Python-如何使用正则表达式
如何利用Python使用正则表达式
目录
正则表达式常用匹配规则
编辑re库的使用
match()方法:
search()方法:
findall()方法 :
sub()方法:
compile()方法;
通用匹配
贪婪与非贪婪匹配
贪婪匹配
非贪婪匹配
修饰符
转义匹配
正则表达式是处理字符的强大工具,他有自己特定的语法结构,有了它,实现字符串的检索,替换,匹配验证都不在话下,不止如此,正则表达式可以从HTML中非常方便地提取想要的信息
正则表达式常用匹配规则
对于URL来说,正则表达式可以用下面的正则表达式来匹配:
[a-zA-Z]+://[^\s]*这个正则表达式看上去十分的糟糕,其实里面都包含了特定的语法规则。比如,a-z代表匹配任意的小写字母,\s表示匹配任意的空白字符,*就代表匹配前面的字符任意多个,这一长串的正则表达式就是这么多平匹配规则的组合。
所以当写完正则表达式后,就可以拿他去一个字符串里匹配查找,不论这个字符串里有什么,这要符合我们写的规范,就统统可以找出来
下面列出常用的匹配规则:
参考来源:开发过程最全的正则表达式匹配中英文、字母和数字

re库的使用
正则表达式不是Python独有的,但Python的re库提供了整个正则表达式的实现,利用re库,就可以在Python中使用正则表达式,下面开始介绍它的一些常用方法:
match()方法:
match方法会尝试从字符的起始位置匹配正则表达式,如果匹配,就返回匹配成功;如果不匹配,就会返回None。示例如下:
import re
content = "Hello world 123 1234 Hello_my world"
print(len(content))
result = re.match('^Hello\s\w\w\w\w\w\s\d{3}\s\d{4}\s\w{8}',content)
print(result)结果显式:

在这里,首先声明了一段字符串content,里面包含了英文字母,空白字符,数字等等,接下来,我们写了一段正则表达式:
^Hello\s\w\w\w\w\w\s\d{3}\s\d{4}\s\w{8}用来匹配这个长字符。^是匹配字符串的开头,也就是说以Hello为开头;然后\s来匹配空白字符;\w匹配字母,5个\w代表匹配5个字母;后面还有阿拉伯数字,如果单纯只用\d\d\d来匹配,非常麻烦,所以\d后面可以跟着{3}代表匹配3个阿拉伯数字,以此类推写出了我们得到正则表达式。其实,我们并没有将字符串完整的匹配下来,但我们仍然可以进行匹配,只不过只是截取字符的一部分来进行匹配而已。
而在match()方法中,第一个参数传入正则表达式,第二个参数传入要匹配的字符。
在打印输出的结果,可以看到结果是re.Match对象,说明匹配成功,但是如果单纯的打印result。则会显示:
<re.Match object; span=(0, 29), match=‘Hello world 123 1234 Hello_my’>
所以一下有两种方法可以更好的进行查看
group()方法:可以输出匹配到的内容,结果是Hello world 123 1234 Hello_my
span()方法: 可以输出匹配的范围,结果是(0,29)
当然match()方法还可以将想要提取的字符串中,提出一部分内容;只需用()将想要的字符串括起来,被括起来的每一个子表达式会一次对应分组,调用group()方法传入分组的索引即可获取提取的结果,示例如下:
import re
content = "Hello world 123 1234 Hello_my world"
print(len(content))
result = re.match('^Hello\s\w\w\w\w\w\s\d{3}\s(\d+)\s\w{8}',content)
print(result)
print(result.group())
print(result.group(1))
print(result.span())
结果显示:
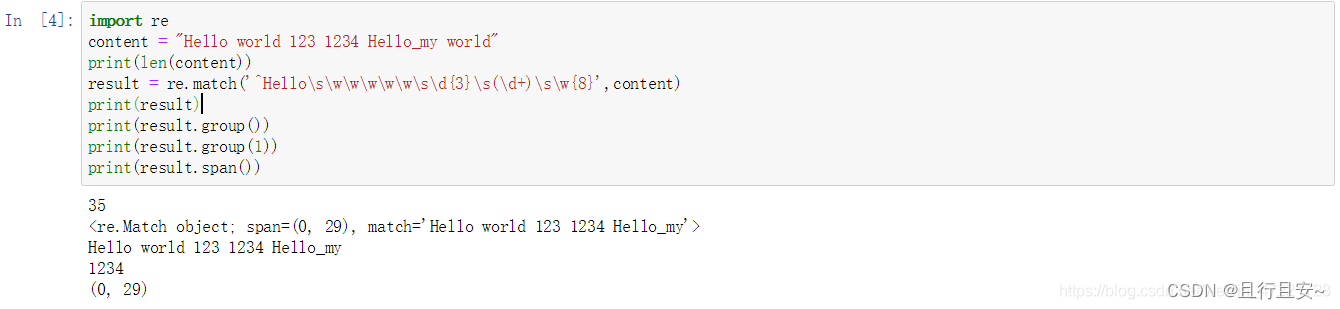
这里将group(1)打印,我们成功得到了1234,如果正则表达式中还有被()包裹的内容,那么可以依次使用group(2),group(3)来获取.
search()方法:
前面讲到match()方法是从字符串开头开始匹配的,一旦开头不匹配,那么整个匹配就是失败了,请看下面例子:
import re
content = "Hello world 123 1234 Hello_my world"
print(len(content))
result = re.match('ello\s\w\w\w\w\w\s\d{3}\s\d{4}\s\w{8}',content)
print(result)
对于上面代码,相对之前,我们只去掉了开头的H,则变成了以下的结果:

但是我们用search()来替换match(),可以看见:

因此,为了方便,我们可以尽量使用search()方法.
findall()方法 :
在介绍search()方法同时,我们发现,不管是match()方法,还是search()方法都只能返回匹配到的第一个内容,但是如果想要获取匹配正则表达式的所有内容,那该怎么办呢?这时就要借助findall()方法了.该方法会搜索整个字符,然后返回匹配正则表达式的所有内容.
因为用法类似,这里只介绍作用,就不用代码演示了
sub()方法:
除了使用正则表达式提取信息外,有时候还需要借助它来修改文本.比如,想把一串文本中的所有数字都去掉,如果只用字符串的replace()方法,那就太繁琐了,这时可以借助sub()方法.示例如下:
import re
content = "Hello world 123 1234 Hello_my world"
print(len(content))
result = re.sub('\d+','',content)
print(result)结果显式:

这里只需要给第一个参数传入匹配的字符(这里是\d+,代表所有数字),第二个参数为替换的字符串(这里是’’,及空字符,我们需要将所有的数字删掉),第三个参数是原字符串.
可以看见所有的数字都被删除
compile()方法;
前面方法都是用来处理字符串的方法,最后介绍一下compile()方法,这个方法可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用,示例如下:
import re
content = "Hello world 123 1234 Hello_my world"
demo = re.compile('\d+')
result = re.sub(demo,'',content)
print(result)结果显式:

这里我们和上题一样,是想要删除字符串里面的数字,和上题不同的是,我们利用compile()方法制作了正则表达式对象,在后面使用时,可以直接套用此对象,更加的方便,快捷
通用匹配
之前我们所写的正则表达式其实比较复杂,出现空白字符我们写\s,出现数字写\d,如果每次书写都这样繁琐,工作量会变得非常大.其实完全没有必要,因为还有一个万能匹配可以使用,那就是.* ,其中.可以匹配任意字符(除了换行符),*可以匹配前面的字符无数次,所以它们合在一起就可以匹配任意字符了,因此,我们可以改写:
import re
content = "Hello world 123 1234 Hello_my world"
print(len(content))
result = re.search('.*',content)
print(result)
print(result.group())
print(result.span())结果如下:

.*非常简单的匹配到了我们所有的字符
贪婪与非贪婪匹配
贪婪匹配
在使用.*时,有时候并不能匹配到我们想要得到结果,请看下面例子:
import re
content = "Hello world 123 1234 Hello_my world"
print(len(content))
result = re.search('H.*(\d+)\s\d{4}\s\w{8}',content)
print(result)
print(result.group())
print(result.group(1))
print(result.span())结果如下:

在这里,我们只想匹配到1前面的内容,再利用group(1)输出123,可是结果只显示了3,这是因为在贪婪模式下,.*会进可能的匹配更多的字符,.*后面是\d+,也就是至少一个字符,并没有指定多少个数字,因此,.*就尽可能的匹配更多的字符,这里就将12匹配了,给\d+留下来一个可满足条件的3了.
非贪婪匹配
前面,因为贪婪匹配,我们没有得到想要的结果,那该怎么办我们才可以匹配出自己想要的字符’123’呢?,其实,只需要使用非贪婪匹配就好了,非贪婪匹配的写法是.?,多了一个?,这样非贪婪模式会竟可能匹配少的字符,与贪婪模式相反,这样当匹配到Hello后面的字符时,后面就是数字了,而\d+正好可以匹配,.?就不会取匹配,交给后面的\d+了.
示例如下:
import re
content = "Hello world 123 1234 Hello_my world"
print(len(content))
result = re.search('H.*?(\d+)\s\d{4}\s\w{8}',content)
print(result)
print(result.group())
print(result.group(1))
print(result.span())结果显式:

所以,做匹配的过程中因尽量使用非贪婪匹配,以免出现匹配结果缺失的情况.
修饰符
正则表达式可包含一些可选修饰符来控制匹配的模式,我们可以用实例来看看:
当我们使用修饰符时,结果如下:
import re
content = '''Hello world 123
1234 Hello_my world'''
print(len(content))
result = re.search('.*',content,re.S)
print(result)
print(result.group())
print(result.span())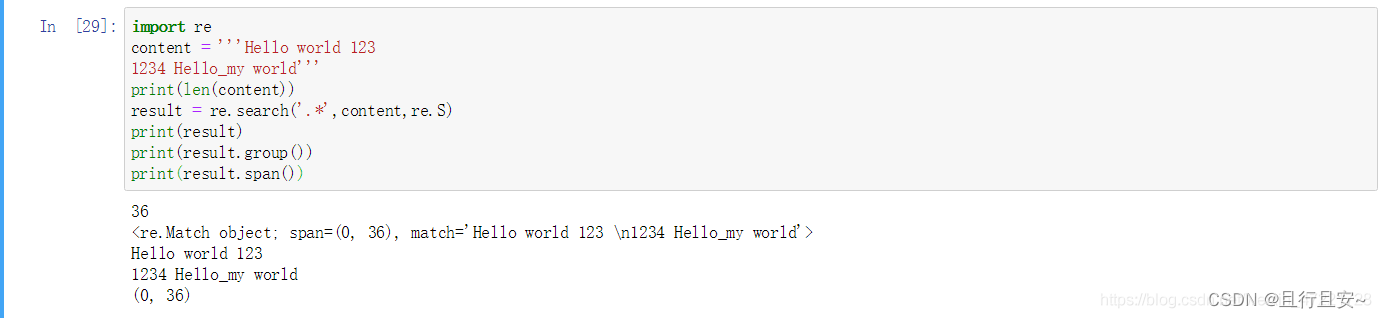
可以看到,没有使用修饰符时,字符串没有匹配完全,而加了修饰符才可以正确显式
修饰符 描述
re.I 使匹配对大小写不敏感
re.L 做本地化识别(locale-aware)匹配
re.M 使能够多行匹配,影响 ^ 和 $
re.S 让点 . 匹配包括换行在内的所有字符
re.U 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解
其中,较为常用的有re.S和re.I
转义匹配
正则表达式定义了许多匹配模式,如.用来匹配除了换行符之外的任意字符,但如果我们需要匹配的目标字符包含.该怎么办?这里就需要用到转义匹配了,当遇到用于正则匹配模式的特殊字符时,只需要在前面加反斜杠转义一下即可,例如可以用.来匹配.
相关文章:
Python-如何使用正则表达式
如何利用Python使用正则表达式 目录 正则表达式常用匹配规则 编辑re库的使用 match()方法: search()方法: findall()方法 : sub()方法: compile()方法; 通用匹配 贪婪与非贪婪匹配 贪婪匹配 非贪婪匹配 修饰符 转义匹配 正则表达式是处理字符的强大…...

