【NVIDIA CUDA】2023 CUDA夏令营编程模型(一)
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接
本人就职于国际知名终端厂商,负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。
博客内容主要围绕:
5G/6G协议讲解
算力网络讲解(云计算,边缘计算,端计算)
高级C语言讲解
Rust语言讲解
文章目录
- CUDA编程模型
- 一、异构计算术语
- 二、CUDA安装
- 2.1 适用设备
- 2.2 软件安装
- 2.3 查看当前设备参数
- 2.4 CUDA程序示例
- 三、CUDA程序的编写
- 四、CUDA关键字介绍
- 4.1 \_\_global__关键字
- 4.2 \_\_device__关键字
- 4.3 \_\_host__关键字
- 五、CUDA程序的编写
- 五、CUDA线程层次
- 六、CUDA内存操作
- 6.1 内存分配
- 6.2 内存拷贝
- 6.3 内存释放
- 七、获取CUDA线程索引
- 八、CUDA 的线程分配
- 九、GPU的存储单元
- 十、CUDA错误检测
- 十一、CUDA统一内存(Unified Memory)
- 十二、CUDA事件
- 十三、NVPROF
CUDA编程模型
一、异构计算术语
Host:CPU和内存(host memory)
Device:CPU和内存(host memory)

二、CUDA安装
2.1 适用设备
所有包含NVIDIA GPU的服务器,工作站,个人电脑,嵌入式设备等电子设备
2.2 软件安装
- Windows:https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html
只需安装一个.exe的可执行程序 - Linux:https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
按照上面的教程,需要6 / 7 个步骤即可 - Jetson: https://developer.nvidia.com/embedded/jetpack
直接利用NVIDIA SDK Manager 或者 SD image进行刷机即可
