Debeizum 增量快照
在Debeizum1.6版本发布之后,成功推出了Incremental Snapshot(增量快照)的功能,同时取代了原有的实验性的Parallel Snapshot(并行快照)。在本篇博客中,我将介绍全新快照方式的原理,以及深入研究其实现细节。
1、快照机制
在以往的Debezium的中,我们需要借助其提供的Snapshot机制来获取数据源中的历史数据。以MySQL为例,Debezium提供了多种锁表方式(snapshot.locking.mode),其中minimal是最小化的锁表方式,connector会在初始化过程中读取database schemas和其他元数据时获取全局读锁,耗时一般不超过1s。然后使用REPEATABLE READS的方式读取表中的记录完成后续的操作。
看上去这种方式和mysqldump的逻辑差不多,但这种方式还是有一些硬通病:
- 这种快照方式依然不能中断,无法暂停和恢复,一旦失败就要重新开始,这种语义类似事务机制(必须完全执行或者根本不执行);
- 如果是运行了一段时间的connector需要重新同步历史数据,需要暂停当前增量任务并新建新的全量任务,在全量结束后重新配置增量任务并且重启;
- 在快照生成的过程中,任何对表中进行的操作变更都无法捕获,直到快照完成。这种情况特别是在历史数据非常大时尤其严重;
- 无法在connector运行过程中添加新表。
直到2019年底,Netfix开发了一套参考流式系统中Watermark(水位)概念的数据捕获框架,并在DBLog: A Watermark Based Change-Data-Capture Framework 该篇论文中介绍了该框架的详细设计。其原理简单来就是将增量任务和全量任务一起执行,框架将高水位标识和低水位标识插入到事务日志中(例如MySQL的binlog),并且在二者发生在同一水位区间时做合并。
Debezium 采取了这个思路,实现了一套增量快照机制。新的增量快照一次只读取部分数据,不需要从头到尾、持续运行,并且支持随时增加新表,还可以随时触发快照,而不是只在任务开始时执行。更重要的是,快照过程中有数据变更,它也可以近乎实时地把变更也打入Kafka流之中。下面将来介绍这一实现细节。
2、增量快照
下面我们以Debezium-MySQL的视角介绍他们是增量快照的实现。当一个表需要获取其当前快照的时候,Debeizum会做两件事:
- 获取当前表中最大的主键,作为快照结束的标准,并且将该值存储在connector offset中;
- 根据主键的顺序,以及increment.snapshot.chunk.size配置的大小将表分成多个块(chunk)
当查询一个块时将构建一个动态SQL语句,选择下一个increment.snapshot.chunk.size数量记录,其最小的主键大于前一个块的最后一个主键,并且小于或等于快照初始化时记录的表中最大的主键。除此之外,当增量快照异常停止恢复后,可以从记录的执行过的主键开始重新执行。
Debezium读取到一个chunk之后,并不着急立即发送,而是将chunk放在一个叫snapshot-window的内存窗口中间。参考以下过程:
- 发送一个snapshot-window-open的信号;
- 读取当前表中的一个chunk,并记录到内存的缓冲区中;
- 发送一个snapshot-window-close的信号。
snapshot-window可以是需要进行快照的数据库中一个表,这里的发送信号也只是往这个表里插入一条数据。时间线可以参考下图:

图中T1~T6分别表示数据库当前执行的事务从prepare到commit所经历的时间,注意在MySQL中只有commit的事务才会被记录到Binlog中,Debezium从发出OPEN信号到发送CLOSE信号的过程中,只有T1~T5能够被监听到。T6因为是在CLOSE信号之外提交的,所以没法监听到。(OPEN和CLOSE两个信号也属于事务,有自己的binlog记录以及commit时间)
Debezium并不是访问数据库的唯一进程。我们可以预期大量进程同时访问数据库,可能访问当前被快照的相同主键记录。如上图所示,对数据的任何更改都会根据提交顺序写入事务日志(例如MySQL的binlog)。由于不可能精确地确定块读事务的时间以识别潜在冲突,因此添加了打开和关闭窗口事件来划分冲突可能发生的时间。Debezium的任务就是消除这些冲突。
为此,Debezium将块生成的所有事件记录到缓冲区中。当接收到snapshot-window-open信号时,将检查来自事务日志的所有事件是否属于快照表。如果是,则检查缓冲区是否包含了事务日志中相同记录的主键。如果是,则快照事件重复主键的记录将从缓冲区中删除,因为这是一个潜在的冲突。由于不可能对快照和事务日志事件进行正确排序,因此只保留事务日志事件(事务日志新于快照日志)。当接收到快照窗口关闭信号时,缓冲区中剩余的快照事件被发送到下游。如下图所示:

