Flink - souce算子
水善利万物而不争,处众人之所恶,故几于道💦
目录
1. 从Java的集合中读取数据
2. 从本地文件中读取数据
3. 从HDFS中读取数据
4. 从Socket中读取数据
5. 从Kafka中读取数据
6. 自定义Source
官方文档 - Flink1.13

1. 从Java的集合中读取数据
fromCollection(waterSensors)
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);List<WaterSensor> waterSensors = Arrays.asList(new WaterSensor("ws_001", 1577844001L, 45),new WaterSensor("ws_002", 1577844015L, 43),new WaterSensor("ws_003", 1577844020L, 42));env.fromCollection(waterSensors).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
运行结果:

2. 从本地文件中读取数据
readTextFile(“input/words.txt”),支持相对路径和绝对路径
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);env.readTextFile("input/words.txt").print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
运行结果:

3. 从HDFS中读取数据
readTextFile(“hdfs://hadoop101:8020/flink/data/words.txt”)
要先在pom文件中添加hadoop-client依赖:
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version>
</dependency>
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);env.readTextFile("hdfs://hadoop101:8020/flink/data/words.txt").print();try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
运行结果:

4. 从Socket中读取数据
socketTextStream(“hadoop101”,9999),这个输入源不支持多个并行度。
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);//从端口中读数据, windows中 nc -lp 9999 Linux nc -lk 9999env.socketTextStream("hadoop101",9999).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
运行结果:

5. 从Kafka中读取数据
addSource(new FlinkKafkaConsumer<>(“flink_source_kafka”,new SimpleStringSchema(),properties))
第一个参数是topic,
第二个参数是序列化器,序列化器就是在Kafka和flink之间转换数据 - 官方注释:The de-/serializer used to convert between Kafka’s byte messages and Flink’s objects.(反-序列化程序用于在Kafka的字节消息和Flink的对象之间进行转换。)
第三个参数是Kafka的配置。
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);Properties properties = new Properties();// 设置集群地址properties.setProperty("bootstrap.servers", "hadoop101:9092,hadoop102:9092,hadoop103:9092");// 设置所属消费者组properties.setProperty("group.id", "flink_consumer_group");env.addSource(new FlinkKafkaConsumer<>("flink_source_kafka",new SimpleStringSchema(),properties)).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
运行结果:

6. 自定义Source
addSource(new XXXX())
大多数情况下,前面的数据源已经能够满足需要,但是难免会存在特殊情况的场合,所以flink也提供了能自定义数据源的方式.
public class Flink06_myDefDataSource {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);env.addSource(new RandomWatersensor()).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
自定义数据源需要定义一个类,然后实现SourceFunction接口,然后实现其中的两个方法,run和cancel,run方法包含具体读数据的逻辑,当调用cancel方法的时候应该可以让run方法中的读数据逻辑停止
public class RandomWatersensor implements SourceFunction<WaterSensor> {private Boolean running = true;@Overridepublic void run(SourceContext<WaterSensor> sourceContext) throws Exception {Random random = new Random();while (running){sourceContext.collect(new WaterSensor("sensor" + random.nextInt(50),Calendar.getInstance().getTimeInMillis(),random.nextInt(100)));Thread.sleep(1000);}}/*** 大多数的source在run方法内部都会有一个while循环,* 当调用这个方法的时候, 应该可以让run方法中的while循环结束*/@Overridepublic void cancel() {running = false;}}
运行结果:

