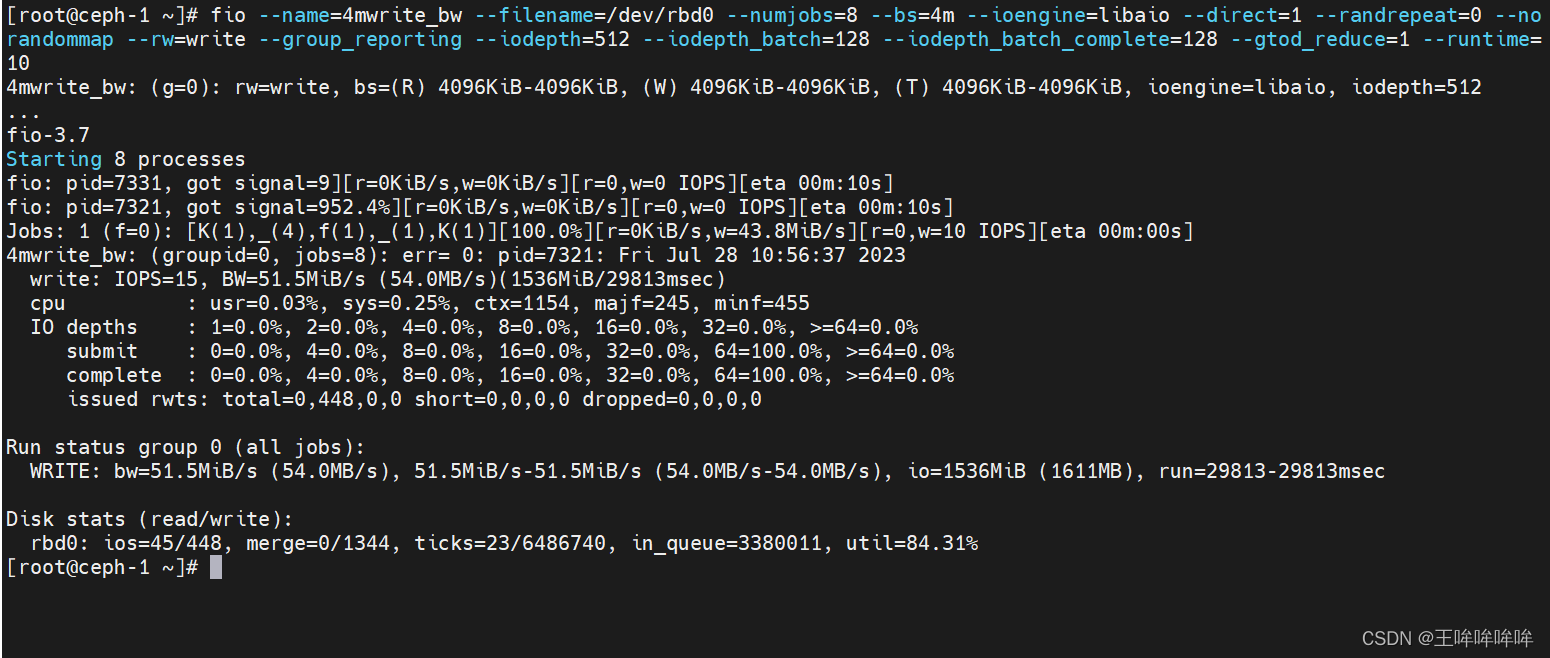
bw=这组进程的总带宽,每个线程的带宽
测试ceph rbd块设备的延迟
测试ceph rbd设备顺序写4kb文件的延迟性能
fio --name=4kwrite_lat --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=sync --direct=1 --randrepeat=0 --norandommap --rw=write --group_reporting --runtime=10
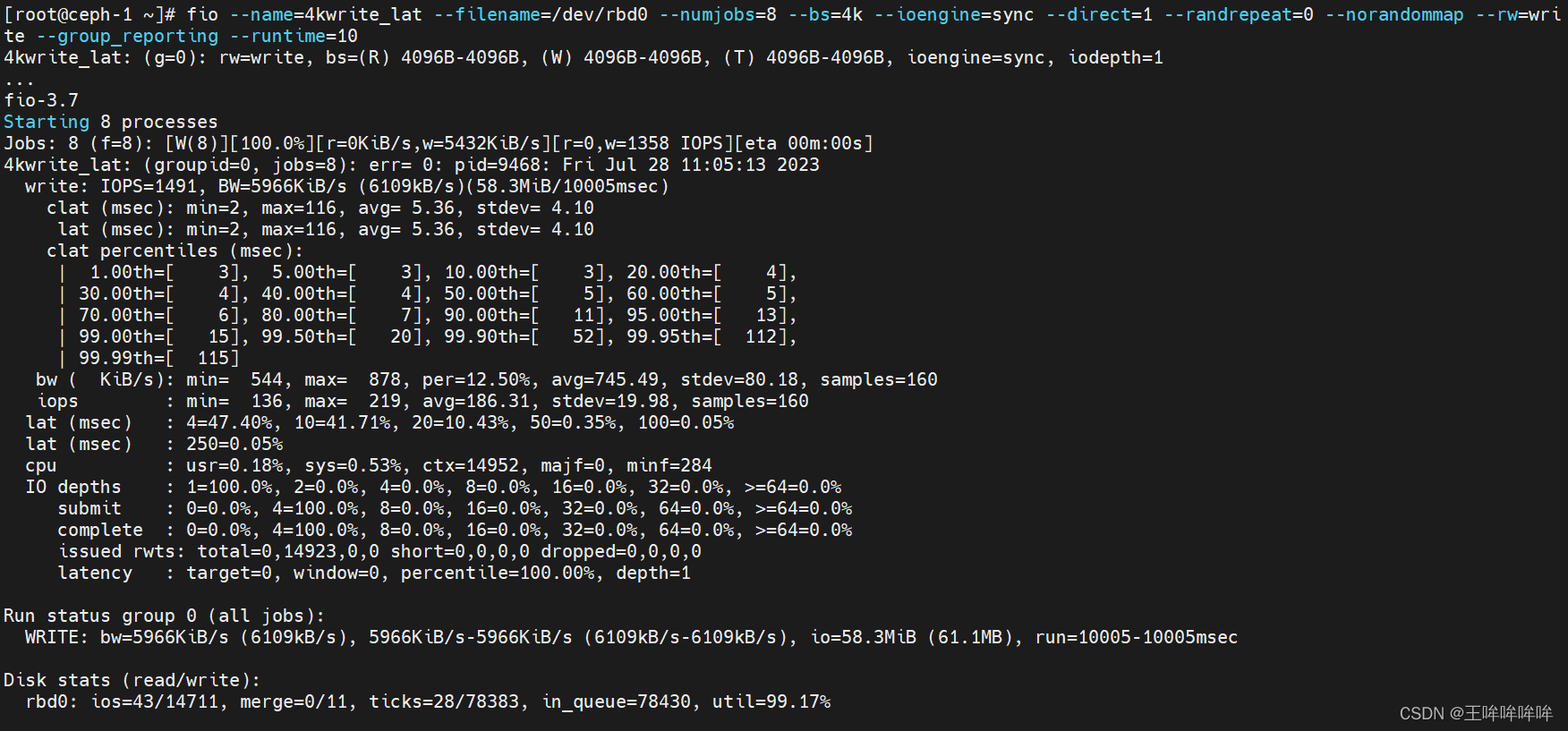
一些参数解释:
slat 表示fio 提交某个I/O的延迟(min为最小值,max为最大值,avg为平均值,stdev为标准偏差)。 对于同步I / O,不会显示该行。
clat 表示从提交到完成I / O的时间。
lat 表示从fio将请求提交给内核,再到内核完成这个I/O为止所需要的时间;
usec:微秒;msec:毫秒;1ms=1000us;
测试ceph rbd设备顺序读4kb文件的延迟性能
fio --name=4kread_lat --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=sync --direct=1 --randrepeat=0 --norandommap --rw=read --group_reporting --runtime=10
