【深度学习】从现代C++中的开始:卷积
一、说明
在上一个故事中,我们介绍了机器学习的一些最相关的编码方面,例如 functional 规划、矢量化和线性代数规划。
本文,让我们通过使用 2D 卷积实现实际编码深度学习模型来开始我们的道路。让我们开始吧。
二、关于本系列
我们将学习如何仅使用普通和现代C++对必须知道的深度学习算法进行编码,例如卷积、反向传播、激活函数、优化器、深度神经网络等。

查看其他故事:
0 — 现代C++深度学习编程基础
2 — 使用 Lambda 的成本函数
3 — 实现梯度下降
4 — 激活函数
...更多内容即将推出。
三、卷 积
卷积是信号处理领域的老朋友。最初,它的定义如下:

在机器学习术语中:
- 我(...通常称为输入
- K(...作为内核,以及
- F(...)作为给定 K 的 I(x) 的特征映射。
考虑一个多维离散域,我们可以将积分转换为以下求和:
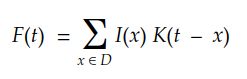
最后,对于2D数字图像,我们可以将其重写为:

理解卷积的一种更简单的方法是下图:
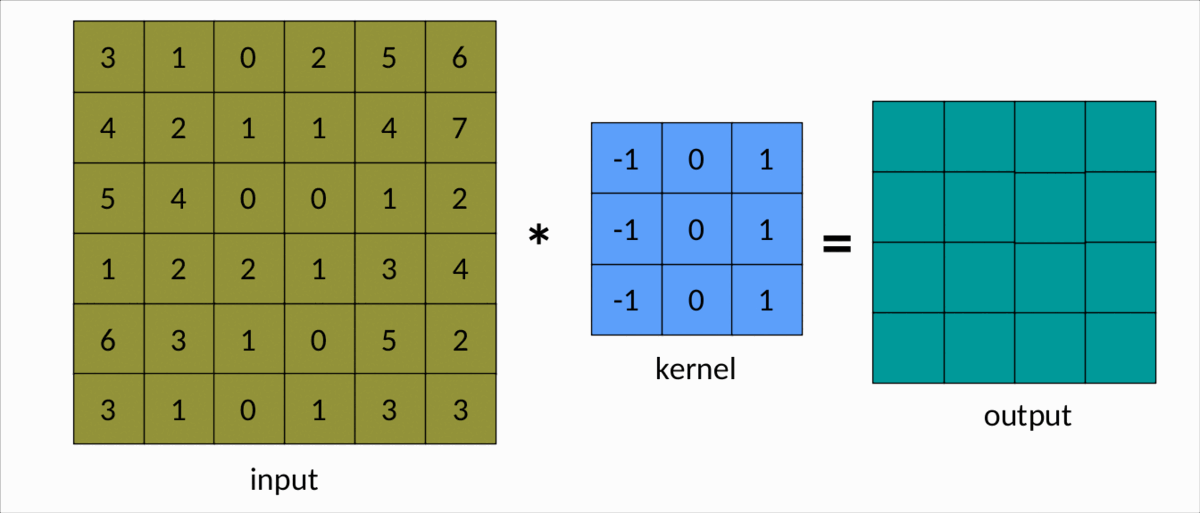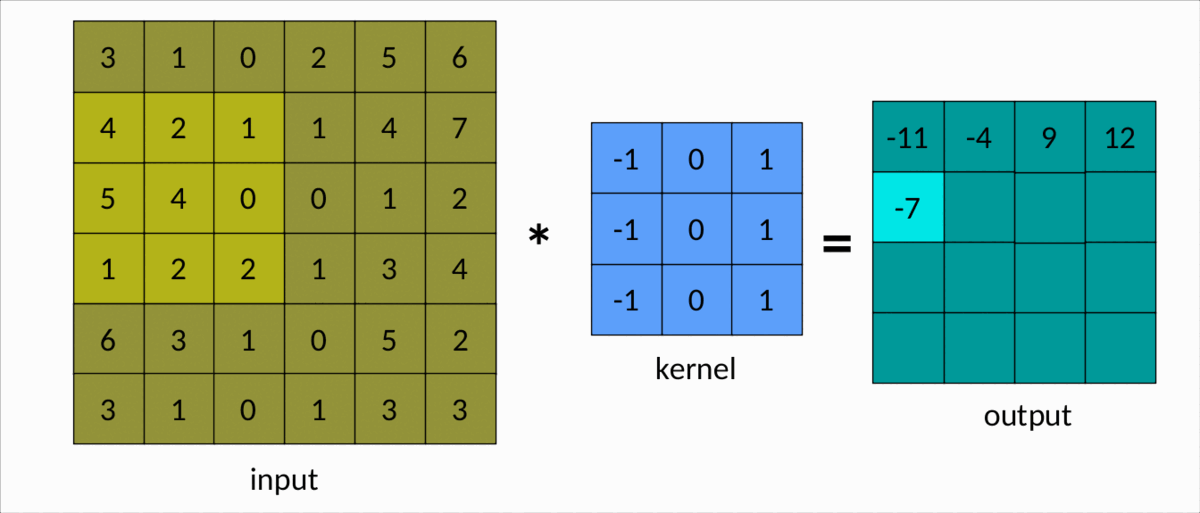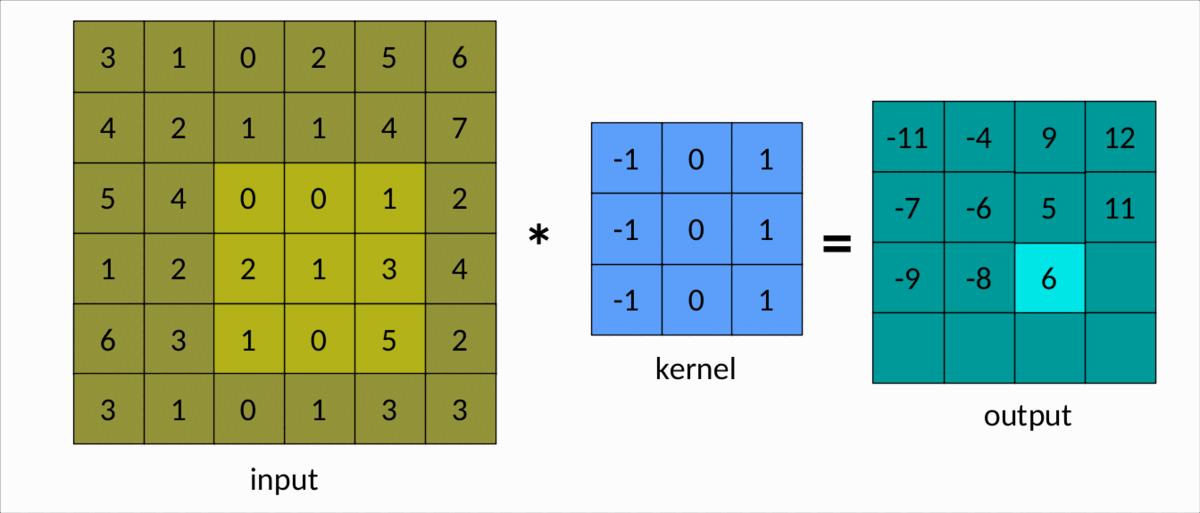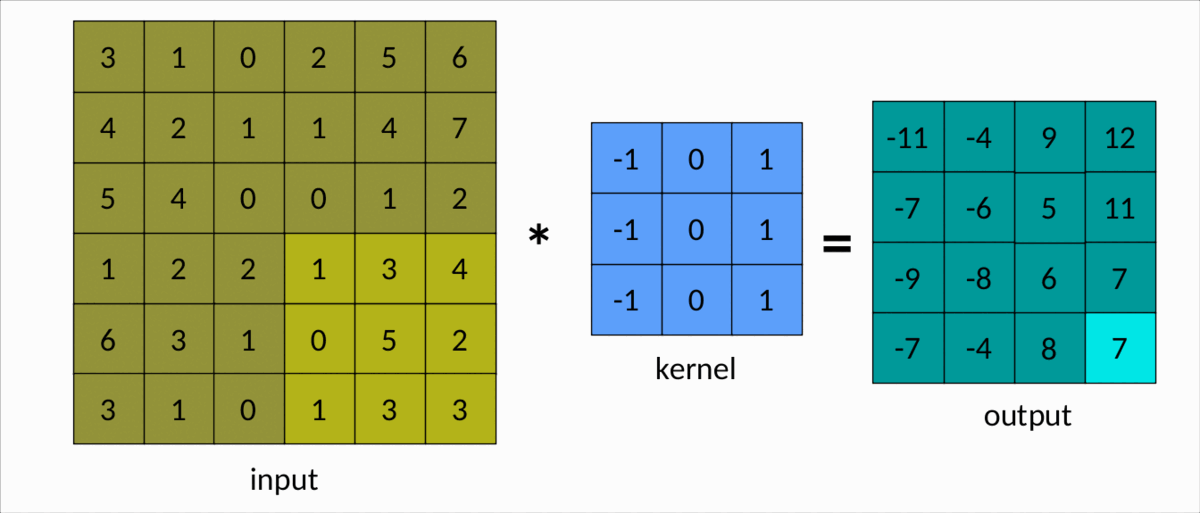
我们可以很容易地看到内核在输入矩阵上滑动,生成另一个矩阵作为输出。这是卷积的简单情况,称为有效卷积。在这种情况下,矩阵的维度由下式给出:Output
dim(Output) = (m-k+1, n-k+1)
这里:
m分别是输入矩阵中的行数和列数,以及nk是平方核的大小。
现在,让我们对第一个 2D 卷积进行编码。
四、使用循环对 2D 卷积进行编码
实现卷积的最直观方法是使用循环:
auto Convolution2D = [](const Matrix &input, const Matrix &kernel)