demo2 - 自定义从socket中读取数据
public class Flink04_Source_Custom {public static void main(String[] args) throws Exception {// 1. 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.addSource(new MySource("hadoop102", 9999)).print();env.execute();}public static class MySource implements SourceFunction<WaterSensor> {private String host;private int port;private volatile boolean isRunning = true;private Socket socket;public MySource(String host, int port) {this.host = host;this.port = port;}@Overridepublic void run(SourceContext<WaterSensor> ctx) throws Exception {// 实现一个从socket读取数据的sourcesocket = new Socket(host, port);BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8));String line = null;while (isRunning && (line = reader.readLine()) != null) {String[] split = line.split(",");ctx.collect(new WaterSensor(split[0], Long.valueOf(split[1]), Integer.valueOf(split[2])));}}/*** 大多数的source在run方法内部都会有一个while循环,* 当调用这个方法的时候, 应该可以让run方法中的while循环结束*/@Overridepublic void cancel() {isRunning = false;try {socket.close();} catch (IOException e) {e.printStackTrace();}}}
}
/*
sensor_1,1607527992000,20
sensor_1,1607527993000,40
sensor_1,1607527994000,50*/
相关文章:
Flink - souce算子
水善利万物而不争,处众人之所恶,故几于道💦 目录 1. 从Java的集合中读取数据 2. 从本地文件中读取数据 3. 从HDFS中读取数据 4. 从Socket中读取数据 5. 从Kafka中读取数据 6. 自定义Source 官方文档 - Flink1.13 1. 从Java的集合中读取数据 …...
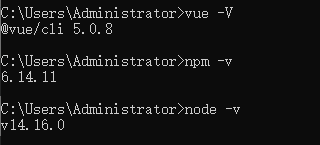
使用vue creat搭建项目
一、查看是否安装node和npm(显示版本号说明安装成功) node -v npm -v 显示版本号说明安装成功,如果没有安装,则需要先安装。 二、安装vue-cli脚手架 查看安装的版本(显示版本号说明安装成功) vue -V 三…...

面试题 -- 基础知识
文章目录 1. 深拷贝 和 浅拷贝的区别2. 懒加载模式3. frame和bounds有什么不同?4. What is push notification?推送实现 5. 什么是序列化?6. 什么是安全释放7. 响应者链8. 简述沙盒机制 1. 深拷贝 和 浅拷贝的区别 浅拷贝是指针拷贝…...