上图表示,数据库中存在了K2、K3和K4三条记录。在OPEN信号发送前,插入了一条K1记录,更新了K2记录和删除了K3记录,所以当前数据库的情况是包含了K1、K2和K4三条记录。然后在OPEN信号发送直到CLOSE信号发送这段时间里,事务日志里面包含了K4被删除、K5插入以及K6插入三个事件,而内存缓冲区里面则是读取了K1、K2、K4和刚刚插入的K5总共4条记录(没有加上锁的情况,所以在读取快照的过程中是可以读到窗口打开时插入的数据)。在窗口打开的范围内,存在K4和K5重复的主键,所以从缓冲区中删除这两条消息,然后把事务日志刷到下游(注意没有清空事务日志中的同ID记录,事务日志还是原封不动刷到下游的),遇到CLOSE事件之后,将当前缓冲区中的快照数据刷到下游去,并清空缓冲区。这里有几个注意点:
- 事务日志和读取快照时间不可能保持一致,所以这里一旦事务日志和缓冲区内存在了相同ID冲突,Debezium保留了事务日志刷到下游,不然可能会丢失部分删除恢复事件。(举个例子,在A窗口内K4记录被删除并发送到事务日志中,在B窗口中K4记录重新插入进数据库,但是因为增量延迟导致读取快照时增量快照只读到A窗口所在时间,这里保留了事务日志,那么会发送删除事件到下游,恢复事件在下次读取时发送)
- 快照事件应该有别于INSERT操作,DEBEZIUM用op:r(有的版本是op:c)表示。
3、实现分析
以下代码分析基于Debezium1.9版本介绍MySQL快照,区别于一开始的全量数据同步,增量快照是在运行增量同步的同时运行的,在Debezium运行的过程中,允许通过外部信号的方式触发增量快照,默认情况下是通过监听某个Kafka的topic获取信号的。
Debezium的源码实现中,会通过Source表示事件源。例如MySQL的增量事件源是MysqlStreamChangeEventSource,而增量快照事件源的实现放在MysqlReadOnlyIncrementalSnapshotChangeEventSource。不过,要知道如何在增量执行同时,执行全量快照,需要我们回到增量发送数据到下游时,也就是EventDispatcher.dispatchDataChangeEvent的逻辑中。
public boolean dispatchDataChangeEvent(P partition, T dataCollectionId, ChangeRecordEmitter<P> changeRecordEmitter) throws InterruptedException {try {boolean handled = false;// 如果从binlog中获取到的数据不需要被订阅,则忽略if (!filter.isIncluded(dataCollectionId)) {LOGGER.trace("Filtered data change event for {}", dataCollectionId);eventListener.onFilteredEvent(partition, "source = " + dataCollectionId, changeRecordEmitter.getOperation());dispatchFilteredEvent(changeRecordEmitter.getPartition(), changeRecordEmitter.getOffset());}else {// 拿到表结构DataCollectionSchema dataCollectionSchema = schema.schemaFor(dataCollectionId);// TODO handle as per inconsistent schema info optionif (dataCollectionSchema == null) {final Optional<DataCollectionSchema> replacementSchema = inconsistentSchemaHandler.handle(partition,dataCollectionId, changeRecordEmitter);if (!replacementSchema.isPresent()) {return false;}dataCollectionSchema = replacementSchema.get();}// 发送到下游changeRecordEmitter.emitChangeRecords(dataCollectionSchema, new Receiver<P>() {@Overridepublic void changeRecord(P partition,DataCollectionSchema schema,Operation operation,Object key, Struct value,OffsetContext offset,ConnectHeaders headers)throws InterruptedException {if (operation == Operation.CREATE && connectorConfig.isSignalDataCollection(dataCollectionId) && sourceSignalChannel != null) {sourceSignalChannel.process(value);if (signalProcessor != null) {// This is a synchronization point to immediately execute an eventual stop signal, just before emitting the CDC event// in this way the offset context updated by signaling will be correctly savedsignalProcessor.processSourceSignal();}}if (neverSkip || !skippedOperations.contains(operation)) {transactionMonitor.dataEvent(partition, dataCollectionId, offset, key, value);eventListener.onEvent(partition, dataCollectionId, offset, key, value, operation);if (incrementalSnapshotChangeEventSource != null) {// 交给下游的snapshot,但是如果window没有打开的话,这里是不会传输给snapshot的// 注意这里只需要传递Key就行,因为如果value一样的话,默认忽略,由stream传递给下游// 但我看了下这里是共用同一个dispatcher,所以会影响到增量的发送incrementalSnapshotChangeEventSource.processMessage(partition, dataCollectionId, key, offset);}// 交给下游的stream增量数据streamingReceiver.changeRecord(partition, schema, operation, key, value, offset, headers);}}});handled = true;}...注意一个binlog的event中可能会存在修改多个row,所以这里是每发送一个row在下游之前,就z需要执行一下incrementalSnapshotChangeEventSource.processMessage
// MySqlReadOnlyIncrementalSnapshotChangeEventSourcepublic void processMessage(MySqlPartition partition, DataCollectionId dataCollectionId, Object key, OffsetContext offsetContext) throws InterruptedException {if (getContext() == null) {LOGGER.warn("Context is null, skipping message processing");return;}LOGGER.trace("Checking window for table '{}', key '{}', window contains '{}'", dataCollectionId, key, window);// 如果当前snapshot的窗口已经关闭了,则立即发送当前window里面的eventboolean windowClosed = getContext().updateWindowState(offsetContext);if (windowClosed) {sendWindowEvents(partition, offsetContext);// 重新再读一个chunk的数据readChunk(partition, offsetContext);}// 如果还没关闭,则delete掉重复的key数据else if (!window.isEmpty() && getContext().deduplicationNeeded()) {deduplicateWindow(dataCollectionId, key);}}增量快照会先检测到当前读取数据窗口是否已经关闭了,如果已经关闭了则立即发送当前窗口中的所有snapshotEvent到下游中,然后读取下一个chunk的数据。
但是这里笔者在阅读时候想到一个问题,这里是在一个线程中执行的操作,检测到一个row,然后检查窗口是否关闭,关闭了就立即发送并读取下一个chunk的数据。这样就很奇怪,它这样操作会加大发送延迟不说,每次只能去检测一个row是否在一个chunk中,这样未免效率有点低。
所以这里的windowClosed,我们来看下这里的updateWindowState实现:
/*** 如果一个高低水印的GTID集合不包含一个binlog事件的GTID,那么这个水印被传递并且窗口处理模式被更新。多个binlog事件可以具有相同的GTID,* 这就是为什么算法等待在水印的GTID之外的binlog事件来关闭窗口,而不是在达到最大事务id时立即关闭它。* 重复数据删除从低水位之后的第一个事件开始,因为直到GTID包含在低水位(在chunk select语句之前捕获的executed_gtid_set)。* 低水位之后的COMMIT用于确保块选择看到在执行之前提交的更改。* 所有高水位的事件继续重复数据删除。重复数据删除的块事件插入在高水位之外的第一个事件之前。*/public boolean updateWindowState(OffsetContext offsetContext) {// 获取当前处理了的event对应的binlog中gtid的值String currentGtid = getCurrentGtid(offsetContext);// windowOpened这个可不是chunk的window打开的标志,每一个chunk读取的时候都是直接读取然后关闭的// 所以不需要这个值,这个值默认为false,只有在监听消息topic收到openWindow的时候这个值才会设置为true(这里不讨论这个场景)// 因为前面如果读过一个chunk,那么这里的lowWatermark不会为空,而是当时读取前的gtid的值if (!windowOpened && lowWatermark != null) {// 如果当前stream处理的gtid不存在于增量快照的低水位中且低水位不为空,则表示window打开,设置windowOpened为true// 注意这里的gtid是一个范围,类似1-100这种,所以这里的contain只需判断是否在当前低水位的范围内boolean pastLowWatermark = !lowWatermark.contains(currentGtid);if (pastLowWatermark) {LOGGER.debug("Current gtid {}, low watermark {}", currentGtid, lowWatermark);windowOpened = true;}}// 如果windowOpened为true,而且chunk读取完了,那么这里的highWatermark就是读取完后的gtid// 否则返回false,表示chunk窗口没关闭,全量还没执行完if (windowOpened && highWatermark != null) {// 正常这里读取了一大批数据的话,高水位应该是不包含当前stream处理的gtid,应该为trueboolean pastHighWatermark = !highWatermark.contains(currentGtid);if (pastHighWatermark) {LOGGER.debug("Current gtid {}, high watermark {}", currentGtid, highWatermark);// 关闭窗口,同时情况高低水位信息closeWindow();return true;}}return false;}// GtidSet MySQL水位用gtid表示高低水位public boolean contains(String gtid) {// split获取出serverId和transactionId范围String[] split = GTID_DELIMITER.split(gtid);// 这里叫serverId才对String sourceId = split[0];// 根据serverId拿到transactionId,我估计这里用Map存储的原因是因为有可能主从切换后// 一个gtid里面会存在多个serverId以及对应的transactionId// gtid类似这样 4160e9b3-58d9-11e8-b174-005056af6f24:1-19,甚至可以是多个8eed0f5b-6f9b-11e9-94a9-005056a57a4e:1-3:11:47-49// GTID = server_uuid :transaction_idUUIDSet uuidSet = forServerWithId(sourceId);if (uuidSet == null) {return false;}// 你用show master status看的话可能是连着的多个,8eed0f5b-6f9b-11e9-94a9-005056a57a4e:1-3:11:47-49// 但是一个行的话只能是一个8eed0f5b-6f9b-11e9-94a9-005056a57a4e:23long transactionId = Long.parseLong(split[1]);return uuidSet.contains(transactionId);}// GtidSetpublic boolean contains(long transactionId) {for (Interval interval : this.intervals) {if (interval.contains(transactionId)) {return true;}}return false;}// GtidSetpublic boolean contains(long transactionId) {return getStart() <= transactionId && transactionId <= getEnd();}当updateWindowState返回true的时候,就会尝试发送快照窗口中的所有数据到下游,然后重新读取一个chunk的数据,否则调用deduplicateWindow删除窗口中与当前row同个ID的快照数据。
首先,通过SHOW MASTER STATUS获取到GTID,并设置为低水位,当时获取到的GTID集合应该是类似xxx:1-465,也就是在当前集群应用过的事务合集。而从binlog拿出的每一个row,其GTID应该是xxx:467这样的类型。这里的updateWindowState的逻辑,主要是用于判断当前ROW是否在低水位的后面,或者在高水位的后面,以此检测row是否在窗口的范围之内的流式数据。