2.3 查看当前设备参数
在CUDA sample中1_Utilities/deviceQuery文件夹下的deviceQuery程序。以Ubuntu为例,deviceQuery 程序
在:/usr/local/cuda/samples/1_Utilities/deviceQu
2.4 CUDA程序示例
https://github.com/NVIDIA/cuda-samples
三、CUDA程序的编写
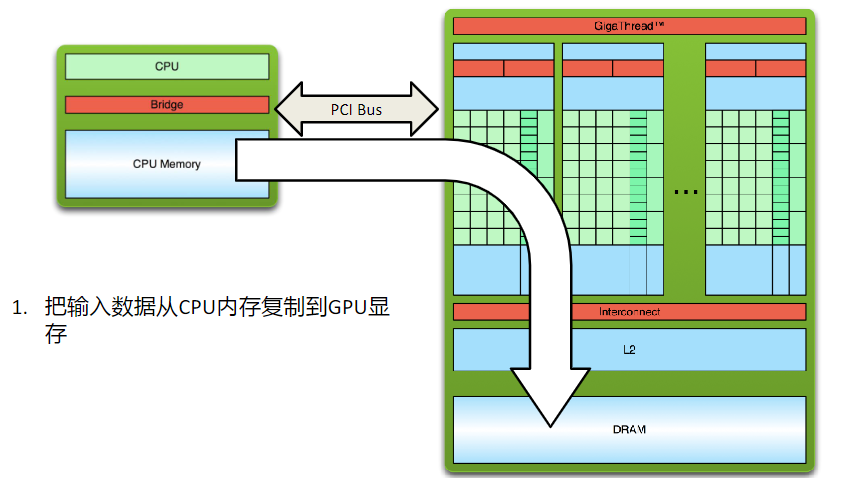
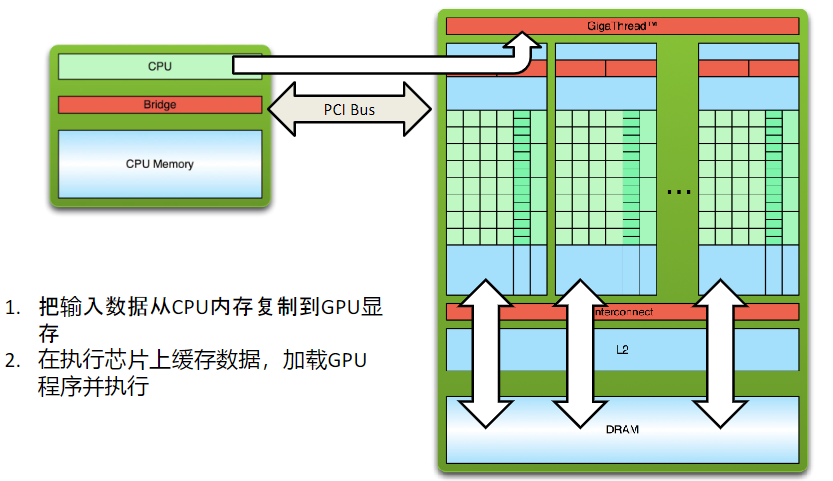
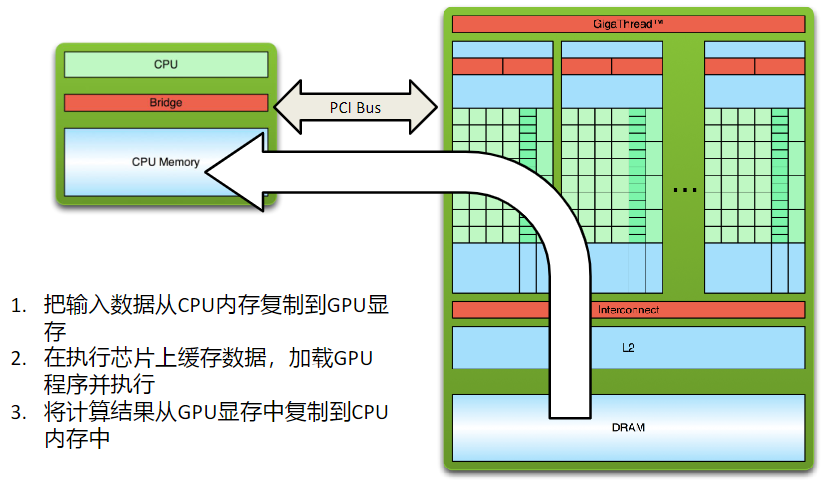
四、CUDA关键字介绍
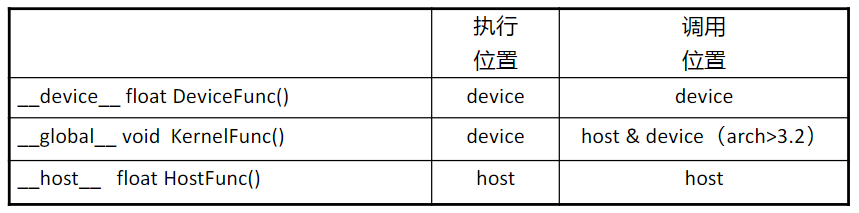
4.1 __global__关键字
__global__执行空间说明符将函数声明为内核。 它的功能是:
- 在设备上执行;
- 可从主机调用,可在计算能力为 3.2或更高的设备调用;
- __global__ 函数必须具有 void 返回类型,并且不能是类的成员;
- 对 global 函数的任何调用都必须指定其执行配置;
- 对 global 函数的调用是异步的,这意味着它在设备完成执行之前返回;
4.2 __device__关键字
__device__ 执行空间说明符声明了一个函数:
- 在设备上执行;
- 只能从设备调用;
- __global__ 和 __device__ 执行空间说明符不能一起使用;
4.3 __host__关键字
__host__ 执行空间说明符声明了一个函数:
- 在主机上执行;
- 只能从主机调用;
- __global__ 和 __host__ 执行空间说明符不能一起使用。但是, __device__ 和 __host__ 执行空间说明
符可以一起使用,在这种情况下,该函数是为主机和设备编译的;
五、CUDA程序的编写
- __global__ 定义一个 kernel 函数
- 入口函数,CPU上调用,GPU上执行;
- 必须返回void;
- __device__ and __host__ 可以同时使用