Zabbix分布式监控快速入门
目录 1 Zabbix简介1.1 软件架构1.2 版本选择1.3 功能特性 2 安装与部署2.1 时间同步需求2.2 下载仓库官方源2.3 Zabbix-Server服务端的安装2.3.1 安装MySQL2.3.1.1 创建Zabbix数据库2.3.1.2 导入Zabbix库的数据文件 2.3.2 配置zabbix_server.conf2.3.3 开启Zabbix-Server服务2.…...
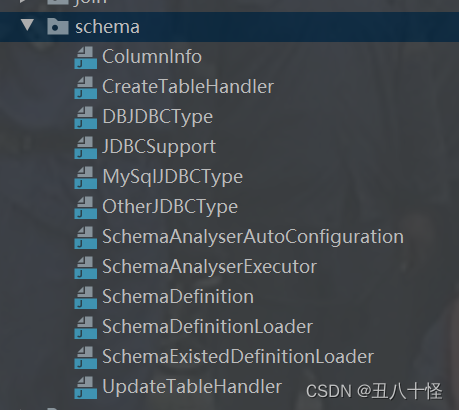
基于Spring包扫描工具和MybatisPlus逆向工程组件的数据表自动同步机制
公司产品产出的项目较多。同步数据库表结构工作很麻烦。一个alter语句要跑到N个客户机上执行脚本。超级费时麻烦。介于此,原有方案是把增量脚本放到一resource包下,项目启动时执行逐行执行一次。但由于模块开发人员较多,总有那么一两个机灵鬼…...
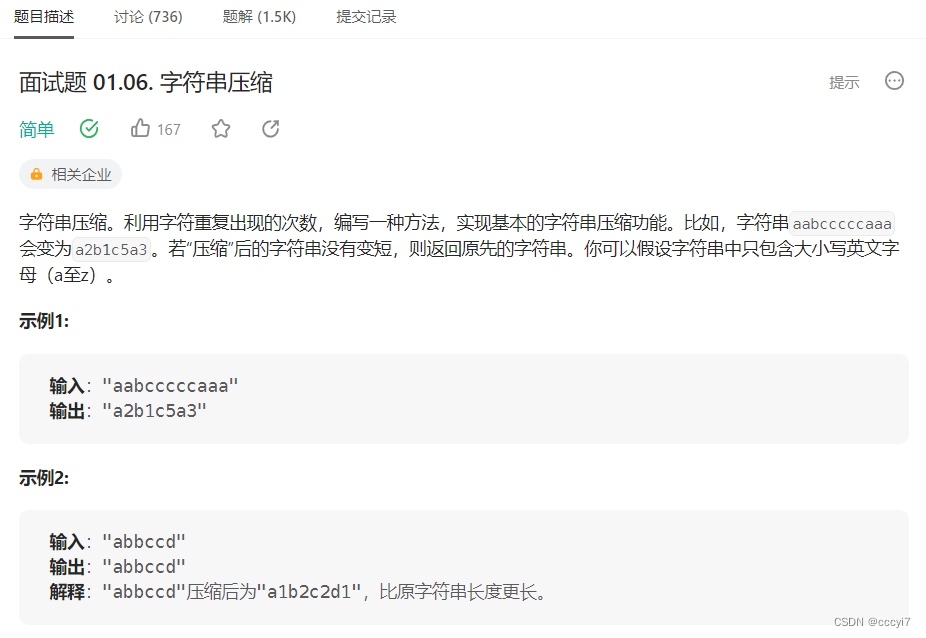
leetcode 面试题 0106.字符串压缩
⭐️ 题目描述 🌟 leetcode链接:面试题 0106.字符串压缩 思路: 开辟一个新的空间(空间要大一点,因为可能压缩后的字符串比原字符串大),然后遍历原字符串统计当前字符的个数,再写入到…...
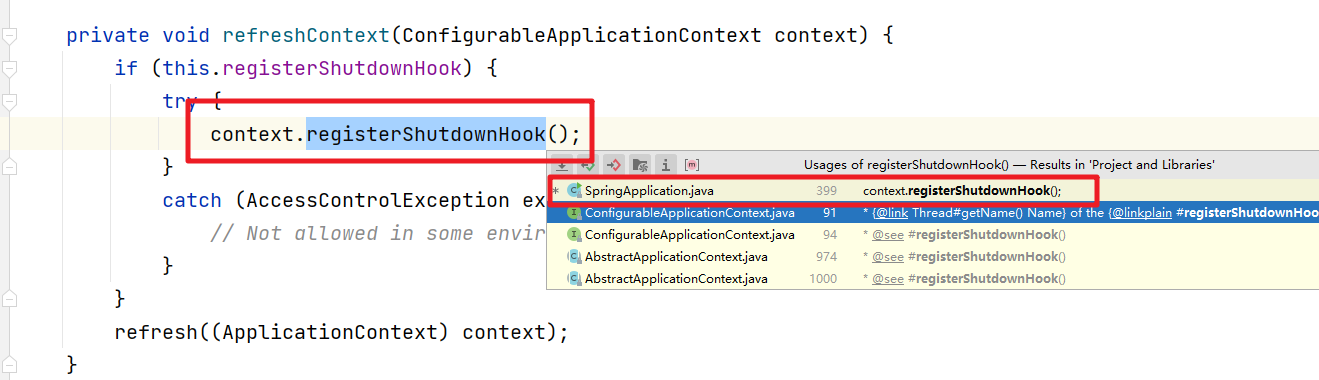
三、Spring源码-实例化
Spring源码-Bean的实例化 接下来我们看看Bean的实例化处理 一、BeanDefinition 首先我们来看看BeanDefinition的存放位置。因为Bean对象的实例化肯定是BeanFactory基于对应的BeanDefinition的定义来实现的,所以在这个过程中BeanDefinition是非常重要的,…...