{const int kernel_rows = kernel.rows();const int kernel_cols = kernel.cols();const int rows = (input.rows() - kernel_rows) + 1;const int cols = (input.cols() - kernel_cols) + 1;Matrix result = Matrix::Zero(rows, cols);for (int i = 0; i < rows; ++i) {for (int j = 0; j < cols; ++j) {double sum = input.block(i, j, kernel_rows, kernel_cols).cwiseProduct(kernel).sum();result(i, j) = sum;}}return result;
};这里没有秘密。我们将内核滑过列和行,为每个步骤应用内积。现在,我们可以像以下那样简单地使用它:
#include <iostream>
#include <Eigen/Core>using Matrix = Eigen::MatrixXd;auto Convolution2D = ...;int main(int, char **)
{Matrix kernel(3, 3);kernel << -1, 0, 1,-1, 0, 1,-1, 0, 1;std::cout << "Kernel:\n" << kernel << "\n\n";Matrix input(6, 6);input << 3, 1, 0, 2, 5, 6,4, 2, 1, 1, 4, 7,5, 4, 0, 0, 1, 2,1, 2, 2, 1, 3, 4,6, 3, 1, 0, 5, 2,3, 1, 0, 1, 3, 3;std::cout << "Input:\n" << input << "\n\n";auto output = Convolution2D(input, kernel);std::cout << "Convolution:\n" << output << "\n";return 0;
}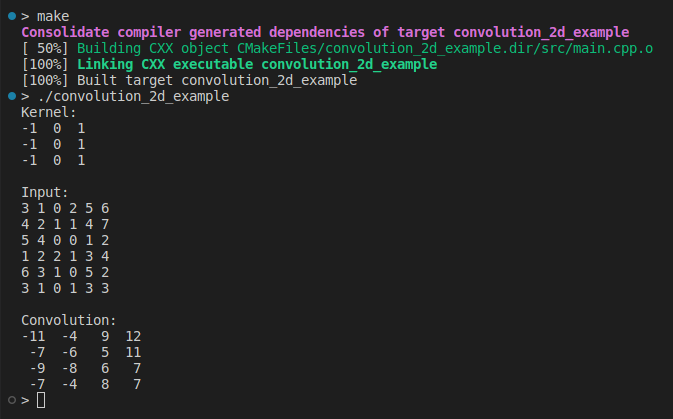
这是我们第一次实现卷积 2D,设计为易于理解。有一段时间,我们不关心性能或输入验证。让我们继续前进以获得更多见解。
在接下来的故事中,我们将学习如何使用快速傅立叶变换和托普利兹矩阵来实现卷积。
五、填充
在前面的示例中,我们注意到输出矩阵始终小于输入矩阵。有时,这种减少是好的,有时是坏的。我们可以通过在输入矩阵周围添加填充来避免这种减少:

填充为 1 的输入图像
卷积中填充的结果如下所示:
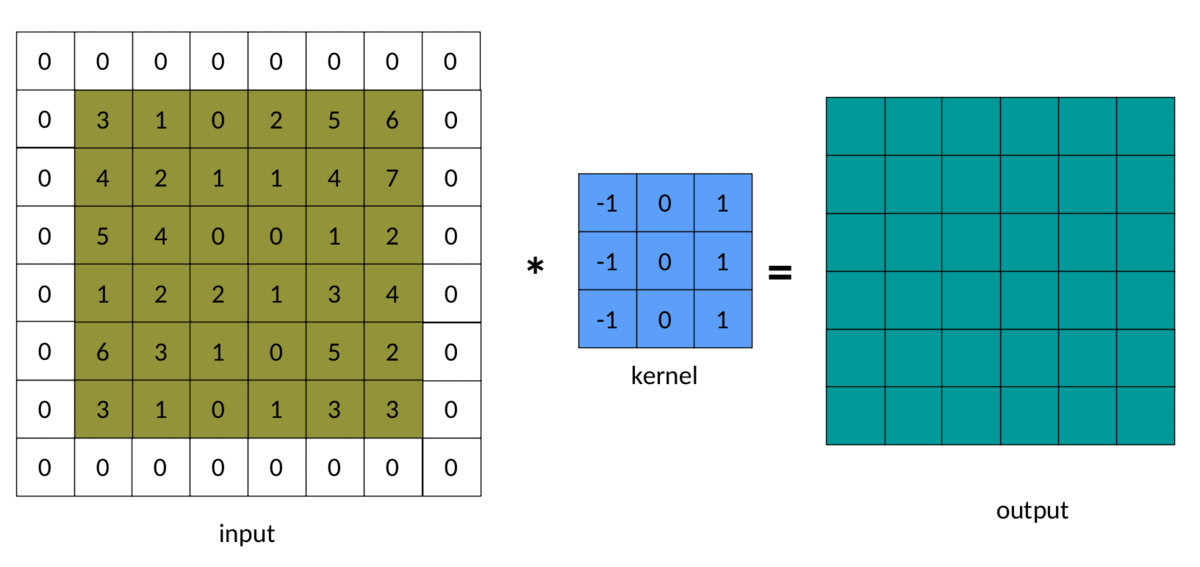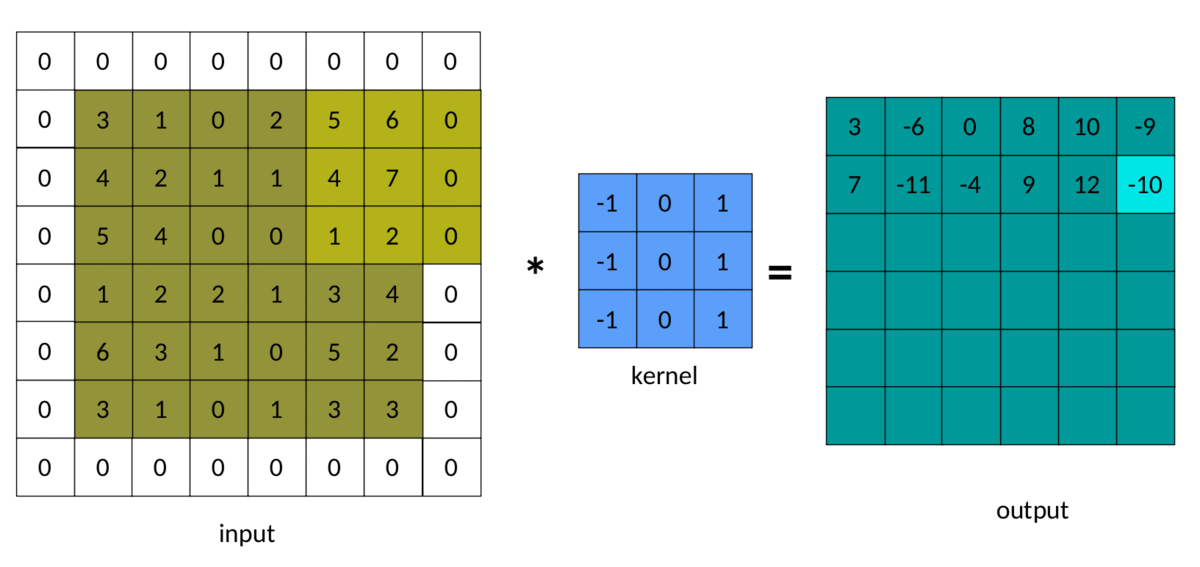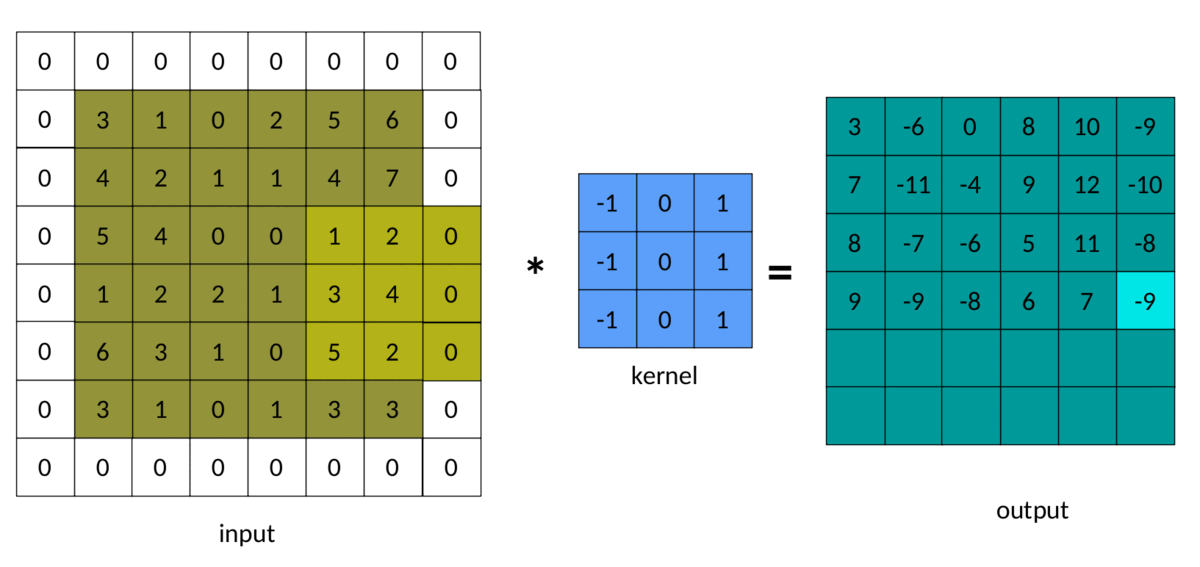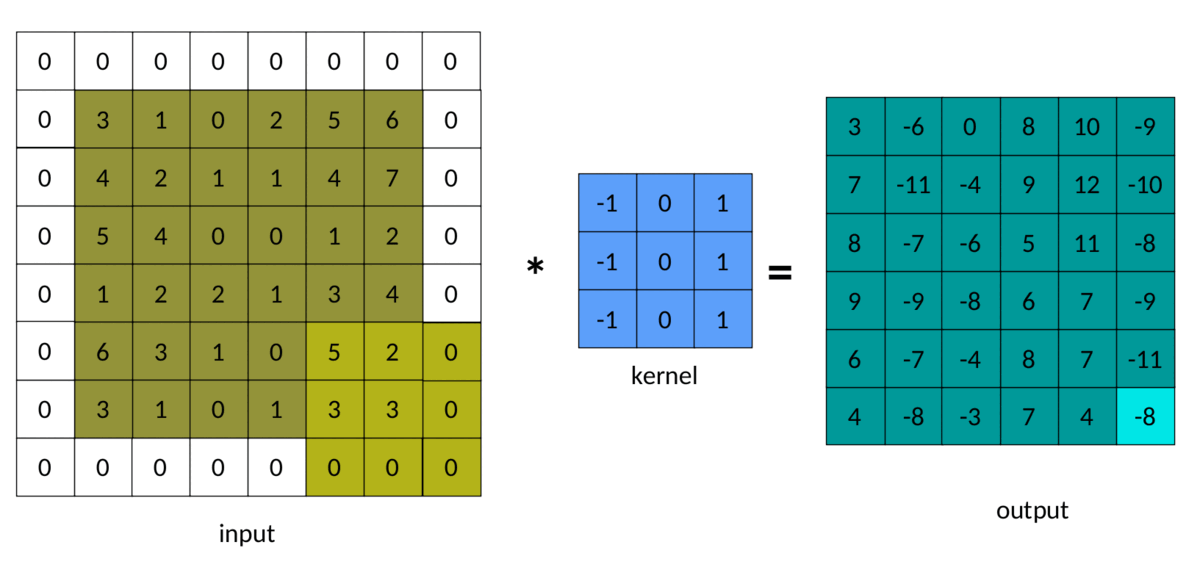
填充卷积 — 作者图片
实现填充卷积的一种简单(和蛮力)方法如下:
auto Convolution2D = [](const Matrix &input, const Matrix &kernel, int padding)
{int kernel_rows = kernel.rows();int kernel_cols = kernel.cols();int rows = input.rows() - kernel_rows + 2*padding + 1;int cols = input.cols() - kernel_cols + 2*padding + 1;Matrix padded = Matrix::Zero(input.rows() + 2*padding, input.cols() + 2*padding);padded.block(padding, padding, input.rows(), input.cols()) = input;Matrix result = Matrix::Zero(rows, cols);for(int i = 0; i < rows; ++i) {for(int j = 0; j < cols; ++j) {double sum = padded.block(i, j, kernel_rows, kernel_cols).cwiseProduct(kernel).sum();result(i, j) = sum;}}return result;
};此代码很简单,但在内存使用方面非常昂贵。请注意,我们正在制作输入矩阵的完整副本以创建填充版本:
Matrix padded = Matrix::Zero(input.rows() + 2*padding, input.cols() + 2*padding);
padded.block(padding, padding, input.rows(), input.cols()) = input;更好的解决方案可以使用指针来控制切片和内核边界:
auto Convolution2D_v2 = [](const Matrix &input, const Matrix &kernel, int padding)
{const int input_rows = input.rows();const int input_cols = input.cols();const int kernel_rows = kernel.rows();const int kernel_cols = kernel.cols();if (input_rows < kernel_rows) throw std::invalid_argument("The input has less rows than the kernel");if (input_cols < kernel_cols) throw std::invalid_argument("The input has less columns than the kernel");const int rows = input_rows - kernel_rows + 2*padding + 1;const int cols = input_cols - kernel_cols + 2*padding + 1;Matrix result = Matrix::Zero(rows, cols);auto fit_dims = [&padding](int pos, int k, int length) {int input = pos - padding;int kernel = 0;int size = k;if (input < 0) {kernel = -input;size += input;input = 0;}if (input + size > length) {size = length - input;}return std::make_tuple(input, kernel, size);};for(int i = 0; i < rows; ++i) {const auto [input_i, kernel_i, size_i] = fit_dims(i, kernel_rows, input_rows);for(int j = 0; size_i > 0 && j < cols; ++j) {const auto [input_j, kernel_j, size_j] = fit_dims(j, kernel_cols, input_cols);if (size_j > 0) {auto input_tile = input.block(input_i, input_j, size_i, size_j);auto input_kernel = kernel.block(kernel_i, kernel_j, size_i, size_j);result(i, j) = input_tile.cwiseProduct(input_kernel).sum();}}}return result;
}; 这个新代码要好得多,因为这里我们没有分配一个临时内存来保存填充的输入。但是,它仍然可以改进。调用和内存成本也很高。input.block(…)kernel.block(…)
调用的一种解决方案是使用 CwiseNullaryOp 替换它们。
block(…)
我们可以通过以下方式运行填充卷积:
#include <iostream>#include <Eigen/Core>
using Matrix = Eigen::MatrixXd;
auto Convolution2D = ...; // or Convolution2D_v2int main(int, char **)
{Matrix kernel(3, 3);kernel << -1, 0, 1,-1, 0, 1,-1, 0, 1;std::cout << "Kernel:\n" << kernel << "\n\n";Matrix input(6, 6);input << 3, 1, 0, 2, 5, 6,4, 2, 1, 1, 4, 7,5, 4, 0, 0, 1, 2,1, 2, 2, 1, 3, 4,6, 3, 1, 0, 5, 2,3, 1, 0, 1, 3, 3;std::cout << "Input:\n" << input << "\n\n";const int padding = 1;auto output = Convolution2D(input, kernel, padding);std::cout << "Convolution:\n" << output << "\n";return 0;
}
请注意,现在,输入和输出矩阵具有相同的维度。因此,它被称为填充。默认填充模式,即无填充,通常称为填充。我们的代码允许 ,或任何非负填充。samevalidsamevalid
六、内核
在深度学习模型中,核通常是奇次矩阵,如、等。有些内核非常有名,比如 Sobel 的过滤器:3x35x511x11
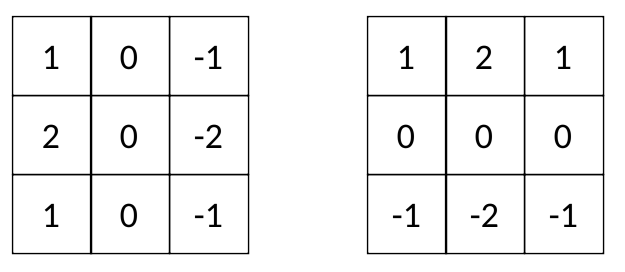
更容易看到每个 Sobel 滤镜对图像的影响:

使用 Sobel 过滤器的代码在这里。
Gy 突出显示水平边缘,Gx 突出显示垂直边缘。因此,Sobel 内核 Gx 和 Gy 通常被称为“边缘检测器”。
边缘是图像的原始特征,例如纹理、亮度、颜色等。现代计算机视觉的关键点是使用算法直接从数据中自动查找内核,例如Sobel过滤器。或者,使用更好的术语,通过迭代训练过程拟合内核。
事实证明,训练过程教会计算机程序实现如何执行复杂的任务,例如识别和检测物体、理解自然语言等......内核的训练将在下一个故事中介绍。
七、结论和下一步
在这个故事中,我们编写了第一个2D卷积,并使用Sobel滤波器作为将此卷积应用于图像的说明性案例。卷积在深度学习中起着核心作用。它们被大量用于当今每个现实世界的机器学习模型中。我们将重新审视卷积,以学习如何改进我们的实现,并涵盖一些功能,如步幅。
相关文章:
【深度学习】从现代C++中的开始:卷积
一、说明 在上一个故事中,我们介绍了机器学习的一些最相关的编码方面,例如 functional 规划、矢量化和线性代数规划。 本文,让我们通过使用 2D 卷积实现实际编码深度学习模型来开始我们的道路。让我们开始吧。 二、关于本系列 我们将学习如何…...