五、CUDA线程层次
HelloFromGPU <<<grid_size, block_size>>>();
- Thread: sequential execution unit
- 所有线程执行相同的核函数
- 并行执行
- Thread Block: a group of threads
- 执行在一个Streaming Multiprocessor (SM)
- 同一个Block中的线程可以协作
- Thread Grid: a collection of thread blocks
- 一个Grid当中的Block可以在多个SM中执行
- 内建变量
- threadIdx.[x y z]:是执行当前kernel函数的线程在block中的索引值;
- blockIdx.[x y z]:是指执行当前kernel函数的线程所在block,在grid中的索引值;
- blockDim.[x y z]:表示一个block中包含多少个线程;
- gridDim.[x y z]:表示一个grid中包含多少个block;
例如,dim3 grid(3,2,1), block(5,3,1)的线程分布示意图:
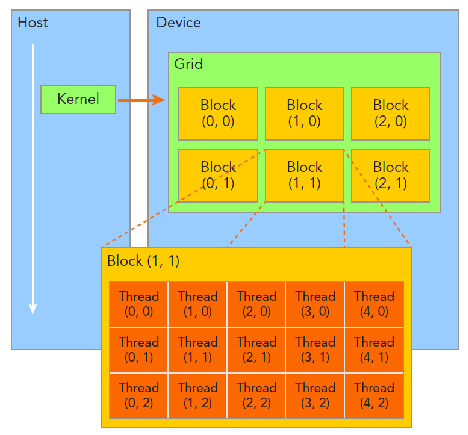
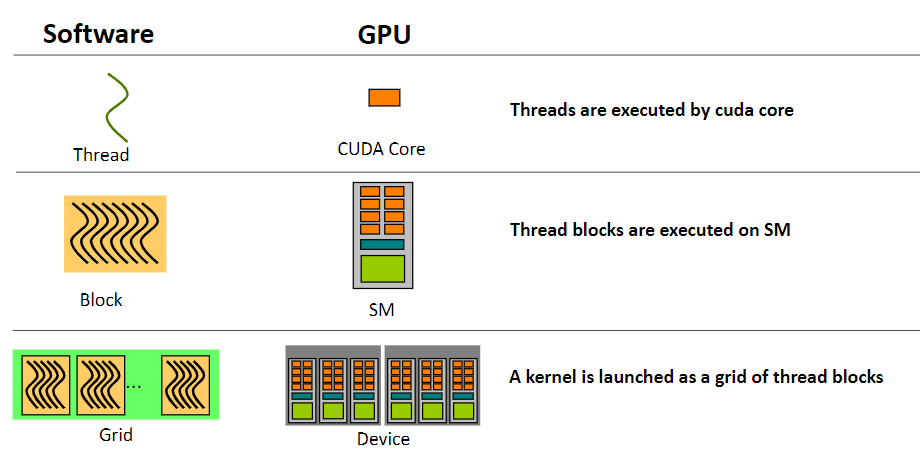
一个cuda线程在一个cuda core上执行,一个block在一个sm上执行,一个grid在整个device上执行,但是反之不成立。
六、CUDA内存操作
6.1 内存分配
__host__ __device__ cudaError_t cudaMalloc(void** devPtr, size_t size)
- devPtr:Pointer to allocated device memory
- Size:Requested allocation size in bytes
6.2 内存拷贝
cudaMemcpy(void *dst, const void *src, size_t count, cudaMemcpyKind kind)
- dst: destination memory address
- src: source memory address
- count: size in bytes to copy
- kind: direction of the copy
- cudaMemcpyKind
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
- cudaMemcpyHostToHost
- cudaMemcpyKind
6.3 内存释放
cudaFree()
七、获取CUDA线程索引
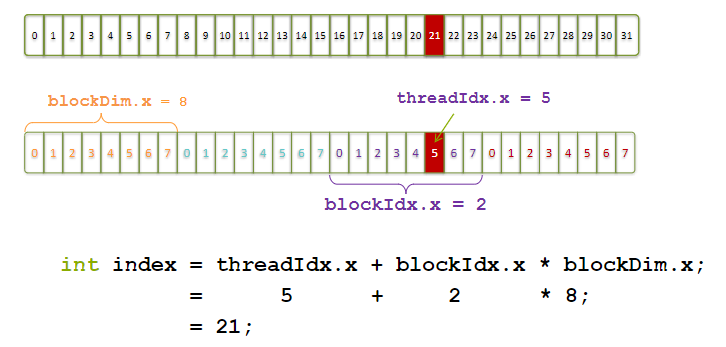
对于一维数据来说:
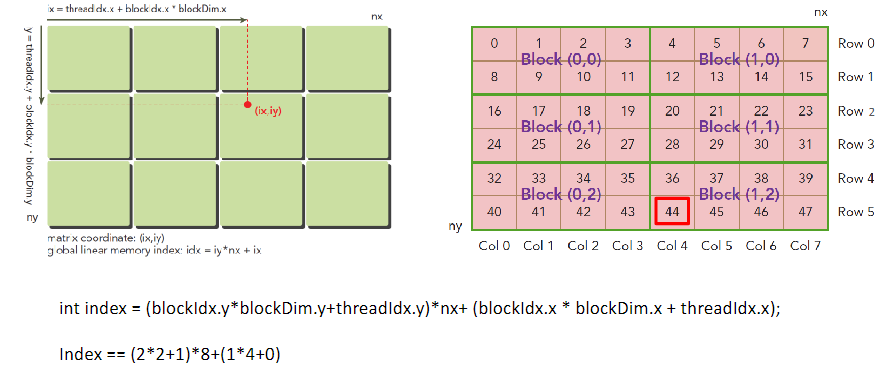
对于二维数据来说:
八、CUDA 的线程分配
一个warp包含32个cuda线程,所以一个block会被分成一个或多个warp执行。