一旦当前row不在低水位的范围内,那么表示窗口打开(windowOpen=true),而如果row在高水位的范围内,那么当前row应该是窗口的增量数据,直到不在这个范围里面则表示关闭且应该flush掉这些窗口中的数据到下游。所以updateWindowState的作用就是检测增量数据是否在窗口的高低水位范围内。对于在范围内的,会采用dedeplicateWindow的逻辑剔除出窗口里的快照数据。
protected void deduplicateWindow(DataCollectionId dataCollectionId, Object key) {if (context.currentDataCollectionId() == null || !context.currentDataCollectionId().getId().equals(dataCollectionId)) {return;}if (key instanceof Struct) {// 直接remove掉if (window.remove((Struct) key) != null) {LOGGER.info("Removed '{}' from window", key);}}}最后看下readChunk的逻辑,这里是每次去源集群中获取足够多的数据。
// AbstractIncrementalSnapshotChangeEventSourceprotected void readChunk(P partition, OffsetContext offsetContext) throws InterruptedException {if (!context.snapshotRunning()) {LOGGER.info("Skipping read chunk because snapshot is not running");postIncrementalSnapshotCompleted();return;}if (context.isSnapshotPaused()) {LOGGER.info("Incremental snapshot was paused.");return;}try {preReadChunk(context);// This commit should be unnecessary and might be removed laterjdbcConnection.commit();// 开始读取一个新的chunkcontext.startNewChunk();// 打开一个新的窗口,这在Mysql中是设置GTID为一个窗口的低水位emitWindowOpen();while (context.snapshotRunning()) {if (isTableInvalid(partition, offsetContext)) {continue;}if (connectorConfig.isIncrementalSnapshotSchemaChangesEnabled() && !schemaHistoryIsUpToDate()) {// Schema has changed since the previous window.// Closing the current window and repeating schema verification within the following window.break;}final TableId currentTableId = (TableId) context.currentDataCollectionId().getId();// 当前上下文中没有关于currentTableId的key最大值if (!context.maximumKey().isPresent()) {// 重新获取表结构currentTable = refreshTableSchema(currentTable);Object[] maximumKey;try {// 获取当前表的最大key,作为快照结束的标志maximumKey = jdbcConnection.queryAndMap(buildMaxPrimaryKeyQuery(currentTable, context.currentDataCollectionId().getAdditionalCondition()), rs -> {if (!rs.next()) {return null;}return keyFromRow(jdbcConnection.rowToArray(currentTable, rs,ColumnUtils.toArray(rs, currentTable)));});context.maximumKey(maximumKey);}catch (SQLException e) {LOGGER.error("Failed to read maximum key for table {}", currentTableId, e);nextDataCollection(partition, offsetContext);continue;}if (!context.maximumKey().isPresent()) {LOGGER.info("No maximum key returned by the query, incremental snapshotting of table '{}' finished as it is empty",currentTableId);nextDataCollection(partition, offsetContext);continue;}if (LOGGER.isInfoEnabled()) {LOGGER.info("Incremental snapshot for table '{}' will end at position {}", currentTableId,context.maximumKey().orElse(new Object[0]));}}// 获取关于该表的dataEvent,从这里开始读取表中的数据if (createDataEventsForTable(partition)) {String dataCollections = context.getDataCollections().stream().map(DataCollection::getId).map(DataCollectionId::identifier).collect(Collectors.joining(","));// 如果窗口中捕获不到任何数据,则立即开始关于下一个dataCollection的数据获取if (window.isEmpty()) {LOGGER.info("No data returned by the query, incremental snapshotting of table '{}' finished",currentTableId);notificationService.notify(buildNotificationWith(SnapshotStatus.TABLE_SCAN_COMPLETED,Map.of("data_collections", dataCollections,"total_rows_scanned", String.valueOf(totalRowsScanned)),offsetContext),Offsets.of(partition, offsetContext));tableScanCompleted(partition);// 开始下一个表dataCollection的获取nextDataCollection(partition, offsetContext);}else {// 