【数据结构篇C++实现】- 特殊的线性表 - 串
友情链接:C/C++系列系统学习目录
文章目录
- 串
- 🚀一、串的定义
- 🚀二、串的存储结构
- 🛴(一)串的顺序存储结构
- 1、定长顺序存储表示
- 2、堆分配存储表示
- 🛴(二)串的链式存储结构
- 3、块链存储表示
- 🚀三、串的基本操作
- 🚀四、串的模式匹配(重点)
- 🛴(一)简单的模式匹配算法
- 🛴(二)KMP算法
- 1、字符串的前缀、后缀和最大公共前后缀长度
- 2、求next数组
- 3、next数组的优化
- 4、KMP算法实现
串
🚀一、串的定义
串( string)是由零个或多个字符组成的有限序列,又名叫字符串。
- 空串:零个字符的串称为空串。
- 空格串:是只包含空格的串。注意它与空串的区别,空格串是有内容有长度的,而且可以不止一个空格。
- 子串与主串:串中任意个数的连续字符组成的子序列称为该串的子串,相应地,包含子串的串称为主串。
- 子串在主串中的位置就是子串的第一个字符在主串中的序号。
串的逻辑结构和线性表极为相似,区别仅在于串的数据对象限定为字符集。在基本操作上,串和线性表有很大差别。线性表的基本操作主要以单个元素作为操作对象,如查找、插入或删除某个元素等;而串的基本操作通常以子串作为操作对象,如查找、插入或删除一个子串等。
🚀二、串的存储结构
🛴(一)串的顺序存储结构
1、定长顺序存储表示
类似于线性表的顺序存储结构,用一组地址连续的存储单元存储串值的字符序列。在串的定长顺序存储结构中,为每个串变量分配一个固定长度的存储区,即定长数组。
#define MAXLEN 255 //预定义最大串长为255
typedef struct{char ch[MAXLEN]; //每个分量存储一个字符int length; //串的实际长度
}SString;
串的实际长度只能小于等于MAXLEN,超过预定义长度的串值会被舍去,称为截断。串长有两种表示方法: 一是如上述定义描述的那样,用一个额外的变量len来存放串的长度;二是在串值后面加一一个不计入串长的结束标记字符“\0”,此时的串长为隐含值。需要遍历一下才能知道
在一些串的操作(如插入、联接等)中,若串值序列的长度超过上界MAXLEN,约定用“截断”法处理,要克服这种弊端,只能不限定串长的最大长度,即采用动态分配的方式。
2、堆分配存储表示
堆分配存储表示仍然以一组地址连续的存储单元存放串值的字符序列,但它们的存储空间是在程序执行过程中动态分配得到的。
typedef struct{char *ch; //按串长分配存储区,ch指向串的基地址int length; //串的长度
}HString;
在C语言中,存在一一个称之为“堆”的自由存储区,并用malloc()和free()函数来完成动则返回一个指向起始地址的指针,作为串的基地址,这个串由ch指针来指示;若分配失败,则返回NULL。已分配的空间可用free()释放掉。
上述两种存储表示通常为高级程序设计语言所采用。块链存储表示仅做简单介绍。
🛴(二)串的链式存储结构
3、块链存储表示
类似于线性表的链式存储结构,也可采用链表方式存储串值。由于串的特殊性(每个元素只有一个字符),在具体实现时,每个结点既可以存放一个字符, 也可以存放多个字符。每个结点称为块,整个链表称为块链结构。图(a)是结点大小为4 (即每个结点存放4个字符)的链表,最后一个结点占不满时通常用“#”补上;图(b)是结点大小为1的链表。

