使用TensorFlow训练深度学习模型实战(下)
大家好,本文接TensorFlow训练深度学习模型的上半部分继续进行讲述,下面将介绍有关定义深度学习模型、训练模型和评估模型的内容。
定义深度学习模型
数据准备完成后,下一步是使用TensorFlow搭建神经网络模型,搭建模型有两个选项:
可以使用各种层,包括Dense、Conv2D和LSTM,从头开始搭建模型。这些层定义了模型的架构及数据流经过它的方式,可基于TensorFlow Hub提供的预训练模型搭建模型。这些模型已经在大型数据集上进行了训练,并可以在特定数据集上进行微调,以达到在较短的训练时间内达到较高的准确度。
可以根据TensorFlow Hub中的预训练模型来建立模型。这些模型已经在大型数据集上进行了训练,并且可以在你的特定数据集上进行微调,以达到较少的训练时间,达到较高的准确性。
-
从头开始定义深度学习模型
TensorFlow中的tf.keras.Sequential函数允许我们逐层定义神经网络模型,我们可以选择各种层,如Dense、Conv2D和LSTM,来搭建定制的模型架构。以下是示例:
# 定义模型架构
model = tf.keras.Sequential([tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),tf.keras.layers.MaxPooling2D(),tf.keras.layers.Flatten(),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(10)
])在这个示例中,我们定义了一个模型,包含以下六个层(4个隐藏层):
-
Conv2D层,具有32个过滤器,3x3的内核大小和ReLU激活。此层以形状为(28,28,1)的输入图像作为输入。
-
MaxPooling2D层,具有默认的2x2池大小。此层对从上一层获得的特征映射进行下采样。
-
Flatten层,将2D特征映射展平为1D向量。
-
Dense层,具有128个神经元和ReLU激活。此层对展平的特征映射执行完全连接操作。
-
Dropout层,在训练期间随机丢弃50%的连接以防止过拟合。
-
Dense层,具有十个神经元,无激活函数。此层表示模型的输出层,神经元的数量对应于分类任务中的类别数目。
这个模型遵循典型的卷积神经网络架构,包括多个卷积层和池化层,以及一个或多个全连接层。
- 从预训练模型定义深度学习模型
利用TensorFlow Hub提供的预训练模型可能是一个不错的选择,因为它们已经在大量的数据集上进行了训练,可以帮助在减少训练时间的同时实现高准确度。在实现任何这些模型之前,让我们先了解一些TensorFlow Hub提供的常见预训练模型。
-
VGG:The Visual Geometry Group(VGG)模型是由牛津大学开发的。这些模型广泛用于图像分类任务,并在各种基准数据集上取得了最先进的结果。
-
ResNet:The Residual Network(ResNet)模型是由微软研究院开发的。这些模型具有独特的架构,可以训练非常深的神经网络(高达1000层)。
-
Inception:Inception模型是由Google开发的。这些模型具有独特的架构,使用不同尺度的多个并行卷积,Inception模型广泛用于目标检测和图像分类任务。
-
MobileNet:MobileNet模型是由Google开发的。这些模型具有针对移动设备和嵌入式设备进行优化的独特架构,MobileNet模型广泛用于移动设备上的图像分类和目标检测任务。
可以通过向预训练模型添加额外层并在特定数据集上训练模型来应用迁移学习。与从头开始训练模型相比,这种技术可以节省大量时间和计算资源。但是,在选择预训练模型并将数据集转换为该格式以确保兼容之前,了解预训练模型所需的输入格式非常重要。
在这个示例中,MobileNet模型被作为基本模型使用。在使用基本模型之前,检查模型所需的格式非常重要, 在本示例中,格式为(224,224,3)。然而,MNIST数据集是一个灰度图像,大小为(28,28,1),其中单个值表示像素的亮度。图像大小也比所需的格式要小得多。因此,需要重新调整数据集。以下是调整大小的主要思路:
使用image.resize函数将图像调整为所需的大小。该函数使用双线性插值来保留原始图像中的信息,同时将其调整为新大小。因此,此步骤可以将原始形状(28,28,1)调整为(224,224,1)的形状。
使用image.grayscale_to_rgb函数将图像转换为新的RGB图像,通过将单个灰度通道复制到新的RGB图像的所有三个通道中,从而将原始形状(224,224,1)调整为(224,224,3)的形状。
# 调整输入图像的大小为224x224,并将其转换为三通道的RGB图像
X_train = tf.image.grayscale_to_rgb(tf.image.resize(X_train, [224, 224]))