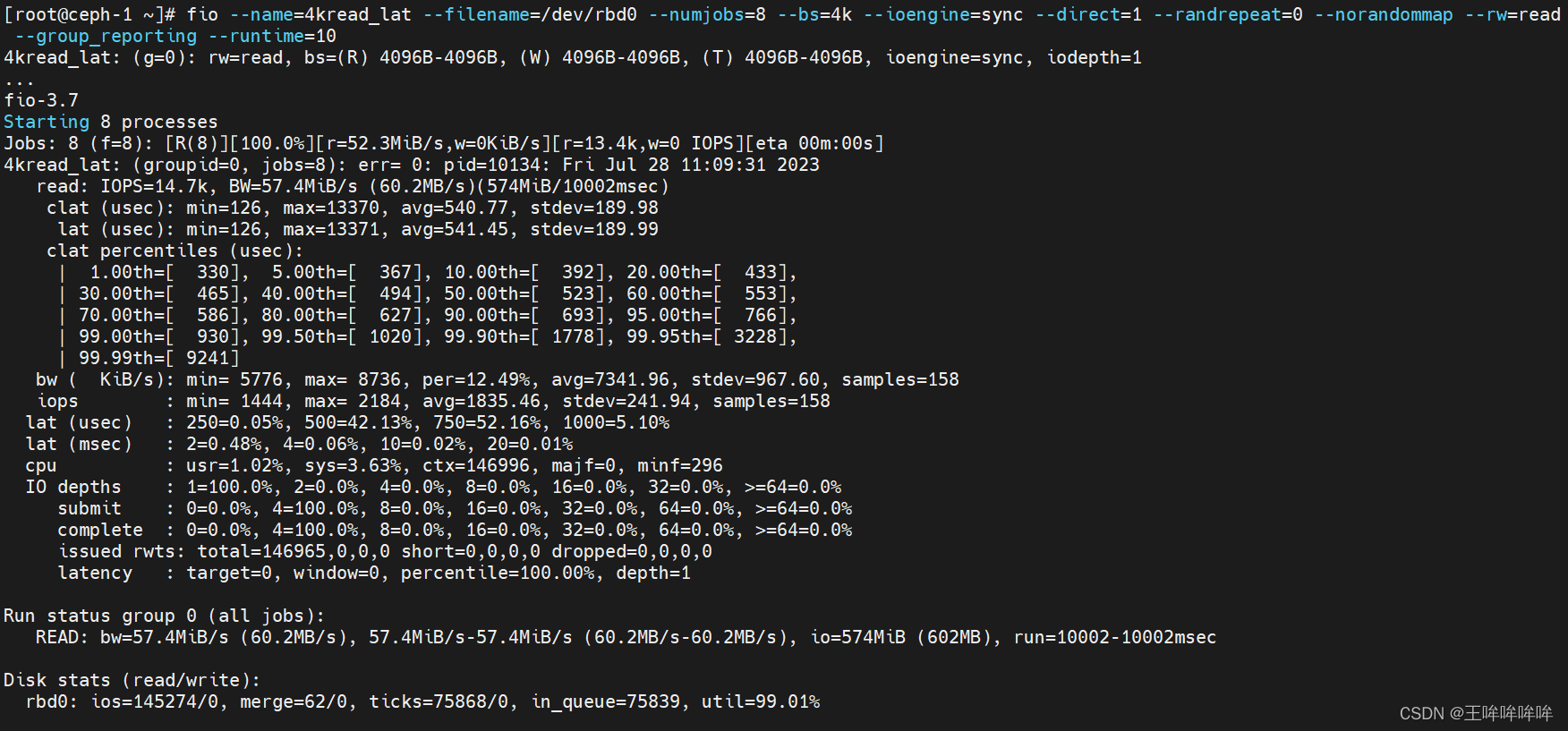
测试ceph rbd设备随机读4kb文件的延迟性能
fio --name=4krandread_lat --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=sync --direct=1 --randrepeat=0 --norandommap --rw=randread --group_reporting --runtime=10
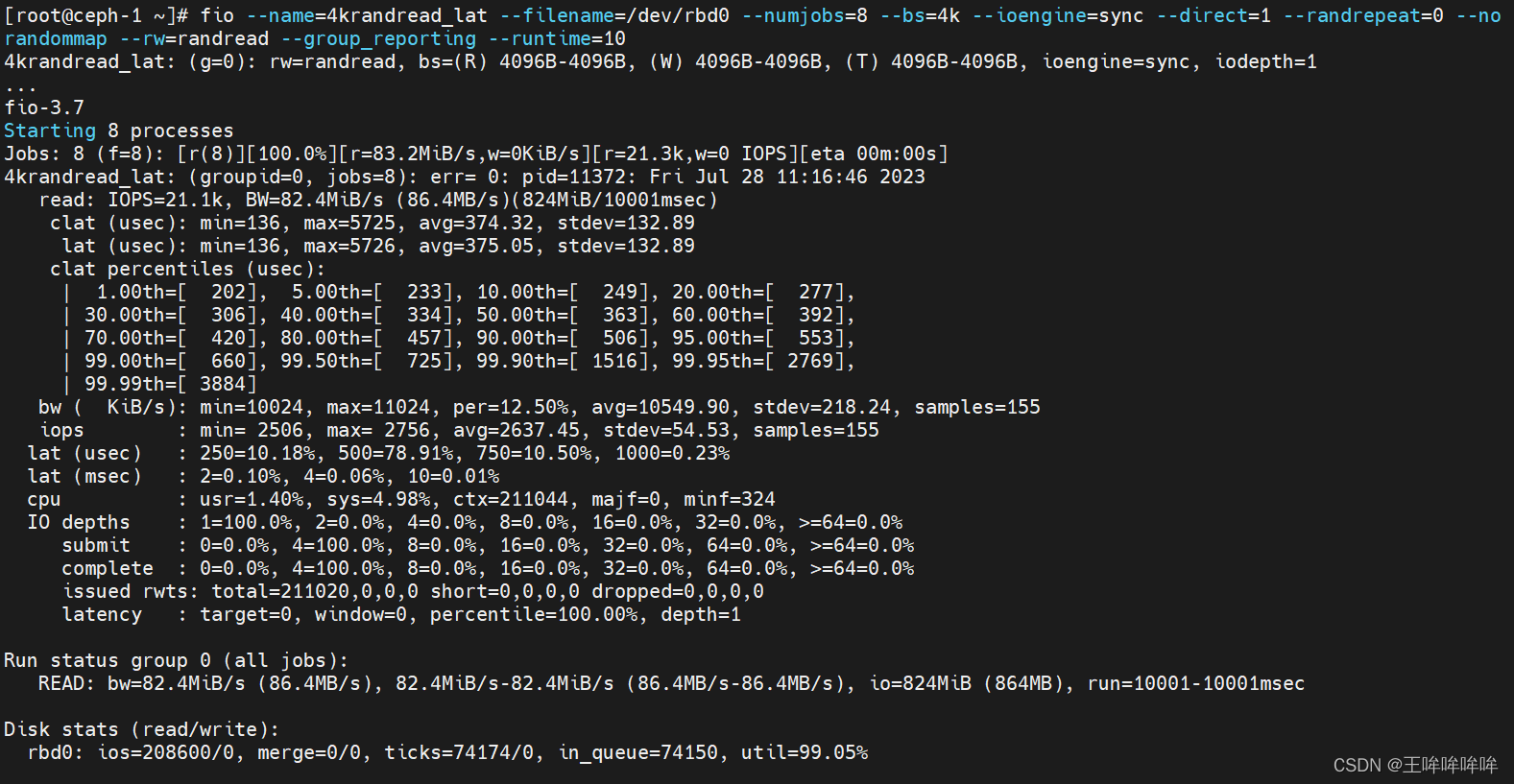
测试ceph rbd设备随机写4kb文件的延迟性能
fio --name=4krandwrite_lat --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=sync --direct=1 --randrepeat=0 --norandommap --rw=randwrite --group_reporting --runtime=10
性能调优
CPU调优:
ceph是使用软件定义的存储,因此其性能很大程度上依赖于OSD节点的CPU速度。CPU主频越高,则运行代码的速度就越快,同时处理io请求的时间就越短。
磁盘调优:
在磁盘参数和硬件配置相同的情况下,大量的io请求会向ceph osd写入数据,同时会向其他osd节点写入数据副本。如果OSD节点数量过少,那么会导致性能不高,因此增加osd数量,在某种程度上能提升写操作性能。