九、GPU的存储单元
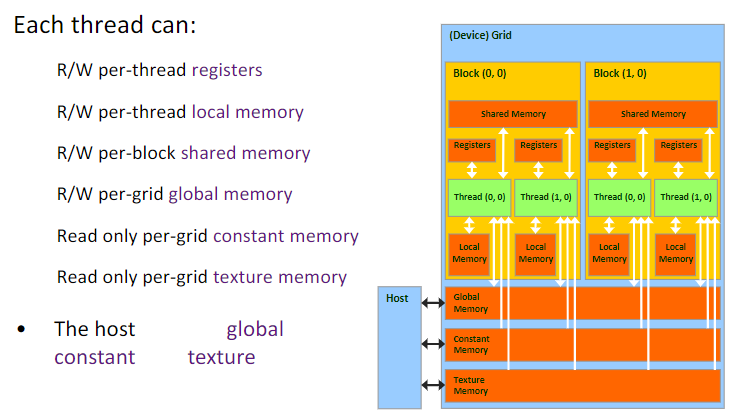
十、CUDA错误检测
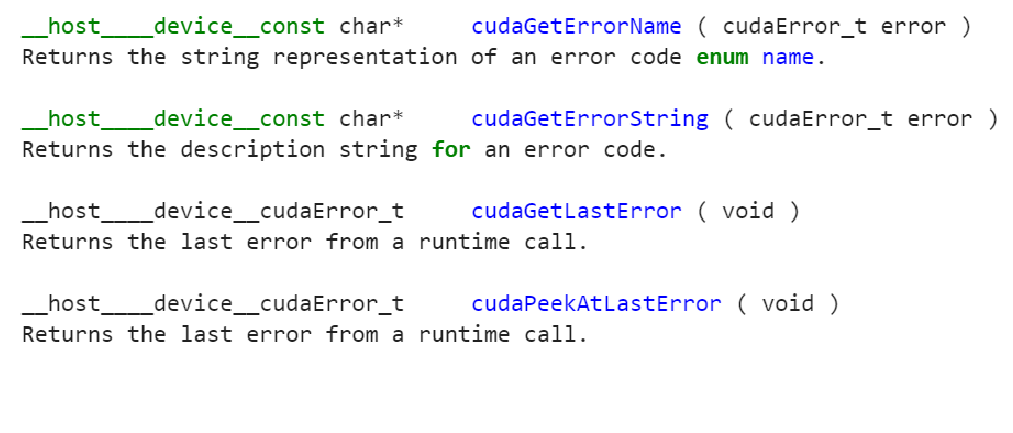

注意:
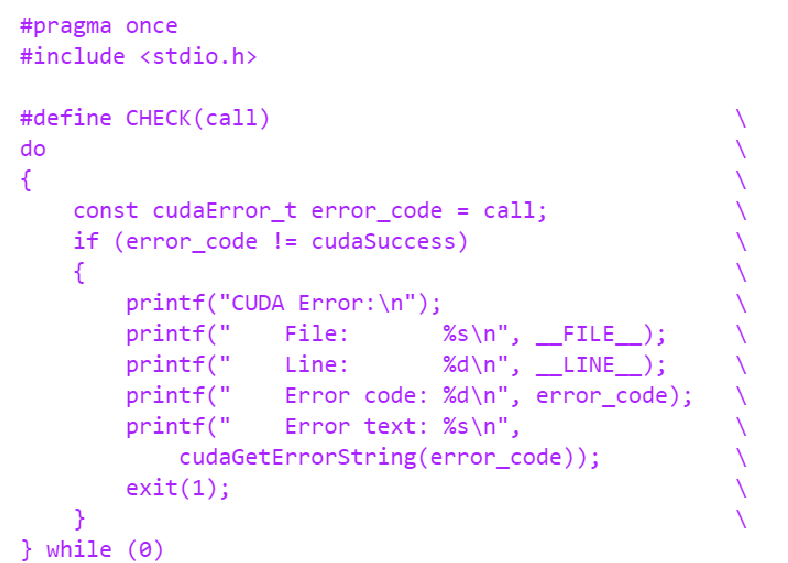
cudaGetLastError(void)与cudaPeekAtLastError(void)的区别是,调用cudaGetLastError(void)之后,会将错误类型重置为cudaSuccess,然后调用cudaPeekAtLastError(void)后不会修改cudaError_t的状态。可以从下面的例子中看出来:

一个通用的cuda error检测宏:
十一、CUDA统一内存(Unified Memory)
统一内存是可从系统中的任何处理器访问的单个内存地址空间。这种硬件/软件技术允许应用程序分配可以从
CPU s 或 GPUs 上运行的代码读取或写入的数据。分配统一内存非常简单,只需将对 malloc() 或 new 的调用替换
为对 cudaMallocManaged() 的调用,这是一个分配函数,返回可从任何处理器访问的指针。

分配Unified Memory有两种方法:
-
cudaError_t cudaMallocManaged(void **devPtr, size_t size, unsigned int flags=0);
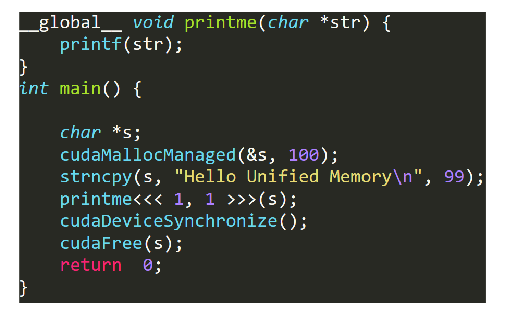
-
使用关键字
__managed__;
使用了统一内存之后并不意味之CPU和GPU使用了同一块内存空间。如下图所示,如果GPU要访问的页面已经在GPU Memory中,则没有任何异常;如果GPU要访问的页面不在当前的GPU Memory中,则将CPU Memory中的page迁移到GPU Memory中。

统一内存的优势:
- 可直接访问CPU内存、GPU显存,不需要手动拷贝数据;
- CUDA 在现有的内存池结构上增加了一个统一内存系统,程序员可以直接访问任何内存/显存资源,或者在合法
的内存空间内寻址,而不用管涉及到的到底是内存还是显存; - CUDA 的数据拷贝由程序员的手动转移,变成自动执行,因此,它仍然受制于PCI-E的带宽和延迟;
十二、CUDA事件
CUDA event本质是一个GPU时间戳,这个时间戳是在用户指定的时间点上记录的。由于GPU本身支持记录时间戳,因此就避免了当使用CPU定时器来统计GPU执行时间可能遇到的诸多问题。

如何使用上述事件函数:
-
声明:
cudaEvent_t event; -
创建:
cudaError_t cudaEventCreate(cudaEvent_t* event); -
添加事件到当前执行流:
cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream
= 0); -
等待事件完成,设立flag:
cudaError_t cudaEventSynchronize(cudaEvent_t event);//阻塞
cudaError_t cudaEventQuery(cudaEvent_t event);//非阻塞当然,我们也可以用它来记录执行的事件:
cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start,
cudaEvent_t stop);cudaEventRecord()视为一条记录当前时间的语句,并且把这条语句放入GPU的未完成队列中。因为直到GPU执行完了再调用 cudaEventRecord()之前的所有语句时,事件才会被记录下来。且仅当GPU完成了之前的工作并且记录了stop事件后,才能安全地读取stop时间值。
-
销毁:
cudaError_t cudaEventDestroy(cudaEvent_t event);
代码示例:
cudaEvent_t start, stop;
cudaEventCreate( &start );
cudaEventCreate( &stop ) ;
cudaEventRecord( start) ;
// GPU
//
//.........................
cudaEventRecord( stop)
cudaEventSynchronize( stop );
float elapsedTime;
cudaEventElapsedTime( &elapsedTime,start, stop ) );
printf( "Time to generate: %.2f ms\n", elapsedTime );
cudaEventDestroy( start );
cudaEventDestroy( stop );
十三、NVPROF
Kernel Timeline 输出的是以gpu kernel 为单位的一段时间的运行时间线,我们可以通过它观察GPU在什么时候有闲置或者利用不够充分的行为,更准确地定位优化问题。nvprof是nvidia提供的用于生成gpu timeline的工具,其为cuda toolkit的自带工具。
非常方便的分析工具!
nvprof -o out.nvvp a.exe
可以结合nvvp或者nsight进行可视化分析
https://docs.nvidia.com/cuda/profiler-users-guide/index.html#nvprof-overview

相关文章:
【NVIDIA CUDA】2023 CUDA夏令营编程模型(一)
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客…...
SHELL——备份脚本
编写脚本,使用mysqldump实现分库分表备份。 1、获取分库备份的库名列表 [rootweb01 scripts]# mysql -uroot -p123456 -e "show databases;" | egrep -v "Database|information_schema|mysql|performance_schema|sys" mysql: [Warning] Using …...

VS创建wsdl服务提供给java调用
文章目录 前言1.c#创建asp.net web服务1.1 创建ASP.NET Web应用程序1.2 添加服务类1.3 定义服务方法1.3 浏览服务1.4 发布服务1.5 IIS部署服务 2.Java中调用服务2.1 用动态客户端工厂类调用2.1.1 引入依赖2.1.2 调用测试代码2.1.3 测试结果 2.2 创建代理类进行调用2.2.1 使用ws…...