X_test = tf.image.grayscale_to_rgb(tf.image.resize(X_test, [224, 224]))现在让我们基于MobileNet模型定义我们的模型:
# 加载MobileNet模型,不包括顶层
base_model = MobileNet(include_top=False, input_shape=(224, 224, 3))# 添加一个全局平均池化层和一个全连接输出层
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(10, activation='softmax')(x)# 将基础模型和新层结合起来,创建完整的模型
model = tf.keras.models.Model(inputs=base_model.input, outputs=x)# 冻结基础模型中的各层
for layer in base_model.layers:layer.trainable = False在上面的示例中,我们定义了一个模型,如下所示:
-
使用
MobileNet()定义基本模型 -
GlobalAveragePooling2D层,使用基本模型的最后一个卷积层的输出,计算每个特征映射的平均值,从而得到一个固定长度的向量,总结了特征映射中的空间信息。
-
Dropout层,在训练期间随机丢弃50%的连接以防止过拟合。
-
Dense层,使用十个单元的完全连接层和
softmax激活。它接收来自上一层的输出并生成覆盖十个可能类别的概率分布。
编译和训练模型
在创建模型之后,必须通过指定在训练期间使用的损失函数、优化器和指标来编译它。以下是一个编译模型的示例代码:
# 编译该模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])由于这是一个多分类问题,因此此示例代码使用了稀疏交叉熵损失函数,我们使用的是Adam优化器和准确率指标。
在训练模型之后可以在测试集上评估它,以查看它在未见过的数据上的表现如何,以下是一个评估模型的示例代码:
# 在测试数据上评估该模型
test_loss, test_acc = model.evaluate(X_test, y_test)
print('Test loss: ', test_loss)
print('Test Acc: ', test_acc)
在此示例代码中,我们在测试集上评估模型,并输出测试损失和准确率。
进行预测
一旦训练和评估了模型,就可以使用它来预测新数据。以下是一个进行预测的示例代码:
# 对新数据进行预测
y_pred = model.predict(X_test)
y_pred_labels = np.argmax(y_pred, axis=1)
print(y_pred_labels)在此示例代码中,我们在模型上使用predict()方法对整个测试集进行预测。
如果我们想要预测单个图像并返回预测标签与真实标签,那么就需要对Keras模型的predict()方法进行更改。因为Keras模型的predict()方法期望输入数据形式为一批图像,而我们想要传递单个图像给predict()方法,所以需要将其重新调整为批次大小为1。
def predict_and_compare(model, X_test, y_test, index):# 从X_test中获取给定索引的例子example = X_test[index]# 将例子重塑为预期的输入形状example = np.reshape(example, (1, 28, 28, 1))# 预测这个例子的标签y_pred = model.predict(example)# 将预测的概率转换为类别标签y_pred_label = np.argmax(y_pred, axis=1)[0]# 使用索引从y_test获取真实标签y_test_array = y_test.values# Get the label for the first example in the test set y_true = y_test_array[index]# 输出预测的和真实的标签print("Predicted label:", y_pred_label)print("True label:", y_true)# 返回预测的和真实的标签return y_pred_label, y_true# 预测并比较测试集中第一个例子的标签
y_pred_label, y_true = predict_and_compare(model, X_test, y_test, 0)在上面的示例中,我们通过添加一个额外的维度来代表批次大小,从而将输入图像从(28,28,1)调整为(1,28,28,1)。这样,我们就可以传递单个图像给predict()方法,并获得该图像的预测结果。当我们调用上面的函数时,可以自定义要预测的图像:

这就是在TensorFlow中实现深度学习的步骤。当然,这只是一个基本示例。你可以搭建具有更多层、不同类型的层和不同超参数的更复杂的模型,以便在数据集上获得更好的性能。
综上,本文我们演示了如何对数据进行预处理、搭建和训练模型、在单独的测试集上评估其性能以及使用简单的卷积神经网络(CNN)进行图像分类的预测,通过学习可以获得如何在TensorFlow中构建深度学习模型以及如何将这些概念应用于真实世界数据集的理解。
相关文章:
使用TensorFlow训练深度学习模型实战(下)
大家好,本文接TensorFlow训练深度学习模型的上半部分继续进行讲述,下面将介绍有关定义深度学习模型、训练模型和评估模型的内容。 定义深度学习模型 数据准备完成后,下一步是使用TensorFlow搭建神经网络模型,搭建模型有两个选项…...

lucene、solr、es的区别以及应用场景
目录 1. Lucene:2. Solr:3. Elasticsearch: Lucene、Solr 和 Elasticsearch(ES) 都是基于 Lucene 引擎的搜索引擎,它们之间有相似之处,但也有一些不同之处。 Lucene 是一个低级别的搜索引擎库,它提供了一种用于创建和维护全文索引的 API&…...

Java方法的使用(重点:形参和实参的关系、方法重载、递归)
目录 一、Java方法 * 有返回类型,在方法体里就一定要返回相应类型的数据。没有返回类型(void),就不要返回!! * 方法没有声明一说。与C语言不同(C语言是自顶向下读取代码)&#…...
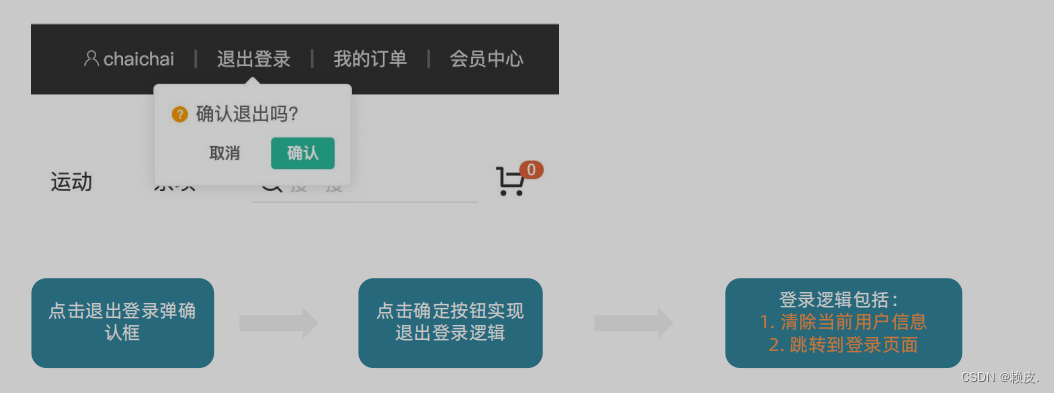
登录页的具体实现 (小兔鲜儿)【Vue3】
登录页 整体认识和路由配置 整体认识 登录页面的主要功能就是表单校验和登录登出业务 准备模板 <script setup></script><template><div><header class"login-header"><div class"container m-top-20"><h1 cl…...

大学如何自学嵌入式开发?
1. C语言:C语言是基础中的基础,刚开始学习不用太深入,一本常用的C语言的教材即可,注意不是当教科书看,而是看完一节过后,打开电脑把后面的习题都写出来,并且编译运行一遍,一定要动手…...

pytorch学习——线性神经网络——1线性回归
概要:线性神经网络是一种最简单的神经网络模型,它由若干个线性变换和非线性变换组成。线性变换通常表示为矩阵乘法,非线性变换通常是一个逐元素的非线性函数。线性神经网络通常用于解决回归和分类问题。 一.线性回归 线性回归是一种常见的机…...