金融数学方法:蒙特卡洛模拟
1.方法介绍 蒙特卡洛模拟是一种基于概率和统计的数值计算方法,用于解决各种复杂问题。它以概率统计为基础,通过随机抽样和重复实验的方式进行模拟,从而得到问题的近似解。它的基本思想是通过大量的随机样本来近似计算问题的解…...

vue 文件扩展名中 esm 、common 、global 以及 mini 、 dev 、prod 、runtime 的含义
vue 文件扩展名中 esm 、common 、global 以及 mini 、 dev 、prod 、runtime 的含义 vue.js 直接用在 script 标签中的完整版本(同时包含编译器 compiler 和运行时 runtime),可以看到源码,适用于开发环境。 这个版本视图可以写在…...

微服务契约测试框架Pact-Python实战
Pact是一个契约测试框架,有多种语言实现,本文以基于pact-python探究契约测试到底是什么?以及如何实现 官网:自述文件 |契约文档 (pact.io) 契约测试步骤 1、为消费者写一个单元测试,让它通过,并生成契约…...

Linux 给用户 赋某个文件夹操作的权限(实现三权分立)
Linux 给用户 赋某个文件夹操作的权限 这里用的ubuntu16.04 一、配置网站管理员 linux文件或目录的权限分为,读、写、可执行三种权限。文件访问的用户类别分为,文件创建者、与文件创建者同组的用户、其他用户三类。 添加用户 useradd -d /var/www/htm…...

【C++入门到精通】C++入门 —— 类和对象(初始化列表、Static成员、友元、内部类、匿名对象)
目录 一、初始化列表 ⭕初始化列表概念 ⭕初始化列表的优点 ⭕使用场景 ⭕explicit关键字 二、Static成员 ⭕Static成员概念 🔴静态数据成员: 🔴静态函数成员: ⭕使用静态成员的优点 ⭕使用静态成员的注意事项 三、友…...

“深入理解Spring Boot:从入门到高级应用“
标题:深入理解Spring Boot:从入门到高级应用 摘要:本文将介绍Spring Boot的基本概念、原理和使用方法,并探讨如何在实际开发中充分发挥Spring Boot的优势。通过详细的示例代码,读者将能够深入理解Spring Boot的各个方…...

Apache Spark 的基本概念和在大数据分析中的应用
Apache Spark是一种快速、通用、可扩展的大数据处理引擎,用于大规模数据处理任务,如批处理、交互式查询、实时流处理、机器学习和图形处理等。它的主要特点包括: 1. 速度:Spark使用In-Memory计算技术,将计算结果存储在…...
Debian LNMP架构的简单配置使用
一、LNMP简介 LinuxNginxMysqlPHP组成的网站架构,常用于中小型网站服务。 二、环境 Debian 6.1.27-1kali1 (2023-05-12) Nginx/1.22.1 10.11.2-MariaDB(mysql) PHP 8.2.7 (Debian 6.1.27包含以上包,直接使用即…...
CAN转EtherNet/IP网关can协议破解服务
JM-EIP-CAN 是自主研发的一款 ETHERNET/IP 从站功能的通讯网关。该产品主要功能是将各种 CAN 总线和 ETHERNET/IP 网络连接起来。 本网关连接到 ETHERNET/IP 总线中做为从站使用,连接到 CAN 总线中根据节点号进行读写。 技术参数 ETHERNET/IP 技术参数 网关做为 …...
最适合新手的Java项目/SpringBoot+SSM项目《苍穹外卖》/项目实战、笔记(超详细、新手)[持续更新……]
小知识 软件设计中提到的UI设计中的UI是什么意思? 在软件设计中,UI设计中的UI是User Interface的简称,即用户界面。UI设计是指对软件的人机交互、操作逻辑、界面美观的整体设计。好的UI设计可以让软件变得有个性有品位,同时让操作…...

CloudDriver一款将各种网盘云盘挂在到电脑本地变成本地磁盘的工具 教程
平时我们的电脑可能由于大量的文件资料之类的导致存储空间可能不够,所以我们可以选择将网盘我们的本地磁盘用来存放东西。 CloudDrive 是一款可以将 115、阿里云盘、天翼云盘、沃家云盘、WebDAV 挂载到电脑中,成为本地硬盘的工具,支持 Window…...

行为型模式之中介者模式
中介者模式(Mediator Pattern) 中介者模式是一种行为型设计模式,旨在通过封装一系列对象之间的交互方式,使其能够独立地进行通信。 中介者模式的核心思想是将对象之间的直接通信改为通过一个中介者对象来进行间接通信,…...
BPMNJS插件使用及汉化(Activiti绘制流程图插件)
BPMNJS插件运行最重要的就是需要安装nodejs插件,这不一定要安装和测试好。 主要是使用npm命令 1、配置BPMNJS插件绘制activiti7工作流 1.1、安装和配置nodejs 插件 1.1.1、下载nodejs 下载地址:https://nodejs.org/en 1.1.2、安装nodejs,傻瓜式安装 安装之后在安装…...

STM32使用HAL库中外设初始化MSP回调机制及中断回调机制详解
STM32使用HAL库之Msp回调函数 1.问题提出 在STM32的HAL库使用中,会发现库函数大都被设计成了一对: HAL_PPP/PPPP_Init HAL_PPP/PPPP_MspInit 而且HAL_PPP/PPPP_MspInit函数的defination前面还会有__weak关键字 上面的PPP/PPPP代表常见外设的名称为…...
创建、删除、添加数据)
Hutool工具类FileUtil----文件(夹)创建、删除、添加数据
1.文件(夹)创建 //创建文件,多级目录会循环创建出来String path "d:/hutool_test/hutool_test.txt";File touch FileUtil.touch("d:/hutool_test/hutool_test.txt");2.文件(夹)的校验 boolean isFile FileUtil.isFil…...