#define CHUNKSIZE 80 //块的大小可由用户定义
typedef struct Chunk{char ch[CHUNKSIZE];struct Chunk *next;
}Chunk;
一个结点存多少个字符才合适就变得很重要,这会直接影响着串处理的效率,需要根据实际情况做出选择。
但串的链式存储结构除了在连接串与串操作时有一定方便之外,总的来说不如顺序存储灵活,性能也不如顺序存储结构好。
🚀三、串的基本操作
-
StrAssign(&T, chars): 赋值操作。把串T赋值为 chars
-
Strcopy(&T, S): 复制操作。由串S复制得到串T。
-
StrEmpty(S): 判空操作。若S为空串,则返回TRUE,否则返回 FALSE
-
StrCompare(S,T): 比较操作。若S>T,则返回值>0;若S=T,则返回值=0;若S<T,则返回值<0。
事实上,串的比较是通过组成串的字符之间的编码来进行的,而字符的编码指的是字符在对应字符集中的序号。
-
StrEngth(S): 求串长。返回串S的元素个数
-
Substring(&Sub,S,pos,1en):求子串。用Sub返回串S的第pos个字符起长度为len的子串。
-
Concat(&T,S1,S2): 串联接。用T返回由S1和S2联接而成的新串。
-
Index(S,T): 定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置;否则函数值为0
-
Clearstring(&S): 清空操作。将S清为空串
-
Destroystring(&S): 销毁串。将串S销毁
不同的高级语言对串的基本操作集可以有不同的定义方法。在上述定义的操作中,串赋值StrAssign、串比较 StrCompare、求串长 Strength、串联接 Concat及求子串 Substring五种操作构成串类型的最小操作子集,即这些操作不可能利用其他串操作来实现;反之,其他串操作(除串清除 Clearstring和串销毁 Destroystring外)均可在该最小操作子集上实现。
例如,可利用判等、求串长和求子串等操作实现定位函数 Index(S,T)。
int Index(Sring S, String T){int i = 1, n = StrLength(S), m = StrLength(T);String sub;while(i <= n-m+1){SubString(sub, S, i, m); //取主串第i个位置,长度为m的串给subif(StrCompare(sub, T) != 0){++i;}else{return i; //返回子串在主串中的位置}}return 0; //S中不存在与T相等的子串
}
🚀四、串的模式匹配(重点)
🛴(一)简单的模式匹配算法
子串的定位操作通常称为串的模式匹配,它求的是子串(常称模式串)在主串中的位置。这里采用定长顺序存储结构,给出一种不依赖于其他串操作的暴力匹配算法。
int Index(SString S, SString T){int i = 1, j = 1;while(i <= S.length && j <= T.length){if(S.ch[i] == T.ch[j]){++i; ++j; //继续比较后继字符}else{//指针后退重新开始匹配i = i-j+2;j = 1;}}if(j > T.length){return i - T.length;}else{return 0;}
}
下图展示了模式串T = ′ a b c a c ′ 和主串S的匹配过程

简单的模式匹配算法的最坏时间复杂度为O(nm),其中n和m分别为主串和模式串的长度。
🛴(二)KMP算法
在上面的简单匹配中,每趟匹配失败都是模式后移一位再从头开始比较。而某趟已匹配相等的字符序列是模式的某个前缀,这种频繁的重复比较相当于模式串在不断地进行自我比较,这就是其低效率的根源。对于要匹配的子串T来说,“abcac”首字母“a”与后面的串“bc”中任意一个字符都不相等。那么既然要全部和主串相等,意味着子串T的首字符“a”不可能与S串的第2、3位字符相等,所以对这两位的判断是多余的
因此,可以从分析模式本身的结构着手,如果已匹配相等的前缀序列中有某个后缀正好是模式的前缀,那么就可以将模式向后滑动到与这些相等字符对齐的位置,主串i指针无须回溯,并继续从该位置开始进行比较。而模式向后滑动位数的计算仅与模式本身的结构有关,与主串无关。
KMP算法的特点就是:仅仅后移模式串,比较指针不回溯。很是牛掰。
1、字符串的前缀、后缀和最大公共前后缀长度
要了解子串的结构,首先要弄清楚几个概念:前缀、后缀和部分匹配值。前缀指除最后一个字符以外,字符串的所有头部子串;后缀指除第一个字符外,字符串的所有尾部子串;部分匹配值则为字符串的前缀和后缀的最大公共前后缀长度。下面以′ a b a b a ′ ’ ababa’′ababa′为例进行说明
- ′ a ′ 的前缀和后缀都为空集,最大公共前后缀长度为0。
- ′ a b ′ 的前缀为{ a } ,后缀为{ b } , ${ { a } } ∩ { { b } }= N U L L $,最大公共前后缀长度长度为0。
- ′ a b a ′ 的前缀为{ a , ab } , 后缀为{ a , ba } , ${ { a,ab } } ∩ { { a,ba } }= {{a}} $, 最大公共前后缀长度为1
- ′ a b a b ′ ,前缀∩后缀,{ a , a b , a b a } ∩ { b , a b , b a b } = {ab},最大公共前后缀长度为2。
- ′ a b a b a ′ ,前缀∩后缀, { a , a b , a b a , a b a b } ∩ { a , b a , a b a , b a b a } = {a,aba}, 公共元素有两个,最大公共前后缀长度长度为3。
故字符串′ a b a b a ′ 的最大公共前后缀长度为00123。这个值有什么作用呢?回到最初的问题,主串为 ′ a b a c a b c a c b a b ′,子串为 ′ a b c a c ′ 。利用上述方法容易写出子串′ a b c a c ′ 的最大公共前后缀长度为00010,将最大公共前后缀长度值写成数组形式,就得到了最大公共前后缀长度(Partial match,PM)的表。

下面用PM表来进行字符串匹配:

-
第一趟匹配过程:
发现c 与a 不匹配,前面的2个字符′ a b ′是匹配的,查表可知,最后一个匹配字符b对应的部分匹配值为0,因此按照下面的公式算出子串需要向后移动的位数:
移动位数 = 已匹配的字符数 − 失配字符上一位字符对应最大公共前后缀长度 移动位数 = 已匹配的字符数 − 失配字符上一位字符对 应 最 大 公 共 前 后 缀 长 度 移动位数=已匹配的字符数−失配字符上一位字符对应最大公共前后缀长度因为2 − 0 = 2,所以将子串向后移动2位,如下进行第二趟匹配:

-
第二趟匹配过程:
发现c 与b 不匹配,前面4个字符′ a b c a ′是匹配的,最后一个匹配字符a对应的部分匹配值为1,4 − 1 = 3 ,将子串向后移动3位,如下进行第三趟匹配:

-
第三趟匹配过程:
子串全部比较完成,匹配成功。整个匹配过程中,主串始终没有回退,故KMP算法可以在O ( n + m ) 的时间数量级上完成串的模式匹配操作,大大提高了匹配效率。
2、求next数组
使用部分匹配值时,每当匹配失败,就去找它前一个元素的部分匹配值,这样使用起来有些不方便,所以将PM表右移一位,这样哪个元素匹配失败,直接看它自己的部分匹配值即可。将上例中字符串′ a b a c ′的PM表右移一位,就得到了next数组:

移动位数 = 失配字符所在位置 − 失配字符对应的 n e x t 值。(涉及到数组,记得位置是从 0 开始的) 移动位数 = 失配字符所在位置 - 失配字符对应的next值。(涉及到数组,记得位置是从0开始的) 移动位数=失配字符所在位置−失配字符对应的next值。(涉及到数组,记得位置是从0开始的)
通过代码递推计算next 数组:
对于next的数组的计算,可以采用递推来算。根据上面的分析,我们知道如果模式串当前位置j之前有k个相同的前缀后缀,那么可以表示为next[j] = k,所以如果当模式串的p[j]跟文本串失配后,我们可以用next[j]处的字符继续和文本串匹配,相当于模式串向右移动了j - next[j]位。那么问题就来了,如何求出next[j+1]的值呢,我们还是来看例子吧:
模式串: A B C D A B C E
next值: -1 0 0 0 0 1 2 ?
索引: k j
如上所示,模式串为"ABCDABCE",且j=6, k = 2,我们有next[j] = k,这表示j位置上的字符C之前的最大前后缀长度为2,即AB。现在我们要求next[j+1]的值,
-
因为 p [ k ] = = p [ j ] p[k] == p[j] p[k]==p[j],所以 n e x t [ j + 1 ] = n e x t [ j ] + 1 = k + 1 = 3 next[j+1] = next[j] + 1 = k + 1 = 3 next[j+1]=next[j]+1=k+1=3。即字母E之前的最大前后缀长度为3,即ABC。
-
那么我们再来看 p [ k ] ! = p [ j ] p[k] != p[j] p[k]!=p[j]的情况下怎么处理,还是来看例子:
模式串: A B C D A B D E
next值: -1 0 0 0 0 1 2 ?
索引: k j
这个例子把上面例子中的第二个’C’换成了’D’,所以字符’E’前面的相同后缀就不再是3了,所以我们希望在k前面找出个k’位置,使得p[k’]为D,这样 n e x t [ j + 1 ] = k ′ + 1 next[j+1] = k' +1 next[j+1]=k′+1,但是这个例子中不存在这样的’D’,所以next[j+1] = 0。
- 我们再看一个能在前缀中找到’D’的例子:
模式串: D A B C D A B D E
next值: -1 0 0 0 0 1 2 3 ?
索引: k j
这个例子上面例子的最前面加上了个’D’,此时j = 7, k = 3了,我们有next[j] = k,这表示j位置上的字符D之前的最大前后缀长度为3,即DAB。要求next[j+1]的值,我们发现此时 p [ k ] ! = p [ j ] p[k] != p[j] p[k]!=p[j],然后我们寻找k’或者直接让 k = n e x t [ k ] = 0 k = next[k] = 0 k=next[k]=0,此时p[0]是D,那么 n e x t [ j + 1 ] = k + 1 = 1 next[j+1] = k + 1 = 1 next[j+1]=k+1=1了,这说明字母E之前的最大前后缀长度为1,即D。综上所述,我们可以写出next的生成函数如下:
vector<int> getNext(string p) {int n = p.size(), k = -1, j = 0;vector<int> next(n, -1);while (j < n - 1) {if (k == -1 || p[j] == p[k]) { //P[J]表示后缀的单个字符,P[K]表示前缀的单个字符,匹配成功++k; ++j;next[j] = k; //第一步就是next[1] = 0,每匹配成功一个就加一} else {k = next[k]; //如果匹配失败}}return next;
}
3、next数组的优化
上面这种计算next数组的方式可以进一步的优化,可以优化的原因是因为上面的方法存在一个小小的问题,如果用这种方法求模式串ABAB,会得到next数组为[-1 0 0 1],我们用这个模式串去匹配ABACABABC:
ABACABABC
ABAB
我们会发现C和B失配,那么根据上面的规则,我们要向右移动j - next[j] = 3 - 1 = 2位,于是有:
ABACABABCABAB
右移2位后,b又跟c失配。事实上,因为在上一步的匹配中,已经得知p[3] = b,与s[3] = c失配,而右移两位之后,让p[ next[3] ] = p[1] = b 再跟s[3]匹配时,必然失配。问题出在哪呢?原因是当p[j] != s[i]时,下一步要用 p [ n e x t [ j ] ] 和 s [ i ] p[next[j]]和s[i] p[next[j]]和s[i]去匹配,而如果 p [ j ] = = p [ n e x t [ j ] ] p[j] == p[next[j]] p[j]==p[next[j]]了,再用 p [ n e x t [ j ] ] 和 s [ i ] p[next[j]]和s[i] p[next[j]]和s[i]去匹配必然会失配。所以我们要避免出现 p [ j ] = = p [ n e x t [ j ] ] p[j] == p[next[j]] p[j]==p[next[j]]的情况,一旦出现了这种情况,我们可以再次递归, n e x t [ j ] = n e x t [ n e x t [ j ] ] next[j] = next[next[j]] next[j]=next[next[j]],修改后的代码如下:
vector<int> getNext(string p) {int n = p.size(), k = -1, j = 0;vector<int> next(n, -1);while (j < n - 1) {if (k == -1 || p[j] == p[k]) { //P[J]表示后缀的单个字符,P[K]表示前缀的单个字符++k; ++j;next[j] = (p[j] != p[k]) ? k : next[k];} else {k = next[k];}}return next;
}
4、KMP算法实现
当想要在C++中实现KMP算法进行字符串匹配时,可以按照以下步骤进行:
- 构建next数组:计算模式串的前缀表,用于在不匹配时快速移动模式串。
- 使用KMP算法进行字符串匹配。
#include <iostream>
#include <vector>
#include <string>// 构建next数组
vector<int> getNext(string p) {int n = p.size(), k = -1, j = 0;vector<int> next(n, -1);while (j < n - 1) {if (k == -1 || p[j] == p[k]) { //P[J]表示后缀的单个字符,P[K]表示前缀的单个字符++k; ++j;next[j] = (p[j] != p[k]) ? k : next[k];} else {k = next[k];}}return next;
}// 使用KMP算法进行字符串匹配
int kmpSearch(const std::string& text, const std::string& pattern) {int n = text.size();int m = pattern.size();std::vector<int> next = getNext(pattern);int i = 0;int j = 0;while (i < n) {if (j == -1 || text[i] == pattern[j]) {++i;++j;if (j == m) {return i - j; // 匹配成功,返回匹配的起始位置}} else {j = next[j];}}return -1; // 未找到匹配的子串
}int main() {std::string text = "ABABDABACDABABCABAB";std::string pattern = "ABABCABAB";int index = kmpSearch(text, pattern);if (index != -1) {std::cout << "在位置 " << index << " 处找到匹配的子串" << std::endl;} else {std::cout << "未找到匹配的子串" << std::endl;}return 0;
}
相关文章:
【数据结构篇C++实现】- 特殊的线性表 - 串
友情链接:C/C系列系统学习目录 文章目录 串🚀一、串的定义🚀二、串的存储结构🛴(一)串的顺序存储结构1、定长顺序存储表示2、堆分配存储表示 🛴(二)串的链式存储结构3、块…...