00 - RAP 开发环境配置
文章目录 [1] Eclipse - ADT[2] BTP / S4HC[3] Add ABAP Env. Service[4] Conn. to BTP [1] Eclipse - ADT 关于如何安装配置,参见文章: Install ABAP Development Tools (ADT) and abapGit Plugin Eclipse Eclipse - ADT Eclipse - abapGit Plugin [2] BTP / S4…...
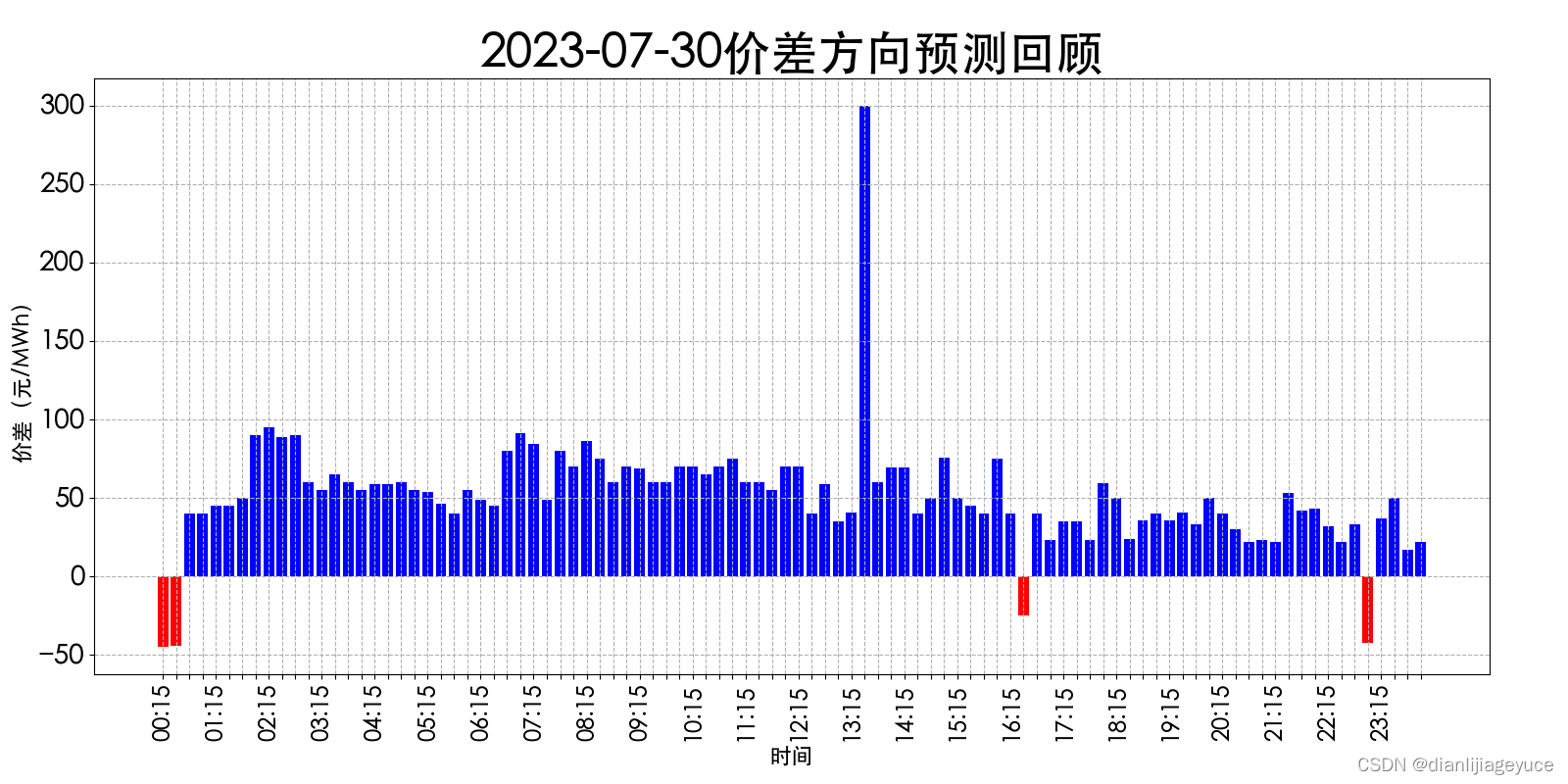
山西电力市场日前价格预测【2023-08-01】
日前价格预测 预测明日(2023-08-01)山西电力市场全天平均日前电价为310.15元/MWh。其中,最高日前电价为335.18元/MWh,预计出现在19: 45。最低日前电价为288.85元/MWh,预计出现在14: 00。 价差方向预测 1:实…...