事件通知notificationService.notify(buildNotificationWith(SnapshotStatus.IN_PROGRESS,Map.of("data_collections", dataCollections,"current_collection_in_progress", context.currentDataCollectionId().getId().identifier(),"maximum_key", context.maximumKey().orElse(new Object[0])[0].toString(),"last_processed_key", context.chunkEndPosititon()[0].toString()),offsetContext),Offsets.of(partition, offsetContext));break;}}else {context.revertChunk();break;}}// 关闭当前窗口,设置gtid为高水位emitWindowClose(partition, offsetContext);}catch (SQLException e) {throw new DebeziumException(String.format("Database error while executing incremental snapshot for table '%s'", context.currentDataCollectionId()), e);}finally {postReadChunk(context);if (!context.snapshotRunning()) {postIncrementalSnapshotCompleted();}}}这里去读取快照数据之前,会先获取到当前table最大的主键的值,作为增量快照结束的点。关键是在这里的createDataEventsForTable(partition)这里。
// AbstractIncrementalSnapshotChangeEventSourceprivate boolean createDataEventsForTable(P partition) {long exportStart = clock.currentTimeInMillis();LOGGER.debug("Exporting data chunk from table '{}' (total {} tables)", currentTable.id(), context.dataCollectionsToBeSnapshottedCount());// 构建chunk查询sqlfinal String selectStatement = buildChunkQuery(currentTable, context.currentDataCollectionId().getAdditionalCondition());LOGGER.debug("\t For table '{}' using select statement: '{}', key: '{}', maximum key: '{}'", currentTable.id(),selectStatement, context.chunkEndPosititon(), context.maximumKey().get());final TableSchema tableSchema = databaseSchema.schemaFor(currentTable.id());try (PreparedStatement statement = readTableChunkStatement(selectStatement);ResultSet rs = statement.executeQuery()) {// 检查表结构是否发生变化,如果失败应该返回false,并重新读取表结构和最大keyif (checkSchemaChanges(rs)) {return false;}final ColumnUtils.ColumnArray columnArray = ColumnUtils.toArray(rs, currentTable);long rows = 0;Timer logTimer = getTableScanLogTimer();Object[] lastRow = null;Object[] firstRow = null;while (rs.next()) {rows++;// 这里是取出表中的记录的所有字段final Object[] row = jdbcConnection.rowToArray(currentTable, rs, columnArray);if (firstRow == null) {firstRow = row;}// 将获取到的快照数据塞入window这个值中,后续发送和删除重复key都是在这个值中操作final Struct keyStruct = tableSchema.keyFromColumnData(row);window.put(keyStruct, row);if (logTimer.expired()) {long stop = clock.currentTimeInMillis();LOGGER.debug("\t Exported {} records for table '{}' after {}", rows, currentTable.id(),Strings.duration(stop - exportStart));logTimer = getTableScanLogTimer();}lastRow = row;}final Object[] firstKey = keyFromRow(firstRow);// 获取到的数据都是根据id严格排序的,所以这里的lastKey可以作为下一次读取chunk的查询条件final Object[] lastKey = keyFromRow(lastRow);if (context.isNonInitialChunk()) {progressListener.currentChunk(partition, context.currentChunkId(), firstKey, lastKey);}else {progressListener.currentChunk(partition, context.currentChunkId(), firstKey, lastKey, context.maximumKey().orElse(null));}// 记录lastKey,作为下一次chunk的查询条件context.nextChunkPosition(lastKey);if (lastRow != null) {LOGGER.debug("\t Next window will resume from {}", (Object) context.chunkEndPosititon());}LOGGER.debug("\t Finished exporting {} records for window of table table '{}'; total duration '{}'", rows,currentTable.id(), Strings.duration(clock.currentTimeInMillis() - exportStart));incrementTableRowsScanned(partition, rows);}catch (SQLException e) {throw new DebeziumException("Snapshotting of table " + currentTable.id() + " failed", e);}return