系统配置参数调优:
设置磁盘的预读缓存:【该参数通过预读取数据并将其加载到随机存取存储器中加快磁盘读操作,设置为较高的值有助于客户端顺序读取操作】
echo "8192" > /sys/block/vdc/queue/read_ahead_kb
设置系统的进程数量
echo 4194303 > /proc/sys/kernel/pid_max
ceph集群的配置参数:
为集群定义内部网络:
[global]
cluster network = {cluster network/netmask}
设置最大文件打开数:
[global]
max open files = 131072
ceph启用rbd缓存,默认的缓存机制是write-back
[client]
rbd cache = true
rbd cache size = 268435456 #rbd缓存大小
rbd cache max dirty = 134217728 #rbd缓存脏数据最大字节数,超过这个值之后,数据会写回备用存储。如果这个值设置为0,那么ceph使用的缓存模式是write-through
为了创建一个一致的提交操作,文件系统需要先静默写操作,并执行一次sync操作。然后将日志中的数据写到数据分区,再释放日志。如果同步操作太频繁,会导致日志中存放的数据很少,日志没有得到重复的利用。配置不那么频繁的同步操作,将有助于文件系统更好的合并写操作。有助于提升性能。
下面的参数定义了两次同步之间最小和最大的时间间隔。
[OSD]
filestore min sync interval = 10
filestore max sync interval = 15
文件存储队列的最大操作数:
[OSD]
filestore queue max ops = 25000
filestore queue max bytes = 10485760 #每个操作的最大字节数
文件系统最大操作线程数:
[OSD]
filestore op threads = 32
其他的一些参数有:
关于journal的参数:
比如可以设置一次性写入的最大字节数 journal max write bytes 、
一次性在队列中的操作数 journal queue max ops等
关于osd config tuning:
osd一次可写入的最大值,osd max write size
osd进程的最大线程数,osd op threads
关于osd client tuning:
rbd 缓存大小,rbd cache size
具体参数描述可以参考文章。
相关文章:
ceph集群中RBD的性能测试、性能调优
文章目录 rados benchrbd bench-write测试工具Fio测试ceph rbd块设备的iops性能测试ceph rbd块设备的带宽测试ceph rbd块设备的延迟 性能调优 rados bench 参考:https://blog.csdn.net/Micha_Lu/article/details/126490260 rados bench为ceph自带的基准测试工具&am…...