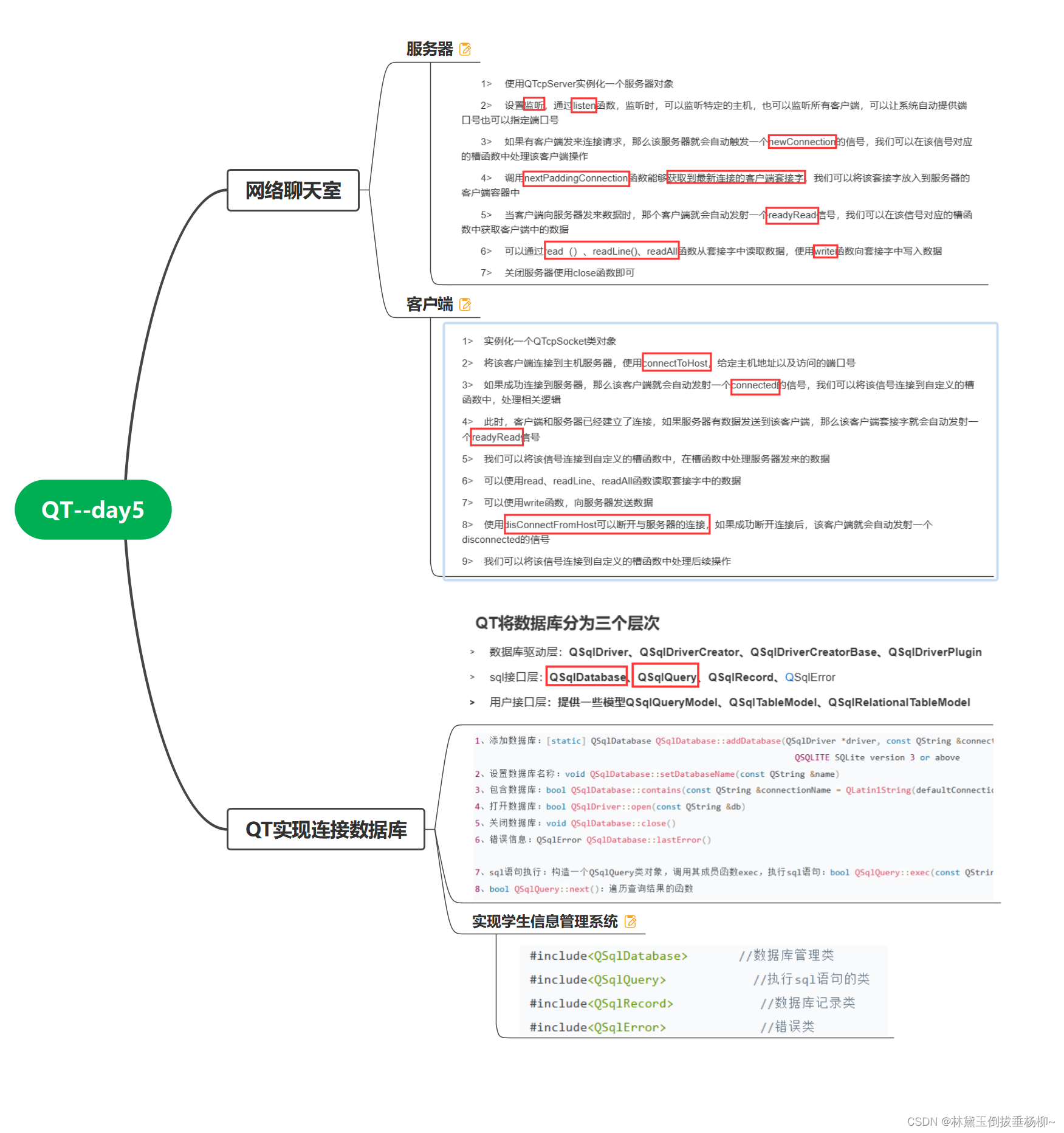
QT--day5(网络聊天室、学生信息管理系统)
服务器: #include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this);//给服务器指针实例化空间servernew QTcpServer(this); }Widget::~Widget() {delete ui; …...
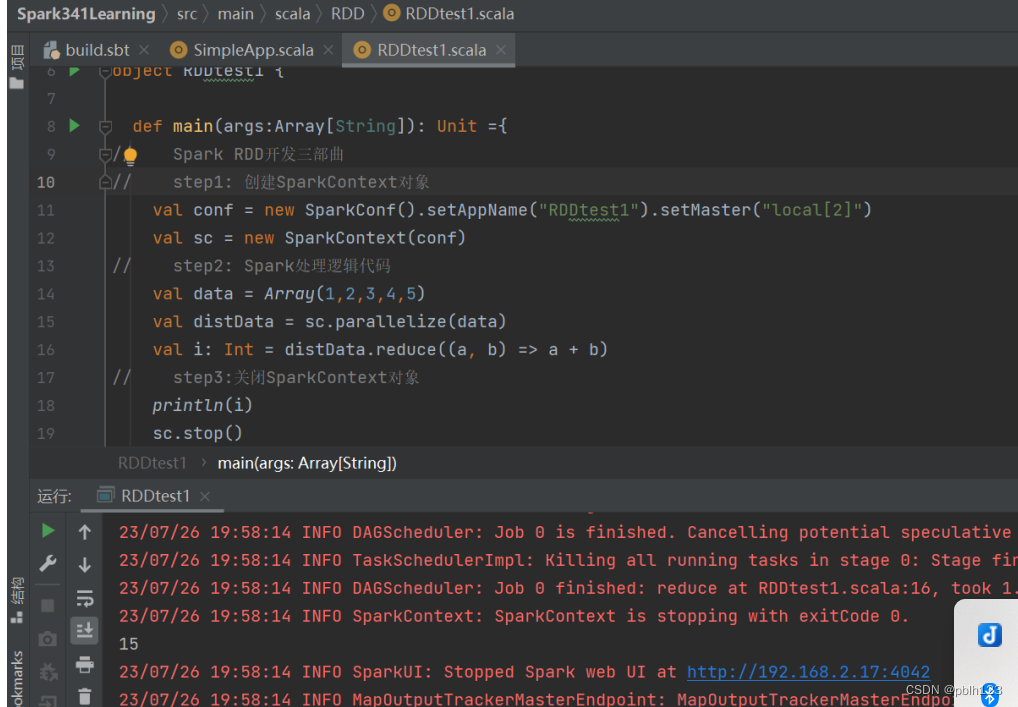
【用IDEA基于Scala2.12.18开发Spark 3.4.1 项目】
目录 使用IDEA创建Spark项目设置sbt依赖创建Spark 项目结构新建Scala代码 使用IDEA创建Spark项目 打开IDEA后选址新建项目 选址sbt选项 配置JDK debug 解决方案 相关的依赖下载出问题多的话,可以关闭idea,重启再等等即可。 设置sbt依赖 将sbt…...