DevOps系列文章 之 Springboot单元测试
在没有代码生成工具或尝试一门新的 ORM框架时,当我们希望不去另外写 Service 和 Controller 来验证 DAO 层的代码不希望只通过接口请求的方式来验证时,这时候单元测试的方式就可以帮助我们满足这一需求。 在我们开发Web应用时,经常会直接去观…...
04 linux之C 语言高级编程
gcc和gdb GNU工具 编译工具:把一个源程序编译为一个可执行程序调试工具:能对执行程序进行源码或汇编级调试软件工程工具:用于协助多人开发或大型软件项目的管理,如make、CVS、Subvision其他工具:用于把多个目标文件链…...

深入学习 Redis - Stream、Geospatial、HyperLogLog、Bitmap、Bitfields 类型扩展
目录 前言 Stream geospatial HyperLogLog Bitmaps Bitfields 前言 redis 中最关键的五个数据类型 String、List、Hash、Set、Zset 应用最广泛,同时 redis 也推出了额外的 5 个数据类型,他们分别是针对特殊场景才进行的应用的. Ps:这几种…...

Windows11+Opencv+Clion编译源码
Windows11OpencvClion编译源码 参考:https://www.robotsfan.com/posts/69395e08.html 注意事项 编译过程中使用的软件,开源码等所有工具的安装路径一定不要有中文和空格。cmake过程会下载一些文件,如果是局域网的话可能下载不下来…...
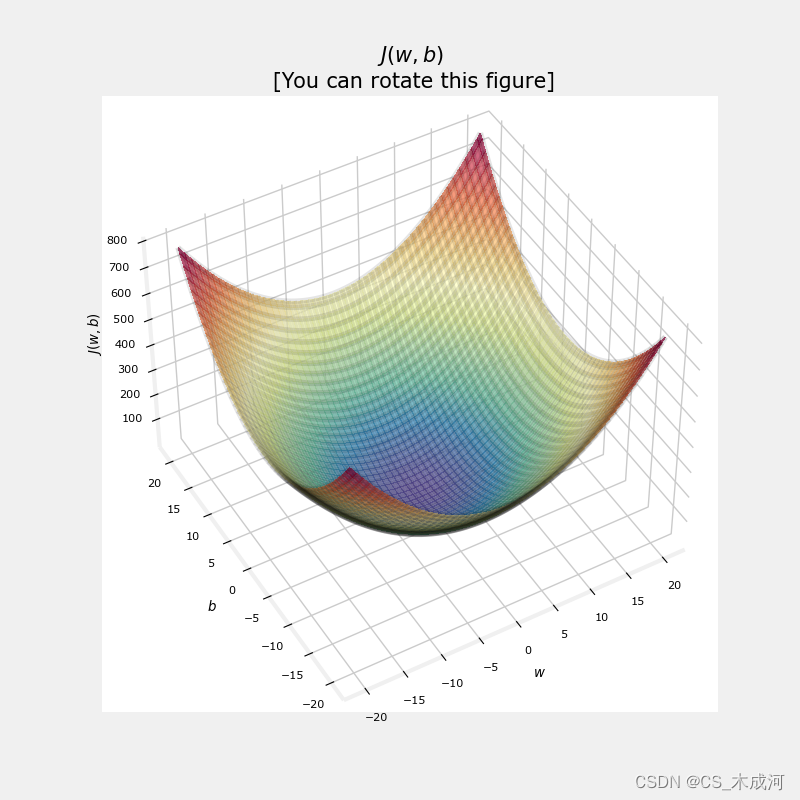
【机器学习】Cost Function
Cost Function 1、计算 cost2、cost 函数的直观理解3、cost 可视化总结附录 首先,导入所需的库: import numpy as np %matplotlib widget import matplotlib.pyplot as plt from lab_utils_uni import plt_intuition, plt_stationary, plt_update_onclic…...
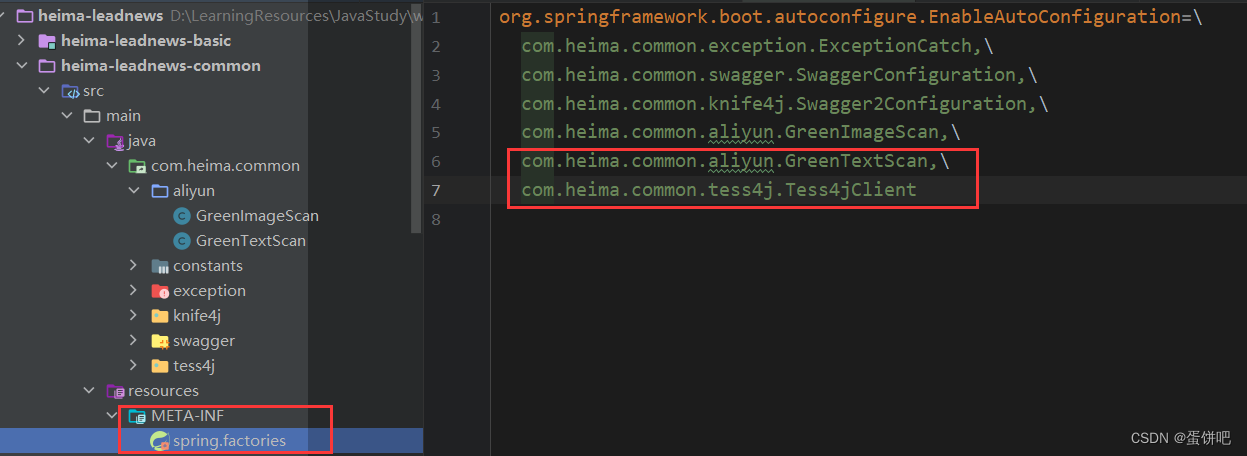
【黑马头条之内容安全第三方接口】
本笔记内容为黑马头条项目的文本-图片内容审核接口部分 目录 一、概述 二、准备工作 三、文本内容审核接口 四、图片审核接口 五、项目集成 一、概述 内容安全是识别服务,支持对图片、视频、文本、语音等对象进行多样化场景检测,有效降低内容违规风…...