true;}// AbstractIncrementalSnapshotChangeEventSourceprotected PreparedStatement readTableChunkStatement(String sql) throws SQLException {final PreparedStatement statement = jdbcConnection.readTablePreparedStatement(connectorConfig, sql,OptionalLong.empty());if (context.isNonInitialChunk()) {final Object[] maximumKey = context.maximumKey().get();final Object[] chunkEndPosition = context.chunkEndPosititon();// Fill boundaries placeholdersint pos = 0;for (int i = 0; i < chunkEndPosition.length; i++) {for (int j = 0; j < i + 1; j++) {statement.setObject(++pos, chunkEndPosition[j]);}}// Fill maximum key placeholdersfor (int i = 0; i < chunkEndPosition.length; i++) {for (int j = 0; j < i + 1; j++) {statement.setObject(++pos, maximumKey[j]);}}}return statement;}这里作者考虑到表的主键可能是复合主键,在每一次重新去读取chunk的时候,都需要读取比上一次读取的最大主键大一定数量的快照数据。
// AbstractIncrementalSnapshotChangeEventSourceprotected String buildChunkQuery(Table table, int limit, Optional<String> additionalCondition) {String condition = null;// Add condition when this is not the first queryif (context.isNonInitialChunk()) {final StringBuilder sql = new StringBuilder();// Window boundariesaddLowerBound(table, sql);// Table boundariessql.append(" AND NOT ");addLowerBound(table, sql);condition = sql.toString();}final String orderBy = getQueryColumns(table).stream().map(c -> jdbcConnection.quotedColumnIdString(c.name())).collect(Collectors.joining(", "));return jdbcConnection.buildSelectWithRowLimits(table.id(),limit,buildProjection(table),Optional.ofNullable(condition),additionalCondition,orderBy);}// AbstractIncrementalSnapshotChangeEventSourceprivate void addLowerBound(Table table, StringBuilder sql) {// To make window boundaries working for more than one column it is necessary to calculate// with independently increasing values in each column independently.// For one column the condition will be (? will always be the last value seen for the given column)// (k1 > ?)// For two columns// (k1 > ?) OR (k1 = ? AND k2 > ?)// For four columns// (k1 > ?) OR (k1 = ? AND k2 > ?) OR (k1 = ? AND k2 = ? AND k3 > ?) OR (k1 = ? AND k2 = ? AND k3 = ? AND k4 > ?)// etc.// 获取pk columnfinal List<Column> pkColumns = getQueryColumns(table);if (pkColumns.size() > 1) {sql.append('(');}// 这里的两个i,j循环的意思是,根据主键列用OR拼接出主键列数量的条件,例如主键有3个,分别是pk1,pk2,pk3// 那么拼接出来的条件就是 (pk1 > ?) OR (pk1 = ? AND pk2 > ?) OR (pk1 = ? AND pk2 = ? AND pk3 > ?)// 后面还有limit,以此获取足够多的chunk,而且根据逐渐数量递增for (int i = 0; i < pkColumns.size(); i++) {// 是否是最后一列final boolean isLastIterationForI = (i == pkColumns.size() - 1);sql.append('(');for (int j = 0; j < i + 1; j++) {final boolean isLastIterationForJ = (i == j);// quotedColumnIdString 是避免用户用关键字作为字段,所以加上开闭服务,类似MySQL可以用`columnName`sql.append(jdbcConnection.quotedColumnIdString(pkColumns.get(j).name()));// 这里加上 > 是用于保证id大于某个值?sql.append(isLastIterationForJ ? " > ?" : " = ?");if (!isLastIterationForJ) {sql.append(" AND ");}}sql.append(")");if (!isLastIterationForI) {sql.append(" OR ");}}if (pkColumns.size() > 1) {sql.append(')');}}
相关文章:
Debeizum 增量快照
在Debeizum1.6版本发布之后,成功推出了Incremental Snapshot(增量快照)的功能,同时取代了原有的实验性的Parallel Snapshot(并行快照)。在本篇博客中,我将介绍全新快照方式的原理,以…...
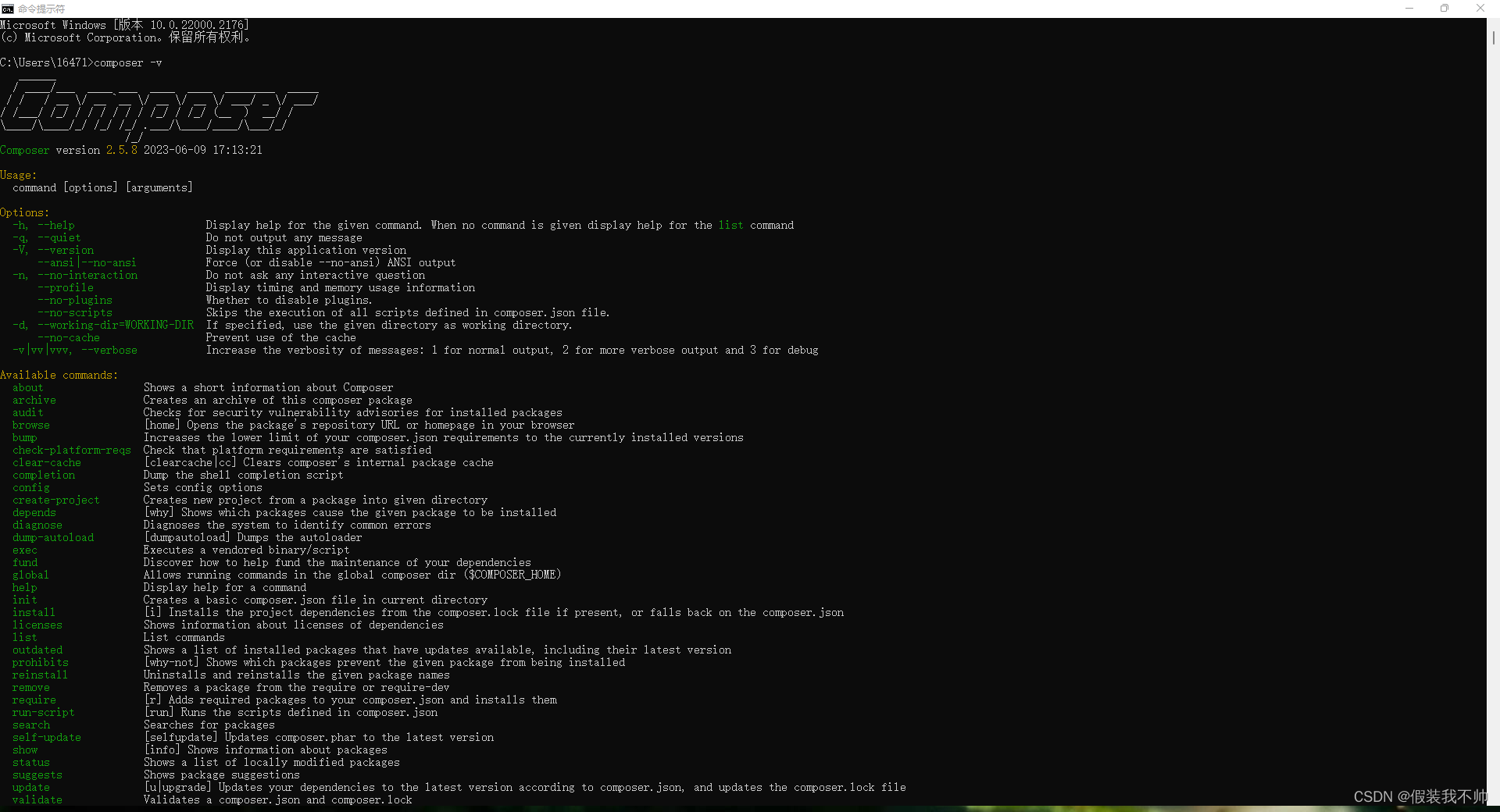
windows下安装composer
安装Php 教程 下载composer 官网 中文网站 exe下载地址 下载好exe 双击运行 找到php.ini注释一行代码 测试 composer -v说明安装成功 修改源 执行以下命令即可修改 composer config -g repo.packagist composer https://packagist.phpcomposer.com # 查看配置…...