HEVC 速率控制(码控)介绍
视频编码速率控制 速率控制: 通过选择一系列编码参数,使得视频编码后的比特率满足所有需要的速率限制,并且使得编码失真尽量小。速率控制属于率失真优化的范畴,速率控制算法的重点是确定与速率相关的量化参数(Quantiz…...
)
四大软件测试策略的特点和区别(单元测试、集成测试、确认测试和系统测试)
四大软件测试策略分别是单元测试、集成测试、确认测试和系统测试。 一、单元测试 单元测试也称为模块测试,它针对软件中的最小单元(如函数、方法、类、模块等)进行测试,以验证其是否符合预期的行为和结果。单元测试通常由开发人…...

ingress-nginx controller安装
文章目录 一、ingress-nginx controller安装环境 1.1 部署yaml1.2 镜像1.3 安装操作 一、ingress-nginx controller安装 环境 kubernetes版本:1.27.1操作系统:CentOS7.9 1.1 部署yaml deploy.yaml apiVersion: v1 kind: Namespace metadata:labels:…...

开源快速开发平台:做好数据管理,实现流程化办公!
做好数据管理,可以提升企业的办公协作效率,实现数字化转型。开源快速开发平台是深受企业喜爱的低代码开发平台,拥有多项典型功能,是可以打造自主可控快速开发平台,实现一对一框架定制的软件平台。在快节奏的社会中&…...
基于深度学习的裂纹图像分类研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
TypeScript入门学习汇总
1.快速入门 1.1 简介 TypeScript 是 JavaScript 的一个超集,支持 ECMAScript 6 标准。 TypeScript 由微软开发的自由和开源的编程语言。 TypeScript 设计目标是开发大型应用,它可以编译成纯 JavaScript,编译出来的 JavaScript 可以运行在…...
Vue3使用vxetable进行表格的编辑、删除与新增
效果图如下: vxetable4传送门 一、引入插件 package.json中加入"vxe-table": "4.0.23",终端中执行npm i导入import {VXETable, VxeTableInstance...