回归预测 | MATLAB实现GRNN广义回归神经网络多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现GRNN广义回归神经网络多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现GRNN广义回归神经网络多输入单输出回归预测(多指标,多图)效果一览基本介绍程序设计参考资料效果一览 基本介绍 MATLAB实现GRNN广义回归神经网络多输入单输出回归…...
详解)
STM32 HAL库函数——HAL_UART_RxCpltCallback()详解
HAL_UART_RxCpltCallback函数 他是谁,他和谁有关功能用法每收到一个字符,就自动调用一次??示例----接收未知长度的字符 他是谁,他和谁有关 HAL_UART_RxCpltCallback 是一个回调函数,用于在使用 HAL 库进行…...
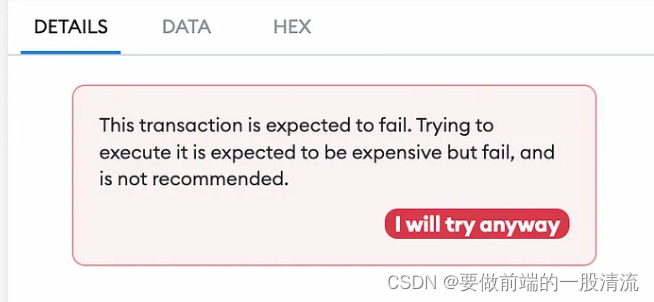
前端调用合约如何避免出现transaction fail
前言: 作为开发,你一定经历过调用合约的时候发现 gas fee 超出限制,但是不知道报了什么错。这个时候一般都是触发了require错误合约校验。对于用户来说他不理解为什么一笔交易会花费如此大的gas,那我们作为开发如何尽量避免这种情…...

选择器的使用
目录 层级选择器属性选择器伪类选择器结构伪类选择器目标伪类选择器 层级选择器 /*子代选择器:选出box下的所有li标签*/.box>li{background-color: aliceblue;}/* 选出box后面的第一个兄弟li标签 */.boxli{background-color: aliceblue;}/* 选出box后面的所有兄…...

软考A计划-系统集成项目管理工程师-项目干系人管理-上
点击跳转专栏>Unity3D特效百例点击跳转专栏>案例项目实战源码点击跳转专栏>游戏脚本-辅助自动化点击跳转专栏>Android控件全解手册点击跳转专栏>Scratch编程案例点击跳转>软考全系列点击跳转>蓝桥系列 👉关于作者 专注于Android/Unity和各种游…...
F5 LTM 知识点和实验 2-负载均衡基础概念
第二章:负载均衡基础概念 目标: 使用网页和TMSH配置virtual servers,pools,monitors,profiles和persistence等。查看统计信息 基础概念: Node一个IP地址。是创建pool池的基础。可以手工创建也可以自动创…...
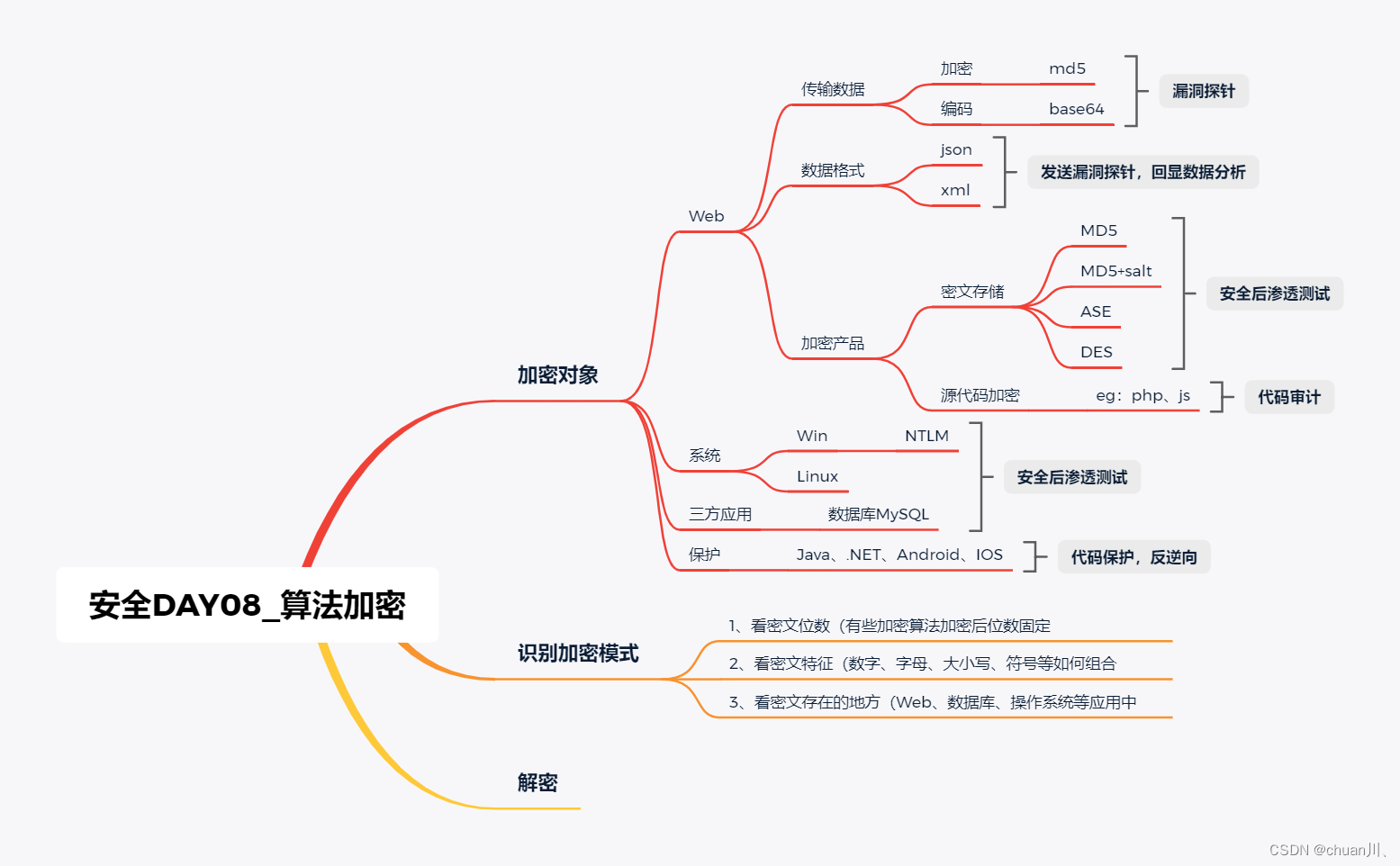
安全学习DAY08_算法加密
算法加密 漏洞分析、漏洞勘测、漏洞探针、挖漏洞时要用到的技术知识 存储密码加密-应用对象传输加密编码-发送回显数据传输格式-统一格式代码特性混淆-开发语言 传输数据 – 加密型&编码型 安全测试时,通常会进行数据的修改增加提交测试 数据在传输的时候进行…...