分解质因子,将一个不小于2的整数分解质因数,例如,输入90,则输出:90=2*3*3*5
假设一个不小于2的整数n,对从2开始的自然数k,这个试探它是否是整数n的一个因子,如果是,则输出该因子,并将n/k的结果赋给n(接下来只需要对n除以已经找到的因子之后的结果继续找因子)。如果n的值不…...
C语言,vs各种报错分析(不断更新)
1.引发了异常: 写入访问权限冲突2.#error: Error in C Standard Library usage 1.引发了异常: 写入访问权限冲突 这里是malloc没有包含头文件<stdlib.h>,包含之后就好了 2.#error: Error in C Standard Library usage 这里就是用C语言写程序时使用了C的头文件…...

AR开发平台 | 探索AR技术在建筑设计中的创新应用与挑战
随着AR技术的不断发展和普及,越来越多的建筑师开始探索AR技术在建筑设计中的应用。AR(增强现实)技术可以通过将虚拟信息叠加到现实场景中,为设计师提供更加直观、真实的建筑可视化效果,同时也可以为用户带来更加沉浸式的体验。 AR开发平台广…...

小白到运维工程师自学之路 第六十集 (docker的概述与安装)
一、概述 1、客户(老板)-产品-开发-测试-运维项目周期不断延后,项目质量差。 随着云计算和DevOps生态圈的蓬勃发展,产生了大量优秀的系统和软件。软件开发人员可以自由选择各种软件应用环境。但同时带来的问题就是需要维护一个非…...
SpringBoot 集成 Elasticsearch
一、版本 spring-boot版本:2.3.7.RELEASEElasticsearch7.8.0版本说明详见 二、Elasticsearch 下载和安装 Elasticsearch 下载 kibana下载 ik分词器下载 配置IK分词器 2.1 解压,在elasticsearch-7.8.0\plugins 路径下新建ik目录 2.2 将ik分词器解压放…...

【ES】使用日志记录
1、修改操作 1、要删除Elasticsearch索引的分区下的数据 <index_name>是要删除数据的索引名称。这个命令会删除该索引下的所有数据。 POST /<index_name>/_delete_by_query {"query": {"match_all": {}} }2、删除特定条件下的数据 要删除a…...
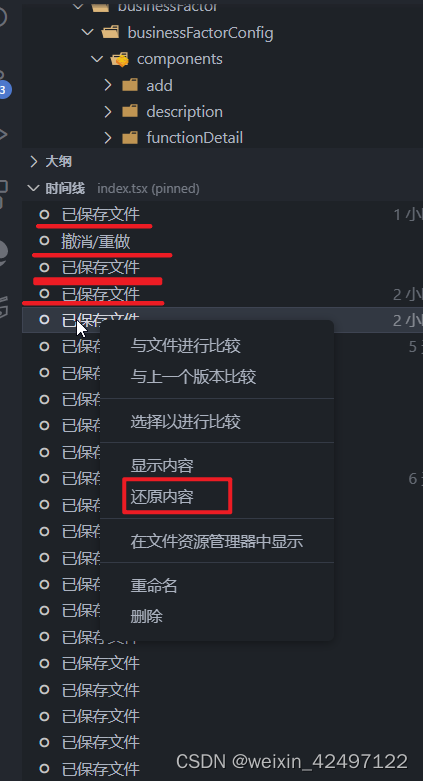
svn还原本地代码
svn代码还原 问题描述:在vscode中修改了代码,没有提交,而且不小心点击了svn更新,导致本地修改的最新代码被覆盖,因为没有提交,所以远程仓库中也没有刚才修改的代码记录 解决: 通过vscode的时间…...
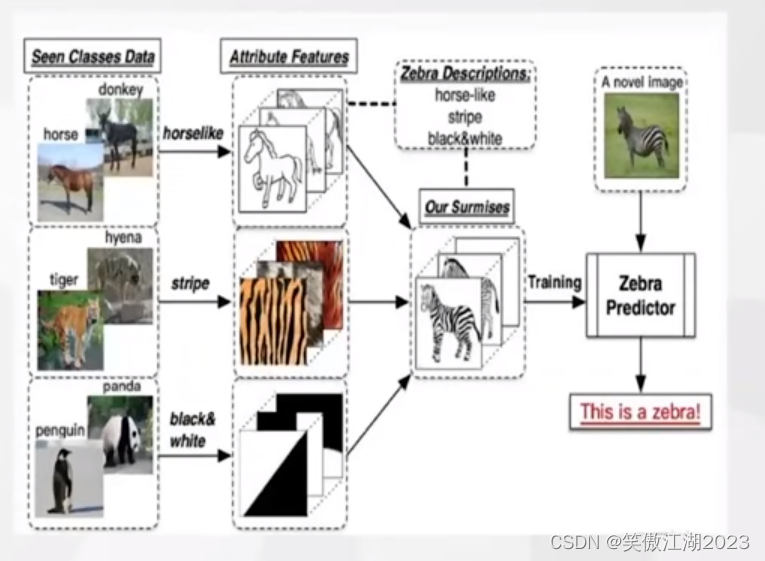
zore-shot,迁移学习和多模态学习
1.zero-shot 定义:在ZSL中,某一类别在训练样本中未出现,但是我们知道这个类别的特征,然后通过语料知识库,便可以将这个类别识别出来。概括来说,就是已知描述,对未知类别(未在训练集中…...