企业游学进华秋,助力电子产业创新与发展
近日,淘IC企业游学活动,携20多位电子行业的企业家,走进了深圳华秋电子有限公司(以下简称“华秋”),进行交流学习、供需对接。华秋董事长兼CEO陈遂佰对华秋的发展历程、业务版块、产业布局等做了详尽的介绍&…...

玩转Tomcat:从安装到部署
文章目录 一、什么是 Tomcat二、Tomcat 的安装与使用2.1 下载安装2.2 目录结构2.3 启动 Tomcat 三、部署程序到 Tomcat3.1 Windows环境3.2 Linux环境 一、什么是 Tomcat 一看到 Tomcat,我们一般会想到什么?没错,就是他,童年的回忆…...

吃透《西瓜书》第四章 决策树定义与构造、ID3决策树、C4.5决策树、CART决策树
目录 一、基本概念 1.1 什么是信息熵? 1.2 决策树的定义与构造 二、决策树算法 2.1 ID3 决策树 2.2 C4.5 决策树 2.3 CART 决策树 一、基本概念 1.1 什么是信息熵? 信息熵: 熵是度量样本集合纯度最常用的一种指标,代表一个系统中蕴…...
)
复现宏景eHR存在任意文件上传漏洞(0day)
目录 一、漏洞描述 二、影响版本 三、资产测绘 四、漏洞复现 一、漏洞描述 北京宏景世纪软件股份有限公司(简称“宏景软件”)自成立以来始终专注于国有企事业单位人力与人才管理数智化(数字化、智能化)产品的研发和应用推广,是中国国有企事业单位人力与人才管理数智…...