算法的法律框架:预测未来的关键趋势
随着科技的飞速发展,算法和人工智能(AI)已成为我们社会生活的重要组成部分。然而,它们也带来了许多新的法律和道德挑战,这使得算法的法律框架变得日益重要。在这个背景下,预测未来算法法律框架的关键趋势成…...
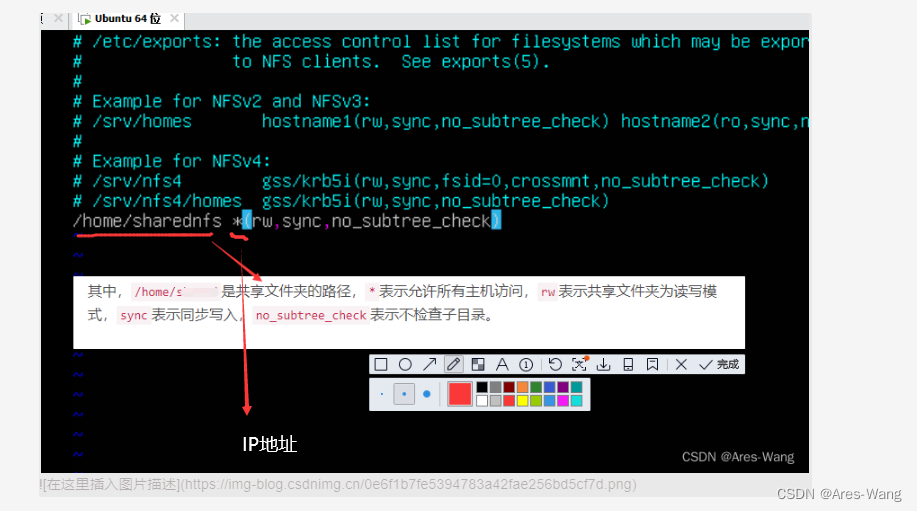
Ubuntu Server版 之 共享文件 samba和NFS 两种方法
NFS 和 Samba NFS : linux之间资源共享 Samba: 是windows系统与Linux系统之间资源共享的 samba 安装samba 工具 sudo apt install samba 创建共享目录 sudo mkdir /home/shared sudo chmod 777 /home/shared 配置sambd sudo vim /etc/samba/smb.con…...

实时协作:团队效率倍增的关键
实时协作是指团队在当前时刻共同完成项目的能力。无论是否使用技术,都能实现这一点。然而,随着远程工作的盛行,安全的协作工具被用来让团队成员在项目和一般业务之间保持联系和同步。 传统协作与实时协作的区别 两种类型的协作最明显的区别…...

