Python实现prophet 理论及参数优化
文章目录
- Prophet理论及模型参数介绍
- Python代码完整实现
- prophet 添加外部数据进行模型优化
之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观的理解要优化哪些参数,模型自带的可调参数比公式里的还要多一些。
Prophet理论及模型参数介绍
优秀文章参考过讲透一个强大算法模型,Prophet!!
想要还了解理论的,可以参考之前写的文章Python实现Prophet时序预测模型
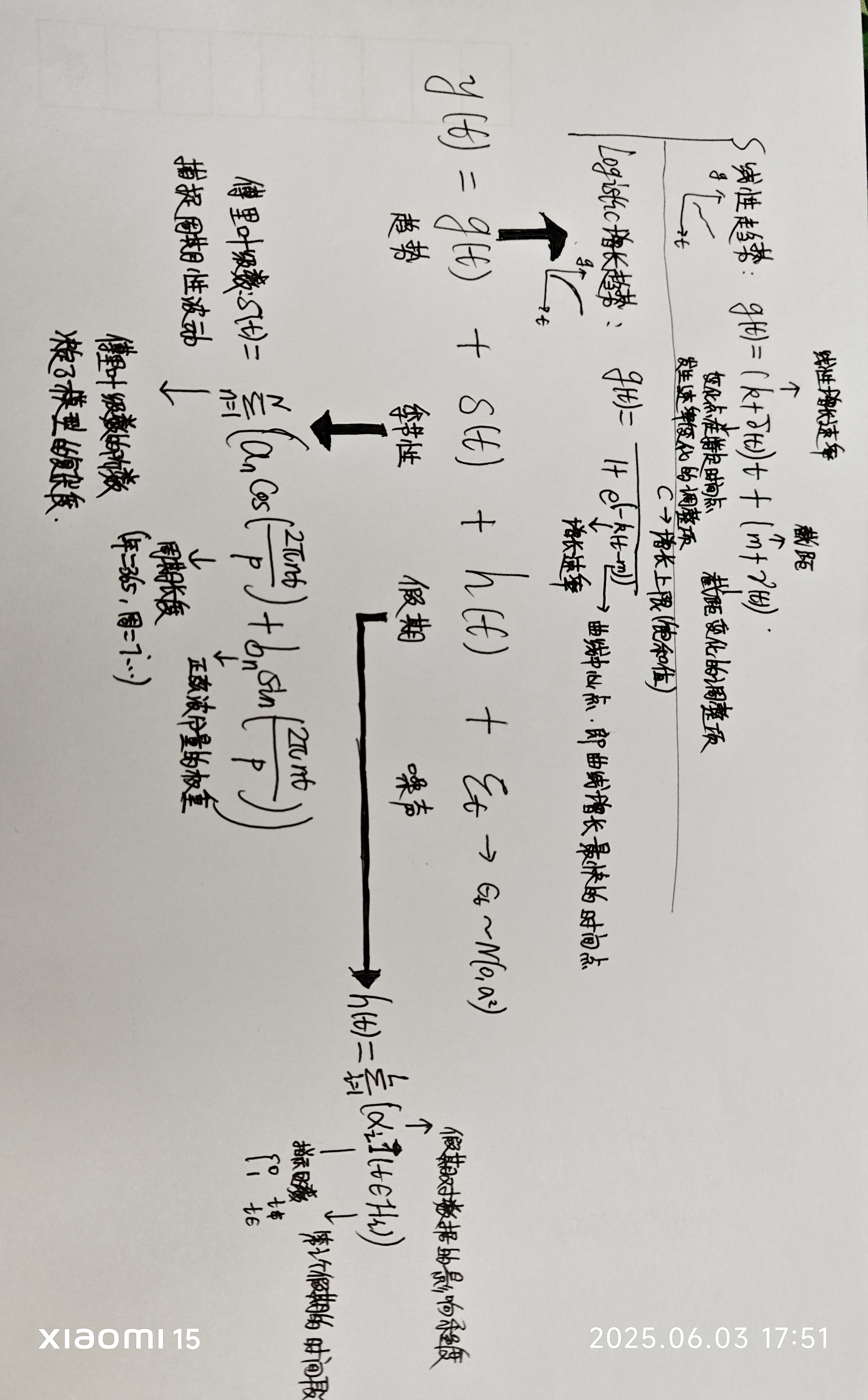
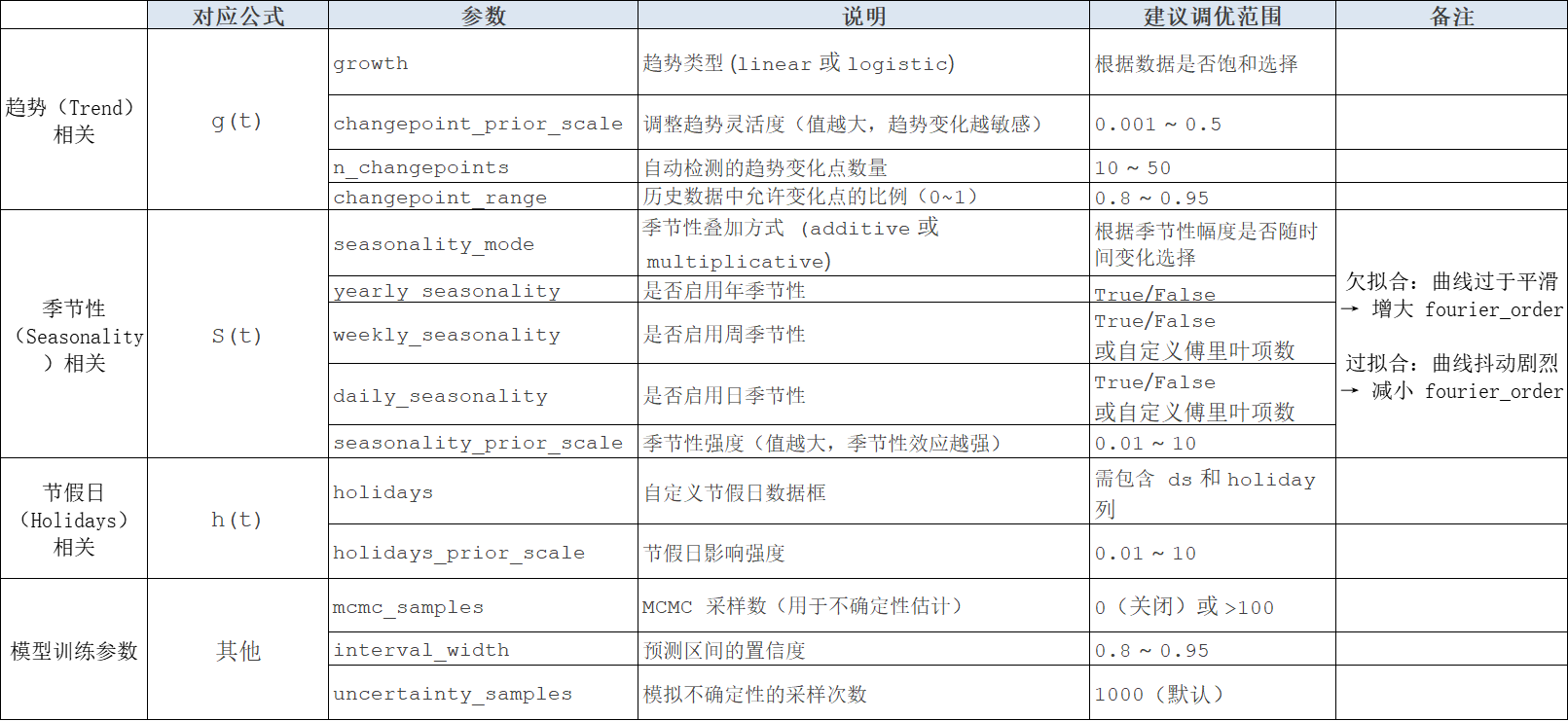
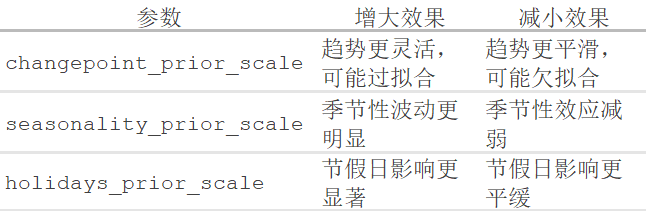
接下来,直接结合理论公式和代码里的参数进行介绍,看完下面我自己整理的图,你会理解以下问题:
- 为什么季节性的参数会选择优化傅里叶级数?