unity连接MySQL数据库并完成增删改查
数据存储量比较大时,我就需要将数据存储在数据库中方便使用,尤其是制作管理系统时,它的用处就更大了。 在编写程序前,需要在Assets文件夹中创建plugins文件,将.dll文件导入,文件从百度网盘自取:…...

13个ChatGPT类实用AI工具汇总
在ChatGPT爆火后,各种工具如同雨后春笋一般层出不穷。以下汇总了13种ChatGPT类实用工具,可以帮助学习、教学和科研。 01 / ChatGPT for google/ 一个浏览器插件,可搭配现有的搜索引擎来使用 最大化搜索效率,对搜索体验的提升相…...
1-linux下mysql8.0.33安装
在互联网企业的日常工作/运维中,我们会经常用到mysql数据库,而linux下mysql的安装方式有三种: 1.mysql rpm安装 2.mysql二进制安装 3.mysql源码安装 今天就为大家讲讲linux下mysql8.0.33版本rpm方式的安装。 1.前提 1.1.系统版本 Cent…...
golang反射获取结构体的值和修改值
功能:根据id和反射技术封装 创建和更新人的查询 一、代码二、演示 一、代码 package coryCommonimport ("context""errors""github.com/gogf/gf/v2/container/gvar""github.com/tiger1103/gfast/v3/internal/app/system/dao&qu…...

中文大模型评估数据集——C-Eval
C-EVAL: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models https://arxiv.org/pdf/2305.08322v1.pdfhttps://github.com/SJTU-LIT/cevalhttps://cevalbenchmark.com/static/leaderboard.html Part1 前言 怎么去评估一个大语言模型呢? 在广泛…...
Unity 四元素
//-------------旋转------------ // //设置角度 (超过90或负数时,会设置-1结果是359这样的问题,可以使用下面旋转的方式) transform.rotate new Quaternion(0,0,0,0);//Quaternion四元数 transform.localEulerAngles new Vector3(0,0,0);//EulerA…...

如何入门python爬虫
对于初学者,想要入门python爬虫需要注意什么,如何快速入门呢? 首先需要明白四点: 熟悉python编程了解HTML了解网络爬虫的基本原理学习使用python爬虫的一些库与框架python编程 如果你不懂python,那么需要先学习python这门非常easy的语言(相对其它语言而言)。 编程语言…...