电脑选睡眠、休眠还是关机?
关机 这是大家最熟悉的。关机时,系统首先关闭所有运行中的程序,然后关闭系统后台服务。随后,系统向主板请求关机,主板断开电源的供电使能,让电源切断对绝大多数设备的供电(只剩一些内部零件仍会维持电源供应…...
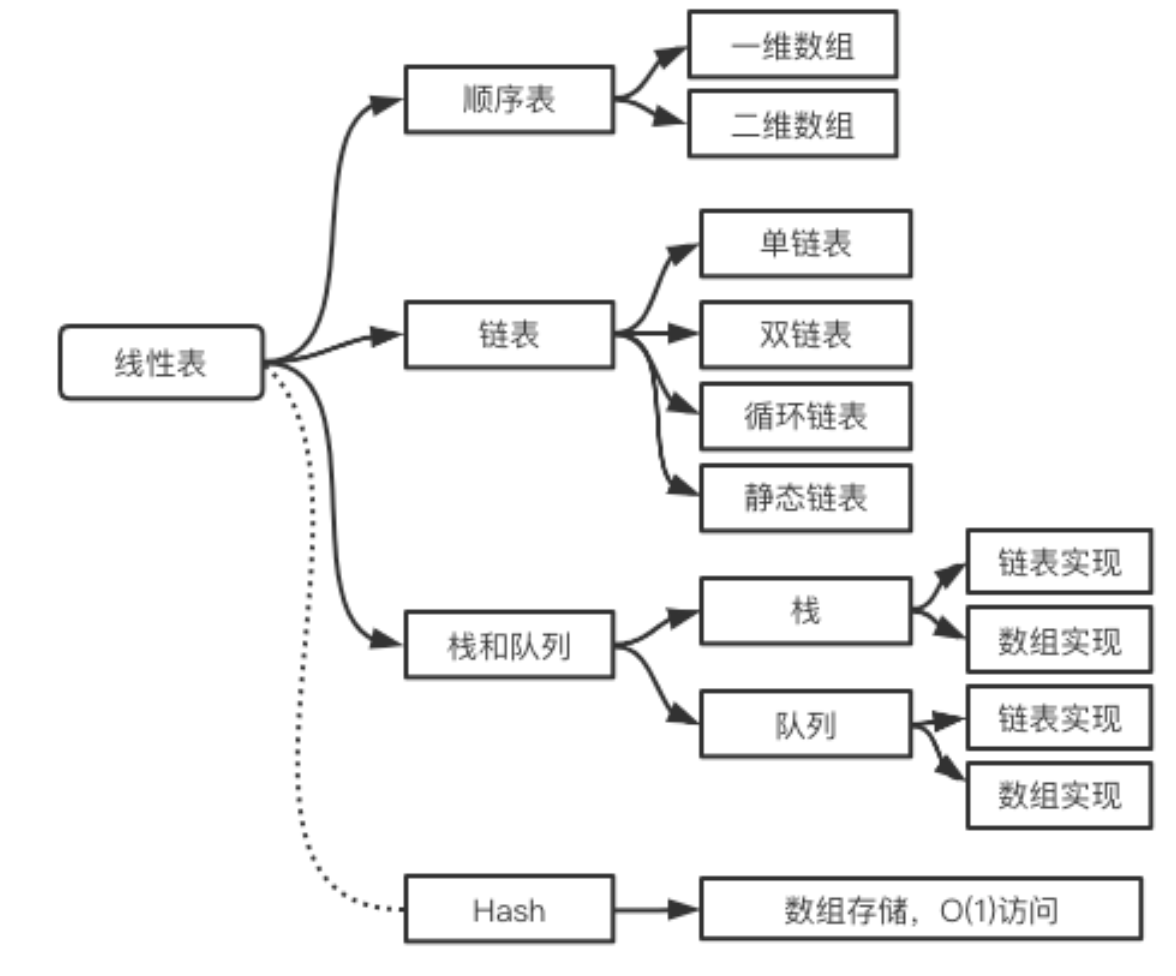
算法通关村第三关——不简单的数组增删改查
线性表基础 线性表概念 线性表就是具有相同特征数据元素的一个有限序列,其中包含元素的个数称为线性表的长度 线性表类型 从不同的角度看,线性表有不同的分类 语言实现角度 顺序表有两种实现方式 一体式 分离式 一体式结构 一体式:存储信息…...
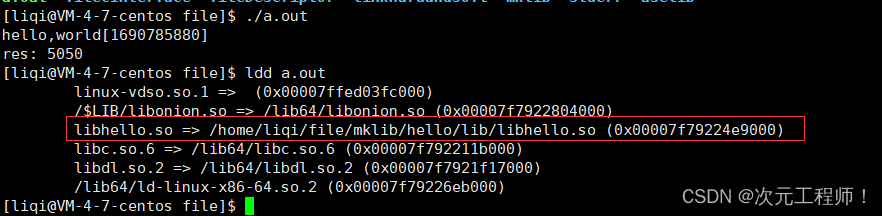
【Linux】动静态库
目录 写在前面的话 如何编写静态库库 编写静态库 ar命令 Makefile自动化形成静态库 如何使用编写的静态库 1.拷贝到系统路径中 2.指定路径搜索 如何编写动态库 编写动态库 完善Makefile 如何使用编写的动态库 指定路径搜索(不可行及原因) 环境变量LD_LIBRARY_PAT…...