- 不同自动检测的趋势变化点数量会影响什么?
- 趋势类型决定了模型的什么部分?
- 节假日影响强度是什么意思?
- … …

Python代码完整实现
import pandas as pd
import numpy as np
from prophet import Prophet
from sklearn.model_selection import ParameterGrid
from prophet.diagnostics import cross_validation, performance_metrics
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error,mean_squared_error
from prophet.plot import plot_cross_validation_metric, plot_components
import matplotlib.pyplot as plt
from datetime import timedelta
import logging
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 配置日志
logging.getLogger('prophet').setLevel(logging.WARNING)
logging.getLogger('cmdstanpy').setLevel(logging.WARNING)
from sklearn.model_selection import ParameterGrid
class normal_Prophet:def __init__(self):self.model = Noneself.freq = '15T' # 15分钟频率def preprocess_data(self, df):df = df.sort_values(by=['xxxx','xxx','xx'])cols = df.columns.tolist()cols[10:-1]=[f'point_{i}' for i in range(1, 97)] df.columns = colsreturn df def data_row_column(self,cus_df): #将数据1*96转换成96*1cus_df = self.preprocess_data(cus_df)hourly_loads = cus_df.drop(['xxxx','xxx','xx','年月'], axis=1)df = hourly_loads[(hourly_loads.cust_id ==20250610)]# 列名格式为 'point_1', 'point_2', ..., 'point_96'load_columns = df.filter(regex="point_").columns# 将96点数据转换为长格式hourly_loads = df.melt(id_vars=["xxxxxxxxxx"],value_vars=load_columns,var_name="point",value_name="load")# 计算时间戳(每15分钟一个点)hourly_loads["point_idx"] = hourly_loads["point"].str.extract("(\d+)").astype(int)hourly_loads["hour"] = (hourly_loads["point_idx"] - 1) // 4 # 计算小时(0-23)hourly_loads["minute"] = ((hourly_loads["point_idx"] - 1) % 4) * 15 # 计算分钟(0, 15, 30, 45)hourly_loads["timestamp"] = hourly_loads["amt_ym"] + pd.to_timedelta(hourly_loads["hour"], unit="h") + pd.to_timedelta(hourly_loads["minute"], unit="m")# 按时间戳排序hourly_loads = hourly_loads.sort_values("timestamp")ts_df = hourly_loads[["timestamp", "load"]].set_index("timestamp")return ts_dfdef z_score_data(self,ts_df):ts_df = self. data_row_column(ts_df)# print("时间范围:", ts_df.index.min(), "到", ts_df.index.max())# print("实际数据点数:", len(ts_df))# print("缺失的日期示例:", ts_df.asfreq('15T').index.difference(ts_df.index)[:5]) # 检查是否有缺失full_index = pd.date_range(start=ts_df.index.min(),end=ts_df.index.max(),freq='15T' )ts_df = ts_df.reindex(full_index).interpolate()ts_df = ts_df.reset_index()ts_df.columns = ['ds','y']"""'''窗口1(时间点0-95):计算 mean(y0:y95) 和 std(y0:y95),用于时间点95的Z-score。窗口2(时间点1-96):计算 mean(y1:y96) 和 std(y1:y96),用于时间点96的Z-score。窗口3(时间点2-97):计算 mean(y2:y97) 和 std(y2:y97),用于时间点97的Z-score。滑动窗口:代码中的 rolling() 是滑动(不重复)的,每个点基于最近的96个点计算统计量。异常值检测:只有完整的窗口(第96个点开始)会触发Z-score计算,前95个点被跳过。适用场景:适合高频数据中连续检测异常值,避免分块导致的边界不连续问题。'''"""window_size = 96 # 24小时窗口(96个15分钟间隔)if len(ts_df) > window_size:rolling_mean = ts_df['y'].rolling(window=window_size).mean()rolling_std = ts_df['y'].rolling(window=window_size).std()ts_df['z_score'] = (ts_df['y'] - rolling_mean) / rolling_stdts_df['y'] = np.where(np.abs(ts_df['z_score']) > 4, np.nan, ts_df['y'])return ts_df.dropna()def add_custom_seasonalities(self, model):"""添加高频数据特有的季节性"""# 周周期model.add_seasonality(name='weekly',period=7,fourier_order = params['weekly_fourier_order'],prior_scale = params['seasonality_weekly_prior_scale'])# 小时周期(覆盖默认的小时季节性) model.add_seasonality(name='hourly',period=24, # 24小时fourier_order = params['hourly_fourier_order'], # 捕捉小时级别模式prior_scale = params['seasonality_hourly_prior_scale'])# model.add_seasonality(# name='daily_15min',# period=1, # 1天周期# fourier_order=12, # 高频数据需要更高阶数# prior_scale=0.5,# mode='additive'# )# 可添加业务特定的周期(如半小时、45分钟等)# model.add_seasonality(# name='year',# period=24*365, # 0.5小时# fourier_order=2,# prior_scale=0.1# )return modeldef param_grid(self):# 参数网格param_grid = { 'seasonality_prior_scale':[0.01,1], #整体季节参数'weekly_fourier_order': [3, 