Flink - souce算子
水善利万物而不争,处众人之所恶,故几于道💦 目录 1. 从Java的集合中读取数据 2. 从本地文件中读取数据 3. 从HDFS中读取数据 4. 从Socket中读取数据 5. 从Kafka中读取数据 6. 自定义Source 官方文档 - Flink1.13 1. 从Java的集合中读取数据 …...
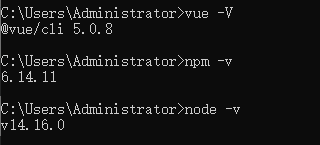
使用vue creat搭建项目
一、查看是否安装node和npm(显示版本号说明安装成功) node -v npm -v 显示版本号说明安装成功,如果没有安装,则需要先安装。 二、安装vue-cli脚手架 查看安装的版本(显示版本号说明安装成功) vue -V 三…...

面试题 -- 基础知识
文章目录 1. 深拷贝 和 浅拷贝的区别2. 懒加载模式3. frame和bounds有什么不同?4. What is push notification?推送实现 5. 什么是序列化?6. 什么是安全释放7. 响应者链8. 简述沙盒机制 1. 深拷贝 和 浅拷贝的区别 浅拷贝是指针拷贝…...

Zabbix分布式监控快速入门
目录 1 Zabbix简介1.1 软件架构1.2 版本选择1.3 功能特性 2 安装与部署2.1 时间同步需求2.2 下载仓库官方源2.3 Zabbix-Server服务端的安装2.3.1 安装MySQL2.3.1.1 创建Zabbix数据库2.3.1.2 导入Zabbix库的数据文件 2.3.2 配置zabbix_server.conf2.3.3 开启Zabbix-Server服务2.…...

DownGit终极指南:3分钟掌握GitHub精准下载技巧
DownGit终极指南:3分钟掌握GitHub精准下载技巧 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 你是否曾经在GitHub上找到心仪的代码片段,却不得不下载整个庞大的项目仓库?或…...

别再死磕SAR ADC了!聊聊那些被低估的‘算法ADC’与‘流水线ADC’实战选型心得
算法ADC与流水线ADC实战选型指南:突破SAR ADC的思维定式 在嵌入式系统与传感器信号链设计中,模数转换器(ADC)的选择往往直接决定整个系统的性能天花板。当工程师们面对"高精度低速"、"中速中精度"和"高速高动态范围"等不同…...

MoE架构揭秘:逐Token路由与活跃参数量的工程真相
1. 项目概述:当“千亿参数”不再是个吓人的数字,而是一套精打细算的调度系统你肯定见过这类标题:“GPT-4拥有1.8万亿参数!”——第一反应是震撼,第二反应是疑惑:我的显卡连加载一个7B模型都得开量化&#x…...

STM32F103C6T6模拟SPI驱动ADS1220:从硬件连接到代码调试的完整避坑指南
STM32F103C6T6模拟SPI驱动ADS1220:从硬件连接到代码调试的完整避坑指南 在嵌入式开发领域,高精度数据采集一直是工程师们面临的挑战之一。TI公司的ADS1220作为一款24位Δ-Σ模数转换器,以其出色的噪声性能和灵活的配置选项,成为许…...

为什么选择Minimal:GitHub Pages最简洁主题的深度解析与快速入门指南
为什么选择Minimal:GitHub Pages最简洁主题的深度解析与快速入门指南 【免费下载链接】minimal Minimal is a Jekyll theme for GitHub Pages 项目地址: https://gitcode.com/gh_mirrors/mini/minimal Minimal主题是GitHub Pages平台上最受欢迎、最简洁的Jek…...

新手教程使用curl命令通过Taotoken测试大模型API连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手教程:使用curl命令通过Taotoken测试大模型API连通性 当你刚刚在Taotoken平台创建了API Key,最直接、最…...

基准测试结果刚出炉,DeepSeek在医疗/法律/金融三大垂直领域事实准确率对比,谁在说真话?
更多请点击: https://intelliparadigm.com 第一章:基准测试结果刚出炉,DeepSeek在医疗/法律/金融三大垂直领域事实准确率对比,谁在说真话? 我们基于权威垂直领域评测集——MedMCQA(医疗)、Case…...

Unlock Music终极指南:5分钟掌握音乐格式转换的隐藏技巧
Unlock Music终极指南:5分钟掌握音乐格式转换的隐藏技巧 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: htt…...

Oracle替代之路:企业去O过程中常见的坑与避坑指南
📌 关键词:Oracle替代、国产数据库、去O、数据库迁移、信创、兼容性、高可用大家好!我是数据库小学妹 👋 最近发现一个有意思的现象:不管是金融、运营商还是政务单位,聊到数据库规划,三句话不离…...

Rescuezilla:3步轻松搞定系统备份与恢复的瑞士军刀
Rescuezilla:3步轻松搞定系统备份与恢复的瑞士军刀 【免费下载链接】rescuezilla The Swiss Army Knife of System Recovery 项目地址: https://gitcode.com/gh_mirrors/re/rescuezilla 当你面对电脑系统崩溃、硬盘损坏或数据丢失的紧急情况时,是…...