《kubernetes权威指南》-第一章学习笔记
1.什么是kubernetes? kubernetes是一个全新的基于容器技术的分布式架构领先方案。 2.为什么要用kubernetes? 使用kubernetes提供的解决方案能够减少30%的开发成本,并且能够将开发人员的精力更加集中于业务本身,同时可以降低系统…...

ubuntu 18.04 磁盘太满无法进入系统
安装了一个压缩包,装了一半提示磁盘空间少导致安装失败。我也没在意,退出虚拟机打算扩展硬盘。等我在虚拟机设置中完成扩展操作,准备进入虚拟机内部进行操作时,发现登录不进去了 shift 登入GUN GRUB设置项的问题 网上都是在开机…...

基于LNMP配置WordPress建站时出现的问题汇总
目录 wordpress上传文件报错问题描述原因分析:解决方案: wordpress裁剪图片报错问题描述原因分析:解决方案: 配置固定链接和伪链接 wordpress上传文件报错 WP内部错误,在上传文件时发生了错误,显示权限不足…...
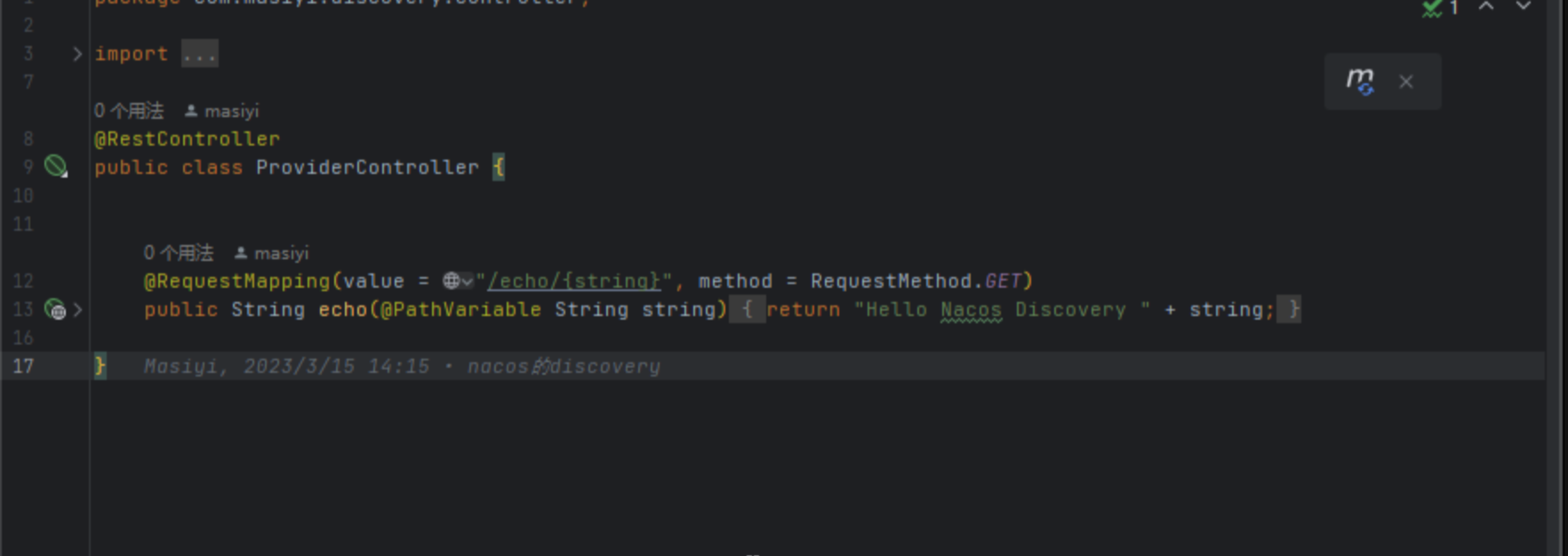
【Spring Cloud】Gateway的配置与使用
文章目录 前言第一步,创建一个springboot工程第二步,添加依赖第三步,编写yml文件第四步,启动主启动类总结 前言 Gateway其实是springcloud 原生的东西,但是我还是想放在这里讲,因为我们使用nacos时&#x…...