texshop mac中文版-TeXShop for Mac(Latex编辑预览工具)
texshop for mac是一款可以在苹果电脑MAC OS平台上使用的非常不错的Mac应用软件,texshop for mac是一个非常有用的工具,广泛使用在数学,计算机科学,物理学,经济学等领域的合作,这些程序的标准tetex分布特产…...
简单认识redis高可用实现方法
文章目录 一、redis群集三种模式二、 Redis 主从复制1、简介2、作用:3、流程:4.配置主从复制 三、Redis 哨兵模式1、简介2、原理:3、作用:4、哨兵结构由两部分组成,哨兵节点和数据节点:5、故障转移机制:6、…...

搭建git服务器
1.创建linux账户,创建文件 adduser git passwd gitpsw su git pwd cd ~/ mkdir .ssh cd ~/.ssh touch authorized_keys 2.特别重要(单独起一行),给文件设权限 chmod 700 /home/git/.ssh chmod 600 /home/git/.ssh/authorized_keys 3.本地生产密钥并把…...

线程中断机制
如何中断一个线程? 首先一个线程不应该由其他线程来强制中断或者停止,而是应该由线程自己自行停止。所以我们看到线程的stop()、resume()、suspend()等方法已经被标记为过时了。 其次在java中没有办法立即停止一个线程,然而停止线程显得尤为重…...