OpenCloudOS 与PolarDB全面适配
近日,OpenCloudOS 开源社区签署阿里巴巴开源 CLA (Contribution License Agreement, 贡献许可协议), 正式与阿里云 PolarDB 开源数据库社区牵手,并展开 OpenCloudOS (V8)与阿里云开源云原生数据库 PolarDB 分布式版、开源云原生数…...

如何在Linux系统中使用yum命令安装MySQL
1、安装软件 # yum install -y https://repo.mysql.com//mysql80-community-release-el7-8.noarch.rpm # yum -y install mysql-community-server网址来源:https://dev.mysql.com/downloads/repo/yum/ 2、启动软件 # systemctl enable mysqld# systemctl start my…...
在Ail Linux中手动配置IPv6
第一步,登录阿里云服务器控制台,在“概览”页面找到对应实例,然后单击实例ID。 第二步,在“实例详情”页面中的“网络信息”栏目中,可以发现“IPv6 地址”中没有数据,然后单击“专有网络”的专有网络ID。 第…...
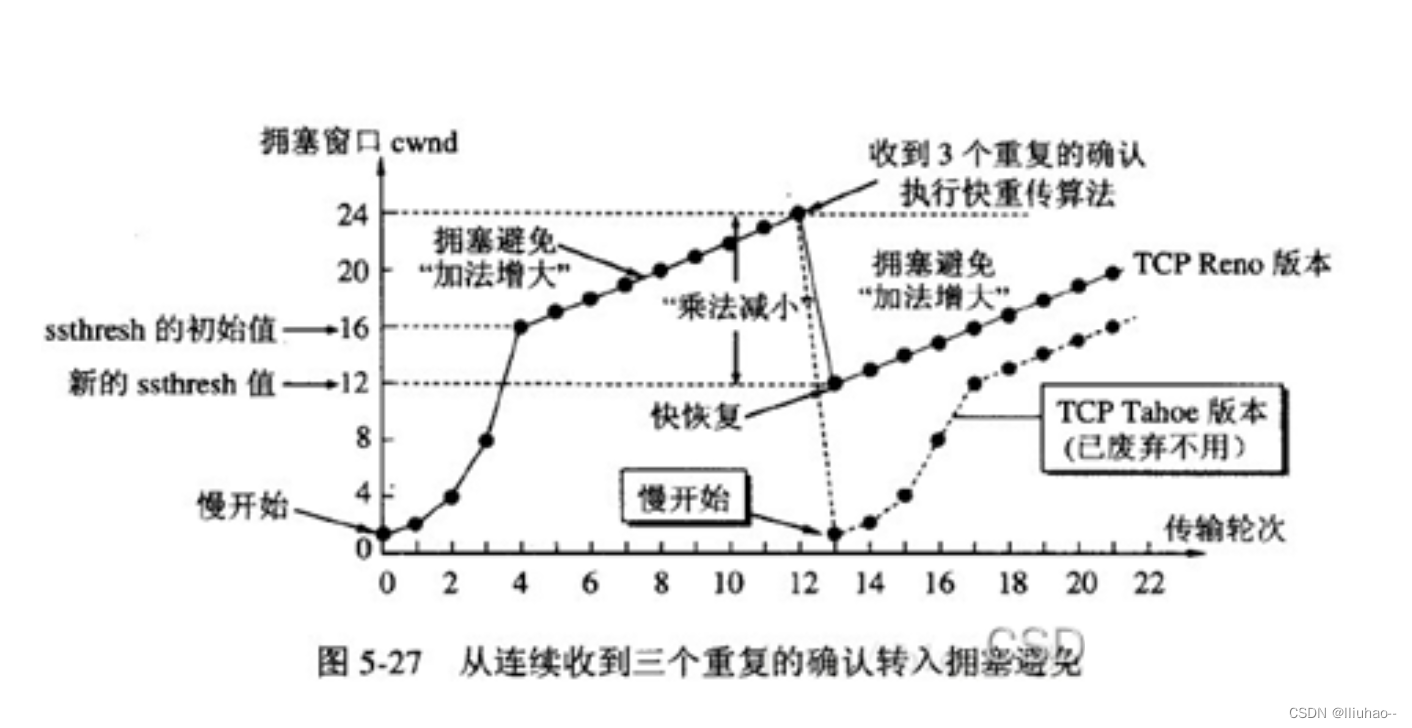
TCP如何保证服务的可靠性
TCP如何保证服务的可靠性 确认应答超时重传流量控制滑动窗口机制概述发送窗口和接收窗口的工作原理几种滑动窗口协议1比特滑动窗口协议(停等协议)后退n协议选择重传协议 采用滑动窗口的问题(死锁可能,糊涂窗口综合征)死…...