深入学习 Redis - 基于 Jedis 通过 Java 客户端操作 Redis
目录 一、Jedis 依赖 二、Java 客户端操控 redis 2.1、准备工作(ssh 隧道) 2.2、概要 2.2、string 2.3、hash 2.4、list 2.5、set 2.5、zset 一、Jedis 依赖 自己去 中央仓库 上面找. 二、Java 客户端操控 redis 2.1、准备工作(ssh 隧…...
019 - STM32学习笔记 - Fatfs文件系统(一) - FatFs文件系统初识
019 - STM32学习笔记 - Fatfs文件系统(一) - FatFs文件系统初识 最近工作比较忙,没时间摸鱼学习,抽空学点就整理一点笔记。 1、文件系统 在之前学习Flash的时候,可以调用SPI_FLASH_BufferWrite函数,将数…...
Selenium开发环境搭建
1.下载Python https://www.python.org/downloads/ 下载下来选择自己创建的路径进行安装,然后配置环境变量 cmd命令框查看 2.安装selenium cmd命令框输入: pip install selenium3.下载pycharm https://www.jetbrains.com/pycharm/download/#sec…...

解决 The ‘more_itertools‘ package is required
在使用爬虫获取维基百科数据时看到了一个很好的项目: 博客:https://blog.51cto.com/u_15919249/5962100 项目地址:https://github.com/wjn1996/scrapy_for_zh_wiki 但在使用过程中遇到若干问题,记录一下: The more_it…...

手把手教你在云环境炼丹(部署Stable Diffusion WebUI)
前几天写了一篇《手把手教你在本机安装Stable Diffusion秋叶整合包》的文章,有些同学反映对硬件的要求太高,显卡太TM贵了。今天我再分享一个云服务器炼丹的方法,方便大家快速入门上手,这个云服务不需要特殊网络设置,能…...
pytorch-gpu 极简安装
1、进入pytoch官网:PyTorch 找到pytorch-gpu版本,看到CUDA11.8、11.7、CPU,这里我选择安装CUDA11.8 2、下载CUDA Toolkit:CUDA Toolkit 11.8 Downloads | NVIDIA Developer 3、下载CUDANN:cuDNN Download | NVIDIA D…...

有道云笔记迁移到自建服务器Joplin
当前有道云笔记各项业务开始逐渐向会员靠拢,如一开始不受限的多端同步现在非会员限制成了两个终端,估计以后会有越来越多的免费内容会逐渐的向会员转移,因此博主开始考虑自建服务器来搞一个云笔记服务端。 因博主已有黑群晖,并且有…...

服务器末级缓存管理优化与Garibaldi架构解析
1. 服务器末级缓存管理的核心挑战 在现代服务器架构中,末级缓存(Last-Level Cache, LLC)作为CPU与主存之间的关键缓冲层,其管理效率直接影响系统整体性能。传统LLC管理面临一个根本性矛盾:随着核心数量增加和负载多样化,有限的缓存…...
)
【顶级EI复现】考虑用户行为基于扩散模型的电动汽车充电场景生成( Python + PyTorch代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

千问 LeetCode 2569. 更新数组后处理求和查询 Java实现
这道题的核心是高效维护nums1的区间反转操作,因为数据规模达到10^5,暴力反转会超时。需要用到线段树(区间更新区间查询)或BitSet来优化。下面给出Java实现,采用线段树 懒标记的方案:class Solution {publi…...

我见过最聪明的技术人,都在偷偷培养这3种“非技术能力”
在软件测试行业摸爬滚打这些年,我见过太多天赋异禀的技术从业者:有人能一夜吃透新的自动化测试框架,有人能对着流量日志半小时定位出隐藏半年的内存泄漏问题,有人能把性能测试指标优化到远超行业标准。可几年过去,真正…...

【Go Interface】接口诞生的意义
结论:接口(Interface)诞生的唯一意义:解耦接口的诞生,是为了解决软件工程里最致命的痛点:“上层代码”被“底层细节”死死绑架。没有接口时的痛苦假设你的 naga 模块现在要保存心跳数据。 第一周࿰…...

中小型企业服务器常见隐患 + 标准化运维维护方案总结
做运维多年,接触过大量中小企业服务器,总结几个最常见、最致命的问题:1、服务器常年不关机、不巡检,磁盘爆满无人察觉;2、对外开放端口过多,没有安全策略,极易被暴力破解;3、数据库无…...

B站视频下载终极指南:5步掌握免费批量下载技巧
B站视频下载终极指南:5步掌握免费批量下载技巧 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/Bilib…...

30天试用期即将到期?3种方法一键重置JetBrains IDE,告别频繁重装烦恼
30天试用期即将到期?3种方法一键重置JetBrains IDE,告别频繁重装烦恼 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经因为JetBrains IDE试用期到期而不得不重新安装软件…...

数据缺失处理实战指南:从原理到应用,掌握KNN与MICE填补技术
1. 项目概述:数据缺失,一个绕不开的“坑”做数据分析、机器学习或者任何和数据打交道的工作,你大概率都遇到过这种情况:打开数据集,满怀期待地准备大干一场,结果发现好几列数据里都夹杂着刺眼的“NaN”、“…...

软件工程方法论与敏捷开发
软件工程方法论与敏捷开发 1. 技术分析 1.1 软件工程概述 软件工程是系统化的软件开发方法: 软件工程要素过程: 开发流程方法: 技术手段工具: 辅助工具核心目标:高质量软件按时交付可控成本1.2 软件开发方法论 方法论分类传统方法: 瀑布模型敏捷方法: Scrum、Kanban…...