概念、框架简介--ruoyi学习(一)
开始进行ruoyi框架的学习,比起其他的前后端不分离的,这个起码看的清晰一些吧。 这一节主要是看了ruoyi的官方文档后,记录了以下不懂的概念,并且整理了ruoyi框架中的相关内容。 一些概念 前端 store store是状态管理库&#x…...

IDEA的基础使用——【初识IDEA】
IDEA的基础使用——【初识IDEA】 文章目录 IDEA简介前言官网 IDEA的下载与安装选择下载路径勾选自己需要的其余按默认选项进行即可 目录简介安装目录简介 运行Hello WorldIDEA快捷键常用模板模板一:psvm(main)模板二:模板三&#…...

LeetCode刷题总结-动态规划篇
LeetCode刷题总结-动态规划篇 本文总结LeetCode上有动态规划的算法题,推荐刷题总数为54道。具体考点分析如下图: 1.中心扩展法 题号:132. 分割回文串 II,难度困难 2.背包问题 题号:140. 单词拆分 II,难…...

百度文库纯净阅读助手:三分钟实现广告屏蔽与PDF导出
百度文库纯净阅读助手:三分钟实现广告屏蔽与PDF导出 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 您是否曾在百度文库上查阅资料时,被满屏的广告、VIP提示和干扰元素所困…...

【产品发布】建享云智能单据扫描仪正式上线,一站式解决单据数字化处理难题
建享云正式推出全新智能单据扫描仪,聚焦各行业单据数字化处理的核心痛点,无需复杂部署流程、无需专业技术支撑,轻松适配个人办公与企业级各类场景。本文将简洁明了地介绍产品核心功能、操作方法及适配范围,帮助用户快速了解产品价…...

单物体最优抓取轨迹生成
基于 3D 位姿规划直线平滑抓取轨迹,包含趋近 - 抓取 - 复位三段最优运动路径,适配机械臂点位运动核心规划逻辑基准位:机械臂初始安全待机点趋近段:直线匀速靠近物体上方预备抓取点抓取段:垂直下落至物体抓取中心位姿抬…...

Mythos模型:通用AI在漏洞挖掘与 exploit 生成中的范式跃迁
1. 这不是一次普通升级:Mythos 的能力跃迁到底意味着什么“Claude Mythos Preview”——这个名字在2026年4月的AI圈里炸开时,我正调试一个用Opus 4.6做代码审计的自动化流水线。看到基准测试数据的第一反应不是兴奋,而是下意识关掉了终端窗口…...

3D-LLM:面向可制造性的三维语言模型技术解析
1. 项目概述:当大语言模型开始“看见”三维空间“From Text to Tangible: 3D-LLM Unleashes Language Models into the 3D World”——这个标题不是科幻小说的副标题,而是2024年真实出现在CVPR和ICML顶会workshop上的技术路线宣言。我第一次在arXiv上读到…...

终极指南:3分钟学会用Awoo Installer免费安装Switch游戏
终极指南:3分钟学会用Awoo Installer免费安装Switch游戏 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游戏安装而烦恼吗…...

7步掌握思源宋体TTF:从零基础到专业应用全攻略
7步掌握思源宋体TTF:从零基础到专业应用全攻略 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 思源宋体(Source Han Serif)是一款由Google与Adobe联…...

如何快速解锁QQ音乐加密音频的完整指南:QMCDecode工具终极解决方案
如何快速解锁QQ音乐加密音频的完整指南:QMCDecode工具终极解决方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&…...

终极AMD Ryzen性能调优指南:SMUDebugTool完全掌握手册
终极AMD Ryzen性能调优指南:SMUDebugTool完全掌握手册 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gi…...

RLHF工程化实践:用合成反馈替代人工标注的完整闭环
1. 这不是“替代人类”的口号,而是一套可落地的RLHF工程闭环“Build Your Own RLHF LLM — Forget Human Labelers!” 这个标题一出来,很多同行第一反应是皱眉——不是质疑技术可行性,而是警惕它背后可能隐含的简化主义陷阱。我带过三轮大模型…...