盘点 TypeScript 内置类型
盘点 TypeScript 内置类型 盘点 TypeScript 内置类型PartialRequiredReadonlyPickRecordExcludeExtractOmitNonNullableParametersConstructorParametersReturnTypeInstanceTypeUppercaseLowercaseCapitalizeUncapitalize 盘点 TypeScript 内置类型 当开发者开始学习 TypeScri…...

Netty 执行了多次channelReadComplete()却没有执行ChannelRead()
[TOC](Netty 执行了多次channelReadComplete()) Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,make a better result,wait for change,challenge Survive. happy for hardess to solve denpendies.…...

直线导轨的精密等级以及划分依据
直线导轨的作用,是用来支撑和引导运动部件,按给定的方向做往复直线运动的,直线导轨是高精密度的传动元件,广泛使用在各行各业中。 直线导轨的精密等级是判断产品质量的一个重要指标。在众多种类的直线导轨产品中,精密等…...
Ubuntu Server版 之 apache系列 常用配置 以及 隐藏 版本号 IP、Port 搭建服务案例
查看版本 旧的 用 httpd -v 新的 用 apache2 -v 配置检测 旧的 httpd -t 新的 apachectl configtest window用的apache 是 httpd -t Linux 中 apachectl configtest 主配置文件 之前旧版apache 是httpd 现在都改成 apache2 /etc/apache2/apache2.conf window中 httpd.con…...
从入门到精通系列之七:K8s的基本概念和术语之安全类)
Kubernetes(K8s)从入门到精通系列之七:K8s的基本概念和术语之安全类
Kubernetes K8s从入门到精通系列之七:K8s的基本概念和术语之安全类 一、安全类二、Role和ClusterRole三、RoleBinding和ClusterRoleBinding一、安全类 开发的Pod应用需要通过API Server查询、创建及管理其他相关资源对象,所以这类用户才是K8s的关键用户。K8s设计了Service A…...

网络安全(黑客)自学误区
前言 网络安全是当今社会中至关重要的议题。随着科技的迅猛发展,网络已经渗透到我们生活的方方面面,给我们带来了巨大的便利和机遇。然而,网络也存在着各种风险和威胁,如黑客攻击、数据泄露等。因此,学习网络安全知识…...

在OK3588板卡上部署模型实现人工智能OCR应用
一、主机模型转换 我们依旧采用FastDeploy来部署应用深度学习模型到OK3588板卡上 进入主机Ubuntu的虚拟环境 conda activate ok3588 安装rknn-toolkit2(该工具不能在OK3588板卡上完成模型转换) git clone https://github.com/rockchip-linux/rknn-to…...

在linux中怎样同时运行三个微服务保证退出时不会终止
前言 1.maven中打jar包 使用插件打包,必须在pom.xml中添加插件,否则不能在linux中编译运行 <build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version&g…...
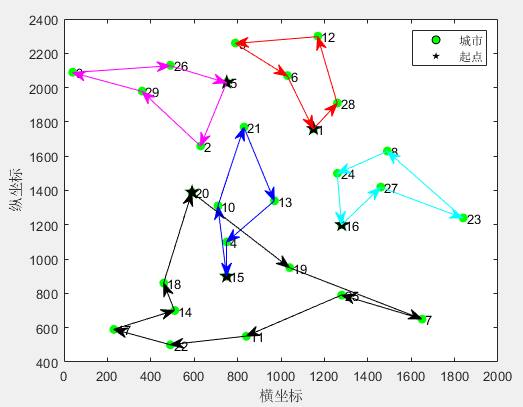
MD-MTSP:成长优化算法GO求解多仓库多旅行商问题MATLAB(可更改数据集,旅行商的数量和起点)
一、成长优化算法GO 成长优化算法(Growth Optimizer,GO)由Qingke Zhang等人于2023年提出,该算法的设计灵感来源于个人在成长过程中的学习和反思机制。学习是个人通过从外部世界获取知识而成长的过程,反思是检查个体自…...