CollectionUtils工具类的使用
来自:小小程序员。 本文仅作记录 org.apache.commons.collections包下的CollectionUtils工具类,下面说说它的用法: 一、集合判空 通过CollectionUtils工具类的isEmpty方法可以轻松判断集合是否为空,isNotEmpty方法判断集合不为…...

基于Nonconvex规划的配电网重构研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
yolo系列笔记(v4-v5)
YOLOv4 YOLOv4网络详解_哔哩哔哩_bilibili 网络结构,在Yolov3的Darknet的基础上增加了CSP结构。 CSP的优点: 加强CNN的学习能力 去除计算瓶颈。 减少显存的消耗。 结构为: 、 其实还是类似与残差网络的结构,保留下采样之前…...

小白如何高效刷题Leetcode?
文章目录 为什么会有这样的现象?研究与学习人生而有别 如何解决困境?1. 要补的:化抽象为具体,列举找规律2. 要补的:前人总结的套路3. 与人交流探讨4. 多写总结文章 总结 明明自觉学会了不少知识,可真正开始…...
使用IDEA打jar包的详细图文教程
1. 点击intellij idea左上角的“File”菜单 -> Project Structure 2. 点击"Artifacts" -> 绿色的"" -> “JAR” -> Empty 3. Name栏填入自定义的名字,Output ditectory 选择 jar 包目标目录,Available Elements 里右击…...
《MySQL 实战 45 讲》课程学习笔记(二)
日志系统:一条 SQL 更新语句是如何执行的? 与查询流程不一样的是,更新流程还涉及两个重要的日志模块:redo log(重做日志)和 binlog(归档日志)。 重要的日志模块:redo l…...
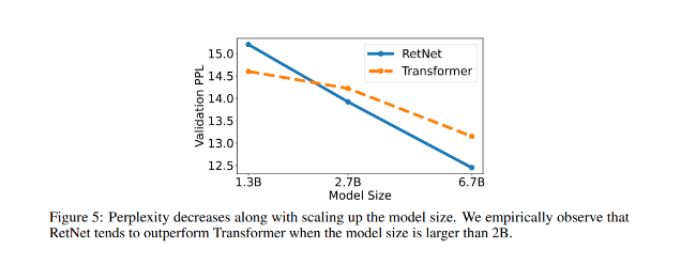
微软亚研院提出模型基础架构RetNet或将成为Transformer有力继承者
作为全新的神经网络架构,RetNet 同时实现了良好的扩展结果、并行训练、低成本部署和高效推理。这些特性将使 RetNet 有可能成为继 Transformer 之后大语言模型基础网络架构的有力继承者。实验数据也显示,在语言建模任务上: RetNet 可以达到与…...

探索单例模式:设计模式中的瑰宝
文章目录 常用的设计模式有以下几种:一.创建型模式(Creational Patterns):二.结构型模式(Structural Patterns):三.行为型模式(Behavioral Patterns):四.并发…...

Bobo String Construction 2023牛客暑期多校训练营4-A
登录—专业IT笔试面试备考平台_牛客网 题目大意:给出一字符串t,求一个长为n的字符串,使tst中包含且仅包含两个t 1<n<1000;测试样例组数<1000 思路:一开始很容易想到如果t里有1,s就全0,否则s就全…...

【React学习】React父子组件通讯
1. 父到子传值 在React框架中,父组件可以通过 props 将数据传递给子组件。子组件通过读取 props 来访问父组件传递过来的数据。 当父组件的 props 发生变化时,React 会自动重新渲染子组件以确保子组件中使用的数据保持同步。 父组件 import React, {…...