【云原生系列】openstack搭建过程及使用
目录 搭建步骤 准备工作 正式部署OpenStack 安装的过程 安装组件如下 登录页面 进入首页 创建实例步骤 上传镜像 配置网络 服务器配置 dashboard配置 密钥配置免密登录 创建实例 绑定浮动ip 免密登录实例 搭建步骤 准备工作 1.关闭防火墙和网关 systemctl dis…...

无涯教程-jQuery - Menu组件函数
小部件菜单功能可与JqueryUI中的小部件一起使用。一个简单的菜单显示项目列表。 Menu - 语法 $( "#menu" ).menu(); Menu - 示例 以下是显示菜单用法的简单示例- <!doctype html> <html lang"en"><head><meta charset"utf-…...
)
告别虚拟机!用WSL2自带的SSH服务连接VSCode远程开发(附端口冲突解决)
告别虚拟机!用WSL2自带的SSH服务连接VSCode远程开发(附端口冲突解决) 在Windows系统上进行Linux开发时,传统虚拟机方案往往显得笨重且资源占用高。WSL2的出现彻底改变了这一局面,它提供了近乎原生的Linux内核体验&…...

如何用Python自动化脚本高效抢购热门演出门票?智能抢票解决方案揭秘
如何用Python自动化脚本高效抢购热门演出门票?智能抢票解决方案揭秘 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 还在为热门演唱会门票秒光而烦恼吗࿱…...

如何快速解锁百度网盘资源:baidupankey智能查询工具终极指南
如何快速解锁百度网盘资源:baidupankey智能查询工具终极指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次遇到需要提取码的资源,都要在多个…...

突破语言壁垒:AI驱动视频学习工具LLPlayer完全指南
突破语言壁垒:AI驱动视频学习工具LLPlayer完全指南 【免费下载链接】LLPlayer The media player for language learning, with dual subtitles, AI-generated subtitles, real-time translation, and more! 项目地址: https://gitcode.com/gh_mirrors/ll/LLPlayer…...

在数据分析和报告自动化场景中集成Taotoken调用大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在数据分析和报告自动化场景中集成Taotoken调用大模型 数据分析与报告生成是许多团队日常工作中的高频任务。传统流程中࿰…...

Soundcore Liberty 5 Pro系列耳塞:价格升级功能多样,通话降噪表现超出色!
产品线内差异:耳塞相同,充电盒不同此前,Soundcore价格最高的耳塞(不包括睡眠耳塞)是售价150美元的Liberty 4 Pro,但Liberty 5 Pro售价170美元,Liberty 5 Pro Max售价230美元,这已经进…...

科技中介机构如何提升服务效率与转化率?
观点作者:科易网-国家科技成果转化(厦门)示范基地 在数智化浪潮席卷全球的今天,科技创新正经历着一场深刻的变革。数据已成为关键生产要素,重塑着创新主体间的关系,也催生了全新的科技成果转化模式。在这一…...

大麦网API签名机制解析:从抓包到Python复现全流程
1. 这不是“破解”,而是理解前端签名机制的常规技术推演大麦网的API接口在请求时普遍要求携带一个名为sign的参数,该参数并非固定值,而是由请求体、时间戳、密钥、随机串等多要素动态拼接后经哈希算法生成。很多初学者看到这个字段第一反应是…...

2026 渗透测试行业全景解析|机遇、挑战与未来趋势
随着数字化转型的深入和网络威胁的日益复杂化,网络安全渗透测试行业在2025年迎来了前所未有的发展机遇与挑战。本文基于最新行业数据、招聘趋势与技术演进,全面剖析当前渗透测试行业的市场规模、人才供需、薪资水平、技术变革及未来发展方向,…...

2026.5.12【芯片设计面试经验分享】上海车载芯片设计公司
一、主管面试 1、介绍下负责的cpu的九级流水线都有哪级? 指令预取、PC取指、指令译码、发射(双发射)、执行1(alu、运算)、执行2(乘法、移位)、访存、写回、提交/重排 2、负责的spyglass cdc 一般…...