7], #周周期-傅里叶级数'seasonality_weekly_prior_scale': [0.1], #周周期-季节强度'hourly_fourier_order': [3,5], #日周期-傅里叶级数'seasonality_hourly_prior_scale': [0.01,0.2], #日周期-季节强度'n_changepoints': [5,10], # 趋势相关-自动检测的趋势变化点数量'changepoint_prior_scale': [0.1,0.2], # 趋势相关-调整趋势灵活度'holidays_prior_scale':[0.01] #节假日相关-节假日影响强度}return param_griddef fit(self, params,df, holidays_df=None,fut_num = 16 ):"""训练模型"""df_processed = self.z_score_data(df)self.model = Prophet(n_changepoints = params['n_changepoints'],seasonality_prior_scale= params['seasonality_prior_scale'],changepoint_prior_scale= params['changepoint_prior_scale'],holidays_prior_scale = params['holidays_prior_scale'])# 添加自定义季节性self.model = self.add_custom_seasonalities(self.model)# 添加节假日效应if holidays_df is not None:holidays_df['ds'] = pd.to_datetime(holidays_df['ds'])self.model.add_country_holidays(country_name='CN')self.model.holidays = holidays_dfself.model.fit(df_processed[:-fut_num] )df_cv = cross_validation(self.model,initial='180 days',period='90 days',horizon='10 days')df_p = performance_metrics(df_cv, rolling_window=1)return self.model,df_p['rmse'].mean()def predict(self, periods=16, freq=None, include_history=True):"""生成预测"""if not self.model:raise ValueError("请先训练模型")freq = freq or self.freqfuture = self.model.make_future_dataframe(periods=periods,freq=freq,include_history=include_history)forecast = self.model.predict(future)return forecastdef plot_components(self, forecast):"""可视化组件"""fig = self.model.plot_components(forecast)for ax in fig.axes:ax.xaxis.set_major_locator(plt.MaxNLocator(5))return figdef result_data(self,df,forecast,fut_num = 16):da = self.z_score_data(df)result = forecast.iloc[-1*fut_num:][['ds','yhat']]rmse = np.sqrt(mean_squared_error(da[['y']][-1*fut_num:], result[['yhat']][-1*fut_num:]))mse = mean_squared_error(da[['y']][-1*fut_num:], result[['yhat']][-1*fut_num:])true_result = da[['ds','y']].iloc[-1*fut_num:]true_result[[ 'yhat', 'yhat_lower', 'yhat_upper']] = forecast[['yhat', 'yhat_lower', 'yhat_upper']].iloc[-1*fut_num:].valuestrue_result['timestamp'] = true_result['ds'].dt.time.apply(lambda x: x.strftime('%H:%M')) ymd = true_result.ds.values[0].astype('datetime64[D]') true_result['误差'] = np.abs(true_result['y'] -true_result['yhat'] )true_result['误差百分比'] = true_result['误差'] /true_result['y']*100print('预测结果\n',true_result)print(f'\n \n预测与真实值之间的RMSE :{rmse}')# #结果可视化plt.figure(figsize=(12,6))plt.scatter(true_result['timestamp'],true_result['y'],ls=':',c='red',lw=1)plt.fill_between(true_result['timestamp'],true_result['yhat_lower'],true_result['yhat_upper'],alpha = 0.15)plt.plot(true_result['timestamp'],true_result['yhat'],c='blue')plt.xlabel('未来4小时时刻点', size= 15)plt.ylabel('实际出力值', size= 15)plt.title('Prophet实际出力预测结果', size= 18)plt.legend(['出力真实值','预测值上下限','出力预测值'])plt.show()return true_resultif __name__ == '__main__':# 数据导入RAWcus_df = pd.read_excel("D:\\data.xlsx",engine='openpyxl') cus_df = RAWcus_df.copy()cus_df['年月'] = cus_df['xxx'].dt.strftime('%Y-%m')##开始模型训练normal_Prophet = normal_Prophet()holidays = pd.DataFrame({'ds': pd.to_datetime(['2023-01-01', '2023-01-22', '2023-04-05']),'holiday': ['元旦', '春节', '清明节'],'lower_window': -1,'upper_window': 1})# 4. 参数训练param_grid = normal_Prophet.param_grid()best_score = float('inf')best_params = {}best_params_list = []params_list = []rmse_list = []for params in ParameterGrid(param_grid):print('当前训练参数',params)params_list.append(params)model,current_rmse = normal_Prophet.fit(params,cus_df, holidays_df=holidays)rmse_list.append(current_rmse)if current_rmse < best_score:best_score = current_rmsebest_params = paramsbest_params_list.append(best_params)print(f"New best rmse: {best_score:.4f}, Params: {best_params}")print('所有参数训练列表',params_list)print(f"Optimized Parameters: {best_params}")# 导出参数训练过程params_jilu = pd.concat([pd.DataFrame(params_list),pd.DataFrame(rmse_list)],axis=1)params_jilu.rename(columns={0:'rmse'})print(params_jilu.head(3))# 5.