Python入门一
目录: python基本操作python基本数据类型python字符串基本操作python的运算符python控制流-判断python控制流-循环python常用数据结构-列表python常用数据结构-元组python常用数据结构-集合python常用数据结构-字典python函数python函数进阶与参数处理pythonlambda…...

mysql_2.4——安装常见问题
1. 将MySQL添加到环境变量 将 mysql 的 bin 目录地址添加到 系统环境变量 --> PATH 中 2. 将MySQL添加到服务 以管理员的方式启动 cmd (命令提示窗口),使用命令进入到 [mysql]\bin ,执行如下命 令。 # mysqld --install (服务名) # 如: mysqld --…...
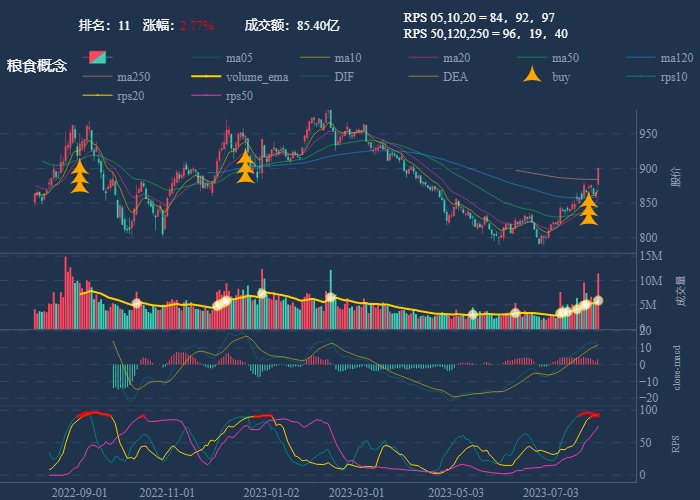
行业追踪,2023-07-31,板块多数都是指向消费
自动复盘 2023-07-31 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...
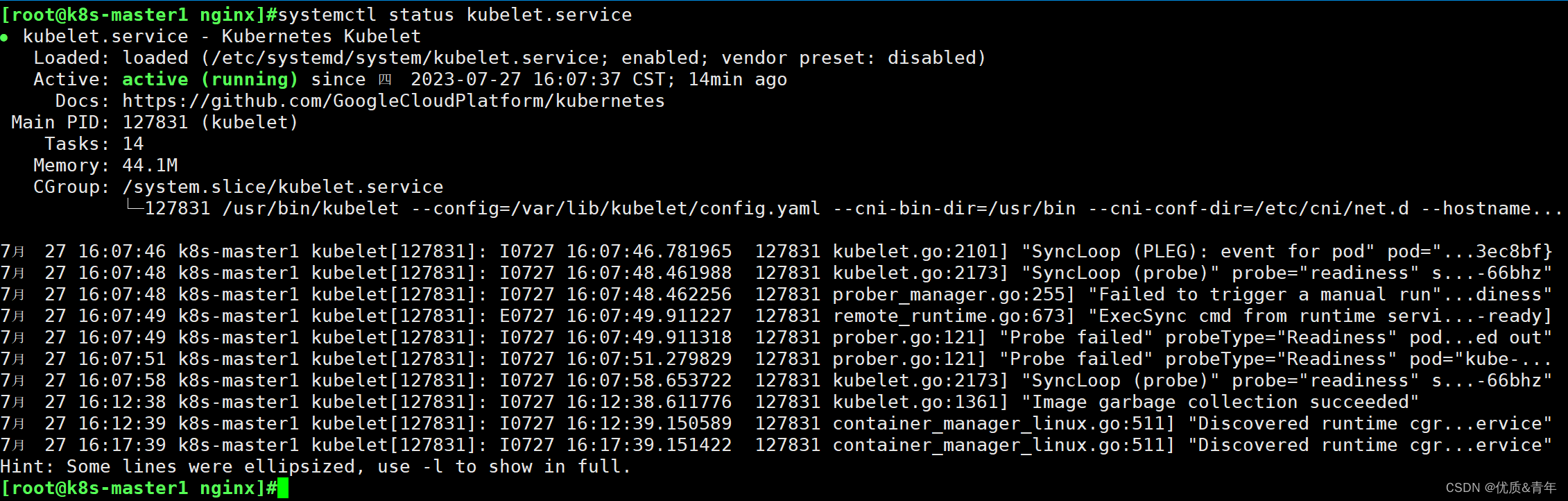
K8S故障排查
故障现象:部署pod时,报错没发调度到节点。 排查步骤: 1、查看集群的状态 [rootk8s-master1 nginx]#kubectl get nodes2、查看k8s组件的状态-kubelet,kube-apiservice 3、查看docker的Cgroup driver和k8s的Cgroup driver类型&…...
idea集成jrebel实现热部署
文章目录 idea集成jrebel实现热部署下载jrebel 插件包下载jrebel mybatisplus extensition 插件包基础配置信息情况一其次情况三情况四情况五情况六情况七 验证生效与否 Jrebel热部署不生效的解决办法 idea集成jrebel实现热部署 在平常开发项目中,我们通常是修改完…...