NASM汇编
1. 前置知识 1. 汇编语言两种风格 intel:我们学的NASM就属于Intel风格AT&T:GCC后端工具默认使用这种风格,当然我们也可以加选项改成intel风格 2. 代码 1. 段分布 .text: 存放的是二进制机器码,只读.data: 存放有初始化的…...
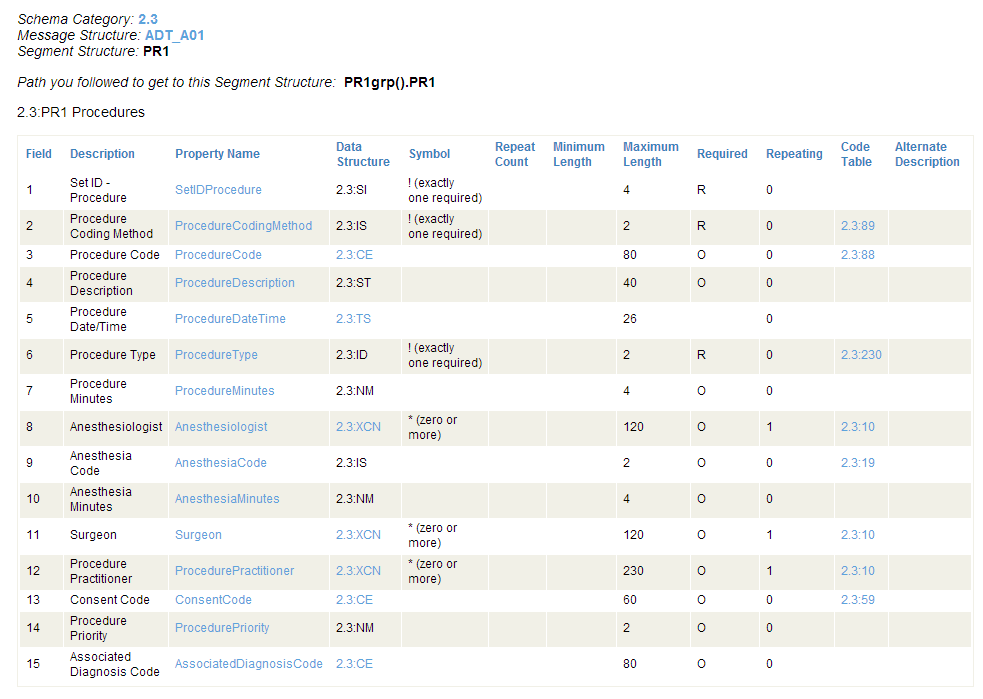
第三章 HL7 架构和可用工具 - 使用 HL7 架构结构页面
文章目录 第三章 HL7 架构和可用工具 - 使用 HL7 架构结构页面使用 HL7 架构结构页面查看文档类型列表查看消息结构查看段结构 第三章 HL7 架构和可用工具 - 使用 HL7 架构结构页面 使用 HL7 架构结构页面 通过 HL7 架构页面,可以导入和查看 HL7 版本 2 架构规范。…...
)
spring注解驱动开发(一)
1、需要导入的spring框架的依赖 <dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>4.3.12.RELEASE</version></dependency>2、Configuration 设置类为配置类 3、Annota…...
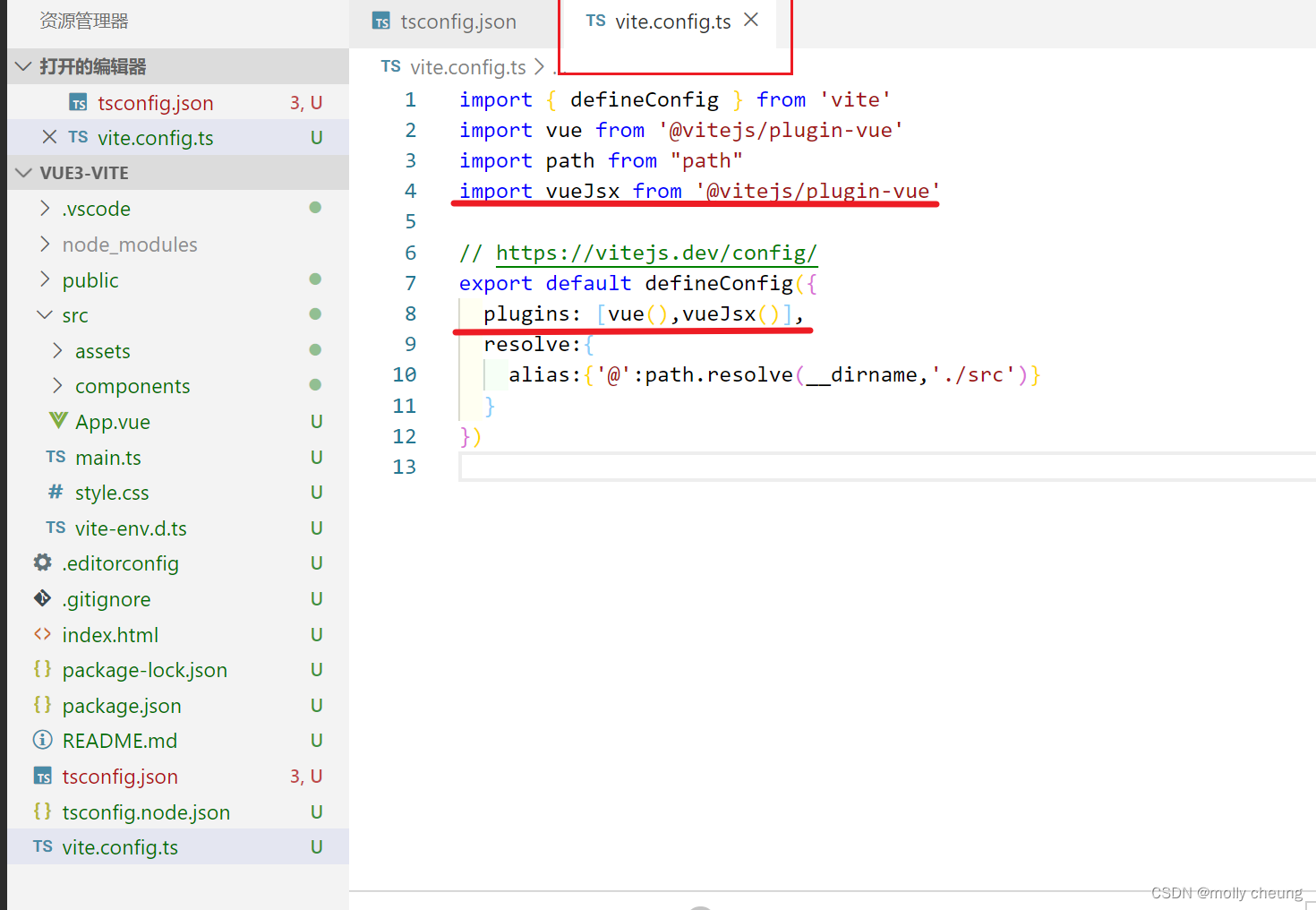
Vue3搭建启动
Vue3搭建&启动 一、创建项目二、启动项目三、配置项目1、添加编辑器配置文件2、配置别名3、处理sass/scss4、处理tsx(不用的话可以不处理) 四、添加Eslint 一、创建项目 npm create vite 1.project-name 输入项目名vue3-vite 2.select a framework 选择框架 3.select a var…...
)
阻塞队列(模拟实现)
概念 阻塞队列是带有阻塞功能的队列 特性 当队列满的时候,继续入队列,就会出现阻塞,阻塞到其他线程从队列中取走元素为止 当队列空的时候,继续出队列,也会发生阻塞,阻塞到其他线程往队列中添加元素为止 特…...