JUC 并发编程之JMM
目录 1. 内存模型JMM 1. 1 主内存和工作内存 1.2 重排序 1. 内存模型JMM Java内存模型是Java虚拟机(JVM)规范中定义的一组规则,用于屏蔽各种硬件和操作系统的内存访问差异,保证多线程情况下程序的正确执行。Java内存模型规定了…...

k8s集群中安装kibana 7.x 踩坑
1. FATAL ValidationError: child "server" fails because [child "port" fails because ["port" must be a number]] 解决办法: 在环境变量中指定端口: - name: SERVER_PORTvalue: 5601 2. Kibana FATAL Error: [elast…...

CSS的一些基础知识
选择器: 选择器用于选择要应用样式的HTML元素。常见的选择器包括标签选择器(如 div、p)、类选择器(如 .class)、ID选择器(如 #id)和伪类选择器(如 :hover)。选择器可以根…...

Triangle Splatting:可微分渲染中的三角形基元优化技术
1. Triangle Splatting:可微分渲染中的三角形基元革命在计算机图形学领域,三角形作为最基础的几何基元,长期以来一直是实时渲染管线的核心支柱。这种简单而强大的几何单元能够高效地表示复杂表面,得益于GPU硬件中专门的三角形处理…...

大规模集群中的ksync:性能测试与资源占用优化策略
大规模集群中的ksync:性能测试与资源占用优化策略 【免费下载链接】ksync Sync files between your local system and a kubernetes cluster. 项目地址: https://gitcode.com/gh_mirrors/ks/ksync 在当今云原生开发环境中,Kubernetes文件同步工具…...

出海技术团队的沟通挑战:不是语言问题,是文化差异
当软件测试从业者成为“出海先锋”,我们最先打包进行李箱的是什么?是精通JIRA操作,是熟练Python脚本,是深谙CI/CD流水线。我们自信满满,以为能用一口流利的英语、一套标准的ISTQB术语,在全球化的技术团队中…...

MyBatis拦截器实现数据权限控制:原理、实现与PageHelper兼容方案
1. 项目概述与核心痛点在开发企业级后台管理系统时,数据权限控制是一个绕不开的经典难题。前端菜单和按钮的权限,我们通常可以通过配置角色与资源的关系来实现,相对直观。但到了后端,特别是数据库查询层面,问题就复杂多…...

Gemini 访问要不要额外网络工具?国内直连体验怎么看
最近不少开发者开始把 Gemini 放进日常工作流里:查资料、写代码注释、整理技术方案、做内容大纲。但实际使用前,大家最关心的往往不是模型参数,而是“能不能顺畅访问”。如果只是想先体验模型能力,可以通过 库拉 这类 AI模型聚合平…...

AI Agent开发工具大爆发:Claude、OpenAI、Google三强争霸
一、开篇:一夜之间,AI Agent开发工具"卷"起来了 说实话,作为一个每天泡在代码里的开发者,我原以为AI代码助手的发展速度已经够快了。但看了过去24小时的AI圈动态,我直呼"好家伙"——Claude Code、…...

《技术底稿 40》别只看文件大小:一次 “反常 OOM” 背后的内存缓存重构
一、反常现象:小文件报错,大文件反倒正常业务场景需批量导入文献类 ZIP 压缩包。本次测试出现诡异问题:一个 282MB 的 ZIP 包导入时,直接抛出 java.lang.OutOfMemoryError: Java heap space 堆内存溢出。当前服务 JVM 堆内存固定配…...

别再盯着大厂了,这3类“隐形冠军”公司才是技术人的归宿
在软件测试行业求职的浪潮中,几乎所有从业者的第一求职目标都锚定了互联网大厂:从BAT到新一代的字节、拼多多,从美团滴滴到华为阿里,大厂开出的高薪、响亮的title和完善的福利体系,始终吸引着一波又一波测试人挤破了头…...

MoE架构揭秘:万亿参数大模型如何实现2%活跃率
1. 项目概述:当“参数规模”不再等于“实际计算量”你可能已经看过不少标题党文章,比如“GPT-4参数量突破1.8万亿!”——但真正值得细品的,是后半句:“它每处理一个词(token),只动用…...

SR全光谱反射式膜厚仪
作者:李志松Pioneer 翟天保Steven 田雨阳 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处注:本文所讲设备由李志松教授团队研发,属于商业产品矩阵内容,商业技术合…...