【Golang 接口自动化07】struct转map的三种方式
目录 背景 struct转map 使用json模块 使用reflect模块 使用第三方库 测试 总结 资料获取方法 背景 我们在前面介绍过怎么使用net/http发送json或者map数据,那么它能不能直接发送结构体数据呢?我们今天一起来学习结构体struct转map的三种方法&am…...
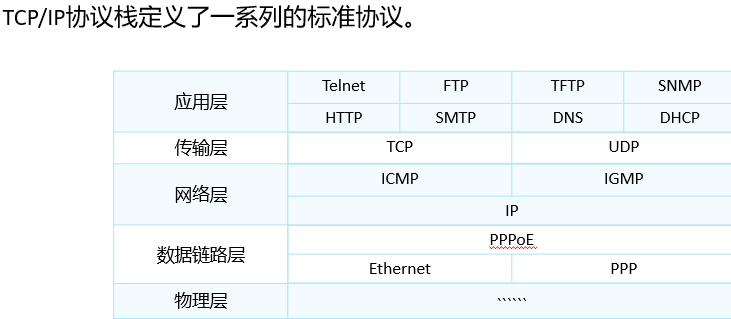
华为数通HCIA-网络模型
TCP 网络通信模式 作用:指导网络设备的通信; OSI七层模型: 7.应用层:由应用层协议(http、FTP、Telnet.)为应用程序产生对应的数据; 6.表示层:将应用层产生的数据转换成网络设备看…...

端口的解说
端口的定义 端口是指计算机与外部交互的出入口,可以按照所见性分为物理端口和虚拟端口 物理端口: USB、HDMI、PDP、VGA、CUP等虚拟端口:mysql——>25, ssh——>22 、http——>80 、https——>443等 IP地址只能锁定到计算机&am…...

“深入了解Spring Boot: 快速构建微服务应用的利器“
标题:深入了解Spring Boot: 快速构建微服务应用的利器 摘要: Spring Boot是一个基于Spring框架的开发工具,旨在提供快速、方便地构建微服务应用。本文将深入探讨Spring Boot的特点和优势,以及如何使用示例代码构建一个简单的微服…...

华为OD机试 Java 实现【批量处理任务】【2023 B卷 200分】,二分查找
目录 专栏导读一、题目描述二、输入描述三、输出描述四、二分查找五、解题思路六、Java算法源码七、效果展示1、输入2、输出3、说明 华为OD机试 2023B卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(…...