如何永久保存微信聊天记录?5分钟掌握免费开源工具WeChatMsg
如何永久保存微信聊天记录?5分钟掌握免费开源工具WeChatMsg 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/…...

独立开发者如何一站式管理多个AI项目的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何一站式管理多个AI项目的API密钥 对于独立开发者而言,同时维护多个AI应用项目是常态。每个项目可能对接不…...
MindSpore Transformers 训练任务快速上手
MindSpore Transformers(简称 MindFormers)是昇思 MindSpore 生态下的大模型训练套件,集成 BERT、GPT、LLaMA、Qwen 等主流 Transformer 模型,提供一键式预训练 / 微调、分布式并行、混合精度、监控可视化能力,适配昇腾…...

3分钟掌握MultiHighlight:让代码阅读效率提升300%的智能高亮插件
3分钟掌握MultiHighlight:让代码阅读效率提升300%的智能高亮插件 【免费下载链接】MultiHighlight Jetbrains IDE plugin: highlight identifiers with custom colors 🎨💡 项目地址: https://gitcode.com/gh_mirrors/mu/MultiHighlight …...

跨镜头人物ID稳定性不足,深度拆解Sora 2的Temporal Identity Token机制与3层对抗对齐策略
更多请点击: https://kaifayun.com 第一章:跨镜头人物ID稳定性不足的根源诊断 跨镜头人物ID稳定性不足是多目标跟踪(MOT)系统在真实监控场景中面临的核心瓶颈。其本质并非单一模块失效,而是特征表征、时空建模与数据分…...

XCOM 2模组管理器终极指南:为什么AML是你的最佳选择?
XCOM 2模组管理器终极指南:为什么AML是你的最佳选择? 【免费下载链接】xcom2-launcher The Alternative Mod Launcher (AML) is a replacement for the default game launchers from XCOM 2 and XCOM Chimera Squad. 项目地址: https://gitcode.com/gh…...

C#字节序反转:从原理到工业级实现
1. 字节序反转不是“字节倒序”,而是数据语义的精准翻转很多人第一次看到“字节序反转”这个词,下意识就去写Array.Reverse(bytes)——结果一测发现:整数读出来完全不对。我去年在做工业PLC通信协议解析时就栽过这个跟头:设备返回…...

从API调用日志看Taotoken路由容灾机制在实际波动中的表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API调用日志看Taotoken路由容灾机制在实际波动中的表现 对于依赖大模型API进行开发的团队而言,服务的稳定性是核心关…...

热门推荐:收藏!软件研发小白必看:AI转型从思维转变开始,轻松掌握大模型协作
本文探讨了软件研发团队如何进行AI转型,强调不应从购买工具或引入Agent开始,而是应首先关注个体思维的转变、团队知识底座的统一以及协作流程的重新设计。文章指出,开发者需要从关注代码实现转向关注编码前的设计、上下文组织和边界定义&…...

人像抠图用什么软件好?2026年实测9款抠图工具制作方法对比
人像抠图(背景分离)是日常生活中的常见需求——换证件照背景、制作社交媒体头像、编辑产品图等场景都离不开它。今年人像抠图的工具选择已经非常丰富,从零基础用户到专业设计师都能找到趁手的方案。本文会详细对比9款主流人像抠图工具的制作方…...