训练模型print("训练模型中...")model,bset_rmse = normal_Prophet.fit(best_params,cus_df, holidays_df=holidays)# 6. 生成预测(预测未来24小时)print("生成预测...")forecast = normal_Prophet.predict(periods=16) # 96个15分钟=24小时# 7. 对比结果true_result =normal_Prophet.result_data(cus_df,forecast)# 8. 可视化结果print("生成整体可视化...")fig1 = model.plot(forecast)fig2 = normal_Prophet.plot_components(forecast)plt.show()
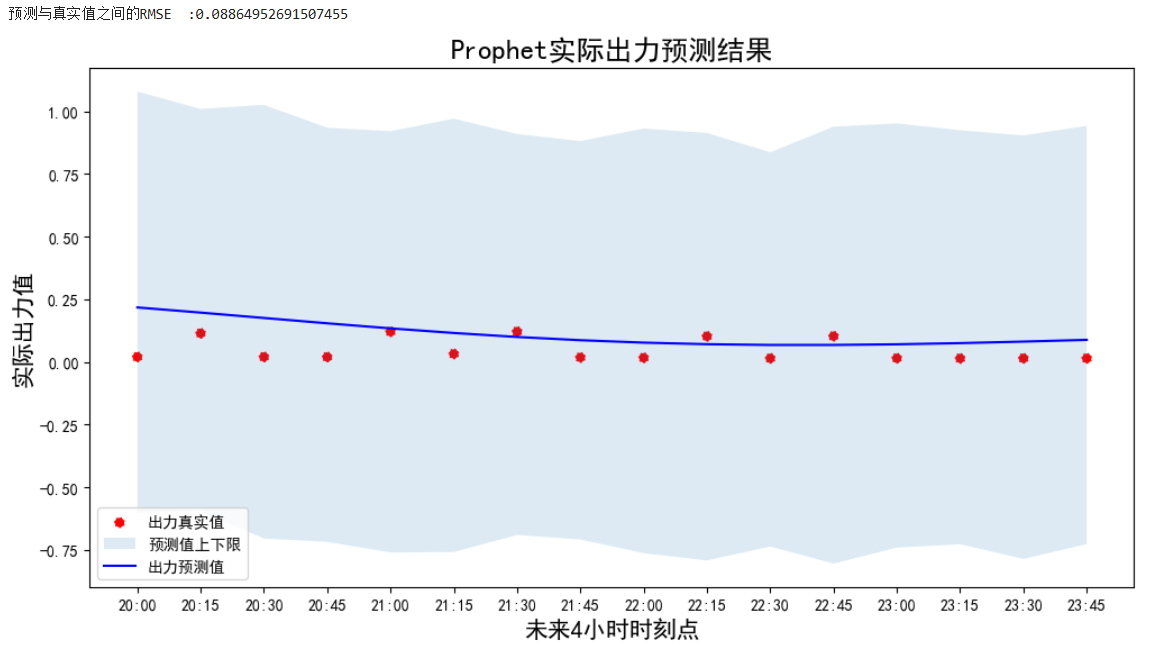
结果展示
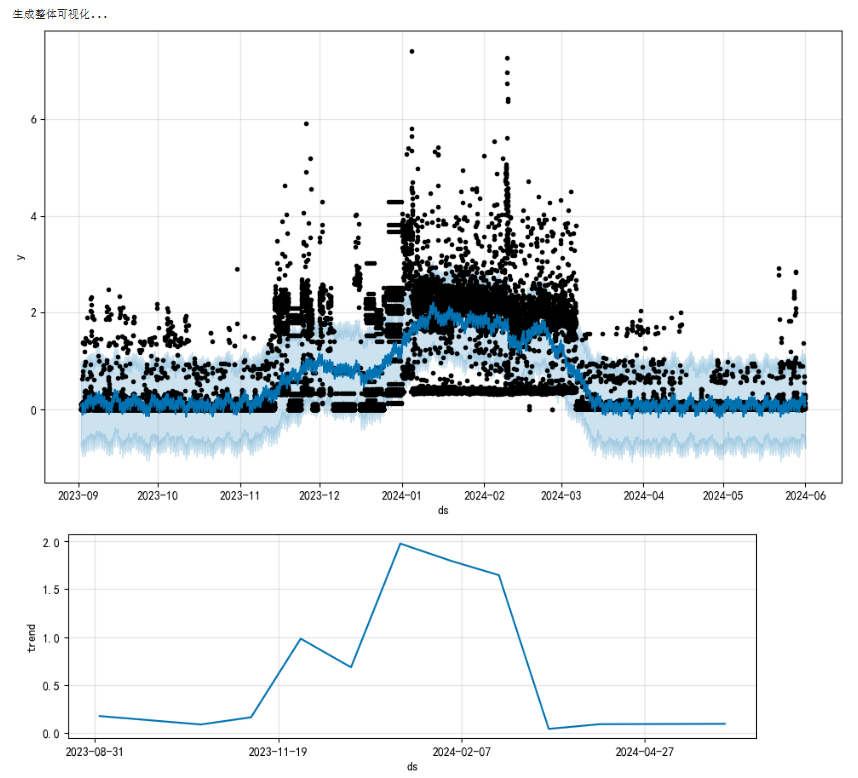
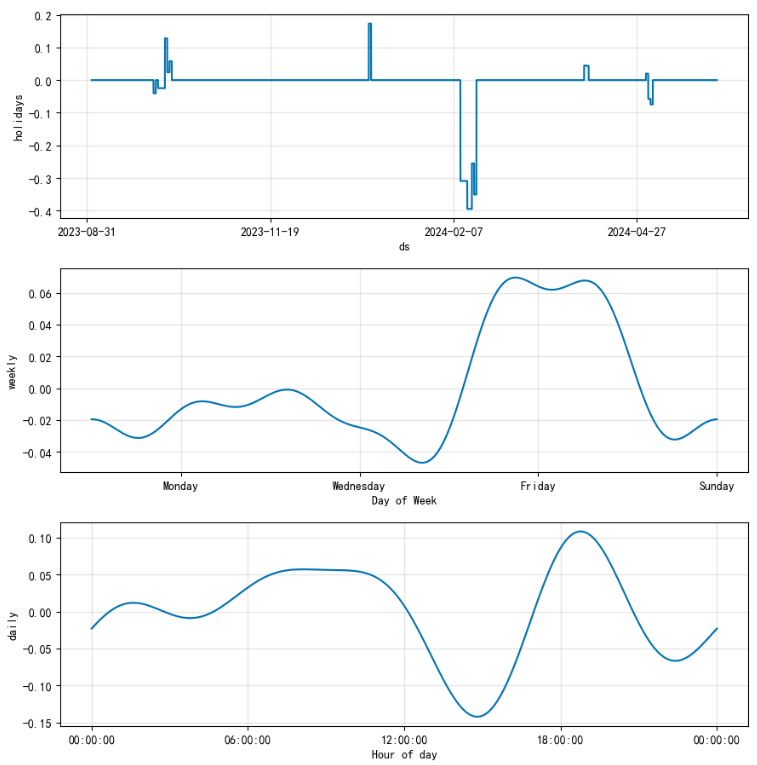
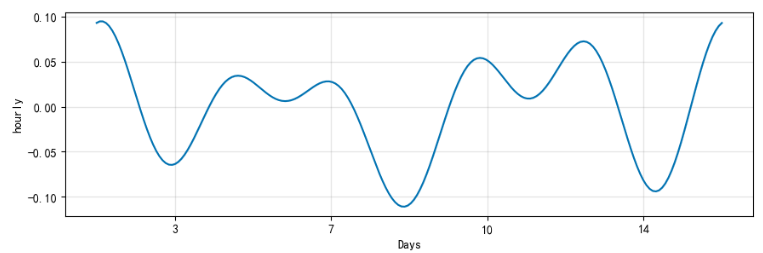
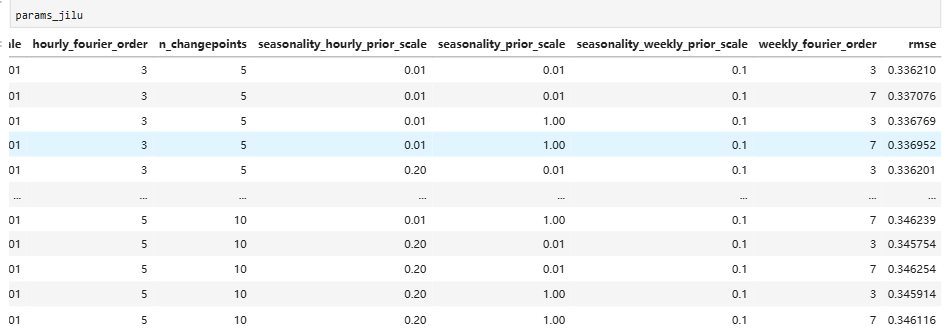

prophet 添加外部数据进行模型优化
大家都熟知prophet 的输入为两列[‘ds’,‘y’]数据,但是 Prophet 模型中整合其他外部数据(如促销活动、天气、经济指标等),可以使用 add_regressor() 方法添加额外的回归变量,从而使模型达到更好的效果。
model.add_regressor('XX', prior_scale=15, mode='additive') # 重要变量
model.add_regressor('ZZ', prior_scale=0.5, mode='additive')# 次要变量
# prior_scale: 控制正则化强度(默认0.5,值越大影响越大)
# mode: 可选 'additive'(默认)或 'multiplicative'model.fit(df)
future = model.make_future_dataframe(periods=30)
#未来外部变量的值需要事先确定在future 中
future = future.merge(pd.DataFrame({'ds': pd.date_range(start='2020-01-01', periods=395), # 合并未来30天的外部数据'XX': [1 if d.day == 15 else 0 for d in future['ds']], 'YY': np.sin(np.linspace(0, 10.5, 395)) * 10 + 25 }),on='ds',how='left'
)
forecast = model.predict(future)
评估回归器影响
# 查看回归器系数
print(model.params['beta'][:, 0]) # 第一个回归器的系数轨迹# 计算贡献度
regressor_effects = forecast[['ds', 'XX', 'ZZ']].copy()
regressor_effects['XX_effect'] = forecast['trend'] * model.params['beta'][0, 0]
regressor_effects['ZZ_effect'] = forecast['trend'] * model.params['beta'][0, 1]
正常的组件图 (plot_components) 将显示外部变量的影响,由于这里的数据不涉及外部变量,所以这里不和第一部分的参数优化融合在一起。
相关文章:
Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...