C# 2的幂
231 2的幂 给你一个整数 n,请你判断该整数是否是 2 的幂次方。如果是,返回 true ;否则,返回 false 。 如果存在一个整数 x 使得 n 2x ,则认为 n 是 2 的幂次方。 示例 1: 输入:n 1 输出&a…...

linux vi指令大全
vi 使用以及快捷键 vi编辑器是所有Unix及Linux系统下标准的编辑器,它的强大不逊色于任何最新的文本编辑器,这里只是简单地介绍一下它的用法和一小部分指令。由于对Unix及Linux系统的任何版本,vi编辑器是完全相同的,因此您可以在其…...

jdk8使用okhttp发送http2请求
本文主要用于工作记录,在项目中遇到了就记录一下 在早期,原生的JDK8是不支持HTTP/2协议的,所以,要想使用这个特性,需要有web服务器和应用环境的支持, 例如:在VM中增加-Xbootclasspath/p:/Users…...

virbr是什么设备
virbr是什么设备 virbr是一个虚拟桥接网络设备,通常由虚拟机管理程序(如 KVM、VirtualBox 或者 libvirt 等)创建和管理。它用于在宿主机和虚拟机之间进行网络连接,以便虚拟机可以通过宿主机访问网络。 默认情况,libv…...

MyBatis缓存-提高检索效率的利器--二级缓存
文章目录 缓存-提高检索效率的利器缓存-官方文档二级缓存基本介绍二级缓存原理图 二级缓存快速入门快速入门注意事项和使用陷阱理解二级缓存策略的参数 四大策略如何禁用二级缓存mybatis 刷新二级缓存的设置 缓存-提高检索效率的利器 缓存-官方文档 文档地址: https://mybati…...

开心档之CSS !important 规则
CSS !important 规则 CSS !important 规则 CSS是网页中最常用的样式语言,用来改变网页的颜色、字体、布局等等。但是当多个样式规则作用于同一个元素上时,由于优先级的差异,可能会出现样式被覆盖的情况。为了解决这个问题,CSS中提…...

ESP32-S2物联网实战:IPv6配置与Adafruit IO双向通信
1. 项目概述与核心价值如果你手头有一块ESP32-S2开发板,并且已经厌倦了仅仅让它连上Wi-Fi、点个灯,想让它真正“活”起来,成为一个能融入现代互联网、能与云端自由对话的智能节点,那么这篇文章就是为你准备的。我们将深入两个在物…...

AI驱动博客平台CodeBlog-app:开发者技术分享的智能解决方案
1. 项目概述:一个为开发者而生的AI驱动博客平台最近在GitHub上看到一个挺有意思的开源项目,叫CodeBlog-ai/codeblog-app。光看名字,你可能会觉得这又是一个普通的博客系统,或者是一个AI写作工具。但当我深入去研究它的代码和设计理…...

Ix开源平台:基于Kubernetes的私有云与家庭实验室一体化管理方案
1. 项目概述与核心价值最近在折腾一个叫Ix的开源项目,它来自ix-infrastructure这个组织。乍一看这个名字,你可能觉得有点抽象,但如果你对自托管、家庭实验室、私有云或者想找一个更现代、更易用的 TrueNAS 替代品感兴趣,那这个项目…...

从零构建个人知识库:Go+React全栈项目RocketNotes实战解析
1. 项目概述:从零到一构建个人知识管理工具最近在整理个人笔记和代码片段时,发现了一个挺有意思的开源项目fynnfluegge/rocketnotes。乍一看这个名字,可能会联想到火箭(Rocket)和笔记(Notes)的结…...

Linuxbonding链路稳定性治理方法
Linuxbonding链路稳定性治理方法这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限…...

如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南
如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏卡顿和掉帧?OpenSpeedy是一款…...

Steam成就管理器终极指南:3步修复错失的游戏成就
Steam成就管理器终极指南:3步修复错失的游戏成就 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&a…...

DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具
DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款革命性的免费开源工具,专为PC游戏玩家设计,能够智能管理、…...

如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南
如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_…...

基于Feather微控制器的智能灯光系统:颜色感应与BLE遥控实现
1. 项目概述与核心价值又到了折腾点节日氛围的时候了。往年都是买现成的彩灯串,总觉得少了点意思,今年决定自己动手,做个能“听懂”指令、甚至能“看见”颜色的智能灯光系统。这个项目的核心,就是用一块小小的微控制器,…...