【Git系列】Git配置SSH免密登录
🐳Git配置SSH免密登录 🧊1.设置用户名和邮箱🧊2. 生成密钥🧊3.远程仓库配置密钥🧊2. 免密登录 在以上push操作过程中,我们第一次push时,是需要进行录入用户名和密码的,比较麻烦。而且…...
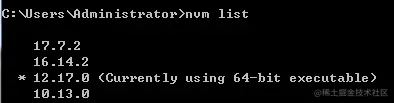
Node.js 安装与版本管理(nvm 的使用)
安装 Node.js Node.js 诞生于 2009 年 5 月,截至今天(2022 年 3 月 26 号)的最新版本为 16.14.2 LTS 和 17.8.0 Current,可以去官网下载合适的版本。 其中,LTS(Long Term Support) 是长期维护…...
SpringBoot项目中使用Lombok插件中Slf4j日志框架
前言:idea需要安装lombok插件,因为该插件中添加了Slf4j注解,可以将Slf4j翻译成 private static final org.slf4j.Logger logger LoggerFactory.getLogger(this.XXX.class); springboot本身就内置了slf4j日志框架,所以不需要单独…...
)
保姆级教程:在Ubuntu 20.04上从源码编译aarch64-linux-gnu交叉工具链(GCC 9.2.0 + Glibc 2.30)
深度实践:从源码构建aarch64-linux-gnu交叉工具链全指南 在嵌入式开发领域,交叉编译工具链的构建能力是区分普通开发者与资深工程师的重要标志。当现成的预编译工具链无法满足特定需求时,从源码手动构建工具链不仅能解决兼容性问题࿰…...

番茄小说下载器:打造属于你的个人数字图书馆终极指南
番茄小说下载器:打造属于你的个人数字图书馆终极指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾经遇到过这样的场景?深夜追更小说时网络突然断线&…...

去中心化AI市场BloomBee:技术架构、挑战与开发者实践指南
1. 项目概述:当AI遇见去中心化,BloomBee想解决什么?最近在AI和Web3的交叉领域,一个名为BloomBee的项目引起了我的注意。它的名字很有意思,“Bloom”是开花、繁荣的意思,“Bee”是蜜蜂,合起来像是…...
从零构建大语言模型:Transformer架构、训练技巧与实战指南
1. 项目概述:从零构建你自己的大语言模型最近几年,大语言模型(LLM)的热度居高不下,从ChatGPT到Claude,再到国内外的各种开源模型,它们展现出的理解和生成能力让人惊叹。但你是否也和我一样&…...

Go语言构建开发者命令行工具箱:navis项目架构与实现解析
1. 项目概述:一个为开发者打造的“导航”工具箱最近在GitHub上看到一个挺有意思的项目,叫navis,作者是NaveenBuidl。光看名字,你可能会联想到“导航”或者“航行”,没错,这个项目的核心定位就是一个为开发者…...
)
别再只会Commit了!用Git Desktop搞定分支合并与冲突解决(附真实开发场景)
别再只会Commit了!用Git Desktop搞定分支合并与冲突解决(附真实开发场景) 当你第一次接触Git时,可能觉得它就是个"保存按钮"——每次改完代码就commit一下。但随着项目规模扩大,特别是多人协作时,…...
NeoPixel光剑制作全攻略:从WS2812B原理到实战装配
1. 项目概述:从零件到光剑的旅程如果你和我一样,是个对《星球大战》里的光剑毫无抵抗力,同时又喜欢动手折腾电子玩意儿的人,那么用NeoPixel灯带自制一把会发光、能变色的光剑,绝对是件充满成就感的事。这不仅仅是把灯塞…...

Claude API钩子框架设计:非侵入式中间件与生命周期管理实践
1. 项目概述与核心价值最近在折腾一些AI应用开发,发现一个挺有意思的现象:很多开发者想给Claude API的调用过程加点“料”,比如在请求发出前或收到响应后,自动执行一些自定义逻辑。可能是为了日志记录、数据清洗、请求重试&#x…...

大气层系统深度解析:构建Switch的六层数字防护体系
大气层系统深度解析:构建Switch的六层数字防护体系 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 在Nintendo Switch的定制固件生态中,Atmosphere(大气…...

Arm Neoverse CMN-700性能监控与优化实践
1. Arm Neoverse CMN-700性能监控体系解析在现代多核处理器架构中,性能监控单元(PMU)如同系统的"听诊器",能够实时捕捉微架构层面的各种行为指标。Arm Neoverse CMN-700作为面向基础设施级应用的互联架构,其PMU设计尤其强调对Mesh网…...